一种处理声音信号实现三维声场听觉效果的方法及装置与流程
本发明涉及音频信号技术领域,特别涉及一种处理声音信号实现三维声场听觉效果的方法及装置。
背景技术:
移动终端或者叫移动通信终端是指可以在移动中使用的计算机设备,广义的讲包括手机、笔记本、平板电脑、pos机甚至包括车载电脑。但是大部分情况下是指手机或者具有多种应用功能的智能手机以及平板电脑。随着网络和技术朝着越来越宽带化的方向的发展,移动通信产业将走向真正的移动信息时代。
耳机为人们使用移动终端带来方便,同时也带来危害。人戴上耳机后,外耳几乎处于闭塞状态。高音量的音频声压直接进入耳内,集中传递到很薄的耳膜上。同时,耳塞机震动膜与耳膜之间距离很近,声波传播的范围小而集中,对耳膜听觉神经的刺激比较大。时间长了,易引起耳鸣、失眠、头痛、耳闷胀痛以及渐进性听力减退。如果有种微型扬声器,能再现音频原来的三维声场,就能大大提高移动终端的用户体验。
mems(微机电系统)到目前为止国际上还没有它的统一的定义,但一般来说,mems是指可以采用微电子批量加工工艺制造的,集微型机构、微型传感器、微型致动器以及信号处理和控制电路、接口、通讯和电源等部件于一体的微型系统。微型扬声器是mems技术的一种具体应用。
微型扬声器是具有小型、薄型结构的微电声换能器,用于在自由声场状态下,将音频电信号通过电声的换能方式转变为失真小并具有足够声压级的可听声音,广泛应用于移动通信终端。
视听已进入三维时代,要想达到更好的视听体验,需要有与三维视频内容同步的三维声场听觉效果,才能真正达到身临其境的视听感受。近年来日本nhk公司推出了22.2声道系统,能够通过24个扬声器再现原来的三维声场。2011年mpeg着手制定三维音频的国际标准,在达到一定编码效率的同时希望能通过比较少的扬声去还原三维声场,以便能将该技术推广到移动终端。
技术实现要素:
本发明的目的在于,提供一种处理声音信号实现三维声场听觉效果的方法,可提升人类听觉对移动立体对象的感受,进而提供更为生动的三维环境,提升所模拟的三维声场的质量。
为了解决上述技术问题,第一方面,本发明实施例提供一种处理声音信号实现三维声场听觉效果的方法,用于移动终端,包括:
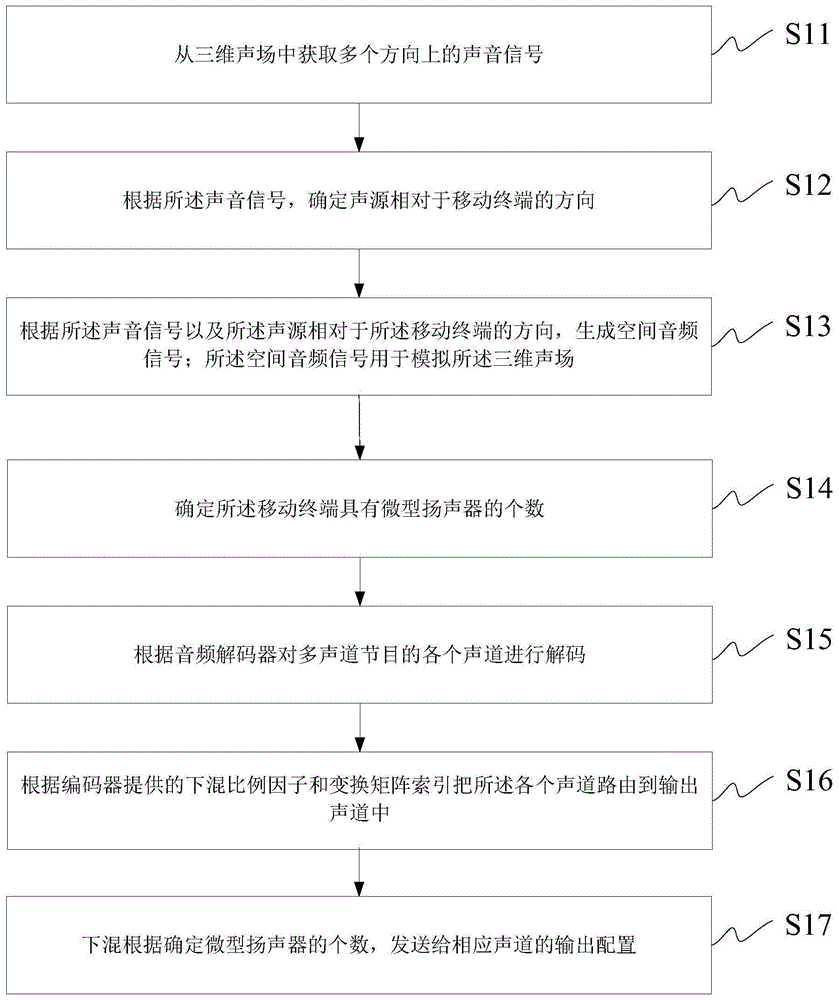
从三维声场中获取多个方向上的声音信号;
根据所述声音信号,确定声源相对于移动终端的方向;
根据所述声音信号以及所述声源相对于所述移动终端的方向,生成空间音频信号;所述空间音频信号用于模拟所述三维声场;
确定所述移动终端具有微型扬声器的个数;
根据音频解码器对多声道节目的各个声道进行解码;
根据编码器提供的下混比例因子和变换矩阵索引把所述各个声道路由到输出声道中;
下混根据确定微型扬声器的个数,发送给相应声道的输出配置。
在一个实施例中,根据所述声音信号,确定声源相对于移动终端的方向,包括:
获取所述移动终端上的麦克风接收到一个方向上的声音信号与另一个方向上的声音信号之间的到达时间差,所述移动终端上的麦克风用于接收至少四个方向上的声音信号;
根据所获取的到达时间差和所述移动终端上的麦克风在所述移动终端上的位置,确定所述声源相对于所述移动终端的方向。
在一个实施例中,获取所述移动终端上的麦克风接收到一个方向上的声音信号与另一个方向上的声音信号之间的到达时间差,包括:
根据音效定位算法,确定声音位置的时间差以及强度差。
第二方面,本发明还提供一种处理声音信号实现三维声场听觉效果的装置,包括:
获取模块,用于从三维声场中获取多个方向上的声音信号;
第一确定模块,用于根据所述声音信号,确定声源相对于移动终端的方向;
生成模块,用于根据所述声音信号以及所述声源相对于所述移动终端的方向,生成空间音频信号;所述空间音频信号用于模拟所述三维声场;
第二确定模块,用于确定所述移动终端具有微型扬声器的个数;
解码模块,用于根据音频解码器对多声道节目的各个声道进行解码;
路由模块,用于根据编码器提供的下混比例因子和变换矩阵索引把所述各个声道路由到输出声道中;
发送模块,用于下混根据确定微型扬声器的个数,发送给相应声道的输出配置。
在一个实施例中,所述第一确定模块,包括:
获取子模块,用于获取所述移动终端上的麦克风接收到一个方向上的声音信号与另一个方向上的声音信号之间的到达时间差,所述移动终端上的麦克风用于接收至少四个方向上的声音信号;
确定子模块,用于根据所获取的到达时间差和所述移动终端上的麦克风在所述移动终端上的位置,确定所述声源相对于所述移动终端的方向。
在一个实施例中,所述获取子模块,具体用于根据音效定位算法,确定声音位置的时间差以及强度差。
本发明的优点在于,本发明的一种处理声音信号实现三维声场听觉效果的方法,该方法可提升人类听觉对移动立体对象的感受,进而提供更为生动的三维环境,提升所模拟的三维声场的质量。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例提供的处理声音信号实现三维声场听觉效果的方法流程图;
图2为本发明实施例提供的生源传播示意图;
图3为本发明实施例提供的处理声音信号实现三维声场听觉效果的装置框图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
本发明实施例提供了一种处理声音信号实现三维声场听觉效果的方法,用于移动终端,参照图1所示,包括:
s11、从三维声场中获取多个方向上的声音信号;
s12、根据所述声音信号,确定声源相对于移动终端的方向;
s13、根据所述声音信号以及所述声源相对于所述移动终端的方向,生成空间音频信号;所述空间音频信号用于模拟所述三维声场;
s14、确定所述移动终端具有微型扬声器的个数;
s15、根据音频解码器对多声道节目的各个声道进行解码;
s16、根据编码器提供的下混比例因子和变换矩阵索引把所述各个声道路由到输出声道中;
s17、下混根据确定微型扬声器的个数,发送给相应声道的输出配置。
本实施例中,本发明实施例可以应用于一种移动终端,移动终端上布置有麦克风,麦克风用于对三维声场进行测量,并从三维声场中获取声音信号并将声音信号传输给移动终端中的处理器进行增强处理,并且可以将增强前后的声音信号传输给移动终端中的存储器进行存储。
具体的,移动终端上布置的麦克风可以是全指向型的麦克风,也可以是具有一定指向性的麦克风,比如,具体可以在移动终端上布置mems(micro-electro-mechanicalsystem,微机电系统)麦克风,或是ecm(electretcondensermicrophones,驻极体电容传声器)麦克风。
在本实施例中,麦克风在移动终端上的布置方式可以有多种,在不同的布置方式中移动终端上的麦克风的数量和位置并不限定,在本实施例中选取4个麦克风和3个麦克风的情况为例进行说明。例如:在移动终端上可以将4个麦克风分别设置在移动终端的四个角上。也可以将4个麦克风分别设置在移动终端的四个边上。还可以在移动终端的底边、正面的听筒旁边、背面摄像头附近以及背面底边附近各设置一个麦克风;再例如:可以在移动终端上只设置3个麦克风。
步骤s12中,根据所获取的声音信号,获取声源相对于所述移动终端的方向。参照图2所示,从声源发出来的声音会直接传播到左耳和右耳,但因为左耳离声源近,所以声音会先到达左耳再到达右耳,由于在传播过程中的衰减,左耳听到的声音要比右耳大,这是直接的声音信号,大脑会接收到这两个耳传过来的信号。同时,从声源发出的声音也会被周围的物体反射,这些反射比直接信号有一定的延迟并且音量更小,这些是间接的声音信号。大脑会采集到直接信号与所有的间接信号并比较从左耳与右耳采集的信号,经过分析计算,从而达到定位声音源的效果。在了解大脑的工作模式后,我们可以通过控制两个音响或者耳机的音量与延迟来达到模拟3d声源的效果,让大脑产生出虚拟的3d声音场景。
移动终端通过麦克风对发出声源进行估计,并得到声源相对于移动终端的方向。在本实施例中,对声源进行估计的方法可以有多种,比如基于最大输出功率的可控波束形成技术,或者是基于到达时间差的定位技术,还可以是基于高分辨率谱估计的定位技术等。
并且,移动终端在对声源位置进行估计的同时,还可以对接收到的声音信号进行增强处理。例如:移动终端可以利用波束形成、空间预测、听觉场景分析等技术手段获得各个方向增强后的声音信号。比如:移动终端通过波束形成增强声音信号的具体方法可以包括:延迟相加波束形成、滤波相加等固定波束形成技术,或者是基于最小方差无畸变响应准则的自适应波束形成算法、线性约束最小方差波束形成、旁瓣抵消算法等自适应波束形成技术,还可以是差分波束形成技术;移动终端通过空间预测增强声音信号的具体方法可以包括:通过预先设定某些方向上期望采集到的空间声信号,然后通过预先训练好的最优滤波器组,利用空间预测技术将移动终端上的声音接收器接收到的各个方向上的声音信号转换成为预先设定的某些方向上期望输出信号,从而使得输出的增强后的声音信号的噪声最小且预测误差趋近于零;在本实施例中,听觉场景分析技术具体可以是盲源分离算法。
增强得到至少具有波束指向性的两个方向上的声音信号,由一个麦克风接收到的声音信号经过增强处理得到的具有波束指向性一个方向上的声音信号,例如:可以区分为前方、后方、左侧、右侧等不同方向声源向移动终端发送的各个方向上的声音信号。比如:移动终端对接收到的声音信号进行增强处理后生成四个方向增强后的声音信号,分别具有左前侧、右前侧、左后侧、右后侧的波束指向性;也可以生成四个方向增强后的声音信号分别具有前侧、后侧、左侧、右侧的波束指向性。在本实施例中,也可以根据具体需要,由多个方向不同指向性的声音信号合成某一个指定方向上的声音信号,且经过增强处理得到的具有波束指向性的声音信号的波束形状可以为心形指向,也可以是超心形等其他形状。103,根据所述声源相对于所述移动终端的方向和所获取的声音信号,得到空间音频信号。
其中,所述空间音频信号用于模拟所述三维声场,所述三维声场可以理解为移动终端周围在一定范围内的声场,声源可以从三维声场任意方向发出声音信号,并被移动终端接收。
例如:移动终端利用声源相对于移动终端的方向和接收到的各个方向上的声音信号,产生用5.1声道回放系统模拟声场的空间音频信号,移动终端可以将增强后得到的各个方向上的声音信号映射为用于组成5.1声道回放系统模拟声场的空间音频信号所需的总共六个方向上的声音信号,并利用声源相对于移动终端的方向,进一步提升用5.1声道回放系统模拟声场的空间音频信号所需的六个方向上的声音信号的分离度,比如:移动终端可以根据声源相对于移动终端的方向,计算每个方向用5.1声道回放系统模拟声场的空间音频信号所需的声音信号的增益调整参数,并利用增益调整参数调整用5.1声道回放系统模拟声场的空间音频信号所需的声音信号。空间音频信号至少包括左侧方向上的信号、右侧方向上的信号、中侧方向上的信号、左后环绕信号、右后环绕信号。
其中,移动终端接收到的各个方向上的声音信号与用5.1声道回放系统模拟声场的空间音频信号所需的六个方向上的声音信号之间的对应关系可以有多种。比如:对移动终端接收到的声音信号进行增强并输出四个方向上的声音信号,分别为左前、左后、右前以及右后;并将左前方向上的声音信号映射为用5.1声道回放系统模拟声场的空间音频信号所需的左侧方向上的声音信号;将右前方向上的声音信号映射为用5.1声道回放系统模拟声场的空间音频信号所需的右侧方向上的声音信号;根据左前方向上的声音信号和右前方向上的声音信号求取平均信号并将平均信号映射为用5.1声道回放系统模拟声场的空间音频信号所需的中侧方向上的信号;将左后方向上的声音信号映射为用5.1声道回放系统模拟声场的空间音频信号所需的左后环绕声音信号;将右后方向上的声音信号映射为用5.1声道回放系统模拟声场的空间音频信号所需的右后环绕声音信号;根据左前方向、左后方向、右前方向和右后方向上的声音信号求取平均值并对平均值进行150hz的低通滤波处理,得到用5.1声道回放系统模拟声场的空间音频信号所需的重的低音信号。
再例如:对移动终端接收到的声音信号进行增强并输出四个方向上的声音信号,分别为前侧、后侧、左侧以及右侧四个方向上的声音信号;并将左侧方向与前侧方向上的声音信号的平均信号映射为用5.1声道回放系统模拟声场的空间音频信号所需的左侧方向上的声音信号;将右侧方向与前侧方向上的声音信号的平均信号映射为用5.1声道回放系统模拟声场的空间音频信号所需的右侧方向上的声音信号;将前侧方向上的声音信号映射为用5.1声道回放系统模拟声场的空间音频信号所需的中侧方向上的信号;将左侧方向与后侧方向上的声音信号的平均信号映射为用5.1声道回放系统模拟声场的空间音频信号所需的左后环绕声音信号;将右侧方向与后侧方向上的声音信号的平均信号映射为用5.1声道回放系统模拟声场的空间音频信号所需的右后环绕声音信号;根据前侧方向、后侧方向、左侧方向和右侧方向上的声音信号求取平均值并对平均值进行150hz的低通滤波处理,得到用5.1声道回放系统模拟声场的空间音频信号所需的重的低音信号。
本发明实施例提供的处理声音信号的方法,能够从移动终端三维声场中获取声音信号;并获取各个声源相对于移动终端的方向;再利用声源相对于移动终端的方向和声音信号,得到用于模拟三维声场的空间音频信号。
本发明提供的方案,能够通过移动终端自身的元件采集和处理用于模拟三维声场的声音信号,并且分析出所接受到的各个方向上的声源相对于移动终端的方向,再结合各个方向上的声源相对于移动终端的方向增强三维声场的效果,相对于现有技术中仅利用波束模拟三维声场的方案,由于本发明中获取了各个方向上的声源相对于移动终端的方向,并利用该方向信息对波束形成进行进一步的增益调整,因此能够缓减所模拟出来的三维声场的左右的区分要比前后明显的现象,从而提升所模拟的三维声场的质量。
在本实施例中,移动终端获取声源相对于所述移动终端的方向的方式可以有多种,比如可以采用定位技术获取作为声源的移动终端和移动终端的空间坐标,并根据作为声源的移动终端和移动终端的空间坐标确定声源相对于所述移动终端的方向。但是在移动终端进行定位的过程中需要占用网络带宽,并且定位过程有一定的延时,而在本实施例中,移动终端需要获取多个方向上的声源相对于移动终端的方向,可以通过基于到达时间差的定位技术获取声源相对于所述移动终端的方向。
为了模拟真实的声波与耳朵之间的相互作用,共振音频(resonanceaudio)技术使用了头部关联传导函数(head-relatedtransferfunctions,hrtfs)音效定位算法。hrtfs包括用来确定声音位置的时间差和强度差的影响,以及用来确定声音位置的频谱效应,该算法计算声波从发射、反射后行经头部、耳朵的种种效应,模拟人的神经系统如何去判断声源位置,尤其是声源的垂直高度(elevation)。通过耳机使用hrtfs处理的听觉音频使用户大脑产生一种错觉,即声音在他们周围的虚拟世界中有一个特定的位置(这就达到了声源的模拟定位的目标)。除此之外,共振音频(resonanceaudio)技术不仅能模拟声波与的耳朵的相互作用,还能模拟声波与其周围环境的相互作用。
基于麦克风阵列的声源定位方法大致可以分为三类:基于最大输出功率的可控波束形成技术、基于高分辨率谱图估计技术和基于声音时间差(time-delayestimation,tde)的声源定位技术。
基于tde的算法核心在于对传播时延的准确估计,一般通过对麦克风间信号做互相关处理得到。进一步获得声源位置信息,可以通过简单的延时求和、几何计算或是直接利用互相关结果进行可控功率响应搜索等方法。这类算法实现相对简单,运算量小,便于实时处理,因此在实际中运用最广。
另外,音频解码器可以进行下混,这在输出声道数比编码声道数少时是需要的。这样,完整的多声道节目可以在较少的声道上重放。解码器对各个声道进行解码,并使用编码器提供的下混比例因子和变换矩阵索引把这些声道路由到输出声道中(这些比例因子设置了每个声道的相对电平,而基于变换矩阵索引获取对应的变换逆矩阵,采用变换逆矩阵还原对应的量化后的声道单元)。下混可以被发送给3至8个声道的输出配置(3至8个声道的输出配置适用于移动终端)。
可根据移动终端的大小,确定微型扬声器的个数;音频解码器对多声道节目的各个声道进行解码;并使用编码器提供的下混比例因子和变换矩阵索引把这些声道路由到输出声道中;下混根据确定的微型扬声器个数,被发送给相应声道的输出配置。
第二方面,本发明还提供一种处理声音信号实现三维声场听觉效果的装置,参照图3所示,包括:
获取模块31,用于从三维声场中获取多个方向上的声音信号;
第一确定模块32,用于根据所述声音信号,确定声源相对于移动终端的方向;
生成模块33,用于根据所述声音信号以及所述声源相对于所述移动终端的方向,生成空间音频信号;所述空间音频信号用于模拟所述三维声场;
第二确定模块34,用于确定所述移动终端具有微型扬声器的个数;
解码模块35,用于根据音频解码器对多声道节目的各个声道进行解码;
路由模块36,用于根据编码器提供的下混比例因子和变换矩阵索引把所述各个声道路由到输出声道中;
发送模块37,用于下混根据确定微型扬声器的个数,发送给相应声道的输出配置。
在一个实施例中,所述第一确定模块32,包括:
获取子模块321,用于获取所述移动终端上的麦克风接收到一个方向上的声音信号与另一个方向上的声音信号之间的到达时间差,所述移动终端上的麦克风用于接收至少四个方向上的声音信号;
确定子模块322,用于根据所获取的到达时间差和所述移动终端上的麦克风在所述移动终端上的位置,确定所述声源相对于所述移动终端的方向。
在一个实施例中,所述获取子模块321,具体用于根据音效定位算法,确定声音位置的时间差以及强度差。
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!