基于机器学习的车联网通信的流量预测方法与流程
技术领域
本发明涉及城市道路车辆交通场景下车辆的流量预测技术领域,具体是一种利用机器学习算法对现有的交通数据进行预测,并结合通信仿真完成车联网通信流量预测的方法。
背景技术:
车载自组织网络是依托计算机网络、现代无线通信和云计算等新一代信息技术的革命性发展,它的开发是为了通过经济高效的数据分发提供可靠的车载通信。车辆通信可用于减少交通事故,交通拥堵,行驶时间,燃料消耗等。车载通信允许道路使用者通过交换一些信息,了解可能发生在他们身上的危急和危险情况时的周围环境。因此对车联网通信流量的研究能进一步促进交通智能化,能有效地提升交通的效率、减少甚至避免交通事故的发生。
在预测交通流量和网络流量的非机器学习方法中,大部分都只能针对特定区域的短时交通流进行预测。如两步优化选择法是对时间序列进行预测的统计方法,但它只能基于单条时间序列进行检测和统计,而对多条时间序列曲线则相对困难些。另一种结合波动理论分析和频谱分析的组合方法,是根据频谱分析将流量数据分成三类成分,而不同的流量成分采用相应的模型预测,但它在处理庞大的交通流量和网络通信流量数据时,不仅耗时耗力,而且数据指标的分布特征都没有很好地得到展示。而近年来陆续被使用在交通流量和网络流量的机器学习方法,都能综合地考虑到交通场景中的时空性数据,且应对海量的流量数据时,能高效率地统计交通流量分布规律,预测未来流量情况。
技术实现要素:
本发明的目的在于提供一种基于机器学习的车联网通信的流量预测方法,提高预测模型的泛化性能和全天候流量预测的准确性。。
实现本发明目的的技术解决方案为:一种基于机器学习的车联网通信的流量预测方法,步骤如下:
步骤1、车流量预测:利用交通数据平台发布的流量速度数据,选取8类指标进行数据处理,完成全天候的车流量预测;
步骤2、分析两种流量关系:利用openstreetmap导出某地城市道路车辆交通场景,配置车流探测文件,获取交通数据,再配置车辆通信仿真文件,获取通信数据,两类数据混合,分析车流量与通信流量二者关系;
步骤3、通信流量预测:在交通数据平台选择某些路段,利用openstreetmap导出这些路段的城市道路车辆交通场景后,配置车辆通信仿真文件,获取通信数据,依据已得的两种流量关系,从交通数据平台发布的流量速度数据和获取的仿真车辆通信数据中,选取9类指标进行数据处理,完成车载网络的通信流量预测。
本发明与现有技术相比,其显著优点:1)本发明采用机器学习算法,将海量经验数据加载给学习算法训练出模型,泛化性能好,能直观看出各指标下高低流量分布情况,针对城市道路车辆交通场景下的数据都有很好的预测性能;2)不局限于其他只针对仿真场景下的车流量短时预测的研究,本发明有效地对真实城市车辆交通场景的未来全天候车流量进行了很好的预测;3)本发明更进一步研究了车流量等交通信息与车联网联实时的通信质量之间的关系,为车联网的技术发展甚至智能交通的构建提供较大的便利。
附图说明
图1是本发明据实测数据预测车流量的方案流程图。
图2是本发明对关联度大且多值指标的处理流程图。
图3是本发明据车联网仿真预测通信流量的方案流程图。
图4是本发明预测通信流量预测的方案流程图。
具体实施方式
下面结合说明书附图和实施例对本发明作进一步说明。
本发明基于机器学习的车联网通信的流量预测,包括如下步骤:
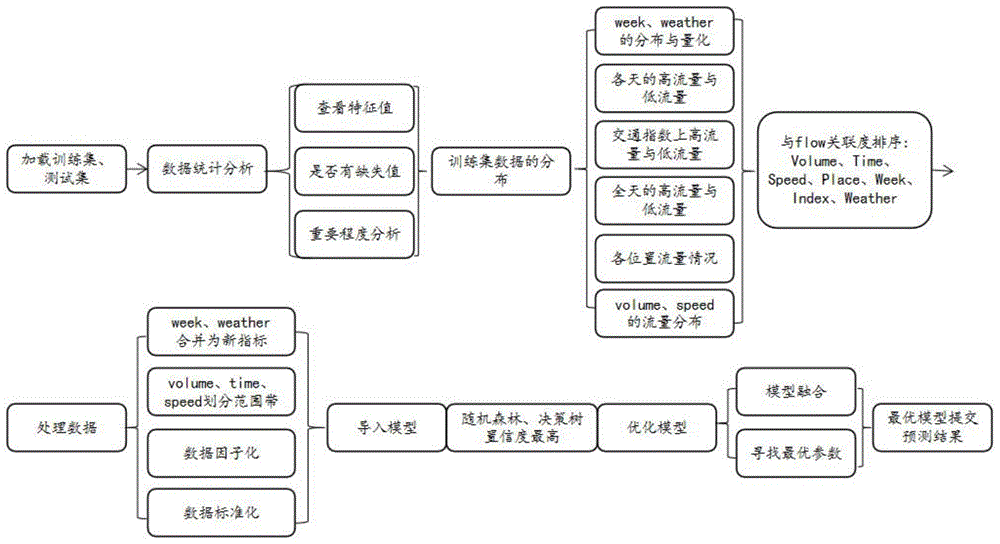
步骤1、车流量预测:利用交通数据平台发布的流量速度数据,选取8类指标进行数据处理,如图1所示完成全天候的车流量预测的具体方法为:
获取交通数据平台发布的某些路段一周全天候的数据,利用这些数据,预测这些路段未来某周某天全天候的车流量,即形成7天的训练数据集train.csv,1天的测试数据集test.csv;8类数据集指标包括6类数字型指标和2类类目型指标,数字型指标:车流量Flow、时间Time、速度Speed、交通量Volume、交通指数Index、路段Place,类目型指标:即星期Week、天气Weather;
利用isna函数判断各指标是否有缺失值,并用len函数对训练集数据train.csv进行统计,包括:各数字型指标的数量count、均值mean、标准差std、最小值min、最大值max;
为了直观看出各指标下高低车流量分布情况,以车流量的均值mean作为高低流量的分界点,用sns.kdeplot函数画内核密度图查看车流量的分布状况:1)类目型指标week、weather上的高流量与低流量分布与量化,2)Week各天的高流量与低流量分布情况,3)交通指数Index上高流量与低流量分布情况,4)Time全天的高流量与低流量分布情况,5)各位置Place的高流量与低流量分布情况,6)volume、speed上的高流量与低流量分布情况;
利用sns.heatmap画图展示各指标间的关联度,关联度值的绝对值越大,两指标间的相互影响关系越深,用groupby函数得到车流量Flow与其它指标的关联度排序。
关联度排序在最后的两种指标,对最终预测结果的准确性程度贡献小,为了提高运算效率,课将这两种指标合并为新指标;关联度排序在前三的三种数值连续性指标,依次设定指标数值分成8、6、4段取值范围,利用pd.cut函数自动寻找各段交界点,以各范围边界点来划分数值连续性指标,获得类目型指标;再使用get_dummies对类目型指标进行数据因子化,将指标平展开后,取值均为0、1,即当某展开指标的取值为1时,它会确定Flow的一个模糊的取值范围,再结合其它指标的贡献,逐渐收敛,一步步将Flow的取值范围缩小,最后确定预测值。由于特征值的取值只有0和1,这会大大加快机器学习运算效率。对关联度大的指标进行取值范围划分,对处理海量的机器学习算法来说,不仅大大提高了运算效率,还在数据收敛方向上,提供了机器学习算法自动划分的的分界点与聚集中心;
如果连续性数据指标取值范围太大,将对逻辑回归的收敛性造成不利影响,利用preprocessing.StandardScaler()函数,对取值超过100种的多样性数据指标进行数据标准化,将数据指标分布调整成标准正太分布,使得其均值为0,方差为1;
将处理后的训练数据集train.csv,输入scikit-learn工具包下的六种常用经典机器学习算法进行模型训练:随机森林模型Random Forest、逻辑回归模型Logistic Regression、K近邻模型KNN、支持向量机模型Support Vector Machines、朴素贝叶斯模型Naive Bayes 、决策树模型Decision Tree等。由于scikit-learn工具包为模型对象提供predict()接口,经过训练的模型,可以用这个接口来进行预测,同时也提供了score()接口来评价一个模型的好坏,根据置信度得分越高则模型预测性能越好,来进行预测模型的选择和验证。
根据给出的置信度得分排序,初步选择置信度得分排在前两位的随机森林模型和决策树模型,对置信度得分最高的随机森林模型和决策树模型进行优化:利用不同的机器学习算法的可调参数以及它们对机器学习算法的性能以及准确率的影响,通过GridSearchCV()、StratifiedKFold()和StratifiedShuffleSplit()函数,寻找最优参数下的决策树模型Decision_best和最优参数下的随机森林模型RandomForest_best。
将处理后的训练数据集train.csv,输入最优参数下的决策树模型Decision_best和最优参数下的随机森林模型RandomForest_best进行模型训练,并计算置信度得分,用置信度得分最高的优化参数下的随机森林模型RandomForest_bes对测试集test.csv进行预测,并提交车流量预测结果fianl_submission1.csv
为了一目了然获得训练数据集的样本大小是如何影响所选模型的置信度得分,避免欠拟合和过拟合情况的发生,需要利用优化参数后的随机森林模型画学习曲线:横坐标为训练集train.csv所训练样本个数,纵坐标为训练集train.csv拟合的准确性得分和交叉验证集预测的准确性得分,画出学习曲线,验证当前训练样本的数量大小下,随机森林模型不仅能很好地拟合训练数据集,而且对测试数据集的预测准确性很高。
本发明采用最优参数下的随机森林对全天候的车流量进行预测,在处理海量的流量速度数据时,能很好地避免出现过拟合问题,且模型泛化性能高。
目前车联网相关的基础设施搭建还未成熟,相关的车载网络通信数据获取成本高且不能保障其有效性,故本发明的通信流量预测工作是基于仿真平台获取的通信数据,利用交通仿真平台SUMO的城市道路车辆交通场景与网络仿真平台NS-3的车载通信网络的连接与搭建,获得仿真车流量与通信流量,分析车流量与通信流量二者关系,进而可以选取对通信流量的预测准确性贡献较大的指标,进而完成由真实车流量来预测未来车联网网络通信状况。
步骤2、分析两种流量关系:利用openstreetmap导出某地城市道路车辆交通场景,配置车流探测文件,获取交通数据,再配置车辆通信仿真文件,获取通信数据,两类数据混合,分析车流量与通信流量二者关系的具体方法为:
基于开源平台openstreetmap导出某实地城市道路交通路口,作为用来实验的城市道路车辆交通场景进行建模:配置车流文件rou.xml、道路文件net.xml、探测器loops Detectors文件等,然后用交通仿真软件SUMO进行交通仿真,获取交通数据:交通量nVehContrib(采集周期内完整通过传感器的车辆数量)、车流量Flow(每小时通过传感器的车辆数量)、时间占有率occupancy(车辆通过的累计值与时间周期的比值)、平均速度speed(采集周期内的平均车速)、通过探测器的车辆平均长度length、接触到传感器车辆的数量nVehEntered。
基于ubuntu16.04操作系统,完成通信仿真软件NS-3与交通仿真软件SUMO的连接,使NS-3能够遵循SUMO实验城市道路车辆交通场景模式输出通信数据,方法为:将车流文件.rou.xml和道路文件.net.xml合并转化为.sumo.tr文件;随后利用java -jar命令下的traceExporter.jar,将道路文件.net.xml和.sumo.tr文件合并转化为NS-3需要的.mobility.tcl文件,最后通过ns2-mobility-trace连接NS-3与SUMO。
配置车辆通信仿真文件dsdv-njust1.cc,要完成路由协议dsdv、车速Speed、通信结点个数Nodes、仿真时间Time、输出文本类型等配置,主要添加std::string CSVfileName = "njust-dsdv1.csv"语句和std::string tr_name = "Dsdv_Manet_" + t_nodes + "Nodes_" + sTotalTime + "SimTime";std::cout << "Trace file generated is " << tr_name << ".tr\n"语句,运行车辆通信仿真文件dsdv-njust1.cc,获取通信数据:路由协议RoutingProtocol、接收到的数据包数目PacketsReceived、数据包接受率ReceiveRate和可供网络链路数据分析的网络抓包.pcap文件。
使用Wireshark的统计功能,选用网络配适滤波器对网络抓包.pcap文件进行分组封装,对通信结点链路和信道的数据包进行数据撷取,获取另一部分通信数据:数据包传送速率PacketsV和平均带宽Band。
对获取到的车流量和通信流量进行相关性分析:使用sns.catplot查看仿真时间内,车流量Flow与数据包传送速率PacketsV、平均带宽Band的相关度,验证交通车流量和车联网通信流量之间的相关性:交通车流量和车联网通信流量存在一定程度的正相关,证明可选取城市道路车辆交通场景与车载通信网络下的数据指标,进行通信流量预测。
步骤3、通信流量预测:在交通数据平台选择某些路段,利用openstreetmap导出这些路段的城市道路车辆交通场景后,配置车辆通信仿真文件,获取通信数据,依据已得的两种流量关系,从交通数据平台发布的流量速度数据和获取的仿真车辆通信数据中,选取9类指标进行数据处理,完成车载网络的通信流量预测的具体方法为:
在交通数据平台选择某些路段,利用openstreetmap导出这些路段的城市道路车辆交通场景后,配置车辆通信仿真文件dsdv-njust2.cc:配置路由协议dsdv、车速Speed、通信结点个数Nodes、仿真时间Time、输出文本类型等;添加std::string CSVfileName = "njust-dsdv2.csv"语句,使得运行通信文件dsdv-njust2.cc后,获得njust-dsdv.csv文件,文件包括一部分通信数据:接收到的数据包数目PacketsReceived、路由协议RoutingProtocol、数据包接受率ReceiveRate;添加std::string tr_name = "Dsdv_Manet_" + t_nodes + "Nodes_" + sTotalTime + "SimTime";std::cout << "Trace file generated is " << tr_name << ".tr\n"语句,使得运行车辆通信仿真文件dsdv-njust2.cc后,获得网络抓包.pcap文件;
使用Wireshark的统计功能,选用网络配适滤波器对网络抓包.pcap文件进行分组封装,对通信结点链路和信道的数据包进行数据撷取,获得另一部分通信数据:数据包传送速率PacketsV和平均带宽Band;
依据已得的交通车流量和车联网通信流量之间的相关性,从交通数据平台发布的这些路段流量速度数据和仿真车辆通信数据中,选取9类指标:平均带宽Band、数据包传送速率PacketsV、车辆数目Vehicles、交叉口数目Junctions、道路数目Lane、速度Speed、数据包接受率ReceiveRate、接收到的数据包数目PacketsReceived、路由协议RoutingProtocol;
利用所选路段在不同车速Speed和不同通信结点个数Nodes下获取的9类数据指标,预测这些路段未来某周某天的通信流量,即形成训练数据集train.csv和测试数据集test.csv;
对9类指标进行统计:利用isna函数判断各指标是否有缺失值,并用len函数对训练集数据train.csv进行统计,包括:各指标的数量count、均值mean、标准差std、最小值min、最大值max ;以平均带宽Band的均值mean作为高低通信流量的分界点,用sns.kdeplot函数画内核密度图查看通信流量的分布状况:1)速度Speed上的高流量与低流量分布,2)Lane各道路的高流量与低流量分布情况,3)车辆数目Vehicles上高流量与低流量分布情况,4)数据包传送速率PacketsV上的高流量与低流量分布情况,5)交叉口数目Junctions上的高流量与低流量分布情况,6)接收到的数据包数目PacketsReceived、数据包接受率ReceiveRate上的高流量与低流量分布情况;
对9类指标进行处理:利用sns.heatmap画图展示各指标间的关联度,用groupby函数得到平均带宽Band与其它指标的关联度,并进行关联度排序;对关联度排序在最后的三种指标,合并为新指标;对关联度排序在前四的连续性指标,依次设定指标数值分成8、6、4、2段取值范围,利用pd.cut函数自动寻找各段交界点,以各范围边界划分连续性指标,获得类目型指标;再使用get_dummies对类目型指标进行数据因子化,将指标平展开;
利用preprocessing.StandardScaler()函数,对取值超过50种的多样性数据指标进行数据标准化,将数据指标分布调整成标准正太分布,使得其均值为0,方差为1
利用scikit-learn工具包下的经典机器学习算法自助聚合BaggingClassifier模型对处理后的9类指标进行训练,然后对测试集test.csv进行预测,并提交结果通信流量预测结果fianl_submission2.csv。
实施例1
为了验证本发明的有效性,利用交通数据平台发布的流量速度数据先进行车流量预测,具体如下:
采用上海市大数据联合创新实验室(交通领域)平台发布的2018年9月1日至9月7日的上海延安高架12个路段全天候的数据,来预测这些路段在9月8日全天候的车流量,即形成7天的训练数据集共60480组(train.csv),1天的测试数据集共8640组(test.csv)。数据集指标包括8类:车流量 Flow、星期 Week、天气Weather、时间Time、速度Speed、交通量Volume、交通指数Index、路段Place。
利用isna函数判断各指标是否有缺失值,并用len函数对训练集数据train.csv进行统计,包括:各数字型指标的数量count、均值mean、标准差std、最小值min、最大值max;以车流量的均值107作为高低流量的分界点,用sns.kdeplot函数画内核密度图查看车流量的分布状况:1)类目型指标week、weather上的高流量与低流量分布与量化,2)Week各天的高流量与低流量分布情况,3)交通指数Index上高流量与低流量分布情况,4)Time全天的高流量与低流量分布情况,5)各位置Place的高流量与低流量分布情况,6)volume、speed上的高流量与低流量分布情况;
利用sns.heatmap画图展示各指标间的关联度,关联度值的绝对值越大,两指标间的相互影响关系越深,用groupby函数得到与车流量Flow的其它指标关联度大小排序:交通量Volume(0.872605)、时间Time(0.533182)、速度Speed(0.328509)、路段Place(0.215406)、星期Week(0.064199)、交通指数Index(0.050326)、天气Weather(0.031915)。
可以得到Volume、Time、Speed这三个多值特征,与Flow关联度很大,可以做相同的数据处理,而Place、Week这两个离散值,与Flow关联度较低,也可以做相同的一类数据处理,排在最后的Index(一天交通指数的均值)、Weather这两项指标,在一天之内没有变化的特征值,同样可以做相同的一类数据处理。
根据关联度排序,将关联度小的week、weather合并为新指标地区region,如图2所示,将关联度高的连续性指标速度Speed、时间Time、交通量Volume分别划分为取值范围是4段、6段、8段,得到类目型指标Speed_group, Time_group, Volume_group。
使用get_dummies进行数据因子化:将类目型指标Place, Speed_group, Time_group, Volume_group平展开,取值均为0、1,比如当一个展开的Place指标取值为1时,它会确定Flow的一个模糊的取值范围,再结合其它指标的贡献性,逐渐收敛,一步步将Flow的取值范围缩小,最后确定预测值。最后Place平展为12个新指标, Speed_group平展为4个新指标, Time_group平展为6个新指标, Volume_group平展为8个新指标,由于特征值的取值只有0和1时,这会大大加快运算效率。完成数据因子化后,再通过drop函数将原先的group, Weather, Index, Speed这四个指标从训练数据集中去掉。
使用preprocessing.StandardScaler()进行数据标准化:注意Time和Volume的数据取值范围太大,这将对逻辑回归的收敛造成不利的影响。进行数据标准化,把这两个数据指标分布调整成标准正太分布,使得其均值为0,方差为1。
由于scikit-learn工具包为模型对象提供predict()接口,经过训练得出模型,可以用这个接口来进行预测,同时也提供了score()接口来评价一个模型的好坏,得分越高则模型预测性能越好,进行模型的选择和验证:将处理后的训练集的8种指标,输入scikit-learn工具包下六种常用机器学习算法进行模型训练,并得出各模型置信度:随机森林模型Random Forest(86.375000)、决策树模型Decision Tree(85.061000)、支持向量机模型Support Vector Machines(82.366000)、K近邻模型KNN(73.132000)、朴素贝叶斯模型Naive Bayes(58.350000)、逻辑回归模型Logistic Regression(35.813000)。
随机森林模型和决策树模型置信度最高,利用不同的机器学习算法的可调参数以及它们对机器学习算法的性能以及准确率的影响,下面对这两种模型进行优化:通过GridSearchCV()、StratifiedKFold()和StratifiedShuffleSplit()函数寻找最优参数下的决策树模型Decision_bes和最优参数下的随机森林模型RandomForest_best。
将处理后的训练集的8种指标,输入最优参数下的决策树模型Decision_bes和最优参数下的随机森林模型RandomForest_best,计算模型置信度得分,用置信度得分最高的最优参数下的随机森林模型RandomForest_best对测试集test.csv进行预测,最后以87%的准确性提交车流量预测结果fianl_submission1.csv。
为了一目了然获得训练数据集的样本大小是如何影响所选模型的置信度得分,避免欠拟合和过拟合情况的发生,需要利用优化参数后的随机森林模型画学习曲线:横坐标为训练集train.csv所训练样本的个数,纵坐标为训练集train.csv拟合的准确性得分和交叉验证集预测的准确性得分,画出学习曲线,验证当前训练样本的数量大小下,随机森林模型不仅能很好地拟合训练数据集,而且对测试数据集的预测准确性很高,即在保证准确度的同时也提升了模型防止过拟合的能力。
以南京理工大学7号门外丁字路口为实验城市道路车辆交通场景进行建模:配置车流文件rou.xml、道路文件net.xml、探测器loops Detectors等,通过改变车辆交通场景中的车辆数Vehicles,车速Speed,车道Lane和交叉口Junctions的设定,即是选择不同的主干路来构建道路交通模式,用交通仿真软件SUMO进行交通建模仿真,获取交通数据:交通量nVehContrib(采集周期内完整通过传感器的车辆数量)、车流量Flow(每小时通过传感器的车辆数量)、时间占有率occupancy(车辆通过的累计值与时间周期的比值)、平均速度speed、通过车辆的平均长度length、接触到传感器车辆的数量nVehEntered。
基于ubuntu16.04操作系统,完成通信仿真软件NS-3与交通仿真软件SUMO的连接,使NS-3能够遵循南京理工大学7号门外丁字路口的道路车辆交通场景输出通信数据,方法为:将车流文件.rou.xml和道路文件.net.xml合并转化为.sumo.tr文件;随后利用java -jar命令下的traceExporter.jar,将道路文件.net.xml和.sumo.tr文件合并转化为NS-3需要的.mobility.tcl文件,最后通过ns2-mobility-trace连接NS-3与SUMO。
配置车辆通信仿真文件dsdv-njust1.cc,要完成路由协议dsdv、车速Speed、通信结点个数Nodes、仿真时间Time、输出文本类型等配置,主要添加std::string CSVfileName = "njust-dsdv1.csv"语句和std::string tr_name = "Dsdv_Manet_" + t_nodes + "Nodes_" + sTotalTime + "SimTime";std::cout << "Trace file generated is " << tr_name << ".tr\n"语句,运行车辆通信仿真文件dsdv-njust1.cc,获取通信数据:路由协议RoutingProtocol、接收到的数据包数目PacketsReceived、数据包接受率ReceiveRate和可供网络链路数据分析的网络抓包.pcap文件。
使用Wireshark的统计功能,选用Npcap Loopback Adapter滤波器对网络抓包.pcap文件进行分组封装,对通信结点链路和信道的数据包进行数据撷取,获取另一部分通信数据:数据包传送速率PacketsV和平均带宽Band。
对获取的交通流量和通信流量进行相关性分析:使用sns.catplot查看仿真时间内车流量Flow与数据包传送速率PacketsV、平均带宽Band的相关性,结果表明交通车流量和车联网通信流量存在一定程度的正相关。当车流量增大时,整体上通信网络流量随着增大,且数据传送质量要求越来越高,车载通信网络容易发生数据拥塞。
利用openstreetmap导出在交通数据平台所选的延安高架路段的城市道路车辆交通场景,配置车辆通信仿真文件dsdv-njust2.cc,获取通信数据。依据已得的交通车流量和车联网通信流量之间的相关性,从交通数据平台发布的这些路段流量速度数据和仿真通信数据中,选取9类指标:平均带宽Band、数据包传送速率PacketsV、车辆数目Vehicles、交叉口数目Junctions、道路数目Lane、速度Speed、数据包接受率ReceiveRate、接收到的数据包数目PacketsReceived、路由协议RoutingProtocol。
用groupby函数得到各指标与平均带宽Band的关联度排序:平均带宽Band(1.000000)、车辆数目Vehicles(0.895059)、接收到的数据包数目PacketsReceived(0.877838)、数据包接受率ReceiveRate(0.871777)、数据包传送速率PacketsV(0.655794)、交叉口数目Junctions(0.030816)、道路数目Lane(0.030816)、速度Speed(0.030816)、路由协议RoutingProtocol(NaN),其中NaN表示数据集中该指标取值唯一,无变化。
将9类指标经过图3所示处理:对关联度排序在最后的三种指标Speed、LaneJunctions,合并为新指标;对关联度排序在前四的连续性指标Vehicles、PacketsReceived、ReceiveRate、PacketsV,依次设定指标数值分成8、6、4、2段取值范围,利用pd.cut函数自动寻找各段交界点,以各范围边界划分连续性指标,获得类目型指标;再使用get_dummies对类目型指标进行数据因子化,将指标平展开;利用preprocessing.StandardScaler()函数,对取值超过50种的多样性数据指标Vehicles、PacketsV进行数据标准化,将数据指标分布调整成标准正太分布,使得其均值为0,方差为1。
将处理后的训练数据集的9类指标,输入scikit-learn工具包下十个经典机器学习算法进行模型训练,并计算各模型置信度:自助聚合模型Bagging(92.683)、决策树模型Decision Tree(90.244)、随机森林模型Random Forest(87.805)、朴素贝叶斯模型Naive Bayes(86.585)、梯度提升决策树模型GradientBoosting(84.146)、高斯过程模型GaussianProcess(81.707)、K近邻模型KNN(75.610)、逻辑回归模型Logistic Regression(48.780)、AdaBoostClassifier模型(48.780)、支持向量机模型Support Vector Machines(39.024)。用置信度最高的Bagging模型进行通信流量预测,最后以92%的准确性提交通信流量预测结果fianl_submission2.csv。
从本实施例可以看出,本发明能够从机器学习的常用的经典算法出发,不仅有效的对真实交通场景的未来全天候车流量进行了很好的预测,还研究了车流量等交通信息与车联网实时的通信质量之间的关系,模型泛化性能好,准确度较高,能为后期利用经济高效的数据分发提供可靠的车载通信分析方法,增强车辆用户驾驶的安全性。
- 还没有人留言评论。精彩留言会获得点赞!