一种基于实时情绪反馈的智能弹幕机器人的制作方法
本发明涉及人工智能技术领域,特别是涉及一种基于实时情绪反馈的智能弹幕机器人。
背景技术:
随着互联网及多媒体技术的发展,视频直播已经成为大众生活、娱乐的一种方式。用户在观看视频直播时候喜欢将文字评论发布到显示画面上表达自己的感受,即通常所说的发布弹幕,弹幕可以起到炒热氛围、提高人气、引导舆论等作用。然而,对于那些刚进入直播行业的视频主播而言,在初步发展阶段,由于缺乏人气,初期可能会存在无弹幕的尴尬。
为了方便视频主播的初步发展,以及对其他热门主播的弹幕进行引导,现有技术提出一种弹幕机器人,弹幕机器人可自动捕获对应的直播内容,并根据直播内容自动产生对应的弹幕。
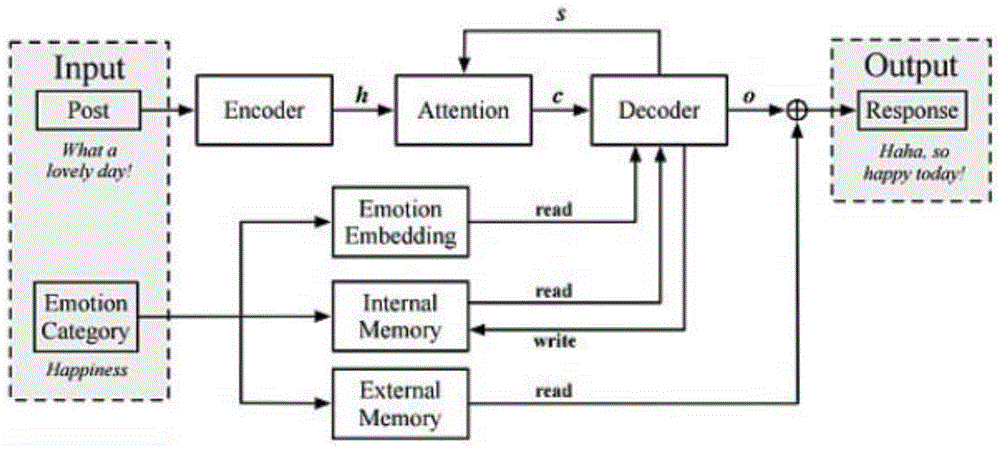
例如,由周豪等人在《Emotional Chatting Machine:Emotional Conversation Generation with Internal and External Memory》中提出了一种情感聊天机器人,其基本工作流程如图1所示。其核心思想是一个引入内外部记忆的基于attention机制的seq2seq模型。该模型将输入的数据输入到ENCODER中,通过attention机制,产生对应的C向量,再将C向量与感情对应的内部记忆以及情感输入DECODER中,产生输出o,将输出o与外部记忆融合产生输出。但是该聊天机器人,情感模块相对简单,需要手动输入情感,对于音频和视频等信息并没有对应的处理。
技术实现要素:
本发明主要解决的技术问题是提供一种基于实时情绪反馈的智能弹幕机器人,能够针对音、视频信息以及主播的情绪进行实时反馈。
为解决上述技术问题,本发明采用的一个技术方案是:提供一种基于实时情绪反馈的智能弹幕机器人,包括信息捕获模块、数据处理模块、弹幕生成模块和弹幕发布模块,所述信息捕获模块包括视频捕获单元和音频捕获单元,所述数据处理模块包括视频转码单元、音频转码单元,所述弹幕生成模块包括视频分析单元、语义分析单元、音频分析单元和弹幕生成单元;所述视频捕获单元用于捕获目标视频的图像数据,并传输至视频转码单元;所述音频捕获单元用于捕获目标视频的音频数据,并传输至音频转码单元;所述视频转码单元用于将所述图像数据压缩至预定尺寸后,通过CNN对图像数据进行特征提取得到N:M的矩阵,对所述矩阵进行矩阵分解,并分别在列和行方向求取平均值,得到1:N和M:1的两个向量,并将所述两个向量传输至视频分析单元,其中,N和M为正整数;所述音频转码单元用于从所述音频数据中提取出语调信息和语速信息,同时对所述音频数据进行语音识别得到文字信息,并将所述语调信息和语速信息传输至音频分析单元,将所述文字信息传输至语义分析单元;所述视频分析单元用于将所述两个向量合并后,输入到seq2seq模型的ENCODER层中,产生对应的V向量,并将V向量传输至弹幕生成单元;所述音频分析单元用于将所述语调信息和语速信息与音频情感库进行对比,产生对应的情绪标签,将所述情绪标签输入到seq2seq模型的ENCODER层中,产生对应的S向量,并将S向量传输至弹幕生成单元;所述语义分析单元用于将所述文字信息输入seq2seq模型的ENCODER层中,产生对应的T向量,并将T向量传输至弹幕生成单元;所述弹幕生成单元用于将V向量,S向量和T向量分别输入到已经训练好的目标Seq2Seq模型中,产生对应的弹幕内容,并将所述弹幕内容传输至弹幕发布模块;所述弹幕发布模块用于将所述弹幕内容以弹幕的形式上传至所述目标视频对应的网站。
优选的,所述还包括数据存储模块,所述数据存储模块用于存储图像数据,形成历史视频数据库,存储音频数据,形成历史音频数据库,以及缓存视频转码单元得到的两个向量以及音频转码单元得到的语调信息、语速信息和文字信息。形成缓存数据库。
优选的,所述视频捕获单元具体用于利用图像截取工具对目标视频逐帧进行截屏得到图像数据。
优选的,所述音频捕获单元具体用于对目标视频进行录音,在音频状态发生改变或录音超时时结束录音得到音频数据。
优选的,所述音频转码单元具体用于利用基于CNTK的实时语音转化软件对所述音频数据进行语音识别。
本发明的有益效果是:本发明相比较于之前的常规情感机器人以及情感聊天机器人,在整体的架构上有较大的不同,仅仅是将实时情绪作为一个要素进行输入,本发明可以在用户打开对应的网站观看视频直播时,自动捕获对应的直播内容,根据实时的视频、音频内容,产生对应的弹幕,从而能够针对音、视频信息以及主播的情绪进行实时反馈,实现拟人化交流,进而起到炒热氛围,提高人气,引导舆论等作用。对于直播平台来说,既方便了小主播的初步发展,避免初期无弹幕的尴尬,又可以对热门主播的直播视频的弹幕进行正能量舆论引导,规避某些恶意弹幕的不良影响。
附图说明
图1是现有技术一种情感聊天机器人的工作流程示意图。
图2是本发明实施例的基于实时情绪反馈的智能弹幕机器人的架构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参阅图2,是本发明实施例的基于实时情绪反馈的智能弹幕机器人的架构示意图。本发明实施例的基于实时情绪反馈的智能弹幕机器人包括信息捕获模块10、数据处理模块20、弹幕生成模块30和弹幕发布模块40,信息捕获模块10包括视频捕获单元11和音频捕获单元12,数据处理模块20包括视频转码单元21、音频转码单元22,弹幕生成模块30包括视频分析单元31、语义分析单元32、音频分析单元33和弹幕生成单元34。
视频捕获单元11用于捕获目标视频的图像数据,并传输至视频转码单元21。在本实施例中,视频捕获单元11具体用于利用图像截取工具对目标视频逐帧进行截屏得到图像数据。图像截取工具可以是视频播放软件内置的图像截取工具。
音频捕获单元12用于捕获目标视频的音频数据,并传输至音频转码单元22。在本实施例中,音频捕获单元12具体用于对目标视频进行录音,在音频状态发生改变或录音超时时结束录音得到音频数据。音频捕获单元12在开始录音时,可以启动一个倒计时,倒计时例如为3分钟。如果目标视频从没有声音忽然有了声音,则音频捕获单元12结束录音得到音频数据,这样保证下一段录音能够完整上传应有信息;如果目标视频从有声音变为无声音,比如说话者发生了停顿,即一句话已经结束,则音频捕获单元12结束录音得到音频数据;如果直到倒计时结束,音频状态没有发生改变,则音频捕获单元12在倒计时结束时结束录音得到音频数据。
视频转码单元21用于将图像数据压缩至预定尺寸后,通过CNN(卷积神经网络)对图像数据进行特征提取得到N:M的矩阵,对矩阵进行矩阵分解,并分别在列和行方向求取平均值,得到1:N和M:1的两个向量,并将两个向量传输至视频分析单元31,其中,N和M为正整数。其中,视频转码单元21在图像数据经过CNN的隐藏层处理后不输入最后的全连接层,反而通过逐行逐列求取平均值,将矩阵分解为1:N和M:1的两个向量。
音频转码单元22用于从音频数据中提取出语调信息和语速信息,同时对音频数据进行语音识别得到文字信息,并将语调信息和语速信息传输至音频分析单元33,将文字信息传输至语义分析单元32。其中,音频转码单元22具体用于利用基于CNTK的实时语音转化软件对音频数据进行语音识别。
视频分析单元31用于将两个向量合并后,输入到seq2seq模型的ENCODER层中,产生对应的V向量,并将V向量传输至弹幕生成单元34。其中,视频分析单元31将两个向量转置,作为输入x1和x2,合并成为(x1,x2),输入到seq2seq模型的ENCODER层中,产生对应的V向量,获得其对应模型V,即可获得该部分对应的目标函数:
音频分析单元33用于将语调信息和语速信息与音频情感库进行对比,产生对应的情绪标签,将情绪标签输入到seq2seq模型的ENCODER层中,产生对应的S向量,并将S向量传输至弹幕生成单元34。其中,音频分析单元33将语调信息和语速信息与音频情感库进行对比,获取语调信息和语速信息对应的情绪标签,将情绪标签转化为one-hot编码,将该编码输入到seq2seq模型的ENCODER层中,产生对应的S向量,获得其对应模型S,即可获得该部分对应的目标函数:
本发明将情绪标签划分为六种:高兴(Happy)、悲伤(Sad)、恐惧(Fear)、愤怒(Angry)、厌恶(Disgust)和惊讶(Surprise),并对它们进行one-hot编码。
语义分析单元32用于将文字信息输入seq2seq模型的ENCODER层中,产生对应的T向量,并将T向量传输至弹幕生成单元34。其中,语义分析单元32将文字信息输入seq2seq模型的ENCODER层中,产生对应的T向量,获得其对应模型T,即可获得该部分对应的目标函数:
弹幕生成单元34用于将V向量,S向量和T向量分别输入到已经训练好的目标Seq2Seq模型中,产生对应的弹幕内容,并将弹幕内容传输至弹幕发布模块40。其中,目标Seq2Seq模型可以通过对样本弹幕资料进行训练得到。在训练时,可以以“爬虫”作为手段,通过对对应的弹幕视频网站的弹幕数据进行爬取,获得对应的样本弹幕资料。
弹幕生成单元34首先将V向量,S向量和T向量分别输入3个模型中,对其进行修改,分别得到其对应的结果,之后使其进行投票,这里选择软投票方法,通过不断对比结果,修改权重,得到最终模型:
即将3个模型输出的结果的加权平均和的最大值作为最终输出,St(x)分别为模型S,V,T对应的输出,argx max表示求最大值,C表示概率组合。
假设3部分的错误率分别为ε1,ε2和ε3,权重分为两种情况:
情况1:
任意两项之和均小于0.5,则集成后的错误率应为:
P(x)=ε1ε2+ε1(1-ε2)ε3+(1-ε1)ε2ε3
该公式包括:1.S、V做错,T可做错,可不做错;2.S做错,V没做错,T做错;3.S没做错,V、T做错3种情况。
通过数学计算,以及求偏导,最后得出当S,V和T模型对应的输出ε1,ε2,ε3<0.5时,P(x)<ε1,ε2,ε3。
情况2
当其中某两项结果权重之和小于0.5,一项大于0.5时则退化为单纯一项的结果。
弹幕发布模块40用于将弹幕内容以弹幕的形式上传至目标视频对应的网站。
在本实施例中,智能弹幕机器人还包括数据存储模块50,数据存储模块50用于存储图像数据,形成历史视频数据库,存储音频数据,形成历史音频数据库,以及缓存视频转码单元21得到的两个向量以及音频转码单元22得到的语调信息、语速信息和文字信息。形成缓存数据库。
本发明不同于以往传统的基于Seq2Seq模型的聊天机器人的是实现了实时情绪反馈,但是由于视频直播的受众特点,即用户群体广泛,背景复杂,观看时间不同,观看时状态不同,且多数为“粉丝”,所以个体情感变动复杂,但是整体情感变动较小,因此本发明倾向于短期情绪反馈,而非长期的情感反馈,且直播文化也是影响弹幕输出的重要组成部分。
对于影响受众情绪的要素选取,因为直播和众多视频表现更加倾向于表演,众多主播的表演相对比较夸张,所以主要选取音频作为影响受众整体情绪的要素,视频则整体作为一个要素来决定用户的输出,而非传统的音频+背景+表情识别来决定用户情感,再通过将这些变量输入情感模型来决定输出。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!