一种基于Catboost算法的信道环境自适应频谱感知方法与流程
本发明属于无线通信与人工智能技术领域。具体涉及一种基于catboost算法的信道环境自适应频谱感知方法。
背景技术:
无线传感网络是一种无线自组织和以数据为中心的网络,其是由大量具备计算和通信能力的微传感节点组成。由于无线传感网络低开销低功耗的特点,其已经在工业农业等领域得到应用。然而随着无线通信技术的发展,频谱资源稀缺成为当前无线传感网络面临最大的挑战。现在主要的无线传感网络频段是2.4ghz,在工业领域如无线hartwia-pa和isa100.11是基于物理层的ieee802.15.4。广泛使用的短距离通信技术像zigbee、蓝牙和wifi都是工作在此频段。因此这个频段的大量使用造成了信道拥塞和不可避免的干扰。因此,认知无线网络技术被提出来解决频谱资源稀缺的问题。认知无线网络技术是智能的无线通信技术,可以感知其周围电磁环境并从中学习,然后做出针对电磁环境变化下对自身工作参数状态的调整。频谱感知是其检测主用户信号的基本方式。opawe等人提出使用svm算法用于在样本协方差矩阵中进行特征值估计的频谱感知方法,其中感知用户设备是多天线设备。作者还提出了一种在慢衰落信道下使用卡尔曼滤波器信道估计来进行频谱感知的方法。针对此问题已经有大量的研究和工作,w.zhang等人注重解决多径衰落、阴影衰落和隐藏终端问题,其主要方式包括不同的合作频谱感知方法和优化的感知方法。此外,umebayashi等人提出利用优化的门限设置方式去提高检测性能,但是其需要之前状态的先验信息。b.l.mark等人主要使用不同的评估算法来估算主用户发射机的位置进而决定主用户和次用户之间的空间位置关系然后提高频谱资源空间方面的利用率。c.liu等人提出转化主用户信号检测方式即利用中心对称特征来提高空间利用率。近些年逐渐有使用机器学习算法解决认知无线网络频谱感知问题的思路,并做出了一些研究成果。比如使用基于能量检测法用svm算法,相比于其他机器学习算法在频谱感知分类问题上有着较佳的性能,其由于极高的分类准确率所以非常流行和实用。但这些工作都一定程度上提高了频谱感知的检测率,但是还有需要继续改进提升的地方,首先检测率还可以继续提高,其次误分类率和误分类风险率也需要继续提高。本发明针对的问题就是在这样的背景下进行的。
技术实现要素:
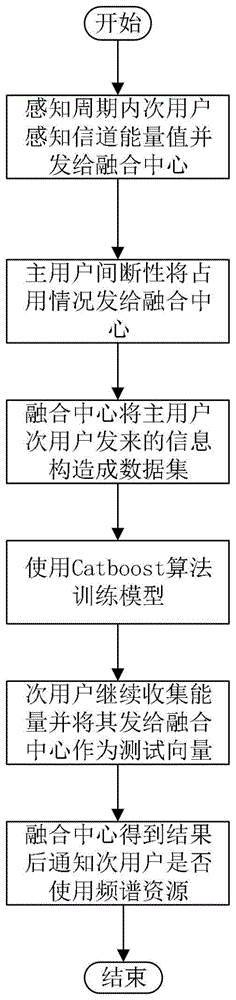
为解决上述问题,本发明提供一种基于catboost算法的信道环境自适应频谱感知方法,具体包括以下步骤:
步骤1:次用户前端能量采集设备采集当前信道环境中的能量值,并将感知周期内的能量值发到作为融合中心的一个次用户。这里采用了能量检测方法对信道环境进行计算,其原理是在主用户上线或者下线时,次用户前端能量采集设备采集到的能量值在统计特征上会有不同,能量检测法不需要先验信息,不会像匹配滤波法一样需要针对每种信号需要专门的接收设备,也不像循环谱技术需要大的计算量。
步骤2:主用户间断性地将占用频道资源情况发送到融合中心。
步骤3:融合中心将主用户和次用户发来的信息构造成数据集,并进一步构建特征向量集。使用catboost这种机器学习算法和能量检测法作为基本感知方式,所以自然而然地想到使用次用户采集到的能量值作为特征。
步骤4:融合中心用catboost算法训练模型。
步骤5:次用户继续将能量值发送到融合中心,作为测试向量并输入进已训练模型。
步骤6:融合中心得到结果后将是否可用信道资源发送给所有次用户,次用户根据融合中心的判断来做出反应。
上述步骤1中次用户和主用户设备上都会包含信号发射机和接收机,同时次用户还包含前端感知设备。在本发明中重点关注在频谱感知阶段,对主用户是否发射信号进行判断,即模型简化为次用户的感知设备对主用户的发射机发射信号的感知。本发明采用了较为实际的非平衡样本,比例为7:1;而之前基于机器学习算法进行频谱感知的工作中正负样本是较为均衡的。
上述步骤3具体为:
3.1:数据设定和能量归一化:
使用能量检测法作为频谱感知基本手段,在系统中包含p个主用户,记为p=1,2,...p和q个次用户q=1,2,...q,为了考虑更加通用的模型,所以p至少是大于等于2的,q可以选择数量较多。假定主用户和次用户共享频带资源同时不会造成干扰,在系统中主用户的工作状态只有两种:上线sp=1或者下线sp=0;主用户上线时其占用了频谱资源,次用户不能使用;主用户下线时其释放频谱资源,此时次用户可以使用频谱资源;系统中只要有一个主用户占用频谱资源,那么认定为次用户不允许再使用频谱资源;用gp代表pu的地理位置,gq代表su的地理位置。
每个su的能量检测器在感知时间周期τ内采样wτ个复基带信号样本,带宽表示为w;rq(i)代表su接收到的第i个信号样本,用如下公式表示:
在这里h0代表信道中没有pu,所以su感知设备收到的只是热噪音,用nq(i)表示;h1代表至少有一个pu上线时的情况,wp(i)代表pup的发射信号样本,hp,q代表pup和suq之间的信道增益,sp即为pu的工作状态。此外,su应该在感知时间段内做出正确决策。本发明为基于机器学习算法的能量检测频谱感知方法,在机器学习中,提取特征是第一步。用yq代表suq收到的归一化能量水平:
此处η为噪声功率谱密度定义为η=e[|nq(i)|2];因此,能量向量包含所有su接收到的能量水平:
y=(y1,...,yq)t(3)
3.2在获得能量向量后,进一步分析其分布;
因为pu的工作模式,每个能量值yq服从非中心的卡方分布,自由度和非中心参数如下:
r=2wτ(4)
这里
lp,q=pl(||gq-gp||).νp,qψp,q(6)
这里||.||代表欧氏距离,pl(dist)=dist-θ代表关于距离dist和损失系数θ的路径损失;νp,q和ψp,q分别代表多径衰落和阴影衰落;pu和su满足802.22协议;此外,在感知时间段内衰落系数νp,q和νp,q不变为准静态,即为1;
能量水平的分布我们已经在前面描述,在有足够多的样本时比如wτ,能量值分布基本服从高斯分布;因此能量向量可以从多元高斯分布中提取,其均值和方差如下:
μyq=r+ζq(7)
σ2yq=2(r+2ζq)(8)
因此能量向量的均值向量和协方差矩阵如下:
μyq=(μy1,...,μyq)t(9)
上述catboost算法具体为:在感知周期内,次用户把感知到的信道中能量值发送到融合中心作为特征能量向量,主用户间断性发送占用频谱资源与否的信息给融合中心作为标签,这样完成了训练数据集的构建。在融合中心中用catboost算法训练模型,现在介绍一下catboost算法:catboost算法由yandex提出,该算法优化了类别特征的处理,并且是在训练阶段处理而不是数据预处理阶段,该算法另一个优点是使用了一种新方法在选择树模型的时候计算叶子节点值,这帮助减少了过拟合。catboost算法有cpu和gpu两种运行方法,gpu方法比当前最流行的xgboost的gpu方式还要快,其cpu方式也是如此。catboost算法和梯度提升方法一样,也是构建新树去拟合当前模型的残差。然而传统的梯度提升方法都会收到有偏点梯度估计的影响容易导致过拟合。每次使用相同的数据点评估梯度,这样模型得以建立。这会导致相比于真正梯度分布空间,待拟合梯度的特征空间分布会偏移,这样会导致过拟合。很多gbdt方法(如xgboost)构建下一个树的方法主要包括两步:选择树架构和设置叶子的值。为了选择最优的数结构,算法会进行不同的拆分枚举、构建树、设置叶子值、评分并选择分裂方式。在这两个阶段叶子值都会被计算来拟合梯度。catboost在第二阶段和传统方法相同,但第一阶段使用了改进方法。用fk代表在构建的第一个k树,gk(xh,zh)代表在第h个训练样本构建k树梯度值构建的模型。为了使梯度gk(xh,zh)无偏,我们需要在没有xh下训练模型fk,这样使训练过程无法实施,考虑如下技巧来解决这个问题:对于每一次实现xh,我们训练一个模型mh,不用梯度估计的方式去更新。用mh在xh的基础上拟合梯度,使用这种方式来得到评分。catboost在训练集中产生了s个随机排列,其使用多种排列采样来获得残差的梯度来强化算法的鲁棒性,使用不同的排列来训练模型,然后使用多种排列来避免过拟合。对于每个排列σ,训练n个模型mk。这意味着构建新树的时候需要存储并重新计算o(n2)来拟合排列σ,对于每个模型mk,需要更新mk(x1),...,mk(xk),所以计算复杂度为o(sn2),在实现过程中使用了一个重要技巧来把每个树构建的时间复杂度降到o(sn):对于每一个排列,不是去存储和更新时间复杂度o(n2)的值mk(xj),而是保持值mk'(xj),k=1,...,[log2(n)],j<2k+1,这里mk(xj)是基于第一个2k样本的样本j的拟合近似。然后,预测的mk(xj)会低于
与现有技术相比,本发明的有益效果:
本发明在使用满足ieee802.11要求的虚警率0.1的情况下,检测率相比svm提升10%,整体分类性能优于svm,同时误分类率、误分类风险也显著下降,此外通过实验还得知主用户发射功率不同即次用户在不同信噪比情况下本发明性能也基本较svm算法强,即不同信道环境下机器学习模型可以重训练以适应当前信道,有着更强的实用性,即使在信噪比较低的情况下性能表现也较好,鲁棒性较强。对于频谱感知应用来说,意义重大。
附图说明
图1是本发明基于机器学习的频谱感知方法步骤图。
图2是7*7合作频谱感知系统结构模型。
图3是catboost算法与svm算法(线性核函数)在7*7模型的roc曲线。
具体实施方式
下面结合附图来对本发明的实施作进一步的说明。
本发明基于catboost算法的信道环境自适应频谱感知方法,其系统结构框架图如附图1所示。
下面结合附图2说明本发明中基于地理位置的合作频谱感知模型,结合图3说明本发明相比于此前表现最好的svm算法在pu不同发射功率下roc曲线、检测率、误分类风险以及误分类率的性能表现。仿真是用python3.6.2在64位pc,内存ram16g,六核i7(3.2ghz)环境下进行的。
本发明比较的性能指标如下:
a)roc曲线(receiveroperatingcharacteristiccurve),结果为实验独立运行200次后平均曲线,此指标体现了算法的整体分类性能。
b)检测率(detectionprobability),授权用户上线时非授权用户成功检测到的概率,结果为实验运行200次的平均检测率。
c)误分类风险(misclassificationrisk),授权用户上线时分类器给出授权用户下线标签的概率,结果为实验运行200次的平均误分类风险率。
d)误分类率(misclassificationerrorrate),分类器判断错误的概率,即把授权用户下线判断为上线以及把授权用户上线判断为下线的概率,结果为实验运行200次的平均误分类率。
实施例
为了验证本发明基于catboost算法解决认知无线网络下的频谱感知问题的可用性和可行性,进行了仿真实验并与svm算法进行算法性能比较。仿真参数设置如下:感知时间段τ为100μs,带宽为5mhz,噪声功率谱密度为-174dbm,每一个pu发射功率为200mw,路径损失系数为4,多径衰落和阴影衰落系数都为1,每一个pu上线的概率为0.5.svm的核函数选择为线性核函数,因为在前期的工作中已经证明了线性核函数在此问题的优秀表现。训练向量为160条测试向量为640条。正负样本比例为7:1.在附图2的7*7合作频谱感知系统结构模型中,有49个su,均匀分布在7*7的网格中,有3个pu分别在(-1100m,-1000m)、(750m,890m)、(1500m,-1000m)位置。在附图3中roc曲线可以看到,用实线标出svm算法,用虚线标出了catboost算法,在虚警率为0.1时,catboost比svm检测率提高了10%,整体分类性能优于svm。
在pu不同的发射功率下相比于svm算法,本发明有着更高的检测率、误分类风险和误分类率具体如表1所示:
表1catboost算法与svm算法在7*7模型中主用户发射功率不同的情况下性能表现指标
随着信噪比提高两个算法指标都会提升,当信噪比较高时catboost达到收敛。这都证明了本发明的可行性和可用性,可将本发明用于解决认知无线网络下的频谱感知问题。
- 还没有人留言评论。精彩留言会获得点赞!