本发明涉及数码摄像技术领域,具体为一种逆光环境下的人脸图像质量提升方法。
背景技术:
在现有的拍照留念的行为为大众所重视时,各种数码摄像设备广受欢迎,而如何在逆光环境下的人脸图像质量提升是人脸识别产品的关键特性与难点,效果好坏直接影响产品的体验和兼容性。
现有方法之一是用背光补偿靠提升视场中央部分的亮度、降低视场四周部分的亮度来达到看清位于中央位置内物体的目的是以牺牲画面的对比度为代价的,且缺乏人脸目标不在视场中央时的动态灵活性。
现有方法之二是利用宽动态技术(hdr)基于多帧图像合成的多次曝光,不同帧之间的曝光采取时间差异,对明亮部分进行短曝。但由于快门速度不同,在两张(或更多)构成合成宽动态图像的单独快照中,捕捉图像时场景的移动部分会出现在不同的位置。宽动态打开时,其它方面的指数就会有所降低,比如清晰度、灵敏度、色彩等等,画面有可能会变得稍微模糊,色彩饱和度下降,画面显得较淡;在低照度环境中灵敏度下降等。
所以如何在逆光场景下实现人脸图像质量提升是需要不断改进优化的问题。
技术实现要素:
本发明的目的在于提供一种逆光环境下的人脸图像质量提升方法,以解决上述背景技术中提出的如何在逆光场景下实现人脸图像质量提升的问题。
为实现上述目的,本发明提供如下技术方案:一种逆光环境下的人脸图像质量提升方法,该逆光环境下的人脸图像质量提升方法如下:
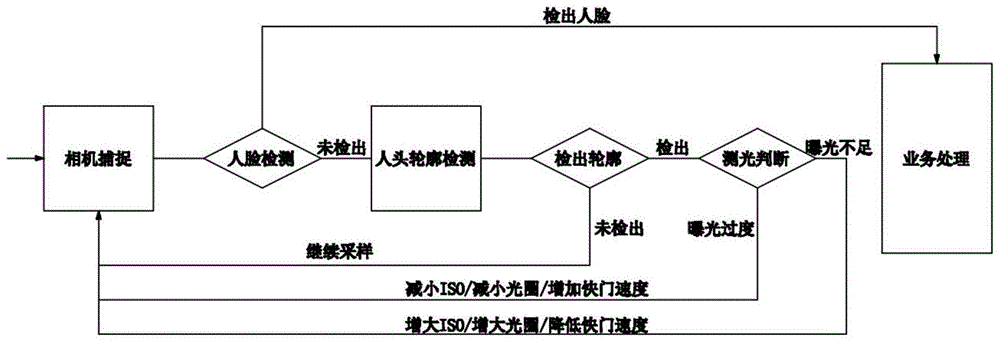
s1:利用卷积神经网络进行深度学习,对人脸的轮廓位置进行定位训练,通过相机对人脸进行样本采集;
s2:对步骤s1中的采集样本进行人工标注人脸位置,并将采集数据进行存储;
s3:对步骤s2中存储采集数据通过深度学习方法,使用人脸边框预测的残差平方和作为损失函数来进行训练与学习,完成对人脸的轮廓定位的训练;
s4:对步骤s3中的检测出的区域做局部测光,并根据局部测光的结果进行曝光强度的调节训练。
优选的,所述步骤s2中的采集样本采取逆光下脸部细节丢失的正脸、逆光下脸部细节丢失的侧脸、正常人脸、正常侧脸进行正反样本的搭配。
优选的,所述步骤s2中的采集数据采用voc格式进行存储。
优选的,所述步骤s4中根据局部测光结果,该局部区域曝光过强则减小iso、减小光圈、增加快门速度使测光区域区域柔和不过曝,曝光不足则增大iso、增大光圈、降低快门速度使测光区域柔和不欠曝。
优选的,所述步骤s1中的卷积神经网络和所述步骤s4中的曝光强度调节训练均采用tiny-dsod计算网络进行训练学习。
与现有技术相比,本发明的有益效果是:本发明通过综合使用神经网络技术以及摄像头调整策略,最终提高逆光环境下的人脸图像质量。该方法具有以下特点:
兼容性佳:针对不同强度光环境特别是极端逆光环境下人脸细节完全丢失的场景下均能有效兼容。
速度快:仅通过一帧图像输入做处理判断,调整后第二帧即可获得质量提升。
定位准确:人脸在摄像头图像中的不同位置均能有效定位。
附图说明
图1为本发明系统原理框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要理解的是,术语“上”、“下”、“前”、“后”、“左”、“右”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
请参阅图1,本发明提供一种技术方案:一种逆光环境下的人脸图像质量提升方法,该逆光环境下的人脸图像质量提升方法如下:
s1:利用tiny-dsod计算网络进行深度学习,对人脸的轮廓位置进行定位训练,通过相机对人脸进行样本采集;
由于深度学习需要大量的训练数据,而针对特定任务需求的训练样本往往是有限的,通常情况下,目标检测算法会先使用在海量数据(如imagenet数据集)上训练好的分类模型对需要训练的网络参数进行初始化(pre-train预训练),然后使用训练样本对网络参数进行微调(fine-tune),而tiny-dsod算法是一种无需预训练,直接基于训练样本从零开始训练目标检测模型的方法,能够从零开始训练检测网络,且效果可以与目前性能最好的模型相媲美,实现了轻量化模型设计,适用于移动端存储与部署。
dsod的网络分为两个部分:提取特征的backbone网络和预测结果的前端网络。backbone网络是深度监督网络densenets的变形,由stemblock、四个denseblocks、两个2个transitionlayers和2个transitionw/opoolinglayers组成。预测网络同样使用dense结构融合多尺度特征进行预测。
s2:对步骤s1中的采集样本进行人工标注人脸位置,采集样本采取逆光下脸部细节丢失的正脸、逆光下脸部细节丢失的侧脸、正常人脸、正常侧脸进行正反样本的搭配,增多各种情况拍摄下的对人脸轮廓的定位捕捉,提高数据样本数量,从而实现对多情况下人脸不易察觉中的对人脸轮廓的定位捕捉,更加适用于逆光下对人脸轮廓的定位,并以voc格式将采集数据进行存储,通过voc的数据集,并且按照voc的数据集自身的架构,实现了深度学习中voc数据集自身进行train文件训练数据存储,val文件的验证数据存储,trainval文件对所有训练和验证数据的存储,test文件的测试数据存储,实现了基于tiny-dsod计算网络进行学习时将深度学习的数据均保存在voc数据集中;
s3:对步骤s2中存储采集数据通过tiny-dsod计算网络进行训练学习,使用人脸边框预测的残差平方和作为损失函数来进行训练与学习,完成对人脸的轮廓定位的训练;
s4:对步骤s3中的检测出的区域做局部测光,并根据局部测光的结果进行曝光强度的调节训练,根据局部测光结果,该局部区域曝光过强则减小iso、减小光圈、增加快门速度使测光区域区域柔和不过曝,曝光不足则增大iso、增大光圈、降低快门速度使测光区域柔和不欠曝,从而实现仅通过一帧图像输入做处理判断,调整后第二帧即可获得质量提升。
局部测光是ttl测光的一种方式,为的是确定画面中央部分的曝光,可对被摄体各个部位进行精密的测光。可对画面的某一局部进行测光,当被摄主体与背景有着强烈明暗反差,而且被摄主体所占画面的比例不大时,运用这种测光方式最合适;在这种情况下,局部测光比中央重点加权平均测光和点测光方式准确,又不像点测光方式那样由于测光点太狭小需要一定测光经验才不容易失误。从而适用于逆光环境下对人脸这一被摄主体抓捕后,从而在被摄主体所占画面比例不大时使用,测光更为准确,从而便于进行曝光增加和曝光降低调节使用,适合配用tiny-dsod计算网络下进行深度学习使用,从而提高逆光环境下的人脸图像质量提升。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点,对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明;因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内,不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。