一种基于模糊聚类算法的无线传感器网络节点分簇优化方法与流程
本发明涉及一种网络节点分簇优化方法,特别是涉及一种基于模糊聚类算法的无线传感器网络节点分簇优化方法。
背景技术:
随着无线传感器网络时间同步算法的发展,从最初的参考广播算法(referencebroadcastsynchronization,rbs)和传感器网络的定时同步算法(timing-syncprotocolforsensornetworks,tpsn)到泛洪时间同步协议(floodingtimesynchronizationprotocol,ftsp),这些算法虽然是提高了时间同步的精度,降低了整个传感器网络的功耗,但这些算法都是基于单挑时间同步机制而发展下来的,但是现在随着传感器网络节点硬件技术的进步,使得传感器节点不断地变小,单跳距离变短,整体的节点网络的规模愈加扩大,同步误差的累积必然会越来越巨大。
技术实现要素:
本发明的目的在于提供一种基于模糊聚类算法的无线传感器网络节点分簇优化方法,本发明是针对无线传感器网络中时间同步技术(主要是泛洪广播时间同步算法(floodingbroadcasttimesynchronizationalgorithm,fbts)的聚类模式的问题,设计一种使其聚类的边界更加确定的方法。
本发明的目的是通过以下技术方案实现的:
一种基于模糊聚类算法的无线传感器网络节点分簇优化方法,所述方法的算法是通过一些设定的指标对样本进行划分将同一个类别划分为一个类然后对各个类进行迭代计算使得每个类都有自己的隶属度,通过迭代进行隶属度的计算,直到完全收敛为止;收敛条件是隶属度的变化量小于规定的阈值;
具体步骤如下:
1)确定模式类数k,1<k≤n,n为样本个数;
2)按照样本个数建立初始矩阵,并使得矩阵列元素和为0;
3)通过算式子求zi(l);
4)对得到的数据进行计算得到新的u(l+1);
5)需要求出迭代的聚类中心不断重复直到完全收敛;
6)得到新的u(l+1)进行聚类,划分方法是按照隶属原则进行的,若
则
所述的一种基于模糊聚类算法的无线传感器网络节点分簇优化方法,所述l为这里面的迭代;
式中,z为聚类中心,u为隶属度矩阵,为矩阵u中第i行第j列的数据,为数据集的第j个数据,参数m≥2,在计算得到的各个聚类中心都要用到n个样本当中。
所述的一种基于模糊聚类算法的无线传感器网络节点分簇优化方法,所述u(l+1),具体计算如下:
为避免分母为零,特别的:
若
可见,dij越大,uij(l+1)越小,其中d为点到质心的距离。
所述的一种基于模糊聚类算法的无线传感器网络节点分簇优化方法,所述收敛条件:
其中
本发明的优点与效果是:
本发明方法使用模糊聚类的算法,使得原来的算法存在的边界节点分界不明的情况缩小。其使得无法归类的边界节点的重新归类的次数减少,能够有效的提高时间同步算法的同步效率增强。
附图说明
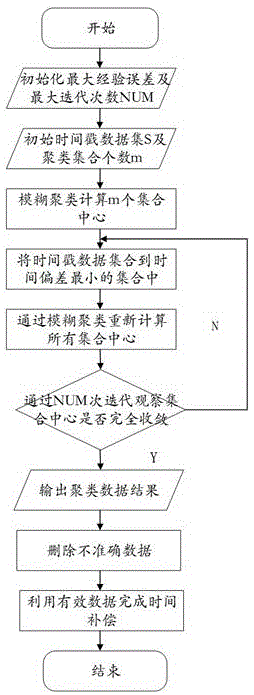
图1为本发明方法的过程状态图。
具体实施方式
下面结合实施例对本发明进行详细说明。
模糊k-means均值算法基本思想是通过一些设定的指标对样本进行划分将同一个类别划分为一个类然后对各个类进行迭代计算使得每个类都有自己的隶属度,是通过迭代进行隶属度的计算,直到完全收敛为止。收敛条件是隶属度的变化量小于规定的阈值。
具体步骤如下:
1.确定模式类数k,1<k≤n,n为样本个数;
2.按照样本个数建立初始矩阵,并使得矩阵列元素和为0
3.通过下面的式子来求zi(l),l为这里面的迭代;
式中,z为聚类中心,u为隶属度矩阵,
4.对得到的数据进行计算可以得到新的u(l+1),具体计算如下:
为避免分母为零,特别的:
若
可见,dij越大,uij(l+1)越小,其中d为点到质心的距离。
5.本发明需要求出迭代的聚类中心不断重复直到完全收敛,收敛条件:
其中
j为加权平方和准则函数,k为聚类中心个数,m为加权指数。
6.本发明得到新的u(l+1)进行聚类,主要的划分方法是按照隶属原则进行的,若
则
对于传统的k-means,是把数据划分到不相交的类中的。模糊聚类的方法应用在无线传感器时间同步算法中有很重要的价值,因为在无线传感器网络中会有多个节点,每个节点都有可能存在是边界节点,那么如何区分是否是边界节点就需要用到模糊聚类进行划分,本发明将各个节点进行分类,每一类都有一个中心点,但是在实际应用中会存在大量节点在多个类的边界上面,这时候能够区分边界就显得特别重要,边界区分明确的话可以更好的提高时间同步精度。
改进算法的主要区别在于聚类上提出了新的算法---efbts算法,该算法主要使用了模糊聚类的方式进行聚类,时间戳聚集到时间偏差最小的集合中,在通过模糊聚类重新计算所有集合中心,删除不准确数据,利用有效数据完成时间补偿。
- 还没有人留言评论。精彩留言会获得点赞!