一种基于CVSD编码特征的语音失步检测方法与流程
本发明涉及一种基于cvsd编码特征的语音失步检测方法。
背景技术:
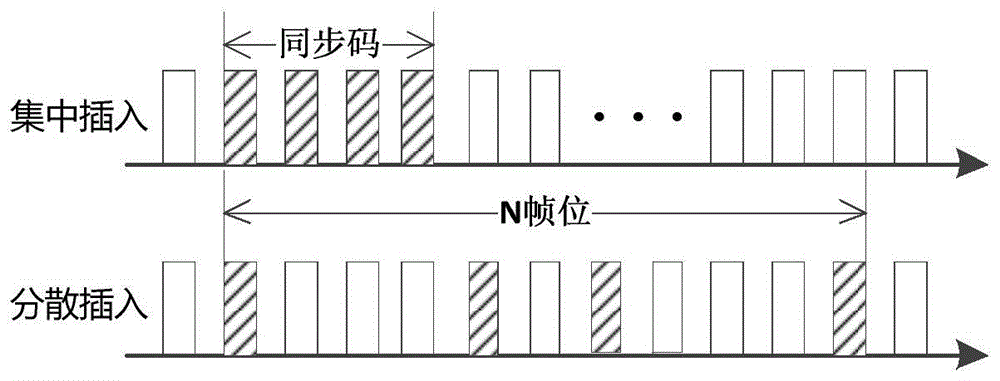
目前通信过程中常用的失步检测方法:发端插入同步码,收端逐位比较的方式。这种方法需要利用信道冗余带宽(传输有效载荷之外的信道资源),发端周期性集中或分散插入同步码,其基本工作原理如图1所示。
在接收端产生一组与发送端插入同步码相同的本地同步码组,在识别电路中使用本地同步码组与接收的信号序列进行逐位的比较、识别,进行失步检测。
当系统处于同步状态时,各个对应比较的码位都相同,则没有失步脉冲输出;当系统处于非同步状态,对应比较的码位不同,这时就有失步脉冲输出,使本地同步码组逐位移动,向接收序列中的同步码组靠近,直至重新进入同步状态。
逐位比较的失步检测方法,首先要求传输信道提供额外的带宽资源,插入帧同步码增加了设计复杂性,同时为降低载荷数据的伪同步概率,同步码组往往较长,这势必会降低信道的容量。此外在通信过程中,还可能由于传输信道误码,引起同步识别电路也会误认为失步,从而造成“假失步”的情况。
技术实现要素:
为了克服现有技术的上述缺点,本发明提供了一种基于cvsd编码特征的语音失步检测方法,通过对检测周期内语音数据的“特征编码”进行统计、分析,然后与预设失步门限阈值的比较,实现对cvsd语音失步的快速检测。本发明方法可有效解决窄带语音通信中的失步检测问题,提高信道的带宽利用率,具备较强的抗误码能力,可广泛地应用于对通话质量和安全性有较高要求的保密通信系统中。
本发明解决其技术问题所采用的技术方案是:一种基于cvsd编码特征的语音失步检测方法,包括如下步骤:
步骤一、对cvsd编码后的串行码流进行串并转换处理;
步骤二、对串并转换处理后的数据进行特征码型统计;
步骤三、根据统计结果与预设的失步门限阈值相比较,进行语音失步判决。
与现有技术相比,本发明的积极效果是:
本发明方法可应用于多类型的数字语音通信系统中,解决在信道资源有限和传输误码较大环境下的语音失步检测技术问题。本发明无需插入同步码组,不占用信道资源,而且检测周期和门限可灵活设置,具备极强的抗信道误码能力,可有效防止“假失步”现象,此外本发明的设计简单,无论采用软件、硬件均可实现。
附图说明
本发明将通过例子并参照附图的方式说明,其中:
图1为插入同步码示意图;
图2为逐位比较法电路原理图;
图3为典型应用实例一;
图4为cvsd数据串并转换示意图;
图5为32k模式失步判决门限示意图;
图6为cvsd语音失步统计示意图。
具体实施方式
一、本发明的基本工作原理
自然界中,正常的各类声音信号(例如人类话音、铃音、音乐、背景声、汽车鸣笛等)均是较为平缓、渐变的,在经过cvsd采样、量化、编码后,表现为在周期内“特征码型”出现概率满足一定的规律,同时的能量分布较为均匀;一旦出现周期内“特征码型”统计超出设定门限阈值以及高能量分布,则表明通信中的语音信号发生了不规律的跳变,预示着语音通信中出现了大量噪声,即语音失步。
本发明正是基于cvsd“特征码型”分布规律,通过对语音数据本身特性进行统计、分析,实现对语音通信系统的失步检测功能。
二、典型应用实例
本发明主要针对cvsd编码的语音数据,通过在检测周期内对“特征码型”的统计、分析,再与预设正常声音信号的门限阈值进行比较,判断当前语音通信处于同步或失步状态。
本发明的输入信号源是经过cvsd编码的语音数据。在发送端,模拟语音信号经过采样、量化、编码后,输出cvsd语音编码,再经过加密运算发往线路进行传输;在接收端,首先从接收单元解密运算还原出cvsd语音数据,送入失步检测模块对预定周期内cvs话音数据的“特征码型”分布进行分析、统计,实现语音通信的失步检测功能,应用实例如图3所示。
下面具体以图3中接收端解密后cvsd编码数据为例,对具体的语音失步检测方法进行说明。
步骤一:串并转换处理
以cvsd编码后的串行码流中,任意bit作为失步检测的起始点。从起始点开始按bit进行移位,将数据送入8位移位寄存器的最低位,实现cvsd话音编码bit流的串并转换,如图4所示。
步骤二:特征码型统计
8位移位寄存器初始值设置为00000000,从检测起始点开始,每收到一个bit数据便移入移位寄存器的最低位。当移入8bit数据后,每移入1bit数据,读取一次移位寄存器中的数据,并对该字节数据进行“特征码型”检测和统计,cvsd编码的特征码型共三种:
(1)全零码:00000000
(2)静噪码:10101
(3)极值码:11111
三种特征码型的统计方法如下:
(1)当8位移位寄存器中,值为00000000,则全零码计数器num_zero加一;
(2)当8位移位寄存器中,低5比特(bit4~bit0)值为10101,则静噪码计数器num_mute加一;
(3)当8位移位寄存器中,低5比特(bit4~bit0)值为11111,则极值码计数器num_maxi加一;
注:每个检测周期开始前,将三种特征码型的计数器清零。
步骤三:语音失步判决
当一个检测周期结束后,将全零码计数器、静噪码计数器、极值码计数器的值与预设失步门限阈值进行比较,判断当前基于cvsd编码的语音通信是否发生失步,具体判决方式如下。
1、检测周期:建议每个检测周期≥1秒,可根据实际应用以1秒为单位递增,每1秒的总统计数为32768bit;
2、判决门限:
条件一:全零码计数器>总统计数*11.25%;
条件二:静噪码计数器>总统计数*5.08%;
条件三:极值码计数器<总统计数*2.34%;
如图5所示,使用方法如下:
三个判决条件任意一个满足时,可判断系统当前处于同步工作状态;
三个判决条件均不满足时,可判断系统当前处于失步工作状态。
下面以1秒(即32768bit数据)作为一个检测周期为例,对图6中cvsd语音编码数据进行失步判决的方法进行具体说明。
从检测起始点开始,逐bit将cvsd语音数据移入8位移位寄存器的最低位,移入1字节(8bit)后开始统计,如图6所示;
移入的第1字节为0xc0,与全零码(00000000)、静噪码(10101)、极值码(11111)对比,均不符合则三种计数器均保持初始值0x00;
此后每移入1bit,都将与三种码型进行比较。因此第2字节为0x80,与全零码、静噪码、极值码对比,均不符合则三种计数器均保持不变;
第3字节为0x00,与全零码、静噪码、极值码对比,符合全零码特征,则全零码计数器num_zero加一,其它计数器保持不变;
……
第32768字节为0xb5,与全零码、静噪码、极值码对比,0xb5的低5比特(bit4~bit0)值,符合静噪码特征,则静噪码计数器num_mute加一,其它计数器保持不变,至此一个检测周期结束,对三个计数器的值分别进行统计分析。
假设条件一:
1.1全零码计数器num_zero=2500;
1.2静噪码计数器num_mute=800;
1.3极值码计数器num_maxi=500;
判决门限:
条件一:全零码计数器2500>总统计数*11.25%=3686,不满足;
条件二:静噪码计数器800>总统计数*5.08%=1664,不满足;
条件三:极值码计数器500<总统计数*2.34%=766,满足;
检测结果:三个判决条件中任意一个满足,则判断系统当前处于同步工作状态。
假设条件二:
2.1全零码计数器num_zero=1600;
2.2静噪码计数器num_mute=616;
2.3极值码计数器num_maxi=1200;
判决门限:
条件一:全零码计数器1600>总统计数*11.25%=3686,不满足;
条件二:静噪码计数器616>总统计数*5.08%=1664,不满足;
条件三:极值码计数器1200<总统计数*2.34%=766,不满足;
检测结果:三个判决条件均不满足,则判断系统当前处于失步工作状态,需启动重新同步。
- 还没有人留言评论。精彩留言会获得点赞!