一种针对边缘网络下突发请求的强化学习调度方法及设备与流程
本发明涉及强化学习和边缘计算领域,具体是一种针对边缘网络下突发请求的强化学习调度方法及设备。
背景技术:
5g的兴起极大地加强了人与机器之间的联系。同时,诸如交互式游戏、图像/视频处理、增强/虚拟现实和面部识别之类的计算密集型应用程序在移动设备上变得越来越流行,并且这些应用程序追求低延迟和低能耗。随着移动边缘计算(mobileedgecomputing,mec)范式的出现,数据和计算从集中式云计算基础架构推到了网络的逻辑边缘,从而可以使得移动设备快速使用边缘服务器上的资源来处理多样化的任务。在当前的mec范式中,边缘云覆盖了较大的服务区域,用户可以在其中向该单个边缘云发送各种请求以进行处理。通常,单个边缘云能快速处理少量请求。然而,当计算密集型任务是突发到来时,单个边缘云处理遇到瓶颈。以多人虚拟现实(virtualreality,vr)游戏为例,如fromothersuns或seekingdawn,通常,vr具有严格的性能要求,体现在高于60的fps(即每秒帧数)和低于20ms的motion-to-photon延迟,计算密集型的渲染处理成为满足此类严格要求的关键障碍。而且,在vr交互过程中,许多玩家可能会同时发布渲染请求,这不可避免地导致计算密集型请求的突然到达。对于边缘云,它不仅需要为每个动作渲染前景和背景,而且还需要通过向每个用户发送实时图像来同步整个vr场景,这将导致不可预测的计算和通信成本。显然,单一资源受限的边缘云无法解决突发的请求。
边缘是一个动态变化和设备异构的聚合体,这主要体现在带宽的波动变化,以及移动设备的多样性。同时,用户在局域网中是移动的,并且需求是多样化的,因而很难有统一的规则来实现请求即来即服务。
技术实现要素:
发明目的:针对现有技术的不足,本发明提出了一种针对边缘网络下突发请求的强化学习调度方法及设备,能够实现边缘网络中对突发请求的迅速调度。
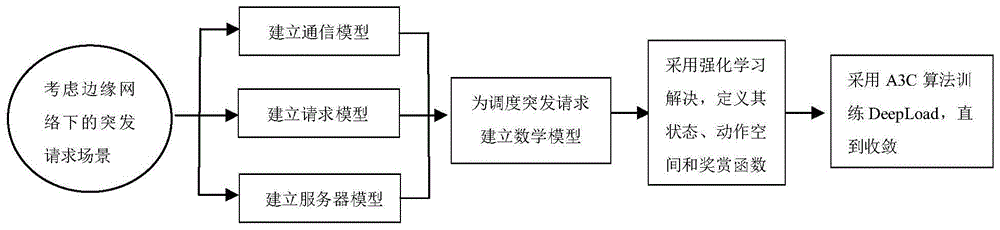
技术方案:根据本发明的第一方面,提供一种针对边缘网络下突发请求的强化学习调度方法,包括如下步骤:
s1、建立系统模型,包括通信模型、请求模型和服务器模型;
s2、根据系统模型为调度突发请求建立目标函数,将调度突发请求转化为优化问题;
s3、采用强化学习求解优化问题,定义状态空间、动作空间和奖赏函数,建立强化学习模型;
s4、采用a3c算法训练强化学习模型直至收敛;
s5、将训练好的强化学习模型用于边缘网络的请求调度。
根据本发明的第二方面,提供一种计算机设备,所述设备包括:
一个或多个处理器;
存储器;以及
一个或多个程序,其中所述一个或多个程序被存储在所述存储器中,并且被配置为由所述一个或多个处理器执行,所述程序被处理器执行时实现如本发明第一方面所述的步骤。
有益效果:本发明的方法以一种多服务器协作的方式处理突发请求,在这种协作方式中,相邻的边缘服务器相互协作以处理请求,从而最大化在deadline之前完成的请求数量。通过将调度问题迁移成强化学习的决策问题,针对每个请求,只需将当前的状态输入到强化学习的actor网络,即可从输出的概率分布图中选择动作,达到快速决策的效果。
附图说明
图1是本发明的调度方法流程图;
图2是边缘网络下两阶段调度突发请求示意图;
图3是本发明的调度器(deepload)基本运作机制示意图。
具体实施方式
下面结合附图对本发明的技术方案作更进一步的说明。
新兴的移动边缘计算大大减轻了用户不断提高的服务质量(qos)与云计算的大量延迟之间的矛盾。此外,智能设备的普及使用户可以在任何地方发送计算密集型请求。边缘服务器能够快速处理少量请求,但是当遇到突发的计算密集型请求时,单个资源受限的边缘服务器可能就陷入了瓶颈。因此,本发明提出以一种多服务器协作的方式处理突发请求,在这种协作方式中,相邻的边缘服务器通过相互协作来处理突发请求,从而最大化在deadline之前完成的请求数量。所述方法通过建立通信模型、请求模型和服务器模型,并将其建模成长期优化问题,以最大程度地提高按时完成的请求数量,然后将多维背包问题规约到调度突发请求问题,证明其为npc问题,考虑到该问题过高的计算复杂性,本发明提出一种基于深度强化学习的调度器deepload,自动学习ap选择和工作量重分配的策略。
参照图1,本发明提出的针对边缘网络环境下突发请求的强化学习调度方法,包括以下步骤:
步骤s1,建立系统模型,包括通信模型、请求模型和服务器模型。
s1-1,建立通信模型:主要是指用户和基站之间的链路,分为上行链路和下行链路,在当前的mec体系结构中,网络部署基于正交频分多址访问(ofdma)。
针对通信模型,为了反映网络带宽的动态变化特性,将网络链接分为上行链路和下行链路。假设带宽h被分成|k|个不同频率的子波,移动设备端和服务器端的传输能力分别为pu和ps,上行和下行链路有相同的噪声n0,上行和下行链路的信道衰弱系数分别为hul和hdl,上行和下行链路的目标误码率分别为gul和gdl,用户和基站之间的距离为d,因为用户是通过移动设备发送请求,所以实际上用户和移动设备在这里是等价的。由于服务器一般是部署在基站,服务器和基站可以绑定在一起,所以这里在衡量距离时实际上它俩也是等价的,但为了清楚起见以及功能的针对性,以便于理解方案,表述时进行了区分。当前可用的的频率子波数量为k,路径损失系数为βl,通过加性高斯白噪声(awgn)通道可得上行和下行链路的最大容量rul和rdl(bps):
γ表示伽马函数。
s1-2,建立请求模型:可以将移动用户发布的请求视为特定作业,这些作业通过边缘服务器中安装的相应服务进行处理。一个请求可以细化地分为多个相互独立的任务,每个任务可以在为该类型的请求配置了相应服务的边缘服务器中独立执行。
针对请求模型,工作量大小通过输入规模来衡量。请求ri的输入大小为bi,不失一般性,用ω代表每字节需要的cpu周期数,那么总工作量wi=ωbi,ω的取值和请求的时间和空间复杂度有关。每个请求都可以切分成一个个独立的任务,并且每个任务都可以独立的运行在配置相关服务(service)的服务器上。
s1-3,建立服务器模型:边缘服务器部署在ap上,通过vm或docker管理资源和虚拟化资源。每个边缘服务器都具有有限的存储和计算功能,本发明侧重于服务器的计算能力上。
针对服务器模型,一个边缘服务器是资源受限的,因此只可以配置有限数量的服务,使用指示变量
步骤s2,根据系统模型为调度突发请求建立目标函数,将调度突发请求转化为优化问题。
对于任何请求来说,从产生到被执行最多经历两个阶段。第一个阶段中,移动设备选择一个最优的接入ap,并将请求发送到该ap上的服务器;第二个阶段中,若请求的预测完成时间超过请求允许被完成的最晚时间(deadline),则需要将一定比例的工作量卸载到相邻服务器。若请求在第一阶段就已经按时完成,则不需要执行第二阶段。图2是两阶段调度突发请求示意图,有两类箭头,序号为1表示第一阶段,序号为2表示第二阶段,若第一阶段上的服务器已经满足了请求的deadline,则不需要第二阶段。
为了更好的理解这两个阶段,考虑其离线场景。离线场景是指针对一个特定时隙,已知其网络拥塞状况和服务器的负载,以此来建模其目标函数,考虑传输延迟。这里时隙指的是一个特定的时间间隔,如五分钟。若请求只在本地服务器上处理,则只需要考虑上行和下行链路的传输时延,服务器处理时延和等待时延。首先表示出用户ui可以连接的ap集合
其中φ(ui)表示用户ui可以直接连接的ap集合,
用指示变量
其中
若
用l(j,k)表示apj和apk之间的传播时延,
其中
针对在时间t内到达的所有请求,我们希望最大化按时完成的请求数量,同时满足服务器和网络的资源限制,那么可得如下优化问题ω:
s.t.
u表示所有用户集合,θ表示所有ap集合。
步骤s3,采用强化学习求解ω问题,定义其状态空间、动作空间和奖赏函数。
通过将每一个请求看成一个item,并且将每个可能的调度策略(接入ap,卸载到相邻服务器的百分比)获取的收益作为value,则可将多维的背包问题规约到ω问题,显然ω问题是npc问题,复杂性过高。多维背包背包中,需要考虑的限制因素不止是重量了,可能还有其他(如流行度、用户偏好度)。上述所得ω问题中的状态也是多维的,而且动作空间是离散的,并且每一种动作也对应一个reward,即价值。多维背包问题是npc问题,复杂度很高,只可能存在伪多项式算法。我们将多维背包问题规约到了ω问题,说明ω的复杂度比多维背包问题还更高,显然ω是npc问题。考虑到深度强化学习(deepreinforcementlearning,drl)在动态环境中出色的决策能力,本发明采用drl解决ω问题,所建立的调度模型本发明称为deepload。首先需要定义出强化学习的三要素,即状态空间、动作空间和奖赏函数。
将状态表示成一个多维向量st={bu,bd,bp,w,c,req},其中包括从环境中获取的网络状态、服务器状态以及请求的特征,
将动作也表示成一个多维向量
步骤s4,采用a3c算法训练强化学习模型直至收敛。
深度强化学习最关键的是定义动作空间、状态空间和奖赏函数,其次是采用何种方式训练其模型。建立调度突发请求的数学模型并将其迁移到深度强化模型后,本发明采用a3c来训练deepload中的actor-critic网络,针对每一个状态,只需要根据actor网络中的动作概率分布图中选择动作,即可实现快速决策。actor-critic网络是a3c中要训练的网络,rl智能体每次都根据actor的动作概率分布图选择动作,以此来进行与环境进行交互,而critic在每次或每几次执行动作之后,都会评判actor的参数优劣,并通过梯度下降的方式不断更新actor网络以及自身网络。图3中,rl-agent通过将对环境的观察表示成一个状态向量,并将其输入到策略网络中,得到动作概率分布图,从中选择一个动作作用到环境中,得到一个立即奖励。
具体地,使用a3c来训练deepload,其中包括critic网络(值函数v(st;θv))和actor网络(策略π(at|st;θ)),这个两个网络除了输出层不一样,其他的层共享参数。rl-agent每次都是根据策略网络的概率分布选择动作。同时开启了n个线程(即rl-agent),同时为避免相关性而采用了不同的环境设置。每个线程独自训练并异步更新全局策略,但在每个训练的训练周期(episode)结束时,会再次同步全局参数。deepload使用梯度下降再更新θv和θ,θv和θ分别是actor和critic这两个网络的参数,关键思想是朝向最大总奖励的参数梯度方向。在每个episode中,基于累积的折扣奖励,可以进一步的更新参数。
步骤s5,利用训练好的模型实现对边缘网络后续请求的调度。
训练deepload直至收敛后,每个用户只需将actor网络模型下载到本地,针对每个请求,只需将当前的状态输入到actor网络,根据输出的动作概率分布图选择动作即可。由于actor的参数规模较小,所以下载时间很短,几乎不占用网络带宽,由于边缘服务器距离用户较近,所以下载代价几乎忽略不计。
基于上述详细描述的调度方法步骤,在一个实施例中根据上海出租车的轨迹数据集,设计了一个模拟器来获取大量样本,并利用两个geforcegtxtitanxpgpu可通过许多情节训练actor-critic网络。最后,进行了几个控制实验,结果证明了deepload的优越性。
具体地,首先设计一个lan模拟器来逼近真实的请求突发场景,并采用了上海出租车数据集的一些关键特征,如出租车每个时间点所在的经纬度以及汽车站每刻的车流量,模拟出了请求的到来模型和基站的分布模型。然后根据本发明所提的方法处理了2017年2月28日一天的数据量,按5分钟为一个时隙,共获取288个时隙,这个时隙可以认为是一个时间间隔(五分钟),t是24小时,所以一天就是288个时隙,将其作为一个训练的episode。
初始化每个请求以及网络的特征,如请求输入量,网络的上行和下行链路容量服从参数不一致的均匀分布,b∈[3000,4000],w∈[400,600],rul∈[125,175],rdl∈[225,275],wq∈[125,175],l(i,j)∈[25,35]模拟了网络的动态变化性,这主要体现在突发请求的到来和处理对网络带宽和服务器的影响。采用a3c算法来训练deepload,并利用了两个gtxtitanxpgpu来训练其actor-critic网络,这两个网络的隐藏层都是400×400×400。为其设置了三个基准值,分别为ssp(单服务器处理)、locp(链路最优处理)以及qocp(排队最优处理),结果发现,随着训练次数的增加,deepload性能也逐渐提高,可以使大部分请求都能按时完成。具体来说,当训练的周期达到3000时,deepload已经能够使90%以上的请求按时完成,当训练周期为10000时,按时完成的比例达到了96%以上,然而losp和qocp均只有50%,ssp更是低于40%。随后我们也分析了学习率和a3c中线程数量对deepload性能的影响,结果发现,线程数量越多,deepload性能越好,这也和理论相符,线程数量代表了对环境的搜索力度;学习率对deepload的影响并不是线性的,学习率越高,性能波动越大,需要在多次调试中选择。
基于与方法实施例相同的技术构思,根据本发明的另一实施例,提供一种计算机设备,所述设备包括:一个或多个处理器;存储器;以及一个或多个程序,其中所述一个或多个程序被存储在所述存储器中,并且被配置为由所述一个或多个处理器执行,所述程序被处理器执行时实现方法实施例中的各步骤。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!