一种基于私有云的骚扰电话拦截方法与流程
本发明属于信息传输与处理领域,特别涉及一种拦截骚扰电话的方法。
背景技术:
现阶段,拦截骚扰电话主要有三种方法。一是使用手机程序,二是根据其他用户的标记进行判断,三是外呼予以拦截。
使用手机程序主要是用系统自带的程序在手机上设置黑名单,或是下载拦截软件进行拦截,直接屏蔽非预期呼叫。但是拦截号码的范围较小,如只可以拦截具体的号码或者只可以拦截以特定数字开头的号码,易被骚扰者规避。除此之外,骚扰拦截软件基于公有云平台,由于有访问用户通讯录的权限,所以有可能窃取用户隐私。
根据其他用户的标记和标记人数进行判断,可以从主观上判断电话类型,从而达到不接听骚扰电话的目的。但是无法达到主动拦截的效果,依旧会有电话提示音。并且由于标记领域不够全面,标记不准确,造成误挂行为。
外呼予以拦截是指运营商对连续多日接通率低于50%,外呼时段或外呼行为不规范,或未经用户同意进行外呼商业营销的号码,外呼予以拦截。其中,个人号码日外呼量超过300次即予以警示,日外呼量超过500次或经警示后仍日外呼量超过300次的,直接对其外呼予以拦截。这类方法识别骚扰电话的周期长,效率低,若外呼量不超过300次则不易被拦截。
技术实现要素:
本发明的目的是提出了一种基于私有云的、能够共享黑白名单、将拦截规则进行融合的骚扰电话拦截方法。
本发明的技术方案是:一种基于私有云的骚扰电话拦截方法,包括以下步骤:
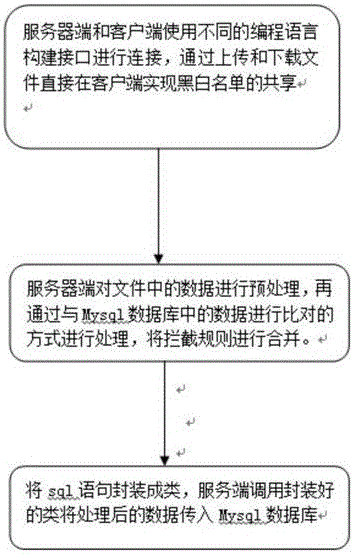
(1)、将服务器端和客户端使用不同的编辑语言构建接口进行连接,用户进行黑白名单的上传和下载;通过上传和下载文件直接在客户端实现黑白名单的共享;
(2)、基于贪婪算法,按照层次结构对数据进行预处理。
(3)、服务器端对文件中的数据进行处理,通过mysq1数据库中的数据进行比对的方式,基于前缀、后缀和位数的方法将拦截规则进行合并;
(4)、将sq1语句封装成类,服务端调用封装好的类将处理后的数据传入mysq1数据库。
(5)、客户端实时识别陌生来电。
进一步的,所述步骤(1)具体包括下述步骤:
(1.1)、客户端添加需要拦截的骚扰电话号码和无条件接受的号码,添加方式是选择添加完整号码、按照前缀号码、按照前缀号码及电话位数;
(1.2)、服务器端开启后,在客户端选择手动连接方可连接服务器端。
(1.3)、上传文件时,客户端自动将用户添加的号码封装成文件传入服务器端;下载文件时,服务器端将数据库中的数据调出,以文件形式传入客户端;客户端将文件解析成具体数据传入用户界面。
进一步的,所述步骤(2)中先顺序处理每一个数据,再将数据库中现有数据按照长度划分为不同层次,将新数据传入最低层次,对其进行预处理。
进一步的,所述步骤(3)具体包括下述步骤:
(3.1)、服务器端顺序处理收到的每一条数据,将数据划分到不同的长度范围内进行匹配,先划分到长度比其小的数据中,寻找用前缀来表示该号码的匹配规则,找到则该号码无需加入;
(3.2)、接着划分到相同长度的数据中,当出现相同号码或者找到除了最后一位为“#”,其余位均和该号码相同的号码,则新数据无需加入;
(3.3)、最后划分到长度比其长的数据中,判断该数据能否对旧数据进行替换。
(3.4)、当本次数据全部接收完毕后,在整个数据库内不同长度范围中进行统计;当发现某一长度的号码除了最后一位全部相同,且最后一位从0到9都有,则最后一位用“#”代替。
进一步的,所述步骤(4)中数据传入数据库时需要传入合并拦截规则后拦截骚扰电话的号码、客户端的账号。
进一步的,所述步骤(5)中客户端采用基于有限自动机的模式匹配算法将陌生来电和黑白名单进行匹配;若匹配黑名单成功,则利用反射技术实现通过程序挂断电话;若匹配白名单成功,则继续拨通,等待用户接听。
本发明具有的有益效果:1、信任者在私有云中进行共享,保证信息不泄露,隐私不被侵犯;2、能够在短时间内获取更多骚扰电话的信息,有效地拦截骚扰电话。3、能够缩短匹配时间,高质量拦截。
附图说明
图1为本发明的服务器端的流程图;
图2为本发明中用户的使用方法图;
图3为本发明中客户端的模块图;
图4是本发明中客户端实时识别算法的示例图。
具体实施方式
下面结合实例和说明书附图对发明的技术方案进行详细说明:
一种基于私有云的骚扰电话拦截方法,包括以下步骤:
(1)、将服务器端和客户端使用不同的编辑语言构建接口进行连接,用户进行黑白名单的上传和下载;通过上传和下载文件直接在客户端实现黑白名单的共享;
(2)、基于贪婪算法,按照层次结构对数据进行预处理。
(3)、服务器端对文件中的数据进行处理,通过mysq1数据库中的数据进行比对的方式,基于前缀、后缀和位数的方法将拦截规则进行合并;
(4)、将sq1语句封装成类,服务端调用封装好的类将处理后的数据传入mysq1数据库。
(5)、客户端实时识别陌生来电。
进一步的,所述步骤(1)具体包括下述步骤:
(1.1)、客户端添加需要拦截的骚扰电话号码和无条件接受的号码,添加方式是选择添加完整号码、按照前缀号码、按照前缀号码及电话位数;还包括其他相似的号码等;
(1.2)、服务器端开启后,在客户端选择手动连接方可连接服务器端;并非自动连接。
(1.3)、上传文件时,客户端自动将用户添加的号码封装成文件传入服务器端;下载文件时,服务器端将数据库中的数据调出,以文件形式传入客户端;客户端将文件解析成具体数据传入用户界面。
进一步的,所述步骤(2)中先顺序处理每一个数据,再将数据库中现有数据按照长度划分为不同层次,将新数据传入最低层次,对其进行预处理。
进一步的,所述步骤(3)具体包括下述步骤:
(3.1)、服务器端顺序处理收到的每一条数据,将数据划分到不同的长度范围内进行匹配,先划分到长度比其小的数据中,寻找用前缀来表示该号码的匹配规则,找到则该号码无需加入;
(3.2)、接着划分到相同长度的数据中,当出现相同号码或者找到除了最后一位为“#”,其余位均和该号码相同的号码,则新数据无需加入;
(3.3)、最后划分到长度比其长的数据中,判断该数据能否对旧数据进行替换。
(3.4)、当本次数据全部接收完毕后,在整个数据库内不同长度范围中进行统计;当发现某一长度的号码除了最后一位全部相同,且最后一位从0到9都有,则最后一位用“#”代替,例如:“1955622444#”。
进一步的,所述步骤(4)中数据传入数据库时需要传入合并拦截规则后拦截骚扰电话的号码、客户端的账号。
进一步的,所述步骤(5)中客户端采用基于有限自动机的模式匹配算法将陌生来电和黑白名单进行匹配;若匹配黑名单成功,则利用反射技术实现通过程序挂断电话;若匹配白名单成功,则继续拨通,等待用户接听。
步骤1、2、3为平台建立的流程,如附图1所示,步骤4为实时识别算法详解,为附图4所示。
1、建立私有云平台:
1.1、用户应当搭建私有云平台,用于存储、下载拦截规则;私有云平台可以从云服务器提供商处采购,也可自行搭建服务器并从因特网服务商处购买静态ip地址;
1.2、传输协议选用安全套接字协议,以防止信息被恶意篡改;
以下结合案例进一步说明;导入socket模块后,服务器端通过socket()函数创建套接字,参数为af_unix和sock_stream(面向连接);客户端用socket()构造方法,通过系统默认类型的socketimpl创建未连接套接字;调用inetsocketaddress类封装端口;服务器端的accept()函数阻塞式被动等待客户端的连接;连接成功后,客户端会收到服务器端发过来的数据并显示,数据统一采用utf-8编码格式。
2、黑白名单的构建及上传下载文件:
2.1、本发明涉及黑名单和白名单:黑名单为骚扰电话的号码,白名单为不需要拦截的号码;当一个号码同时出现在白名单和黑名单中时,默认的操作是将其作为白名单号码;
2.2、黑白名单号码允许使用通配符;支持的通配符包括“*”、“#”,支持单独或结合使用;“*”可表示零位或多位数字,如“952112*”则表示以952112开头的所有号码,拦截范围广,设置简便;“#”表示一位数字,如“8521##87”则表示8521开头且五六位数字任意的8位号码,将拦截设置精确到每一位,降低错误拦截的可能性;
2.3、用户可以手动输入黑白名单内容。
2.4、当用户提交上传名单申请时,客户端自动建立到服务器端的安全套接字连接,将数据发送到服务器端;服务器端需要对内容做进一步处理后加以存储。
3、服务器端黑白名单的处理:
3.1、数据库中按照编号,长度,号码的方式存储骚扰电话的信息,其中编号为主key键,设置为自增;传入数据库的号码为数据处理之后的号码,保证数据库中的拦截规则始终为最简;如果有规则需要合并,则姓名不以具体的人名或公司命名,直接改为“骚扰者”;
3.2、服务器端收到黑白名单后对数据进行预处理,顺序处理收到的每一个数据;将数据库中现有数据按照长度划分为不同层次,最先将新数据传入最低层次,之后按照顺序依次进入不同层次,直到匹配到当前存在的规则或是作为新规则使用为止;
3.3、合并规则为:①与已有规则进行比较,以范围大的为准;②对所有完整号码进行统计,如果某类号码只有最后一位不同,且0-9全部存在,则进行合并;
规则①在每次收到单条数据时使用,其操作步骤如下:
(1)、收到黑白名单数据后,判断电话号码的长度,记作length,先把它划分到长度比它小的数据中;
(2)、将该电话号码与数据库中当前所有长度小于length的拦截规则进行匹配,如果有规则能够表示该号码,则该号码不用加入数据库;
(3)、如果以上规则无法表示该号码,则将它划分到长度和它一样的数据中;
(4)、若在此次比较中找到相同号码,则该号码不用加入数据库中;
(5)、若在此次比较中找到除了最后一位为“#”,其余位均和该号码相同的号码,例如数据库中有“1321888729#”,而该号码为“13218887290”,该号码也无需加入数据库;
(6)、如果该号码还未被表示,将该电话号码划分到数据库中所有长度大于它的数据中;如果找到了拦截范围比当前数据小的规则,则用当前数据代替旧数据;
(7)、若以上步骤均无法找到表示该数据的规则,则将该数据存入数据库;
规则②在所有数据上传完毕后使用:完整手机号长度为11,完整座机号长度为8或11(加区号);在整个数据库内不同长度范围中进行统计;如果发现某一长度的号码除了最后一位全部相同,且最后一位从0到9都有,则最后一位用“#”代替;例如“1955622444#”。
3.3、合并中出现冲突,即当指定为黑名单中的号码同时出现在白名单中时,白名单中的号码具有优先权。
4、实时识别:
4.1、客户端监听电话状态,收到来电后和名单中已有的骚扰电话进行匹配,采用基于有限自动机的模式匹配算法;匹配成功后利用反射技术实现通过程序挂断电话;
4.2、有限自动机的匹配模式算法通常用一个五元组来表示,m={q,q,a,∑,δ};如果当前有限自动机的状态为p,读入字符为a,则它从p变为状态δ(p,a)的过程就是一次转移;如果δ(p,a)∈q,则表示自动机接受迄今为止输入的所有字符;当一个文本字符串被自动挤读取过程中存在状态f∈a,则表示当前字符串被接受,匹配成功,否则,则匹配失败;在本发明中,将黑名单中的所有数据生成一个自动机,来电作为符号序列输入,通过转移函数改变状态;如果最终状态属于接收状态,则匹配成功;以附图4所示为例,当前缀为137*、136*时,按位匹配,匹配成功则进入下一个状态,直到达到接收状态,表示匹配成功。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!