基于杠杆采样的网络时延估计方法与流程
本发明涉及网络时延估计领域,具体涉及一种基于杠杆采样的网络时延估计方法。
背景技术:
网络时延监测在网络性能评估中起到非常重要的作用,因而受到广泛关注。目前,有许多应用程序对网络时延的变化非常敏感,特别是个人设备,如笔记本电脑,可穿戴设备和个人移动电话等。举例来说,在线视频服务需要较低的传输时延以确保服务质量。因此,如何在短时间内获取整个网络的时延情况进行性能评估,并进一步选择最高效的数据传输路径,才能确保服务质量。然而,在大规模网络中,由于测量成本较高,难以对所有的节点对都进行时延测量。比较常用的方法是通过测量一部分节点对的时延数据来估计整个网络的时延情况,推测其他未测量节点对之间的时延。
关于网络时延估计的研究主要分为两类:矩阵填充和张量填充。矩阵填充最早由candès提出,可以应用到网络监控和时延估计中。张量填充可以看作是矩阵填充在高维情况下的扩展。该方法旨在从观察到的部分样本中恢复未知数据。在信号处理和数据分析领域,张量填充是一种广泛使用的技术,并且已应用于网络流量估计应用中。这些流量数据通常都是低秩的,而网络时延数据也表现出低秩特性。
由于个人设备(包括笔记本电脑、可穿戴设备和手机等)的普及,网络时延估计变得更加复杂。与传统的固定网络设备不同,由于个人设备的移动性和通信环境的复杂多变,个人设备的时延总是波动变化的。这给网络的性能评估带来较大的困难。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于杠杆采样的网络时延估计方法,充分利用网络时延数据的时空相关性,以低的采样成本精确估计未知的网络时延数据,克服了现有方法采样成本高,恢复精度低的问题。
为实现上述目的,本发明采用如下技术方案:
一种基于杠杆采样的网络时延估计方法,包括以下步骤:
步骤s1:采集端到端网络的时延数据,并构造为张量模型;
步骤s2:在预设的时间间隙内,随机选择网络中的节点对测量其时延数据;
步骤s3:根据测量到的时延数据,计算时延张量的杠杆分数以及下一时隙各节点对的采样概率;
步骤s4:根据杠杆分数选择分数大于阈值的节点对并测量其时延;
步骤s5:重复步骤s3和s4直到采样完成,得到相应的采样值;
步骤s6:根据得到的采样值,利用基于张量奇异值分解的交替方向乘子法进行张量填充,估计未知的网络时延数据。
进一步的,所述步骤s1具体为:对于包含n个节点的端到端网络,分析在n3个时隙内的时延变化情况,将时延数据构造为一个三阶张量模型,记为
进一步的,所述步骤s2具体为:
步骤s21:在n3个时隙内,按照设定的比例β选择前l个连续的时隙,即l=βn3;
步骤s22:在前l个连续的时隙内,根据给定的采样比例α,在每个时隙随机地选择m=n×n×α个节点对并测量其时延;
步骤s23:将第k个时隙的采样样本集合记为ωk,k=1,...,l,记
步骤s24:初始化一个全零采样张量
进一步的,所述步骤s3具体为:
步骤s31:令k=k+1。
步骤s32:采用张量奇异值分解方法计算采样张量
步骤s33:计算第k个时隙的各节点对(i,j)的采样概率:
其中,r为张量的秩,μi和νj分别是采样张量
进一步的,所述步骤s4具体为:
步骤s41:根据采样概率pij,在第k个时隙选择采样概率最大的m个节点对测量其时延。
步骤s42:将在第k个时隙新采样到的样本记为ωk,更新ω和
进一步的,所述步骤s6具体为:
步骤s61:所有已知样本的集合为ω,采样张量为
其中,ρ>0,s表示迭代次数,1(.)代表指示函数,
步骤s62:经过优化得到的解表示为:
本发明与现有技术相比具有以下有益效果:
本发明充分利用其历史数据并结合网络时延的时空特征,在降低采样成本的同时提高时延数据的恢复精度。
附图说明
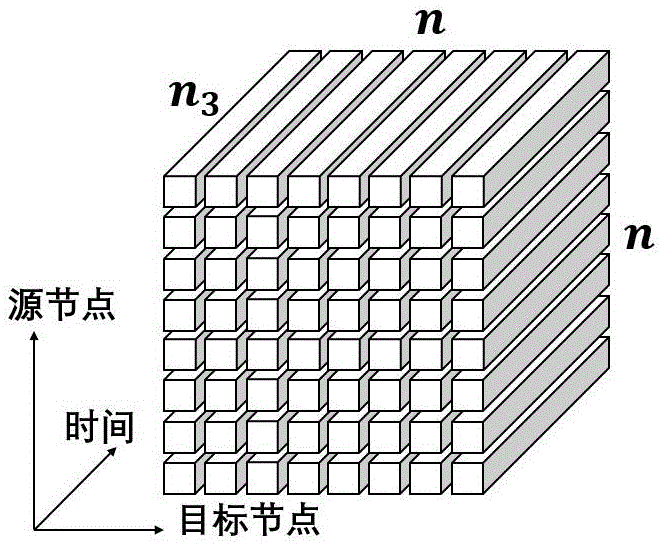
图1是本发明一实施例中构造的网络时延数据的张量模型;
图2是本发明一实施例中进行采样与恢复的步骤示意图
图3为本发明一实施例中在,合成数据无噪声的情况下,本发明实施例(leveragesampling+admm)的恢复误差与其他算法的结果对比示意图。
图4为本发明一实施例中,在合成数据加噪声的情况下,本发明实施例(leveragesampling+admm)的恢复误差与其他算法的结果对比示意图。
图5为本发明一实施例中,在个人设备时延数据集上,本发明实施例(leveragesampling+admm)的恢复误差与其他算法的结果对比示意图。
图6为本发明一实施例中,在固定的网络设备时延数据集上,本发明实施例(leveragesampling+admm)的恢复误差与其他算法的结果对比示意图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
请参照图1,本发明提供一种基于杠杆采样的网络时延估计方法,包括以下步骤:
步骤s1:采集端到端网络的时延数据,并构造为张量模型;
步骤s2:在预设的时间间隙内,随机选择网络中的节点对测量其时延数据;
步骤s3:根据测量到的时延数据,计算时延张量的杠杆分数以及下一时隙各节点对的采样概率;
步骤s4:根据杠杆分数选择分数大于阈值的节点对并测量其时延;
步骤s5:重复步骤s3和s4直到采样完成,分别对接下来的时隙进行采样,直到k=n3,完成所有n3个时隙的采样过程,采样完成。此时所有已知样本的集合为ω,采样张量为
步骤s6:根据得到的采样值,利用基于张量奇异值分解的交替方向乘子法进行张量填充,估计未知的网络时延数据。
在本实施例中,所述步骤s1具体为:对于包含n个节点的端到端网络(网络中任意两个节点可相互通信),分析在n3个时隙内的时延变化情况,即n个源节点×n个目标节点×n3个时隙,将时延数据构造为一个三阶张量模型,记为
在本实施例中,所述步骤s2具体为:
步骤s21:在n3个时隙内,按照设定的比例β选择前l个连续的时隙,即l=βn3;
步骤s22:在前l个连续的时隙内,根据给定的采样比例α,在每个时隙随机地选择m=n×n×α个节点对并测量其时延;
步骤s23:将第k个时隙的采样样本集合记为ωk,k=1,...,l,记
步骤s24:初始化一个全零采样张置
在本实施例中,所述步骤s3具体为:
步骤s31:令k=k+1。
步骤s32:采用张量奇异值分解方法计算采样张量
步骤s33:计算第k个时隙的各节点对(i,j)的采样概率:
其中,r为张量的秩,μi和vj分别是采样张量
在本实施例中,所述步骤s4具体为:
步骤s41:根据采样概率pij,在第k个时隙选择采样概率最大的m个节点对测量其时延。
步骤s42:将在第k个时隙新采样到的样本记为ωk,更新ω和
在本实施例中,在通过上述步骤得到的采样样本ω的基础上,利用基于t-svd的admm方法进行张量填充,对未知的时延数据进行估计,可以得到完整的数据
步骤s61:所有已知样本的集合为ω,采样张量为
其中,ρ>0,s表示迭代次数,1(.)代表指示函数,
步骤s62:经过优化得到的解表示为:
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!