一种轨道交通流数据处理方法与流程
本发明涉及轨道交通领域,尤其涉及一种轨道交通流数据处理方法。
背景技术:
本发明使用云平台计算技术来对轨道交通获取到流数据进行处理,来加快对庞大数据的处理,节省处理时间,能更有效的根据数据及时做出反应。云计算只需要很少的管理工作,如与服务器之间的交互,就能够实现从可配置的计算资源共享池中,便捷地通过关联网络获取需要的资源,提供的速度十分迅速,并且在使用完毕后也能够迅速的释放资源。本发明加快了轨道交通中不间断的庞大流数据的处理,将处理后的有效数据传递到下一步根据平台预先设置的决策方法来快速的生成对应指令,使得轨道交通中的各项指令步骤能够实时给出,快速完成。此技术是基于主要用于实时处理计算大规模不间断数据流的storm架构,借助zookeeper来协调整个集群,主节点(控制节点)运行nimbus,负责发布拓扑程序和任务,并对集群状态进行监控;从节点(工作节点),运行supervisor,负责接收任务并执行。其中有一个拓扑数据入口spout,将外部传输的数据流转换为元组发送给处理加工的逻辑单元bolt,一个bolt完成处理后可以继续传递给后续的bolt,处理完成后即可得到所需的数据。数据入口spout和逻辑单元bolt间采用流分组策略进行链接,它们均能配置成多个实例以达到并行处理的目的,而这些实例最终也就是所需执行的任务,将会在工作节点中被调度执行,最终形成机器所需执行的命令。
目前轨道交通流数据进行处理的技术主要存在以下缺点:
1、现有技术虽然实时计算延迟度较低,但仍为秒级的延迟而非毫秒级;
2、现有技术是准实时的,是将一个时间段内的数据收集起来作为一个rdd(弹性分布式数据集),然后进行处理,而非来一条数据处理一条数据这样纯实时处理。
3、现有技术的健壮性一般,没有特别大的容错能力。
技术实现要素:
本发明目的在于针对现有技术的不足,提出一种基于云计算的轨道交通流数据处理方法,将数据处理的延时进一步降低达到毫秒级别的处理延迟,并且数据的处理过程是纯实时的,急来一条数据处理一条数据,增强数据处理过程中的容错能力,提高平台运行的健壮性。
本发明的目的是通过以下技术方案来实现的:一种轨道交通流数据处理方法,该方法包括以下步骤:
(1)基于kafka的消息分发,kafka用于发布与订阅消息,包括控制节点和工作节点,即控制节点运行nimbus,负责发布拓扑结构和任务,工作节点运行supervisor,负责接收任务并执行;通过kafka汇总轨道交通客流及设备等监测数据形成数据源,并将数据源发送给storm进行实时处理;
(2)storm拓扑结构的设计,所述storm拓扑结构由数据源组件kafkaspout和三个逻辑处理单元prebolt、runbolt以及postbolt组成;
storm通过zookeeper来控制kafka集群,控制节点运行的nimbus进程向zookeeper发送轨道交通中所有的状态信息,进而发布storm拓扑结构中所有逻辑处理单元节点个数和任务,所述轨道交通中所有的状态信息包括保存在kafka集群上的实时客流量、运载量和运输速率等;zookeeper提供的watcher接口则用于对storm进行监听,通过监听来了解轨道交通信息等变化,然后控制kafka集群做出相应的指令处理;
(3)kafkaspout从kafka集群中拉取数据,并将其处理成元组,传递到后续的逻辑处理单元preblot中;传递的方式采用随机分组的方式,使得元组均匀的分布到prebolt的数据处理程序中,在prebolt中对元组进行预处理,即根据需求剔除无关的数据,所述无关的数据为除实时客流量、运载量、运输速率之外的数据,然后将剔除后的数据标记数据的来源并处理成特征向量的形式;
(4)prebolt逻辑单元将预处理后的数据传递到runbolt逻辑单元中,在runbolt逻辑单元中将特征向量作为vpmcd模型的训练样本,完成vpmcd模型初始化与vpmcd模型的在线增量学习;
所述vpmcd模型初始化具体为:首先采用历史数据对模型进行首次训练,将训练好后的模型参数储存到关系型数据库中,然后通过runbolt读取首次训练后的模型;
所述模型的在线增量学习,通过zookeeper对runbolt的监听,可以实现模型的增量学习,具体为:随着轨道交通中的客流数据信息变化,当积累了新的训练样本时,zookeeper会将把新的训练样本序列化后发送给runbolt逻辑单元,runbolt逻辑单元将序列化的训练样本通过getdata方法进行反序列操作,获得实际新的训练样本,然后对runbolt逻辑单元读取的vpmcd模型进行重新训练。
(5)runbolt将标记来源的数据和在线增量学习后的vpmcd模型采用随机分组的方式发送到postbolt逻辑处理单元中,通过postbolt逻辑处理单元将标记来源的数据和在线增量学习后的vpmcd模型参数保存于关系型数据库中;所述在线增量学习后的vpmcd模型可用于对轨道交通情况进行预测。
进一步地,zookeeper对storm进行监听,具体为:
(1)在storm拓扑结构中设计一个connection类实现watcher接口,zookeeper通过watcher接口监听到kafka、prebolt、runbolt、postbolt等节点状态信息的变化。
(2)在kafkaspout中设计一个datalistener接口,其getdatainfo方法负责将数据从zookeeper中获取到拓扑结构中。
(3)设计一个能够向拓扑结构传递消息的zookeeper客户端,通过此客户端,zookeeper能够向拓扑程序发送指令和数据,并能将序列化后的指令或数据发送到节点路径上。
进一步地,步骤(4)的模型的在线增量学习中,根据样本的时效性,确定积累的新的训练样本的时间间隔。
进一步地,多个postbolt逻辑处理单元同时运行,而且因为每个数据流均被标记了来源,所以不同数据流的数据可以储存在同一个物理分区中,节省了计算资源,降低延时。
进一步地,同时运行的runbolt逻辑处理单元有多个,而其个数在控制节点发布storm拓扑结构时已经确定,将个数作为参数传递给postbolt,并且postbolt统计收到的vpmcd模型个数,当runbolt逻辑处理单元个数与统计的vpmcd模型个数相等时执行一次存储操作,避免了重复存储,而在之后的运行过程中导致出错。
本发明的有益效果:
1、延时低,达到毫秒级:数据在程序的传递过程均采用随机分组的方式,分布式处理的过程使得数据处理的延时大大降低;
2、数据纯实时处理:zookeeper能够实时监测到每个步骤中的数据变化,同时runbolt逻辑处理单元能够通过监测的数据变化提供新样本进行在线的增量学习,而不会积累太多样本进行处理,因此其学习改进也是近乎实时的;
3、健壮性好容错能力强:制定了一个避免重复存储同一个模型分类的策略,postbolt逻辑单元统计收到的vpmcd模型个数,当runbolt逻辑处理单元与统计的vpmcd模型个数相等时执行一次存储操作,避免了重复存储而导致出错。
附图说明
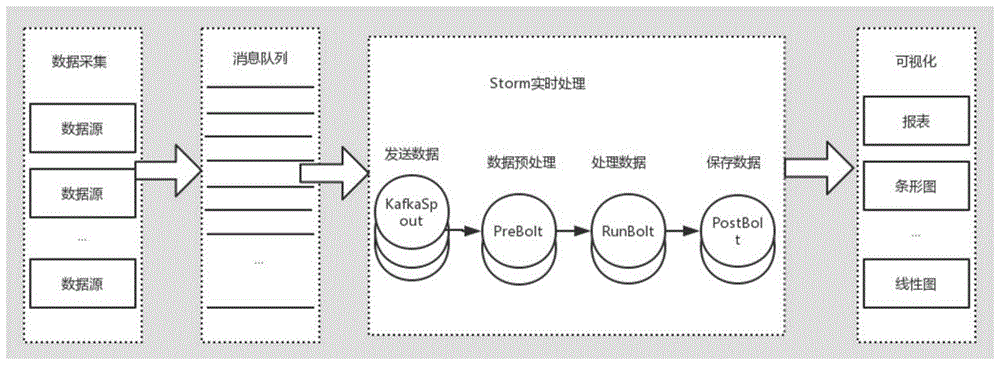
图1为本发明中基于storm平台的实时处理框架示意图;
图2为本发明中kafka架构示意图;
图3为本发明zookeeper监听机制示意图;
图4为本发明storm拓扑结构示意图。
具体实施方式
以下结合附图对本发明具体实施方式作进一步详细说明。
如图1所示,一种轨道交通流数据处理方法,该方法可以通过云平台实现,该方法包括以下步骤:
(1)基于kafka的消息分发,kafka是一个开源的消息系统,用于发布与订阅消息,即控制节点运行nimbus,负责发布拓扑结构和任务,工作节点运行supervisor,负责接收任务并执行。同时kafka还具有高吞吐量、分布式处理、拓展性强等优点,本方法通过kafka汇总轨道交通客流及设备等监测数据形成数据源,并将数据源发送给storm进行实时处理;kafka中有六个重要的角色类型,分别如下:
(a)message(消息):通信的基本单元,为一个无类别的特征向量。
(b)topic(话题):即message的类型,同一个类别的message在同一个topic中。
(c)partition(分区):topic的物理分区,每个partition是一个有序队列,每条message有一个有序标记(offset),topic可以分为多个partition。
(d)producer(生产者):message的发布者,为轨道交通中监测到的数据源。
(e)broker(代理):集群中的服务器,可水平拓展。
(f)consumer(消费者):订阅若干个topic,从broker中拉取message进行消费,为storm工作节点中的数据入口spout。
(2)storm拓扑结构的设计,所述storm拓扑结构由数据源组件kafkaspout和三个逻辑处理单元prebolt、runbolt以及postbolt组成,结构如图4所示;
storm通过zookeeper来控制kafka集群,控制节点运行的nimbus进程向zookeeper发送轨道交通中所有的状态信息,进而发布storm拓扑结构中所有逻辑处理单元节点个数和任务,所述轨道交通中所有的状态信息包括保存在kafka集群上的实时客流量、运载量、运输速率,通过云平台计算得到,所述节点个数的发布通过函数putnodenum(objectspoutnum,objectprenum,objectrunnum,objectpostnum)来进行,如设置spoutnum=10,prenum=20,runnum=50,postnum=20,即存在10个数据入口,20个数据预处理逻辑单元,50个数据处理逻辑单元和20个数据存储逻辑单元;zookeeper提供的watcher接口则用于对storm进行监听,其过程如图2所示,通过监听来了解轨道交通信息等变化,然后控制kafka集群做出相应的指令处理;zookeeper对storm进行监听,具体为:
(a)在storm拓扑结构中设计一个connection类实现watcher接口,zookeeper通过watcher接口监听到kafka、prebolt、runbolt、postbolt等节点状态信息的变化。
(b)在kafkaspout中设计一个datalistener接口,其getdatainfo方法负责将数据从zookeeper中获取到拓扑结构中。
(c)设计一个能够向拓扑结构传递消息的zookeeper客户端,通过此客户端,zookeeper能够向拓扑程序发送指令和数据,并能将序列化后的指令或数据发送到节点路径上。
(3)kafkaspout从kafka集群中拉取数据,并将其处理成元组,传递到后续的逻辑处理单元preblot中;传递的方式采用随机分组的方式,使得元组均匀的分布到prebolt的数据处理程序中,在prebolt中对元组进行预处理,即根据需求剔除无关的数据,所述无关的数据为除实时客流量、运载量、运输速率之外的数据,然后将剔除后的数据标记数据的来源并处理成特征向量的形式:例如设变量costumenum为客流量(百人),transportnum为运载量(百人),speed为运输速率(km/h),假设数据来源为地铁,将各站点costumenum/100,transportnum/100,speed/100,作为128维向量的值传入,通过一个softmax函数对向量进行编码,并将128维向量后的空值置为0便得到所需特征向量。
(4)prebolt逻辑单元将预处理后的数据传递到runbolt逻辑单元中,在runbolt逻辑单元中采用vpmcd模型对特征向量进行类别的识别,在runbolt逻辑单元中将特征向量作为vpmcd模型的训练样本,完成vpmcd模型初始化与vpmcd模型的在线增量学习;
所述vpmcd模型初始化具体为:首先采用历史数据对模型进行首次训练,将训练好后的模型参数储存到关系型数据库中,然后通过runbolt读取首次训练后的模型;
所述模型的在线增量学习,通过zookeeper对runbolt的监听,可以实现模型的增量学习,具体为:随着轨道交通中的客流数据信息变化,根据样本的时效性,确定积累的新的训练样本的时间间隔,本发明中将时间间隔设为1小时,即每小时将获取到的客流信息传入训练通过设置timespan=60设置间隔为60分钟。如图3所示,当积累了新的训练样本时,zookeeper会将把新的训练样本序列化后发送给runbolt逻辑单元,runbolt逻辑单元将序列化的训练样本通过getdata方法进行反序列操作,获得实际新的训练样本,然后对runbolt逻辑单元读取的vpmcd模型进行重新训练。由于模型增量更新耗时很短,在runbolt中只会积累十分少量的未处理元组,因此不会影响拓扑程序的正常运行。
(5)runbolt将标记来源的数据和在线增量学习后的vpmcd模型采用随机分组的方式发送到postbolt逻辑处理单元中,通过postbolt逻辑处理单元将标记来源的数据和在线增量学习后的vpmcd模型参数保存于关系型数据库中;所述在线增量学习后的vpmcd模型可用于对轨道交通情况进行预测。为了节省计算资源,减少延时,将各个轨道交通传感器的多种不同的客源数据流在同一个postbolt组件中进行存储处理,因为数据流已经被标记过,因此postbolt可以根据标记来识别数据来源,然后进行不同的存储操作。多个postbolt逻辑处理单元同时运行,而且因为每个数据流均被标记了来源,所以不同数据流的数据可以储存在同一个物理分区中,节省了计算资源,降低延时。
同时运行的runbolt逻辑处理单元有多个,而其个数在控制节点发布storm拓扑结构时已经确定,使用函数getrunnum(objectrunnum)将个数runnum作为参数传递给postbolt,postbolt统计收到的vpmcd模型个数,当runbolt逻辑处理单元与统计的vpmcd模型个数相等时执行一次存储操作,避免了重复存储,而在之后的运行过程中导致出错。
本发明对kafka中收集到的监测数据是通过随机分组来发送到prebolt中的,使得其在各个服务器各个bolt实例中较为均匀的分散,分布式处理的过程,使得对数据预处理的时间大大缩短。在vpmcd模型中,模型的在线增量模型更新耗时短,并且不会堆积在runbolt中,对拓扑程序的运行不会产生影响,不会导致延时的增加。
通过zookeeper提供的监听接口watcher,zookeeper能够实时监测到每个步骤中的数据变化,数据分散为流,并及时做出指令反应,同时runbolt的模型能够通过监测的数据变化提供新样本进行在线的增量学习,而不会积累很多的元组数据后再进行下一次的学习改进,其学习改进也是近乎实时的。因此本发明能够做到纯实时的来一条数据就着手处理一条数据。
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!