一种无拓扑结构的社交消息传播范围预测方法与流程
本发明涉及社交消息传播范围预测方法。
背景技术:
近年来随着社交网络的快速发展,越来越多的用户使用新浪微博、推特、facebook等社交网站分享自己的生活。据统计facebook截止到2018年12月31日每月的活跃用户超过23亿[1](zephoria.thetop20valuablefacebookstatistics-up-datedapril2018.[online],available:https://zephoria.com/top-15-valuable-facebook-statistics/,january1,2019.)。由此可见社交网已经成为许多人生活中的一部分。与此同时各大社交平台也在促进着各种消息的快速传播。例如在新浪微博上平均每天有几亿条微博产生。在每天产生的微博中会包含很多重要信息。用户更新一条微博可能包含着用户对某消息的态度和观点[2](yul,cuip,wangf,etal.frommicrotomacro:uncoveringandpredictinginformationcascadingprocesswithbehavioraldynamics[c]//2015ieeeinternationalconferenceondatamining.ieee,2015:559-568.),也可能是分享身边的新鲜事[3](althofft,jindalp,leskovecj.onlineactionswithofflineimpact:howonlinesocialnetworksinfluenceonlineandofflineuserbehavior[c]//tenthacminternationalconferenceonwebsearch&datamining.acm,2017:537-546.)。预测消息的传播范围在病毒营销、舆情监控、商品推荐等诸多领域都有广泛的应用,因此受到了数据挖掘领域的广泛关注。
目前对消息传播范围进行预测所使用的方法主要有两种,一种是根据消息特征或者消息的特定类型进行传播范围预测。例如可以根据发布的twitter是否带有标志性的图片从而预测它在facebook上的传播范围[4](chengj,adamicl,dowpa,etal.cancascadesbepredicted?[c]//proceedingsofthe23rdinternationalconferenceonworldwideweb.acm,2014:925-936.);也可以通过分析发布的twitter是否包含对消息传播有利的内容来预测它的传播范围[6]。然而使用消息特征预测消息传播范围显然不能推广到不同的平台。另一种方法是使用社交网络中用户的拓扑结构[5,6,7,8]([5]l.weng,f.menczer,andy.-y.ahn.predictingsuccessfulmemesusingnetworkandcommunitystructure.arxivpreprintarxiv:1403.6199,2014.[6]c.tan,l.lee,andb.pang.theeffectofwordingonmessagepropagation:topic-andauthor-controllednaturalexperimentsontwitter.arxivpreprintarxiv:1405.1438,2014.[7]lic,maj,guox,etal.deepcas:anend-to-endpredictorofinformationcascades[c]//proceedingsofthe26thinternationalconferenceonworldwideweb.internationalworldwidewebconferencessteeringcommittee,2017:577-586.[8]islam,m.r.,muthiah,s.,adhikari,b.,prakash,b.a.,&ramakrishnan,n.(2018,november).deepdiffuse:predictingthe'who'and'when'incascades.in2018ieeeinternationalconferenceondatamining(icdm)(pp.1055-1060).ieee.)或消息的转发结构[9](lic,guox,meiq.jointmodelingoftextandnetworksforcascadeprediction[c]//twelfthinternationalaaaiconferenceonwebandsocialmedia.2018.)来预测消息传播范围。然而在很多实际应用中,很难获得消息的传播结构以及用户的拓扑结构,通常只能获得消息的传播序列。例如在豆瓣网中,对于电影的影评只显示用户在什么时间评价了电影,而没有表明用户因为受到哪些用户影响才评价该电影。因此,只利用消息的传播序列而不考虑用户的拓扑结构来预测消息的传播范围具有更广泛的应用场景。
相关工作
在社交网中消息的传播范围包括微博/推特在一定时间内的转发数[4,5,10,11,12]([4]chengj,adamicl,dowpa,etal.cancascadesbepredicted?[c]//proceedingsofthe23rdinternationalconferenceonworldwideweb.acm,2014:925-936.
[5]l.weng,f.menczer,andy.-y.ahn.predictingsuccessfulmemesusingnetworkandcommunitystructure.arxivpreprintarxiv:1403.6199,2014.
[10]cheng,kongq,maow,etal.apartitionandinteractioncombinedmodelforsocialeventpopularityprediction[c]//2018ieeeinternationalconferenceonintelligenceandsecurityinformatics(isi).ieee,2018:232-237.
[11]jendersm,kasnecig,naumannf.analyzingandpredictingviraltweets[c]//proceedingsofthe22ndinternationalconferenceonworldwidewebcompanion.acm,2013:657-664.
[12]cheungm,shej,junusa,etal.predictionofviralitytimingusingcascadesinsocialmedia[j].acmtransactionsonmultimediacomputing,communications,andapplications(tomm),2017,13(1):2.),照片的被浏览数[2],视频被点赞的次数[13,14]([13]wus,rizoiuma,xiel.beyondviews:measuringandpredictingengagementinonlinevideos[c]//twelfthinternationalaaaiconferenceonwebandsocialmedia.2018.
[14]renzm,shiyq,liaoh.characterizingpopularitydynamicsofonlinevideos[j].physicaa:statisticalmechanicsanditsapplications,2016,453:236-241.)、或者学术论文在一定时间内被引用的次数[15](shenh,wangd,songc,etal.modelingandpredictingpopularitydynamicsviareinforcedpoissonprocesses[c]//twenty-eighthaaaiconferenceonartificialintelligence.2014.)等多种情况。相关工作大致可以分为3类:(1)利用消息本身的特征进行预测;(2)利用消息的传播序列和用户的社交关系进行预测;(3)只利用消息的传播序列进行预测。
消息特征或者消息的特定类型可以帮助预测消息的传播范围。例如:文献[4]根据发布的twitter是否带有标志性的图片来预测它在facebook上的转发次数;文献[6]分析twitter是否包含对消息传播有利的内容来预测它的转发次数;文献[13]分析视频在规定的时间段内观看人数的增长量来预测消息被观看的次数。然而消息的传播范围除了消息本身的特征,更多依赖发布消息或者转发消息用户的影响力,因此此类方法预测效果一般,而且不易推广到其他平台。
目前的绝大多数研究都是利用消息的传播序列和用户的社交关系进行预测。该类方法又可分为2种。一类是将消息传播预测视为分类问题,通过预测传播范围是否会超过某个阈值,来预测某个消息是否会变成流行消息[8,13,15]。另一类将消息传播范围预测看作回归问题,预测消息的最终传播范围或者截止到某一时刻的传播范围。此类研究通常使用确定的时间属性[13]、早期消息传播的拓扑结构[7,24]([7]lic,maj,guox,etal.deepcas:anend-to-endpredictorofinformationcascades[c]//proceedingsofthe26thinternationalconferenceonworldwideweb.internationalworldwidewebconferencessteeringcommittee,2017:577-586.
[24]zhangj,liub,tangj,etal.socialinfluencelocalityformodelingretweetingbehaviors[c]//proceedingsofthetwenty-thirdinternationaljointconferenceonartificialintelligence.aaaipress,2013.)以及用户的拓扑结构[25](zhangj,tangj,zhongy,etal.structinf:miningstructuralinfluencefromsocialstreams[c]//thirty-firstaaaiconferenceonartificialintelligence.2017.),来进行传播范围预测。文献[16,17]([16]lermank,ghoshr,surachawalat.socialcontagion:anempiricalstudyofinformationspreadondiggandtwitterfollowergraphs[j].computerscience,2012.
[17]zangc,cuip,songc,etal.structuralpatternsofinformationcascadesandtheirimplicationsfordynamicsandsemantics[j].2017.)预测消息的宏观传播范围。文献[18](yul,cuip,wangf,etal.frommicrotomacro:uncoveringandpredictinginformationcascadingprocesswithbehavioraldynamics[c]//2015ieeeinternationalconferenceondatamining.ieee,2015:559-568.)学习多数消息传播过程中的普遍拓扑结构预测消息传播范围。此类方法需要消息的传播结构或者用户的拓扑结构,但实际应用中这些信息不易获得。
目前在无拓扑结构结构(用户社交关系)条件下,对消息传播范围预测的研究相对较少。2012年rodriguez等人[19](gomez-rodriguezm,leskovecj,krausea.inferringnetworksofdiffusionandinfluence[j].acmtransactionsonknowledgediscoveryfromdata(tkdd),2012,5(4):21.)利用用户被影响的时间特征推断消息传播的路径,然后累加路径上的用户数计算传播范围。2012年aleksandr等人[20](simmaa,jordanmi.modelingeventswithcascadesofpoissonprocesses[j].computerscience-learning,2012:546-555.)提出了基于连续时间和霍克斯进程的随机过程范围预测模型。2014年bourigault等人[21](bourigaults,lagnierc,lampriers,etal.learningsocialnetworkembeddingsforpredictinginformationdiffusion[c]//acminternationalconferenceonwebsearchanddatamining.acm,2014:393-402)提出了基于学习映射观察动态时间对连续空间的影响,将参与扩散的节点投射到潜在的表达空间。然后计算用户向量的相似性判断用户是否会被另一个用户影响。2016bourigault等人[22](bourigaults,lampriers,gallinarip.representationlearningforinformationdiffusionthroughsocialnetworks:anembeddedcascademodel[c]//proceedingsoftheninthacminternationalconferenceonwebsearchanddatamining.acm,2016.)使用用户表达空间,将用户的影响能力映射到一个多维空间中,通过计算多维空间中两个向量的距离来计算是否会被影响。
技术实现要素:
本发明的目的是为了解决现有方法并没有考虑消息在传播过程中会存在相互影响的问题,而提出一种无拓扑结构的社交消息传播范围预测方法。
一种无拓扑结构的社交消息传播范围预测方法具体过程为:
步骤一、根据消息动作日志中的传播时间差为每个消息构造一个加权的传播图,传播图边上的数字代表用户之间的影响概率,在传播图构造完成之后,使用随机游走方式从传播图中提取若干条该消息可能的传播路径;
步骤二、使用word2vec方法计算出消息的传播路径上每个目标用户的初始特征向量;
步骤三、将消息的传播路径上的每个目标用户的初始特征向量送入bi-gru中得到传播路径上每个目标用户的最终向量表示;
所述bi-gru为双向门控制循环神经网络;
步骤四、基于传播路径上每个目标用户的最终向量表示和注意力机制,计算出每个目标消息的传播特征向量;
步骤五、构造加权传播图、随机游走、word2vec计算其他消息参与用户的特征向量,然后构造其他消息的传播向量;
基于其他消息的传播向量,使用梯度下降方法计算出其他消息的影响向量;
步骤六、将步骤四得到的目标消息的传播特征向量和其他消息的影响向量结合在一起,使用mlp拟合出目标消息的增量传播范围。
本发明的有益效果为:
本发明研究了无拓扑结构条件下消息传播范围预测问题,提出了一种无拓扑结构的消息传播范围预测方法nt-ep。该方法由4部分构成:(1)利用消息传播随时间衰减的特性为每个消息构造一个加权的传播图,在传播图上使用随机游走策略获取多条传播路径,再使用word2vec方法计算每个用户的特征向量;(2)把目标消息的传播路径替换成用户的特征向量序列输入到双向门控制循环神经网络(bi-gru),结合注意力机制计算出目标消息的传播特征向量;(3)考虑到不同消息传播可能存在的相互影响,利用目标消息发生前的其他消息,使用梯度下降方法计算出其他消息的影响向量;(4)将目标消息的传播特征向量和其他消息的影响向量结合在一起,使用多层感知机(mlp)拟合出目标消息的传播范围。
与其他方法相比,nt-ep方法具有2个明显的创新:(1)首次考虑了消息之间的相互影响;(2)利用消息传播随时间衰减特性为每条消息构造加权传播图,抽取传播路径。
nt-ep方法充分考虑了消息之间的相互影响。这是因为在消息的传播过程中,消息与消息之间必然会产生影响。例如:在公布个人所得税起征点改革消息之后的一段时间内,用户会增加对包含具体税率改革内容的消息的关注。因此个人所得税起征点改革消息对有相关内容的消息传播产生了影响。消息传播中的相互影响来自于两方面,一方面来源于消息本身的内容,也就是消息本身是否为热点消息,是否会被普遍关注。另一方面来源于已经参与消息传播的用户对于其他消息传播的影响。在一段时间内,用户使用社交网络的时间上限是固定的。用户浏览某些消息的时间更多意味着用户浏览其他消息的时间会减少。因此本发明方法nt-ep考虑了目标消息发生前后其他消息对目标消息可能存在的各种影响,构造了其他消息的影响向量,结合目标消息的传播特征向量来预测目标消息的传播范围。本发明实验部分比较了利用消息影响与不利用消息影响nt-ep方法的两种变体,证明了消息影响对范围预测的重要性。
nt-ep方法根据传播序列构造加权传播图,来模拟接近真实传播轨迹的传播路径。在无拓扑结构的条件下,只有用户的动作序列。但是用户在接受消息过程中必然会受到之前接受相同消息用户的影响,而且影响强度依赖于接受消息的时间差。假设在消息e传播过程中用户a接受了消息e,在用户a之前用户b和用户c也接受消息e,并且用户b接受的时间早于用户c。那么直觉上用户c对用户a接受消息影响更大。根据消息传播随消息衰减的特性[13],构造有向边b->a和c->a,c->a边上的权值大于b->a,边上的权值代表了影响强度,依赖于两个用户接受消息的时间差。nt-ep方法按照这种方式为每个消息构造一个随时间衰减的传播图,然后使用随机游走策略抽取多条传播路径,这些传播路径更接近于真实的传播轨迹。本发明实验部分构造了nt-ep方法的两种变体,一种利用时间衰减构造传播图,另一种与不利用时间衰减构造传播图,比较了这两种变体的性能,再次证明了消息传播符合时间衰减特性。本发明的贡献如下:
1.提出了一种新的无拓扑结构条件下的消息传播范围预测方法nt-ep。
2.nt-ep利用了消息之间的相互影响,提高了消息传播范围预测的准确性。
3.nt-ep利用了消息传播随时间衰减的特性为消息构造加权传播图,使得抽取的随机游走路径更接近真实的传播轨迹,提高了消息传播范围预测的准确性。
4.实验结果表明,nt-ep能对无拓扑结构条件下的消息传播范围进行准确预测,并且预测效果明显优于现有的方法。
现有方法并没有考虑消息在传播过程中会存在相互影响的情况。本发明利用了消息之间的相互影响,提出了一种无拓扑结构的传播范围预测方法nt-ep。该方法具有以下优势:(a)是一种端对端的学习框架;(b)适用于无拓扑结构;(c)考虑了消息传播过程中的相互作用;(d)抽取的随机游走路径更接近真实的传播路径;(e)结合目标消息的传播向量和其他消息的影响向量,同时利用注意力机制预测传播范围,使预测结果更准确。
本发明研究了无拓扑结构条件下消息传播范围预测问题,提出一种社交消息传播范围预测方法nt-ep。nt-ep首次利用消息之间的相互影响来提高范围预测的准确性。实验结果表明,nt-ep在多个评价指标上优于现有的方法deepcas和embeddingic。未来研究准备加入用户兴趣向量和用户基本属性进行范围预测,以及增加多层注意力机制尝试改善预测
附图说明
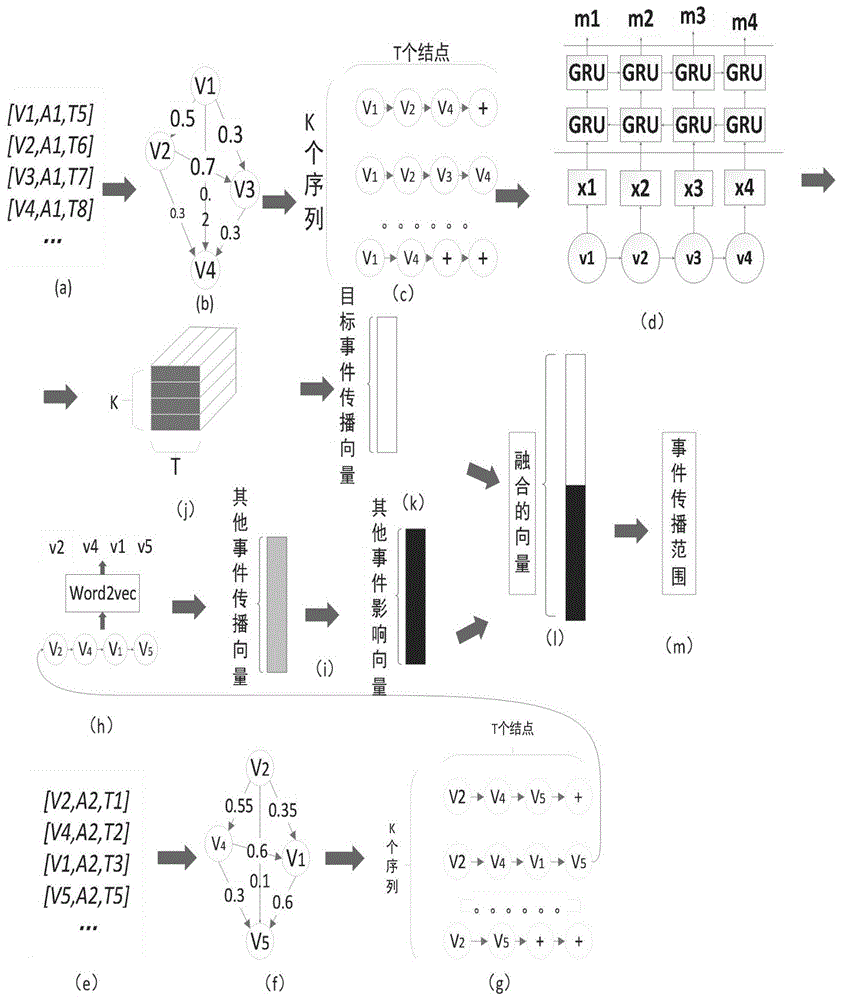
图1为nt-ep方法的框架图;
图2为构造消息传播的加权图;
图3为用户向量不同维度对mse的影响图;
图4为α选取对mse的影响图;
图5为μ值选取对mse的影响图;
图6为k值的选择对mse的影响图;
图7为t值的选择对mse的影响图。
具体实施方式
具体实施方式一:本实施方式一种无拓扑结构的社交消息传播范围预测方法具体过程为:
本发明研究了无拓扑结构条件下消息传播范围预测问题,提出了一种无拓扑结构的消息传播范围预测方法nt-ep。该方法由4部分构成:(1)利用消息传播随时间衰减的特性为每个消息构造一个加权的传播图,在传播图上使用随机游走策略获取多条传播路径,再使用word2vec方法计算每个用户的特征向量;(2)把目标消息的传播路径替换成用户的特征向量序列输入到双向门控制循环神经网络(bi-gru),结合注意力机制计算出目标消息的传播特征向量;(3)考虑到不同消息传播可能存在的相互影响,利用目标消息发生前的其他消息,使用梯度下降方法计算出其他消息的影响向量;(4)将目标消息的传播特征向量和其他消息的影响向量结合在一起,使用多层感知机(mlp)拟合出目标消息的传播范围。
在无拓扑结构的消息传播预测中,没有社交网络的拓扑结构,只有用户的动作日志l={(u,i,t)|u∈v,i∈i,t∈t},其中v为社交网中用户集合,i为社交网中发生的消息集合,t为用户参与消息传播的时间区间,(u,i,t)表示用户u在时间t参与了消息i(例如:用户u对消息i转发、点赞等)。对于给定的目标消息ia,有消息ia从发生时刻it到当前时刻tc的动作日志
nt-ep传播范围预测框架
对于无拓扑结构下社交消息传播预测问题,本发明提出了一种新的社交消息传播范围预测方法nt-ep,其框架如图1所示。
步骤一、根据消息动作日志中的传播时间差为每个消息构造一个加权的传播图,如图1中(a)、(b)所示。传播图边上的数字代表用户之间的影响概率,在传播图构造完成之后,使用随机游走方式从传播图中提取若干条该消息可能的传播路径,如图1中(c)所示;
步骤二、使用word2vec方法计算出消息的传播路径上每个目标用户的初始特征向量;
步骤三、将消息的传播路径上的每个目标用户的初始特征向量送入bi-gru中得到传播路径上每个目标用户的最终向量表示,如图1中(d)所示。
所述bi-gru为双向门控制循环神经网络;
步骤四、基于传播路径上每个目标用户的最终向量表示和注意力机制,计算出每个目标消息的传播特征向量,如图1中(j)所示。
步骤五、在消息传播过程中,不同消息之间会存在相互影响。因此也必须计算目标消息发生前其他消息的可能影响。如图1中(e),(f),(g),(h)所示,使用和目标消息类似的方式,构造加权传播图、随机游走、word2vec计算其他消息参与用户的特征向量,然后构造其他消息的传播向量;
基于其他消息的传播向量,使用梯度下降方法计算出其他消息的影响向量,如图1中(i)所示;
步骤六、将步骤四得到的目标消息的传播特征向量和其他消息的影响向量结合在一起,使用mlp拟合出目标消息的增量传播范围,如图1中(l),(m)所示。
具体实施方式二:本实施方式与具体实施方式一不同的是,所述步骤一中根据消息动作日志中的传播时间差为每个消息构造一个加权的传播图,如图1中(a)、(b)所示。传播图边上的数字代表用户之间的影响概率,在传播图构造完成之后,使用随机游走方式从传播图中提取若干条该消息可能的传播路径,如图1中(c)所示;具体过程为:
传播路径选取
给定的动作日志通常对每个消息的动作按照传播时间排序,如图2中(a)所示。用户v1在时间1接受了消息a1,用户v2在时间2接受了消息a1,……。从给定的动作日志中无法获得消息真实的传播轨迹。因为真实的其情况可能是:用户v3在时间3接受了消息a1可能是因为用户v3和用户v1是朋友,并且用户v3看到了用户v1接受了消息a1,从而影响用户v3也接受了消息a1。用户v3不认识用户v2,v3接受了消息a1从来没有受到用户v2的影响。这样的真实传播轨迹在没有用户社交关系的条件下是无法获得的。
但是根据社交网上消息传播呈指数衰减特性[13],有理由认为当用户v3接受消息a1的时候,用户v2影响的概率大于用户v1影响的概率,因为v2接受消息a1的时间离v3接受消息a1的时间更近。
因此根据两个用户接受消息的时间差来刻画两个用户的影响。假设用户v1和v2接受消息的时间分别为t1和t2,并且t1<t2,则用户v1对v2的影响概率由公式(1)定义:
其中,μ为调整时间差影响的超参数,实验中给出了该参数的选择过程;
计算出每个消息中用户之间的影响概率后,根据影响概率为每个消息构造一个加权图,来模拟该消息的真实传播轨迹,如图2中(b)所示,如果在消息a1中用户v1接受消息a1的时间早于用户v2接受消息a1的时间,则从用户v1引出一条边指向用户v2,边上的权值表示用户v1对用户v2的影响概率,由(1)计算。在得到加权图后,再对加权图归一化,使得每个节点到其他节点的边的概率和为1,如图2中(c)所示;为了模拟真实的传播路径,在归一化的加权图上根据边上的概率进行随机游走,每次游走的开始节点都是接受消息的第一个用户,例如图2中(c)中的v1;
针对每个消息,采样k条路径,并且每条路径的长度为t,即每条路径最多包含t个节点;当游走过程中遇到某条路径长度小于t的时候,在后面添加若干补充位,让每条路径长度都等于t;
在抽取了所有消息的传播路径后,使用词向量方法word2vec计算每个用户的初始特征向量。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是,所述步骤二中使用word2vec方法计算出消息的传播路径上每个目标用户的初始的特征向量;具体过程为:
在抽取了所有消息的传播路径后,将每条传播路径当作一个句子,路径上的每个用户当作句子中的单词,输入到word2vec[23](leq,mikolovt.distributedrepresentationsofsentencesanddocuments[c]//internationalconferenceonmachinelearning.2014:1188-1196.)的skip-gram模型中,得到每个目标用户的初始特征向量;假设用户初始的特征向量的维度为h。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是,所述步骤三中将消息的传播路径上的每个目标用户的初始特征向量送入bi-gru中得到传播路径上每个目标用户的最终向量表示;具体过程为:
因为循环神经网络适合处理时序数据,本发明采用门控循环单元(gru)来捕捉目标消息的传播过程。对于每条传播路径,从前向后处理路径上的每个用户,第i个用户的输入为用户i的初始特征向量xi∈rh,gru对初始特征向量xi进行计算后更新隐藏状态hi=gru(xi,hi-1),其中hi-1∈rh表示gru更新前的隐藏状态,hi∈rh表示gru更新后的隐藏状态。
其中,rh为用户向量的维度;
为了知道消息在传播过程中会被哪些用户影响,使用相同的方法再从后向前处理路径上的每个用户。因此本发明使用的是双向gru(bi-gru),拼接隐藏状态的输出得到对应用户的最终向量表示。
具体通过如下公式对用户向量进行更新,
其中,w和u作为训练期间学习的gru参数,ri为更新门,wr为权重参数,ur为权重参数,br为权重参数,σ为激活函数,ui为重置门,wu为权重参数,uu为权重参数,bu为权重参数,
如图1中(d)所示,每条传播路径经过gru处理后,会得到该路径上每个目标用户的最终向量表示(m1,m2,m3,……)。
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是,所述步骤四中基于传播路径上每个目标用户的最终向量表示和注意力机制,计算出每个目标消息的传播特征向量,如图1中(j)所示。具体过程为:
使用注意力机制合并用户的最终向量表示,得到该传播路径的向量表示,最后对所有传播路径的向量表示累加求和,得到目标消息的传播特征向量h(a),如公式(6)所示:
其中,k代表消息a上抽取的传播路径数,t表示每条传播路径的长度,mki是通过gru得到的第k条路径上第i个用户的最终用户向量,λi为参数。
为了区分同一条路径上不同节点对消息传播向量的作用,使用注意力机制,设t个节点的权重分别为λ1,λ2,…,λt,并且满足
其它步骤及参数与具体实施方式一至四之一相同。
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是,所述步骤五中在消息传播过程中,不同消息之间会存在相互影响。因此也必须计算目标消息发生前其他消息的可能影响。如图1中(e),(f),(g),(h)所示,使用和目标消息类似的方式,构造加权传播图、随机游走、word2vec方法计算其他消息参与用户的特征向量(参照步骤一步骤二),然后构造其他消息的传播向量;
基于其他消息的传播向量,使用梯度下降方法计算出其他消息的影响向量,如图1中(i)所示;具体过程为:
构造加权传播图、随机游走;具体过程为:
传播路径选取
给定的动作日志通常对每个消息的动作按照传播时间排序,如图2中(a)所示。用户v1在时间1接受了消息a1,用户v2在时间2接受了消息a1,……。从给定的动作日志中无法获得消息真实的传播轨迹。因为真实的其情况可能是:用户v3在时间3接受了消息a1可能是因为用户v3和用户v1是朋友,并且用户v3看到了用户v1接受了消息a1,从而影响用户v3也接受了消息a1。用户v3不认识用户v2,v3接受了消息a1从来没有受到用户v2的影响。这样的真实传播轨迹在没有用户社交关系的条件下是无法获得的。
但是根据社交网上消息传播呈指数衰减特性[13],有理由认为当用户v3接受消息a1的时候,用户v2影响的概率大于用户v1影响的概率,因为v2接受消息a1的时间离v3接受消息a1的时间更近。
因此根据两个用户接受消息的时间差来刻画两个用户的影响。假设用户v1和v2接受消息的时间分别为t1和t2,并且t1<t2,则用户v1对v2的影响概率定义为:
其中,μ为调整时间差影响的超参数,实验中给出了该参数的选择过程;
计算出每个消息中用户之间的影响概率后,根据影响概率为每个消息构造一个加权图,来模拟该消息的真实传播轨迹,如图2中(b)所示,如果在消息a1中用户v1接受消息a1的时间早于用户v2接受消息a1的时间,则从用户v1引出一条边指向用户v2,边上的权值表示用户v1对用户v2的影响概率,由(1)计算。在得到加权图后,再对加权图归一化,使得每个节点到其他节点的边的概率和为1,如图2中(c)所示;为了模拟真实的传播路径,在归一化的加权图上根据边上的概率进行随机游走,每次游走的开始节点都是接受消息的第一个用户,例如图2中(c)中的v1;
针对每个消息,采样k条路径,并且每条路径的长度为t,即每条路径最多包含t个节点;当游走过程中遇到某条路径长度小于t的时候,在后面添加若干补充位,让每条路径长度都等于t;
在抽取了所有消息的传播路径后,使用词向量方法word2vec计算每个用户的初始特征向量。
使用word2vec方法计算其他消息参与用户的特征向量;具体过程为:
在抽取了所有消息的传播路径后,将每条传播路径当作一个句子,路径上的每个用户当作句子中的单词,输入到word2vec[23](leq,mikolovt.distributedrepresentationsofsentencesanddocuments[c]//internationalconferenceonmachinelearning.2014:1188-1196.)的skip-gram模型中,得到每个目标用户的初始特征向量;假设用户初始的特征向量的维度为h。
其他消息影响向量
社交网中消息与消息之间存在着不同程度的联系。一个消息的传播可能促进或者抑制另一个消息的传播。例如:国家个人所得方案公布时,短时间内对税率信息查询有促进传播的作用。此外,用户上网浏览消息的时间有限,对于某些消息的关注增加,对其他消息的关注就会降低。
下面介绍其他消息对目标消息的影响能力。该影响能力通过一个影响向量来刻画。
设当前的目标消息为a,a发生时间为ta;如果消息e在消息a之前发生,并且消息e的发生时间与消息a的发生时间距离较近,那么消息e的传播很可能会对消息a的传播产生影响;基于这一思想,获取在ta之前很短的时间段τ内发生的影响消息集合sa={e1,e2,…,em},该集合内每个消息对消息a传播的影响都需要考虑;
假设影响消息集合sa={e1,e2,…,em}中每个消息截止到时间ta时刻的传播范围分别为n1,n2,…,nm,发生时间分别为t1,t2,…,tm,并且满足t1<t2<…<tm<ta,ta-t1<τ;对影响消息集合sa={e1,e2,…,em}中的某个消息ei来说,消息ei的影响能力与传播能力共同作用决定了消息ei在ta时的传播范围ni;
消息ei影响范围ni越大,消息ei的影响能力越强。这是因为在某段时间内若消息ei成为热点消息,在短时间内有巨大的浏览量,用户对当前目标消息的浏览量会有所减少。根据这一思想,使用d维向量pi表示消息ei的传播能力,使用d维向量qi表示消息ei的影响向量,构造下面的目标函数:
式中,m为sa中的消息数量;
消息ei的传播向量pi来自于参与消息ei的用户传播能力,因此消息ei的传播向量pi表示为:
其中,xj是使用word2vec(词向量)的skip-gram(跳字模型)模型从传播路径上得到的用户向量,j为参与消息传播的用户数量;
因为消息ei的传播范围为ni,所以有ni个不同的用户向量xj;对于消息ei的影响向量qi,本发明使用梯度下降算法求解,使公式(2)的目标函数最小化;
在得到影响消息集合sa={e1,e2,…,em}中每个消息的影响向量{q1,q2,…,qm}后,使用如下方式计算整个消息集合sa对当前目标消息a的影响向量qsa;
式中,qj为影响消息集合的影响向量,tj为影响消息集合中每个消息发生的初始时间。
其它步骤及参数与具体实施方式一至五之一相同。
具体实施方式七:本实施方式与具体实施方式一至六之一不同的是,所述对于消息ei的影响向量qi,本发明使用梯度下降算法求解,使公式(2)的目标函数最小化,具体过程为:具体算法如算法1所示。
将其他消息的传播向量pi,i=1.2….,m;其他消息当前传播范围ni,i=1.2….,m;学习率
第一步初始化qi,i=1.2….,m,然后多轮重复迭代
式中,δg为中间变量;
其它步骤及参数与具体实施方式一至六之一相同。
具体实施方式八:本实施方式与具体实施方式一至七之一不同的是,所述步骤六中将步骤四得到的目标消息的传播特征向量和其他消息的影响向量结合在一起,使用mlp拟合出目标消息的传播范围,如图1中(l),(m)所示;具体过程为:
目标消息a的传播范围依赖于目标消息a的传播向量h(a)和其他消息的影响向量qsa,将目标消息a的传播向量h(a)和其他消息的影响向量qsa融合为一条向量l(a),表达式如下:
l(a)=h(a)+αqsa(7)
其中,α为其他消息影响向量的权重,实验部分给出了参数α的选择过程;
将融合后的向量l(a)作为多层感知机的输入,输出预测的目标消息a的传播范围f(a)=mlp(l(a));
其中mlp为一个多层感知机,f(a)为目标消息a的传播范围。
其它步骤及参数与具体实施方式一至七之一相同。
采用以下实施例验证本发明的有益效果:
实施例一:
实验结果及分析
实验数据
本发明中使用两套无拓扑结构的传播数据进行实验并对结果评估。数据描述如表1所示。
微博[24]:基于用户关系的信息分享、传播的社交媒体。从论文中提供的数据中选取在2012.9.28到2012.10.29之间发生的1280个消息的动作日志。截取的数据中包含261839个用户,1280个消息,以及933683条传播记录。
flixster[12]:是一个电影社交网站,可以让用户分享电影的评分,讨论新的电影。使用1000个消息的动作日志。其中包含109816个用户和581202条传播记录。
表1实验数据描述
实验中预测消息传播范围时通过调整时间长度t和δt来选择预测的时间区间。t表示消息从发生开始到当前时刻所经过的时间,也就是消息已经发生了多久。δt表示在t时间之后的时间长度。实验中选择t与δt的大小分别为12小时、24小时、36小时来对消息的传播范围进行预测。实验中需要进行其他消息影响向量和用户特征向量占用空间存储。实验中将数据按7:1:2的比例分为训练集、验证集、测试集。数据集中每个消息的全部动作日志只出现在训练集、测试集、验证集中的一个。在训练集中训练模型,在验证集中调整超参数,在测试集中测试方法的性能。
评估指标
本发明中使用均方误差(mse)来评估传播范围预测效果。这是回归任务中常见的评估指标。它是由预测值与真实值差的平方和求平均得到,定义如下:
其中pi为实际传播用户数,
本发明中使用精确率、召回率、f1-score来评估消息热点预测效果。在热点消息预测时,只进行采样12小时的传播并预测消息的最终传播范围。实验中设置一个阈值,超过阈值会被认为是热点消息。实验中选择的阈值为1000。具体的定义如下:
tp(真正例):预测传播范围大于阈值,并且实际传播范围大于阈值的消息数。
fn(假负例):预测传播范围大于阈值,但实际传播范围小于阈值的消息数。
fp(假正例):预测传播范围小于阈值,但实际传播范围大于阈值的消息数。
tn(真负例):预测传播范围小于阈值,并且实际传播范围小于阈值的消息数。
精确率p(precession):在所有被预测为热点的消息中,实际为热点的消息所占的百分比,如下式所示。
召回率r(recall):在所有实际为热点的消息中,被预测为热点的消息所占的百分比,如下式所示。
f1分数(f1-score):统计学中同时兼顾精确率和召回率的一种指标,如下式所示。
对比方法
embeddingic[22]:一种嵌入版本的独立级联模型,充分考虑用户之间的相互影响,把用户嵌入到隐藏投影空间中,借助em算法求发送方和接收方的嵌入向量,推测传播概率。根据计算出的传播概率计算最终消息传播范围。
deepcas[7]:一种消息传播范围预测方法。通过随机采样获得消息扩散的路径,使用gru网络将路径转换为路径的表达向量。最后通过注意力机制来预测消息的传播范围。
nt-ep-t:nt-ep的一种变体。通过时间衰减游走采样传播路径,不利用消息的相互影响。
nt-ep-r:nt-ep的一种变体。不使用时间衰减游走(使用传统的随机游走)采样传播路径,但是利用消息的相互影响。
实验中,传播序列的选择算法使用c语言编写,在vs环境下编译运行,对比算法也使用c语言编写。
nt-ep中神经网络部分使用python语言和tensorflow框架编写,在anaconda3环境下编译运行。评价标准也使用python语言进行处理。所使用的台式机环境为intel(r)corei7-7700k4.2ghzcpu,16gbram,操作系统为window10。
参数选择
在验证集中调整模型的超参数,包括用户向量维度d,其他消息影响向量的权重α,时间差的影响参数μ,学习率λ,消息抽取的路径数k,路径长度t等。实验中设置算法1中计算消息影响向量的学习率λ为0.0005。
参数选择均使用微博数据进行实验,采样12小时传播序列,预测未来12小时传播范围。先随机固定其他参数来考察用户向量维度d对mse的影响,实验结果如图3所示。随着维度d的增加,mse的值在逐渐减小,表明预测效果越来越好。但当维度超过50时,预测效果改善并不明显。为了平衡预测效果和运行时间,本发明后面的所有实验都采用用户向量维度d=50。
其他参数的选取也采用上述类似的处理方式。在选取其他消息影响向量的权重α时,固定用户向量维度d=50。图4为α选取过程,选取α时在0到1之间每0.2取值,其中α=0.8时mse的取值最优,因此本发明后面的所有实验都采用α=0.8。图5给出了参数μ的选择过程,先固定用户向量维度d=50和α=0.8,其他参数随机选择,观察参数μ对mse的影响,在μ=1时mse值最小。因此后续实验选择μ=1时作为时间衰减游走采样的参数值。传播路径数量k与传播路径长度t的选择过程如图6和图7所示,因此后续实验中固定k=200和t=10作为传播路径数量和传播路径长度。
实验结果
表2微博数据传播范围预测结果
表3flixster数据集传播范围预测结果
表4微博数据精确率、召回率、f1-score结果
不同方法对传播范围的预测效果如表2和表3所示。其中表2为微博数据上的实验结果,实验中分别采样12小时、24小时、36小时,然后对未来12小时、24小时、36小时的传播范围预测。表3为flixster数据集的实验结果,实验中分别采样10天、20天、30天,然后对未来10天、20天、30的传播范围预测。从表2和表3中可以看出,本发明方法nt-ep、及其变体nt-ep-r和nt-ep-t预测效果均优于对比方法deepcas和embeddingic。表3中的实验结果好于表2中的结果,其原因在于微博数据比flixster数据的消息数更多,每个消息的传播范围更广,能让各种模型学习的更充分。
embedding-ic方法所在行只有一个实验结果,因为embedding-ic方法和时间长度δt无关。embedding-ic把所有用户映射到一个向量空间中,通过距离计算用户之间的影响概率。该方法考虑所有用户对当前用户的影响,导致许多无关的用户也进行计算,但实际上激活时间上相近的用户才可能产生影响,所以embedding-ic方法很容易导致过拟合,预测效果较差。deepcas使用传统随机游走采样传播路径,没有考虑时间差对传播消息的影响,而且deepcas也没有考虑消息之间的相互影响,因此预测效果并不理想。
方法变体nt-ep-t通过时间衰减游走采样传播路径,不利用消息的相互影响预测时间传播范围。从表2和表3可以看出,nt-ep-t优于deepcas,说明时间差对消息的传播起重要作用。方法变体nt-ep-r利用消息的相互影响,但不使用时间衰减游走采样传播路径。从表2和3可以看出,nt-ep-t优于deepcas,说明消息之间确实存在相互影响。nt-ep方法同时考虑消息的相互影响与时间差对消息传播的作用,预测效果明显优于deepcas、nt-ep-t和nt-ep-r。
为了进一步验证本发明方法的有效性,也对热点消息进行了预测,实验结果如表4所示。实验中使用微博数据采样12小时,对未来12小时、24小时、36小时是否会成为热点消息进行预测,在实验中设置的阈值为1000。如果传播范围预测值大于阈值,则预测为热点消息。实验结果再次表明本发明方法nt-ep优于现有方法,也再次证明了消息之间的相互影响确实存在以及消息传播具有时间衰减等特性。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!