一种投影对焦方法及投影对焦装置与流程
本申请涉及投影技术领域,具体涉及一种投影对焦方法及投影对焦装置。
背景技术
目前对焦大多采用测距法和清晰度对比法,测距法是通过传感器获得投影机与投影平面的距离信息,然后根据预先所存储的距离与最佳对焦位置对照表,直接计算得出镜头所需移动到最佳对焦位置的距离,然后驱动电机带动镜头移动,其优点是速度较快,所需时间只有电机移动到最佳位置的时间,但精度不够,且无法解决投影机热失焦的问题,在投影热失焦时,镜头的位置并没有改变,但所对应的最佳对焦位置因为光学仪器的膨胀而发生了位移,此时便失去了能够参考的距离信息,导致测距法失效。
清晰度对比法的依据是图像的清晰度在镜头移动范围内的分布具有单峰性,通过爬山搜索的方法可以控制电机,让镜头位置逼近最佳对焦位置,要达到比较理想的对焦位置,镜头会在最佳对焦位置附近来回震荡几次,由于清晰度曲线存在局部鞍点,若电机步长过小,则镜头容易陷入鞍点中,导致对焦失败,若步长过大,则会增大镜头在最佳对焦位置来回震荡的次数,减慢对焦速度;因此,一种比较高效的做法是动态地改变电机移动的步长,让镜头在距离最佳对焦位置较远时,电机大步长移动;当镜头在距离最佳对焦位置较近时,减小电机步长,然而步长的变化参数依然需要人根据经验设置,且泛化性远远不够。
技术实现要素:
本申请提供一种投影对焦方法及投影对焦装置,能够利用强化学习模型对电机进行控制,减少投影装置到达最佳对焦位置的时间。
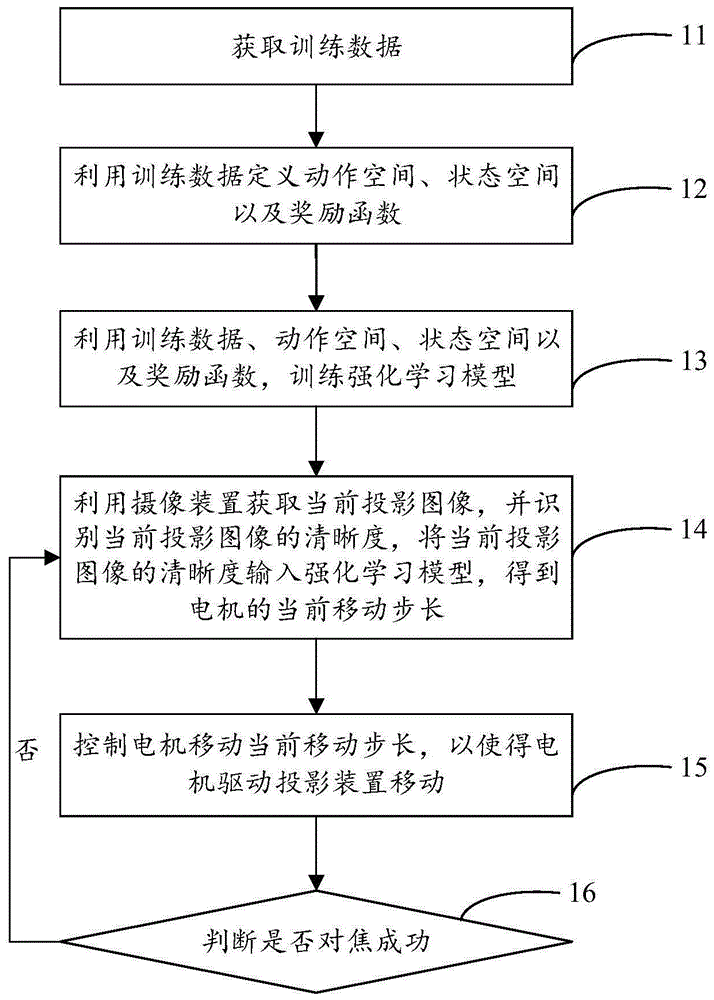
为解决上述技术问题,本申请采用的技术方案是:提供一种投影对焦方法,该方法包括:获取训练数据,训练数据包括多张投影图像的清晰度;利用训练数据定义动作空间、状态空间以及奖励函数,其中,动作空间包括当前时间段电机的移动步长,状态空间包括清晰度的梯度与当前时间段的上一时间段的动作,奖励函数用于对所执行的动作进行评估;利用训练数据、动作空间、状态空间以及奖励函数,训练强化学习模型,其中,强化学习模型的输入包括投影图像的清晰度,强化学习模型的输出包括电机的移动步长;利用摄像装置获取当前投影图像,并识别当前投影图像的清晰度,将当前投影图像的清晰度输入强化学习模型,得到电机的当前移动步长;控制电机移动当前移动步长,以使得电机驱动投影装置移动;判断是否对焦成功,若对焦未成功,则返回利用摄像装置获取当前投影图像,并识别当前投影图像的清晰度,将当前投影图像的清晰度输入强化学习模型,得到电机的当前移动步长的步骤,直至对焦成功。
为解决上述技术问题,本申请采用的技术方案是:提供一种投影对焦装置,该投影对焦装置包括互相连接的存储器和处理器,其中,存储器用于存储计算机程序,计算机程序在被处理器执行时,用于实现上述的投影对焦方法。
通过上述方案,本申请的有益效果是:先获取训练数据,然后基于收集的训练数据定义动作空间与状态空间,并设计奖励函数;再基于所收集的训练数据、所定义的动作空间、状态空间以及奖励函数,构建强化学习模型,然后进行训练得到强化学习模型;在实际使用时,可将当前投影图像的清晰度输入该强化学习模型中,从而得到当前电机需要移动的步长,电机带动投影装置移动,能够有效地减少投影装置移动的时间,从而快速达到对焦效果。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。其中:
图1是本申请提供的投影对焦方法一实施例的流程示意图;
图2是本申请提供的投影对焦方法另一实施例的流程示意图;
图3是本申请提供的投影对焦装置一实施例的结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性的劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
强化学习可以用来解决决策型的问题,典型的强化学习模型由两部分组成,分别是智能体(Agent)和环境(Environment),智能体由策略函数和值函数组成,环境包括奖励函数、状态空间、动作空间以及状态转移函数;值函数评估当前状态下,动作空间中所有动作的值的大小;策略函数根据值函数所评估的值选择执行动作;奖励函数对所执行的动作的好坏进行评估,然后反馈给智能体;状态转移函数根据当前状态和动作,让智能体进入下一状态;强化学习的目标是让智能体在与环境交互的过程中完成某项任务,使得智能体在环境中得到的奖励值的和最大化。
请参阅图1,图1是本申请提供的投影对焦方法一实施例的流程示意图,该方法包括:
步骤11:获取训练数据。
训练数据包括多张投影图像的清晰度,可利用摄像装置拍摄多张投影设备投影出来的投影图像或者从图像数据库中获取多张投影图像,然后使用计算图像清晰度的方法计算这些投影图像的清晰度,得到训练数据。
步骤12:利用训练数据定义动作空间、状态空间以及奖励函数。
在获取到训练数据之后,可对训练数据进行处理,定义出动作空间、状态空间以及奖励函数,该动作空间包括当前时间段电机的移动步长,状态空间包括清晰度的梯度与当前时间段的上一时间段的动作,奖励函数用于对所执行的动作进行评估,并可将评估结果反馈至智能体。
步骤13:利用训练数据、动作空间、状态空间以及奖励函数,训练强化学习模型。
在定义出动作空间、状态空间以及奖励函数之后,可利用训练数据进行强化学习模型的训练,强化学习模型的训练可使用迭代的方法,每一轮训练都会让智能体从一个初始化位置开始,然后根据策略函数输出不同的动作,从而改变智能体在环境中的位置,得到训练好的强化学习模型,该强化学习模型的输入包括投影图像的清晰度,强化学习模型的输出包括电机的移动步长。
可以理解的,步骤11-13可在实际应用开始之前进行,即为训练模型阶段,在实际应用时,可直接利用步骤11-13得到的强化学习模型,执行步骤14-16。
步骤14:利用摄像装置获取当前投影图像,并识别当前投影图像的清晰度,将当前投影图像的清晰度输入强化学习模型,得到电机的当前移动步长。
在训练好强化学习模型之后,可进入实际调整阶段,即调整电机运行的阶段,使得电机能够带动投影装置移动,从而实现对焦。该电机可以为步进电机、伺服电机等,摄像装置可以为摄像头,为了不带来摄像头造成的误差,摄像头可固定设置于投影机本体上,摄像头不进行移动。电机驱动投影装置移动,具体地,驱动投影装置中的投影镜头移动,例如,电机控制投影镜头伸出和缩进,以使投影装置移动,从而实现调焦;作为另一种实施例,电机驱动投影装置移动,也可以是驱动投影装置中的支脚移动,例如,电机控制支脚伸长和缩进,以使投影装置移动实现调焦。
进一步地,可控制摄像装置进行拍摄,得到当前投影图像,再利用计算图像清晰度的方法计算该当前投影图像的清晰度,然后利用将当前投影图像的清晰度输入训练好的强化学习模型中,得到当前电机需要移动的步长。
步骤15:控制电机移动当前移动步长,以使得电机驱动投影装置移动。
在得到当前移动步长后,可输出控制指令至电机,以控制电机移动该当前移动步长,或者可将该当前移动步长输入至电机中,使得电机移动,由于电机与投影装置中的投影镜头或者支脚连接,电机带动投影装置中的投影镜头或者支脚移动。在一种实施例中,电机驱动投影镜头前进或者后退适当的步长,以使投影镜头位于最佳的对焦位置。在另一种实施例中,电机驱动投影装置的支脚伸长或者缩短适当的步长,以使支脚的高度位于最佳的对焦位置。
步骤16:判断是否对焦成功。
在投影装置移动了之后,可判断投影装置的当前位置是否为最佳对焦位置;若投影装置当前到达最佳对焦位置,则表明对焦成功,可以进行清晰地拍摄;若投影装置当前未到达最佳对焦位置,与最佳对焦位置之间有距离,则表明对焦未成功,此时可返回利用摄像装置获取当前投影图像,并识别当前投影图像的清晰度,将当前投影图像的清晰度输入强化学习模型,得到电机的当前移动步长的步骤,直至对焦成功。
本实施例提供了一种基于强化学习的投影自动对焦方法,可利用摄像装置来捕获投影机的投影图像,基于收集的训练数据定义动作空间与状态空间,并设计奖励函数;再基于所收集的训练数据、所定义的动作空间、状态空间以及奖励函数,构建强化学习模型;然后训练强化学习模型,生成最优对焦策略,使用训练好的强化学习模型进行对焦,将当前清晰度输入强化学习模型中,得到当前电机需要移动的步长,从而使得电机带动投影装置移动,能够基于清晰度对比对焦法建立的强化学习模型,训练控制电机的最优策略,实现动态调整电机的移动步长,减少投影装置到达最佳对焦位置的时间,实现快速对焦。
请参阅图2,图2是本申请提供的投影对焦方法另一实施例的流程示意图,该方法包括:
步骤21:控制电机在预设移动区间内以预设步长移动,以使得电机带动投影装置移动。
可先将投影机放置好,控制投影机投影出图像,然后控制电机从预设移动区间的端点移动至另一个端点。
步骤22:控制摄像装置在电机移动预设步长后进行拍摄,得到投影图像,并采用梯度法计算投影图像的清晰度。
在电机每移动一预设步长后,可对投影画面进行拍摄,得到投影图像,然后可使用梯度法对获取到的投影图像进行处理,得到该投影图像的清晰度,并进行存储,从而得到清晰度数组,将其作为训练强化学习模型的数据集。
可选地,为了增加强化学习模型的泛化能力,可将投影机摆放在距离投影平面不同的位置,采集多组清晰度数组作为训练数据。
步骤23:利用训练数据定义动作空间、状态空间以及奖励函数。
所得到的清晰度数组的长度即为预设移动区间的长度,可根据预设移动区间的长度确定电机单次移动的最大步长;例如,清晰度数组的长度为N,则定义最大步长为N/4。
由于电机可以正反转,动作空间可由一个包含两个元素的向量来表示,即动作空间记作a,a∈[d,n],d为电机的转动方向的标识值,d=-1,1,n为电机的移动步长,n=1,2,…,Lmax,Lmax为最大步长,其中,d=-1表示电机反转,d=1表示电机正转;当最大步长为N/4时,输出的动作一共有N/2个,即动作空间为离散且长度为N/2的向量。
强化学习模型的状态需满足马尔科夫性,即环境的响应仅取决于当前的状态和动作,状态的定义应该尽可能充分描述智能体在强化学习模型中的位置,具有丰富性和唯一性,可定义清晰度的梯度和上一时间段的动作为当前时间段的状态,即状态空间包括清晰度的梯度与上一时间段电机的移动步长以及上一时间段电机的转动方向的标识值,状态空间记作s,s∈[g,d,n],g为清晰度的梯度,且St为t时刻投影图像的清晰度,St-1为t-1时刻投影图像的清晰度,n为t-1时刻电机的移动步长,由于清晰度的梯度是连续的,因而理论上状态空间为无穷大。
由基于清晰度评价的对焦方法可知:当投影装置靠近最佳对焦位置时,清晰度的梯度逐渐变小,步长也逐渐减小,基于此特性,设计的奖励函数为:
其中,α与β为加权系数,α与β的取值与训练数据相关,k为当前执行动作的次数,其目的是让强化学习策略尽可能少地被执行,提高对焦速度;具体地,通过采集的数据不断进行测试与学习,根据测试结果对加权系数α与β进行评估。
步骤24:利用动作空间、状态空间以及奖励函数,构建强化学习模型网络。
强化学习模型中的环境模型可以由所储存的清晰度数组表示,由于投影装置所处位置的清晰度和执行动作后的新位置的清晰度都可以从储存的清晰度数组中读取,能够避免实际控制电机时,计算清晰度所花费的时间,加快模型训练。
智能体采用经典的DQN(Deep Q-Learning,深度Q学习)算法,采用神经网络算法建立将状态空间映射到动作空间的策略函数,然后采用Q-learning算法和反向传播算法更新神经网络的参数。
步骤25:使用训练数据对强化学习模型网络进行训练,得到强化学习模型。
对建立好的强化学习模型网络进行训练,每一轮训练的终止条件为强化学习模型中的智能体到达最佳对焦位置和/或智能体的决策次数大于预设次数。
每经过预设轮训练后,利用测试数据对训练得到的当前强化学习模型进行测试,得到测试数据对应的奖励值;然后对测试数据对应的奖励值进行求和,得到总奖励值,并存储总奖励值;继续进行训练,直至总奖励值收敛,即训练的终止条件为:总奖励值不再增长,此时可结束训练,得到强化学习模型。
步骤26:利用摄像装置获取当前投影图像,并识别当前投影图像的清晰度,将当前投影图像的清晰度输入强化学习模型,得到电机的当前移动步长。
步骤27:控制电机移动当前移动步长,以使得电机驱动投影装置移动。
步骤28:判断是否对焦成功。
步骤26-28与上述实施例中步骤14-16相同,在此不再赘述。
本实施例先利用摄像装置获取训练数据,所定义的动作空间包括电机的转动方向的标识值与电机的移动步长,所定义的状态空间包括清晰度的梯度与上一时间段的动作,并利用电机的转动方向的标识值、清晰度的梯度、电机的移动步长以及执行动作的次数来设计奖励函数;然后构建强化学习模型网络,并进行训练得到强化学习模型,通过该强化学习模型可实时调整电机的移动步长,能够有效地减少投影装置移动的时间,实现快速对焦。
参阅图3,图3是本申请提供的投影对焦装置一实施例的结构示意图,投影对焦装置30包括互相连接的存储器31和处理器32,存储器31用于存储计算机程序,计算机程序在被处理器32执行时,用于实现上述实施例中的投影对焦方法。
以上仅为本申请的实施例,并非因此限制本申请的专利范围,凡是利用本申请说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本申请的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!