多信道数据打包器和多信道数据解包器的制作方法
本文公开的主题涉及多信道(channel)数据系统。更具体地说,本文公开的主题涉及能够并行压缩和解压缩多信道比特流的系统。
背景技术:
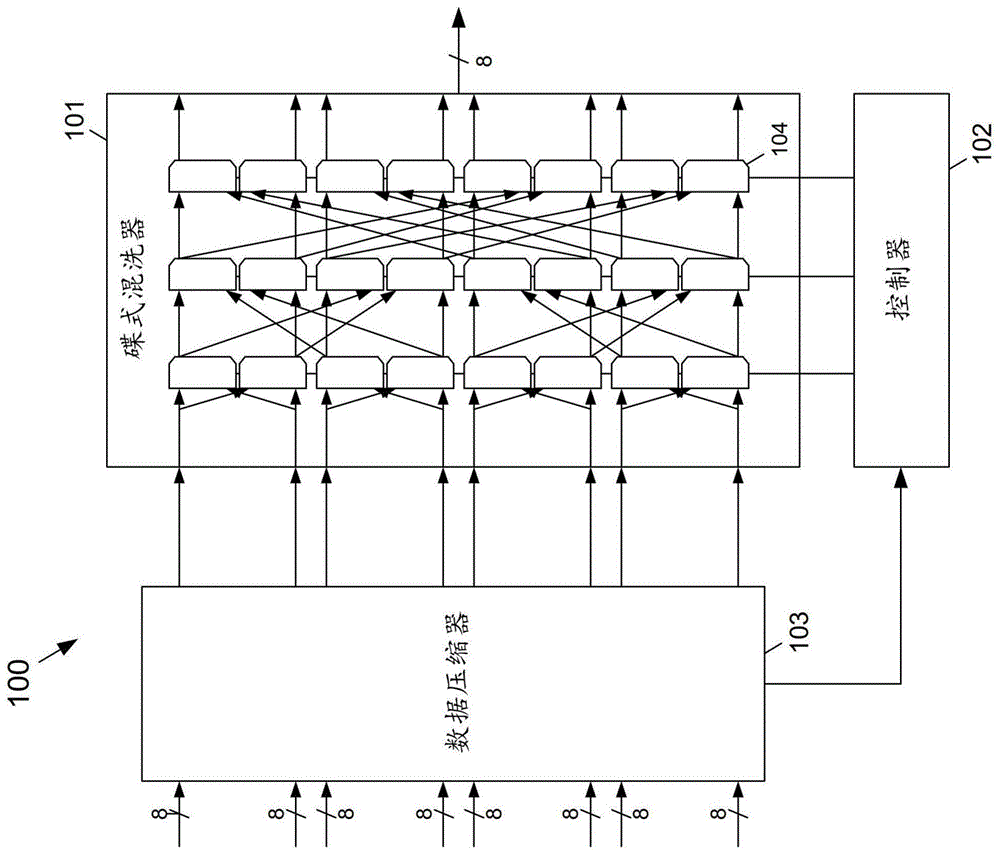
:神经推理加速器硬件可以以并行方式(例如,16个并发通道(lane))存储和检索数据,诸如从激活函数输出的权重和特征图。存储和检索的数据可能有许多零,可以并且应该被压缩以减少动态随机访问存储器(dram)和静态随机访问存储器(sram)中的存储装置的读写功率和大小。已知的压缩和解压缩数据算法(例如,霍夫曼、基于字典的、zip、游程长度编码、golombrice等)通常是串行过程,并且一次只能处理一个数据比特流。技术实现要素:示例实施例提供了一种多信道数据打包器,其可以包括多个两输入复用器以及控制器。多个两输入复用器可以布置在2n行和n列中,其中n是大于1的整数,其中,第一列中的每个复用器的每个输入可以接收2n个信道的比特流中的相应比特流,其中,所述相应比特流可以包括基于所述相应比特流中的数据的比特流长度,并且其中最后一列中的输出2n个信道的打包比特流的复用器可以各自具有相同的比特流长度。控制器可以控制所述多个两输入复用器,以使得最后一列中的复用器输出2n个信道的打包比特流,每个打包比特流具有相同的比特流长度。在一个实施例中,n=3,并且所述多个复用器可以布置在8行和3列中,第一列中的复用器的输出可以耦合到同一行中的第二列中的复用器的输入,并且第二列中的复用器的输出可以耦合到同一行中的第三列中的复用器的输入,一列中的一个复用器可以与同一列中的另一个复用器组合,以形成一列中的多对复用器中的一对复用器,所述一列中的每对复用器可以对应于另一列中的一对复用器,第一列中的一对复用器的第一复用器和第二复用器的输出可以进一步耦合到第二列中的相应的一对复用器的第一复用器和第二复用器的相应输入,并且第二列中相应的一对复用器的第一复用器和第二复用器的输出可以进一步耦合到第三列中的相应的一对复用器的第一复用器和第二复用器的相应输入。在另一个实施例中,由第一列中的复用器接收的每个比特流可以包括零比特掩码部分和非零数据部分。比特流的零比特掩码部分可以指示比特流中的零值的位置。示例实施例提供了一种多信道数据打包器,其可以包括可以布置在8行和3列中的多个两输入复用器。第一列中的复用器的输出可以耦合到同一行中的第二列中的复用器的输入,并且第二列中的复用器的输出可以耦合至同一行中的第三列中的复用器的输入。一列中的一个复用器可以与所述一列中的另一个复用器组合,以形成所述一列中的多对复用器中的一对复用器。所述一列中的每对复用器可以对应于另一列中的一对复用器。第一列中的一对复用器的第一复用器和第二复用器的输出可以进一步耦合到第二列中的相应的一对复用器的第一复用器和第二复用器的相应输入,并且第二列中的相应的一对复用器的第一复用器和第二复用器的输出可以进一步耦合到第三列中的相应的一对复用器的第一复用器和第二复用器的相应输入。在一个实施例中,第一列的每个复用器的每个输入可以接收8个信道的比特流中的相应比特流,所述相应比特流可以包括基于所述相应比特流中的数据的比特流长度,并且第三列中的复用器可以输出8个信道的打包比特流,其中每个打包比特流具有相同的比特流长度。在另一实施例中,由第一列中的复用器接收的每个比特流可以包括零比特掩码部分和非零数据部分,其中比特流的零比特掩码部分指示比特流中的零值的位置。示例实施例提供了多信道数据解包器,其可以包括多个两输入复用器以及控制器。多个两输入复用器可以布置在2n行和n列中,其中n是大于1的整数,其中第一列中的每个复用器的每个输入可以接收2n个信道的打包比特流中的相应打包比特流,其中所述相应打包比特流可以包括相同的比特流长度,并且其中最后一列中的复用器可以输出2n个信道的解包比特流,每个解包比特流具有与比特流的解包数据相对应的比特流长度。控制器可以控制多个两输入复用器,以使得最后一列的复用器输出2n个信道的解包比特流,其中每个解包比特流具有与每个比特流的解包数据相对应的比特流长度。在一个实施例中,由第一列中的复用器接收的每个打包比特流可以包括零比特掩码部分和非零数据部分。附图说明图1a描绘了根据本文公开的主题的多信道数据打包器的一个示例实施例的框图;图1b描绘了根据本文公开的主题的蝶式混洗器(butterflyshuffler)复用器的示例实施例的框图;图1c描绘了根据本文公开的主题的蝶式混洗器的一个示例实施例的框图;图1d描绘了根据本文公开的主题的蝶式混洗器的另一示例实施例的框图;图2a至图2c概念性地描绘了根据本文所公开的主题,不同比特流长度的八个示例比特流被递归打包以变成各自具有相等的比特流长度的八个比特流;图3a描绘了根据本文公开的主题的数据打包的另一示例,该数据打包包括原始8比特数据的示例块,诸如8×8的权重集合;图3b描绘了根据本文公开的主题的蝶式混洗器的第一列的多信道输出;图3c描绘了根据本文公开的主题的蝶式混洗器的第二列的多信道输出;图3d描绘了根据本文公开的主题的蝶式混洗器的第三列的多信道输出;图4描绘了根据本文公开的主题的示例数据解包器的框图;图5描绘了根据本文公开的主题的包括流长度部分和压缩数据部分的数据块;图6a描绘了根据本文公开的主题,提供对打包数据的随机访问的示例实施例的零崩溃(zero-collapsing)数据压缩器和打包器电路的框图;图6b描绘了具有对由图6a的零崩溃数据压缩器和打包器电路提供的打包数据的随机访问的示例数据压缩;图6c描绘了根据本文公开的主题的使用零崩溃移位器的零值移除器的示例实施例的框图;图6d描绘了根据本文公开的主题的使用零崩溃移位器的零值移除器的示例替代实施例的框图;图6e描绘了根据本文公开的主题的零崩溃移位器的示例实施例,其中所有信道都接收非零值;图6f描绘了根据本文公开的主题的零崩溃移位器的示例实施例,其中,一个信道(信道12)接收零值输入;图6g至图6j分别描绘了根据本文公开的主题的零崩溃频移位器的示例实施例,其用于其中信道逐渐接收更多零值的另外的更高级的情况;图7描绘了根据本文公开的主题的示例电路的框图,所述示例电路可以用于从比特流中移除零值;图8a和图8b分别示出了根据本文公开的主题的未压缩数据和具有对由图6a的零崩溃数据压缩器和打包器电路提供的打包数据的随机访问的数据压缩的另一示例;图9描绘了根据本文公开的主题的解包器和解压缩器电路的示例实施例的框图;图10a至图10b描绘了根据本文所公开的主题的,由图6a的零崩溃数据压缩器和打包器电路以及图9的解包和解压缩器电路提供的打包数据的随机访问能力的示例细节;图10c是根据本文公开的主题的,使用由图6a的零崩溃数据压缩器和打包器电路提供的打包数据的随机访问能力来访问图10a和图10b中描绘的压缩数据的方法的示例实施例的流程图;图10d描绘了根据本文公开的主题的从像素阵列读出窗口的图10c的方法;图11a描绘了根据本文公开的主题的,利用蝶式混洗器来均匀化稀疏数据的稀疏数据处理系统的实施例的示例框图;图11b描绘了根据本文公开的主题的蝶式数据路径复用器的示例实施例;图11c描绘了根据本文公开的主题的16信道蝶式数据路径的示例实施例;图11d描绘了根据本文公开的主题的,具有控制数据路径置换(permutation)的伪随机发生器的16信道蝶式数据路径的示例实施例;图12a描绘了根据本文公开的主题的提供对打包数据的随机访问的示例实施例的信道并行压缩器电路的框图;图12b描绘了具有由图12a的信道并行压缩器电路提供的对打包数据的随机访问的示例的信道并行的数据压缩;图13a至图13c概念性地描绘了根据本文所公开的主题的,具有不同字节流长度的八个示例字节流被递归打包以成为各自具有相等的字节流长度的八个字节流;图14描绘了根据本文公开的主题的解包器和解压缩器电路的示例实施例的框图;图15示出了对于常见示例卷积神经网络的三个不同压缩粒度的压缩比(compressionratio)的曲线图;图16a描绘了根据本文公开的主题的用于8比特数据单元(即字节)的逐信道转置技术;图16b描绘了根据本文公开的主题的用于16比特数据的转置技术;图17描绘了根据本文公开的主题的,可以提供半字节压缩粒度的压缩电路的示例实施例的框图;图18描绘了根据本文公开的主题的可以与图17的压缩电路一起使用的解压缩电路的示例实施例的框图;图19描绘了根据本文公开的主题的,可以提供半字节压缩粒度并且可以用于通过总线发送压缩数据的压缩电路的示例实施例的框图;图20描绘了根据本文公开的主题的,可以提供半字节压缩粒度并且可以用于通过总线接收压缩数据解压缩电路的示例实施例的框图;和图21描绘了根据本文公开的主题的包括使用蝶式混洗器的数据压缩器和/或数据解压缩器的电子设备。具体实施方式在下面的详细描述中,阐述了许多具体细节以便提供对本公开的透彻理解。然而,本领域技术人员将理解,可以在没有这些具体细节的情况下实践所公开的方面。在其他情况下,没有详细描述公知的方法、过程、组件和电路,以免使本文公开的主题不清楚。在整个说明书中对“一个实施例”或“一实施例”的引用是指结合该实施例描述的特定特征、结构或特性可以包括在本文公开的至少一个实施例中。因此,在整个说明书中各处出现的短语“在一个实施例中”或“在一实施例中”或“根据一个实施例”(或具有相似含义的其他短语)可能不一定全都指同一实施例。此外,在一个或多个实施例中,可以以任何合适的方式组合特定的特征、结构或特性。就这一点而言,如本文所用,词语“示例的”是指“用作示例、实例或说明”。本文中描述为“示例的”的任何实施例均不应被解释为一定比其他实施例更优选或有利。而且,取决于本文讨论的上下文,单数术语可以包括对应的复数形式,并且复数术语可以包括对应的单数形式。类似地,连字符的术语(例如,“二-维”、“预-定”、“像素-特定的”等)可以偶尔与对应的非连字符的版本(例如,“二维”,“预定”,“像素特定的”等)互换使用,并且大写条目(例如“counterclock”,“rowselect”,“pixout”等)可以与相应的非大写版本(例如,“counterclock”,“rowselect”,“pixout”等)互换使用。这种偶尔的互换使用不应被认为是相互不一致的。还应注意,本文中示出和讨论的各种附图(包括组件图)仅用于说明目的,并且未按比例绘制。同样,各种波形和时序图仅出于说明目的。例如,为了清楚起见,一些元件的尺寸可能相对于其他元件被放大。此外,如果认为适当,则在附图之间重复参考标号以指示相应和/或类似的元件。在本文使用的术语仅出于描述一些示例实施例的目的,而不旨在限制所要求保护的主题。如本文所使用的,单数形式“一”,“一个”和“该”也意图包括复数形式,除非上下文另外明确指出。还将理解的是,当在本说明书中使用时,术语“包括”和/或“包含”指定了所述特征、整数、步骤、操作、元件和/或组件的存在,但并不排除一个或多个其他特征、整数、步骤、操作、元件、组件和/或其组的存在或添加。如本文中所使用的,术语“第一”,“第二”等被用作它们之后的名词的标签,并且除非明确定义,否则不暗示任何类型的排序(例如,空间、时间、逻辑等)。此外,可以在两个或更多个附图上使用相同的附图标记来指代具有相同或相似功能的部件、组件、块、电路、单元或模块。但是,这种用法仅是为了说明简便和易于讨论;这并不意味着这些组件或单元的构造或架构细节在所有实施例中都是相同的,或者这种共同参考的部件/模块是实现本文所公开的示例实施例中的一些的唯一方式。将理解的是,当元件或层被称为在另一元件或层之上、“连接至”或“耦合至”另一元件或层时,其可以直接在另一元件或层之上,连接至或耦合至另一元件或层或可以存在中间元件或中间层。相反,当元件被称为“直接在”另一元件或层“上”,“直接连接至”或“直接耦合至”另一元件或层时,则不存在中间元件或中间层。全文中,相同的标号表示相同的元素。如本文所使用的,术语“和/或”包括相关联列出的项目中的一个或多个的任何和所有组合。除非另有定义,否则本文中使用的所有术语(包括技术和科学术语)具有与该主题所属领域的普通技术人员通常理解的相同含义。还将理解的是,诸如在常用词典中定义的那些术语的术语应被解释为具有与其在相关技术的上下文中的含义一致的含义,并且除非在本文中明确定义,否则不会被理想化或过度形式化地解释。如本文中所使用,术语“模块”是指被配置为结合模块提供本文描述的功能的软件、固件和/或硬件的任何组合。该软件可以体现为软件包、代码和/或指令集或指令,并且如本文所述的任何实施方式中所使用的术语“硬件”可以包括例如单个或任意组合的硬连线电路、可编程电路、状态机电路和/或存储由可编程电路执行的指令的固件。模块可以集体或单独地体现为形成更大系统的一部分的电路,例如但不限于集成电路(ic)、片上系统(soc)等。本文公开的各种组件和/或功能块可以体现为模块,该模块可以包括提供结合各种组件和/或功能块在本文中描述的功能的软件、固件和/或硬件。本文公开的主题提供了一种压缩和解压缩系统和技术,其可以并行处理许多信道(例如,8个或16个),并且还可以是硬件友好的(即,具有较小硅面积和较低操作功率)。另外,本文公开的主题提供了可伸缩的复用器电路或模块,其在本文中称为“蝶式混洗器”,其有效地置换数据以用于包括以并行方式打包和解包数据的目的。在一种操作模式中,蝶式混洗器打包多个信道的比特流,以使得所有信道具有相等的比特长度或比特数。在另一种操作模式中,蝶式混洗器将长度相同的比特流或信道解包,以重新形成原始的比特流。对于在八(8)个信道的比特流上操作的系统,蝶式混洗器包括可以灵活地将比特流中的比特置换或重新排列到另一个比特流中的24个2对1(2-to-1)复用器。对于在16个信道的比特流上操作的系统,蝶式混洗器包括可以灵活地将比特流中的比特置换或重新排列到另一个比特流中的64个2对1复用器。本文公开的蝶式混洗器不是全交叉复用器配置。全交叉配置具有大面积o(n2),其中n是数据通道的数量。相反,蝶式混洗器的面积为o(n*log(n)),其中n是数据通道的数量。本文公开的主题的一个实施例提供了一种“零崩溃”数据压缩器和数据打包器,其可以使用蝶式混洗器并提供对打包数据的随机访问,以使得可以随机访问打包数据的任何部分,其中“零崩溃”是指从未压缩的数据中移除零以获得压缩数据的能力。另一个实施例提供了一种解包器和解压缩器,其可以用于使用由零崩溃数据压缩器和数据打包器提供的随机访问能力来解包和解压缩打包的数据。本文公开的主题的又一个实施例可以提供蝶式混洗器,其可以均匀化稀疏数据以使数据的稀疏度更加均匀。蝶式混洗器可用于置换(即重新排列)稀疏数据的数据值,从而均匀化稀疏数据,以使得非零值的团块更均匀地分布在稀疏数据中。本文公开的主题的又一个实施例可以提供可以使用蝶式混洗器并且提供对打包数据的随机访问的信道并行压缩器和数据打包器。信道并行解包器和解压缩器可用于使用信道并行解压缩器和数据打包器提供的随机访问能力对打包的数据进行解包和解压缩。不同的压缩粒度也可以与本文公开的各种数据压缩器一起使用。使用蝶式混洗器的数据压缩器的一个实施例可以为压缩数据提供半字节压缩粒度。使用蝶式混洗器的数据压缩器的另一实施例可以为压缩数据提供字节压缩粒度。使用蝶式混洗器的数据压缩器的另一个实施例可以为压缩数据提供多字节压缩粒度。图1a描绘了根据本文公开的主题的多信道数据打包器100的一个示例实施例的框图。多信道数据打包器100可以包括蝶式混洗器101、控制器102和数据压缩器103。数据压缩器103可以接收8个字节流并将每个字节流压缩为比特流。每个输入字节流都与所有其他输入字节流并行且独立地被压缩。压缩算法可以是将字节流压缩为比特流的任何已知算法。蝶式混洗器101可以接收所得的通常具有不同比特流长度的8个信道的比特流,并且在控制器102的控制下,可以置换8个信道的比特流,以使得每个输出流具有相同的比特流长度并且可被视为单个字节流。在一个实施例中,数据压缩器103可以接收8个信道的比特流,并从每个比特流中移除零值,以为每个比特流信道提供压缩比特流。数据压缩器103还可以为每个比特流信道生成零比特掩码(zbm)(图1a中未示出)。蝶式混洗器101、控制器102和/或数据压缩器103可被实现为电路和/或模块。蝶式混洗器101可以包括复用器模块组件104或“复用器”,其可以被实现为具有使用移位寄存器111缓冲的输出的复用器110,如图1b所示。在一些实施例中,移位寄存器111可以是可选的。图1c描绘了根据本文公开的主题的蝶式混洗器101的一个示例实施例的框图。蝶式混洗器101可以包括以8行(r=0至r=7)和3列(c=0至c=2)的阵列布置的24个2对1的8比特复用器104。蝶式混洗器101可以接收通常具有不同比特流长度的8个信道的比特流。可替换地,复用器104可以以3行和8列的阵列布置,其中每个相应的列接收8个信道的比特流中的一个信道的比特流。参考图1c所示的布置,列c=0的一行中的复用器的输出可以连接到列c=1中的同一行中的相应复用器的输入。类似地,列1中一行的复用器的输出可以连接到列c=2中的同一行中相应复用器的输入。例如,复用器10400的输出连接到复用器10401的输入,并且复用器10401的输出连接到复用器10402的输入。另外,列c=0中的复用器10400和复用器10410的输出可以进一步分别耦合到列c=1中的复用器10421和复用器10431的输入。列0中的复用器10420和复用器10430可以进一步分别耦合到列c=1中的复用器10401和复用器10411的输入。列0中的复用器10440和复用器10450的输出可以进一步分别耦合到到列c=1中的复用器10461和复用器10471的输入。列0中的复用器10460和复用器10470的输出可以进一步分别耦合到列c=1中的复用器10441和复用器10451的输入。列1中的复用器10401和复用器10411的输出可以进一步分别耦合到列c=2中的复用器10442和复用器10452的输入。列c=1中的复用器10421和复用器10431的输出可以进一步分别耦合到列2中的复用器10462和复用器10472的输入。列c=1中的复用器10441和复用器10451的输出可以进一步分别耦合到列c=2中的复用器10402的和复用器10412的输入。列c=1中的复用器10461和复用器10471的输出可以进一步分别耦合到列c=2中的复用器10422和复用器10432的输入。列c=0中的每个复用器的一个输入可以接收比特流。例如,复用器10400可以接收比特流0,并且复用器10410可以接收比特流1。复用器10400和复用器10410被配对,因此也可以将比特流0输入到复用器10410,并且可以将比特流1输入到复用器10400。类似地,可以将比特流2和比特流3输入到复用器10420和复用器10430两者。可以将比特流4和比特流5输入到复用器10440和复用器10450两者。可以将比特流6和比特流7输入到复用器10460和复用器10470两者。也可以使用更大的比特宽度(即字节)的比特流。通常,具有2k个输入的蝶式混洗器包括2k行和k列的2对1复用器,其中k是大于1的整数,并且可以如下构造。每列c中的复用器可以分组为逻辑连续集合,其中每个集合的大小为2c+1,其中c=0,1...k。更具体地,列c=0(即,图1c中最左边的列)中的复用器可以被分组为集合,其中列c=0中的每个集合的大小为2c+1=2。因此,复用器10400和10410形成集合p0...1,0。复用器10420和10430形成集合p2...3,0。复用器10440和10450形成集合p4...5,0。复用器10460和10470形成集合p6...7,0。集合p0...1,0接收分别连接到复用器10400和10410的比特流0和1。类似地,集合p2...3,0接收比特流2和3。集合p4...5,0接收比特流4和5;诸如此类。列c=0中的每个集合可以从控制器102(图1a)接收控制信号,例如s0...1,0。如果控制信号被声明无效(de-assert),则连接到控制信号的复用器集合将选择输入比特流以使得每个输入比特流都通过所述复用器集合以保持在同一行中。如果控制信号被声明有效(assert),则连接到控制信号的复用器集合选择输入比特流以使得输入比特流被输出到复用器集合的另一行,从而行号被交换。例如,在图1c中,考虑集合p0...1,0,控制信号s0...1,0被声明无效导致输入比特流0(即,行0、列0中的比特流)被输出到同一行0中的列1,而输入比特流1(即行1、列0中的比特流)被输出到同一行1中的列1。s0...1,0被声明有效导致输入比特流0和输入比特流1在被输出到列1时交换行。即,被输入到行0、列0的比特流被输出到行1、列1,并且被输入到行1、列0的比特流被输出到行0、列1。其他复用器集合以相同的方式响应它们各自的控制信号。列c=1(即,图1c中从左数第二列)中的复用器可以分组为集合,每个集合的大小为2c+1=4。例如,复用器10401、10411,10421和10431形成集合p0...3,1,并且复用器10441、10451、10461和10471形成集合p4...7,1。列c=1中的每个集合的复用器从前一列c=0中的两个集合的复用器接收输入。通常,列c+1中的每个集合的复用器从前一列c中的两个集合的复用器接收输入。列1中的集合p0...3,1可以接收控制信号s0...3,1。如果控制信号s0...3,1被声明无效,则集合p0...3,1中的每个复用器发挥作用以将来自上一列的对应集合的输入传递到下一列c=2,以使得数据留在同一行中。例如,参考集合p0...3,1,复用器10401、10411、10421和10431的输出分别等于复用器10400、10410、10420和10430的输出。类似地,对于集合p4...7,1,如果s4...7,1被声明无效,则复用器10441、10451、10461和10471的输出分别等于复用器10440、10450、10460和10470的输出。如果控制信号s0...3,1被声明有效,则集合p0...3,1中的复用器发挥作用以交换相关联的输入集合。具体地,参考集合p0...3,1,复用器10401、10411、10421和10431的输出分别等于复用器10420、10430、10400和10410的输出。类似地,对于集合p4...7,1,如果s4...7,1被声明有效,则复用器10441、10451、10461和10471的输出分别等于复用器10460、10470、10440和10450的输出。通常,如果在列c=1中控制信号s被声明无效,则由控制信号s控制的复用器的相关联的集合发挥作用以传递与所述复用器的集合相关联的两个输入集合的输出,而不交换两个相关联的输入集合,即两个相关的输入集合的输出留在同一行中。然而,如果在列c=1中控制信号s被声明有效,则由控制信号s控制的复用器的相关联的集合发挥作用以在将与所述复用器的集合相关联的两个输入集合彼此交换的同时输出所述两个输入集合的输出。可以遵循与以上针对列1所描述的规则相同的规则来构造列c=2...(k-1)中的复用器连接。对于图1c所描绘的仅包括三列复用器的特定实施例,列c=2的复用器被分组为一个逻辑集合p0...7,2,其大小为2c+1=23=8。控制信号si...j,k可以由逻辑电路基于比特流长度使用以下的功能/操作描述来生成。图1d描绘了根据本文公开的主题的蝶式混洗器101'的另一示例实施例的框图。蝶式混洗器101'可以包括布置在16行(r=0至r=15)和4列(c=0至c=3)的阵列中的64个2对1的8比特复用器104'。蝶式混洗器101'的第一列c=0的复用器104'可以接收通常具有不同比特流长度的16个信道的比特流。可以控制蝶式混洗器101',以使得列c=3的复用器104'输出16个信道的比特流,每个信道的比特流具有相同的比特流长度。图1d中的蝶式混洗器101'以与图1c中描绘的蝶式混洗器101基本相同的方式操作,除了蝶式混洗器101'接收16个输入并提供16个输出之外。图1d中的控制信号si...j,k已被省略。再次参考图1a,数据压缩器103接收未压缩的(即,原始的)数据块,并使用例如任何已知的接受比特流作为输入并生成另一个比特流作为输出的压缩算法,将每个字节流单独压缩为相应的比特通道。因为每个比特通道是单独压缩的,即独立于其他比特通道,所以输出比特流的长度可能会在一个比特通道与另一个比特通道之间变化。例如,数据压缩器103可以将8信道乘32字节长的原始数据块压缩为各种长度的八个比特流,并输出压缩的八个比特流,如图2a中的201所描绘的。具有有效压缩比特的每个比特流在201处用矩形描绘,因为这些比特流是从数据压缩器103并行时钟输出的,其中比特流4是所有八个通道中最长的,而比特流3是最短的。相应地,随着蝶式混洗器101开始首先(即在第一时钟周期期间)并行地接收八个压缩流,仅通道4中的比特包含有效数据。在随后的时钟周期期间,除了通道4中的比特有效之外,通道0中的比特还将在某些点变得有效。最终,所有八比特通道中的所有比特都变得有效,对应于201处的流的尾部,即最左侧。图2a至图2c概念性地描绘了根据本文所公开的主题,不同比特流长度的八个示例比特流被递归打包以变成各自具有相等的比特流长度的八个比特流。在201描绘的八个示例比特流0-7通常具有不同的比特流长度,并且被输入到例如图1c中的蝶式混洗器101的复用器10400至10470。比特流0-7被配对或分组为与输入复用器的配对相对应的四对(pair)。在图2a的202处,将每对中的更长比特流长度的前部或头部通过蝶式混洗器101重新定位或重定向,以成为该对中的更短比特流的一部分,这是通过控制该对的复用器、以使得该对比特流具有相等的比特流长度来实现的。例如,比特流0的一部分被列c=0的复用器重定向,以变成比特流1的一部分。类似地,比特流2的一部分被重定向以变成比特流3的一部分。比特流4的一部分被重定向到比特流5,并且比特流7的一部分被重定向以成为比特流6的一部分。在一对比特流的比特流长度的差是奇数个比特的情况下,虚拟比特或填充比特可以被添加到所述两个比特流中的更短的一个。所述对内具有相等比特流长度的几对比特流在203处被描绘,并从列c=0的复用器被输出。在203处指示的灰色区域表示已被重定向以变成另一个比特流的一部分的比特流部分。203处的所得到的流可以由蝶式混洗器101的列c=0生成。使能复用器模块104的输入的时钟可以用于防止移位寄存器时钟输入无效比特,同时保持缓冲的数据直到到了开始将缓冲的数据移出的时间。并且,在蝶式打包开始之前,应该知道每个压缩数据块的比特流长度。在图2b的204处,将在对内具有相等比特流长度的比特流对输入到蝶式混洗器101的第二列(列c=1)中的复用器10401至10471。所述比特流对被进一步配对或分组为与蝶式混洗器101的第二列中的复用器的配对相对应的两对的对(twopairsofpairs)。在205处,通过控制第二列的复用器,将具有更长比特流长度的比特流对中的每个比特流的一部分重新定位或重定向,以分别成为具有更短比特流长度的比特流对的一部分。例如,第一对的对(对的对1)的比特流中的每一个的一部分被第二列的复用器重定向以分别成为第一对的比特流对中的更短比特流的一部分。类似地,第二对的对(对的对2)的比特流中的每一个的一部分被第二列的复用器重定向以分别成为第二对的比特流对中的更短比特流的一部分。在一对的对内的具有相等的比特流长度的几对比特流对在206处被描绘。在206处的所得到的流可以由蝶式混洗器101的列c=1生成。在图2c中的207处,具有相等的比特流长度的几对比特流对被输入到蝶式混洗器101的第三列(列c=2)中的复用器10402至10472。所述几对比特流对被进一步配对或分组为与蝶式混洗器101的第三列中的复用器的配对相对应的比特流的对的四元组(apairofquads)。在208处,通过控制蝶式混洗器101的第三列的复用器,具有更长的比特流长度的比特流的对的对(四元组)的比特流中的每一个的一部分被重定位或重定向,以分别成为具有更短的比特流长度的比特流的对的对(四元组)的一部分。例如,第一个四元组中的比特流中的每一个的一部分被第三列的复用器重定向以分别成为比特流的第二个四元组中的更短比特流的一部分。现在具有相等的比特流长度的比特流在209处被描绘。在209处的所得到的流可以由蝶式混洗器101的列c=2生成。图3a描绘了根据本文公开的主题的数据打包的另一示例,该数据打包涉及原始8比特数据的示例块,诸如8×8的权重集合。权重集合301可以包括零值和非零值。数据压缩器103(图1a)可以压缩权重集合301以移除零值,并提供例如zbm(零比特掩码)压缩的多信道比特流302,其中一个信道对应于8x8的权重集合的一行。在另一个实施例中,示例框301可以是从激活函数输出的特征图值的集合。多信道比特流302的每个信道可以包括前八比特中的零比特掩码部分303、和压缩数据部分304。在一个实施例中,零比特掩码部分303中的非零比特表示集合301的非零值。相应地,压缩数据部分304包含权重301,其顺序保持不变,只是省略了等于零的权重值。每个信道的比特流长度通常与其他zbm压缩信道不同。如果压缩数据302按原样存储在诸如易失性存储器或非易失性存储器的存储器中,则不同信道的不相等比特流长度会浪费存储器空间。蝶式混洗器101可用于打包数据以使不同信道的比特流长度相等。数据压缩器103(图1a)的逻辑可以使用零比特掩码来计算每个比特流的长度,并使用控制器102控制通过蝶式混洗器101的路径。在图3b中,多信道比特流302被输入到蝶式混洗器101。多信道比特流305从蝶式混洗器101的第一列复用器输出。即,每对信道的具有更长比特流的长度的一部分在控制器102(图1a)的控制下被重定位或重定向,以成为该对中的更短比特流的一部分,从而使得每对比特流具有相等的比特流长度,类似于结合图2a所描述的。在图3c中,多信道比特流305被输入到蝶式混洗器101的第二列中的复用器,并且多信道比特流306被输出,类似于结合图2b所描述的。在图3d中,多信道比特流306被输入到蝶式混洗器101的第三列中的复用器,并且多信道比特流307被输出,类似于结合图2c所描述的。多信道比特流307的所有信道已经使用蝶式混洗器101被打包成相等的长度,并且由多信道比特流307表示的数据块可以高效地存储在存储器中,无论是易失性还是非易失性,而无需浪费空间。注意,作为该示例的一般概念,前八比特中的零比特掩码部分303和蝶式混洗器101的处理之后剩余的信道的压缩数据部分304被一起存储。代替通过移位寄存器111缓冲输出的方式来使用复用器104,可以单独使用复用器110(无需移位寄存器111)来减小电路面积和功率。更具体地说,图2a至图2b和图3a至图3b中描绘的每个步骤可以通过以下步骤来实现:将比特流缓冲到临时存储器中,使用蝶式混洗器101应用置换,并且将置换后的流保存回到临时存储器中。相应地,可能需要三遍这样的处理来打包数据,其中每一遍对应于图2a至图2b和图3a至图3b中的一个步骤。解包打包数据以相反的方式操作。零比特掩码可以被放置在每个打包信道中的最前面,因此可以使用零比特掩码对在零比特掩码之后的打包的非零数据进行解包。更具体地,解包打包的流包括:首先,确定原始流的长度,该原始流的长度可从打包块的开始处的零比特掩码303容易地获得,然后,再现在打包期间执行的计算,在打包时,几对(pairs)(或者几对的几对(pairs-of-pairs)、或者几对的几对的几对(pairs-of-pairs-of-pairs))内的流长度被比较,以确定哪个流的哪个头部将被裁剪并附加到哪个流。在那时,流长度之间的差异被确定或计算,被除以二以确定要裁剪和附加的头部的长度,并使用可选的填充来避免除法之后出现小数部分。该计算提供了打包流中的偏移,该偏移指向每个裁剪并附加的头部可以在存储装置中位于何处。在解包期间,蝶式混洗器101可以被控制为在信道之间交换回头部以恢复原始流。请注意,在将头部从更短的信道重新添加到头部的原始流时,复用器可能需要寄存数据,并且更短的信道中的比特流流动可能需要暂停。图4描绘了根据本文公开的主题的示例数据解包器400的框图。数据解包器400可以包括比特解包器401、蝶式混洗器101和控制器(图4中未示出;参见例如图1a中的控制器102)。比特解包器401接收打包的非零数据的块作为多信道信号。在一个实施例中,图4所示的解包器400可以被配置用于8个信道的打包数据。比特解包器401的每个信道可以包括两个8比特寄存器和八个8:1的1比特复用器,它们与比特解包器401的其他信道独立地操作。打包数据可以是n比特整数。例如,对于n=5,在每个信道中,打包数据可以是int5或uint5类型。然而,计算机系统中的解包数据通常具有一个字节的粒度,即int8或uint8。在这种情况下,可以在解包之前将5比特数据转换(填充)为8比特数据。作为示例,打包数据可以是5比特无符号(unsigned)数据,其在402处被描绘。在该示例中,比特解包器401将三个零比特添加到每个打包数据字节的最高有效位(msb)以在403处形成8比特(一字节)的无符号数据。包括针对每个信道的8比特零比特掩码的比特解包器401的输出被输入到递归信道解包器,该递归信道解包器可以是图1c中的蝶式混洗器101。在该特定示例中,蝶式混洗器的每个信道的宽度为一个字节,而不是一个比特,如前所述。控制器(即控制器102)使用每个信道的零比特掩码来控制通过蝶式混洗器101的数据路径,以在404处形成解包的多信道8比特数据(即权重、特征图值等)。在替代实施例中,不是使用具有固定比特长度并且跳过零的编码数据,而是可以将本文公开的主题扩展到具有提供可变比特宽度的数据长度的编码技术。例如,如果数据被使用golombrice编码或使用稀疏指数golombrice编码而预压缩,则零比特掩码303(图3a)可以被指示流长度和当以解包形式存储时的完整流长度的数据部分替换。图5示出了根据本文公开的主题的数据块501,其包括流长度部分502和压缩数据部分503。打包压缩流可以如本文公开的那样执行。流长度比特宽度应被选择为适应最长可能的可变长度序列。在替代实施例中,可以使用本文公开的蝶式混洗器对输出特征图和/或来自激活函数的输出进行混洗(同时存储还进行了预混洗的权重),以将零值散布(即,平衡)到可以从激活函数输出的通道当中,以更好地利用如本文其他地方所述的乘法器。图6a描绘了根据本文公开的主题,提供对打包数据的随机访问的示例实施例的零崩溃数据压缩器和打包器电路的框图。图6b描绘了具有对由图6a的零崩溃数据压缩器和打包器电路提供的打包数据的随机访问的示例数据压缩。参考图6a和图6b,电路600可以包括零值移除器601、非零值打包器602、存储器写仲裁器603、零比特掩码生成器604、掩码打包器605和行指针生成器606。形成电路600的各种组件(包括整个电路600)可以被实现为一个或多个电路和/或一个或多个模块。零值移除器601可以接收例如16个通道(即,lane0[7:0]-lane15[7:0](通道0[7:0]-通道15[7:0]))或信道的流数据610。流数据610的每个通道可以包括未压缩的非零值数据和零值数据的8比特(一个字节)值。数据流610可以被再划分(subdivide)为组,每组具有16个字节的长度,以使得打包电路600在大小为16字节乘16通道的数据块上进行操作。示例的非零值数据在图6a和图6b中用交叉影线或阴影表示,并且零值数据由“0”表示。在一个实施例中,8比特值可以对应于像素数据。零值移除器601可以被配置为从每个数据流610移除零值数据。零值移除器601输出16个数据流str0[7:0]-str15[7:0](流0[7:0]-流15[7:0]),其中各个数据流都移除了零字节值。图6c描绘了根据本文所公开的主题的使用零崩溃移位器630的零值移除器601(图6a)的示例实施例的框图。零崩溃移位器630的一个目的是从输入向量中移除零。例如,如果输入向量是由具有值{0x01,0x02,0x00,0x04,0x05,0x06,0x07}的字节形成的,则零崩溃移位器630将该输入向量转换为具有字节值{0x01,0x02,0x04,0x05,0x06,0x07,0x00}的输出向量。请注意,(从左开始数)第三个位置中的零值被取出(“崩溃”),位置4、5、6和7中的非零值都向左移动了一个位置,并且零值字节从向量的第三个位置移到位置8处的向量的末尾。在另一个示例中,具有值{0x01,0x02,0x00,0x04,0x05,0x00,0x00,0x08}的输入向量被零崩溃移位器630转换为具有值{0x01,0x02,0x04,0x05,0x08,0x00,0x00,0x00}的输出向量。在此,输入向量中的位置3、6和7处的零被“崩溃”并移动到输出向量中的位置6、7和8处。剩余的非零元素根据需要向左移动,以填充“崩溃的”零留下的空隙,同时保留非零元素的顺序。在又一个示例中,如果输入值都不为零,则输出将与输入相同。如前所述,零崩溃移位器630的一个目的是使得能够仅在存储器620(图6a)中存储非零值,同时使用零比特掩码来跟踪零值的原始位置,以使得可以以无损方式对压缩数据(即,移除了零值的数据)进行解压缩。考虑具有m个值的向量i[m-1..0][n-1..0],其被输入到零崩溃移位器630。所有m个值的比特宽度n都相同,并且被选择为与要处理的数据的宽度相匹配。例如,在一个示例实施例中,该值可以被设置为m=16并且n=8,从而得到i[15..0][7..0]。设零崩溃移位器630的输出是具有m个值的向量o,o[m-1..0][n-1..0]。向量i和o两者具有相同的长度m,并且向量i和o的所有元素的具有相同的比特宽度n。具有m=2n个输入(信道)的零崩溃移位器630可以被实现为多级互连网络,该多级互连网络可以包括复用器631的矩阵(仅指示了所述矩阵的一个复用器631)以及控制逻辑。更具体地,在一个实施例中,如图6c所示,具有m=2n个输入(信道)的零崩溃移位器630可以包括被组织成m列(信道)和n行的2:1复用器631的矩阵。为了清楚地说明,m可以是n的幂,其中n是自然数,例如,n=4。具有不等于2的幂的输入数量m的零崩溃移位器630可以通过使用具有k个输入的零崩溃移位器630'来等效地表示,在零崩溃移位器630'中,k=2n>m,并且其中未使用的i[k..m-1]输入被设置为零,并且未使用的输出o[k..m-1]被保持断开,如图6d所示。控制逻辑可以包括例如如图6a所示的零比特掩码生成器604,以及用于复用器矩阵中的每个复用器的选择信号的生成器(未示出)。零比特掩码生成器604可以检查每个输入信道以确定该信道的值是否等于零。零比特掩码生成器604输出一比特信号的向量z[0..m-1],其中每个高电平有效(active-high)信号指示相应的输入信道的值等于零。随后,选择信号生成器逻辑将z[0..m-1]转换为用于复用器矩阵中的所有复用器631的选择信号s的控制值,如下文更详细描述的。选择信号s可以定义为矩阵s[row][channel](s[行][信道])的形状,其中row=0..n-1,channel=0..m-1。参考图6c,s[0][0]位于左上角,并且s[3][15]位于右下角。从z[0..m-1]确定选择信号s[row][channel]的过程如下。最初,所有复用器选择信号都设置为零,即s[0..n-1][0..m-1]:=0。零值信道的计数nz_ch也初始化为等于零,即,nz_ch:=0。接下来,复用器选择信号s[row][col](s[行][列])被配置为将值从非零输入信道正确路由到输出信道。为此,从信道ch:=0开始迭代信道,同时在nz_ch中保存零值信道的计数。作为符号,注意,设置用于矩阵位置的复用器选择信号s[row][col]:=x等效于s[row][ch][0..n-1]:=n{x},即,比特值x被复制到宽度n,如verilog符号中所写的。因此,为简洁起见,在适当的地方,符号s[row][col]:=x将代替s[row][ch][0..n-1]:=n{x}被使用。如果i[ch]!=0,则nz_ch计数增加,nz_ch的当前值被转换为二进制符号nz_ch_bin[0..n-1],当前复用器选择信道被初始化为ch_current:=ch,并且从row=0开始,nz_ch_bin[0..n-1]被迭代。迭代循环首先设置s[row][ch_current]:=nz_ch_bin[row],然后检查是否nz_ch_bin[row]==1。如果参考图6c或图6d确定该条件为真,则通过设置ch_current:=ch_current2row,横向(水平)跟随从对应于s[row][ch_current]的复用器的输出到复用器选择矩阵s中左侧的连线。如果条件为假,即,如果s[row][ch]==0,则nz_ch计数增加,并且复用器选择信号配置为输出o[m-nz_ch]:=0,如下文详细描述。例如,考虑ch_z:=m-nz_ch。在图6d的示例实施例中,可以通过以下步骤完成设置o[ch_z]:=0:将ch_z解码为z[0..m-1][0..n-1],以使得z[0..ch_z1][0..n-1]:=0,z[ch_z..m-1][0..n-1]:=1;以及逐位应用逻辑“与(and)”,o[0..m-1][0..n-1]:=s[n-1][0..m-1][0..n-1]and!z[0..m-1][0..n-1]。在图6c所示的示例实施例中,代替将“与”门相加以将零崩溃移位器630的输出归零,可以使用现有的复用器矩阵将感兴趣的输出归零。具体来说,如果(nz_ch==m),则不执行任何操作(即,所有信道输入均为零),否则按以下方式循环遍历行n-1...0。如果ch_z≥m,则计算已完成,否则设置选择信号s[row][ch_z]:=1,其中该行是当前行号,并检查是否正在通过横向连接接收用于复用器的零值s[row][ch_z]。零值检查包括设置lateral_distance:=2row(即,以信道表示的该行中的横向连接的长度),然后设置ch_z:=m-lateral_distance,即,可能通过横向连接将零传递给选择信号s[row][ch_z]的信道号。如果ch≥ch_z,则计算完成;否则,如果(ch_z+lateral_distance<m),则设置ch_z:=ch_z+lateral_distance,即,如果存在横向连接(从复用器s[row][ch_z+lateral_distance]到s[row][ch_z]),遵循该连接以在下一次迭代中配置复用器选择信号s[row][ch_z+lateral_distance]。图6e描绘了零崩溃级移位器630的所有信道都接收非零值的情况。在这种情况下,所有复用器选择信号s[row][ch]:=0,并且零崩溃移位器630的输出o[0..m-1][0..n-1]与输入i[0..m-1][0..n-1]相同。在图6e-图6j中,具有相对更粗的线宽的信号路径指示被特定输入值采用以通过零崩溃移位器630到达输出的路径。图6f描绘了其中信道12接收零值输入,而其余信道接收非零值输入,即i[12][0..n-1]==0的情况。遵循如上所述的复用器选择算法,s[0..n-1][0..m-1]:=0被初始化。接下来,复用器631被配置为正确地输出非零值。具体而言,从信道ch:=0开始迭代信道,同时保留零值信道的计数nz_ch。当到达接收零的信道ch==12时,i[12]==0,nz_ch从0增加到nz_ch:=1,nz_ch被转换为二进制符号nz_ch_bin[0..n-1]:=1000b,当前复用器选择信道ch_current:=12被启动,并从row=0开始迭代nz_ch_bin[0..n-1]==1000b。迭代循环包括设置s[row][ch_current]:=nz_ch_bin[row]。由于nz_ch_bin[0]==1b,所以i[0][12]:=1b。由于nz_ch_bin[0]==1b,所以来自复用器s[row][ch_current]的复用器选择矩阵s(即,由选择信号s[row][ch_current]控制的复用器的输出线,如图6f中所示),被横向遵循到左侧到s[row][ch_current-2row],即从选择信号s[0][12]到选择信号s[0][12-20]==s[0][11],设置ch_current:=ch_current-2row==12-20==11。其余的行1..3在位向量nz_ch_bin[1..n-1]中进行迭代以产生所有零,即nz_ch_bin[1..n-1]==000b。因此,在此步骤中,不对复用器选择信号进行任何改变。在信道ch==12处,复用器选择信号还被配置为从信道ch_z:=(m-nz_ch)==16–1==15输出零。在图6d的实施例中,o[m-nz_ch][0..n-1]:=0,即,z[16-1][0..7]:=0。在图6c的实施例中,row3..0如下迭代。对于row==4,确定是否ch≥m,其为假(否则计算将停止),设置[row][ch_z]:=1,即s[3][15]:=1,并且检查复用器s[3][15]是否未通过横向连接接收零输入被执行。行3中的横向连接长度等于lateral_distance:=23==8个信道。如果对于复用器信号s[3][15]存在横向连接,则复用器信号s[3][15]将从复用器信号s[row1][ch_z+lateral_distance]接收该零值,即s[3-1][15+8]==s[2][23]。由于列23超过列n==16的总数,所以不存在复用器信号s[2][23]。因此,迭代将在其余的行2、1和0中继续。行2、1、0的横向连接长度等于2row,为4、2和1。在所有这些情况下,不存在横向连接,因为(ch_z+4)>n,(ch_z+2)>n并且(ch_z+1)>n,即,(15+4)>15,(15+2)>15并且(15+1)>15。因此,计算被完成。图6g至图6j描绘了当信道逐渐接收更多零值时的另外的更高级的情况。图7描绘了根据本文公开的主题的示例电路700的框图,该示例电路700可用于从比特流中移除零值。电路700可以包括布置在16行(r=0至r=15)和4列(c=0至c=3)的阵列中的64个2对1的8比特复用器631。如图7所示,复用器631的输入被配置为接收n=8比特。在列c=0中,行r=15中的复用器631的两个输入之一被连接为接收8比特0值作为输入。在列c=1中,行r=14和r=15中的复用器的两个输入之一被连接以接收8比特0值作为输入。在列c=2中,行r=12至r=15中的复用器的两个输入之一被连接以接收8比特0值作为输入。最后,在列c=3中,行r=8至r=15中的复用器的两个输入之一被连接以接收8比特0值作为输入。形成电路700的各种组件(包括整个电路700)可以被实现为一个或多个电路和/或一个或多个模块。已经省略了控制复用器631的选择信号。第一列c=0中的复用器631接收16个数据流中的相应数据流的8比特值。第一列的复用器被控制,以使得将非零值移向行r=0,以替换在r=0方向上的与所述非零值相邻的行中的等于0的值。即,输入到相应复用器631的数据流的值被检测,并且如果值被检测为零,则可以移动相邻行中的非零值以替换所述被检测为零的值。再次参考图6a,在611处指示用于示例输入610的零值移除器601的示例输出。通常,在已经移除零值之后,各个数据流可以具有不同的长度。非零值打包器602接收不同长度的数据流str0[7:0]-str15[7:0],并生成打包数据data_wr_packed[127:0],其中,不同长度的数据流已被级联,在612处被描绘。在一个实施例中,非零值打包器602可以包括蝶式混洗器,诸如图1c中的蝶式混洗器101。所级联的数据可以被保存在非零值打包器602内的先进先出(fifo)队列中,以最终存储在存储器620中。零比特掩码生成器604可以耦合到比特流lane0[7:0]-lane15[7:0]的16个通道中的每一个。零比特掩码生成器604为每个通道生成比特掩码,该比特掩码指示例如相对应的比特流的16字节组中的零值的位置。即,零比特掩码生成器604为每个通道lane0[7:0]-lane15[7:0]中的每个16字节组生成比特掩码613。比特掩码中的一个比特对应于16通道×16字节的数据块中的一个字节,因此使得比特掩码本身有256比特长。在替代实施例中,可以为具有不同于16字节值组的大小的比特流的值的组生成由零比特掩码生成器604生成的比特掩码。零比特掩码生成器604所生成的掩码中的信息可以用于控制零值移除器601和非零值打包器602的操作。掩码打包器605接收比特掩码数据613,并且可以将比特掩码数据613级联以用于存储。掩码打包器605还将级联的比特掩码数据分割成16字节的字,以作为data_wr_mask[127:0]存储,以匹配存储器620的输入宽度。比特掩码数据613可以保持在掩码打包器605的fifo队列中。行指针生成器606还可以接收零比特掩码数据,并且可以跟踪非零值计数以生成行指针数据,如在614处指示的data_wr_rowptr[127:0]。行指针是存储器620中的偏移,其指向张量(tensor)内的每个平面行中的第一像素。例如,层激活的张量可以具有64×128×32字节的大小,其中64×128对应于层平面大小,即高度和宽度,而32对应于该层中的深度信道的数量。在该示例中,可以存在64个行指针,每行一个,其中每个行指针包含存储在存储器620中的压缩数据的偏移。行指针数据614可以保持在行指针生成器606内的fifo队列中。可以使用比特掩码数据613和行指针数据614随机访问存储在存储器620中的压缩数据。存储器写仲裁器603接收data_wr_packed[127:0]、data_wr_mask[127:0]和data_wr_rowptr[127:0],并且仲裁将各个数据写入存储器620。存储器620可以是易失性存储器和/或非易失性存储器,并且可以包括用于非零值数据(其大小可以变化)的区域或空间621、以及用于零比特掩码数据和行指针数据的元数据622的区域或空间。存储器写仲裁器603还可以从非零值打包器602接收addr_wr_packed[]信号和queue_len_packed[2:0]信号,从掩码打包器605接收addr_wr_mask[]信号和queue_len_mask[127:0]信号,以及从行指针生成器606接收addr_wr_rowptr[]信号和queue_len_rowptr[2:0]。存储器写仲裁器603基于queue_len_packed[2:0]信号、queue_len_mask[2:0]信号和queue_len_rowptr[2:0]信号的值,确定哪个特定数据被写入存储器620以及何时将该数据写入存储器620。例如,存储器写仲裁器603可以选择与具有最大值的queue_len信号相对应的数据,该值指示例如相关联的fifo包含最多的准备好存储到存储器620中的数据。被选择写入存储器620以进行写操作的数据的量可以受到存储器620的端口宽度的限制。在一个实施例中,写操作可以包括16个字节。在另一个实施例中,写操作可以包括8个字节。利用由写使能(we)信号提供的定时,数据作为data_wr[127:0]被写到存储器620到addr_wr信号指示的位置。addr_wr_packed[]信号可以被存储器写仲裁器603用来确定存储器620内的用于非零值数据的区域621中被写入打包数据的位置。类似地,addr_wr_mask[]信号和addr_wr_rowptr[]信号可以被用于确定存储器620内的元数据区域622中被写入零比特掩码数据和行指针数据的位置。存储器写仲裁器603可结合仲裁器将该数据写入存储器620,从而将弹出信号(即,pop_packed信号、pop_mask信号或pop_rowptr信号)发送至fifo队列之一,以使得可以从fifo移除所述数据。存储器写仲裁器603还可以包括忙信号输出,其被输出以控制通过通道lane0[7:0]-lane15[7:0]输入的数据的量。图8a和图8b分别描绘了根据本文公开的主题的未压缩数据801和具有对由零崩溃数据压缩器和打包器电路600提供的打包数据的随机访问的数据压缩的另一示例。在图8a中,未压缩数据801可以表示8比特像素数据,其中每个像素包括16字节的数据,并且一行像素包括四个像素。具有零值的像素由“0”表示,并且具有非零数据的像素由行号、像素号和通道号表示。零崩溃数据压缩器和打包电路600的16个通道中的每一个接收一个字节的未压缩像素数据。例如,lane0接收用于像素0(pix0)的未压缩数据的字节0。lane1接收用于pix0的未压缩数据的字节1,依此类推。因此,图8a中描绘的未压缩像素数据可以对应于图6a和图6b中的比特流610。图8b描绘了已经由零崩溃数据压缩器和打包电路600对未压缩数据801进行压缩以形成压缩数据802。压缩像素数据802可以对应于打包数据612。对应于压缩像素数据802的零比特掩码数据在803处被指示。零比特掩码数据803包括用于每个16字节的未压缩像素数据的两字节的掩码数据。例如,掩码数据803a对应于用于像素pix0(像素0)的16字节的未压缩数据。类似地,掩码数据803b对应于用于像素pix1(像素1)的16字节的未压缩数据,依此类推。对应于压缩像素数据802的行指针数据在804处被指示。行指针数据804包括用于每个16字节的未压缩像素数据801的两字节的行指针数据。例如,行指针数据804a对应于用于像素pix0的16字节的未压缩数据。行指针数据804b对应于像素用于pix1的16字节的未压缩数据,依此类推。图9描绘了根据本文公开的主题的解包器和解压缩器电路900的示例实施例的框图。电路900通常通过使用行指针数据614和零比特掩码数据613解包存储器区域621中的非零值数据,来与图6a的零崩溃数据压缩器和打包电路600相反地操作。电路900可以包括存储器读仲裁器901、非零值解包器902、零值插入器903和掩码解包器904。形成电路900的各种组件(包括整个电路900)可以被实现为一个或多个电路和/或一个或多个模块。存储器读仲裁器901从存储器620读取非零值数据、行指针数据和比特掩码数据。非零值解包器902基于比特掩码数据解包打包数据。零值插入器903也基于比特掩码数据将零值插入解包数据中。如果电路600的非零值打包器602包括蝶式混洗器,例如蝶式混洗器101,则非零值解包器902还可以包括相对应的蝶式混洗器以解包数据。图10a至图10b描绘了根据本文所公开的主题的,由零崩溃数据压缩器和打包电路600以及解包和解压缩器电路900提供的压缩数据的随机访问能力的示例细节。在图10a中,在1001处描绘了35×35像素阵列。为方便起见,仅指示了像素0-2、35-37和70-72。在1002,用于像素阵列1001的压缩像素数据被描绘为存储在例如图6a中的存储器620的非零值数据区域621中。用于像素阵列1001的比特掩码数据1003和行指针数据1004可以存储在例如存储器620的元数据区域622中。在1005,用于像素阵列1001的前三行的行指针数据被扩展。每个行指针包括两字节的数据,其中前十比特可以提供像素阵列1001中的行的第一像素的非零值数据区域621中的行或单元(cell)的地址。接下来的四比特可以提供像素阵列1001中的行的第一像素的单元中的偏移。最后两比特可以是未被使用的。例如,在图10b中,用于位于阵列1001的行1处的像素35的行指针数据的前十比特指向用于像素阵列1001的非零值数据区域621的第六行或单元。接下来的四比特指向用于像素35的单元中的偏移。图10c是根据本文公开的主题的,使用由零崩溃数据压缩器和打包电路600提供的打包压缩数据的随机访问能力来访问压缩数据1002内的窗口1006(例如,图10d中)的方法1010的流程图。方法1010从1011开始。在1012,相对于大小为h×w×d的像素阵列1001放置h×w×d窗口,其中h和w是指窗口平面的高度和宽度,h和w指示像素阵列平面高度和宽度,并且窗口1006内的深度信道d的数量与张量1001的深度信道的数量相同,即d=d。在1013,平面索引c和r被初始化,将数据张量1001内的窗口的位置指示为平面列索引和平面行索引。更具体地说,c和r是指窗口1006内左上像素的位置。在1014,针对行r处的像素访问行指针数据。步骤1015检查是否存在位于由在1014处检索到的行指针所指定的行起点与窗口1006的起始列之间的像素。由于不需要前部像素,因此应跳过其检索和解压缩。当存在任何前部像素时,步骤1017和1018更新行指针以考虑前部像素。更具体地,在1017,方法1010检索用于行r、列0...c-1中的像素的比特掩码。步骤1018对检索到的比特掩码中的零的数目n进行计数以获得前部像素在非零值数据区域621中占用的字节(包含非零值)的数量。步骤1019将行指针r增加偏移n,以计算存储器620的起始位置,即其中用于行r和列c的压缩数据被存储的sram字内的存储器620地址和字节偏移。对应于(r,c)处的像素的比特掩码被包含,从存储器620字floor((r*w+c)*d/b)+abit_mask和存储器620字内的比特偏移mod((r*w+c)*d,b)开始,其中b是以字节为单位的sram字大小,而abit_mask是起始地址,其中比特掩码元数据被存储在存储器620中。在不存在要跳过的前部像素的情况下,步骤1016将要跳过的字节数n设置为零,然后进行到步骤1019。步骤1020从用于行r中的像素c…c+w-1的存储器区域621检索压缩像素数据,并且从存储器区域622检索相关联的比特掩码数据。步骤1021使用相关联的比特掩码解压缩并输出所检索的像素数据。步骤1022使行索引r增加,并且该过程从步骤1014开始重复,直到已经提取了来自整个窗口1006的数据,并且步骤1023中断了循环以完成方法1010的执行。在窗口1006内的深度信道d的数量小于张量1001内的深度信道d的数量,即d<d的情况下,可以通过跳过未使用的深度信道的输出来修改方法1010。如上所述,在必须使用除一个以外的垂直和/或水平跨度来检索窗口1006内的数据的情况下,如上所述,可以以类似于跳过前部像素的方式来抑制未使用像素的检索和输出。图10d描绘了根据本文公开的主题的从35×35像素阵列1001中检索3×4数据窗口1006的方法1010。对于此示例,窗口坐标(row0,col0)为(0,3)。为了方便起见,仅指示了像素阵列1001的像素0-6、35-41和70-76。最初,方法1010检索用于行0的行指针。检索到的值指向像素0的位置。随后,方法1010通过以下步骤来跳过不需要的前部像素0...3:提取与像素0、1、2和3相关联的比特掩码,通过对这些比特掩码中的零比特进行计数来计算像素0..3在压缩数据存储区域621中占用的字节数,并将指针增加所计算的字节数,诸如增加到像素4处的点。存储器行指针可以包括:字地址和字的偏移。访问位于存储器620内的偏移abyte处的字节对应于访问位于存储器字内的偏移mod(abyte,s)处的存储器地址floor(abyte/s),其中s是以字节为单位的sram字宽。已经计算出用于像素4的存储区域621中的压缩数据的位置,即像素4的地址及其在存储器字的偏移,方法1010提取用于像素4...6的压缩数据,提取用于像素4...6的比特掩码数据,将两者合并以对压缩数据进行解压缩,通过重新插入零值字节来对压缩数据进行膨胀(inflat),然后输出解压缩的结果。此过程对行1重复一次,对行2重复一次,从而完成了从像素阵列1001检索窗口1006。蝶式混洗器也可以用于均匀化稀疏数据。可以存在这样的情况:稀疏数据(诸如与神经网络的特征图和权重相关联的数据)可以包括成簇的非零值。即,数据可以是非均匀的稀疏数据。在这种情况下,可以通过例如将输入特征图(ifm)值或从激活函数输出的值与权重值并行相乘来并行处理稀疏数据的系统可能有许多乘法器空转(至少一个操作数等于0),而同时小组的乘法器可能会提供大量的乘法运算,从而导致出现瓶颈状况。如本文所使用的,术语“激活值(或数据)”是指从激活函数输出的值。同样如本文所使用的,术语“输入特征图值(或数据)”和“激活值(或数据)”可以互换使用。可以使用蝶式混洗器对ifm值和/或权重值进行混洗(置换),以使得稀疏数据更加均匀,从而乘法器被更均匀地利用。图11a描绘了根据本文公开的主题的,利用蝶式混洗器来均匀化稀疏数据的稀疏数据处理系统1100的实施例的示例框图。在一个实施例中,稀疏数据处理系统1100可以并行将ifm值和权重值相乘以并行地生成输出特征图(ofm)值,以计算卷积和向量乘矩阵乘法,如在2019年6月19日提交的名称为“神经处理器”、其全部内容通过引用合并于此的美国专利申请第16/446,610号(’610申请)中更详细地描述的。处理系统1100可以包括存储器1101、存储器读仲裁器1102、双端口高速缓存1103、高速缓存控制器1104、第一零扩展移位器1105、第二零扩展移位器1106、双端口fifo1107、先行稀疏控制器1108、乘法器单元阵列(mua)1109、蝶式混洗器1110、数据压缩器1111和存储器控制器1112。形成电路1100的各种组件(包括整个电路1100)可以被实现为一个或多个电路和/或被实现为一个或多个模块。存储器1101可以存储用于一个或多个输出特征图的ifm值。由于输出特征图通常充当用于神经网络模型中的下一层的输入特征图,因此可以将输出特征图称为输入特征图。存储器1101可以是易失性存储器和/或非易失性存储器。在一个实施例中,存储器1101可以对应于图6中描绘的存储器620,并且ifm值可以包括打包和压缩的非零值、零比特掩码数据和行指针数据,如本文其他地方所描述的。存储器1101的输出可以被输入到存储器读仲裁器1102。存储器读仲裁器1102可以在概念上对应于图9中所示的模块901。存储器读仲裁器1102的输出,包括ifm压缩数据、比特掩码、以及可选的行指针,可以被输入到高速缓存1103。高速缓存1103、零扩展移位器1105和1106以及fifo1107可以全部放置在乘法器单元阵列1109附近。高速缓存控制1104可以控制ifm值的接收以及将ifm值输出到第一零扩展移位器1105和第二零扩展移位器1106。可以用于第一输入特征图的一组ifm值可以被输出到第一零扩展移位器1105,而用于第二输入特征图的另一组ifm值可以被输出到第二零扩展移位器1106。零扩展移位器1105和1106可以被配置为基于ifm值中包括的零比特掩码数据将零值添加回ifm值。所得到的扩展的ifm数据可以是稀疏数据。零扩展移位器1105和1106可以在概念上对应于图9中的模块902、903和904。在扩展之后,ifm值被输入到双端口fifo1107,在’610申请中也称为ifm缓冲器。最多两个ifm像素可以被解包、膨胀、并同时输入双端口fifo。高速缓存控制器1104控制双端口高速缓存1103的输出,以使得fifo1107保持等待处理的像素队列(在’610申请中被称为ifm切片)。像素可以属于同一ifm,并且可以根据乘法器单元阵列1109的处理顺序进行排队,如’610申请中详述的。更具体地,在’610申请中公开的基准实施例控制fifo1107(ifm缓冲器)以避免将零值的激活发送到乘法器单元阵列1109。在每个通道中,当将被发送到乘法器阵列1109以进行计算的激活恰好具有零值时,fifo(ifm缓冲器)1107可以尝试查找并发送非零激活值而不是零值激活。查找非零激活可以包括:检查在同一通道中排队的下一个激活的值,以及检查相邻通道(即,当前通道上面的一个通道以及下面的一个通道)中的激活的值。如果找到非零值的激活,则该激活可以不按顺序发送到乘法器单元阵列1109,而不是发送零值的激活。然后,乘法器单元阵列1109将正确的权重应用于替代的非零值的激活,并使用额外的加法器树来正确计算所需的点积,如’610申请中更详细地描述的。与’610申请的基准实施例不同,图11a的实施例可以将对非零值的激活的搜索限制为仅在同一通道内,即,不对上面和下面一个通道进行旁视搜索,以减小电路面积和功率。然而,图11a中的fifo(ifm缓冲器)1107向乘法器单元阵列1109提供两组激活广播通道,其中,第一组激活通道广播当前排队的值(ifm切片),而第二组激活通道广播下一个(up-next)排队的值,即在基准实施例中将在下一个时钟周期中广播的值。乘法器单元阵列1109可以包括例如布置在16行和8列中的乘法器电路1120的阵列。每个乘法器电路120可以包括乘法器1121、第一输入复用器1122、第二输入复用器1123和输出复用器1124。第一输入复用器1122可以被配置为从双端口fifo(ifm缓冲器)1107接收两个ifm值。例如,在行0列0的乘法器1121的第一输入复用器可以接收用于信道0的ifm数据以及用于信道0的下一个ifm数据。第二输入复用器1123可以被配置为从本地权重寄存器文件(此处未示出,但在’610申请中被更详细地描述)接收两个权重值。例如,在行0列0的乘法器1121的第二输入复用器1123可以接收用于权重0和权重1的权重数据。先行稀疏控制器1108评估在双端口fifo1107中的通道中排队的ifm值,并控制第一复用器1122选择输入到第一复用器1122的非零ifm值作为第一操作数。另一个先行稀疏控制器(未示出)查看在本地权重寄存器文件(未示出)的通道中排队的权重值,并控制第二复用器1123选择输入到第二复用器1123的非零值权重作为第二操作数,即,如果权重为零或该通道中的激活为零,则跳过乘法。乘法器1121生成输入到乘法器1121的两个非零操作数的乘积。输出复用器1124被控制,以基于由先行稀疏控制器提供给第一输入复用器1122和第二输入复用器1123的控制,选择用于由乘法器1121生成的乘积的合适的加法器树(未示出)。双端口fifo1107、先行稀疏控制器1108和乘法器单元1109的操作的附加细节可以在’610申请中找到,其全部内容通过引用并入本文。乘法器单元1109的ofm输出被输入到蝶式混洗器1110。乘法器单元1109的ofm输出可以是非均匀稀疏数据。即,在稀疏数据中可能存在成簇的非零值。蝶式混洗器1110可以对数据进行混洗以生成均匀的稀疏数据。也就是说,从乘法器单元1109的8列输出的每个相应的ofm被输入到蝶式混洗器1110的对应输入,所述蝶式混洗器1110可以如图11b和11c所描绘的进行配置。注意,与图1a-图1b中的蝶式混洗器不同,图11c中的蝶式混洗器的更少的控制输入被绑在一起,因此能够进行更多的置换。蝶式混洗器1110可以包括图11b所描绘的多个复用器模块组件1150,以包括第一复用器1151和第二复用器1152。每个复用器1151和1152包括两个输入,每个输入接收n个比特。一组n比特a0被输入到复用器1151的“a”输入,并且一组n比特a1被输入到复用器1151的“b”输入。一组n比特b0被输入到复用器1152的“b”输入,并且一组n比特b1被输入到复用器1152的“a”输入。控制输入“x”被输入到复用器1151和1152两者。图11c描绘了根据本文公开的主题的蝶式混洗器1110的一个示例实施例的框图。蝶式混洗器1110可以包括32个2对1的8比特复用器模块1150,其布置在8行(r=0至r=7)和4列(c=0至c=3)的阵列中,并如图所示连接。每个相应的复用器模块1150可以接收控制信号x0..7,0..3。蝶式混洗器1110可以被控制为以逐个值为基础对数据进行混洗。如果从乘法器单元阵列1109输出的ofm数据是8比特数据,则蝶式混洗器1110的复用器模块1150可以被控制为混洗8比特数据。也就是说,与ofm数据的单个值相关联的比特在这些值被混洗时被保持在一起。例如,如果ofm数据是16比特数据,则蝶式混洗器1110的复用器被控制为混洗16比特数据,然后蝶式混洗器1110可以被配置为类似于图11d中描绘的蝶式混洗器。如图11d中所描绘的,蝶式混洗器1110的复用器可以由伪随机发生器1160以随机方式或伪随机方式控制,以使得ofm数据均匀化。在由伪随机值发生器控制mua1109输出的混洗的情况下,必须相应地离线对下一层权重进行预混洗,以匹配应用于输出激活的伪随机混洗序列,从而如在’610申请中所描述的,在下一层计算期间,ifm值正确地对应于将与预加载到乘法器单元阵列1109中的权重一起应用的相关联的权重。蝶式混洗器1110的ofm输出可以被输入到数据压缩器1111,该数据压缩器可以对应于图6a中所描绘的压缩器。数据压缩器1111的ofm输出可以被存储在存储器1101中。在一个实施例中,蝶式混洗器1110的ofm输出可以被输入到图6a中所描绘的零崩溃数据压缩器和打包电路600以通过移除零值并将数据打包以存储在存储器1101(或更确切地说,存储器620)中来压缩数据。图11a中的实施例与’610申请中公开的基准实施例之间的差异可能是出于多种考虑。首先,考虑sram1101和/或ifm交付结构的带宽可能受到限制的情况。更具体地说,某些层中的ifm值可能具有很高的稀疏度,例如,高达90%,以至于ifm值必须被更快地检索几次,即1/(100%-90%)=10,以使得提供足够的非零激活给mua1109以防止乘法器1121空转。相对于未压缩的ifm,通过ifm结构检索和发送压缩的ifm可能有助于提高乘法器利用率。在无法存储和发送压缩的ifm或ifm检索的速率仍然不足以保持乘法器利用率高的情况下,与’610申请相比,乘法器单元1120可以被配置为通过计算每个ifm输入切片的几个ofm切片结果(即,有效地进行’610申请中所描述的ofm循环)来生成更多的ofm值。参考图11a,第二个考虑可以是除了激活稀疏性之外,还利用权重稀疏性,即,当要被乘法器1121相乘的激活或权重(或两者)具有零值时,跳过乘法以及执行这些乘法的时间。更具体地,每个乘法器单元1120可以检查权重乘以通过第一组激活通道广播的激活是否为零,从而该乘法器单元可以取而代之地继续采用通过第二组激活通道广播的“下一个”激活,并且将其与相关联的权重相乘。以这种乱序的方式将激活乘以权重可能导致乘法器单元1120中的某一些在其他乘法器单元1120之前运行。因此,乘法器单元的输出可能需要重新同步,以使得每个乘法器单元列中的单独的乘积通过每个乘法器单元列中存在的加法器树而正确地减为点积。重新同步乘法器单元1120输出的一种方式可以包括添加小的输出fifo。重新同步乘法器单元1120输出的另一种方法可以是使领先其他乘法器单元1120相当多地运行的乘法器单元1120空转(即,由于稀疏性的波动),同时使ifm均匀地稀疏,诸如使用蝶式混洗器1110以伪随机方式在每个ofm切片内置换输出结果。注意,在零权重乘法和执行所述乘法的时间两者都被跳过的情况下,剩余要执行的乘法的数量可能会减少。在ifm以固定速率到达的情况下,乘法器1121的利用率将因此降低,因为由于在通过跳过涉及零权重的乘法而腾出的时间期间没有更多非零ifm值要处理,乘法器1121可能变得空闲。通过增加ifmsram和ifm交付结构带宽,可以逆转乘法器利用率的这种降低。如前所述,随着稀疏度从一个通道到另一个通道以及从一个ifm切片到另一个ifm切片波动,特别是当ifm带宽不足以使乘法器单元1120保持高利用率时,某些乘法器单元1120可能在其他乘法器单元1120之前运行,其中fifo1107充当ifm缓冲器,发送每个通道中当前和下一个非零激活,以使得在其他列(单元1120)之前运行的乘法器阵列列(或具有输出fifo的单独的乘法器单元1120)可以前进到计算下一个ofm切片,而不是等待其他列。每个乘法器阵列列可以在前进到下一个ifm切片之前计算例如2个ofm切片。针对每个ifm切片计算一个以上的ofm切片(ofm循环)需要相应地更少的ifm带宽以保持乘法器1121被利用。图12a描绘了根据本文公开的主题的示例实施例信道并行压缩器电路1200的框图,该信道并行压缩器电路1200提供对打包数据的随机写访问。图12b描绘了具有对由零崩溃数据压缩器和打包电路1200提供的压缩数据的随机访问的示例信道并行数据压缩。压缩器电路1200类似于图6a所描绘的零崩溃数据压缩器和打包电路600,具有以下区别。在压缩器电路1200中,非零值打包器602被蝶式混洗器1201和fifo1202替换。电路1200可以包括零值移除器601、蝶式混洗器1201、fifo1202、存储器写仲裁器603、零比特掩码生成器604、掩码打包器605和行指针生成器606。零值移除器电路601被替换为电路1220,以使得在电路601沿着通道索引维度单独地从每个ifm切片移除(崩溃)零的情况下,电路1220沿着时间序列索引维度从由相关联的通道接收的每个信道流独立地移除(崩溃)零。可以通过在每个输入通道上串联放置fifo缓冲器,来实现沿时间序列索引维度移除零的电路1220,从而当且仅当值不为零时,才将该值写入信道fifo。形成电路1200的各种组件(包括整个电路1200)可以被实现为一个或多个电路和/或实现为一个或多个模块。电路1200的操作类似于电路600的操作,并且结合电路600描述了许多操作细节。参考图12a和图12b,零值移除器601可以接收16个通道(即,lane0[7:0]-lane15[7:0])或信道的字节流数据1210。每个通道的字节流数据1210可以包括16个字节的未压缩的非零值数据和零值数据。非零值数据用交叉影线或阴影表示,并且零值数据用“0”表示。在一个实施例中,16个字节的数据可以对应于像素的数据。零值移除器1220可以被配置为如上所述从每个字节流1210中移除零值数据。零值移除器1220输出16个字节流str0[7:0]-str15[7:0],其中各个字节流被移除了零值。零值移除器1220的输出在图12a中的1211处针对示例输入1210被描绘。通常,在移除零值之后,各个字节流可以具有不同的长度。蝶式混洗器1201接收不同长度的字节流str0[7:0]-str15[7:0],并生成打包数据,在打包数据中不同长度的字节流已经被级联,如图13a-图13b所描绘的。图13a至图13c概念性地描绘了根据本文所公开的主题的,具有不同字节流长度的八个示例字节流被递归打包以成为各自具有相等的字节流长度的八个字节流。尽管此示例示出了8通道字节流,但16通道字节流以类似的方式工作。而且,该示例示出了如先前在图2a至图2c中所描述的以一个字节而不是一个比特的粒度(即,输入比特宽度)操作的蝶式混洗器。参考图1、图12a和图13a-图13b,在1301处描绘的八个示例字节流0-7通常具有不同的字节流长度,并且被输入到例如(为了方便)蝶式混洗器101的复用器10400至10470。图12a中的蝶式混洗器1201可以被配置为类似于图1c中的蝶式混洗器101。不同的字节流用不同的交叉影线描绘。字节流0-7被配对或分组为对应于输入复用器的配对的四对。在图13a的1302处,将每对中的更长字节流长度的一部分或头部通过蝶式混洗器101重新定位或重定向,以成为该对中的更短字节流的一部分,这是通过控制该对的复用器、以使得该对字节流具有相等的字节流长度来实现的。例如,字节流0的一部分被列c=0的复用器重定向,以变成字节流1的一部分。类似地,字节流2的一部分被重定向以变成字节流3的一部分。字节流4的一部分被重定向到字节流5,并且字节流7的一部分被重定向以成为字节流6的一部分。在一对字节流的字节流长度的差是奇数个字节的情况下,虚拟字节或填充字节可以被添加到所述两个字节流中的更短的一个。所述对内具有相等字节流长度的几对字节流在1303处被描绘,并从列c=0的复用器被输出。在1303处指示的不同的交叉影线区域表示已被重定向以变成另一个字节流的一部分的字节流部分。在图13b的1304处,将在对内具有相等字节流长度的字节流对输入到蝶式混洗器1201的第二列(列c=1)中的复用器10401至10471。所述字节流对被进一步配对或分组为与蝶式混洗器101的第二列中的复用器的配对相对应的两对的对(twopairsofpairs)。在1305处,通过控制第二列的复用器,将具有更长字节流长度的字节流对中的字节流中的每一个的一部分重新定位或重定向,以分别成为具有更短字节流长度的字节流对的一部分。例如,第一对的对(对的对1)的字节流中的每一个的一部分被第二列的复用器重定向以分别成为第一对的字节流对中的更短字节流的一部分。类似地,第二对的对(对的对2)的字节流中的每一个的一部分被第二列的复用器重定向以分别成为第二对的字节流对中的更短字节流的一部分。在一对的对内的具有相等的字节流长度的几对字节流对在1306处被描绘。在图13c中的1307处,具有相等的字节流长度的几对字节流对被输入到蝶式混洗器1201的第三列(列c=2)中的复用器10402至10472。所述几对字节流对被进一步配对或分组为与蝶式混洗器101的第三列中的复用器的配对相对应的字节流的对的四元组。在1308处,通过控制蝶式混洗器101的第三列的复用器,具有更长的字节流长度的字节流的对的四元组中的字节流中的每一个的一部分被重定位或重定向,以分别成为具有更短的字节流长度的字节流的对的四元组的一部分。例如,对的四元组中的字节流中的每一个的一部分被第三列的复用器重定向以分别成为字节流的对的四元组中的更短字节流的一部分。现在具有相等的字节流长度的字节流在1309处被描绘。存储器写仲裁器603,零比特掩码生成器604,掩码打包器605和行指针生成器606以类似于结合图6a中描绘的零崩溃数据压缩器和打包电路600所描述的方式操作,并且将在此不再描述。返回参考图12a和图12b,蝶式混洗器1201的输出被输入到fifo1202。对于示例输入1210,fifo1202的输出在1212处被描绘。随着fifo1202填充,并且随着掩码打包器605和行指针生成器606中的fifo填充,存储器写仲裁器603将数据写到存储器620中的各个区域。非零值数据1212已经由蝶式混洗器1201布置,以使得压缩和打包的数据1212以逐列的布置被存储。零比特掩码数据613和行指针数据614被如前所述地存储。更具体地,零比特掩码数据没有被存储为先前在图3a中示出的打包流302的一部分303。图14描绘了根据本文公开的主题的解包器和解压缩器电路1400的示例实施例的框图。解包器和解压缩器电路1400类似于图9所描绘的解包器和解压缩器电路900,具有以下区别。在解压缩器电路1400中,非零值解包器902被蝶式混洗器1401替换。零值插入器903被电路1420替换,以使得沿时间流索引维度向每个信道流中膨胀(重新插入零)。形成电路1400的各种组件(包括整个电路1400)可以被实现为一个或多个电路和/或实现为一个或多个模块。通过使用行指针数据614和零比特掩码数据613解包存储器620的存储器区域621中的非零值数据,电路1400通常与图12a的信道并行压缩器电路1200相反地操作。电路1400可以包括存储器读仲裁器901、蝶式混洗器1401、零值插入器1420和掩码解包器904。存储器读仲裁器901从存储器620读取非零值数据、行指针数据和比特掩码数据。非零值解包器902基于比特掩码数据解包打包数据。零值插入器1420也基于比特掩码数据将零值插入到解包数据中。先前描述的实施例可以使用零比特掩码技术来使用零比特掩码的一个比特来对零值进行编码。即,先前描述的实施例使用具有每比特掩码比特一个数据单元的开销的压缩技术。当使用8比特数据单元(即字节)时,压缩技术的开销是每一个字节的未压缩数据一个比特掩码比特。根据本文公开的主题,也可以使用不同的压缩粒度。例如,激活和/或权重数据可以主要具有小的绝对值。如果例如基于半字节(即4比特数据单元)使压缩的粒度更精细,则在此粒度级别上,激活和/或权重数据可能变得更加稀疏,因为激活和/或权重数据的许多最高有效半字节(msn)(即使对于非零激活和权重而言)也可以为零。基于每比特半字节压缩粒度的数据压缩可用于减少压缩掩码开销。或者,可以将更粗略的压缩粒度用于极其稀疏的数据,以减少压缩掩码开销。即,每比特两字节的掩码开销可以用于减少压缩掩码开销。图15示出了对于常见的示例卷积神经网络(cnn)(诸如谷歌的inceptionv3cnn)的三个不同压缩粒度1501-1503的压缩比的曲线图1500,其中所述cnn的权重被量化为int8数据类型并且激活被量化为uint8数据类型。示例cnn的层数沿曲线图1500的横坐标显示,而用百分比表示的激活的压缩比沿曲线图1500的纵坐标显示。纵坐标的比例可能会使得在一些地方难以看出压缩比的差异,因此在多个位置指示了用于不同压缩粒度1501-1503的压缩比。其他示例cnn可以为不同的压缩粒度提供相似的压缩比。用于示例的逐信道的半字节压缩粒度的压缩比在1501处被指示。用于逐信道的半字节压缩粒度的零比特掩码对于每个半字节使用一个比特掩码比特。用于采用转置技术的逐信道的一字节压缩粒度的压缩比在1502处被指示。用于一字节压缩粒度的零比特掩码对于每个字节的未压缩数据使用一个比特掩码比特。数据的数据单元可以是8比特数据的字节。用于一字节压缩粒度的转置技术将当前数据单元(例如,字节)和下一个逐信道的数据单元(例如,字节)的最高有效半字节转置为一起在相同的数据单元(例如,字节)中,然后将当前数据单元和下一个逐信道的数据单元的最低有效半字节转置为在下一个数据单元中。如图17所描绘的,图6a中所描绘的模块可以被修改为使用半字节粒度压缩数据,所述使用半字节粒度压缩数据是通过将每个传入字节分割成两个半字节(上下)、然后对半字节而不是字节进行操作。类似地,图6a中所描绘的模块可以被修改为使用两字节粒度压缩数据,所述使用两字节粒度压缩数据是通过将每个传入字节合并为一个16比特单元、然后对16比特单元而不是字节进行操作。也可以使用其他粒度,包括2比特、4字节等等。图16a描绘了根据本文公开的主题的用于8比特数据单元(即字节)的逐信道转置技术。在通道0中,原始的8比特数据可能包括0x020x070x080x0a...。在转置后,通道0的8比特数据现在可以布置为0x000x270x000x8a...,其中字节对0x02和0x07的两个最高有效半字节0x0和0x0形成字节0x00、并且两个最低有效半字节0x2和0x7形成字节0x27。在图16a的其他通道中发生类似的转置,即,获取每个传入字节对、并重新排列其半字节以将最高有效半字节拼接在一起并将最低有效半字节拼接在一起。图16b描绘了根据本文公开的主题的用于16比特数据的转置技术。在通道0中,原始的16比特数据可以包括0x020x070x080x0a...。在转置后,通道0的16比特数据现在可以布置为0x000x000x270x8a,即,每对传入的16比特值被分割为字节,然后将最高有效字节拼接在一起并且将最低有效字节拼接在一起。在图16b中的其他通道中发生类似的转置。可以使用的另一种转置技术是跨信道转置,其中相邻信道中的数据单元部分相互转置,这与在每个信道中独立于其他信道来拼接最高有效(或最低有效)半字节(或字节)相反。利用转置技术的每信道两字节压缩粒度的压缩比在图15中的1502处被指示。用于两字节压缩粒度的转置技术进行操作以转置两个当前数据单元和下一个逐信道的两个数据单元的最高有效半字节以使其一起在相同的两个数据单元中,然后,转置两个当前数据单元和下一个两个逐信道的数据单元的最低有效半字节以使其在下一个两个数据单元中。从曲线图1500可以看出,半字节压缩粒度1501通常向示例cnn的开始到中间层提供比其他两个压缩粒度更大的压缩比,如1504处所指示的。激活和/或权重通常在示例cnn的这个范围的层内具有适度的稀疏性。尤其是,当除具有适度的稀疏性的激活之外、激活具有绝对幅度小的值(即可以在字节(例如uint8)的最低半字节中编码的值1...15,同时该字节的最高半字节等于零)时,半字节粒度压缩的性能特别好。从cnn的中间层到端层,如图15中的1505处所指示,一字节压缩粒度1502通常提供最佳压缩比。在示例cnn的这个范围的层中,与层范围1504中的数据相比,激活和权重数据通常具有更高的稀疏性。在cnn的稀疏性最大的端层中(在1506处所指示的),两字节压缩粒度1503通常提供最佳压缩比。因此,选择压缩粒度可以优化cnn的给定层和/或给定范围的层以及权重内核的压缩比。图17描绘了根据本文公开的主题的,可以提供半字节压缩粒度的压缩电路1700的示例实施例的框图。压缩电路1700类似于图6a中描绘的压缩电路600,并且大体上以相同的方式操作。不同之处在于,零值移除器1701、非零值打包器1702、存储器写仲裁器1703和零比特掩码生成器1704可以被配置为对半字节而不是字节进行操作。当需要随机访问时,可以使用行指针生成器。图17描绘了在生成的行指针被省略的情况下不需要随机访问的情况。其他实施例可以被配置为对字节进行操作以作为压缩粒度和/或对多个字节进行操作以作为压缩粒度。形成电路1700的各种组件(包括整个电路1700)可以被实现为一个或多个电路和/或实现为一个或多个模块。表1的最左列示出了可以在第一时钟周期输入到电路1700的零值移除器1701的示例数据集合。中间列示出了基于示例输入数据集合的被输入到非零值打包器1702的零值移除器1701的输出。表1的最右列示出了针对示例输入数据集合在第二个时钟周期的零值移除器1701的输出。下表中的“x”表示“不关心(donotcare)”值。表1针对示例输入数据的从零比特掩码生成器1704输出的零比特掩码是01111101111000011100010010000111,其中“1”表示零值。表2的左列了示出了针对表1的示例数据输入的、将从存储器写仲裁器1703输出的、非零值打包器1702和掩码打包器1705的fifo中的打包数据和零比特掩码数据。表2的左列中的“x”表示fifo填充,但尚未填充。表2的右列示出了在将存储器写仲裁器1703的fifo中的数据写入存储器620之前(即,尚未将数据写入存储器620)的存储器620的内容。表2fifo打包存储器打包0x571219e1@0x00000x6a21513xxxxxxxxxxxxxxxxxfifo掩码存储器掩码0x7de1c487@0x1000xxxxxxxxxxxxxxxxxxxxxxxx表3的最左列示出了在第二时钟周期被输入到电路1700的零值移除器1701的下一示例数据。中间列是被输入到非零值打包器1702的来自零值移除器1701的输出。表3的最右列示出了在第三时钟周期的零值移除器1701的输出。表3针对示例输入数据从零比特掩码生成器1704输出的零比特掩码为10000010000111100011101100000000。表4的左列示出了针对表3的示例数据输入的、将从非零值打包器1702和掩码打包器1705的各个fifo输出到存储器写仲裁器1703的打包数据和零比特掩码数据。表4的右列示出了存储器620的内容。表4fifo打包存储器打包0xf272xxxx@0x0000xxxxxxxx0x571219e1xxxxxxxx0x6a21513axxxxxxxx0x1789112c0x221b9123fifo掩码存储器掩码0x7de1c487@0x10000x821e3d00xxxxxxxxxxxxxxxx表5的最左列示出了在第三时钟周期被输入到电路1700的零值移除器1701的下一示例数据。中间列是被输入到非零值打包器1702的零值移除器1701的输出。表5的最右列示出了在第四时钟周期的零值移除器1701的输出。表5针对示例输入数据从零比特掩码生成器1704输出的零比特掩码是00100111001100000100110001000010。表6的左列示出了针对表5的示例数据输入的、将从非零值打包器1702和掩码打包器1705的各个fifo输出到存储器写仲裁器1703的打包数据和零比特掩码数据。右列示出了存储器620的内容。表6fifo打包存储器打包0xf272fe96@0x00000xda5113550x571219e10x492bb9e80x6a21513a0x4xxxxxxx0x1789112c0x221b9123fifo掩码存储器掩码0x7de1c487@0x10000x821e3d000x27304a82xxxxxxxx表7的最左列示出了在第四时钟周期被输入到电路1700的零值移除器1701的示例数据集合。中间列是被输入到非零值打包器1702的零值移除器1701的输出。表7的最右列示出了在第五时钟周期的零值移除器1701的输出。表7针对示例输入数据从零比特掩码生成器1704输出的零比特掩码是01101000000000001100010011000001。表8的左列阐述了针对表7的示例数据输入的,将从非零值打包器1702和掩码打包器1705的各个fifo输出到存储器写仲裁器1703的打包数据和零比特掩码数据。右列示出了存储器620的内容。表8fifo打包存储器打包0x115a1b32@0x00000x7f7ad8880x571219e1xxxxxxxx0x6a21513axxxxxxxx0x1789112c0x221b9123@0x00010xf272fe960xda5113550x492bb9e80x425b924dfifo掩码存储器掩码xxxxxxxx@0x1000xxxxxxxx0x7de1c487xxxxxxxx0x821e3d00xxxxxxxx0x27304a820x6800c8c1图18描绘了根据本文公开的主题的可以与压缩电路1700一起使用的解压缩电路1800的示例实施例的框图。解压缩电路1800类似于图9所描绘的压缩电路900,并且通常以相同的方式操作。不同之处在于,非零值解包器1802和零值插入器1803可以被配置为对半字节而不是字节进行操作。另一个不同之处在于,在此特定示例中,直接内存访问被移除,并且行指针模块被省略。形成电路1800的各种组件(包括整个电路1800)可以被实现为一个或多个电路和/或实现为一个或多个模块。对存储器620中存储的打包数据执行随机访问的替代方法可以利用控制逻辑(未示出),该控制逻辑可以在数据被压缩的同时对零比特掩码中的零比特进行计数,并且可以形成查找表,所述查找表提供(即,存储在存储器620中的)未压缩数据中的偏移以及压缩数据的偏移。即,在偏移x处的未压缩数据已经被存储在物理地址y处。在一个实施例中,查找表粒度可以基于逻辑偏移条目,诸如0x0000、0x0040、0x0080等,以为每个表条目提供步骤0x0040。其他步骤可以被使用。可替换地,如果预先知道稍后将需要读取的地址,则可以基于那些地址来设置表条目。在又一替代实施例中,表结构可以被配置为类似于树结构。相对更小的步骤通常会增加表的大小,因此可以根据可用存储器来选择步长。为了在任意逻辑偏移x检索数据,可以在查找表中找到与x相对应的物理地址y。如果该表不包含准确的y(x),则查找xp和yp,以使得x紧随xp之后。然后比特掩码被读取以确定y(x),并且y(x)从存储器620被读取。表9示出了示例查找表。表9本文公开的各种实施例可用于压缩和解压缩数据以通过总线传输,而不是存储到存储器和从存储器检索。图19描绘了根据本文公开的主题的压缩电路1900的示例实施例的框图,该压缩电路1900可以提供半字节压缩粒度并且可以用于通过总线发送压缩数据。压缩电路1900类似于图17所描绘的压缩电路1700,并且通常以相同的方式操作。不同之处在于,总线发送fifo与仲裁器1903替代了存储器写仲裁器1703。除了输出压缩的打包数据之外,总线发送fifo与仲裁器1903还输出data_valid信号和mask_valid信号。当正被发送的bus_data是压缩的打包数据时,data_valid信号是有效(active)的,并且当正被发送的bus_data是零比特掩码数据时,mask_valid信号是有效的。当没有数据通过总线被发送时,data_valid信号和mask_valid信号两者均无效(inactive)。否则,压缩电路1900以与压缩电路1700相同的方式操作。形成电路1900的各种组件(包括整个电路1900)可以实现为一个或多个电路和/或实现为一个或多个模块。图20描绘了根据本文中公开的主题的解压缩电路2000的示例实施例的框图,该解压缩电路2000可以提供半字节压缩粒度并且可以用于通过总线接收压缩数据。解压缩电路2000类似于图18所描绘的解压缩电路1800,并且通常以相同的方式操作。不同之处在于,总线接收fifo2001替代了存储器读仲裁器1801。当正被接收的bus_data是压缩的打包数据时,data_valid信号有效,并且当正被接收的bus_data是零比特掩码数据时,mask_valid信号有效。当没有数据通过总线被接收时,data_valid信号和mask_valid信号两者均无效。否则,解压缩电路2000以与解压缩电路1800相同的方式操作。形成电路2000的各种组件(包括整个电路2000)可以被实现为一个或多个电路和/或实现为一个或多个模块。图21描绘了根据本文公开的主题的电子设备2100,所述电子设备2100可以包括使用蝶式混洗器的数据压缩器和/或数据解压缩器。电子设备2100可以用于但不限于计算设备、个人数字助理(pda)、膝上型计算机、移动计算机、网络平板计算机、无线电话、蜂窝电话、智能电话、数字音乐播放器、或有线或无线电子设备。电子设备2100可以包括通过总线2150彼此耦合的控制器2110、输入/输出(i/o)设备2120(诸如但不限于小键盘、键盘、显示器、触摸屏显示器、相机和/或图像传感器)、存储器2130和接口2140。控制器2110可以包括例如至少一个微处理器、至少一个数字信号处理、至少一个微控制器等。存储器2130可以被配置为存储要由控制器2110使用的命令代码或用户数据。电子设备2100和电子设备2100的各种系统组件可以包括根据本文公开的主题的使用蝶式混洗器的数据压缩器和/或数据解压缩器。接口2140可以被配置为包括无线接口,该无线接口被配置为使用rf信号向无线通信网络发送数据或从无线通信网络接收数据。无线接口可以包括例如天线、无线收发器等。电子设备2100也可以用在通信系统的通信接口协议中,诸如但不限于、码分多址(cdma)、全球移动通信系统(gsm)、北美数字通信(nadc)、扩展时分多址(e-tdma)、宽带cdma(wcdma)、cdma2000、wi-fi、市政wi-fi(muniwi-fi)、蓝牙、数字增强型无绳电信(dect)、无线通用串行总线(wirelessusb)、快速低延迟访问无缝切换的正交频分复用(flashofdm)、ieee802.20、通用分组无线业务(gprs)、iburst、无线宽带(wibro)、wimax、先进的wimax、通用移动电信服务–时分双工(umts-tdd)、高速分组访问(hspa)、演进数据优化(evdo)、先进的高级长期演进(先进的lte)、多信道多点分发服务(mmds)等。本说明书中描述的主题的实施例和操作可以在数字电子电路中实施,或在计算机软件、固件或硬件(包括本说明书中公开的结构及其结构等同物)中实施,或者以它们中的一个或多个的组合来实施。本说明书中描述的主题的实施例可以被实施为一个或多个计算机程序,即,计算机程序指令的一个或多个模块,其被编码在计算机存储介质上以由数据处理装置执行或控制数据处理装置的操作。可替换地或额外地,程序指令可以被编码在人工生成的传播信号上,例如机器生成的电、光或电磁信号,其被生成以对信息进行编码以传输到合适的接收器装置以由数据处理装置执行。计算机存储介质可以是或可以包括在计算机可读存储设备、计算机可读存储基板、随机或串行存取存储器阵列或设备或其组合中。此外,尽管计算机存储介质不是传播信号,但是计算机存储介质可以是被编码在人工生成的传播信号中的计算机程序指令的源或目的地。计算机存储介质也可以是一个或多个单独的物理组件或介质(例如,多个cd、磁盘或其他存储设备)或包括在其中。本说明书中描述的操作可以被实施为由数据处理装置对存储在一个或多个计算机可读存储设备上或从其他源接收到的数据执行的操作。术语“数据处理装置”涵盖用于处理数据的所有种类的装置、设备和机器,例如包括可编程处理器、计算机、片上系统、或前述的多个或组合。该装置可以包括专用逻辑电路,例如,fpga(现场可编程门阵列)或asic(专用集成电路)。除了硬件之外,该装置还可以包括为计算机程序创建执行环境的代码,例如,构成处理器固件、协议栈、数据库管理系统、操作系统、跨平台运行时环境、虚拟机或其组合的代码。装置和执行环境可以实现各种不同的计算模型基础设施,诸如网络服务、分布式计算和网格计算基础设施。计算机程序(也被称为程序、软件、软件应用、脚本或代码)可以任何形式的编程语言来编写,包括编译语言或解释语言、说明性语言或过程语言,并且计算机程序可以任何形式部署,包括作为独立程序部署或作为模块、组件、子例程、对象或适合用于计算环境中的其他单元部署。计算机程序可以但不需要对应于文件系统中的文件。程序可存储在持有其他程序或数据(例如,存储在标记语言文档中的一个或多个脚本)的文件的一部分中,存储在专用于所讨论的程序的单个文件中,或者存储在多个协调文件(例如,存储代码的一个或多个模块、子程序或部分的文件)中。计算机程序可以被部署成在一个计算机上执行或者在位于一个站点或分布在多个站点中且由通信网络互连的多个计算机上执行。本说明书中描述的过程和逻辑流可以由执行一个或多个计算机程序的一个或多个可编程处理器执行以通过对输入数据进行操作以及生成输出来执行动作。适合于计算机程序的执行的处理器包括例如通用微处理器和专用微处理器二者以及任何种类的数字计算机的任何一个或多个处理器。通常,处理器可以从只读存储器或随机存取存储器或者从二者接收指令和数据。计算机的关键元件是用于根据指令执行动作的处理器以及用于存储指令和数据的一个或多个存储器设备。通常,计算机还将包括用于存储数据的一个或多个大容量存储设备(例如,磁盘、磁光盘或光盘)或者可操作性地耦合到一个或多个大容量存储设备以便从其接收数据或向其发送数据或兼而有之。然而,计算机并非必须具有这种设备。此外,计算机可嵌入在另一个设备中,例如移动电话、个人数字助理(pda)、移动音频或视频播放器、游戏机、全球定位系统(gps)接收器或便携式存储设备(例如,通用串行总线(usb)闪存驱动器),这只是列举几个例子。适合于存储计算机程序指令和数据的设备包括所有形式的非易失性存储器、介质和存储器设备,包括例如:半导体存储器设备,例如,eprom、eeprom和闪存设备;磁盘,例如内部硬盘或可移动盘;磁光盘;和cd-rom盘和dvd-rom盘。处理器和存储器可由专用逻辑电路补充或并入专用逻辑电路中。为提供与用户的交互,本说明书所描述主题的实施例可在具有向用户显示信息的显示设备(例如,crt(阴极射线管)或lcd(液晶显示器)监视器)以及可供用户向计算机提供输入的键盘和指向设备(例如,鼠标或轨迹球)的计算机上实施。也可使用其他种类的设备来提供与用户的交互;例如,向用户提供的反馈可为任何形式的感觉反馈,例如,视觉反馈、听觉反馈或触觉反馈;并且来自用户的输入可以包括声音输入、语音输入或触觉输入在内的任何形式接收。本说明书中描述的主题的实施例可实施在以下计算系统中:包括后端组件(例如,作为数据服务器)的计算系统;或包括中间件组件(例如,应用服务器)的计算系统;或包括前端组件(例如,具有图形用户界面或网络浏览器的用户计算机,用户可通过所述图形用户界面或网络浏览器与本说明书描述的主题的实施方式交互)的计算系统;或者包括一个或多个这种后端组件、中间件组件或前端组件的任何组合的计算系统。系统的组件可通过数字数据通信的任何形式或介质(例如通信网络)进行互连。通信网络的示例包括局域网(lan)和广域网(wan)、互联网络(例如,互联网)和对等网络(例如,adhoc对等网络)。计算系统可以包括用户和服务器。用户与服务器通常彼此相距遥远且通常通过通信网络进行交互。用户与服务器的关系是通过在相应的计算机上运行且彼此具有用户-服务器关系的计算机程序建立的。尽管本说明书含有许多具体实施细节,然而这些具体实施细节不应被视为对任何发明的范围或者可要求保护的范围的限制,而是应被视为对特定于特定发明的特定实施例的特征的描述。在本说明书中在单独实施例的上下文中描述的某些特征也可以在单个实施例中组合实施。相反,在单个实施例的上下文中描述的各种特征也可以在多个实施例中分开实施或者以任何适合的子组合实施。此外,尽管以上将特征描述为以某些组合发挥作用且甚至在开始时便主张如此,然而所要求保护的组合中的一个或多个特征在一些情形中可从所述组合去除,且所要求保护的组合可针对子组合或子组合的变形。因此,本主题的特定实施例已经被描述。其他实施例在所附权利要求的范围内。在一些情况下,权利要求中记载的动作可以以不同的顺序执行并且仍能实现期望的结果。类似地,尽管在附图中以特定顺序示出了操作,然而这不应被理解为需要以图中所示的顺序或以顺序性次序来执行这些操作或者需要执行所有所示出的操作来实现期望的结果。在某些情形中,多任务和并行处理可以是有利的。此外,上述实施例中的各种系统组件的分离不应被理解为在所有实施例中均需要这种分离,并且应该理解,所描述的程序组件及系统通常可以一起集成在单个软件产品中或者封装到多个软件产品中。如所属领域中的技术人员将认识到的,可以在各种各样的应用中对本文所描述的创新构思进行修改及变化。因此,所要求保护的主题的范围不应限于以上所论述的任何具体示例性教导,而是由所附权利要求定义。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1