一种基于多智能体深度强化学习的无人机网络悬停位置优化方法与流程
本发明涉及无线通信技术领域,特别涉及一种基于多智能体深度强化学习的多无人机网络悬停位置优化方法。
背景技术:
近年来,由于无人机的高机动性、易部署性和低成本,基于无人机的通信技术引起了广泛的关注,成为了无线通信领域的一个新的研究热点。无人机辅助通信技术主要有以下几个应用场景:无人机作为移动基站为基础设施稀少或灾后地区提供通信覆盖、无人机作为中继节点为相距较远的无法直接建立连接的两个通信节点提供无线连接、基于无人机的数据分发和采集。本发明主要针对第一个场景,在该场景中,无人机的悬停位置决定了整个无人机网络的覆盖性能和吞吐量大小。无人机网络所服务的地面设备可能具有移动性,因此无人机需要不断地调整自身的悬停位置以实现最优的性能。
2018年,qingqingwu等人在论文《jointtrajectoryandcommunicationdesignformulti-uavenabledwirelessnetworks》中提出一种多无人机对地通信系统的uav路径规划方案,将时间划分为多个周期,每个周期uavs的移动轨迹是相同的,在每个时隙,无人机基站服务特定的地面用户。该方案将优化问题建模为混合整数规划问题,并使用块坐标梯度下降和近似凸优化技术进行求解,求得周期内每个时间片的最优悬停位置,最大化和地面用户间的下行链路吞吐量。但是,该论文提出的方案只适用于静态环境,是假设地面设备不具备移动性的条件下进行的,并不适用于地面用户不断移动的场景。chiharoldliu等人在论文《energy-efficientuavcontrolforeffectiveandfaircommunicationcoverage:adeepreinforcementlearningapproach》提出了一种基于深度强化学习的uav路径规划算法,通过深度强化学习方法训练出了一个决策模型,该模型根据当前状态输出uavs下一步的决策(移动方向、移动距离)。该论文提出的方法能够实现大范围区域的公平无线覆盖,并尽可能减少uavs的能耗。但是,该方法仅仅考虑了uavs网络的覆盖性能,且是针对区域的粗粒度覆盖公平,而不是针对用户的细粒度覆盖公平。此外,该方法是一种集中式的方案,需要一个控制器在每个时隙收集所有无人机的信息,才能做出决策。
综上所述,基于无人机基站的对地通信网络中的uavs路径规划技术主要有如下缺陷:(1)没有考虑环境的动态性,即地面用户的移动性。(2)采用的是集中式的算法,依赖全局信息和集中式控制,某些大范围的场景中,进行集中式控制是较为困难的,因此需要一种分布式的控制策略,每个无人机基站仅靠自己获得的信息做出决策。(3)忽略了考虑用户层次的服务公平性。这些缺陷使得现有的无人机网络中的uavs轨迹优化方法无法适用于实际通信环境。
技术实现要素:
本发明的目的是提出一种基于多智能体强化学习的多无人机悬停位置优化方法,以解决上述技术问题。
本发明的技术方案:
一种基于多智能体深度强化学习的无人机网络悬停位置优化方法,步骤如下:
(1)建立多无人机対地通信网络模型,主要包括以下4个步骤:
(1.1)建立场景模型:建立一个边长为l的正方形目标区域,该区域中有n个地面用户和m个无人机基站(uav-bss),这些无人机基站为地面用户提供通信服务。时间被划分为t个相同的时隙,从上一时隙到当前时隙,地面用户可能静止也可能发生移动,因此无人机基站需要在每个时隙寻找新的最优悬停位置,并在到达目标位置后选择地面用户进行数据传输服务。
(1.2)建立空对地通信模型:本发明使用空对地信道模型对无人机基站和地面用户之间的信道进行建模,无人机基站由于高飞行高度,相比于地面基站更容易与地面用户建立视距链路(los),在los情况下,无人机基站m和地面用户n之间的路径损耗模型为:
其中η表示额外路径损耗系数,c表示光速,fc表示子载波频率,α表示路径损失指数,
其中σ表示加性高斯白噪声,pt表示无人机基站的发射功率,gn,m(t)表示t时刻无人机基站m和地面用户n之间的信道增益。
(1.3)建立覆盖模型:由于硬件限制,每个无人机基站的覆盖范围是有限的。本发明定义了最大可容忍路径损失lmax,如果某一时刻无人机基站和用户之间路径损失小于lmax,我们认为建立的连接是可靠的,否则,我们认为建立连接失败。因此,可以根据最大可容忍路径损耗定义出每个无人机基站的有效覆盖范围,该范围以无人机基站在地面的投影点为圆心,以rcov为半径,根据路径损失公式,rcov可以表示为:
(1.4)建立能量损耗模型:本发明主要关注无人机移动造成的能量损耗,考虑无人机的飞行速度v以及飞行功率pf,无人机基站m在时隙t的飞行能耗取决于飞行的距离:
其中
(2)将问题建模为局部可观测马尔科夫决策过程:
每个无人机基站相当于一个智能体;在每一个环境状态为s(t)的时隙中,智能体m在仅能获得自身覆盖范围内的局部观察om,并根据决策函数um(om),从动作集a中选择动作am,以最大化折扣总期望奖励
系统状态集合s={s(t)|s(t)=(su(t),sg(t))},分别包含无人机基站的当前状态
无人机动作集合a={a(t)|a(t)=(θ(t),d(t))},在时隙t,无人机m需要在得到当前局部观察信息后做出决策am(t),移动到下一个悬停位置,因此动作集合包括飞行旋转角度θ(t)和移动距离d(t)。
系统及时奖励r(t):本文的目标是在考虑用户服务公平性和能耗的同时,最大化无人机网络的吞吐量。因此,在每个时刻t通过调整无人机悬停位置所产生的额外吞吐量是一个正项奖励,表示为:
δc(t)=c(su(t+1),sg(t))-c(su(t),sg(t))
其中c(su(t),sg(t))表示无人机基站状态为su(t),地面用户状态为sg(t)时网络产生的吞吐量。c(su(t+1),sg(t))则表示无人机基站状态为su(t+1),地面用户状态为sg(t)时网络产生的吞吐量。考虑到用户服务的公平性,如果某个区域聚集有大量用户,而某个区域只有一个用户,无人机基站为了追求最大化吞吐量会一直悬停在高密度区域,而忽略低密度区域,因此本发明为每个用户的吞吐量奖励施加一个权重wn(t)实现比例公平调度。rreq表示的是地面用户需求的最小通信速率要求,rn(t)表示的是地面用户n从开始阶段到时刻t的平均通信速率。当无人机基站服务该用户时,rn(t)增长,该用户的权重会逐渐变小;若该用户没有被服务到,则rn(t)减小,该用户权重不断增大。因此,用户稀疏地区的奖励权重会不断增大,吸引无人机基站进行服务。
其中,an,m(t)是一个指示变量,在t时刻,如果无人机基站m服务地面用户用户n,那么an,m(t)=1,因此,综合考虑公平性吞吐量奖励和能耗损失惩罚,本发明给出系统实时奖励r(t):
其中α表示能耗惩罚所占的权重,α越大,则该系统在决策时更注重能耗损失,反之则越忽略能耗损失。
局部观察集合o(t)={o1(t),…,om(t)},当多无人机基站在一个大范围区域协同工作时,每个无人机无法观察到全局信息,只能观察到自身覆盖范围内的地面用户信息。om(t)表示t时刻无人机基站m所观察到的处于自己覆盖范围内的地面用户的位置信息。
(3)基于多智能体深度强化学习算法进行训练:
本发明将多智能体深度强化学习算法maddpg引入到无人机对地通信网络悬停位置优化中,采用集中式训练和分布式执行的架构,在训练时使用全局信息,更好地指导每个无人机的决策函数的梯度更新,在执行时每个无人机仅使用自己观察到的局部信息做出下一步决策,更贴合实际场景的需要;每个智能体采用了actor-critic架构的ddpg网络进行训练,策略网络用来拟合策略函数u(o),输入局部观察o,输出动作策略a;评价网络用来拟合状态-动作函数q(s,a),表示在系统状态为s时,采取动作a所获得的期望奖励;令u={u1,…,um}表示m个智能体的确定性策略函数,
(3.1)初始化经验回放空间,设置经验回放空间大小,初始化每个ddpg网络的参数,训练回合数等
(3.2)从训练回合epoch=1开始,从时刻t=1开始。
(3.3)获取当前无人机的局部观察信息o和整个系统当前状态s;每个无人机m使用t时隙得到的局部观察信息,基于∈贪婪策略和ddpg网络输出决策信息am调整悬停位置,并根据和地面用户间的路径损耗,基于贪婪方案选择路径损耗最低的w个地面用户进行通信服务,得到瞬时回报奖励r,达到下一系统状态s′并获得局部观察信息o′;将(s,o,a,r,s′,o′)作为样本存入经验回放空间,a={a1,…,am}表示所有无人机的联合动作,o={o1,…,om}表示所有无人机的局部观察信息,t=t+1。
(3.4)若回放空间存储的样本数量大于b,到达步骤3.5;否则,继续收集样本,返回步骤3.3。
(3.5)对每个智能体m,从经验回放空间中随机采样固定数量k的样本,计算目标值,其中第k个样本(sk,ok,ak,rk,s′k,ok)的目标值yk可以表示为:
根据评价网络和样本信息,基于样本的策略梯度,更新该智能体策略网络的参数:
(3.6)间隔一定回合后,即,更新目标网络参数θq′和θu′:θq′=τθq+(1-τ)θq′,θu′=τθu+(1-τ)θu′。当达到总时长t或无人机能量耗尽后,退出当前训练回合,否则,返回步骤3.3。若训练回合数已到,则退出训练过程,否则进入新的训练回合。
(4)将训练好的策略网络u分配给每个无人机,将无人机部署到目标区域,每个无人机在每个时隙根据自身的局部观察调整悬停位置,并对地面用户进行通信服务。
本发明的有益效果:本发明提出一种基于多智能体深度强化学习的无人机网络悬停位置优化方法,将无人机对地通信网络场景下的吞吐量最大化问题建模为局部可观察马尔可夫决策过程,引入多智能体深度强化学习方法maddpg进行集中式训练和分布式执行,解决动态环境下无人机悬停位置优化问题。该方法使得无人机集群能够更好的适应动态环境,且多个无人机不依赖集中式控制器,能够以分布式的方式进行协作,本发明在即时奖励函数构建中引入了比例公平权重和能耗损失信息,在提高吞吐量的同时一定程度上保证了用户服务的公平性和无人机集群的低能耗。
附图说明
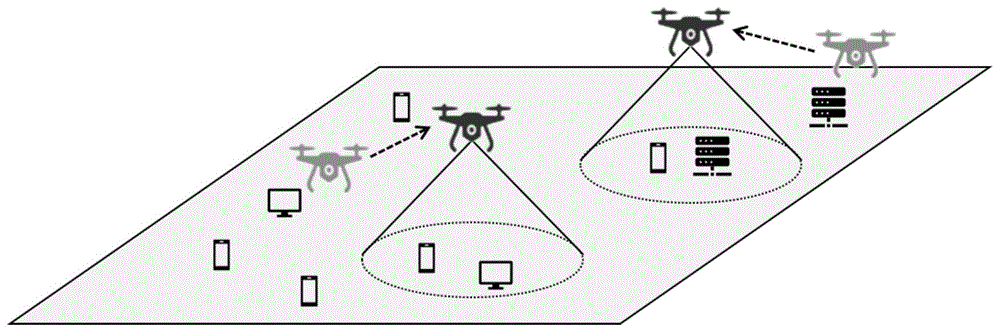
图1是本发明所述的无人机对地通信网络场景示意图。
图2是本发明一种基于多智能体深度强化学习的无人机网络悬停位置优化方法的流程图。
图3是本发明基于多智能体深度强化学习的训练无人机分布式策略网络的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
一种基于多智能体深度强化学习的无人机网络悬停位置优化方法,应用于缺少地面基础设施或灾后地区的紧急通信恢复。如图1所示,该区域缺少基础通信设施,由无人机作为移动基站进行通信覆盖,地面环境是动态变化的,地面设备可能会发生移动,无人机基站需要不断调整自身的悬停位置,以实现更好的通信服务(最大化系统的吞吐量)。同时还要考虑服务的公平性和能耗损失,不能因为追求吞吐量最大化而忽略某些地面用户,并尽可能减少无人机基站移动所造成的能耗损失。本发明的流程如图2所示,首先,对具体的应用场景中的通信模型、覆盖模型和能耗模型等进行建模并构建优化目标;其次,根据优化目标和多无人机系统特性将优化问题建模为局部可观测马尔科夫决策过程;然后,使用仿真平台模拟多无人机对地通信场景,通过无人机集群和环境的交互采集样本,使用多智能体深度强化学习算法maddpg进行集中式训练,得到每个无人机的分布式策略。最后,将训练好的策略网络部署到无人机中,将无人机集群部署到目标区域,无人机互相协作完成高吞吐量、低能耗、公平的通信覆盖。
具体步骤如下:
(1)建立多无人机対地通信网络模型,主要包括以下4个步骤:
(1.1)建立场景模型:建立一个边长为l的正方形目标区域,该区域中有n个地面用户和m个无人机基站(uav-bss),这些无人机基站为地面用户提供通信服务。时间被划分为t个相同的时隙,从上一时隙到当前时隙,地面用户可能静止也可能发生移动,因此无人机基站需要在每个时隙寻找新的最优悬停位置,并在到达目标位置后选择地面用户进行数据传输服务。
(1.2)建立空对地通信模型:本发明使用空对地信道模型对无人机基站和地面用户之间的信道进行建模,无人机基站由于高飞行高度,相比于地面基站更容易与地面用户建立视距链路(los),在los情况下,无人机基站m和地面用户n之间的路径损耗模型为:
其中η表示额外路径损耗系数,c表示光速,fc表示子载波频率,α表示路径损失指数,
其中σ表示加性高斯白噪声,pt表示无人机基站的发射功率,gn,m(t)表示t时刻无人机基站m和地面用户n之间的信道增益。
(1.3)建立覆盖模型:由于硬件限制,每个无人机基站的覆盖范围是有限的。本发明定义了最大可容忍路径损失lmax,如果某一时刻无人机基站和用户之间路径损失小于lmax,我们认为建立的连接是可靠的,否则,我们认为建立连接失败。因此,可以根据最大可容忍路径损耗定义出每个无人机基站的有效覆盖范围,该范围以无人机基站在地面的投影点为圆心,以rcov为半径,根据路径损失公式,rcov可以表示为:
(1.4)建立能量损耗模型:本发明主要关注无人机移动造成的能量损耗,考虑无人机的飞行速度v以及飞行功率pf,无人机基站m在时隙t的飞行能耗取决于飞行的距离:
其中
(2)将问题建模为局部可观测马尔科夫决策过程:
每个无人机基站相当于一个智能体;在每一个环境状态为s(t)的时隙中,智能体m在仅能获得自身覆盖范围内的局部观察om,并根据决策函数um(om),从动作集a中选择动作am,以最大化折扣总期望奖励
系统状态集合s={s(t)|s(t)=(su(t),sg(t))},分别包含无人机基站的当前状态
无人机动作集合a={a(t)|a(t)=(θ(t),d(t))},在时隙t,无人机m需要在得到当前局部观察信息后做出决策am(t),移动到下一个悬停位置,因此动作集合包括飞行旋转角度θ(t)和移动距离d(t)。
系统及时奖励r(t):本文的目标是在考虑用户服务公平性和能耗的同时,最大化无人机网络的吞吐量。因此,在每个时刻t通过调整无人机悬停位置所产生的额外吞吐量是一个正项奖励,表示为:
δc(t)=c(su(t+1),sg(t))-c(su(t),sg(t))
其中c(su(t),sg(t))表示无人机基站状态为su(t),地面用户状态为sg(t)时网络产生的吞吐量。c(su(t+1),sg(t))则表示无人机基站状态为su(t+1),地面用户状态为sg(t)时网络产生的吞吐量。考虑到用户服务的公平性,如果某个区域聚集有大量用户,而某个区域只有一个用户,无人机基站为了追求最大化吞吐量会一直悬停在高密度区域,而忽略低密度区域,因此本发明为每个用户的吞吐量奖励施加一个权重wn(t)实现比例公平调度。rreq表示的是地面用户需求的最小通信速率要求,rn(t)表示的是地面用户n从开始阶段到时刻t的平均通信速率。当无人机基站服务该用户时,rn(t)增长,该用户的权重会逐渐变小;若该用户没有被服务到,则rn(t)减小,该用户权重不断增大。因此,用户稀疏地区的奖励权重会不断增大,吸引无人机基站进行服务。
因此,综合考虑公平性吞吐量奖励和能耗损失惩罚,本发明给出系统实时奖励r(t)
其中α表示能耗惩罚所占的权重,α越大,则该系统在决策时更注重能耗损失,反之则越忽略能耗损失。
局部观察集合o(t)={o1(t),…,om(t)},当多无人机基站在一个大范围区域协同工作时,每个无人机无法观察到全局信息,只能观察到自身覆盖范围内的地面用户信息。om(t)表示无人机基站m所观察到的处于自己覆盖范围内的地面用户的位置信息。
(3)基于多智能体深度强化学习算法进行训练:
本发明将多智能体深度强化学习算法maddpg引入到无人机对地通信网络悬停位置优化中,采用集中式训练和分布式执行的架构,在训练时使用全局信息,更好地指导每个无人机的决策函数的梯度更新,在执行时每个无人机仅使用自己观察到的局部信息做出下一步决策,更贴合实际场景的需要;每个智能体采用了actor-critic架构的ddpg网络进行训练,策略网络用来拟合策略函数u(o),输入局部观察o,输出动作策略a;评价网络用来拟合状态-动作函数q(s,a),表示在系统状态为s时,采取动作a所获得的期望奖励;令u={u1,…,um}表示m个智能体的确定性策略函数,
(3.1)初始化经验回放空间,并设置经验回放空间大小b,初始化每个ddpg网络的参数θ,训练回合数p,时长t等
(3.2)从训练回合epoch=1开始,从时刻t=1开始。
(3.3)获取当前无人机的局部观察信息o和整个系统当前状态s;每个无人机m使用t时隙得到的局部观察信息,基于∈贪婪策略和ddpg网络输出决策信息am调整悬停位置,并根据和地面用户间的路径损耗,基于贪婪方案选择路径损耗最低的w个地面用户进行通信服务,得到瞬时回报奖励r,达到下一系统状态s′并获得局部观察信息o′;将(s,o,a,r,s′,o′)作为样本存入经验回放空间,a={a1,…,am}表示所有无人机的联合动作,o={o1,…,om}表示所有无人机的局部观察信息,t=t+1;
(3.4)若回放空间存储的样本数量大于b,到达步骤3.5;否则,继续收集样本,返回步骤3.3。
(3.5)对每个智能体m,从经验回放空间中随机采样固定数量k的样本,计算目标值,其中第k个样本(sk,ok,ak,rk,s′k,ok)的目标值yk可以表示为:
根据评价网络和样本信息,基于样本的策略梯度,更新该智能体策略网络的参数:
(3.6)间隔一定回合后,更新评价目标网络参数θq′和策略目标网络参数θu′:θq′=τθq+(1-τ)θq′,θu′=τθu+(1-τ)θu′。当达到总时长t或无人机能量耗尽后,退出当前训练回合,否则,返回步骤3.3。若训练回合数已到,则退出训练过程,否则进入新的训练回合。
(4)将训练好的策略网络u分配给每个无人机,将无人机部署到目标区域,每个无人机在每个时隙根据自身的局部观察调整悬停位置,并对地面用户进行通信服务。
综上所述:
本发明提出一种基于多智能体深度强化学习的无人机网络悬停位置优化方法,通过将多无人机对地通信场景中的吞吐量最大化问题建模为局部可观测马尔科夫决策过程,并使用maddpg算法进行解决,使得无人机集群能够适应动态环境,进行分布式协作,实现网络的高吞吐量、低能耗和服务公平性。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!