一种移动边缘计算网络下内容缓存和用户关联优化方法与流程
本发明涉及边缘计算领域,具体是一种移动边缘计算网络下内容缓存和用户关联优化方法。
背景技术:
随着自动化程度的不断提高和智能移动设备的迅速普及,用户对互联网内容(如视频、音频内容等)需求日益密切,移动网络流量呈现爆发式增长趋势。传统以云服务器为中心的存储模式,由于请求内容离用户较远,在面对海量用户请求时,会产生高额的内容传输成本,难以满足用户对高质量服务的需求。移动边缘计算作为一种新型的计算模式,通过下沉计算、存储资源到网络边缘来提高用户的服务质量。在移动边缘计算网络环境下,边缘服务器可以部署在基站中或者基站附近,互联网厂商通过将热点内容缓存在边缘服务器中,以减少内容获取的传输成本。
近年来,5g互联网通信技术取得了实质性的突破,为了实现对热点区域的全面覆盖和提高流量峰值时期用户服务质量,基站的密集部署已经成为一种合理的解决方案。在超密集移动边缘计算系统中,如何联合优化内容缓存和用户关联,以降低边缘计算系统中内容获取的传输成本已经成为了一个热门的研究问题。目前普遍采用的策略是在边缘服务器中缓存最流行的内容,将用户与信号功率最强的基站关联,但是这种模式存在着一些难以解决的问题:第一:内容流行度难以预测且时空差异明显,难以捕获用户的实时请求。第二:用户总是试图与信号最强的服务器关联,容易导致基站之间的负载失衡。第三:在用户动态移动的场景下,内容缓存和用户关联没有联合考虑,会导致用户与基站之间频繁切换,降低用户服务质量,导致整个移动边缘计算网络效率低下。
技术实现要素:
本发明的目的是提供一种移动边缘计算网络下内容缓存和用户关联优化方法,包括以下步骤:
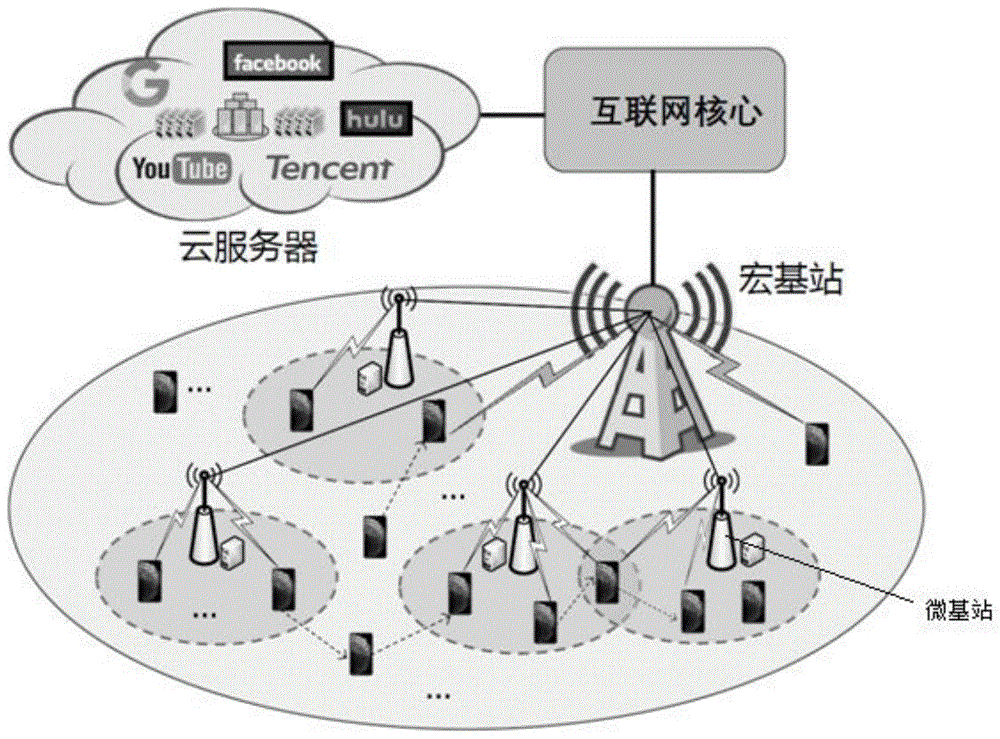
1)建立超密集移动边缘计算系统。所述超密集移动边缘计算系统包括远程云服务器、宏基站、m个不同密集部署的微基站、n个移动设备和c个内容文件。其中,每个微基站均具有边缘服务器。
2)获取当前移动网络中所有移动用户、边缘服务器的信息数据。
所述移动用户和边缘服务器的信息数据包括边缘服务器的缓存大小dm、边缘服务器最大服务用户数zm、内容文件大小vc、用户的移动路径矩阵xn×t、用户的内容请求矩阵yn×t和状态转移矩阵bm×m。边缘服务器序号m=1,2,…,m。m为边缘服务器总数。内容文件序号c=1,2,…,|c|;|c|为内容文件总数;c为内容文件集合。
3)初始化时刻t=0。初始化超密集移动边缘计算系统的参数,令所有的边缘服务器内容缓存策略a=0,移动用户关联策略b=0。其中a=0表示边缘服务器不缓存内容文件,b=0表示边缘服务器与移动用户不关联。
所述超密集移动边缘计算系统参数包括观测时间ε、最大容忍访问间隔σ和内容优先级系数p。
4)确定当前t时刻的内容缓存策略at和用户关联策略bt。
确定当前t时刻的内容缓存策略at和用户关联策略bt的步骤如下:
4.1)初始化当前t时刻的用户关联策略bt。确定每个边缘服务器服务范围内的移动用户。将剩余最大服务用户数的边缘服务器与位于边缘服务器服务范围内的移动用户相关联。将不在边缘服务器服务范围内的移动用户与宏基站相关联。
4.2)移除每个微基站中过时的内容文件。在观测时间ε内平均访问次数
4.3)计算第c个内容文件与第m个微基站之间的适应度
4.3.1)建立t时刻请求第c个内容的移动用户集合
4.3.2)遍历移动集合
适应度
式中,
4.4)选取适应度
5)修正当前t时刻的用户关联策略bt。
修正当前t时刻的移动用户关联策略bt的步骤如下:
5.1)判断移动用户n在t时刻的请求是否被t–1时刻关联的边缘服务器所满足,若是,则保持关联策略,否则,将移动用户n写入待更新集合中。在所有移动用户均判断完毕后,进入步骤2)。
5.2)随机交换待更新集合中任意两个不同用户关联的边缘服务器,并计算交换后t时刻的超密集移动边缘计算系统总传输成本
t时刻超密集移动边缘计算系统总传输成本
式中,
其中,云服务器向边缘服务器传输内容文件的总传输成本
式中,
用户通过边缘服务器获取请求内容总传输成本
式中,
用户通过宏基站直接从云服务器中获取内容的传输成本
式中,
5.3)判断总传输成本
6)计算超密集移动边缘计算系统中总平均系统成本
7)判断t>t是否成立,若不成立,则令t=t+1,返回步骤4),若成立,则进入步骤8)。t为关联周期。
超密集移动边缘计算系统中总平均系统成本
式中,
用户总切换成本
8)选取令超密集移动边缘计算系统中总平均系统成本
值得说明的是,本发明设计了包括远程云服务器、一个宏基站、m个不同密集部署的微基站、n个不同的移动设备的超密集移动边缘计算系统模型。本发明综合考虑了在用户动态移动过程中,基站的内容缓存和用户关联设计,并提出传输成本和切换成本的联合优化目标函数。
同时,针对目标函数及其限制条件,本发明提出一种移动性感知的内容缓存算法和基于匹配论的懒重新关联的用户关联算法来进行基站内容缓存和移动用户关联。本方法用移动用户和边缘服务器的信息数据来进行建模,通过算法来计算基站的内容缓存并给出相应地用户关联方案,相比于其他的内容缓存和用户关联方法有更好的效率和准确性,为移动边缘计算领域的内容缓存和用户关联问题提供了一种解决思路。
本发明的技术效果是毋庸置疑的。本发明内容是提供一种移动边缘计算网络下内容缓存和用户关联优化方法,通过综合考虑系统内容传输成本和切换成本来最小化系统开销。
本发明综合考虑边缘服务器的内容缓存和移动用户的关联问题,相比于其他边缘计算系统,应用范围更加广泛。本发明综合考虑基站缓存空间的大小、基站的服务能力以及用户对内容的请求概率等综合因素,给出了基站内容的最佳缓存,同时通过基于匹配论的懒重新关联算法确定用户关联策略,很大程度减少了移动边缘计算系统的传输成本和切换成本。
本发明提供了移动边缘计算网络中内容缓存和用户关联优化方法。该方法在保证了在满足边缘服务器缓存大小要求的前提下,通过联合基站的内容缓存和用户关联,综合考虑基站缓存空间的大小、基站的服务能力以及用户对内容的请求概率,得以最小化系统的传输成本和切换成本。
附图说明
图1为系统模型图;
图2为计算基站内容缓存和移动用户关联策略算法流程图。
具体实施方式
下面结合实施例对本发明作进一步说明,但不应该理解为本发明上述主题范围仅限于下述实施例。在不脱离本发明上述技术思想的情况下,根据本领域普通技术知识和惯用手段,做出各种替换和变更,均应包括在本发明的保护范围内。
实施例1:
参见图1至图2,一种移动边缘计算网络下内容缓存和用户关联优化方法,包括以下步骤:
1)建立超密集移动边缘计算系统。所述超密集移动边缘计算系统包括远程云服务器、宏基站、m个不同密集部署的微基站、n个移动设备和c个内容文件。其中,每个微基站均具有边缘服务器。
2)获取当前移动网络中所有移动用户、边缘服务器的信息数据。
所述移动用户和边缘服务器的信息数据包括边缘服务器的缓存大小dm、边缘服务器最大服务用户数zm、内容文件大小vc、用户的移动路径矩阵xn×t、用户的内容请求矩阵yn×t和状态转移矩阵bm×m。边缘服务器序号m=1,2,…,m。m为边缘服务器总数。内容文件序号c=1,2,…,|c|;|c|为内容文件总数;c为内容文件集合。
3)初始化时刻t=0。初始化超密集移动边缘计算系统的参数,令所有的边缘服务器内容缓存策略a=0,移动用户关联策略b=0。其中a=0表示边缘服务器不缓存内容文件,b=0表示边缘服务器与移动用户不关联。
所述超密集移动边缘计算系统参数包括观测时间ε、最大容忍访问间隔σ和内容优先级系数p。
4)确定当前t时刻的内容缓存策略at和用户关联策略bt。
确定当前t时刻的内容缓存策略at和用户关联策略bt的步骤如下:
4.1)初始化当前t时刻的用户关联策略bt。确定每个边缘服务器服务范围内的移动用户。将剩余最大服务用户数的边缘服务器与位于边缘服务器服务范围内的移动用户相关联。将不在边缘服务器服务范围内的移动用户与宏基站相关联。
4.2)移除每个微基站中过时的内容文件。在观测时间ε内平均访问次数
4.3)计算第c个内容文件与第m个微基站之间的适应度
4.3.1)建立t时刻请求第c个内容的移动用户集合
4.3.2)遍历移动集合
适应度
式中,
4.4)选取适应度
5)修正当前t时刻的用户关联策略bt。
修正当前t时刻的移动用户关联策略bt的步骤如下:
5.1)判断移动用户n在t时刻的请求是否被t–1时刻关联的边缘服务器所满足,若是,则保持关联策略,否则,将移动用户n写入待更新集合中。在所有移动用户均判断完毕后,进入步骤2)。
5.2)随机交换待更新集合中任意两个不同用户关联的边缘服务器,并计算交换后t时刻的超密集移动边缘计算系统总传输成本
t时刻超密集移动边缘计算系统总传输成本
式中,
其中,云服务器向边缘服务器传输内容文件的总传输成本
式中,
用户通过边缘服务器获取请求内容总传输成本
式中,
用户通过宏基站直接从云服务器中获取内容的传输成本
式中,
5.3)判断总传输成本
6)计算超密集移动边缘计算系统中总平均系统成本
7)判断t>t是否成立,若不成立,则令t=t+1,返回步骤4),若成立,则进入步骤8)。t为关联周期。
超密集移动边缘计算系统中总平均系统成本
式中,
用户总切换成本
式中,
8)选取令超密集移动边缘计算系统中总平均系统成本
实施例2:
一种移动边缘计算网络下内容缓存和用户关联优化方法,主要包括以下步骤:
1)建立超密集移动边缘计算系统模型。
所述的超密集移动边缘计算系统模型包括远程云服务器、一个宏基站、m个不同密集部署的微基站、n个不同的移动设备和c个不同的内容文件。边缘服务器部署在微基站中,由微基站提供内容分发服务,宏基站不缓存内容。系统以固定时间片刻方式运行,总的运行周期为t。
2)获取当前移动网络中所有移动用户、边缘服务器的信息数据。
所述的移动用户和边缘服务器的信息数据包括边缘服务器的缓存大小dm,边缘服务器最大服务用户数zm,每个内容大小vc,用户的移动路径矩阵xn×t,用户的内容请求矩阵yn×t,状态转移矩阵bm×m。
3)初始化超密集移动边缘计算系统参数,开始迭代运算。
超密集移动边缘计算系统参数包括观测时间ε、最大容忍访问间隔σ、内容优先级系数p。初始状态下,令所有的边缘服务器内容缓存策略a=0和移动用户关联策略b=0。其中a=0表示边缘服务器不缓存,b=0表示不关联。
4)确定当前t时刻的内容缓存策略at,主要步骤如下:
4.1)初始化bt。将每个用户与剩余最大服务用户数的边缘服务器相关联。不在边缘服务器服务范围内的用户直接与宏基站相关联。
4.2)移除每个微基站中所有过时的内容。在观测时间ε的范围内,计算第c个内容的平均访问次数
4.3)计算第c个内容与第m个微基站之间的适应度
否则更新
式中,
4.4)每次选取适应度
5)修正当前t时刻的用户关联策略bt,主要步骤如下:
5.1)懒重新关联策略。如用户在t时刻的请求可以被t–1时刻关联的服务器所满足,那么保持该用户与t–1时刻相同的关联方式。
5.2)交换、更新匹配。每次只交换其中两个不同用户关联的边缘服务器,其他用户保持相同的关联策略。两个不同用户可以交换的条件是当且仅当交换后t时刻的总传输成本
t时刻超密集移动边缘计算系统总传输成本
其中云服务器向边缘服务器总传输成本
式中
用户通过边缘服务器获取请求内容总传输成本
用户通过宏基站直接从云服务器中获取内容的传输成本计算如下:
6)量化超密集移动边缘计算系统中总平均系统成本。
超密集移动边缘计算系统中总平均系统成本
式中
7)返回步骤4,重复迭代,直至确定t=t。输出该移动边缘计算系统中最优内容缓存a和用户关联策略b。
- 还没有人留言评论。精彩留言会获得点赞!