传感边缘云智能干扰攻击的博弈防御策略优化方法及系统与流程
本发明属于物联网技术领域,更具体地,涉及一种传感边缘云智能干扰攻击的博弈防御策略优化方法及系统。
背景技术:
传感设备的计算任务能通过服务访问点或基站节点卸载到边缘服务节点,这极大的减少了传感设备的资源消耗,提高了用户的服务质量。然而,在开放的环境中,传感设备计算任务卸载过程容易受到智能干扰攻击。
传感边缘云系统集成了传感能力、控制、通信和计算能力,已经广泛应用于工业互联网领域。在传感边缘云系统中处于边缘侧的边缘服务节点通过开放的无线环境响应传感设备节点的请求,并且接收来自传感设备节点的计算任务。考虑到边缘侧复杂的无线通信特性,在传感设备和边缘服务节点之间的计算任务卸载中,特别是针对延迟敏感计算任务的智能干扰攻击,使得边缘计算性能降低或任务卸载失败。因此,传感设备和边缘服务的床杆设备簇头节点之间的安全通信面临巨大挑战。
传感设备簇头节点作为防御者,由于难以捕获智能干扰攻击者的信道增益,特别是智能干扰攻击者对多信道发起的ddos(distributeddenialofserviceattack)攻击,越多的信道受攻击,防御者越需要高的计算成本才能获得优化的防御策略。s.bhattacharya等形式化了一个零和追逐-逃避博弈来计算优化策略,并进行抗uav(unmannedaerialvehicle)干扰攻击(game-theoreticanalysisofanaerialjammingattackonauavcommunicationnetwork[c].)。l.xiao等考虑了智能uav干扰攻击者,能够指定攻击类型,如干扰攻击、窃听攻击和欺骗攻击等,并且基于强化学习的功率分配策略来防御这些攻击(user-centricviewofunmannedaerialvehicletransmissionagainstsmartattacks.)。y.xu等人考虑了不完全信道状态信息,使用贝叶斯stackelberg博弈研究了uav用户和干扰攻击者之间的竞争交互过程(aone-leadermulti-followerbayesian-stackelberggameforanti-jammingtransmissioninuavcommunicationnetworks[j].)。在y.xu等的方案中,防御者使用stackelberg抗干扰攻击博弈来评估智能干扰攻击的观察误差对防御性能的影响,并获得了纳什均衡(aone-leadermulti-followerbayesian-stackelberggameforanti-jammingtransmissioninuavcommunicationnetworks)。
这些方案存在的不足如下:
(1)已提出的方法对不完全的信道状态信息考虑有限,使得博弈参与者最优策略的选择面临复杂性,当博弈参与者双方攻防策略改变时,已提出的方法也未提供快速的推理功能来实现防御策略选择。
(2)虽然已提出的解决方案设计了基于学习的防御策略,但未考虑如何防御具有学习能力的智能干扰攻击者。
(3)智能干扰攻击者对计算任务卸载的多信道攻击,已提出的解决方案需要解决复杂的问题,极大降低了防御性能。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种传感边缘云智能干扰攻击的博弈防御策略优化方法及系统,其目的在于按照博弈模型预测智能干扰攻击者的攻击策略,并针对预测的攻击策略进行防御策略的智能优化,由此解决现有技术无法针对不完全达到信道状态信息、不能对具有学习能力的智能干扰攻击者进行防御或者防御方案过于复杂导致的方案不可用的技术问题。
为实现上述目的,按照本发明的一个方面,提供了一种传感边缘云中受智能干扰攻击的博弈防御策略优化方法,包括以下步骤:
(1)获取初始的传感器设备簇头节点集合的分配给所述计算任务传输功率向量p:p=(p1,p2,...,pm),其中m为传感设备簇头节点的可用信道资源个数;
(2)按照斯塔克尔伯格模型,以设备簇头节点为领导者,以智能干扰攻击者为追随者,根据智能干扰攻击者攻击的n个传感设备簇头节点的信道其信道增益向量,计算当最大化智能干扰攻击者的博弈效用时,所述智能干扰攻击者对于其攻击的n个信道的功率分配向量jnn,作为智能干扰攻击者的功率分配策略;
(3)按照斯塔克尔伯格模型,以所述智能干扰攻击者采用步骤(2)的功率分配策略为前提,根据传感设备簇头节点的m个信道的信道增益向量,计算最大化传感设备簇头节点的博弈效用从而达到纳什均衡点时,所述传感设备簇头节点对m个可用信道的传输功率分配向量pmm,作为所述传感设备簇头节点的功率分配策略;
(4)按照步骤(3)获得的传感器设备簇头节点的功率分配策略pmm,确定决策配置变量,进行任务卸载。
优选地,所述传感边缘云中受智能干扰攻击的博弈防御策略优化方法,其步骤(2)所述智能干扰攻击者的博弈效用的计算方法如下:
其中,n为智能干扰攻击者攻击的信道总个数,p为传感器设备簇头节点集合的分配给所述计算任务传输功率向量,j为智能干扰攻击者的传输功率向量j=(j1,j2,...,jn);as,i为第s个传感设备簇头节点第i个信道的使用状态,当as,i=1时,第s个传感设备簇头节点第i个信道用于卸载该计算任务,否则as,i=0;hs,i为第s个传感设备簇头节点第i个信道上行的计算任务卸载链路信道增益,pi为第i个信道的传感设备簇头节点的传输功率,n0,i为第i个信道的噪声功率,hj,i为智能干扰攻击者在第i个信道的信道增益,ji为智能干扰攻击者在第i个信道的传输功率,γ为智能干扰攻击者的每单位干扰功率的干扰攻击成本。
优选地,所述传感边缘云中受智能干扰攻击的博弈防御策略优化方法,其步骤(2)所述计算当最大化智能干扰攻击者的博弈效用时,所述智能干扰攻击者的功率分配策略,采用深度神经网络建立智能攻击模型,根据智能干扰攻击者攻击的n个传感设备簇头节点的信道其信道增益向量hs,i=(hs,1,hs,2,...,hs,n),预测智能干扰攻击者的功率分配策略。
优选地,所述传感边缘云中受智能干扰攻击的博弈防御策略优化方法,其步骤(2)所述最大化智能干扰攻击者的博弈效用记作:
其中,jmax为智能干扰攻击者的最大传输功率,为常数。
所述采用深度神经网络建立的智能攻击模型,包括依次连接的输入层、归一化层、全连接层、数据整形层、卷积模块、池化层组、和输出层;
所述输入层,用于输入智能干扰攻击者攻击的n个传感设备簇头节点的信道其信道增益向量hs,i=(hs,1,hs,2,...,hs,n)至归一化层;
所述归一化层,将传感设备簇头节点信道增益向量hs,i=(hs,1,hs,2,...,hs,n)进行归一化处理,获得归一化后的传感设备簇头节点信道增益向量
所述数据整形层,用于将全连接层的输出经过
所述卷积模块,包括两组卷积层,所述两组卷积核分别通过relu线性整流函数连接,每组卷积核包括n个卷积核;整形后的归一化传感设备簇头节点信道增益,通过相应卷积核做第一次卷积运算后,经激活函数输出,再次通过相应卷积核做第二次卷积运算,经过激活函数,输出到池化层组;
所述池化层组,包括n个并联的池化层和全连接层;
所述输出层,用于输出stackelberg博弈存在的纳什均衡点的智能干扰攻击者传输功率向量(jn,1,jn,2,...,jn,n),即为所述智能干扰攻击者的功率分配策略。
优选地,所述传感边缘云中受智能干扰攻击的博弈防御策略优化方法,其所述采用深度神经网络建立的智能攻击模型,按照如下方法训练获取:
随机初始化多信道训练权值向量
其中,αj,i表示损失函数的权重系数,(1-αj,i)tanh(|ji-jmax|)为正则化项,智能干扰攻击者的功率约束参与训练,
训练智能攻击模型的权值更新方程为:
其中,θj表示学习率。
优选地,所述传感边缘云中受智能干扰攻击的博弈防御策略优化方法,其步骤(3)所述传感设备簇头节点的博弈效用的计算方法如下:
其中,m为传感器设备簇头节点可用的信道资源总数,p为传感器设备簇头节点集合的分配给所述计算任务传输功率向量,j为智能干扰攻击者的传输功率向量j=(j1,j2,...,jn);as,i为第s个传感设备簇头节点第i个信道的使用状态,当as,i=1时,第s个传感设备簇头节点第i个信道用于卸载该计算任务,否则as,i=0;hs,i为第s个传感设备簇头节点第i个信道上行的计算任务卸载链路信道增益,pi为第i个信道的传感设备簇头节点的传输功率,n0,i为第i个信道的噪声功率,hj,i为智能干扰攻击者在第i个信道的信道增益,ji为智能干扰攻击者在第i个信道的传输功率,λ为传感设备簇头节点的每单位传输功率的传输成本。
优选地,所述传感边缘云中受智能干扰攻击的博弈防御策略优化方法,其所述计算最大化传感设备簇头节点的博弈效用从而达到纳什均衡点时,所述传感设备簇头节点的传输功率分配策略,采用深度神经网络建立只能防御模型,获得传感器设备簇头节点的功率分配策略。
优选地,所述传感边缘云中受智能干扰攻击的博弈防御策略优化方法,其步骤(3)所述最大化传感设备簇头节点的博弈效用记作:
其中,pmax为传感设备簇头节点的最大传输功率,是一个常数。
所述采用深度神经网络建立的智能防御模型,包括依次连接的输入层、归一化层、全连接层、数据整形层、卷积模块、池化层组、和输出层;
所述输入层,用于输入传感设备簇头节点的m个信道的信道增益向量hs,i=(hs,1,hs,2,...,hs,m)至归一化层;
所述归一化层,将传感设备簇头节点信道增益向量hs,i=(hs,1,hs,2,...,hs,m)进行归一化处理,获得归一化后的传感设备簇头节点信道增益向量
所述数据整形层,用于将全连接层的输出经过
所述卷积模块,包括两组卷积层,所述两组卷积核分别通过relu线性整流函数连接,每组卷积核包括m个卷积核;整形后的归一化传感设备簇头节点信道增益,通过相应卷积核做第一次卷积运算后,经激活函数输出,再次通过相应卷积核做第二次卷积运算,经过激活函数,输出到池化层组;
所述池化层组,包括m个并联的池化层和全连接层;
所述输出层,用于输出stackelberg博弈存在的纳什均衡点的传感设备簇头节点的输功率向量pmm=(pm,1,pm,2,...,pm,m),即为所述传感器设备簇头节点的功率分配策略。
优选地,所述传感边缘云中受智能干扰攻击的博弈防御策略优化方法,其步骤(3)所述智能防御模型按照如下方法训练获取:
随机初始化多信道训练权值向量
其中,αs表示损失函数的权重系数,平衡约束对训练过程的影响;(1-αs)tanh(|p-pmax|)为正则化项,传感设备簇头节点的功率约束参与训练,
训练智能防御模型的权值更新方程为:
其中,θs表示学习率。
按照本发明的另一个方面,提供了一种传感边缘云中受智能干扰攻击的博弈防御策略优化系统,包括初始化模块、智能干扰攻击者预测模块、防御策略决策模块、以及配置模块;
所述初始化模块,用于获取初始的传感器设备簇头节点集合的分配给所述计算任务传输功率向量p:p=(p1,p2,...,pm)并提交给所述智能干扰攻击者预测模块,其中m为传感设备簇头节点的可用信道资源个数;
所述智能干扰攻击者预测模块,用于按照斯塔克尔伯格模型,以设备簇头节点为领导者,以智能干扰攻击者为追随者,根据智能干扰攻击者攻击的n个传感设备簇头节点的信道其信道增益向量,计算当最大化智能干扰攻击者的博弈效用时,所述智能干扰攻击者对于其攻击的n个信道的功率分配向量jnn,作为智能干扰攻击者的功率分配策略,提交给所述防御策略决策模块;
所述防御策略决策模块,用于按照斯塔克尔伯格模型,以所述智能干扰攻击者采用功率分配策略为前提,根据传感设备簇头节点的m个信道的信道增益向量,计算最大化传感设备簇头节点的博弈效用从而达到纳什均衡点时,所述传感设备簇头节点对m个可用信道的传输功率分配向量,作为所述传感设备簇头节点的功率分配策略,提交给配置模块;
所述配置模块,用于按照传感器设备簇头节点的功率分配策略pmm,确定决策配置变量,进行任务卸载。总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
本发明在传感边缘云环境下,针对传感设备和边缘服务节点之间的安全任务卸载问题,基于stackelberg博弈资源充足的传感设备簇头节点通过学习来优化功率分配策略并防御智能干扰攻击,能有效的防御具有学习能力的智能干扰攻击者,提供了对抗智能干扰攻击的防御方法。
优选方案,基于dnn(deepneuralnetwork)的stackelberg博弈策略学习过程,其中传感设备簇头节点作为leader角色,智能干扰攻击者作为follower角色。首先,智能干扰攻击者获取传感设备簇头节点的传输功率分配策略,并且通过自身的信道增益学习最优的功率分配策略,并最大化其博弈效用。其次,传感设备簇头节点获取智能干扰攻击者的功率分配策略,并且通过自身的信道增益学习最优的功率分配策略,最大化其博弈效用,能在智能干扰攻击者的功率分配策略信息不全的情况下有效的进行防御决策
附图说明
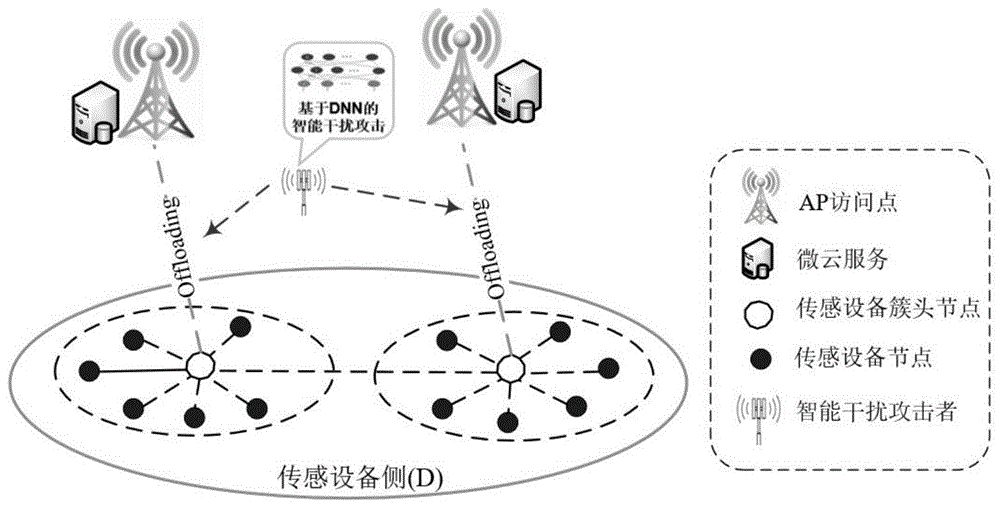
图1是本发明针对的传感边缘云结构示意图;
图2是本发明实施例提供的智能攻击模型结构示意图;
图3是本发明实施例提供的单信道智能攻击模型结构示意图;
图4是本发明实施例提供的智能防御模型结构示意图;
图5是本发明实施例提供的单信道智能防御模型结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明中,传感边缘云系统由传感设备节点、传感设备簇头节点、边缘服务节点和智能干扰攻击者组成。其中,边缘服务节点由ap访问点和微云服务组成。如图1所示。在受到智能干扰攻击时,传感设备节点通过传感设备簇头节点卸载其计算任务到边缘服务节点,利用传感设备簇头节点的计算能力对具有学习能力的智能干扰攻击者实施防御策略。
本发明提供的传感边缘云中受智能干扰攻击的博弈防御策略优化方法,包括以下步骤:
(1)获取初始的传感器设备簇头节点集合的分配给所述计算任务传输功率向量p:p=(p1,p2,...,pm),其中m为传感设备簇头节点的可用信道资源个数;
(2)按照斯塔克尔伯格模型,以设备簇头节点为领导者,以智能干扰攻击者为追随者,根据智能干扰攻击者攻击的n个传感设备簇头节点的信道其信道增益向量,计算当最大化智能干扰攻击者的博弈效用时,所述智能干扰攻击者对于其攻击的n个信道的功率分配向量jnn,作为智能干扰攻击者的功率分配策略。
所述智能干扰攻击者的博弈效用的计算方法如下:
其中,n为智能干扰攻击者攻击的信道总个数,p为传感器设备簇头节点集合的分配给所述计算任务传输功率向量,j为智能干扰攻击者的传输功率向量j=(j1,j2,...,jn);as,i为第s个传感设备簇头节点第i个信道的使用状态,当as,i=1时,第s个传感设备簇头节点第i个信道用于卸载该计算任务,否则as,i=0;hs,i为第s个传感设备簇头节点第i个信道上行的计算任务卸载链路信道增益,pi为第i个信道的传感设备簇头节点的传输功率,n0,i为第i个信道的噪声功率,hj,i为智能干扰攻击者在第i个信道的信道增益,ji为智能干扰攻击者在第i个信道的传输功率,γ为智能干扰攻击者的每单位干扰功率的干扰攻击成本。
所述计算当最大化智能干扰攻击者的博弈效用时,所述智能干扰攻击者的功率分配策略,优选采用深度神经网络建立智能攻击模型,根据智能干扰攻击者攻击的n个传感设备簇头节点的信道其信道增益向量hs,i=(hs,1,hs,2,...,hs,n),预测智能干扰攻击者的功率分配策略;具体如下:
所述最大化智能干扰攻击者的博弈效用记作:
其中,jmax为智能干扰攻击者的最大传输功率,是一个常数。
所述采用深度神经网络建立的智能攻击模型,结构如图2所示,包括依次连接的输入层、归一化层、全连接层、数据整形层、卷积模块、池化层组、和输出层;
所述输入层,用于输入智能干扰攻击者攻击的n个传感设备簇头节点的信道其信道增益向量hs,i=(hs,1,hs,2,...,hs,n)至归一化层;
所述归一化层,将传感设备簇头节点信道增益向量hs,i=(hs,1,hs,2,...,hs,n)进行归一化处理,获得归一化后的传感设备簇头节点信道增益向量
其中,e(·)表示期望,d(·)表示方差。
所述数据整形层,用于将全连接层的输出经过
所述卷积模块,包括两组卷积层,所述两组卷积核分别通过relu线性整流函数连接,每组卷积核包括n个卷积核;整形后的归一化传感设备簇头节点信道增益,通过相应卷积核做第一次卷积运算后,经激活函数输出,再次通过相应卷积核做第二次卷积运算,经过激活函数,输出到池化层组;
第一次卷积运算,使用3×3步长为1的卷积核,提取出智能干扰攻击者n个信道增益信息,卷积运算输出如下:
其中,
第一次卷积运算后采用relu函数作为激活函数,输出向量:
第二次卷积运算,使用3×3步长为1的卷积核,卷积运算输出如下:
第二次卷积运算后采用relu函数作为激活函数,输出向量:
所述池化层组,包括n个并联的池化层和全连接层;优选为了加快训练速度,使用最大化池化层,经过2×2步长为1的滑动窗口,得到最大化池化层的输出向量为
所述输出层,优选采用sigmoid函数,输出stackelberg博弈存在的纳什均衡点的智能干扰攻击者传输功率向量(jn,1,jn,2,...,jn,n),即为所述智能干扰攻击者的功率分配策略;优选采用sigmoid函数作为输出层,
所述采用深度神经网络建立的智能攻击模型,按照如下方法训练获取:
随机初始化多信道训练权值向量
其中,αj,i表示损失函数的权重系数,(1-αj,i)tanh(|ji-jmax|)为正则化项,智能干扰攻击者的功率约束参与训练,
训练智能攻击模型的权值更新方程为:
其中,θj表示学习率。
所述智能攻击模型训练完成后,使用训练好的智能攻击模型预测智能干扰攻击者的传输功率策略,当输入智能干扰攻击者攻击的n个信道的传感设备簇头节点信道增益向量时,所述智能攻击模型输出的智能干扰攻击者的功率分配策略jnn=(jn,1,jn,2,...,jn,n)。
(3)按照斯塔克尔伯格模型,以所述智能干扰攻击者采用步骤(2)的功率分配策略为前提,根据传感设备簇头节点的m个信道的信道增益向量,计算最大化传感设备簇头节点的博弈效用从而达到纳什均衡点时,所述传感设备簇头节点对m个可用信道的传输功率分配向量,作为所述传感设备簇头节点的功率分配策略;
所述传感设备簇头节点的博弈效用的计算方法如下:
其中,m为传感器设备簇头节点可用的信道资源总数,p为传感器设备簇头节点集合的分配给所述计算任务传输功率向量,j为智能干扰攻击者的传输功率向量j=(j1,j2,...,jn);as,i为第s个传感设备簇头节点第i个信道的使用状态,当as,i=1时,第s个传感设备簇头节点第i个信道用于卸载该计算任务,否则as,i=0;hs,i为第s个传感设备簇头节点第i个信道上行的计算任务卸载链路信道增益,pi为第i个信道的传感设备簇头节点的传输功率,n0,i为第i个信道的噪声功率,hj,i为智能干扰攻击者在第i个信道的信道增益,ji为智能干扰攻击者在第i个信道的传输功率,λ为传感设备簇头节点的每单位传输功率的传输成本。
所述计算最大化传感设备簇头节点的博弈效用从而达到纳什均衡点时,所述传感设备簇头节点的传输功率分配策略,优选采用深度神经网络建立只能防御模型,获得传感器设备簇头节点的功率分配策略;具体如下:
所述最大化传感设备簇头节点的博弈效用记作:
其中,pmax为传感设备簇头节点的最大传输功率,是一个常数。
所述采用深度神经网络建立的智能防御模型,结构如图4所示,包括依次连接的输入层、归一化层、全连接层、数据整形层、卷积模块、池化层组、和输出层;
所述输入层,用于输入传感设备簇头节点的m个信道的信道增益向量hs,i=(hs,1,hs,2,...,hs,m)至归一化层;
所述归一化层,将传感设备簇头节点信道增益向量hs,i=(hs,1,hs,2,...,hs,m)进行归一化处理,获得归一化后的传感设备簇头节点信道增益向量
其中,e(·)表示期望,d(·)表示方差。
所述数据整形层,用于将全连接层的输出经过
所述卷积模块,包括两组卷积层,所述两组卷积核分别通过relu线性整流函数连接,每组卷积核包括m个卷积核;整形后的归一化传感设备簇头节点信道增益,通过相应卷积核做第一次卷积运算后,经激活函数输出,再次通过相应卷积核做第二次卷积运算,经过激活函数,输出到池化层组;
第一次卷积运算,使用3×3步长为1的卷积核,提取出智能干扰攻击者m个信道增益信息,卷积运算输出如下:
其中,
第一次卷积运算后采用relu函数作为激活函数,输出向量:
第二次卷积运算,使用3×3步长为1的卷积核,卷积运算输出如下:
第二次卷积运算后采用relu函数作为激活函数,输出向量:
所述池化层组,包括m个并联的池化层和全连接层;优选为了加快训练速度,使用最大化池化层,经过2×2步长为1的滑动窗口,得到最大化池化层的输出向量为
所述输出层,用于输出stackelberg博弈存在的纳什均衡点的传感设备簇头节点的输功率向量pmm=(pm,1,pm,2,...,pm,m),即为所述传感器设备簇头节点的功率分配策略;优选采用sigmoid函数作为输出层,
按照如下方法训练获取:
随机初始化多信道训练权值向量
其中,αs表示损失函数的权重系数,平衡约束对训练过程的影响;(1-αs)tanh(|p-pmax|)为正则化项,传感设备簇头节点的功率约束参与训练,
训练智能防御模型的权值更新方程为:
其中,θs表示学习率。
所述智能防御模型训练完成后,使用训练好的智能防御模型决策传感器设备簇头节点的传输功率策略,当输入m个传感设备节点的信道增益向量时,所述智能防御模型输出的传感设备簇头节点的功率分配策略pmm。
(4)按照步骤(3)获得的传感器设备簇头节点的功率分配策略pmm,确定决策配置变量,进行任务卸载。
本发明提供的传感边缘云中受智能干扰攻击的博弈防御策略优化系统,包括初始化模块、智能干扰攻击者预测模块、防御策略决策模块、以及配置模块;
所述初始化模块,用于获取初始的传感器设备簇头节点集合的分配给所述计算任务传输功率向量p:p=(p1,p2,...,pm)并提交给所述智能干扰攻击者预测模块,其中m为传感设备簇头节点的可用信道资源个数;
所述智能干扰攻击者预测模块,用于按照斯塔克尔伯格模型,以设备簇头节点为领导者,以智能干扰攻击者为追随者,根据智能干扰攻击者攻击的n个传感设备簇头节点的信道其信道增益向量,计算当最大化智能干扰攻击者的博弈效用时,所述智能干扰攻击者对于其攻击的n个信道的功率分配向量jnn,作为智能干扰攻击者的功率分配策略,提交给所述防御策略决策模块;
所述防御策略决策模块,用于按照斯塔克尔伯格模型,以所述智能干扰攻击者采用功率分配策略为前提,根据传感设备簇头节点的m个信道的信道增益向量,计算最大化传感设备簇头节点的博弈效用从而达到纳什均衡点时,所述传感设备簇头节点对m个可用信道的传输功率分配向量,作为所述传感设备簇头节点的功率分配策略,提交给配置模块;
所述配置模块,用于按照传感器设备簇头节点的功率分配策略pmm,确定决策配置变量,进行任务卸载。
以下为实施例:
在传感设备簇头节点卸载延迟敏感性计算任务时,智能干扰攻击者增加了计算任务卸载的延迟时间和能量消耗,降低了信道的可靠性和计算任务的卸载容量。令计算任务卸载的决策配置变量为a={as,i|s∈m,i∈e},其中m表示传感设备簇头节点集合,e表示传感设备簇头节点的信道集合。如果传感设备簇头节点s利用信道i来卸载计算任务,则as,i=1,否则as,i=0。因此,对于单信道i,传感设备簇头节点s的计算任务卸载容量为:
传感设备簇头节点s作为抗干扰攻击的防御者,选择一定的传输功率来卸载计算任务,因此,传感设备簇头节点s的博弈效用为:
其中,p表示传感设备簇头节点s的传输功率,j表示智能干扰攻击者的传输功率。传感设备簇头节点和智能干扰攻击者每单元的功率分别为λ和γ。n0表示噪声功率。hs,i表示上行的计算任务卸载链路信道增益,hj,i表示智能干扰攻击者的信道增益。
智能干扰攻击者选择一定的功率干扰传感设备簇头节点s的延迟敏感计算任务的卸载过程。因此,智能干扰攻击者的博弈效用为:
当传感设备簇头节点有m个可用的信道资源时,智能干扰攻击者发起多信道攻击,导致多个信道上卸载的计算任务传输失败。令pi和ji表示传感设备簇头节点和智能干扰攻击者分配给信道i的传输功率。令p=(p1,p2,...,pm)表示传感设备簇头节点的传输功率向量。j=(j1,j2,...,jn)表示智能干扰攻击者的传输功率向量。传感设备簇头节点和智能干扰攻击者的传输功率满足
在多信道模式下,智能干扰攻击者对n个信道进行干扰攻击,智能干扰攻击者的博弈效用为:
在受到具有学习能力的智能干扰攻击者进行攻击时,本发明模型化了抗干扰攻击的功率分配问题为一个基于dnn的stackelberg博弈。在博弈模型中,传感设备簇头节点和智能干扰攻击者是博弈参与者。传感设备簇头节点是leader,首先实施传输功率的分配,智能干扰攻击者是follower,对传感设备簇头节点计算任务卸载过程进行干扰攻击。每个博弈参与者的最优功率分配策略通过dnn推理获得。本发明针对具有学习能力的智能干扰攻击者设计防御策略,智能干扰攻击者通过博弈交互能够获得传感设备簇头节点的传输功率,同时根据自身的信道增益推理功率分配策略来最大化其博弈效用。同理,传感设备簇头节点作为防御者,通过博弈交互也能获取智能干扰攻击者的功率分配策略,同时根据自身的信道增益推理计算任务卸载的功率分配策略。
(1)获取初始的传感器设备簇头节点集合的分配给所述计算任务传输功率向量p:p=(p1,p2,...,pm),其中m为传感设备簇节点的可用信道资源个数;
(2)按照斯塔克尔伯格模型,以设备簇头节点为领导者,以智能干扰攻击者为追随者,根据智能干扰攻击者攻击的n个传感设备簇头节点的信道其信道增益向量,计算当最大化智能干扰攻击者的博弈效用时,所述智能干扰攻击者对于其攻击的n个信道的功率分配向量jnn,作为智能干扰攻击者的功率分配策略;
当智能干扰攻击者对卸载链路发起多信道攻击时,最大化智能干扰攻击者的博弈效用可形式化如下:
本实施例建立多信道智能攻击模型网络mjnet来最大化智能干扰攻击者的多信道攻击博弈效用。同时,通过训练mjnet来推理多信道模式下智能干扰攻击者的最优攻击策略向量。
mjnet结构,如图2所示:
mjnet处理智能干扰攻击者信道增益的输入、输出步骤如下:
①输入:归一化智能干扰攻击者多信道攻击的信道增益为均值是0,方差是1的标准正态分布。mjnet多信道增益归一化的输入为:
②经过
③整形后的数据输入到卷积层,使用n个3×3步长为1的卷积核,进行第一次卷积操作,提取出智能干扰攻击者n个信道增益信息。
④第一次卷积层的输出为:
⑤第一次卷积层的输出使用relu作为激活函数,
⑥然后进行第二次卷积操作,单个输出为:
⑦再次使用relu作为激活函数,
⑧为了加快训练速度,使用最大化池化层,经过2×2步长为1的滑动窗口,得到最大化池化层的输出向量为
⑨最后使用sigmoid函数,单个输出为
mjnet训练及推理过程如下:
智能干扰攻击者通过mjnet推理其多信道攻击策略。所以,智能干扰攻击者首先随机初始化多信道训练权值向量
其中,αj,i表示损失函数的权重系数,(1-αj,i)tanh(|ji-jmax|)为正则化项,智能干扰攻击者的功率约束参与训练,
训练mjnet的权值更新方程为:
其中,θj表示学习率。mjnet训练完成后,使用训练好的mjnet推理智能干扰攻击者多信道攻击的传输功率策略。当输入智能干扰攻击者的多信道增益向量
当m=n=1时,即单信道攻击模式下,最大化智能干扰攻击者的博弈效用可以特别的简化为:
mjnet可具体简化为一个单层的sjnet,通过训练sjnet来学习和推理单信道攻击模式下智能干扰攻击者的响应策略,以此最大化智能干扰攻击者的博弈效用。
sjnet结构如图3所示:该网络模型由归一化、全连接层、数据整形、卷积层、池化层等组成
sjnet处理智能干扰攻击者信道增益的输入、输出步骤如下:
①为了加快智能干扰攻击者博弈策略学习的收敛速度和保证输入的智能干扰攻击者的信道增益是同分布的。因此,把输入的信道增益归一化处理为均值为0,方差为1的标准正态分布。智能干扰攻击者信道增益归一化的输出为:
其中,e(·)表示期望,d(·)表示方差。把归一化后的智能干扰攻击者的信道增益向量
②数据整形。全连接层的输出经过
③整形后的数据输入到卷积层,使用3×3步长为1的卷积核,进行第一次卷积操作,提取出智能干扰攻击者关键变化的信道增益信息。
④卷积层一的输出为:
⑤卷积层一的输出使用relu作为激活函数,
⑥然后进行第二次卷积操作,卷积层二的输出为:
⑦再次使用relu作为激活函数,
⑧为了加快训练速度,使用最大化池化层,使用2×2步长为1的滑动窗口,得到最大化池化层的输出为
⑨使用全连接层,把最大化池化层的输出拉伸成n×1向量。
⑩最后使用sigmoid函数,输出
sjnet训练及推理过程如下:
智能干扰攻击者通过sjnet推理其攻击策略。所以,智能干扰攻击者首先随机初始化训练权值
其中,αj表示损失函数的权重系数。第2项为正则化项,智能干扰攻击者的干扰功率约束参与训练,
通过对损失函数中的功率j求偏导,得到:
训练sjnet的权值更新方程为:
其中,θj表示学习率。sjnet训练完成后,使用训练好的sjnet推理智能干扰攻击者的传输功率策略,当输入智能干扰攻击者的信道增益向量
(3)按照斯塔克尔伯格模型,以所述智能干扰攻击者采用步骤(2)的功率分配策略为前提,根据传感设备簇头节点的m个信道的信道增益向量,计算最大化传感设备簇头节点的博弈效用从而达到纳什均衡点时,所述传感设备簇头节点对m个可用信道的传输功率分配向量,作为所述传感设备簇头节点的功率分配策略;
传感设备簇头节点通过深度神经网络推理其防御策略。当智能干扰攻击者对卸载链路发起多信道攻击时,最大化传感设备簇头节点的博弈效用可形式化如下:
在多信道攻击模式下建立深度神经网络防御模型msnet来最大化传感设备簇头节点的博弈效用。同时,通过训练msnet来推理多信道攻击模式下传感设备簇头节点的最优防御策略向量。msnet结构如图4所示。
msnet处理多信道攻击模式下传感设备簇头节点信道增益的输入、输出步骤如下:
①输入:归一化均值为0,方差为1的传感设备节点多信道增益向量
②数据整形。经过
③整形后的数据输入到卷积层,使用m个3×3步长为1的卷积核,进行第一次卷积操作,提取出传感设备簇头节点关键变化的多信道增益信息。
④卷积层的单个输出为:
⑤卷积层的输出使用relu作为激活函数,
⑥然后进行第二次卷积操作,使用m个3×3步长为1的卷积核,卷积层的单个输出为:
⑦再次使用relu作为激活函数,
⑧为了加快训练速度,使用最大化池化层,经过2×2步长为1的滑动窗口,得到最大化池化层的单个输出为
⑨最后使用sigmoid函数,输出
msnet训练及推理过程如下:
传感设备簇头节点通过msnet推理其防御策略。所以,传感设备簇头节点首先随机初始化训练权值向量
其中,αs,i表示损失函数权重系数,平衡约束对训练过程的影响,(1-αs,i)tanh(|pi-pmax|)为正则化项,传感设备簇头节点的功率约束参与训练msnet的权值。
通过对损失函数中的功率求偏导,得到:
训练msnet的权值更新方程为:
其中,θs表示学习率。msnet训练完成后,使用训练好的msnet推理传感设备簇头节点用于防御的传输功率策略向量。在多信道攻击模式下,当输入传感设备簇头节点的信道增益向量
此时,在多信道攻击模式下,智能干扰攻击者和传感设备簇头节点的效用达到最大。
当m=n=1时,即单信道攻击模式下,最大化传感设备簇头节点的博弈效用可以特别简化为:
msnet可具体简化为一个单层的ssnet,通过训练ssnet来学习和推理单信道攻击模式下传感设备簇头节点的博弈策略,以最大化传感设备簇头节点的博弈效用。
ssnet的结构如图5所示:该网络模型由归一化、全连接层、数据整形、卷积层、池化层等组成。
ssnet处理传感设备簇头节点信道增益的输入、输出步骤如下:
①为了加快传感设备簇头节点博弈策略学习的收敛速度和保证传感设备簇头节点的信道增益是同分布的。因此,把输入的信道增益归一化处理为均值为0,方差为1的标准正态分布。传感设备簇头节点信道增益归一化输出为:
其中,e(·)表示期望,d(·)表示方差。把归一化后的传感设备簇头节点信道增益向量
②数据整形。全连接层的输出经过
③整形后的数据输入到卷积层,使用3×3步长为1的卷积核,进行第一次卷积操作,提取出传感设备簇头节点关键变化的信道增益信息。
④卷积层一的输出为:
⑤卷积层一的输出使用relu作为激活函数,
⑥然后进行第二次卷积操作,卷积层二的输出为:
⑦再次使用relu作为激活函数,
⑧为了加快训练速度,使用最大化池化层,使用2×2步长为1的滑动窗口,得到最大化池化层的输出为
⑨使用全连接层,把最大化池化层的输出拉伸成m×1向量。
⑩最后使用sigmoid函数,输出
ssnet训练及推理过程如下:
传感设备簇头节点通过ssnet推理其防御策略。所以,传感设备簇头节点首先随机初始化训练权值
其中,αs表示损失函数权重系数,平衡约束对训练过程的影响,(1-αs)tanh(|p-pmax|)为正则化项,传感设备簇头节点的功率约束参与训练ssnet的权值。
通过对损失函数中的功率p求偏导,得到:
训练ssnet的权值更新方程为:
其中,θs表示学习率。ssnet训练完成后,使用训练好的ssnet推理传感设备簇头节点用于防御的传输功率策略,当输入传感设备簇头节点的信道增益向量
4)按照步骤(3)获得的传感器设备簇头节点的功率分配策略pmm,确定决策配置变量,进行任务卸载。
本实施例在传感边缘云环境下,传感设备计算任务卸载中,具有学习能力的智能干扰攻击者对传感设备计算任务卸载链路攻击时,实现低复杂性和精准的防御。具体通过以下方案:
本实施例针对传感设备计算任务卸载场景,建立资源充足的传感设备簇头节点的计算任务卸载容量模型。针对具有学习能力的智能干扰攻击者对计算任务卸载过程的攻击设计防御策略。
本实施例特别列出在单信道攻击模式下,分别形式化智能干扰攻击者和传感设备簇头节点最大化其博弈效用的优化问题。建立单信道攻击模式下智能干扰攻击者进行博弈策略优化的深度神经网络模型sjnet、传感设备簇头节点进行博弈防御策略优化的深度神经网络模型ssnet,以最大化博弈参与者的效用为目标分别训练sjnet和ssnet,并且在智能干扰攻击者改变单信道攻击策略时,使得传感设备簇头节点在单信道攻击模式下使用ssnet推理快速获得最优的功率分配策略来防御智能干扰攻击。
普通地,在多信道攻击模式下,分别形式化智能干扰攻击者和传感设备簇头节点最大化其博弈效用的优化问题。建立多信道攻击模式下智能干扰攻击者进行多信道攻击博弈策略优化的深度神经网络模型mjnet、传感设备簇头节点进行多信道防御策略优化的深度神经网络模型msnet,以最大化多信道模式下智能干扰攻击者和传感设备簇头节点的博弈效用为目标分别训练mjnet和msnet,并且在智能干扰攻击者改变多信道攻击策略时,使得传感设备簇头节点在多信道攻击场景下使用msnet推理快速获得最优的功率分配策略向量来防御智能干扰攻击者的多信道攻击。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!