一种可视化的金融私有云的部署运维方法与流程
1.本发明涉及一种计算机软件开发领域,特别是涉及一种可视化的金融私有云的部署运维方法。
背景技术:
2.随着容器化技术和云原生技术的发展,为了支持业务的快速迭代和devops(development+operations,开发运维一体化)的实践,传统的it基础架构也在逐步上云。由于金融行业的特殊性和数据安全性要求,不能完全依赖公有云作为基础架构,一般采取私有云或者混合云的方案。大多数公司自建的私有云,都是基于容器编排技术实现的,但是原生的kubernetes学习曲线陡峭、复杂度高,对普通开发人员来说门槛较高。如何快速搭建本地私有云环境,降低kubernetes的学习门槛和使用的复杂度,快速支撑公司各种业务和运营系统的高可用部署,可持续集成,可持续构建,对容器集群建立完善的监控预警机制,这些成为金融科技亟待解决的问题。
技术实现要素:
3.鉴于以上所述现有技术的缺点,本发明的目的在于提供一种可视化的金融私有云的部署运维方法,用于解决现有技术中原生的kubernetes学习曲线和使用的复杂度较高,对普通开发人员来说门槛较高,造成金融科技行业的开发和维护成本高、效率低的问题。
4.本发明提供一种可视化的金融私有云的部署运维方法,包括以下步骤:
5.步骤101:使用虚拟化软件,对本地机房的服务器的硬件资源进行虚拟化,并生成m台虚拟机;
6.步骤102:从所述m台虚拟机中选定n台,将选定的n台虚拟机搭建为第一集群,在所述第一集群上部署多个服务节点和多个代理节点,其中,每个服务节点和每个代理节点分别对应所述n台虚拟机中的一台,在每台虚拟机上安装预设的软件后,形成第二集群;所述n至少为4,2台与服务节点相对应,2台与代理节点相对应;
7.步骤103:在所述第二集群上添加p台虚拟机,所述p台虚拟机为所述m台虚拟机中除所述步骤102中选定的所述n台之外的虚拟机,在所述第二集群上部署多个控制节点和多个工作节点,其中,每个控制节点和每个工作节点分别对应所述p台虚拟机中的一台,为各虚拟机选择对应的角色,将添加好角色的各虚拟机加入第二集群中,形成第三集群;所述控制节点的数量为奇数,且至少为三个;
8.步骤104:为所述第三集群部署负载均衡器;
9.步骤105:在所述第三集群中部署用于日志存储、日志采集和日志可视化的软件套件,在第二集群中开启集群日志功能,通过日志可视化界面查看集群日志;
10.其中,所述m等于所述n加上所述p。
11.于本发明的一实施例中,所述步骤101还包括以下步骤:根据使用粒度的划分,对各虚拟机的配置进行设置。
12.于本发明的一实施例中,所述第一集群为k3s集群,由k3s软件通过n台虚拟机搭建而成。
13.于本发明的一实施例中,所述第二集群为rancher集群。
14.于本发明的一实施例中,所述步骤102中,从所述m台虚拟机中选定n台,将选定的n台虚拟机搭建为第一集群之前的步骤还包括:
15.搭建mysql数据库服务器,并选用所述mysql数据库服务器为所述服务节点的外部存储数据库。
16.于本发明的一实施例中,所述步骤103中,所述为各虚拟机选择对应的角色之前的步骤还包括:
17.为各虚拟机安装docker软件;
18.为所述docker软件配置本地私有仓库。
19.于本发明的一实施例中,所述rke集群(rancher kubernetes engine,rancher的轻量级kubernetes安装程序)可部署的负载均衡器包括metallb或公有云厂商提供的负载均衡器中的任意一个。
20.于本发明的一实施例中,所述步骤103中所述各虚拟机对应的角色包括:控制器角色、etcd存储角色及工作节点角色。
21.于本发明的一实施例中,所述软件套件采用efk套件。
22.本发明还提供一种服务器,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如本发明的一种可视化的金融私有云的部署运维方法中任意一项所述的方法。
23.如上所述,本发明的一种可视化的金融私有云的部署运维方法,具有以下有益效果:
24.1、本发明将硬件资源虚拟化为多个虚拟机,使用一部分虚拟机搭建第一集群,并在第一集群上部署第二集群,不仅可快速搭建容器集群,还能使第二集群具有高可用性;
25.2、通过第二集群创建第三集群,可自动实现备份恢复功能;
26.3、通过在第三集群中部署负载均衡器,并为负载均衡器配置ip地址池,使用时将域名解析指向该ip地址池,即可实现集群服务的对外暴露功能;
27.4、通过在第三集群中部署用于日志存储、日志采集和日志可视化的软件套件,开启集群日志功能,并通过可视化软件查看集群日志,实现对集群的监控预警功能。
28.本发明通过可视化的界面,能够方便快捷的部署企业私有云容器编排集群,解决了现有kubernetes集群通过直接kubernetes api的方式进行运维,操作不便,部署困难,门槛较高的问题,降低了kubernetes集群使用和运维的复杂度,降低了成本,提升了效率。
附图说明
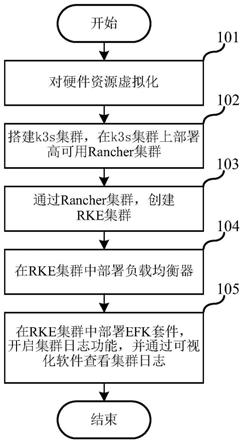
29.图1显示为本发明第一实施方式中的整体步骤示意图。
30.图2显示为本发明第一实施方式中的k3s集群的部署示意图。
31.图3显示为本发明第一实施方式中的rke集群的部署示意图。
32.图4显示为本发明第三实施方式中的服务器的示意图;
具体实施方式
33.以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
34.需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
35.请参阅图1,本发明的第一实施方式涉及一种可视化的金融私有云的部署运维方法,具体如下:
36.步骤101,使用虚拟化软件,对本地机房的服务器的硬件资源进行虚拟化,并生成m台虚拟机。
37.具体的说,本实施例中选用vmware软件,对硬件资源进行虚拟化,其中,硬件资源包括cpu、内存、存储及网络。
38.对硬件资源进行虚拟化之前,还可根据使用粒度的划分,对各虚拟机的配置进行设置,如控制节点所对应的虚拟机,可使用配置较低的虚拟机,工作节点对应的虚拟机,需要使用配置较高的虚拟机。
39.本步骤中生成的m台虚拟机即为步骤102及步骤103中使用的虚拟机。
40.步骤102,从m台虚拟机中选定n台,将选定的n台虚拟机搭建为第一集群,在第一集群上部署多个服务节点和多个代理节点,其中,每个服务节点和每个代理节点分别对应所述n台虚拟机中的一台,在每台虚拟机上安装预设的软件后,形成第二集群;n至少为4,2台与服务节点相对应,2台与代理节点相对应。
41.请参阅图2,具体的说,本实施例中,第一集群为k3s集群,由k3s软件通过n台虚拟机搭建而成;第二集群为rancher集群。
42.使用k3s软件,从m台虚拟机中选用n台虚拟机搭建k3s集群,在k3s集群上部署多个服务节点和多个代理节点,其中,每个服务节点和每个代理节点分别对应一台虚拟机,在每台虚拟机上安装预设的软件后,形成rancher集群;
43.需要说明的是,服务节点用于负责调度协调、网络通信等基础功能;代理节点用于部署真正的应用程序。本实施例中采用了6台虚拟机,其中,3台与服务节点相对应,3台与代理节点相对应,实际使用中,可根据需要对虚拟机的数量进行设定,此处不再赘述。
44.此外,在使用k3s软件,选用多台虚拟机搭建k3s集群之前的步骤还包括:
45.搭建mysql数据库服务器,并选用mysql数据库服务器为集群控制节点的外部存储数据库。
46.在各虚拟机上安装的预设软件包括docker软件和rancher软件,软件安装好后,由rancher管理自动加入集群。
47.通过在k3s集群上部署rancher集群,可使rancher集群具有高可用性。
48.步骤103,在第二集群上添加p台虚拟机,p台虚拟机为m台虚拟机中除步骤102中选
定的n台之外的虚拟机,在第二集群上部署多个控制节点和多个工作节点,其中,每个控制节点和每个工作节点分别对应p台虚拟机中的一台,为各虚拟机选择对应的角色,将添加好角色的各虚拟机加入第二集群中,形成第三集群;所述控制节点的数量为奇数,且至少为三个。
49.具体的说,本实施例中,第三集群为rke集群。
50.请参阅图3,本实施例中,步骤103中虚拟机的数量至少为9台,其中,3台与控制节点相对应,6台与工作节点相对应。需要说明的是,控制节点的功能与服务节点功能相似,也是用于负责调度协调、网络通信等基础功能;工作节点的功能与代理节点相似,也是用于部署真正的应用程序。
51.首先为各虚拟机安装docker软件,并为docker软件配置本地私有仓库,采用这种方案,可提高拉取镜像的速度。
52.再将这9台虚拟机按照对应的角色规划,加入到rancher集群中,形成rke集群。虚拟机对应的角色包括控制器角色、etcd存储角色及工作节点角色,其中,控制节点对应控制器角色及etcd存储角色,工作节点对应工作节点角色。
53.通过rancher集群创建的rke集群,即可自动具备备份恢复功能。
54.步骤104,为第三集群部署负载均衡器。
55.具体的说,rke集群可部署的负载均衡器包括metallb或公有云厂商提供的负载均衡器中的任意一个,本实施例中选用metallb作为负载均衡器,部署到rke集群的system命名空间下,并为metallb配置ip地址池。
56.metallb的部署是参考官方文档在rke集群中部署的,主要工作是对metallb的配置文件进行修改后,在rancher集群的管理平台中进行操作即可。
57.需要说明的是,ip地址池可自行规划设定,人为指定一段未被使用的ip段。使用时将域名解析指向该ip地址池,即可实现集群服务的对外暴露功能。
58.步骤105,在第三集群中部署用于日志存储、日志采集和日志可视化的软件套件,在第二集群中开启集群日志功能,通过日志可视化界面查看集群日志。
59.具体的说,本实施例中的软件套件采用efk套件(elasticsearch filebeat kibana,日志收集处理),在rke集群中部署efk套件,在rancher集群中开启集群日志功能,并配置elasticsearch服务的地址,将集群日志收到elasticsearch中,通过kibana可视化界面查看集群日志。
60.通过rancher平台的应用商店,在rancher集群中部署efk套件。
61.efk套件为日志收集处理套件,其中,elasticsearch是一个文本搜索引擎,用于对日志文件创建索引;filebeat可自动实现对日志的收集;kibana是一个web程序,用于做数据展示。
62.efk套件部署完成后自动生成url(uniform resource locator,统一资源定位器),浏览器输入这个url就可以进入kibana浏览界面,在输入框中还可以输入关键字,通过kibana界面查看结果。
63.需要说明的是,集群日志是rke集群的系统级别的日志,不可以自定义。
64.本发明的第二实施方式涉及一种存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述第一实施方式中所述方法的任意一项。
65.请参阅图4,本发明的第三实施方式涉及一种服务器,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行所述程序时实现上述第一实施方式中所述方法的任意一项。
66.其中,存储器和处理器采用总线方式连接,总线可以包括任意数量的互联的总线和桥,总线将一个或多个处理器和存储器的各种电路连接在一起。总线还可以将诸如外围设备、稳压器和功率管理电路等之类的各种其他电路连接在一起,这些都是本领域所公知的,因此,本文不再对其进行进一步描述。总线接口在总线和收发机之间提供接口。收发机可以是一个元件,也可以是多个元件,比如多个接收器和发送器,提供用于在传输介质上与各种其他装置通信的单元。经处理器处理的数据通过天线在无线介质上进行传输,进一步,天线还接收数据并将数据传送给处理器。
67.处理器负责管理总线和通常的处理,还可以提供各种功能,包括定时,外围接口,电压调节、电源管理以及其他控制功能。而存储器可以被用于存储处理器在执行操作时所使用的数据。
68.综上所述,本发明的一种可视化的金融私有云的部署运维方法,
69.1、本发明将硬件资源虚拟化为多个虚拟机,使用一部分虚拟机搭建k3s集群,并在k3s集群上部署rancher集群,不仅可快速搭建kubernetes集群,还能使rancher集群具有高可用性;
70.2、通过rancher集群创建rke集群,可自动实现备份恢复功能;
71.3、通过在rke集群中部署负载均衡器,并为负载军分区配置ip地址池,使用时将域名解析指向该ip地址池,即可实现集群服务的对外暴露功能;
72.4、通过在rke集群中部署efk套件,开启集群日志功能,并通过可视化软件查看集群日志,实现对集群的监控预警功能。
73.本发明通过可视化的界面,能够方便快捷的部署企业私有云容器编排集群,解决了现有kubernetes集群通过直接kubernetes api的方式进行运维,操作不便,部署困难,门槛较高的问题,降低了kubernetes集群使用和运维的复杂度,降低了成本,提升了效率。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。
74.上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1