基于模糊自编码器的水声信号自动调制识别方法与流程
本发明属于水声通信技术领域,具体地说,涉及一种基于模糊自编码器的水声信号自动调制识别方法。
背景技术:
声波作为一种优秀的水下信息载体,因其具有较高的传输距离和传输速度以及较低的衰减系数,成为了水下通信的首选媒介。水声通信系统中,发送端通常使用自适应调制编码技术(adaptivemodulationcoding,amc),该技术可依据信道状况,自适应地选择适合当前信道的调制方式,该技术需要信号发送端与接收端通过握手信号同步调制方式,然而水声信道噪声干扰与多径效应严重,致使握手信号无法准确传输,致使接收端采用了不匹配的解调方式,进而导致解调数据的严重错误。
自动调制识别(automaticmodulationrecognition,amr)技术可使接收端在调制信息未知的情况下,自动识别出信号的调制方式,保证接收端采用正确的解调方式解调数据。目前调制方式智能识别的方法主要有基于最大似然比的识别方法与基于特征提取的识别方法。前者虽然数学理论完备,但是需要大量的先验信息,难以实际应用且复杂度较高;后者则实现简单,易于工程应用,但却极其依赖提取特征的质量。然而水下信道复杂多变,存在严重的噪声干扰与多径效应,不同调制信号的特征往往会趋于一致,这样的特征辨识度很低,难以用于自动调制识别。
技术实现要素:
针对现有水声信号自动调制识别方法的抗干扰能力差、计算成本高、识别准确率低等技术问题,本发明的目的是提供一种基于模糊自编码器的水声信号自动调制识别方法,以解决上述问题。
为实现上述发明目的,本发明采用下述技术方案予以实现:
一种基于模糊自编码器的水声信号自动调制识别方法,包括以下步骤:
s1:获取水声信号;
s2:提取s1中水声信号的形态特征与熵特征,并进行归一化处理;
s3:利用模糊自编码器将s2中处理后特征向量进行模糊处理后,用于训练模糊自编码神经网络,得到用于编码的权值与偏置;
s4:将s2中处理后的特征向量与s4得到的权值相乘后,加上偏置项,得到模糊自编码器编码后的特征向量;
s5:将s4得到的特征向量进行归一化之后,训练人工神经网络;
s6:将需要识别的水声信号经过上述相同的特征提取与编码后,输入到s5中训练好的人工神经网络中,实现自动调制识别。
进一步的,所述s1中计算水声信号的特征所采用的信号处理方法包括:功率谱、奇异谱、相位谱、小波能量谱、频谱以及瞬时幅度。
进一步的,所述s2中,所述形态特征:零中心归一化瞬时幅度谱密度的最大值、零中心归一化瞬时幅度标准差、波动系数;
所述熵特征:功率谱香农熵、功率谱指数熵、奇异谱香农熵、奇异谱指数熵、频谱幅度香农熵、频谱幅度指数熵、相位谱香农熵、相位谱指数熵、小波能量指数熵、小波能量香农熵、瞬时幅度指数熵、瞬时幅度香农熵。
更进一步的,所述零中心归一化瞬时幅度谱密度的最大值的公式为:
γmax=max{dft[acn(n)]}2/n
式中n=(1,2,..,n),n为采样点数,acn(n)=an(n)-1,an(n)为归一化后的瞬时幅度,dft(·)表示离散傅里叶变换。
其中,零中心归一化瞬时幅度标准差的公式为:
式中
其中,波动系数的具体公式为:
β=v/μ
其中v与μ分别为an(n)的方差与均值。
其中,奇异谱香农熵和奇异谱指数熵的计算方法为:
将离散的水声采样信号嵌入维数m和延迟时间n后得到重构相空间矩阵:
对该矩阵进行奇异值分解得:
奇异谱香农熵:
奇异谱指数熵:
其中,功率谱香农熵与功率谱指数熵的计算公式如下:
功率谱香农熵:
功率谱指数熵:
式中pi为信号功率谱中各点的权值,k为功率谱的点数。
其中,频谱幅度香农熵与频谱幅度指数熵的计算公式如下:
频谱幅度香农熵:
频谱幅度指数熵:
其中,相位谱香农熵与相位谱指数熵的计算公式如下:
相位谱香农熵:
相位谱指数熵:
其中,小波能量香农熵与小波能量指数熵的计算公式如下:
小波能量香农熵:
小波能量指数熵:
其中,瞬时幅度香农熵与瞬时幅度指数熵的计算公式如下:
瞬时幅度香农熵:
瞬时幅度指数熵:
式中pi为信号瞬时幅度中各点的权值,k为信号的长度。
进一步的,所述s2中归一化的公式为:
式中n为样本数量,max与min分别为特征向量的最大值与最小值。
进一步的,模糊自编码器是在传统自编码器的基础上,依据二项分布,选取部分样本的部分特征进行均值化模糊处理后,用以模拟被噪声干扰后的特征,作为传统自编码器的输入,得到模糊自编码器,提高了编码后特征的抗干扰能力。
更进一步的,所述s3中,模糊自编码器的训练步骤如下;
s3-1:计算s2中得到的样本各个特征的均值;
s3-2:依据二项分布,选取s2中的部分样本,得到需要进行模糊处理的样本;
s3-3:对s3-2中得到的样本,依据二项分布,选择部分特征,将其替换为样本在该特征下的均值;
s3-4:将s3-3得到的样本用于训练自编码器,得到映射权值与偏置。
本发明的优点和积极效果是:
本发明首先提取水声信号中抗噪声干扰能力强的形态特征与熵特征,保证了提取特征的分类可用性;然后,在传统自编码器的基础上,依据现实生活中水声信号的特征在噪声与多径效应的严重干扰下会趋于一致的现象,提出了模糊自编码器,通过对原始特征进行模糊处理用以模拟噪声干扰后的特征,将处理后的特征用于自编码器的训练后,便可以得到更具辨识度的特征向量,更有利于自动调制识别;最后,将模糊自编码器编码后的特征用于训练参数较少的bp神经网络,保证了识别准确率的同时也不需要太高的计算成本。
本发明最终实现低延迟、高准确率的水声信号自动调制识别,该方法抗干扰能力强、识别准确率与稳定性高。
附图说明
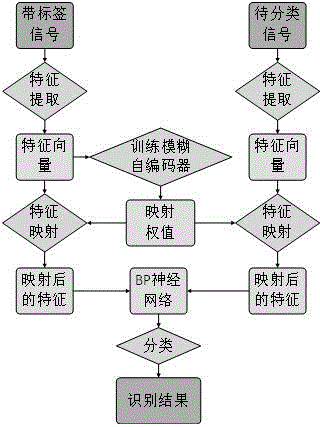
图1是本发明实施例的流程图。
图2是本发明实施例中模糊自编码器的结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下将结合附图和实施例,对本发明作进一步详细说明。
实施例
在水声自适应调制编码通信系统中,信号发送端与接收端需要通过握手信号同步调制方式,然而水声信道噪声干扰与多径效应严重,致使握手信号无法准确传输,此时接收端可使用自动调制识别方法准确识别出接收信号的调制方式,正确地解调数据,保障通信的质量。
本实施例是一种基于模糊自编码器的水声信号自动调制识别方法,为了验证本方法,本实施例中使用山东省青岛市栈桥附近海域中采集到的不同类别的共计7种调制信号进行实验,调制方式分别为:bpsk、qpsk、bfsk、qfsk、16qam、64qam、ofdm;每类调制信号200组,总样本数总计1400组。依据4:1的比例将采集到的水声信号均匀划分为训练集与测试集,后续处理包括以下部分,如图1所示:
s1:调制信号特征提取与处理步骤,包括:
s11、求出调制信号的功率谱、奇异谱、相位谱、小波能量谱、频谱以及瞬时幅度;
s12、对s11处理后的信号进行形态特征与熵特征的提取;
s13、对s12得到的水声调制信号特征进行归一化;
本实施例选择抗噪声能力强的形态特征与熵特征作为该自动调制识别方法的特征;其中,信号的形态特征与熵特征具体包括:
所述形态特征:零中心归一化瞬时幅度谱密度的最大值、零中心归一化瞬时幅度标准差、波动系数;
所述熵特征:功率谱香农熵、功率谱指数熵、奇异谱香农熵、奇异谱指数熵、频谱幅度香农熵、频谱幅度指数熵、相位谱香农熵、相位谱指数熵、小波能量指数熵、小波能量香农熵、瞬时幅度指数熵、瞬时幅度香农熵。
其中,零中心归一化瞬时幅度谱密度的最大值的公式为:
γmax=max{dft[acn(n)]}2/n
式中n=(1,2,..,n),n为采样点数,acn(n)=an(n)-1,an(n)为归一化后的瞬时幅度,dft(·)表示离散傅里叶变换。
其中,零中心归一化瞬时幅度标准差的公式为:
式中
其中,波动系数的具体公式为:
β=v/μ
其中v与μ分别为an(n)的方差与均值。
其中,奇异谱香农熵和奇异谱指数熵的计算方法为:
将离散的水声采样信号嵌入维数m和延迟时间n后得到重构相空间矩阵:
对该矩阵进行奇异值分解得:
奇异谱香农熵:
奇异谱指数熵:
其中,功率谱香农熵与功率谱指数熵的计算公式如下:
功率谱香农熵:
功率谱指数熵:
式中pi为信号功率谱中各点的权值,k为功率谱的点数。
其中,频谱幅度香农熵与频谱幅度指数熵的计算公式如下:
频谱幅度香农熵:
频谱幅度指数熵:
式中pi为信号幅频响应曲线中各点的权值,k为幅频响应曲线的点数。
其中,相位谱香农熵与相位谱指数熵的计算公式如下:
相位谱香农熵:
相位谱指数熵:
式中pi为信号相频响应曲线中各点的权值,k为相频响应曲线的点数。
其中,小波能量香农熵与小波能量指数熵的计算公式如下:
小波能量香农熵:
小波能量指数熵:
式中pi为小波能量谱中各点的权值,k为小波能量谱的点数。
其中,瞬时幅度香农熵与瞬时幅度指数熵的计算公式如下:
瞬时幅度香农熵:
瞬时幅度指数熵:
式中pi为信号瞬时幅度中各点的权值,k为信号的长度。
所述s13中归一化的公式为:
式中n为样本数量,max与min分别为特征向量的最大值与最小值。
s2:模糊自编码器训练步骤,其中模糊自编码器的网络结构如图2所示,包括:
s21、计算s13中得到的样本各个特征的均值。
s22、依据二项分布,选取s13中的部分样本,得到需要进行模糊处理的样本。
s23、对s22中得到的样本,依据二项分布,选择部分特征,将其替换为样本在该特征下的均值。
s24、将s23得到的样本作为传统自编码器的输入,用于训练模糊自编码器,得到映射权值与偏置。
s3:bp神经网络训练步骤,包括:
s31、将s13中处理后的特征向量与s24得到的权值相乘并加上偏置项,得到模糊自编码器编码后的特征向量。
s32、将s31得到的特征向量进行归一化之后,用于训练bp神经网络。
s4:自动调制识别步骤,包括:
s41、对测试集的信号进行相应的特征提取和处理后,使用训练好的模糊自编码器对其进行编码,得到编码后的特征向量。
s42、将s41得到的特征向量进行归一化后,输入训练好的bp神经网络中,实现自动调制识别。
实施例提供的方法的识别性能如表1所示:
表1fae-bp与bp识别准确率对比
表1统计了10次连续实验的识别结果,其中模糊系数代表模糊自编码器中二项分布的概率,模糊系数越高,被模糊的特征占比越大;同时,为了保证公平性,编码后特征的维度与原始特征维度一致。
结果表明:随着模糊系数的提高,fae-bp与bp的准确率均不断下降,说明特征的模糊会严重降低特征的辨识度;同时,在相同的模糊系数下,fae-bp的准确率均高于bp,并且稳定在90%以上,展示出良好的识别性能以及对模糊后特征的识别鲁棒性。
上述说明了,经模糊自编码器编码后的特征极大程度上减弱了特征模糊带来的影响,提高了特征间的辨识度,比未编码的特征更加适合分类。
以上实施例仅用以说明本发明的技术方案,而非对其进行限制;尽管参照前述实施例对本发明进行了详细的说明,对于本领域的普通技术人员来说,依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或替换,并不使相应技术方案的本质脱离本发明所要求保护的技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!