一种面向智能制造场景的边云协同服务编排方法与流程
[0001]
本发明属于智能制造领域,具体涉及一种面向智能制造场景的边云协同服务编排方法。
背景技术:
[0002]
随着电子电气技术,信息技术和先进制造技术的快速发展,制造企业的生产方式正在从数字化向智能化转变。万物互联的工业4.0时代已经到来!智能终端和各类传感器产生的数据正以指数级爆发增长。在这种情况下,考虑到网络带宽和延迟限制导致的性能限制,云计算不再是支持这些智能工厂应用程序的适当平台。边缘计算应运而生,它将计算移向网络边缘以减少响应延迟,同时避免了边缘到核心的网络带宽限制。最小化延迟是边缘计算系统的热门研究课题,尤其在工业4.0场景下,整个工厂系统数据流的实时性,直接影响系统的生产效率和正常运行。资源编排是确保应用实时的重要视角。如何编排这些异构资源以满足智能工厂应用的延迟约束是当前亟待解决的问题。针对边缘计算的资源编排已有多方面的工作然而这些工作集中于优化编排策略,忽略了精确刻画服务延迟对于编排结果的重要性。延迟主要由通信和计算两方面组成,当前的数学模型方法无法对延迟(尤其多跳延迟)精确建模,主要原因如下:(1)通信和计算过程都可能出现排队,而排队论无法建模多跳延迟;(2)通信时间不只简单的与通信量和带宽相关,还与链路的可靠性、链路总通信量等信息有密切关联;(3)同样地,微服务的需求/设备的总量也不能精确刻画计算时间,设备性能,cpu利用率,消息中心数据量也是影响计算时间的重要因素。
技术实现要素:
[0003]
本发明的目的在于克服上述不足,提供一种面向智能制造场景的边云协同服务编排方法,解决了多跳应用的延迟难精确刻画和在应用延迟约束下,如何使所有应用延迟之和最小化。
[0004]
为了达到上述目的,本发明包括以下步骤:
[0005]
一种面向智能制造场景的边云协同服务编排方法,包括以下步骤:
[0006]
步骤1,搭建基于容器的测试平台,然后对应用的流程进行容器化封装;
[0007]
步骤2,通过分析应用的流程,生成微服务的放置方案;
[0008]
步骤3,通过工具crf(容器资源获取)和工具lsf(获取样本延迟)来获取多跳应用在不同编排方案下的延迟样本;
[0009]
步骤4,对延迟样本进行分析,并送入基于机器学习的延迟预测算法lpml中得到回归模型,并预测设备上的微服务延迟;
[0010]
步骤5,将微服务优先放在边缘设备上以减少延迟,其他放至云端减少延迟,完成边云协同服务编排。
[0011]
进一步的,步骤1中,对应用的流程进行容器化封装时,是将每个应用的微服务封装在docker(一个开源的应用容器引擎)容器中,微服务间采用轻量级发布/订阅信息传输
协议mqtt进行信息交互。
[0012]
进一步的,步骤3中,工具crf(容器资源获取)用于自动获取测试平台中每个容器在在运行过程中的资源需求;工具lsf(获取样本延迟)用于使多跳应用自动运行内置的所有放置方案,并从中获取多跳应用的延迟样本。
[0013]
进一步的,步骤4中,分析每个延迟样本,并从中提取当前微服务及微服务上游的所有特征,将延迟样本分为训练集和测试集,并送入基于机器学习的延迟预测算法lpml中得到回归模型,再通过以下公式来预测微服务的延时l
v
;
[0014]
l
v
=xgboost
|u|
(fea
v
,fea
u
,fea
k
,fea
uk
)
[0015]
其中,fea
v
代表微服务v的特征,fea
u
代表微服务v的上游微服务u的特征,fea
k
代表微服务v所在设备k的特征,fea
uk
代表微服务u所在设备uk的特征。
[0016]
进一步的,根据微服务上游数目的不同,延迟的计算方法也不同;
[0017]
当微服务v的延迟为l
v
,则上游数目为1的延迟计算公式为:
[0018][0019]
设微服务v的上游为u,上游的延迟为l
u
,则上游数目为2或3的延迟计算公式为:
[0020][0021]
其中,代表微服务v的处理完成时间,代表数据源的发送时间,l
u
代表上游微服务的延迟,表示微服务u到微服务v的传输事件,代表微服务v的处理时间。
[0022]
进一步的,步骤5中,对微服务进行广度优先搜索,并对微服务进行广度排序,遍历每个微服务,并确定同时满足延迟、位置和资源需求,且延迟最低的设备,确保设备中放置的微服务资源需求的总和小于或等于资源容量,以及确保微服务不放置在多个设备之上。
[0023]
进一步的,步骤5中,如果边缘设备资源不足或者前一个微服务被放置在云上,则将当前的微服务放置在云上。
[0024]
与现有技术相比,本发明有以下技术效果:
[0025]
本发明通过搭建测试平台获取多组件应用的延迟样本,深入分析多跳延迟特点,设计基于机器学习的延迟预测方法lpml,基于上游数目的不同,得到不同回归模型,并提出延迟感知的边云协同编排算法laecp。并且通过实验结果表明,lpml的延迟预测标准rmse比基于排队论的数学模型低10倍;基于lpml的laecp算法所得系统总延迟比基于排队论的laecp算法快30倍。解决了多跳应用的延迟难精确刻画问题和在应用延迟约束下,如何使所有应用延迟之和最小化的问题。
附图说明
[0026]
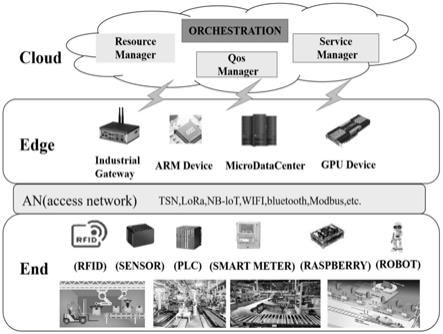
图1为面向智能制造的多层异构网络体系结构图;
[0027]
图2为基于容器的边云协作的服务编排体系结构图;
[0028]
图3为三个延迟敏感服务的处理工作流的dag模型图;
[0029]
图4为xgboost1特征重要性排序图;
[0030]
图5为xgboost2特征重要性排序图;
[0031]
图6为xgboost3特征重要性排序图;
[0032]
图7三个延迟敏感应用在不同数据量下的延迟图;
[0033]
图8为laecp的性能图;
[0034]
图9为延迟预测方法lpml和queue的对比图。
具体实施方式
[0035]
下面结合附图对本发明做进一步说明。
[0036]
参考图1和图2,智能工厂的系统架构本质是一种特殊的分布式系统,其核心特征是多层、资源受限和高度异构。如何编排这些异构资源以满足智能工厂应用的延迟约束是当前亟待解决的问题。为解决多跳应用的延迟难精确刻画问题,我们以半导体智能工厂系统中三个延迟敏感的应用为例,着手搭建了基于容器的测试平台,从而获取多跳应用在不同编排方案下的延迟样本,通过对延迟特点的分析,设计基于机器学习的延迟预测方法lpml,并提出延迟感知的边云协同编排算法laecp。具体包括以下步骤:
[0037]
1)首先搭建端边云三层测试平台semi-heteroedge以支持3个延迟敏感的应用;
[0038]
2)将每个应用的微服务封装在docker容器中,微服务间采用轻量级发布/订阅信息传
[0039]
输协议mqtt进行信息交互;
[0040]
3)开发自动化工具crf,让其自动获取semi-heteroedge测试平台每个容器在在运行过程中的资源需求。并基于浏览器可视化的展示这些信息;
[0041]
4)开发工具lsf,让其自动跑1596组各应用组件的放置方案,并从中获取组件的延迟样本;
[0042]
5)通过对数据进行预处理、分析和特征提取,提出了基于机器学习方法xgboost的延迟预测算法lpml,以弥补数学模型的不准确性;
[0043]
6)分析每个微服务中每条数据的延迟,从两个方面提取当前微服务v及其上游u的19个特征;
[0044]
7)然后将19个特征样本分为训练集和测试集,并将其输入延迟预测算法中得到训练模型。得到了上游数分别为1、2、3的三种回归模型。并通过以下公式来获得预测设备k上的微服务v的延迟:
[0045]
l
v
=xgboost
|u|
(fea
v
,fea
u
,fea
k
,fea
uk
)
[0046]
8)提出基于时延感知的边缘云协同编排算法laecp。将微服务尽可能地放在边缘设备上以减少延迟。在edge设备资源不足的情况下,将微服务转移到云端。而微服务一旦被放到云上,其后续的微服务也会被放到云上,以减少边缘到云的往返时间。
[0047]
参考图3,这幅图记录了三个延迟敏感服务的处理工作流的dag模型,其中蓝色表示放在末端,绿色表示放在边缘,黄色表示放在云上,红色表示等待编排。对于三个应用而言,采用了不同的机器学习方法进行训练,并且进行了集成学习,组件跳数超过了排队论的范围,并且工作流更加复杂和多样;
[0048]
参考图4至图7,可以看出,uplatency和data totalcount是这三种模型最重要的特征。根据公式
[0049][0050]
微服务的等待时间等于uplatency加上通信和计算时间,所以uplatency起着决定
性的作用。从图7可以看出,随着数据量的增加,三种应用程序的等待时间呈线性增加。这是因为随着数据数量的增加,在通信和计算过程中出现了排队,等待时间也相应增加。因此,数据数量对延迟有很大的影响。
[0051]
参考图8,显示了不同totalcount下三种布局算法的总时延,我们可以发现:
[0052]
(1)基于lmpl的laecp时延最低,约为纯云方案的30倍,进一步验证了lmpl的有效性。
[0053]
(2)两种laecp方案的时延均小于其他比较算法,验证了laecp的有效性。
[0054]
(3)纯云方案的延迟并不是所有方案中最低的,说明端云协同放置算法的结果并不总是有效的,需要设计更高效的放置算法。
[0055]
参考图9,显示了lpml和queue在数据数量为10~80时预测延迟的rmse值和得到的真实延迟。首先,对lpml的三种模型的纵向比较表明:
[0056]
(1)随着数据包数量的增加,三种模型的rmse值基本稳定,说明了lpml的可扩展性。
[0057]
(2)在三种模型中,xgboost1的rmse值最大,其次是xgboost2和xgboost3。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1