一种引入深层次行为理解的视频浓缩方法与流程
[0001]
本发明涉及视频处理技术领域,具体而言涉及一种引入深层次行为理解的视频浓缩方法。
背景技术:
[0002]
随着多媒体技术的快速发展,越来越多的监控摄像头应用在交通卡口、商场等各个重要的地方,24小时不间断工作,监控视频的连续性导致视频文件存在许多冗余信息,同时海量视频数据存在存储数据量大、存储时间长等特点,通过视频数据获取有效信息的做法要耗费大量人力、物力以及时间,效率极其低下。如何实现海量视频中快速检索出所需要的视频内容已成为当前监控视频领域的重要研究内容。因此视频浓缩技术正在被广泛研究,并在监控领域得到了大量的应用。
[0003]
视频浓缩技术作为智能视频监控的一部分,近十几年国内外很多大学和公司对其进行了研究。视频浓缩技术主要分为三类:视频快进(video fast-forward)、视频摘要(video abstraction)和视频概要(video summarization)。视频快进是最直接的视频摘要技术,从视频中选取关键帧,组成新的视频摘要。视频概要将截取视频片段,然后将这些片段链接起来形成概要视频。上述两种方法,处理最小单位都是帧。视频摘要则是将不同时间段的数据,基于像素的分析和处理,将不同时间段的数据移动到同一帧。该方法的最小单位是像素,与基于帧的处理方法相比,性能得以提高。但是目前的视频浓缩方法在将长达几个小时的视频浓缩成几十分钟的视频,并没有对视频内容进行深层次理解和分类,观看者还是需要从长达几十分钟的视频中继续检索所需要的内容。
[0004]
现有技术中针对前述问题提出了将视频帧划分成前景和背景,再结合运动对象的运动轨迹以实现进一步浓缩视频的技术。例如,专利号为cn103189861a的发明中还提出一种在线视频浓缩装置、系统及方法,通过将视频帧划分成前景和背景,对前景中的运动目标进行处理,再累积各帧图像的背景图像,从中提取特定n帧背景图像作为主背景序列,将该主背景序列与该运动物体序列进行拼接,形成浓缩视频。该方法利用在线浓缩方式,缩短了浓缩视频长度,尽量保留视频中的运动物体信息。然而,采用前述方法得到的浓缩视频仍然包含多个运动物体的大量信息,在视频监控日益普及的今天,如何从一个包含大量信息的浓缩视频中快速获取用户需要的视频片段信息,仍是亟需解决的问题。
技术实现要素:
[0005]
本发明针对现有技术中的不足,提供一种引入深层次行为理解的视频浓缩方法,通过对运行目标分析,提取运动目标,然后对各个目标运动轨迹进行分析,对各个目标的运动轨迹进行深层次行为理解,其中包括目标属性结构化识别和行为识别,将运动目标的轨迹根据标签类别保存在数据库,根据检索的需要和标签类别,将需要检索的目标轨迹拼接到背景中,并进行融合成为视频。本发明在视频浓缩过程中引入了对视频行为的深层次理解步骤,结合标签的使用,有效提高人们检索视频中关键信息的效率,极大方便了监控视频
的浏览和存储。
[0006]
为实现上述目的,本发明采用以下技术方案:
[0007]
一种引入深层次行为理解的视频浓缩方法,所述视频浓缩方法包括以下步骤:
[0008]
s1,对拍摄视频进行处理,分离得到前景图像和背景图像;
[0009]
s2,对前景图像中的运动对象进行目标检测,并进行跟踪,生成每个运动目标的运动轨迹;
[0010]
s3,结合背景图像对每个运动目标的运行轨迹进行深层次行为理解,所述深层次行为理解包括目标属性结构化识别和目标行为识别,生成对应的结构化标签和行为标签;
[0011]
s4,按照运动目标建立图像数据库,将与其相关的前景图像以及对应的结构化标签和行为标签存储至图像数据库;
[0012]
s5,根据输入的检索标签信息,匹配得到对应的结构化标签或行为标签,结合运动轨迹将符合匹配标签的前景图像融合对应的背景图像,生成符合检索标签的浓缩视频。
[0013]
为优化上述技术方案,采取的具体措施还包括:
[0014]
进一步地,步骤s1中,所述对拍摄视频进行处理,分离得到前景图像和背景图像包括以下步骤:
[0015]
s11,对拍摄视频进行处理,得到视频帧序列;
[0016]
s12,采用混合高斯法对所有视频帧进行背景建模,分离得到前景图像和背景图像。
[0017]
进一步地,步骤s2中,所述对前景图像中的运动对象进行目标检测,并进行跟踪,生成每个运动目标的运动轨迹包括:
[0018]
在所有视频帧的前景和背景分离完成后,采用基于深度学习网络构建的目标检测模型对前景中的运动目标进行检测,并加入外观特征对运动目标进行跟踪,生成运动目标轨迹。
[0019]
进一步地,所述结合背景图像对每个运动目标的运行轨迹进行深层次行为理解的过程包括:
[0020]
s31,利用基于深度学习网络训练得到的结构化识别模型对目标检测模型输出的运动目标进行结构化识别,得到运动目标的结构化标签:
[0021][0022]
式中,n为深度学习网络训练出的权重文件,为权重文件处理目标i
t
,i
t
为监控视频中通过目标检测模型检测出的目标,是t类别中第m个的物体;f1....f
n
代表该物体的特征类别,特征类别可拓展;(f
11 f
12
ꢀ…ꢀ
f
1n
)代表特征类别下面的具体特征;
[0023]
s32,基于深度学习网络训练得到行为识别模型,结合运动目标轨迹和对应的背景对运动目标轨迹进行行为理解,得到运动目标的行为标签:
[0024][0025]
式中,n为深度学习网络训练出的权重文件,是跟踪到的目标m对应的运动序列,假设是1到n;通过权重文件对运动序列检测的行为,得出a1…
a
n
的行为特征;
[0026]
s33,将属性特征集合和行为特征集合合并后生成对应的标签信息将运动目标轨迹信息和对应标签信息保存到数据库中。
[0027]
进一步地,当运动目标为人时,所述结构化标签包括生理特征、衣着特征、饰物特征和携带物特征,所述行为标签包括行为特征、行为对象和所属群体行为特征;
[0028]
当运动目标为车时,所述结构化标签包括车身特征和车牌特征,所述行为标签包括交通状态特征。
[0029]
进一步地,所述方法还包括:
[0030]
当检索目标为任意一个结构化特征时,检索该结构化特征对应的存储在数据库中的所有结构化标签,则以检索到的所有结构化标签为融合对象,融合与之对应的所有行为的视频生成视频序列;
[0031]
当检索目标为任意一个行为特征时,检索与之对应的存储在数据库中所有行为标签,融合与之对应的所有结构化标签的视频生成视频序列;
[0032]
当检索目标为任意一个结构化特征和行为特征时,检索与之对应的存储在数据库中的结构化标签和行为标签,融合对应的视频生成视频序列。
[0033]
本发明的有益效果是:
[0034]
本发明在视频浓缩过程中引入了对视频行为的深层次理解步骤,结合标签的使用,有效提高人们检索视频中关键信息的效率,极大方便了监控视频的浏览和存储。
附图说明
[0035]
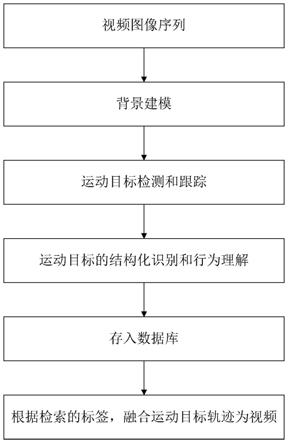
图1是本发明的引入深层次行为理解的视频浓缩方法的流程图。
[0036]
图2是本发明的背景建模流程图。
[0037]
图3是本发明的运动目标检测和跟踪流程图。
[0038]
图4是本发明的行为理解流程图。
具体实施方式
[0039]
现在结合附图对本发明作进一步详细的说明。
[0040]
需要注意的是,发明中所引用的如“上”、“下”、“左”、“右”、“前”、“后”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
[0041]
结合图1,本发明提及一种引入深层次行为理解的视频浓缩方法,所述视频浓缩方法包括以下步骤:
[0042]
s1,对拍摄视频进行处理,分离得到前景图像和背景图像。
[0043]
s2,对前景图像中的运动对象进行目标检测,并进行跟踪,生成每个运动目标的运动轨迹。
[0044]
s3,结合背景图像对每个运动目标的运行轨迹进行深层次行为理解,所述深层次行为理解包括目标属性结构化识别和目标行为识别,生成对应的结构化标签和行为标签。
[0045]
s4,按照运动目标建立图像数据库,将与其相关的前景图像以及对应的结构化标签和行为标签存储至图像数据库。
[0046]
s5,根据输入的检索标签信息,匹配得到对应的结构化标签或行为标签,结合运动轨迹将符合匹配标签的前景图像融合对应的背景图像,生成符合检索标签的浓缩视频。
[0047]
为优化上述技术方案,采取的具体措施还包括:
[0048]
进一步地,步骤s1中,所述对拍摄视频进行处理,分离得到前景图像和背景图像包括以下步骤:
[0049]
s11,对拍摄视频进行处理,得到视频帧序列;
[0050]
s12,采用混合高斯法对所有视频帧进行背景建模,分离得到前景图像和背景图像。
[0051]
第一步,背景建模,分离前景和背景
[0052]
结合图2,步骤s12中,所述采用混合高斯法对所有视频帧进行背景建模,分离得到前景图像和背景图像的过程包括以下步骤:
[0053]
s121,采用混合高斯模型对视频序列进行处理,背景图像的每一个像素分别用k个高斯分布构成的混合高斯模型来建模:
[0054][0055]
式中,x
j
表示像素j在t时刻的取值,如果像素为rgb像素,则x
j
为向量,表示时刻t混合高斯模型中第i个高斯分布的权系数的估计值,和分别表示时刻t混合高斯模型中第i个高斯分布的均值向量和协方差矩阵,η表示高斯分布概率密度函数;在读取第一帧视频图像时,每个像素对应的第一个高斯分布进行初始化,均值赋为当前像素的值,权值赋为1,除第一个高斯分布函数以为的均值、权重都初始化为零。
[0056]
s121,在时刻t对任意一个视频帧的每个像素x
t
与混合高斯模型中第i个高斯分布均值的距离小于其标准差的2.5倍,则定义高斯分布与像素值x
t
匹配,如果该像素对应的混合高斯模型中没有高斯分布与像素值x
t
匹配,那么将最不可能代表背景过程的高斯分布重新赋值,直至处理完当前视频帧。
[0057]
s123,更新混合高斯模型的参数,使高斯分布位于序列的顶部,由背景暂态扰动产生的分布滑向序列的底部,最终被新赋值的高斯分布所取代,判断每一个像素值与得到的高斯分布的匹配关系,如果匹配则像素为背景点,否则该像素为前景。
[0058]
第二步,检测运动目标,生成运动轨迹
[0059]
结合图3,步骤s2中,所述对前景图像中的运动对象进行目标检测,并进行跟踪,生成每个运动目标的运动轨迹包括:
[0060]
在所有视频帧的前景和背景分离完成后,采用基于深度学习网络构建的目标检测模型对前景中的运动目标进行检测,并加入外观特征对运动目标进行跟踪,生成运动目标轨迹。
[0061]
第三步,深层次行为理解
[0062]
结合图4,步骤s3中,所述结合背景图像对每个运动目标的运行轨迹进行深层次行为理解的过程包括:
[0063]
s31,利用基于深度学习网络训练得到的结构化识别模型对目标检测模型输出的运动目标进行结构化识别,得到运动目标的结构化标签:
[0064][0065]
式中,n为深度学习网络训练出的权重文件,为权重文件处理目标i
t
,i
t
(t为目标检测出的类别人、车、物体等)为监控视频中通过目标检测模型检测出的目标,是t类别中第m个的物体。f1....f
n
代表该物体的特征类别,特征类别可拓展,例如,检测类别为人的话,特征类别就是生理特征、衣着特征、饰物特征和携带物特征。如果检测类别为车的话,特征类别就是车身特征和车牌特征。(f
11 f
12
ꢀ…ꢀ
f
1n
)代表特征类别下面的具体特征。例如t为人,f1代表生理特征,(f
11 f
12
ꢀ…ꢀ
f
1n
)就代表年龄,性别,体型特征等。
[0066]
s32,基于深度学习网络训练得到行为识别模型,结合运动目标轨迹和对应的背景对运动目标轨迹进行行为理解,得到运动目标的行为标签:
[0067][0068]
式中,n为深度学习网络训练出的权重文件,是根据目标跟踪到目标为m的目标的运动序列,假设是1到n。通过权重文件对运动序列检测的行为,得出a1…
a
n
的行为特征。可能一段视频序列中只有一个行为特征或者多个特征。
[0069]
s33,将运动目标轨迹信息和对应标签信息保存到数据库中:
[0070]
将属性特征集合和行为特征集合合并后生成对应标签信息并将该物体存储到数据库中。
[0071]
当运动目标为人时,所述结构化标签包括生理特征(如年龄,性别,体型等)、衣着特征(如上衣、裤子、裙子样式、颜色等)、饰物特征(如鞋子、帽子、眼镜、围巾、腰带等)和携带物特征(如单肩挎包、双肩背包、手提包、拉杆箱、雨伞等),所述行为标签包括行为特征、行为对象和所属群体行为特征,如站位朝向,打手机,交谈,聚集,抱东西等。当运动目标为车时,所述结构化标签包括车身特征(如车辆类型、车辆颜色、车辆品牌等)和车牌特征(如车牌号、车牌颜色等),所述行为标签包括交通状态特征(如逆行,交通事故等)。当运动目标为其他物体时,所述结构化标签包括物体的结构特征,行为标签包括物体盗移和物体滞留等。前述例子是常用的部分标签,在实际应用中,可以根据应用场景设置不同的运动目标类
型和对应的标签,以满足监控人员快速提取具有相关特征视频的需求。
[0072]
当检索对应物体、行为特征的时候,根据对应的结构化标签或者行为标签,进行视频融合,形成完整的视频。在此基础上,本发明设定视频融合规则如下:
[0073]
(1)当检索某一个结构化特征时,根据对应结构化特征(如f
n
),检索所属存储在数据库中为那融合视频就针对对象,融合其行为的视频成视频序列。
[0074]
(2)当检索某一个行为特征时,根据对应行为特征(如a
n
),检索所属存储在数据库中为那么融合视频就针对行为,融合其结构化的视频成视频序列。
[0075]
(3)当检索某一个结构化、行为特征时,根据对应的结构化特征(如f
n
)和行为特征(如a
n
),检索所属存储在数据库中的为和那么融合视频就针对结构化特征和行为特征融合其成为视频序列。
[0076]
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1