一种针对基于SSL加密的VPN流量识别方法与流程
本发明涉及加密流量识别领域,具体涉及一种针对基于ssl加密的vpn流量识别方法。
背景技术:
互联网技术的高速发展,在为人们生活带来便利的同时,也会被一些犯罪分子用于不法传输,这对网络空间的稳定性及安全性产生了极大的影响。使得网络安全问题越来越受到人们的关注,因此,全球加密网络流量不断飙升。虽然流量经过加密后再传输,使得传输数据的安全性得到保障,但也为流量的审计增加了难度。如果没有解密技术,it团队将无法查看流量内包含的信息。这意味着加密能够像隐藏其他信息一样隐藏恶意流量,从而带来一系列蠕虫、木马和病毒。因此识别加密流量对于维护网络的安全运行具有十分重要的意义。
facebook、twitter和linkedin等使用ssl协议的网站,在过去都曾遭受过恶意软件传播、数据泄露和垃圾邮件等威胁的侵害。针对ssl流量的识别,bernaille等人提出了一种ssh流量识别方法,该方法基于ssh协议建立连接阶段的特征,对使用ssl协议的流量进行识别。alshammari采用签名和统计相结合的方法,选择了13个特征字段和14个流属性,通过c4.5naivebayesian和svm等多种机器学习算法,对ssl协议流进行识别。
流量识别研究大多围绕对某种协议流量的识别展开,针对vpn流量识别的研究尚不足。西佛罗里达大学的研究人员对文献发布的数据集开展深一步的研究,比较了logistic回归、朴素贝叶斯、svm、knn、rf和gbt方法的识别效果,并对算法参数进行了相应的优化,最终vpn流量达到了90%以上识别率。王琳等人提出一种将指纹识别与机器学习方法相结合识别sslvpn流量,取得了91%以上的识别率。
目前,常采用指纹识别的方法识别ssl加密流量,但传统的指纹识别方法漏识别率较高。针对vpn流量的识别则采用机器学习,而机器学习对特征设计的依赖很强,对于流的特征需要手工提取,且难以判断当前特征集是否为最优特征子集。
技术实现要素:
本发明针对现有技术中的不足,提供一种针对基于ssl加密的vpn流量识别方法,所提方法不仅有效解决了传统ssl加密流量指纹识别方法存在的漏识别率较高的问题,同时改进后的深度学习模型能提取网络流量中具有非常显著性的细粒度的特征,从而更加有效地捕捉网络流量中存在的依赖性。
为达到上述目的,本发明是通过以下技术方案实现的:
一种针对基于ssl加密的vpn流量识别方法,包括以下步骤:
(1)获取数据集:捕获网络数据流量,生成会话,通过五元组对网络数据流量过滤分流并获取原始实验数据集,将原始数据集分为实验数据集和位签名数据集两部分;
(2)数据预处理:提取实验数据集和位签名数据集中每条流内所有数据包的有效载荷数据并连接起来;
(3)位签名:使用位签名数据集的有效载荷的不变位集,依据如果每个流的第k位(1≤k≤l)的值都为0,k签名位设置为0,如果每个流的第k位(1≤k≤l)的值为1,k签名位设置为1。如果这些位的位置中有0位和1位,则第k个签名位设置为^的规则,生成ssl加密流量特定的位签名;
(4)运行长度编码:对步骤(3)生成的位签名进行运行长度编码(rle);
(5)ssl状态转换机:将经过编码的位签名转换成ssl状态转换机;
(6)识别ssl流量:提取实验数据集中每个流的有效负载的前40位,将它们输入到ssl状态转换机;
(7)ssl流量实验数据集:利用步骤(6)中识别出来的ssl加密流量组成ssl流量实验数据集;
(8)ssl流集数据预处理:读取数据流,截断数据,并拆分为一定长度的向量,将ssl流量实验数据集分为训练集和测试集两部分;
(9)识别sslvpn加密流量:将经过步骤(8)处理后的数据集输入到基于注意力机制的双向gru网络流量识别算法,识别sslvpn加密流量;
(10)对获得的指标结果分析,并选取参数,优化加密流量识别方法。
本发明的进一步改进,所述步骤(1)中获取数据集的具体内容和方法是:
1)定义tcp流为以握手协议中的syn标志位开始,并且以fin标志位或以rst标志位结尾的tcp双向流;
2)定义udp流为以第一个数据包到达为开始,如果两个数据包到达的时间间隔超过一分钟,则认为数据流结束,新数据流的开始。
本发明的进一步改进,所述步骤(2)中所述数据预处理,具体内容和过程为:
1)检测每条流内的所有数据包;
2)若该数据包包含有效负载,则提取有效有负载;
3)按顺序连接提取到的有效负载,用作后续签名生成阶段的输入。
本发明的进一步改进,步骤(3)中所述位签名的具体过程为:
1)从ssl的l个流中各收集前n位,并为ssl流生成n位签名。第h个流(1≤h≤l)的前n位为f1h、f2h、···、fnh。l个流都被提取都用于生成如下签名。每个流提取的第k位[1,n]位置用来决定ssl流的第k个签名位。签名创建过程如下所示,其中每个si是一个签名位。
根据上述所示规则生成ssl流的位签名。
本发明的进一步改进,步骤(4)中所述在运行长度编码的具体过程为:
步骤(3)生成的位签名由1位、0位和^位组成,每个签名为n位。对位签名进行运行长度编码(rle),将许多连续数据元素中具有相同数据值的序列存储为单个值,并存储该数据值重复的次数计数。
例如它的位置是1111111000000^^^^111,在使用rle编码之后,它被转换为7o6z4^3o显示状态。
本发明的进一步改进,步骤(5)中所述ssl状态转换机的具体过程为:
根据压缩后的位签名确定ssl状态转换机的状态个数,再为每一个状态配置相应的计数器作为保护,只有当约束被满足(评估为true)时,才允许转换。用20位位签名(11111111000000^^^111,压缩签名为8o6z3^3o)生成的ssl状态转换机。
本发明的进一步改进,步骤(6)中所述识别ssl流量的具体过程为:
1)将实验数据集中所有流的前n位分别提供给ssl状态转换机,ssl状态转换机进行允许的转换;
2)如果数据流能达到ssl状态转换机最终状态,则流被标记ssl流。如果没有达到最终状态,则标记为非ssl。
本发明的进一步改进,步骤(8)所述ssl流集数据预处理的具体过程为:
1)读取数据流,选择每个会话中前a个包,判断每个数据包长度是否大于b个字节;
2)如果有效负载长度超过b,则执行截断,如果有效负载长度小于b,则执行零填充;
3)对提取的数据进行归一化处理,设时间步长t时固定的线性向量xt的维数设为c,可以推导出(a*b)/c个向量;
4)将处理好后的ssl流量数据集分为训练集和测试集两部分。
本发明的进一步改进,步骤(9)所述识别sslvpn加密流量的具体过程为:
1)采用训练集的数据流训练基于注意力机制的双向gru网络流量识别模型;
2)用测试集数据流测试模型分类效果,调节模型参数;
3)重复步骤1),2),直至得到最优的基于注意力机制的双向gru网络流量识别模型。
本发明的有益效果:与现有技术相比,本发明包括以下优点和有益效果:
(1)本发明对sslvpn流量的识别两个步骤,先利用bit级dpi指纹生成技术识别ssl流量,缩小识别范围。再利用基于注意力机制的双向gru网络流量识别模型识别sslvpn流量。相比于单步实现流量识别,分阶段实现目标流量的识别,会更加精确有效,提高了识别准确率。
(2)bit级dpi指纹生成技术识别ssl流量,这种方法扩大了ssl流识别的范围,不仅能够识别ssl握手阶段的流,同时也能识别数据传输阶段的ssl流,有效解决了传统ssl加密流量指纹识别方法存在的漏识别率较高的问题。
(3)基于注意力机制的双向gru网络流量识别模型,不仅克服需要手工提取特征且难以获取最优特征子集的问题,还能提取网络流量中具有非常显著性的细粒度的特征,从而更加有效地捕捉网络流量中存在的依赖性,提升识别准确率。
附图说明
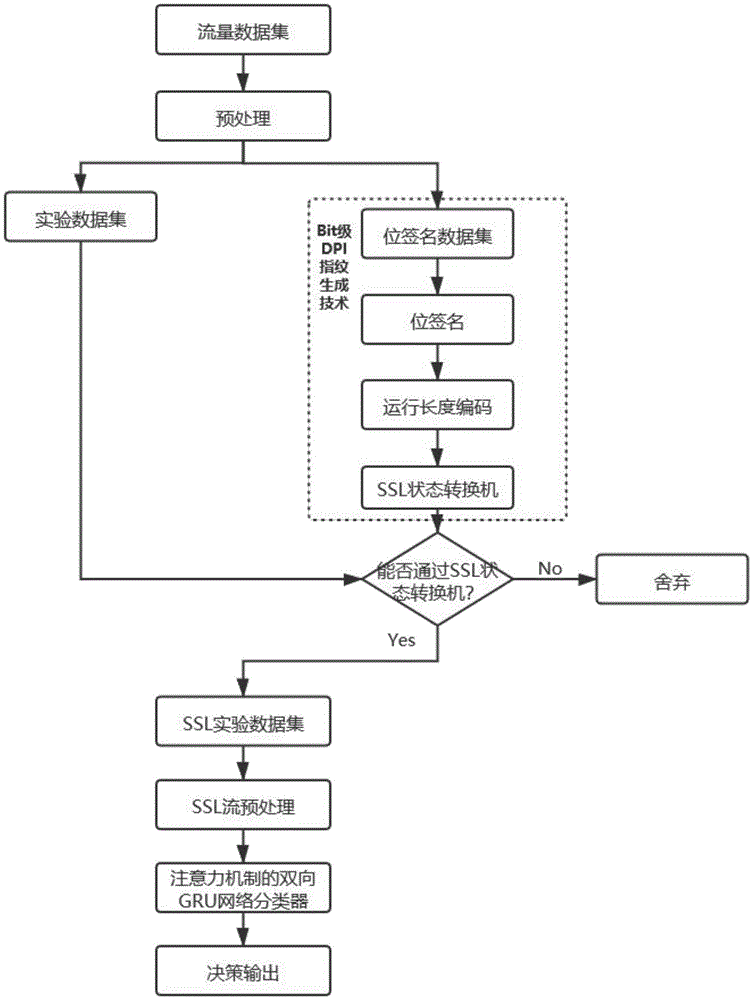
图1为本发明的针对基于ssl加密的vpn流量识别模型整体流程图。
图2为本发明生成位签名的原理示意图。
图3为本发明生成ssl状态转换机的示意图。
图4为本发明与传统方法ssl流识别结果对比图。
图5为本发明与传统方法sslvpn加密流识别结果对比图。
具体实施方式
为了加深对本发明的理解,下面将结合附图和实施例对本发明做进一步详细描述,该实施例仅用于解释本发明,并不对本发明的保护范围构成限定。
现在结合附图对本发明作进一步详细的说明。
实施例:一种针对基于ssl加密的vpn流量识别方法,针对传统ssl加密流量指纹识别方法存在的漏识别率较高的问题,采用bit级dpi指纹生成技术识别ssl流量。对数据进行预处理后,通过特定的规则生成位签名,再对位签名进行运行长度编码,利用编码后的位签名生成ssl状态转换机,用来识别ssl流量。在已识别的ssl流量基础上利用基于注意力机制的双向gru网络流量识别模型,识别sslvpn流量。
如图1所示,面向类别不平衡下的加密流量识别方法过程至少包括:获取数据集、数据预处理、bit级dpi指纹生成、识别ssl流量、ssl流集数据预处理、识别sslvpn加密流量和指标结果分析几个步骤。
获取数据集:采用的是lashkar等人在2016年发布的vpn-nonvpn数据集,通过五元组对流量过滤分流获取原始实验数据集。其中对于tcp流,本发明实验判定条件是以握手协议中的syn标志位开始,并且以fin标志位或者rst标志位结尾的tcp双向流。对于udp流,由于udp协议设计特点不同于tcp协议有着显式的fin结束标志,本发明则以第一个数据包到达为开始,如果两个数据包到达的时间间隔超过一分钟,则可认为数据流结束,意味着新数据流的开始。
数据预处理:提取实验数据集和位签名数据集中每条流内所有数据包是否含有有效载荷数据,若含有有效载荷,则将有效载荷提取出来并按顺序连接起来,用作后续签名生成阶段的输入。
bit级dpi指纹生成:一个完整的握手协议,其通信过程一定包含5种类型协议,基于传统的dpi检测技术若某数据流中未能全部包含以上5种类型的消息,则判断为非ssl流。因此,会产生漏识别的情况。为了解决这一问题,本文提出一种基于bit级dpi的ssl加密流量识别技术。不仅能够识别ssl握手阶段的流,同时也能识别数据传输阶段的ssl流,有效解决了漏识别率高的问题。
bit级dpi指纹生成技术具体过程实现如下:
根据一定的规则,使用前一阶段选择的有效载荷的不变位集生成应用程序特定的位签名;
位签名由1位、0位和^位组成,每个签名为n位。对位签名进行运行长度编码(rle),将许多连续数据元素中具有相同数据值的序列存储为单个值,并存储该数据值重复的次数计数;
根据压缩后的位签名确定ssl状态转换机的状态个数,再为每一个状态配置相应的计数器作为保护,只有当约束被满足(评估为true)时,才允许转换。
识别ssl流量:提取实验数据集所有数据流有效负载的前n位作为输入(从第一个位到最后一个位,每次一个位),来自测试流的n位将提供给ssl状态转换机。ssl状态转换机进行了允许的转换,如果数据流能达到ssl状态转换机最终状态,则流被标记ssl流。如果没有达到最终状态,则标记为非ssl。用识别为ssl流的数据流组成ssl流量数据集。
ssl流集数据预处理:读取ssl流量数据集中所有的数据流,选择每个会话中前a个包,判断每个数据包长度是否大于b个字节。如果有效负载长度超过b,则执行截断,如果有效负载长度小于b,则执行零填充。然后,对提取的数据进行归一化处理,设时间步长t时固定的线性向量xt的维数设为c,可以推导出(a*b)/c个向量。最后,将处理好后的ssl流量数据集分为训练集和测试集两部分。
识别sslvpn加密流量:把训练集的数据流输入到基于注意力机制的双向gru网络流量识别模型中识别目的加密流量,通过测试集数据流调试模型参数,得到最优的分类器模型并决策评估。其中基于注意力机制的双向gru网络流量识别模型主要流程如下:
网络流量识别模型由两个双向gru层(即gru层-1和gru层-2)组成。每一层由前向gru和后向gru组成。每个gru包括输入层和自连接隐藏层;
并非所有的包向量对流量的分类都有同等的贡献。因此,应该更加注意更有用的向量。利用注意层为每个隐藏状态生成一个权值。将每个隐藏状态和其对应的权值进行计算,得到注意力层向量;
使用全连接连接步骤2)的输出,完成流量识别。
注意力机制的双向gru网络流量识别模型能提取网络流量中具有非常显著性的细粒度的特征,从而更加有效地捕捉网络流量中存在的依赖性,更有利于加密流量的识别效果。
指标结果:对实验结果得到的指标结果进行分析,并选取合适的参数,优化算法,提高识别率。
如图2所示,生成位签名的规则是如果每个流的第k位(1≤k≤l)的值都为0,k签名位设置为0,如果每个流的第k位(1≤k≤l)的值为1,k签名位设置为1。如果这些位的位置中有0位和1位,则第k个签名位设置为^。图2显示了一个使用位的ssl流位签名生成。在这个示例中,有3个流,每个流有15位,用于签名生成。
如图3所示,用20位签名(11111111000000^^^111)生成的示例状态转换机。在状态转换机中有5种状态,从q0到q4,q0是开始状态,q4是结束状态。每个状态都有一个计数器(c0到c4),每次转换访问该状态时,该计数器都会被初始化为一个新值。机器在q0状态下启动,将q0的计数器设置为0,从测试流中读取比特,并进行允许的转换以达到最终状态。状态转换机的转换有一个输入符号(位值)和一个对计数器值的约束,计数器值充当保护,只有当约束被满足(评估为true)时,才允许转换。
状态q0在输入1上定义了一个到自身的转换(selfloop)。这个转换对c0的计数器值有一个限制,它在0到8之间。这个约束映射了在开始时在流中读取8个连续的1的要求,而每次遍历计数器值时都要将其增加1。从q0到q1的下一个过渡是在输入0上,只有当c0处的计数器值为8时才有效(已经读取了8个连续的1),并将q1处的计数器c1设置为1(在8个连续的1之后读取0)。无论何时在签名中有^,它将有两个转换,一个是输入0,另一个是输入1,这两个转换都将增加下一个状态的计数器值。同样,所有的比特和它们的位置都由状态转化机强制执行。
如图4所示,可以看出传统的识别方法最高的识别准确率为94.3%,最低的识别准确率仅为81.5%,本发明bit级dpi指纹生成技术具有明显的提升识别效果,其最高的识别准确率为100%,最低的识别准确率为96.8%,具有良好的识别效果。传统的ssl加密流量指纹识别方法在没有检测到完整的ssl握手协议的消息,就会将其判定为非ssl流,而本发明采用的方法有效的解决了传统ssl加密流量指纹识别方法存在的漏识别率较高的问题。
如图5所示,当前识别sslvpn加密流量效果最好的采用的是机器学习模型,不止需要手工提取特征,而且其训练过程相对简单,实验平均的精确率、召回率和f1-measure仅有92.6%、91.9%和92.1%。本发明模型融合双层gru网络模型自动提取特征和注意力机制对不同特征赋予不同的权重,模型能够专注于有用特性。最终,模型平均的精确率、召回率和f1-measure达到了97.5%、97.4%和97.5%以上,本发明模型取得了良好的识别效果。
以上显示和描述了本发明的基本原理、主要特征及优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!