用于估计个人听者的大脑对声音信号刺激的系统响应的方法与流程
本发明涉及一种用于估计个人听者的大脑对声音信号刺激的系统响应的方法,所述系统响应表示在听者的头部的给定测量点处测量的由所述声音信号刺激引起的脑电图(electroen-cephalography,eeg)信号的生成。本发明还涉及一种通过使用在听者的头部的给定测量点处测量的脑电图信号,对个人听者对至少第一有用信号和第二有用信号中的一个的注意力进行听觉注意力解码的方法。本发明还涉及一种助听器,其被配置成估计助听器用户的大脑对声音信号刺激的所述系统响应。
背景技术:
当人类听觉系统受到声学信号的刺激时,人类大脑对声学刺激的反应可以通过使用听者的头部上的相应电极的脑电图(eeg)来测量。听者的神经活动经历变化,这些变化以固定的时延和相似的波形跟踪声学刺激的改变。这种由特定声学刺激引起的神经活动的改变(诸如,正弦音调或短音节,如/da、/ta或类似的)称为听觉诱发电位(auditoryevokedpotential,aep),其可以通过听者的头部的电极来测量。
当用作对听者的声学刺激的声音包含多个有用信号(诸如,来自两个或更多个不同扬声器的语音信号)时,由听者的头部的一个或多个电极测量的对应eeg信号可以用于根据每个语音信号的变化与对应eeg信号之间的相关性来推断听者实际正在注意语音信号中的哪一个,由于调制的改变随不同的语音信号而变化,所以eeg信号可以显示哪个调制模式,从而可以显示语音信号中的哪一个是实际刺激听者的神经活动的语音信号。这种方法称为听觉注意力解码(auditoryattentiondecoding,aad)。
由于与声音信号刺激有关的真实eeg信号只能针对所有语音信号在一起的混合进行测量,所以对于通过eeg进行的aad来说,需要对听者的大脑对声音信号刺激的系统响应进行估计,以便能够以某种方式模拟在没有任何其他语音信号的情况下每个单独的语音信号在听者的大脑中引发的神经活动,以在语音信号可以通过声音信号处理技术彼此分离时,用于观测真实测量的eeg信号与每个语音信号的模拟或推断的神经反应之间的相关性。aep和通常与听觉事件有关的eeg信号已经变得越来越令人感兴趣,特别是在助听器的上下文中,将一个扬声器的语音从混合的多扬声器声音情景中分离出来是常见的信号处理任务。
技术实现要素:
因此,本发明的目的是提供一种用于估计个人听者的大脑对声音信号刺激的系统响应的方法,该方法可以与助听器中使用或应用的aad过程兼容,并且该方法将允许推断在听者的头部的给定测量点处的并且与所述声音信号刺激有关或对应的eeg信号。本发明的另一目的是提供一种用于aad的可靠的方法,该方法也可用于助听器。最后,本发明的目的是提供一种带有助听器的收听系统,该系统能够估计个人听者的大脑对声音信号刺激的系统响应。
根据本发明,第一个目的通过一种用于估计个人听者的大脑对声音信号刺激的系统响应的方法来解决,所述系统响应表示在听者的头部的给定测量点处测量的由声音信号刺激引起的eeg信号的生成,其中包含声音信号刺激的第一声音信号被呈现给听者的耳朵,其中生成对应于第一声音信号的第一音频信号,并且从第一音频信号中提取第一音频信号数据,其中在听者的头部的所述给定测量点处使用第一测量电极,在包含声音信号刺激的第一声音信号撞击(impinge)在听者的所述耳朵上时测量第一eeg训练信号,并且根据第一eeg训练信号生成第一测量数据集,并且其中在第一声音信号撞击在听者的所述耳朵上时,在听者的头部的噪声测量点处使用噪声测量电极测量噪声信号,并且根据噪声信号生成噪声数据集。
此外,在该方法中,在给定第一测量数据集的观测值的情况下,根据第一测量数据集和噪声数据集推导出听者的大脑对所述第一音频信号数据的系统响应的高斯条件概率密度函数(conditionalprobabilitydensityfunction,cpdf),并且其中,针对所述给定测量点,所述高斯cpdf被视为听者的大脑对声音信号刺激的系统响应。特定优点的实施例将在以下描述和从属权利要求中概述。
根据本发明,第二个目的是通过一种用于对个人听者对至少第一有用信号和第二有用信号中的一个的注意力进行aad的方法来解决,其中听者的耳朵暴露于包含声音信号刺激的第一声音信号,其中听者的大脑对所述给定测量点处的声音信号刺激的系统响应是借助于使用布置在所述给定测量点处的测量电极来测量的第一eeg训练信号来估计的,所述估计是使用上述方法来执行的,声音信号刺激被包含在所述第一声音信号中,其中包含至少第一有用信号和第二有用信号的环境声音在听者的所述耳朵处被转换成第二音频信号,其中从第二音频信号中提取第一有用信号的第一信号贡献,并且其中从第二音频信号中提取第二有用信号的第二信号贡献。
此外,aad方法包括根据听者的大脑的系统响应和第一信号贡献推导出第一重构eeg信号,并且根据听者的大脑的系统响应和第二信号贡献推导出第二重构eeg信号,其中当环境声音撞击在听者耳朵上时,借助于位于所述给定测量点处的测量电极来测量第一eeg应用信号,并且其中根据所述第一eeg应用信号与第一重构eeg信号之间的相关性并且根据所述第一eeg应用信号与第二重构eeg信号之间的相关性,推断听者对第一有用信号或第二有用信号的注意力。根据本发明,用于个人听者的aad的方法共享根据本发明的所提出用于估计听者的大脑的系统响应的方法的益处。用于估计听者的大脑的系统响应的所述方法及其实施例的所公开的优点可以以直接的方式转移到aad方法。
最后,根据本发明,第三个目的通过一种包括助听器的收听系统来解决,该助听器包括:至少第一输入换能器,其被配置成将第一声音信号转换成第一音频信号;和/或至少第一输出换能器,其用于根据第一音频信号生成第一声音信号;第一测量电极,其被配置成测量助听器用户头部的第一电信号,第一电信号指示由包含在所述第一声音信号中的声音信号刺激所刺激的第一eeg训练信号;噪声测量电极,其被配置成在助听器用户的头部测量指示针对第一eeg训练信号的噪声信号的另一电信号,并且该收听系统还包括数据处理设施,被配置成根据所述第一电信号推导出第一eeg训练信号、根据所述另一电信号推导出噪声信号、处理所述第一音频信号的,并且还被配置成通过采用上述相应估计方法来估计助听器用户的大脑对包含在第一声音信号中的所述声音信号刺激的系统响应,该估计使用第一音频信号、第一eeg训练信号和噪声信号。
根据本发明,收听系统分共享根据本发明的所提出的用于估计听者的大脑的系统响应的方法的益处和所提出的aad方法的益处。用于估计听者的大脑的系统响应的所述方法和用于所述aad方法的所公开的优点以及它们的相应实施例可以以直接的方式转移到助听器。在收听系统的上下文中,如果噪声信号指示在第一eeg训练信号的测量中存在噪声,则该噪声信号应被理解为与第一eeg训练信号有关。特别地,为此,噪声信号与第一eeg训练信号同时测量。
关于用于估计个人听者的大脑对声音信号刺激的系统响应的方法,所述系统响应θ应当表示声音信号刺激s可能在听者的大脑中引起的神经活动,使得在给定测量点处可以测量由r表示的eeg信号(可能在从布置在所述给定测量点处的测量电极的电信号中减去由参考测量电极测量的参考信号之后),其中eeg信号r由卷积s*θ给出,可能受一些附加噪声的影响。
一方面,第一声音信号可以是撞击在听者耳朵上的环境声音,其包含用于该方法的适当的声音信号刺激,并且其通过适当的输入换能器被转换成第一音频信号(即被配置成将声音转换成电信号),该输入换能器优选地靠近所述耳朵。另一方面,可以由位于听者耳朵附近的适当的输出换能器(即被配置成将电信号转换成声音)根据第一音频信号生成第一声音信号,生成的第一音频信号使得对应的第一音频信号包含适当的声音刺激,例如正弦音调或正弦音调的序列或叠加。
第一音频信号数据尤其包括第一音频信号的以可用于该方法的方式(例如,通过下采样和/或将数据截断成特定长度的帧)进行处理的声学信息,该第一音频信号数据优选地与声音信号刺激的持续时间有关。为了从第一音频信号中提取第一音频信号数据,可以应用例如放大和/或降噪等的进一步或其他处理。
第一eeg训练信号可以由第一测量电极的信号直接给出,或者可以根据所述信号推导出,特别地,通过减去位于适当参考测量点处的参考测量电极的适当参考信号来推导。由于第一eeg训练信号被测量,所以当包含声音信号刺激的第一声音信号撞击在听者耳朵上时,eeg训练信号指示听者的大脑针对所述声音信号刺激的神经活动。对于估计,即模型的“训练”,在声音信号刺激由正弦音调或短音节给出的情况下,第一eeg训练信号可以由aep或听觉事件相关电位给出。第一eeg训练信号也可以由任何其他类型的听觉事件相关的eeg信号给出,该eeg信号由任何种类的声音信号刺激引起,尤其是由语音信号引起。
第一测量数据集和噪声数据集可以通过数据处理(诸如,将数据截断到特定帧(即时间窗))分别根据第一eeg训练信号和噪声信号来生成,该数据处理优选地与声音信号刺激的持续时间和/或下采样相关。优选地,第一测量数据集、第一音频信号数据和噪声数据具有相同的采样率,例如,64hz。
测量噪声信号是为了识别存在于第一eeg训练信号中的神经活动中的“噪声”,该“噪声”与声音信号刺激无关,并且不能通过数据处理去除。由于该噪声通常具有统计性质,所以简单的减法也不会提高第一eeg训练信号中所包含的信息的质量。
然而,噪声数据的该统计信息可以与系统响应和测量的神经活动都是联合高斯分布的假设(由测量结果证明的假设)结合使用。这个假设并不太明显,因为语音的幅度例如遵循拉普拉斯分布。在这个假设下,给定第一测量数据集的观测值,可以针对系统响应,用公式表示高斯cpdf(即贝叶斯pdf)。当已经观测到给定的第一测量数据集作为对已知来自第一音频信号的声音信号刺激的反应时,该高斯cpdf给出了找到系统响应的特定值的概率,该系统响应在模型中是对神经活动建模的一组滤波器系数或滤波器系数的矢量。因此,高斯cpdf将噪声统计作为提高系统响应的预测的分辨率的一个因素。事实上,在上述高斯假设下,噪声统计的使用,尤其是方差的使用,允许将噪声集成到基础线性模型r=s*θ(其中r是eeg信号,s是声音信号刺激,θ是系统响应)中。
用于将声音信号刺激与代表大脑对所述声音信号刺激的反应的eeg信号相关联的传统模型至少隐含地涉及声音信号刺激向eeg信号的“传播”的矩阵方程,“传播核”是系统响应。然而,这种基于矩阵的模型至少隐含地依赖于所述“传播核”矩阵的确定,主要是通过相关性测量。然而,该矩阵可能是高度欠定的,因此为了执行矩阵求逆以能够预测大脑对给定声音信号刺激的反应,要么需要测量非常大的训练数据集,要么必须对该矩阵应用正则化技术从而引入不希望的偏差。本发明采用不同的方法,其依赖于具有上述针对系统响应和测量的神经活动的联合概率分布的高斯假设的统计模型,因此能够通过条件概率来推断系统响应,并且能够将测量的噪声(这是将声音信号刺激的“传播”转化为神经反应的一个主要问题)作为相应的噪声统计(例如,以附加方差项的形式)。
高斯cpdf可以作为估计的系统响应,该高斯cpdf尤其可以借助于在给定第一测量数据集的观测值的情况下的系统响应的条件期望值,根据第一测量数据集(即表示eeg信号r)和系统响应θ的联合高斯概率分布而获得。由于系统响应在很大程度上依赖于第一测量数据集,而第一测量数据集又取自在第一测量点处测量的第一测量数据,所以系统响应对于在该测量点处执行的其他测量具有预测值。为了在另一不同的测量点处获得系统响应的估计,优选地,将在该不同的测量点处测量不同的eeg训练信号(其可以包含对在参考点处测量的参考信号执行减法),并且上述估计基于在另一测量点处取得的对应测量数据来完成。
优选地,第一包络被提取为第一音频信号的包络,其中根据第一包络推导出第一音频信号数据。可以看出,eeg信号通常跟踪声音信号刺激的包络,因此丢弃与音频信号的相位相关的信息不会损害该方法,同时降低了数据开销。
如果采用下采样过程、根据第一包络推导出第一音频信号数据,则更有利。在某些情况下,感兴趣的神经活动尤其是由处于1-8hz的范围内的所谓的delta波和theta波给出的。因此,通过下采样,第一音频信号数据的时间分辨率可以适应于第一测量数据集的时间分辨率(就采样率而言)。
优选地,采用下采样过程、根据第一eeg训练信号生成第一测量数据集,和/或采用下采样过程、根据噪声信号生成噪声数据集。考虑到为了正确识别相应峰值,采样速率为例如8倍的神经活动波的频率可能就足够了,从而下采样可以帮助简化下面的计算。对于所述delta波和theta波,这意味着64hz的采样率可能足够了。
在实施例中,在给定第一测量数据集的观测值的情况下,根据听者的大脑的系统响应和第一测量数据集的高斯联合概率密度函数推导出听者的大脑对第一音频信号数据的系统响应的高斯cpdf。这考虑到第一测量数据集(如根据第一eeg训练信号推导出的)和大脑的系统响应两者都可以被假设为高斯。在这种情况下,由于可以使用高斯函数及其协方差矩阵的整个框架,所以可以简化计算。
具体地,在给定第一测量数据集的观测值的情况下,听者的大脑对第一音频信号数据的系统响应的高斯cpdf由以下形式的期望值给出:
e(θ/r)=μθ+cθθst(scθθst+cw)-1(r-sμθ)
其中,e(·)表示期望值、r表示主数据集、θ表示听者的大脑对包含在第一音频信号数据中的由s表示的声音刺激的系统响应、μθ和cθθ分别表示θ的期望值e(θ)和协方差矩阵、cw表示噪声数据集w的协方差矩阵、以及s表示构造为使得从乘积s·θ产生的矢量逐条目地表示针对不同时间自变量的两个矢量s和θ的卷积的矩阵,即s(j,k)=s(j-k),其中s的长度为n个条目,并且对于j<0或j≥n,s(j)=0。
由于期望值e(θ)可以假设为零,并且cθθ(θ的协方差矩阵)可以通过选择适当的归一化和θ的基而被设置为单位矩阵,因此可以进一步简化针对听者的大脑对声音信号刺激的系统响应的估计的结果。该估计产生了cpdf:
e(θ/r)=st(s·st+cw)-1·r
在另一实施例中,使用多个声音信号刺激,以便生成初步高斯cpdf的集合,通过采用上述方法并通过使用所述多个声音信号刺激中的不同声音信号刺激来估计初步高斯cpdf的集合中的每一个初步高斯cpdf,其中针对所述给定测量点,根据所述初步高斯cpdf的算术平均推导出听者的大脑对声音信号刺激的系统响应。这意味着:多个优选的不同的声音信号刺激v1,v2,...,逐个呈现给听者的收听。每个声音信号刺激vj的对应eeg训练信号被测量,同样每个声音信号刺激vj期间的对应噪声信号也被测量。根据每个eeg测量生成测量数据集rj,测量数据集中的每一个对应于声音信号刺激vj,并且根据对应的噪声信号生成噪声数据集nj。根据每个声音信号刺激vj生成(根据声音信号刺激vj的记录生成,或者通过对由扬声器/接收器呈现给听者收听的声音信号进行处理和可能的下采样而生成)音频信号数据sj。对于声音信号刺激vj中的每一个,估计初步高斯cpdf,即ej(θj|rj)。最后,听者的大脑对一般声音信号刺激的系统响应是通过使用关于初步高斯cpdf的算术平均(即关于j的ej(θj|rj)进行平均)来获得的。由于生成噪声信号的噪声被认为与信号不相关,所以该平均进一步有助于减少噪声i对系统响应的估计的影响。
关于aad方法,aad是借助于在给定测量点处测量的eeg信号来执行的。对于aad,需要听者的大脑关于该测量点的系统响应。因此,所述系统响应的估计是通过根据第一eeg训练信号生成第一测量数据集来执行的,第一eeg训练信号是使用所述给定测量点处的测量电极来测量的。优选地,相同的测量电极既用于系统响应的估计,还用于被用于aad框架中的相关性的第一eeg应用信号的测量。然后,不需要进一步校准。当在助听器或另一收听设备的帮助下执行aad方法时,使用相同的测量电极来估计系统响应和实际aad是有利的。注意,特别地,第一eeg应用信号可以与第一eeg应用信号不同主要在于使用阶段,即对于模型的“训练”(估计阶段)或对于模型在aad中的应用,但是优选地,所述两个信号没有进一步的物理或概念差异。
一旦知道了所需的系统响应,听者的耳朵就暴露于包含感兴趣的有用信号的环境声音中。通常,这些有用信号是由单个扬声器的语音贡献给出的。为了解码听者实际上正在关注哪个扬声器,从表示环境声音的第二音频信号中提取它们的相应信号贡献。这种提取可以通过例如盲源分离技术(blindsourceseparation,bss)来实现。通过使用系统响应,即通过使用听者的大脑的系统响应,根据信号贡献推导出相应的重构eeg,该系统响应包含关于大脑将在感兴趣的测量点处对某些声音信号刺激表现出哪种反应的信息,该信息被用来推断在高斯模型内大脑将对由相应有用信号贡献给出的刺激表现出什么反应或者由此推导出的某些数据。
针对与在环境声音包含撞击在听者的耳朵上的有用信号的时间期间在测量点处执行的“真实”eeg测量(即第一eeg应用信号)的可能的相关性,分析对于每个有用信号的这种“推断”、重构eeg信号。与相应的重构eeg信号的相关性越高,听者就越可能关注潜在的有用信号。
在aad方法的实施例中,从第一有用信号的第一信号贡献中提取第一有用信号包络,并且根据听者的大脑的系统响应和第一有用信号包络推导出第一重构eeg信号,和/或其中,从第二有用信号的第二信号贡献中提取第二有用信号包络,并且根据听者的大脑的系统响应和第二有用信号包络推导出第二重构eeg信号。使用信号包络允许更有效的计算,因为不需要与第一和第二信号贡献的相位相关的信息开销。优选地,当根据声音信号中给出的声音信号刺激来推断相应eeg信号时,经由第一音频信号数据,系统响应的估计被适配为使用对应的信号包络作为输入。
优选地,借助于使用布置在所述第二测量点处的第二测量电极测量的辅助eeg训练信号来估计听者的大脑对关于听者的头部的第二测量点的声音信号刺激的辅助系统响应,所述估计是使用上述方法执行的,声音信号刺激被包含在所述第一声音信号中,其中根据听者的大脑的辅助系统响应和第一有用信号的第一信号贡献推导出第三重构eeg信号,其中根据听者的大脑的辅助系统响应和第二有用信号的第二信号贡献推导出第四重构eeg信号,其中,当环境声音撞击在听者耳朵上时,借助于所述第二测量点处的测量电极来测量辅助eeg应用信号,并且其中,考虑所述辅助eeg应用信号与第三重构eeg信号之间的相关性以及所述辅助eeg应用信号与第四重构eeg信号之间的相关性来推断听者对第一有用信号或第二有用信号的注意力。
这允许对取自不止一个测量点处的eeg信号进行积分(integration)。因此,一方面,通过对第一和第二重构eeg信号与相应第一测量数据之间的相应相关性进行平均或对其进行加权决策,另一方面,通过对第三和第四重构eeg信号与辅助eeg应用信号之间的相应相关性进行平均或对其进行加权决策,可以提高aad的可靠性。优选地,为此,辅助eeg应用信号通过下采样来处理。优选地,用于测量辅助eeg训练信号(其进而用于估计听者的大脑在第二测量点处的辅助系统响应)的第二测量电极还用于推导出辅助eeg应用信号,该辅助eeg应用信号用于与第三和第四重构eeg信号相关。
关于收听系统,第一音频信号可以是撞击在助听器用户的耳朵上的声音信号,并且第一输入换能器将第一声音信号转换成第一音频信号、或包含特定频率的探测音调(probetone)(诸如正弦)或其混合的探测信号、或诸如/da、/ta的短音节,并且输出换能器将第一音频信号转换成第一声音信号。特别地,在上述两种情况下的第一音频信号也可以包含语音信号。
噪声信号可以由来自噪声测量电极的所述另一电信号的函数给出(例如通过从参考测量电极减去电参考信号),或者同样可以由所述另外的电信号直接给出。在后一种情况下,在数据处理设施中根据所述另一电信号推导出噪声信号变得微不足道。
数据处理设施可以由作为助听器的一部分的一些微机电设备给出,优选地包括用于该估计所需的计算的cpu和分别寻址的ram,或者可以被给出为在与助听器数据连接的外部设备(例如,移动设备)上部分实施。在后一种情况下,数据处理设施的一部分位于助听器中以便推导出所提到的信号,并且数据处理设施的一部分位于外部设备中以用于执行系统响应的估计的计算。第一测量数据集、噪声数据集和来自对应信号的第一音频信号数据的生成可以在数据处理设施的任一部分中实施。数据处理设施尤其还应包括用于生成所需信号的不在助听器的主信号处理单元(例如,如asic等)中实施的各种信号处理电子器件。
在收听系统的实施例中,数据处理设施还被配置成根据第一电信号推导出第一eeg应用信号,并且当包含第一有用信号和第二有用信号的环境声音被转换成第一音频信号时,通过使用第一eeg应用信号,执行用于对助听器用户对上述至少第一有用信号和第二有用信号中的一个的注意力进行aad的方法。在助听器信号处理的框架中,将aad应用于助听器是非常有益的,因为它允许根据助听器用户是否将注意力指向所述有用信号来对有用信号进行特定处理。
特别地,数据处理设施还被配置成当听觉注意力解码结果产生助听器用户对第一有用信号的注意力时,通过增强第一信号贡献来处理第一音频信号。如果助听器包括不止一个输入换能器,则增强可以通过例如bss技术或通过波束形成来实施。
在实施例中,收听系统的助听器包括参考测量电极,该参考测量电极被配置成在听者的头部上的参考测量点处测量电参考信号,其中数据处理设施被配置成根据第一电信号和电参考信号推导出第一eeg训练信号和/或第一eeg应用信号,优选地作为差信号,和/或根据噪声测量电极信号的所述另一电信号和电参考信号推导出噪声信号,优选地作为差信号。使用所述电参考信号允许更好地平均系统“共模”波动。
在实施例中,收听系统的助听器包括被配置成至少部分地佩戴在所述耳朵的耳廓后面的耳钩和具有被配置成至少部分地插入助听器用户的耳朵的外耳和/或外耳道中的模具的听筒(earpiece),其中第一测量电极布置在耳钩上,使得当耳钩被至少部分地佩戴在耳廓后面时,第一测量电极与助听器用户的头皮接触,优选地在耳廓后面或耳廓到头皮的过渡部分的上方。特别地,助听器可以是bte型的,和/或耳钩可以包括用于电子组件的外壳,第一测量电极布置在所述外壳的侧面。耳钩的使用允许将第一测量电极与噪声测量电极分离,从而降低噪声信号与第一eeg训练和应用信号之间的系统相关性。优选地,接地装置也位于模具上。
在另一实施例中,噪声测量电极布置在助听器的模具上,使得当模具相应地插入时,噪声测量电极与外耳或外耳道的皮肤接触。这产生噪声测量电极与第一测量电极的高空间分离。
在可选实施例中,噪声测量电极布置在助听器的耳钩上,在空间上与第一测量电极分离,并且使得当耳钩被至少部分地佩戴在耳廓后面时,噪声测量电极与助听器用户的头皮接触,优选地在耳廓后面或耳廓到头皮的过渡部分的上方。如果模具上的空间不足以容纳噪声测量电极和可能的参考测量电极,则这可能是有利的。
在另一实施例中,参考测量电极被布置在助听器的模具上,使得当模具相应地插入时,参考测量电极与外耳或外耳道的皮肤接触。
附图说明
下面借助附图解释本发明的实施例。具体地,
图1示意性地示出对应于正弦音调的aep的图;
图2示意性地示出在声音信号刺激期间,由人体头部上的相应测量电极测量的一组不同的aep信号;
图3是使用高斯cpdf方法,通过测量eeg信号和噪声信号来估计听者的大脑对声学刺激的系统响应的方法的框图;
图4是采用根据图3中显示的方法来估计的听者的大脑的系统响应,对个人听者对两个有用声学信号中的一个的注意力进行aad的方法;
图5以侧视图示意性地示出配置成执行根据图3的估计方法和根据图4的aad方法的助听器;并且
图6以侧视图示意性地示出配置成执行根据图3的估计方法和根据图4的aad方法的助听器的替代实施例。
在不同的附图中,相互对应的部分和量用相同的参考符号标记。
具体实施方式
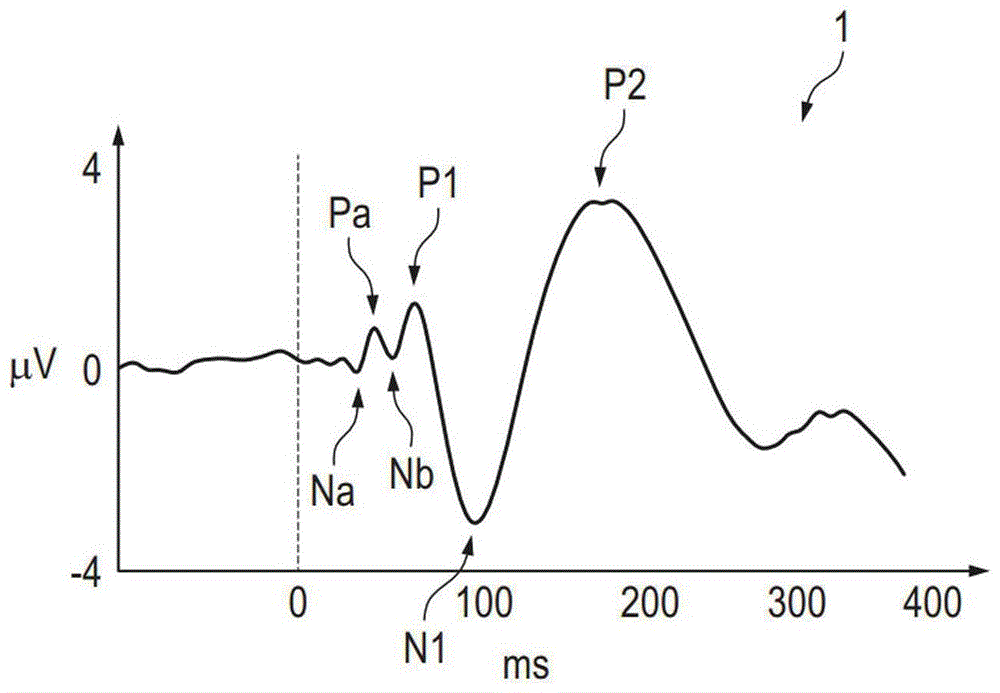
图1示意性示出由可听正弦音调(例如,频率为1khz)诱发的aep1,因为它可以例如经由对通过位于正在听正弦音调的人的头部的适当测量电极的eeg测量值进行整体平均来测量。aep1在所测量的μv随时间(以ms为单位)变化的图中描绘。在t=0ms处,正弦音调被激活。从图1可以看出,在正弦音调从0ms开始之前,测量aep1的eeg信号有小的波动。正弦音调在0ms开始之后,eeg信号随着增加的强度慢慢开始出现正负峰值。在大约30ms处,在eeg信号中可以注意到第一个小的负峰值,由na表示,随后在大约40ms处是第一个小的正峰值,由pa表示。接下来,另一对是在大约50ms处的负峰值nb和在大约60-65ms处的正峰值p1,其中,这两个峰值的强度已经比初始负峰值na和正峰值pa的强度更高。
在正弦音调开始后接近100ms处,可以测量到强度接近-4μv的明显的负峰值n1,比先前的负峰值na和nb高大约一个数量级。这个负峰值n1之后是在160-170ms处的强度接近+4μv的明显的正峰值p2。正峰值p2的持续时间比以前的峰值长,因此更难确定该峰值的最大值的准确时刻。
从图1可以看出,在所测量的eeg信号中,在0ms处开始的正弦音调的声学刺激之后,存在强度增加的负峰值na、nb和n1以及正峰值pa、p1和p2的清晰的交替图案。该图案将由正弦音调诱发的aep作为声音信号刺激进行显示。如果声音刺激改变,即如果声音信号的频率或者尤其是幅度经历了实质性的改变,则在相应的aep中也可以看到这种改变,对于各个正峰值和负峰值,在30ms和200ms之间有一定的时滞,如图1所示。
请注意,所测量的aep的确切形状还取决于在听者的头部的点(即eeg测量电极所在的位置)处的特定神经活动。这显示在图2中,其中示出了用测量电极在人体头部的不同位置in、t7、c3、cz、c4和t8处进行的六个不同的aep测量。测量点位于沿听者头皮冠状面从左耳到右耳的拱形上,其中,t7和t8靠近耳朵,cz代表人体头部的“顶点”。位置in对应于位于听者耳朵内部的测量电极,优选地位于外耳道,靠近到外耳的过渡部分。
在六个测量点in、t7、c3、cz、c4和t8处的测量值对应于对在图1中示例性显示的正弦音调(即在图2中显示的六个eeg测量图中的每一个,在=0ms处开始的频率为1hz的正弦音调)做出的反应中获得的aep。
可以看出,在测量点t7、c3、cz、c4和t8处,至少在某种程度上可见与图1所示的aep相当的aep。上述五个图中的每一个都显示了从明显的负峰值(表示在每个位置处测量的最小电压)向明显的正峰值(至少接近在每个位置处测量的最大电压)的急剧转变。对于所讨论的所有五个测量值,这种转变开始于接近100ms之前的负峰值,结束于200ms之前的正峰值。因此,这种转变可以被认为是在图1中的从n1到p2的转变。唯一没有神经反应的测量点(一点aep的痕迹也测量不到)是耳内测量点in。这表明在耳道内部的测量点in处测量的测量信号本质上是系统中存在的噪声。
请注意,对于在头顶(即在位置cz)处进行的测量,所测量的电压达到-10μv到+5μv,即覆盖15μv的总差,而c3和c4的电压范围稍低(大约在10-12μv),并且在“外部”测量点t7和t8处,总电压范围仅覆盖大约6μv(对于t7为-3μv至+3μv,对于t8为-2μv至4μv)。
由此可见,为了确定aep,例如对于aad来说,测量点cz将是有益的。然而,这种测量对于与普通助听器结合使用是不实际的,因为它将需要助听器用户佩戴特定的弓形头戴装置,其中测量电极沿着弓形放置。然而,测量aep的eeg信号越小,通常受噪声影响越大的是该eeg信号,这使得在aad的框架内使用在耳朵附近获得的信号(例如,来自测量点t7和t8的信号)通常是困难的。由于对于aad来说,通常需要一种模型来推断从真实音频信号(表示听者在aad的时刻听到的声音)中提取的信号分量的一些假设的aep,所以这种模型通常是基于给定测量点处的真实aep测量而开发的。因此,低信号质量(就信号中包含的噪声(即snr)而言)使模型恶化,并因此使总的aad方法恶化。
为了解决这个问题,并使aad更适用于助听器,借助于图3中给出的框图,示出了一种用于估计听者的大脑对信号声音刺激的系统响应的改进的方法。在所示的过程中,第一输入换能器2拾取第一声音信号4并将其转换成第一音频信号6。第一声音信号4包含适当且定义明确的短长度(例如,1-3s)声音图案5和明确定义的频谱(诸如正弦音调或带有其谐波的音乐音调,但也是语音信号的短部分)作为支配第一声音信号4的声音信号刺激7。因此,所述第一环境声音4的听者(仅部分示出)的头部8处的神经活动可以被触发,并且可以以下面解释的方式相应地测量eeg信号。第一音频信号6被数字化(未示出),并且从第一音频信号6提取第一包络10,所述第一包络10以64hz下采样,以便生成第一音频信号数据12。第一包络10可以通过在适当的时间窗口上使用希尔伯特变换(hilberttransform),或者仅仅通过获取第一音频信号6的绝对值来从第一音频信号6中提取。
在替代实施例中,可以由声学探测信号生成声音信号刺激7,例如,包括正弦音调或带有其谐波的一组音乐音调,或给定长度的前述语音信号。在这种情况下,第一音频信号由所述声学探测信号给出,该信号由靠近听者耳朵(或在外耳道处或内部)的输出换能器(未示出)转换成第一声音信号4。
在听者的头部8,第一测量电极14位于第一测量点16,并且噪声测量电极18位于噪声测量点20。所述第一测量电极14和噪声测量电极18分别在它们适当的第一测量点16和噪声测量点20的定位可以通过将在其表面包含这两个所述电极14、18的一个单一的设备定位在听者的头部8来实现。在本实施例中,这种设备由bte型助听器(未示出)给出,第一测量电极布置在耳钩外壳的外表面上,以佩戴在助听器用户的耳朵后面,例如,使得第一测量点16对应于图2的测量点t7或t8之一,并且噪声测量电极被布置在耳朵模具上,以至少部分地插入到所述使用者的外耳通道中,例如靠近图2的参考测量点r。
第一电极14生成第一电信号22,而噪声测量电极18生成另一电信号23。根据第一电信号推导出eeg信号,其用作第一eeg训练信号26。在本实施例中,这是通过从第一电信号22中减去电参考信号28来实现的,电参考信号28由位于参考测量点r的对应参考测量电极30来测量,该参考测量点r位于听者的头部,优选地位于或接近他的外耳道。也可以实施用于从第一电信号22生成第一aep26的不同方法。噪声信号24作为噪声测量电极18的输出信号和电参考信号28的差信号而获得。差信号,即第一eeg训练信号26和噪声信号24,在该实施例中是经由运算放大器(未示出)而获得的,该运算放大器放大它们各自输入信号的差值。可以使用用于获得噪声信号的替代方法。此外,接地电极(未示出)可以用于本实施例的运算放大器。
第一eeg训练信号26和噪声信号24都以64hz下采样,以便分别生成第一测量数据集34(根据第一eeg训练信号26生成)和噪声数据集36。下采样到64hz考虑到了aad感兴趣的神经活动是所谓的delta和theta振荡,其仅在8hz上下波动的,因此八倍高的时间分辨率应该足以用于eeg信号,以便识别相关的峰值。更高的时间分辨率在第一包络10中也没有任何意义。
现在,第一测量数据集34基本上是大矢量r,具有来自第一eeg训练信号26的经下采样eeg差信号电压作为其条目,而噪声数据集36是大矢量w,具有来自噪声测量电极18的相应电压作为其条目。相应地,第一音频信号数据12是矢量s,具有经下采样的第一音频信号6的幅度(信号电压)作为其条目。为了进一步处理,矢量s和w被截断成n个样本的长度,优选地按照例如192个样本(对应3秒的声音)的幅度的阶数(order)。特别地,矢量s和w可以被截断为声音信号刺激7的长度。现在必须开发用于正在收听第一声音信号4的人的大脑的系统响应的模型。从图1和图2可以看出,对0ms处声音信号刺激的到来所做出的神经反应的最重要部分发生在最初的300-400ms期间。因此,在声音信号刺激7结束后的300ms或400ms,神经活动以及矢量r中的条目将慢慢消失,或者至少失去它们与由声音信号刺激7给出的声音信号刺激的相关性。因此,可以将系统响应视为由系数矢量θ给出的线性滤波器,其长度p应对应于所假设的最大响应时间(在这种情况下为300-400ms,其对应于大约20-25个滤波器系数,即θ的“样本”),并且其将与第一测量数据集12的矢量s进行卷积,受到在矢量w中表示的噪声的影响。因此,与声音信号刺激7有关的相当大的神经反应可能仅在第一测量数据集12中可见,即在最大程度上对应于声音信号刺激7的长度加上大脑系统响应θ的所假设的“长度”的矢量r的条目中可见,即在本例中,r可能被截断为n+p-1个样本。这个模型然后产生
r=s*θ+w
=s·θ+w
其中,矩阵s具有条目s(j,k)=s(j-k),s(j)为矢量s的条目,其中对于j<0,j≥n,s(j)=0(由于上述第一音频信号数据12的截断)。
在系统响应θ和测量的神经反应(即对应于第一测量数据集12的矢量r)是来自联合高斯pdf的高斯变量的假设下,
其中,可以定义e(·)为期望值,并且c为变量矢量r和/或θ之间的协方差cr/θ,r/θ的协方差矩阵,
可以看出,从这个联合高斯pdf,在给定r的观测值的情况下,可以用逆矩阵(·)-1推导出θ的cpdf作为(条件)期望值,
在给定r的观测值的情况下,可以取高斯pdfp(r,θ)的条件期望值e(θ|r)作为高斯cpfd。e(θ|r)的结果可以进一步被简化为:
e(θ/r)=μθ+cθθst(scθθst+cw)-1(r-sμθ)
其中,μθ是θ的平均值,cw是在矢量w中表示的噪声数据集36的协方差,以及st是s的转置矩阵。
由于所述平均值被假设为零(否则,它可能导致第一测量数据集34中的系统偏移或偏斜),并且由于协方差cθθ(可以通过选择适当的归一化和θ的基而被设置成单位矩阵(identitymatrix)),最终获得听者的大脑对声音信号刺激的系统响应θ的估计,该声音信号刺激由包含在第一声音信号4中的声音信号刺激7给出。该估计产生了cpdf:
e(θ/r)=st(s·st+cw)-1·r.
用于估计系统响应θ的两个关键点是第一测量数据集34和系统响应θ是高斯变量的合理假设使得整个条件概率的工具箱(toolkit)可用,以及噪声数据集36的知识,以便确定用作系统响应θ的估计的cpdf所需的协方差矩阵cw。
听者的大脑的这种系统响应θ可用于aad,这可以通过图4所示的框图中显示的相应方法来解释。首先,关于听者的大脑的第一测量点16的系统响应θ通过图3所示的方法来估计。为此,听者暴露于包含第一声音信号刺激7的第一声音信号4、根据第一声音信号4生成第一音频信号数据12、并且分别经由第一测量电极14和参考测量电极30以及噪声测量电极18测量第一eeg训练信号26和噪声信号24。
一旦系统响应θ已知,就指示在给定特定声音信号的情况下,在第一测量点16预期哪一个eeg信号,该信息就可用于aad。为此,撞击在听者耳朵(未示出)上的环境声音40被第一输入换能器2转换成第二音频信号42,该环境声音包含第一有用信号44和第二有用信号46。第一有用信号44和第二有用信号46通常可以由来自不同扬声器的语音贡献给出,但是也可以由可能被认为对听者“有用”的其他声音信号(与“声音噪声”相反)给出,例如从扬声器播放的音乐可以被包括为有用的信号。
通过包含数字化第二音频信号42的音频信号处理48,第二音频信号42中对应于第一有用信号44和第二有用信号46的信号贡献分别作为第一信号贡献50和第二信号贡献52从第二音频信号42中分离出来。音频信号处理48可以包含适合于所述分离的已知过程,诸如bss。在第二环境声音40被与第一输入换能器2隔开的另一输入换能器(未示出)转换成另一音频信号的情况下,音频信号处理还可以包含波束形成技术,以便提取第一和第二信号贡献50、52,例如,通过将波束指向第一有用信号44和第二有用信号46的相应声源,或者通过借助于凹口形状的(notch-shaped)方向特征选择性地“静音”它们相应的信号贡献,将凹口中的每一个指向所述声源之一。
在不存在其他有用信号的情况下,第一信号贡献50和第二信号贡献52在其分离的分辨率范围内可以被认为是分别对应于第一有用信号44或第二有用信号46的音频信号。然后,通过提取相应的第一有用信号包络54和第二有用信号包络56进一步处理第一信号贡献50和第二信号贡献52,并且通过以64hz下采样,生成第一有用信号数据的矢量s1和第二有用信号数据的矢量s2。
根据第一有用信号数据矢量s1,通过使用系统响应θ的知识,第一重构eeg信号r1被推导为
r1=s1*θ。
以类似的方式,可以根据第二有用信号数据矢量s2和系统响应θ推导出第二重构eeg信号r2。
当包含第一有用声音44和第二有用声音46的环境声音42撞击在听者耳朵上时,第一eeg应用信号58也借助于第一测量点16处的第一测量电极14和参考测量点r处的参考测量电极30来测量。从所述第一eeg应用信号58中,通过下采样提取数据矢量ra,并且现在对所述第一eeg应用信号58的数据矢量ra分别相对于第一重构eeg信号r1和第二重构eeg信号r2中的每一个应用相关分析59(注意,第一重构eeg信号r1和第二重构eeg信号r2不需要任何进一步的下采样,因为它们通过构造具有64hz的采样率)。相关性分析可以包括,例如,计算数据矢量ra与重构eeg信号r1、r2中的每一个的相应相关,或者计算数据矢量ra与重构eeg信号r1、r2中的每一个的互相关,以及关于所述互相关的时间自变量的最大化。
最后,作为aad的结果,从相关分析可以确定听者正将其注意力60指向第一有用信号44和第二有用信号46中的哪一个。如果第一重构eeg信号r1与第一eeg应用信号58的数据矢量ra之间的相关性高于第二重构eeg信号r2与数据矢量ra之间的相关性(就所应用的相关性度量而言),则推断听者正在注意第一有用信号44,而不是第二有用信号46。
为了改进aad,所描述的过程可以另外关于第二测量电极65执行,第二测量电极65位于与第一测量点16间隔开的第二测量点66处。这意味着首先,当听者暴露于包含第一声音信号刺激7的第一声音信号4时,通过使用第一音频信号12、噪声信号24和借助于位于第二测量点66处的第二测量电极65和参考测量电极30测量的辅助eeg训练信号(67),听者的大脑的辅助系统响应θaux通过图3所示的方法来估计。
一旦用于将第二测量点66处的eeg建模为对声音信号刺激7的反应的辅助系统响应θaux已知,则根据辅助系统响应θaux以及第一有用信号数据的矢量s1和第二有用信号数据的矢量s2,分别产生第三重构eeg信号r3和第四重构eeg信号r4。当包含第一有用信号44和第二有用信号46的环境声音40撞击在听者耳朵上时,辅助eeg应用信号68由第二测量电极65测量。特别地,辅助eeg应用信号68也可以借助于参考测量电极30来测量(以类似于aep58的方式)。根据辅助eeg应用信号68,通过下采样生成辅助数据矢量raux,并且对所述辅助数据矢量raux和第三和第四重构eeg信号r3、r4中的任一个之间的相关性进行相关性分析69。由于第三重构eeg信号r3表示听者对第一有用信号44的潜在注意力,所以与第一重构eeg信号r1相同,这些相关性也可以被考虑用于aad的最终结果。
图5示意性地示出bte类型的助听器70的侧视图,包括由耳钩72给出的外壳和带有模具76的听筒74。耳钩72被配置成佩戴在助听器用户(未示出)的耳朵后面,而模具76被配置成至少部分地插入所述用户的外耳道。耳钩72的外壳包含由麦克风给出的第一输入换能器2并连接到由具有cpu和分别寻址的ram的适当微机电设备给出的数据处理设施78,以及位于耳钩72的外侧表面并且还连接到所述数据处理设施78的第一测量电极14。当耳钩72佩戴在助听器用户的耳朵后面时,第一测量电极14与助听器用户的耳朵后面的头皮接触。
在模具76上,在其尖端的相对位置上,布置有参考测量电极30和噪声测量电极18,使得当模具76被相应地佩戴时,所述电极在助听器用户的外耳道处与助听器用户的皮肤接触。噪声测量电极18和参考测量电极30也连接到数据处理设施78。数据处理设施78被配置成根据由第一测量电极14和参考测量电极30的信号之差给出的eeg信号、根据由噪声测量电极18测量的噪声信号、以及根据由第一输入换能器2根据对应声音信号生成的第一音频信号6来估计助听器用户大脑对声音信号刺激的系统响应θ,如图3中相应的方法所描述的。
此外,数据处理设施78被配置成当环境声音包含至少两个不同的有用信号时,根据所述环境声音(在图5中未示出),通过使用由第一测量电极14和参考测量电极30的信号之差以及第一音频信号6给出的eeg信号,来执行图4中描述的aad方法。数据处理设施78还可以被配置成根据aad方法的结果,增强助听器用户正将其注意力所指向的、第一音频信号6中的有用信号的信号贡献。这种增强可以例如通过波束形成、使用另一个输入换能器(未示出)的另一个音频信号、或者通过bss技术来完成。
图6示意性地示出图5中给出的助听器70的替代实施例。这里,噪声测量电极18也位于耳钩72的外壳上。对应的噪声信号优选作为噪声测量电极18的信号与由位于模具76顶端的参考测量电极30测量的电参考信号28的差信号。
尽管已经借助于优选实施例详细说明和描述了本发明,但是本发明不受该实施例的限制。在不脱离本发明保护范围的情况下,本领域技术人员可以推导出其他变型。
参考标号
1aep
2第一输入换能器
4第一声音信号
6第一音频信号
8头部
10第一包络
12第一音频信号数据
14第一测量电极
16第一测量点
18噪声测量电极
20噪声测量点
22第一电信号
23另一电信号
24噪声信号
26第一eeg训练信号
28电参考信号
30参考测量电极
34第一测量数据集
36噪声数据集
40环境声音
42第二音频信号
44第一有用信号
46第二有用信号
48音频信号处理
50第一信号贡献
52第二信号贡献
54第一有用信号包络
56第二有用信号包络
58第一eeg应用信号
59相关性分析
60注意力
65第二测量电极
66第二测量点
67辅助eeg训练信号
68辅助eeg应用信号
69相关性分析
70助听器
72耳钩
74听筒
76模具
78数据处理设施
θ系统响应
θaux辅助系统响应
c4、c3、cz测量点
in测量点
na,nb,n1负峰值
pa,p1,p2正峰值
r(第一测量数据集的)数据矢量
ra(第一eeg应用信号的)数据矢量
raux(辅助eeg应用信号的)数据矢量
r参考测量点
r1-r4第一至第四重构eeg信号
s第一音频信号数据(的矢量)
s1、s2第一/第二有用信号数据(的矢量)
t7、t8测量点
w噪声数据(的矢量)。
- 还没有人留言评论。精彩留言会获得点赞!