一种基于深度学习的双模正交频分复用索引调制检测方法及装置与流程
1.本发明涉及一种基于深度学习的双模正交频分复用索引调制检测方法及装置,属于通信系统技术领域。
背景技术:
2.正交频分复用(ofdm)技术能够有效地抵抗无线信道频率选择性引起的码间干扰,成为无线通信中最流行的多载波传输技术。与传统的ofdm系统相比,正交频分复用索引调制(ofdm
‑
im)不仅可以通过信号星座来传输信息,而且可以通过ofdm子载波的索引来传输信息,因此具有更好的误码率性能。双模正交频分复用索引调制(dm
‑
ofdm
‑
im)在ofdm
‑
im的基础上,将所有子载波分成若干个子块,每个子块中的所有子载波被分成部分,分别由一对不同调制模式的星座图进行调制。因此,信息比特不仅可以由激活的子载波通过星座符号进行传输,还可以通过不同的调制方式由非激活子载波进行传输,对比传统的基于索引调制的ofdm系统,该技术在保持较好误码率的前提下,提高了可达到的吞吐量。
3.深度学习已成为当今的一项热点技术,应用于计算机、通信、机械制造、自动化等各个领域。在通信领域中,深度学习依然有很好的表现,在5g中经常可以看到深度学习和机器学习的许多实际应用。例如深度学习应用到5g中毫米波(mmwave)设备到设备通信的中继选择方案、深度学习与非正交多址和大规模多输入多输出毫米波结合的新通信框架等。ofdm作为5g中的关键技术,将深度学习与其结合,有着广阔的应用前景。
4.传统的ofdm检测方法有:最大似然检测(ml)、低复杂度对数似然比检测(llr)、迫零检测(zf)等,传统算法存在着复杂度与性能表现之间的问题,想要得到更好的性能往往代表着更高的计算复杂度,而低复杂度算法则会导致检测性能的下降。
技术实现要素:
5.对于传统方法不能较好地协调检测性能与计算复杂度的问题,本发明提出了一种基于深度学习的双模正交频分复用索引调制检测方法;
6.本发明还提出了一种基于深度学习的双模正交频分复用索引调制检测装置。
7.本发明在瑞利信道条件下对双模正交频分复用索引调制信号进行检测,可以获得与ml检测器相似的误码率,并大大缩短了检测时间。具体来说,对实验获得的dm
‑
ofdm
‑
im信号和信道进行预处理,得到的多个预处理数据作为dnn的输入,进行dnn的离线训练。特别地,为了在复杂度和误码率之间达到很好的折衷,dnn被设置为两个全连接(fc)层,在隐藏层中设置128个节点。通过离线训练得到的dnn模型可以在短时间内对新的dm
‑
ofdm
‑
im数据在瑞利信道条件下进行在线调制,可以获得较好的误码率。仿真结果表明,与ml检测器相比,本发明提出的dnn检测器可以大大缩短运行时间,得到近似最优的误码率。
8.本发明通过深度学习与神经网络,可以将训练好的数据模型应用到新生成的随机数据的检测中,可以大大提高检测效率并能够保持不错的性能。
9.术语解释:
10.1、dm
‑
ofdm
‑
im系统,如图3所示,双模正交频分复用索引调制(dm
‑
ofdm
‑
im)在ofdm
‑
im的基础上,将所有子载波分成若干个子块,每个子块中的所有子载波被分成部分,分别由一对不同调制模式的星座图进行调制。因此,信息比特不仅可以由激活的子载波通过星座符号进行传输,还可以通过不同的调制方式由非激活子载波进行传输,对比传统的基于索引调制的ofdm系统,该技术在保持较好误码率的前提下,提高了可达到的吞吐量。
11.2、随机梯度下降(sgd)算法,在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(gradient descent)是最常采用的方法之一,在求解损失函数的最小值时,可以通过梯度下降法迭代求解,得到最小化的损失函数和模型参数值。随机梯度下降(stochastic gradient descent,sgd)是梯度下降算法的一个扩展。随机梯度下降算法每次只随机选择一个样本来更新模型参数,因此每次的学习是非常快速的,并且可以进行在线更新。
12.3、ml检测器:在接收端,采用最大似然检测,通过处理每个ofdm子块上接受到的频域信号来恢复信息比特。对于其中第β个子块(随机选取一个子块,命名为β子块)来说,通过最小化ml矩阵得到最优的索引模式和传输符号。在得到索引模式和符号向量的最大似然估计后,通过索引模式查表和两种星座图集合来解调得到g比特信息。ml检测器的复杂度与星座图m
a
、m
b
,用于生成ofdm信号的比特数g,子块长度l和活跃子载波个数k均有关。当,g,l,k或者调制阶数较大时,最大似然检测器的复杂度会呈指数增加,严重影响了实用程度。
13.本发明的技术方案为:
14.一种基于深度学习的双模正交频分复用索引调制检测方法,包括步骤如下:
15.(1)数据预处理:对获得的dm
‑
ofdm
‑
im信号(双模正交频分复用索引调制信号)和信道进行预处理;dm
‑
ofdm
‑
im信号分为若干组,每组四个子载波,由于每组子载波的生成方式相同,选取一组子载波进行处理。
16.(2)训练dm
‑
ofdm
‑
im模型:将步骤(1)得到的预处理数据作为dm
‑
ofdm
‑
im模型的输入,进行dm
‑
ofdm
‑
im模型的离线训练;
17.(3)在线调制:通过训练好的dm
‑
ofdm
‑
im模型对新的dm
‑
ofdm
‑
im信号在瑞利信道条件下进行在线调制,输出信噪比和误码率的关系曲线。
18.根据本发明优选的,步骤(1)中,dm
‑
ofdm
‑
im信号的生成过程如下:
19.在一个具有m个输入比特的dm
‑
ofdm
‑
im系统中,m个输入比特被分成p组,每组由g个比特组成,即p=m/g;
20.每组g个比特被输入一个索引选择器(序号选择器)和两个不同的星座映射器,两个不同的星座映射器包括星座映射器a和星座映射器b,生成长度为l=n/p的ofdm子块,n是快速傅里叶变换(fft)的大小;与现有的ofdm
‑
im只对部分子载波进行调制相比,dm
‑
ofdm
‑
im中的所有子载波都被调制,提高了频谱利用率;索引选择器使用输入的g个比特中的前g1个比特将每个ofdm子块的索引划分为两个索引子集,分别表示为i
a
和i
b
;剩下g个比特中的g2个比特被传送给星座映射器a和星座映射器b,用于生成与m
a
和m
b
大小相关联的m
a
和m
b
星座集;m
a
和m
b
分别是两种不同的星座图,满足两种不同星座图的表达式m
a
={
‑1‑
j,1
‑
j,1+j,
‑
1+j},1+j},由此,通过索引选择器,i
a
和i
b
对应的子载波分别由星座映射器a和星座映射器b调制;
21.设一个ofdm子块中的k个子载波用m
a
方式调制,(l
‑
k)个子载波用m
b
方式调制,则g1和g2分别表示为式(i)和式(ii):
[0022][0023]
g2=klog2(m
a
)+(l
‑
k)log2(m
b
)
ꢀꢀꢀ
(ii)
[0024]
式(i)中,表示向下取整;
[0025]
一旦知道了i
a
,i
b
也就确定了。为了在接收端可靠地检测索引部分,由映射器a和b生成的星座图应该易于识别区分,即满足条件由g比特生成的传输信号向量表示成式(iii):
[0026]
x=[x1,x2,...,x
n
]
ꢀꢀꢀ
(iii)
[0027]
式(iii)中,x1,x2,...,x
n
是指由g比特生成的双模ofdm索引调制的时域信号;
[0028]
由比特到符号的映射由函数f
ofdm
‑
im
(bit)表示,bit是由一组g比特的二进制数组成,如式(iv)所示:
[0029]
bit=[0,1,0,1,......]
ꢀꢀꢀ
(iv)
[0030]
在接收端,时域接收信号y表示为式(v):
[0031]
y=h
⊙
x+n
ꢀꢀꢀ
(v)
[0032]
式(v)中,
⊙
表示元素相乘,h=[h1,h2,...,h
n
]代表瑞利信道,n为加性高斯白噪声(awgn);平均接收信噪比表示为式(vi):
[0033][0034]
式(vi)中,e
s
为传输符号的平均能量,σ2为噪声的平方。
[0035]
根据本发明优选的,步骤(1)中,对获得的dm
‑
ofdm
‑
im信号和信道进行预处理,包括:
[0036]
首先,将时域接收信号y乘以信道h的倒数,得到如式(vii)所示:
[0037][0038]
利用这种变换可以减少dnn中预测值与实际值之间的误差,实现对新数据的更高匹配度,进一步提高测试时的误码率性能。
[0039]
然后,求得的能量如式(viii)所示:
[0040][0041]
式(viii)中,分别是指经过预处理后的n个接收信号;预处理过程如式(vii)所示。
[0042]
在贪婪检测(gd)检测器中,接收信号的能量还用于解码子载波索引调制。因此,运用基于gd检测器的方法对输入数据进行预处理得到接收信号的能量,可以提高索引检测的效率,提高训练模型的性能。
[0043]
最后,将的实部的实部的虚部以及共同组成dm
‑
ofdm
‑
im模型的输入dnn
input
,如式(ix)所示:
[0044][0045]
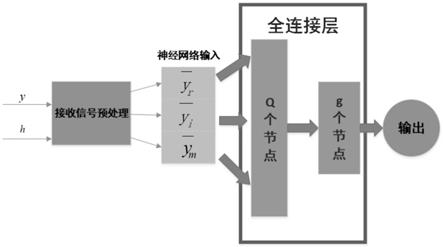
根据本发明优选的,所述dm
‑
ofdm
‑
im模型包括两个全连接层,包括一个含有q个节点的隐藏层和一个含有g个节点的输出层;隐藏层节点设置为128,目的是在复杂度和误码率性能之间找到一个好的平衡。当调制方式或训练数据量发生变化时,可以通过调整q的大
小来获得合适的误码率性能,具体来说,q的取值大小应为2
n
,在数据量较大的情况下,q的取值应越大,从而可以通过训练得到性能更好的dnn模型。隐藏层使用的激活函数为relu函数f
relu
(x),如式(x)所示:
[0046]
f
relu
(x)=max(0,x)
ꢀꢀꢀ
(x)
[0047]
输出层应用的激活函数是sigmoid函数f
sigmoid
(x),如式(xi)所示:
[0048][0049]
以输出所传输数据比特的估计值。
[0050]
在本发明中,dm
‑
ofdm
‑
im模型只需要两个全连接层就可以高精度地检测dm
‑
ofdm
‑
im的索引位。
[0051]
根据本发明优选的,所述dm
‑
ofdm
‑
im模型的输出如式(xii)所示:
[0052][0053]
式(xii)中,w1、w2分别是指所述隐藏层、所述输出层的权重,b1、b2分别是指所述隐藏层、所述输出层的偏差。
[0054]
根据本发明优选的,q=128。
[0055]
dm
‑
ofdm
‑
im模型的输入和输出长度由dm
‑
odfm
‑
im的参数l、m和k决定,而隐层的长度q需要正确选择以匹配不同数据量的样本(将q设为128个节点)。直观地说,随着每个dm
‑
odfm
‑
im组发送比特数的增加,我们需要一个足够大的q来保证神经网络的性能。与需要依赖更多dm
‑
odfm
‑
im参数的ml检测器相比,基于深度学习的dm
‑
odfm
‑
im检测器大大降低了计算复杂度。
[0056]
根据本发明优选的,步骤(2)中,训练dm
‑
ofdm
‑
im模型,包括步骤如下:
[0057]
将得到的dnn
input
输入dm
‑
ofdm
‑
im模型进行离线训练,以获得最小的训练误差,换言之,使用于生成信号的比特的真实值和预测值差值最小。具体来说,dm
‑
ofdm
‑
im模型的误差函数表示如式(xiii)所示:
[0058][0059]
(xiii)中,loss是指训练误差;g是指g个二进制比特;
[0060]
使用随机梯度下降(sgd)算法来更新dm
‑
ofdm
‑
im模型的参数,如式(xiv)所示:
[0061][0062]
式(xiv)中,η表示dm
‑
ofdm
‑
im模型的学习速率,θ为随机梯度下降中的初始参数,θ
+
为更新后的参数,通过梯度下降一次次的更新参数θ。
[0063]
一种基于深度学习的双模正交频分复用索引调制检测装置,即dm
‑
ofdm
‑
im检测器,包括依次连接的dm
‑
ofdm
‑
im信号产生器及dm
‑
ofdm
‑
im模型;
[0064]
所述dm
‑
ofdm
‑
im信号产生器用于实现上述步骤(1)中生成dm
‑
ofdm
‑
im信号;
[0065]
所述dm
‑
ofdm
‑
im模型用于实现上述步骤(2)至步骤(3)。
[0066]
本发明的有益效果为:
[0067]
1、本发明基于深度学习的双模正交频分复用索引调制检测方法,可以在很短的时间内获得比传统的或新的单模ofdm检测器更好的误码性能,并且可以用于不同信噪比的数据集,无需复杂的操作过程。
[0068]
2、为了提高该方法的性能,本发明对接收到的信号进行预处理,并使用只含有两
个全连接层的dnn网络,以保持较低的复杂度。利用预处理后的数据集通过离线训练得到系统模型,并将其应用于瑞利信道下dm
‑
ofdm
‑
im信号的在线检测。实验结果表明,本发明提出的基于深度神经网络的检测与解调方案可以在较低的运行时间内达到接近最大似然(ml)检测器的误码率(ber)。
[0069]
3、本发明的dm
‑
ofdm
‑
im检测器,基于深度学习的dm
‑
ofdm
‑
im检测器在5g无线网络中具有非常广阔的应用前景。
附图说明:
[0070]
图1是本发明dm
‑
ofdm
‑
im模型的结构示意图。
[0071]
图2是本发明dm
‑
ofdm
‑
im模型与现有的ml检测器的得到的信噪比和误码率的关系曲线对比示意图。
[0072]
图3是本发明dm
‑
ofdm
‑
im系统的结构示意图。
具体实施方式
[0073]
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
[0074]
实施例1
[0075]
一种基于深度学习的双模正交频分复用索引调制检测方法,包括步骤如下:
[0076]
(1)数据预处理:对获得的dm
‑
ofdm
‑
im信号(双模正交频分复用索引调制信号)和信道进行预处理;dm
‑
ofdm
‑
im信号分为若干组,每组四个子载波,由于每组子载波的生成方式相同,选取一组子载波进行处理;
[0077]
(2)训练dm
‑
ofdm
‑
im模型:将步骤(1)得到的预处理数据作为dm
‑
ofdm
‑
im模型的输入,进行dm
‑
ofdm
‑
im模型的离线训练;
[0078]
(3)在线调制:通过训练好的dm
‑
ofdm
‑
im模型对新的dm
‑
ofdm
‑
im信号在瑞利信道条件下进行在线调制,输出信噪比和误码率的关系曲线。
[0079]
训练好的dm
‑
ofdm
‑
im模型可以实时检测任意信噪比下接收信号的误码率。与现有的检测器相比,在对新数据进行检测时,只需要使用训练好的模型对数据进行检测,不需要像其他现有检测器一样重复复杂和耗时的训练过程。因此,即使在数据量很大的情况下,训练好的dm
‑
ofdm
‑
im模型仍然可以在很短的时间内达到与现有检测器相似的误码率。
[0080]
实施例2
[0081]
根据实施例1所述的一种基于深度学习的双模正交频分复用索引调制检测方法,其区别在于:
[0082]
步骤(1)中,dm
‑
ofdm
‑
im信号的生成过程如下:
[0083]
在一个具有m个输入比特的dm
‑
ofdm
‑
im系统中,图3是dm
‑
ofdm
‑
im系统的结构示意图,m个输入比特被分成p组,每组由g个比特组成,即p=m/g;
[0084]
每组g个比特被输入一个索引选择器(序号选择器)和两个不同的星座映射器,两个不同的星座映射器包括星座映射器a和星座映射器b,生成长度为l=n/p的ofdm子块,n是快速傅里叶变换(fft)的大小;与现有的ofdm
‑
im只对部分子载波进行调制相比,dm
‑
ofdm
‑
im中的所有子载波都被调制,提高了频谱利用率;索引选择器使用输入的g个比特中的前g1个比特将每个ofdm子块的索引划分为两个索引子集,分别表示为i
a
和i
b
;剩下g个比特中的
g2个比特被传送给星座映射器a和星座映射器b,用于生成与m
a
和m
b
大小相关联的m
a
和m
b
星座集;m
a
和m
b
分别是两种不同的星座图,满足m
a
={
‑1‑
j,1
‑
j,1+j,
‑
1+j},1+j},由此,通过索引选择器,i
a
和i
b
对应的子载波分别由星座映射器a和星座映射器b调制;
[0085]
假设一个ofdm子块中的k个子载波用m
a
方式调制,(l
‑
k)个子载波用m
b
方式调制,则g1和g2分别表示为式(i)和式(ii):
[0086][0087]
g2=klog2(m
a
)+(l
‑
k)log2(m
b
)
ꢀꢀꢀ
(ii)
[0088]
式(i)中,表示向下取整;
[0089]
一旦知道了i
a
,i
b
也就确定了。为了在接收端可靠地检测索引部分,由映射器a和b生成的星座图应该易于识别区分,即满足条件由g比特生成的传输信号向量表示成式(iii):
[0090]
x=[x1,x2,...,x
n
]
ꢀꢀꢀ
(iii)
[0091]
式(iii)中,x1,x2,...,x
n
是指由g比特生成的双模ofdm索引调制时域信号;
[0092]
由比特到符号的映射由函数f
ofdm
‑
im
(bit)表示,bit是由一组g比特的二进制数组成,如式(iv)所示:
[0093]
bit=[0,1,0,1,......]
ꢀꢀꢀ
(iv)
[0094]
在接收端,时域接收信号y表示为式(v):
[0095]
y=h
⊙
x+n
ꢀꢀꢀ
(v)
[0096]
式(v)中,
⊙
表示元素相乘,h=[h1,h2,...,h
n
]代表瑞利信道,n为加性高斯白噪声(awgn);平均接收信噪比表示为式(vi):
[0097][0098]
式(vi)中,e
s
为传输符号的平均能量,σ2为噪声的平方。
[0099]
步骤(1)中,对获得的dm
‑
ofdm
‑
im信号和信道进行预处理,包括:
[0100]
首先,将时域接收信号y乘以信道h的倒数,得到如式(vii)所示:
[0101][0102]
利用这种变换可以减少dnn中预测值与实际值之间的误差,实现对新数据的更高匹配度,进一步提高测试时的误码率性能。
[0103]
然后,求得的能量如式(viii)所示:
[0104][0105]
式(viii)中,分别是指经过预处理后的n个接收信号;预处理过程如式(vii)所示。
[0106]
在贪婪检测(gd)检测器中,接收信号的能量还用于解码子载波索引调制。因此,运用基于gd检测器的方法对输入数据进行预处理得到接收信号的能量,可以提高索引检测的效率,提高训练模型的性能。
[0107]
最后,将的实部的实部的虚部以及共同组成dm
‑
ofdm
‑
im模型的输入dnn
input
,如式(ix)所示:
[0108][0109]
实施例3
[0110]
根据实施例2所述的一种基于深度学习的双模正交频分复用索引调制检测方法,其区别在于:
[0111]
如图1所示,dm
‑
ofdm
‑
im模型包括两个全连接层,包括一个含有q个节点的隐藏层和一个含有g个节点的输出层;隐藏层节点设置为128,目的是在复杂度和误码率性能之间找到一个好的平衡。当调制方式或训练数据量发生变化时,可以通过调整q的大小来获得合适的误码率性能,具体来说,q的取值大小应为2
n
,在数据量较大的情况下,q的取值应越大,从而可以通过训练得到性能更好的dnn模型。隐藏层使用的激活函数为relu函数f
relu
(x),如式(x)所示:
[0112]
f
relu
(x)=max(0,x)
ꢀꢀꢀ
(x)
[0113]
输出层应用的激活函数是sigmoid函数f
sigmoid
(x),如式(xi)所示:
[0114][0115]
以输出所传输数据比特的估计值。
[0116]
在本发明中,dm
‑
ofdm
‑
im模型只需要两个全连接层就可以高精度地检测dm
‑
ofdm
‑
im的索引位。dm
‑
ofdm
‑
im模型的输出如式(xii)所示:
[0117][0118]
式(xii)中,w1、w2分别是指所述隐藏层、所述输出层的权重,b1、b2分别是指所述隐藏层、所述输出层的偏差。q=128。
[0119]
dm
‑
ofdm
‑
im模型的输入和输出长度由dm
‑
odfm
‑
im的参数l、m和k决定,而隐层的长度q需要正确选择以匹配不同数据量的样本(将q设为128个节点)。直观地说,随着每个dm
‑
odfm
‑
im组发送比特数的增加,我们需要一个足够大的q来保证神经网络的性能。与需要依赖更多dm
‑
odfm
‑
im参数的ml检测器相比,基于深度学习的dm
‑
odfm
‑
im检测器大大降低了计算复杂度。
[0120]
实施例4
[0121]
根据实施例1所述的一种基于深度学习的双模正交频分复用索引调制检测方法,其区别在于:
[0122]
步骤(2)中,训练dm
‑
ofdm
‑
im模型,包括步骤如下:
[0123]
将得到的dnn
input
输入dm
‑
ofdm
‑
im模型进行离线训练,以获得最小的训练误差,换言之,使用于生成信号的比特的真实值和预测值差值最小。具体来说,dm
‑
ofdm
‑
im模型的误差函数表示如式(xiii)所示:
[0124][0125]
(xiii)中,loss是指训练误差;g是指g个二进制比特;
[0126]
使用随机梯度下降(sgd)算法来更新dm
‑
ofdm
‑
im模型的参数,如式(xiv)所示:
[0127][0128]
式(xiv)中,η表示dm
‑
ofdm
‑
im模型的学习速率,θ为随机梯度下降中的初始参数,θ
+
为更新后的参数,通过梯度下降一次次的更新参数θ。
[0129]
将dm
‑
ofdm
‑
im模型与现有的ml检测器进行了比较,并给出了仿真结果。图2是dm
‑
ofdm
‑
im模型与现有的ml检测器的得到的信噪比和误码率的关系曲线对比示意图。dm
‑
ofdm
‑
im模型与现有的ml检测器的训练输入数据集包含5
×
105组数据,每组包含10个比特数据用于ofdm信号的调制,具体地说,共使用5
×
106比特大小的样本对dm
‑
ofdm
‑
im模型进行训练。另外,将训练的信噪比设为150db,实验表明,在该信噪比下训练的dm
‑
ofdm
‑
im模型可以很好地应用于其它任意信噪比数据的测试。dm
‑
ofdm
‑
im模型将隐藏层节点数设为128个,在复杂度和误码率性能之间取得了良好的折衷。训练误差的激活函数为relu,当全连接层节点数较多时,该函数具有更好的性能。如图2所示,dm
‑
ofdm
‑
im模型的误码率性能优于现有的ml检测器,具有很好的应用前景。
[0130]
实施例5
[0131]
一种基于深度学习的双模正交频分复用索引调制检测装置,即dm
‑
ofdm
‑
im检测器,包括依次连接的dm
‑
ofdm
‑
im信号产生器及dm
‑
ofdm
‑
im模型;
[0132]
dm
‑
ofdm
‑
im信号产生器用于实现实施例1
‑
4中步骤(1)中生成dm
‑
ofdm
‑
im信号;
[0133]
dm
‑
ofdm
‑
im模型用于实现实施例1
‑
4中步骤(2)至步骤(3)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1