一种基于深度学习的TebNet神经网络模型的WLAN室内定位方法
一种基于深度学习的tebnet神经网络模型的wlan室内定位方法
技术领域
1.本发明涉及wlan室内定位领域,具体涉及一种wlan室内定位方法。
背景技术:
2.近年来,随着通信技术和智能设备的技术突破,智能移动终端的衍生服务得到了高速的发展。同时人们对于稳定有效的定位服务需求日益提高。统计数据表明,人们在绝大多数时间处于室内环境下,然而传统的gps定位系统在建筑物遮蔽严重的室内场景下无法实现可靠的定位功能,所以室内定位方面的研究在近年来成为一个越来越热门的研究方向。
3.由于人们生活环境中wi
‑
fi基站的数量日益增多,设备搭建简易且成本低廉,所以wifi室内定位拥有数据采集方便、定位模型简单且不存在累进误差的优势,但由于多径效应以及wifi信号穿过物体强度减弱等因素导致wifi定位系统的精度普遍偏低。目前主流wifi室内定位研究多采用位置指纹匹配的方法,离线阶段在参考点上采集ap接入点的信号强度rssi值,与该参考点的位置坐标组成一条指纹信息,存入指纹数据库,在线阶段根据用户实时的位置指纹信息与离线数据库中的指纹信息进行匹配从而获取实时的位置信息。但由于离线指纹数据的采集工作量十分庞大,理论上用户需要定位到的位置都需要预先采集位置信息并存入指纹数据库,这使得该方法建立的定位系统具有极大的空间局限性且难以得到扩展和普及。
4.目前,深度神经网络在图像、文本和音频取得了巨大成功,然而对于表格数据集,依然是提升树模型的主场,在众多数据挖掘竞赛中,xgboost、lightgbm凭借其很好的拟合表格数据中的超平面边界、可解释性和训练速度快成为众多算法中的首选。但对于传统的dnn,一味地堆叠网络层很容易导致模型过参数化(overparametrized),导致dnn在表格数据集上表现并不尽如人意。2019年8月,ar1k提出的tabnet网络,它在保留dnn的end
‑
to
‑
end和representation learning特点的基础上,还拥有了树模型的可解释性和稀疏特征选择的优点,逐渐成为表格数据任务的首选。
5.根据现有wifi室内定位系统存在的问题以及新的决策树模型的性能突破,本发明提出了一种基于深度学习的tebnet神经网络模型的wlan室内定位方法。
技术实现要素:
6.一种基于深度学习的tebnet神经网络模型的wlan室内定位方法,其特征在于,包括以下步骤:
7.(1)根据待定位区域参考图建立室内坐标系,以固定间隔设置参考点,记录每个参考点坐标并采集rssi数据、基站mac地址以及csi幅值和相位信息。
8.(2)利用matplotlib工具生成统计数据分析热力图如图2所示,得出统计数据存在黑色区域的缺失值以及白色区域的异常值,利用k近邻算法和中值滤波进行数据预处理,预
处理后统计数据即为位置指纹数据的训练集。
9.(3)对统计数据进行预处理,利用基于距离的填补方法k
‑
最近邻法,根据欧氏距离和马氏距离函数估计缺失值,利用grubbs检验方法检验异常值,进行标注并重复,直到没有异常值为止,预处理后的指纹数据集设定为训练集。
10.(4)特征工程与对抗验证数据训练,步骤如下:
11.1)对预处理的数据引入正则项增强模型稀疏能力,正则项的计算公式:
[0012][0013]
其中n
steps
为总的时间步长,b和d是mask矩阵的维度,对应(3)中统计数据的行数和不同mac地址的基站数(即列数),mask为由0和1组成的掩码矩阵,m
b,j
[i]为对应mask矩阵中指纹数据第b(b=1,2,...,b)行和第j(j=1,2,...,d)个基站位置的第i(i=1,2,...,n
steps
)个样本的注意力权重分配,注意力权重由训练集输入稀疏概率激活函数sparsemax求得,该函数为稀疏化的softmax函数,ε为高斯白噪声,正则项总体计算了一个平均熵值,反映m
b,j
[i]的稀疏程度,训练得到后设为tabnet网络attentive transformer层的instance
‑
wise参数。
[0014]
2)采用borderline smote算法改善数据不平衡性。
[0015]
应用自监督学习方法训练表格数据的encoder模型,采用正则化后的均方误差作为误差值,形式如下:
[0016][0017]
其中s∈{0,1}
b
×
d
为mask矩阵,b、d为矩阵维度,b(b=1,2,...,b)和j(j=1,2,...,d)为mask矩阵对应横纵坐标值,f
b,j
为第b行第j列的特征数据,为(1
‑
s)
·
f
b,j
输入encoder模型后的特征输出。将没有经过fc全连接层的加和向量f
b,j
作为decoder模型的输入,经过全部时间步长n
steps
的加和得到重构特征f
new
,添加重构特征到指纹数据训练集。
[0018]
3)对2)所得数据进行平衡性分析,检测wifi信号强度,取信号强度大于50dbm的基站为实时数据来源,在参考点采集指纹数据作为测试集,将其与1)中的训练集添加标签并合并,训练lightgbm模型对数据进行分类预测,得到结果auc在0.4到0.6内为平衡;
[0019]
(5)为保证tabnet的可解释性,需要求经(4)平衡后特征属性f
b,j
的全局重要性,归一化后的特征全局重要性m
agg
表示为:
[0020][0021]
其中表示第i(i=1,2,...,n
steps
)个时间步长对最后结果的贡献,其中n
d
为该时间步长的总和,由时钟计时,relu(...)为线性整流函数,d
b,c
[i]为i处贡献值,由(4)中所得特征数据f
b,j
输入tabnet模型的feature attribute模块得到,m
b,j
[i]是第i个时间步长的注意力权重。特征f
b,j
在时间步长内的贡献与贡献总和
的比值即为该特征属性的全局重要性m
agg
‑
b,j
,训练得到后设置为tabnet网络的feature attribute的m
agg
参数。
[0022]
(6)将(4)中所得正则项l
sparse
、(5)中所得特征全局重要性m
agg
‑
b.j
输入tabnet模型,其他参数选择:
[0023][0024][0025]
其中n_d,n_a,n_steps是决定模型的容量重要参数,普遍认为时间步长n_steps设置为3
‑
10为合理参数,n_d,n_a分别为决策预测层宽度和注意力嵌入掩膜矩阵宽度,通常设为n_d=n_a是合理选择。optimizer优化器设为adam算法,learning_rate学习率以0.01~0.001为宜,此次选定0.01。gamma决定稀疏特征的选择强度,为1时掩膜矩阵在层之间的相关性最小,取值范围为1.0
‑
2.0。
[0026]
(7)在线阶段采集测试点上ap的rssi值以及基站mac地址等数据,输入模型得出具体的测试点坐标。
[0027]
本发明公开的基于深度学习的tebnet神经网络模型的wlan室内定位方法,拥有较强的环境自适应性和定位精度,具有随着数据积累强化学习功能,其有益效果如下:
[0028]
(1)本发明采用深度神经网络模型,具有强化学习能力,随数据量提升可提升定位精度和环境适应性;
[0029]
(2)本发明采用模型预测定位结果,不必在定位区域每个点都进行位置指纹采集,节约时间和人力成本;
[0030]
(3)预测模型过滤噪声和异常值,填补缺失值,提升定位精度。
附图说明
[0031]
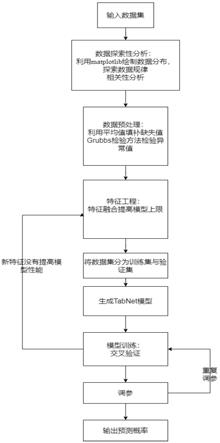
图1是定位算法模型流程图
[0032]
图2是统计数据分析热力图
[0033]
图3是数据集样本平衡性分析图
[0034]
图4是本发明所述预测总流程图
具体实施方式
[0035]
预设室内定位场景为走廊及电梯间,面积为80平方米。
[0036]
本发明定位预测总流程框图参见图4。离线阶段,在参考点采集接入点ap的信号强度rssi数据并进行eda探索数据,利用matplotlib工具生成统计数据分析热力图如图2所示,可以得出统计数据存在黑色区域的缺失值以及白色区域的异常值,所以需要进行数据预处理。接着对预处理好的数据进行特征工程的的工作,选择具体特征并进行特征合成,生成统计特征并交付tabnet神经网络模型,利用交叉验证的方法训练数据。具体实施步骤如下:
[0037]
(1)首先建立室内坐标系,以一定间隔设置参考点采集rssi数据、基站mac地址以及csi幅值和相位信息,并与参考点坐标组成有序向量,该向量为参考点的位置指纹数据。
[0038]
(2)利用matplotlib工具生成统计数据分析热力图如图2所示,得出统计数据存在黑色区域的缺失值以及白色区域的异常值,利用k近邻算法和中值滤波进行数据预处理,预处理后统计数据即为位置指纹数据的训练集。
[0039]
(3)对预处理过的数据进行特征工程工作。
[0040]
1)为增强模型对特征稀疏选择的能力,引入一个正则项:
[0041][0042]
其中n
steps
为总的时间步长,b和d是mask矩阵的维度,对应(3)中统计数据的行数和不同mac地址的基站数(即列数),mask为由0和1组成的掩码矩阵,m
b,j
[i]为对应mask矩阵中指纹数据第b(b=1,2,...,b)行和第j(j=1,2,...,d)个基站位置的第i(i=1,2,...,n
steps
)个样本的注意力权重分配,注意力权重由稀疏概率激活函数sparsemax求得,该函数为稀疏化的softmax函数,ε为高斯白噪声,正则项总体计算了一个平均熵值,反映m[i]的稀疏程度,训练得到后设为tabnet网络attentive transformer层的instance
‑
wise参数。
[0043]
2)模型训练采用borderline smote算法改善数据不平衡性,样本平衡分析图如图3所示。应用自监督学习方法训练表格数据的encoder模型,采用正则化后的均方误差作为误差值,形式如下:
[0044][0045]
其中s∈{0,1}
b
×
d
为mask矩阵,b、d为矩阵维度,b(b=1,2,...,b)和j(j=1,2,...,d)为mask矩阵对应横纵坐标值,f
b,j
为第b行第j列的特征数据,为(1
‑
s)
·
f
b,j
输入encoder模型后的特征输出。将没有经过fc全连接层的加和向量f
b,j
作为decoder模型的输入,经过全部时间步长n
steps
的加和得到重构特征f
new
,添加重构特征到指纹数据训练集。
[0046]
3)对2)所得数据进行平衡性分析,检测wifi信号强度,取信号强度大于50dbm的基站为实时数据来源,在参考点采集指纹数据作为测试集,将其与1)中的训练集添加标签并合并,训练lightgbm模型对数据进行分类预测,得到结果auc在0.4到0.6内为平衡;
[0047]
(4)为保证tabnet的可解释性,需要求经(3)平衡的特征属性f
b,j
的全局重要性,归一化后的特征全局重要性m
agg
表示为:
[0048]
[0049]
其中表示第i(i=1,2,...,n
steps
)个时间步长对最后结果的贡献,其中n
d
为该时间步长的总和,由时钟计时,relu(...)为线性整流函数,d
b,c
[i]为i处贡献值,由(4)中所得特征数据f
b,j
输入tabnet模型的feature attribute模块得到,m
b,j
[i]是第i个时间步长的注意力权重。特征f
b,j
在时间步长内的贡献与贡献总和的比值即为该特征属性的全局重要性m
agg
‑
b,j
,训练得到后设置为tabnet网络的feature attribute的m
agg
参数。
[0050]
(5)将(4)中所得正则项l
sparse
、(5)中所得特征全局重要性m
agg
‑
b.j
输入tabnet模型,其他参数选择:
[0051][0052][0053]
其中n_d,n_a,n_steps是决定模型的容量重要参数,普遍认为时间步长n_steps设置为3
‑
10为合理参数,n_d,n_a分别为决策预测层宽度和注意力嵌入掩膜矩阵宽度,通常设为n_d=n_a是合理选择。optimizer优化器设为adam算法,learning_rate学习率以0.01~0.001为宜,此次选定0.01。gamma决定稀疏特征的选择强度,为1时掩膜矩阵在层之间的相关性最小,取值范围为1.0
‑
2.0。
[0054]
(6)在线阶段采集测试点上ap的rssi值以及基站mac地址等数据,输入模型得出具体的测试点坐标。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1