一种日志数据增强方法、分类检测方法及系统与流程
本公开涉及网络安全及人工智能技术领域,尤其涉及一种日志数据增强方法、分类检测方法及系统。
背景技术:
在网络空间安全领域日志数据中存在正常样本和威胁样本不平衡的问题,在实际的日志数据采集中,只存在少量的威胁数据,因此需要对少量的威胁数据进行数据增强。
现阶段,对于数据增强,一方面通过采样技术,即人工数据合成来增强数据集,仅依靠人工搜集更多稀缺类别的数据,无法实现数据集的均衡,对于数据集本身就很稀少,无法实现有效规模的样本采用。包括欠采样法、过采样法和数据合成等方法,均会导致过拟合的问题,或是放大正比例噪音对模型的影响,导致在实际测试时准确率比较低。
对于通过日志数据分类检测未知网络安全的方法,目前多采用深度学习模型,但在训练深度学习模型时,经常会面临少量甚至没有标签数据的情况,日志样本标签分类不平衡的问题,因缺乏代表性样本导致相似度和过拟合问题,使得训练的模型性能大幅度下降,导致预测准确率很低,可能将恶意威胁误判为正常从而导致重大损失,错分成本较高。
技术实现要素:
为了解决上述日志数据样本不平衡、缺乏代表性样本所导致相似度和过拟合以及对于恶意威胁存在误判的技术问题,本发明公开了一种日志数据增强方法、分类检测方法及系统。
本公开实施例提供了一种日志数据增强方法,包括:
对采集的所述日志数据进行预处理;
对所述预处理后的日志数据进行数据归并处理;
构建生成对抗网络模型,利用所述数据归并处理后的日志数据对所述生成对抗网络模型进行训练;
根据训练好的所述生成对抗网络模型生成日志数据样本;
基于所述日志数据样本与所述数据归并处理后的日志数据进行数据结合,形成增强的日志数据集。
可选地,所述日志数据为网络安全信息日志数据,对所述日志数据进行预处理包括:
利用规则库去除所述日志数据中的冗余数据;
将所述去除冗余数据的日志数据存储为统一的文档格式。
可选地,对所述预处理后的日志数据进行数据归并处理包括:
对所述预处理后的日志数据按照时间戳规则进行数据归并处理。
可选地,所述生成对抗网络模型包括生成器和判别器,所述构建生成对抗网络模型,利用所述数据归并处理后的日志数据对所述生成对抗网络模型进行训练,包括:
随机初始化所述生成器和所述判别器的参数;
通过最大似然估计预训练所述生成器;
根据所述预训练生成器生成初始数据,基于所述初始数据通过最小化交叉熵预训练所述判别器;
将随机变量输入所述预训练生成器中生成日志文本序列;其中,所述日志文本序列包括完整的日志文本序列和非完整的日志文本序列;
采用蒙特卡洛树搜索对所述非完整的日志文本序列进行模拟;
将所述模拟的日志文本序列与所述完整的日志文本序列结合,形成新的日志文本序列;
根据所述新的日志文本序列和所述数据归并处理后的日志数据训练所述预训练判别器,更新所述预训练判别器的参数形成新的判别器,并生成奖励值;
利用策略梯度算法结合所述奖励值对所述预训练生成器进行训练,更新所述预训练生成器的参数生成新的生成器。
本公开实施例还提供一种日志数据分类检测方法,包括:
采集日志数据,基于所述日志数据采用上述的日志数据增强方法构建增强的日志数据集;
提取所述增强的日志数据集的语义向量,构建语义向量数据集;
对所述语义向量数据集进行上下文分析,形成特征向量数据集;
构建深度神经网络模型,根据所述特征向量数据集训练所述深度神经网络模型,生成分类检测模型。
可选地,所述提取所述增强的日志数据集的语义向量,构建语义向量数据集包括:
利用自然语言模型提取所述增强的日志数据集的语义向量,构建语义向量数据集;其中,提取所述增强的日志数据集的语义向量包括词向量、基于词向量的段向量和关键词。
本公开实施例还提供一种日志数据增强装置,包括:
日志数据预处理模块,用于对采集到的日志数据进行预处理;
数据归并处理模块,用于对所述预处理后的日志数据按时间戳规则进行数据归并处理;
生成对抗网络模型构建和训练模块,构建生成对抗网络模型,利用所述数据归并处理后的日志数据进行训练并生成模型;
日志数据样本增强模块,根据训练好的所述生成对抗网络模型生成日志数据样本,将所述日志数据样本与所述数据归并处理后的日志数据结合,形成增强的日志数据集。
本公开实施例还提供一种日志数据分类检测系统,包括:上述的日志数据增强装置,以及,
数据采集模块,采集日志数据,并由所述日志数据增强装置构建增强的日志数据集;
语义向量数据集构建模块,提取所述增强的日志数据集的语义向量,构建语义向量数据集;
上下文分析模块,将构建的所述语义向量数据集进行上下文分析,形成特征向量数据集;
日志数据分类检测模块,构建深度神经网络模型,根据所述特征向量数据集训练深度神经网络模型,生成分类检测模型。
本公开实施还提供一种计算机装置,其特征在于,所述计算机装置包括处理器,所述处理器用于执行存储器中存储的计算机程序时实现如上述的日志数据增强方法,或者用于如上述的日志数据分类检测方法。
本公开实施例还提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如上述的日志数据增强方法的步骤,或者用于如上述的日志数据分类检测方法的步骤。
本公开实施例提供了的一种日志数据增强方法、分类检测方法及系统,首先,对采集的日志数据进行预处理,去除冗余数据,并将其存储为统一的文档格式,之后利用时间戳规则进行数据归并处理,构建生成对抗网络模型,利用所述数据归并处理后的日志数据进行训练并生成模型,根据生成对抗网络模型生成增强的日志样本,解决了在网络空间安全领域日志数据中存在的正常和恶意样本不平衡的问题,通过样本合成,扩充了日志数据集,有助于解决缺乏代表性样本导致的相似度和过拟合问题,继而降低了网络安全数据集中每一类别的分类错误的成本。其次,提供的日志数据分类检测方法,扩充了不同日志种类的样本数量,确保深度学习训练的样本充足,形成了用于威胁检测的专属分类检测器,能够检测到设备关联的ip地址中建立的一些相似的网络威胁连接,从而检测未知网络威胁,并逐步形成新的检测机制。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。
为了更清楚地说明本公开实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
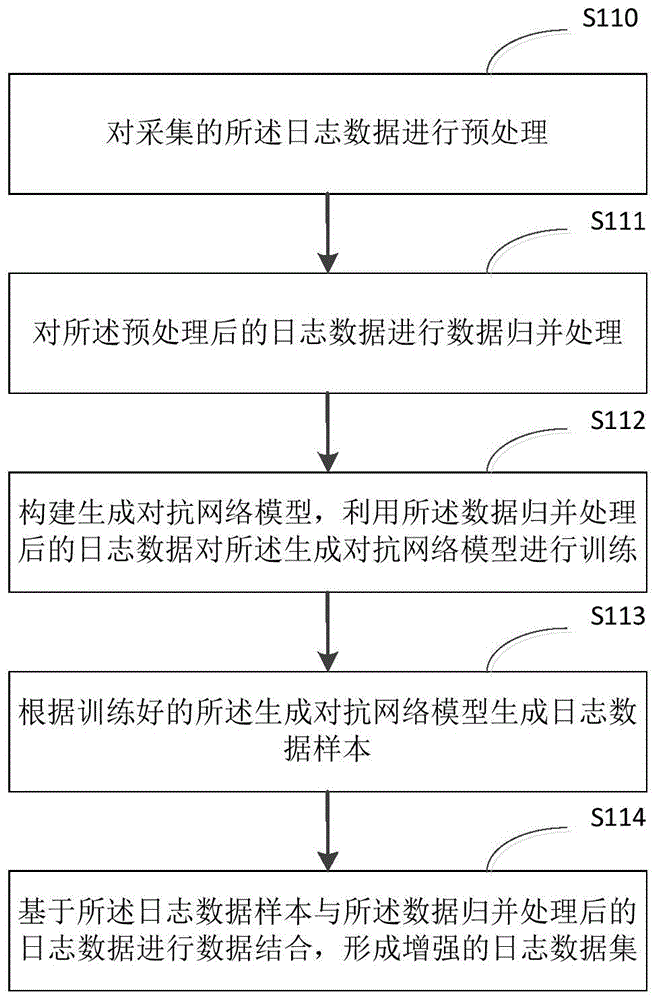
图1为本公开实施例提供的一种日志数据增强方法的实现流程图;
图2为本公开实施例提供的生成对抗网络模型的实现流程图;
图3为本公开实施例提供的一种日志数据分类检测方法的实现流程图;
图4为本公开实施例提供的一种日志数据增强装置的结构示意图;
图5为本公开实施例提供的一种日志数据分类检测系统的结构示意图;
图6为本公开实施例提供的另一种日志数据分类检测系统的结构示意图。
具体实施方式
为了能够更清楚地理解本公开的上述目的、特征和优点,下面将对本公开的方案进行进一步描述。需要说明的是,在不冲突的情况下,本公开的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本公开,但本公开还可以采用其他不同于在此描述的方式来实施;显然,说明书中的实施例只是本公开的一部分实施例,而不是全部的实施例。
本公开实施例提供了一种日志数据增强方法,能够有效的解决日志数据中正常和恶意样本存在的样本不平衡问题,其中,样本不平衡问题包括标签分类不平衡和错分成本不平衡,其中,标签分类不平衡可理解为某一类样本多,而另一类样本少,甚至没有样本的情况。同样,数据集中每一类别的分类错误的成本通常是一样的,但在实际应用中,不平衡的数据集导致错分成本上升,可能会出现无法挽回的情况。因此,样本不平衡的问题对验证和测试样本的获取造成了干扰,一些类观测极少的情况下,很难在类中有代表性,使得训练的模型或算法没有充分的考虑到隐含类,从而导致样本少的种类预测性能很差,甚至无法预测,但是用不平衡的数据训练出来的模型纵使有以上问题,一般情况下也往往会得到最高的准确率ap。因此,解决日志样本不平衡的问题,能够最大限度的降低了网络安全数据集中每一类别的分类错误的成本,准确的检测处未知网络威胁。
在现有技术中,对于数据增强的方法,一方面采用采样技术,以人工数据合成来增强数据集方法,对于数据不平衡的问题采取的最直接的方法就是搜集更多稀缺类别的数据,使得数据分布趋于平衡通过。包括:
欠采样法:该方法主要是对大类进行处理它会减少大类的观测数来使得数据集平衡这一办法在数据集整体很大时较为适宜,它还可以通过降低训练样本量来减少计算时间和存储开销。但该方法丢弃了大量数据,和过采样一样会存在过拟合的问题。由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别而不够泛化。
过采样法:这一方法针对小类进行处理它会以重复小类的观测的方式来平衡数据该方法也被称作升采样(upsampling)和欠采样类似,它也能分为随机过采样和有信息的过采样两类。但是,该方法只是重复正比例数据,实际上没有为模型引入更多数据,过分强调正比例数据,会放大正比例噪音对模型的影响。使用该方法的一大优势是没有任何信息损失,缺点则是由于增加了小类的重复样本,很有可能导致过拟合。
数据合成:smote(syntheticminorityoversamplingtechnique)即合成少数类过采样技术,它是基于随机过采样算法的一种改进方案,smote算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。该算法主要存在两方面的问题:一是在近邻选择时,存在一定的盲目性。其次,该算法无法克服非平衡数据集的数据分布问题,容易产生分布边缘化问题。由于负类样本的分布决定了其可选择的近邻,如果一个负类样本处在负类样本集的分布边缘,则由此负类样本和相邻样本产生的“人造”样本也会处在这个边缘,且会越来越边缘化,从而模糊了正类样本和负类样本的边界,而且使边界变得越来越模糊。这种边界模糊性,虽然使数据集的平衡性得到了改善,但加大了分类算法进行分类的难度,分类精度在一定程度上无法保证。
另一方面,利用小样本学习这种更先进的数据增强方法,新的网络威胁数据增强方法包括基于gan网络扩展数据,从少数样本中幻觉图像以及增强特征空间中的数据。但传统的gan模型一次只能学习一类数据,对于包含多个类的数据样本集,需逐类学习及生成相应类的被增强样本集,因此,模型的效率比较低。
为解决上述利用现有技术进行日志数据增强时存在的问题,本公开实施例一种日志数据增强方法,采用改进的生成对抗网络模型扩充恶意/威胁样本种类和数量,有效减少过拟合,预测效果较好。
图1为本公开实施例提供的一种日志数据增强方法的实现流程图,具体详情如下:
步骤s110,对采集的所述日志数据进行预处理;
可选地,所述步骤s110中采集的日志数据为网络安全信息日志数据,对所述日志数据进行预处理包括:
利用规则库去除所述日志数据中的冗余数据;
将所述去除冗余数据的日志数据存储为统一的文档格式。
可选地,所述日志数据为多源异构日志数据。
其中,将所述去除冗余数据的日志数据存储为统一的文档格式,可理解为,对所述预处理后的日志数据进行数据格式转换,设计日志数据的文档,结合编程进行数据格式转换,经过数据格式转换后得到统一的文档格式。
优选地,日志数据文档格式可以为txt、json、csv和xml等格式。
步骤s111,对所述预处理后的日志数据进行数据归并处理;
可选地,在步骤s111中对步骤s110中所述预处理后的日志数据进行数据归并处理包括:
对所述预处理后的日志数据按照时间戳规则进行数据归并处理。
可选地,按时间戳规则对日志数据进行数据归并,能够将同一时间点发生的网络安全事件进行综合判断。
步骤s112,构建生成对抗网络模型,利用步骤s111中所述数据归并处理后的日志数据对所述生成对抗网络模型进行训练;
生成对抗网络gan是由goodfellow等人提出的一个通过对抗过程估计生成模型的新框架,在该框架中同时训练两个网络:生成网络g和判别网络d。在训练过程中,生成网络g的目标就是尽量生成真实的图片去欺骗判别网络d,而判别网络d的目标就是尽量把生成网络g生成的图片与真实的图片区分开来。这样,生成网络g和判别网络d构成了一个动态的“博弈过程”,即寻找二者之间的一个平衡点,如果达到该平衡点,判别网络d无法判断数据来自生成网络g还是真实样本,此时g达到最优状态。
生成模型是机器学习中一种重要的模型,生成对抗网络属于隐式生成模型的范畴。生成对抗网络作为隐式生成模型,关键在于如何判断生成的样本是否服从真实的分布,判别器正是用于监督生成器生成样本的好坏,即判断生成数据的真伪。从这个角度来看,判别器实际上是一个二分类网络。二者相互对抗:生成网络不断提高自己的生成能力试图瞒过判别网络的审查,从而以假乱真;判别网络不断提升甄别的能力,以防止生成网络生成的数据鱼目混珠,两者在对抗中相互提高,在理想的状态下,生成网络生成的数据达到了以假乱真的效果,判别网络输出样本是来自真实数据分布的概率,损失为交叉熵损失。
与其他一些生成模型相比,gan有以下两大特点:
不需要依赖任何先验分布,生成对抗网络不需要先验假设,这样减少了模型的局限性,拓宽了模型的学习能力,从模型中采样数据十分简单。相比其他生成方法的繁琐采样过程,gan只需要一次前向计算即可。
gan包括d和g分别表示判别器和生成器,它们的结构都为cnn。其中,判别器d的输入为真实数据x,输出为1或0,生成器g的输入是一维随机噪声向量z,输出是g(z)。训练的目标是使得g(z)的分布pz尽可能接近真实数据的分布pdata。d的目标是实现对输入数据的二值分类,若输入来源于真实样本,则d的输出为1;若输入为g(z),则d的输出为0。g的目标是使自己生成的数据g(z)在d上的表现d(g(z))和真实数据x在d上的表现d(x)尽可能一致,g的损失函数可以如下式计算:
式(2)描述的是,g在不断对抗学习的过程中,生成的数据g(z)越来越接近真实样本,d对g(z)的判别也越来越模糊。d的损失函数可如下式计算:
综上,g和d的总体损失函数可以如下式计算:
可选的,本实施例对于离散型数据,采用gan的变型,离散序列生成对抗网络的方法对小样本数据进行增强。实施例基础框架采用改进的gan,即seq-gan网络模型,解决了基于文本日志数据生成器(generator)难以传递梯度更新,在生成部分文本后判别器(discriminator)难以评估非完整序列的问题。
可选的,改进的gan的生成器使用循环神经网络(recurrentneuralnetwork,rnn),判别器使用卷积神经网络(convolutionalneuralnetworks,cnn),并引入强化学习(reinforcementlearning,rl)和蒙特卡洛树搜索(montecarlo)。
可选的,图2是根据图1对应实施例示出的一种日志数据增强方法中步骤s112的一种具体实现流程图。如图2所示,步骤s112具体可以包括如下步骤:
步骤s1120,随机初始化所述生成器和所述判别器的参数;
步骤s1121,通过最大似然估计预训练步骤s1120中所述生成器;
可理解的是,通过最大似然估计mle预训练生成器g网络,能够提高g网络的效率。
步骤s1122,根据步骤s1121中所述预训练生成器生成初始数据,基于所述初始数据通过最小化交叉熵预训练步骤s1120中所述判别器;
可理解的是,当生成器通过训练时,需要定期对判别器进行重新训练,以保持与生成器的良好同步。
步骤s1123:将随机变量输入步骤s1121中所述预训练生成器中生成日志文本序列;
其中,所述日志文本序列包括完整的日志文本序列和非完整的日志文本序列;
步骤s1124,采用蒙特卡洛树搜索对步骤s1123中所述非完整的日志文本序列进行模拟;
可理解的是,采用蒙特卡洛树搜索的方法解决了生成器生成部分文本后判别器discriminator难以评估非完整序列的问题。
步骤s1125,将步骤s1124中所述模拟的日志文本序列与步骤s1123中所述完整的日志文本序列结合,形成新的日志文本序列;
步骤s1126,根据步骤s1125中所述新的日志文本序列和步骤s111中所述数据归并处理后的日志数据训练步骤s1122中所述预训练判别器,更新所述预训练判别器的参数形成新的判别器,并生成奖励值;
可选地,当训练判别器时,给定的日志数据集作为正的例子,而生成器生成的日志数据作为负的例子。为了保持平衡,生成的负示例数与正示例数相同。同时,为了降低估计的可变性,需要使用不同的负样本集和正样本集。
可选地,对于生成器生成的非完整的序列用generator作为roll-outpolicy,将剩余的t-t个元素采用蒙特卡洛树思想采样。利用日志文本序列计算奖励的公式如下式所示:
其中,在时刻t,当前的状态s被定义为“已生成的序列”,(y1,…,yt-1),记作y1:t-1,而动作a是接下来要选出的元素yt,所以策略policy模型就是gθ(yt|y1:t-1)。
可理解的是,采用判别器基于完整序列的输出作为强化学习的奖励,即作为下述策略梯度算法的奖励来更新生成器的参数。
步骤s1127,利用策略梯度算法结合步骤s1126中所述奖励值对步骤s1121中所述预训练生成器进行训练,更新所述预训练生成器的参数生成新的生成器。
优选的,本申请所述生成对抗网络中通过直接执行策略梯度算法更新g的参数来避免传统gan中离散序列数据的区分问题,同时也解决了基于文本日志数据生成器generator难以传递梯度更新的问题。
可选地,策略梯度policygradient对参数进行迭代更新的计算公式如下:
其中,给定一个参数θ,
步骤s113,根据步骤s112中训练好的所述生成对抗网络模型生成日志数据样本;
步骤s114,基于步骤s113中所述日志数据样本与步骤s111所述数据归并处理后的日志数据进行数据结合,形成增强的日志数据集。
本公开提供的一种日志数据增强方法,一方面,解决了日志样本标签分类不平衡的问题,增强的日志数据样本使得标签分类趋于平衡,近而解决了安全样本错分成本不平衡问题,生成更加平衡的日志数据集也降低了错分成本;另一方面,为面临少量标签日志数据训练模型的情况提供了大量日志数据,解放了人工标注标签数据的繁重工作,同时便于之后利用深度学习模型训练分类检测模型时提供所需的大量日志样本,提高了模型性能。
下述为本公开一种日志数据分类检测方法实施例。采用上述日志数据增强方法对日志数据进行增强,形成增强的日志数据集。
图3为本公开实施例提供的一种日志数据分类检测方法的实现流程图,具体实现步骤如下所示:
步骤s115,采集日志数据,基于所述日志数据采用上述一种日志数据增强方法构建增强的日志数据集;
可选地,采用上述一种日志数据增强方法增强生成恶意样本,完成恶意/威胁样本扩充。
步骤s116,提取步骤s115中所述增强的日志数据集的语义向量,构建语义向量数据集;
可选的,所述提取所述增强的日志数据集的语义向量,构建语义向量数据集包括:
利用自然语言模型提取步骤s115中所述增强的日志数据集的语义向量,构建语义向量数据集;其中,提取所述增强的日志数据集的语义向量包括词向量、基于词向量的段向量和关键词。
可选地,构建日志中的海量文本数据的语义向量。
优选的,不需要设计特征向量,即可进行词向量、基于词向量的段向量、关键词的提取。
可选地,自然语言模型可以采用但不限于lstm、rnn以及cnn等网络模型来提取日志数据的语义向量。
步骤s117,对步骤s116中所述语义向量数据集进行上下文分析,形成特征向量数据集;
可选地,转变日志ip地址到连续特征空间中,进行上下文分析。
可理解的是,当出现的ip地址在相似的上下文中时,例如经常会在特征空间中出现频率相互接近的特征,因此通过上下文分析检测可以得出哪些设备关联的ip地址建立了一些相似的网络威胁连接。
步骤s118,构建深度神经网络模型,根据步骤s117中所述特征向量数据集训练所述深度神经网络模型,生成分类检测模型。
可理解为,利用上述日志数据增强方法生成大量日志样本中的威胁数据集,或是为特定任务生成少量假的例子,将增强的日志数据添加到原始日志数据中,然后使用普通深度神经网络或匹配网络继续宁训练,生成分类检测模型。
本公开提供的一种日志数据分类检测方法,解决了网络空间安全领域日志多维数据正常和恶意样的不平衡问题,增加了样本的差异性,达到了网络安全样本的数据扩充的目的,平衡的日志数据训练出来的分类检测模型使日志样本少的威胁种类预测性能提高,同时也解决了缺乏代表性样本导致的过拟合问题,还增强了网络模型的泛化能力。
下述为本公开装置实施例,可以用于执行本公开上述一种日志数据增强方法实施例。对于本公开装置实施例中未披露的细节,请参照本公开一种日志数据增强方法实施例。
图4是本公开实施例提供的一种日志数据增强装置的结构示意图,该装置包括但不限于:日志数据预处理模块11、数据归并处理模块12、生成对抗网络模型构建和训练模块13以及日志数据样本增强模块14。
日志数据预处理模块11,用于对采集到的日志数据进行预处理;
可选地,对所述日志数据进行预处理包括:
利用规则库去除所述日志数据中的冗余数据;
将所述去除冗余数据的日志数据存储为统一的文档格式。
数据归并处理模块12,用于对日志数据预处理模块11中所述预处理后的日志数据按时间戳规则进行数据归并处理;
可选地,对所述预处理后的日志数据进行数据归并处理包括:
对日志数据预处理模块11所述预处理后的日志数据按照时间戳规则进行数据归并处理。
生成对抗网络模型构建和训练模块13,构建生成对抗网络模型,利用数据归并处理模块12中所述数据归并处理后的日志数据进行训练并生成模型;
可选地,所述生成对抗网络模型包括生成器和判别器。
可选地,所述构建生成对抗网络模型,利用数据归并处理模块12所述数据归并处理后的日志数据对所述生成对抗网络模型进行训练并形成模型。
日志数据样本增强模块14,根据生成对抗网络模型构建和训练模块13训练好的所述生成对抗网络模型生成日志数据样本,将所述日志数据样本与数据归并处理模块12所述数据归并处理后的日志数据结合,形成增强的日志数据集。
本公开实施例提供的一种日志数据增强装置,解决了网络空间安全领域日志多维数据正常和恶意样本普遍存在的不平衡问题,完成验证和测试样本的增强,实现在一些类观测极少的情况下,生成的数据在类中有代表性。
下述为本公开系统实施例,具体基于本公开上述一种日志数据分类检测方法系统实施例。对于本公开系统实施例中未披露的细节,请参照本公开一种日志数据分类检测方法实施例。
图5为本公开实施例提供的一种日志数据分类检测系统的结构示意图,该系统包括数据采集模块15、语义向量数据集构建模块16、上下文分析模块17和日志数据分类检测模块18。
数据采集模块15,用于采集日志数据,并由本公开上述日志数据增强装置构建增强的日志数据集;
可选地,所述采集的日志数据为网络安全信息日志数据。
可选地,所述增强的日志数据集可以包括恶意/威胁日志数据集。
语义向量数据集构建模块16,用于提取数据采集模块15所述增强的日志数据集的语义向量,构建语义向量数据集;
可选地,所述构建语义向量数据集包括:
利用自然语言模型提取数据采集模块15所述增强的日志数据集的语义向量,构建语义向量数据集;其中,提取所述增强的日志数据集的语义向量包括词向量、基于词向量的段向量和关键词。
上下文分析模块17,将语义向量数据集构建模块16构建的所述语义向量数据集进行上下文分析,形成特征向量数据集;
日志数据分类检测模块18,构建深度神经网络模型,根据上下文分析模块17所述特征向量数据集训练深度神经网络模型,生成分类检测模型。
本公开实施例提供的日志数据分类检测系统,降低了网络安全数据集中每一类别的分类错误的成本,减少了将一个正常的数据误诊存在恶意威胁带来的损害,避免了将恶意威胁误判为正常将可能导致的重大损失。
下述为本公开另一系统实施例,具体基于本公开上述一种日志数据分类检测方法系统实施例。对于本公开系统实施例中未披露的细节,请参照本公开一种日志数据分类检测方法实施例。
图6为本公开实施例提供的另一种日志数据分类检测系统的结构示意图,该系统包括日志数据预处理模块11、数据归并处理模块12、生成对抗网络模型构建和训练模块13、日志数据样本增强模块14语义向量数据集构建模块16、上下文分析模块17和日志数据分类检测模块18。模块具体实施步骤如下:
日志数据预处理模块11,用于对采集到的日志数据进行预处理;
可选地,对所述日志数据进行预处理包括:
利用规则库去除所述日志数据中的冗余数据;
将所述去除冗余数据的日志数据存储为统一的文档格式。
数据归并处理模块12,用于对日志数据预处理模块11所述预处理后的日志数据按时间戳规则进行数据归并处理;
可选地,对所述预处理后的日志数据进行数据归并处理包括:
对日志数据预处理模块11所述预处理后的日志数据按照时间戳规则进行数据归并处理。
生成对抗网络模型构建和训练模块13,构建生成对抗网络模型,利用数据归并处理模块12所述数据归并处理后的日志数据进行训练并生成模型;
可选地,所述生成对抗网络模型包括生成器和判别器。
可选地,所述构建生成对抗网络模型,利用数据归并处理模块12所述数据归并处理后的日志数据对所述生成对抗网络模型进行训练并形成模型。
日志数据样本增强模块14,根据生成对抗网络模型构建和训练模块13训练好的所述生成对抗网络模型生成日志数据样本,将所述日志数据样本与数据归并处理模块12所述数据归并处理后的日志数据结合,形成增强的日志数据集;
语义向量数据集构建模块16,提取日志数据样本增强模块14所述增强的日志数据集的语义向量,构建语义向量数据集;
可选地,构建语义向量数据集包括:
利用自然语言模型提取数据采集模块15所述增强的日志数据集的语义向量,构建语义向量数据集;其中,提取所述增强的日志数据集的语义向量包括词向量、基于词向量的段向量和关键词。
上下文分析模块17,将语义向量数据集构建模块16构建的所述语义向量数据集进行上下文分析,形成特征向量数据集;
日志数据分类检测模块18,构建深度神经网络模型,根据上下文分析模块17所述特征向量数据集训练深度神经网络模型,生成分类检测模型。
本公开实施例提供的另一种日志数据分类检测系统,弥补某些威胁/恶意样本数量种类的不足,实现网络安全领域的多维数据少量存在的威胁数据增强,降低了网络安全数据集中每一类别的分类错误的成本,减少了将一个正常的数据误诊存在恶意威胁带来的损害,避免了将恶意威胁误判为正常将可能导致的重大损失。
本公开实施例还提供一种计算机装置,所述计算机装置包括处理器,所述处理器用于执行存储器中存储的计算机程序时实现上述各个实施例中日志数据增强方法,或者用于上述任一实施例中日志数据分类检测方法。
本公开实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一实施例中日志数据增强方法的步骤,或者用于上述任一实施例中日志数据分类检测方法的步骤。
需要说明的是,在本文中,诸如“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
以上所述仅是本公开的具体实施方式,使本领域技术人员能够理解或实现本公开。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本公开的精神或范围的情况下,在其它实施例中实现。因此,本公开将不会被限制于本文所述的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!