一种基于非均匀节点部署的无线传感器网络通信方法
本发明涉及无线传感器的技术领域,具体涉及一种基于非均匀节点部署的无线传感器网络通信方法。
背景技术:
由于无线传感器网络技术具有高度灵活性和拓展性,广泛应用于智能家居、环境监测、军事等领域,但是因为无线传感器网络的节点能量受到限制,能量控制成为衡量无线传感器网络质量的重要指标。无线传感器网络是一个面向应用的系统,对于不同的应用环境进行不同的节点部署,所以大多数协议所采用的均匀部署策略不适用于多个特定目标区域的监测。
其中leach协议作为一种经典的分簇路由协议,它存在着簇首选举过于随机,可能使得能量很小或距离基站很远的节点成为簇首,从而导致网络能耗不均匀的问题。并且对于非均匀分布的无线传感器网络,leach未能考虑节点密度对簇首选举的影响,选举的簇首可能距离聚类中心过远,使得簇内能耗过大。
技术实现要素:
本发明的目的在于提供一种基于非均匀节点部署的无线传感器网络通信方法,延长网络寿命,提高无线传感器网络的稳定性和可靠性。
为实现上述目的,本发明采用的技术方案是:
一种基于非均匀节点部署的无线传感器网络通信方法,包括基站和节点,所述节点包括位于目标区域内的普通节点和簇首节点。
所述普通节点与基站之间的通信采用以下两种方式中数据转发能耗较小的一种:
方式一:节点将数据转发给基站;
方式二:节点将数据转发给簇首节点,簇首节点再将数据转发给基站。
优选的,所述两种方式的数据转发对整个网络能耗的确定方法如下;
方式一、普通节点将k比特数据转发给基站,能耗为:
其中ε1与t1的值根据普通节点到基站的距离dbs决定;
方式二、节点将k比特,数据转发给簇首,能耗为:
其中eg为融合单位数据的能耗,ε2与t2的值根据节点到最近且能量最大的下一跳簇首的距离dch决定。
优选的,所述目标区域内的簇首节点选举采用leach协议中“轮”的概念,每一轮中,目标区域内的节点相互竞举出簇首节点,同时衡量簇首节点到基站距离的远近。
进一步优选的,所述簇首节点选举的具体方法如下:
factor_e(i)表示节点i的能量因子,定义如下:
其中,ni表示节点所属的节点分区,e(i)表示此刻节点的能量,eaverage(ni)表示节点分区内的平均能量;
factor_d(i)为距离因子,衡量节点到基站的距离远近:
其中,dmax和dmin表示该区域内所有节点距离基站最大和最小的距离,d(i)是节点i到基站的距离,该式表示距离的归一化处理,d(i)是节点i到基站的距离,该式为距离的归一化处理;
factor_r(i)为密度因子,用于衡量节点分区内节点与节点的距离大小:
factor_r(i)=rho(i)/rho_nm(5)
其中,
节点的簇首竞争权值如下:
w(i)=k1factor_e(i)+k2factor_d(i)+k3factor_r(i)(6)
其中,k1+k2+k3=1;
k值如下设定:
将节点的竞争权值进行降序排序,由大到小选取前5%-20%的节点作为簇首节点。
进一步的,所述目标区域由部署区域内的节点按照以下方法分区获得:
节点i的密度定义为:
其中dc是截断距离参数,设定为网络中所有可通信距离中第2%的距离;
节点i到更高局部密度点的距离如下:
选取前km个γi=ρiδi值大的节点作为筛选聚类中心,km为部署区域划分目标区域的个数,然后对节点按照密度从大到小排序,依次加入距离最近的局部密度高的目标分区。
进一步的,在目标区域中减少噪声点,定义噪声点的判据为该节点的密度为0,即该节点可通信范围内没有其余节点。
优选的,所有节点同构。
优选的,所述节点随机分布。
优选的,所述节点的信息包括:能量、种类、位置、是否为簇首。
优选的,所述部署区域形状不限。
本发明相较与leach和leach-c,网络的整体寿命明显优于前两种方法,并且网络整体能量降低速率明显低于该两种方法。
附图说明:
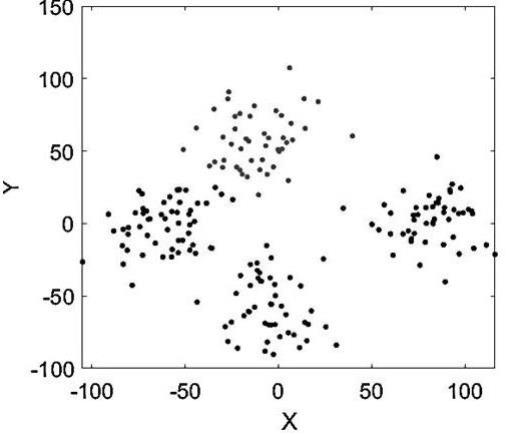
图1为无线传感器节点分布图;
图2为节点存活数量示意图;
图3为网络剩余能量示意图;
图4为分区决策图;
图5为分区结果图。
具体实施方式
下面结合附图对本发明的实施例进行详细说明。
如图1所示,本发明公开的基于非均匀节点部署的无线传感器网络通信方法,可采用如下步骤建立和验证:
(1)网络模型
已知在200m×200m区域内有4个模糊目标区域需要进行节点部署,然后通过随机抛洒的方式围绕着目标位置进行节点的随机部署,共部署200个无线传感器节点,节点周期性采集数据或转发数据。该网络有以下假设:
1、无线传感器网络节点部署后位置不会改变;
2、节点分布随机,主要围绕着大概的目标位置进行部署;
3、所有节点是同构的;
节点集合定义为node={node(i)|1≤i≤n},节点需要管理能量、种类、位置、是否为簇首的信息。
(2)能耗模型
节点发送k比特的数据到距离d的位置,采用典型无线通信能耗模型:
其中eelec是节点接收或发送1bit数据的能耗,且有
节点接受k比特的数据能耗模型:
erx=keelec
(3)网络分区
本发明考虑到节点部署有明显的密度差异,因此采用改进的密度峰值聚类方法(dpc)进行网络分区。
节点i的密度定义如下:
其中r为节点的通信距离,dc是截断距离参数,设置为网络中所有节点可通信距离中第2%的距离。
节点i到更高局部密度点的距离定义如下:
为了筛选出合适的聚类中心,定义聚类中心需要同时具有较大的ρi和δi,因此设γi=ρiδi,聚类中心即为γ值较大的点。因为已知该网络是对km个目标区域进行部署,所以聚类中心即为γ的前km个点。
然后对节点按照密度从大到小排序,依次加入距离最近的局部密度高的节点类别。为了减少噪声点的存在,定义噪声点的判据为该节点的密度为0,即该节点可通信范围内没有其余节点。否则不是噪声点。至此网络分区结束,将分区结果表示为n={nm|1≤m≤k}。
(4)簇首选举
factor_e(i)表示节点i的能量因子,定义如下:
ni表示节点所属的区域,e(i)表示此刻节点的能量,eaverage(ni)表示该区域内的平均能量。
factor_d(i)是距离因子,衡量节点到基站的距离远近,
其中,dmax和dmin表示该区域内所有节点距离基站最大和最小的距离,d(i)是节点i到基站的距离,该式表示距离的归一化处理。
factor_r(i)是密度因子,衡量节点与区域内其他节点的距离大小:
factor_r(i)=rho(i)/rho_nm
其中,
本发明沿用leach协议中“轮”的概念,每一轮中,区域内的节点相互竞争,
选举出该区域内的簇首,竞争权值定义如下:
w(i)=k1factor_e(i)+k2factor_d(i)+k3factor_r(i)
其中k1+k2+k3=1,因此能量越多、距离基站越近、通信范围内节点密度越大的节点越容易成为簇首。由于随着距离基站的远近,竞争权值首要考虑的因
素不一样,因此对k值进行如下设定:
已有文献研究簇首数量占总节点数量的5%-20%,节能和覆盖效果较好,因此事先预估每个分区的簇首数量,将每个区域节点的竞争权值进行降序排序,取适当数量的节点作为簇首。此处簇首依旧是在一个周期内不重复担任,以免个别节点耗能过快。
(5)路由选择
对于每一个节点都存在两种选择,将数据转发给基站或簇首,为使得选择路径最优,考虑不同路由选择下对整个网络的能耗。
如果节点选择将kbit数据转发给基站,能耗为
其中ε1与t1的值根据节点到基站的距离dbs决定。
如果节点选择将数据转发给下一跳簇首,能耗为
其中eg表示融合单位数据的能耗,ε2与t2的值根据节点到最近且能量最大的下一跳簇首的距离dch决定。对于普通节点而言,不需要将数据进行融合,直接发给簇首,因此上式eg=0。
将不同选择下的能耗进行比较选择能耗最小的路由,通过这个方法可使得数据转发能耗最小。
二、方案效果
如图2所示,本发明与leach和leach-c相比较,本发明虽然首个节点死亡轮数早于leach-c协议,但是在轮数过半时,本方法仍能存活大量节点,网络的整体寿命明显优于前两种方法;如图3所示,网络整体能量降低速率明显低于该两种方法。
以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制,应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!