视频编码和解码中的色度帧内预测的制作方法
1.本公开涉及视频编码和解码。
背景技术:
2.可以对数字视频进行编码以用于传输和/或存储。这在对信道带宽的需求、存储要求以及错误检测和/或校正方面可以具有效率优势。
3.视频压缩技术涉及采集视频数据块并采用多种方法来发挥冗余的优势。例如,帧内预测是一种空间性方法,其涉及针对一个视频块,参考视频数据的同一帧中的另一个(预测性的)视频块来对其进行编码。另一方面,帧间预测是一种时间性方法,其涉及针对视频帧的一个视频块,参考视频数据的另一帧的相应的(预测性的)块来对其进行编码。
4.通常,视频数据包括亮度(luma)数据和色度(chroma)数据。亮度数据表示图像的亮度,而并不参考颜色。本质上,亮度数据描述了黑白图像,并且准确地说,这样的图像可以单独地根据亮度数据进行重构。色度数据表示颜色信息,该颜色信息可被用于在黑白图像上对颜色进行重构。
5.可以使用不同的方法来对亮度数据和色度数据进行编码。人眼对亮度比对色度更加敏感;这导致相比亮度数据有机会更进一步地压缩色度数据。
附图说明
6.图1是根据实施例的通信网络的示意图;
7.图2是图1的通信网络的发送器的示意图;
8.图3是示出在图2的发送器上实施的编码器的图;
9.图4是示出图3的编码器的预测模块的结构和功能的过程图;
10.图5是图1的通信网络的接收器的示意图;
11.图6是示出在图4的接收器上实施的解码器的图;以及
12.图7是示出图6的解码器的预测模块的结构和功能的过程图。
具体实施方式
13.多功能视频编码(vvc:versatile video coding)(mpeg-i part 3)是目前由联合视频专家团队(jvet:joint video experts team)、iso/iec jtc 1的mpeg工作组的联合视频专家团队和itu-t的vceg工作组开发的视频压缩标准。
14.通常通过基于当前块附近环境中已经重构的样本计算预测值来采用帧内预测,以便开发帧内的空间冗余。最新的vvc草案(在本文档的其余部分中被简称为vvc)允许使用大量可能的帧内预测模式(“帧内模式”)来预测亮度分量,所述大量可能的帧内预测模式包括多达65个角度(定向)模式、平面(planar)和直流(dc)预测以及其它高级的预测方法。
15.这大量的选项是以相当大数量的信令数据为代价的,用以用信号通知在亮度数据块上采用了哪种帧内模式。相反,为了限制帧内模式信令的影响,采用了缩减数量的帧内模
式来对色度分量进行帧内预测。这包括可被用于预测亮度的模式的子集,包括例如导出模式(dm:derived mode,对应于使用被用于预测亮度的模式)加上一小组固定候选模式(包括planar模式、dc模式、纯水平模式和纯垂直模式)。
16.此外,vvc规定了交叉分量线性模型(cclm:cross-component linear model)帧内模式的使用。当使用cclm时,使用线性模型从已经重构的亮度样本中预测色度分量。该模型的参数是借助于简单的线性回归而导出的,被应用于从编码块左上边界中提取出的已重构的相邻的亮度和色度样本。目前在vvc中采用了三种cclm模式,包括使用左上可用样本的通用lm模式以及分别采用仅从当前块的顶部或左侧提取出的参考样本的扩展阵列的两种定向lm模式。
17.已经证实了lm预测的使用有效地提高了色度帧内预测的效率。然而,本文所公开的实施例寻求从其它方法中获得进一步的优势。
18.在此应注意,简单线性预测的使用可能会受到限制。相对于现有技术,本文所公开的实施例可以通过使用基于机器学习(ml:machine learning)机制的更复杂的架构来实现改进的性能。
19.在“用于色度帧内预测的混合神经网络”(2018年第25届ieee图像处理国际会议(icip:international conference on image processing);li yue、li li、zhu li、jianchao yang、ning xu、dong liu和houqiang li;ieee,2018,pp.1797-1801)中对用于色度帧内预测的混合神经网络进行了描述,其中,用于从当前块的已重构亮度样本中提取特征的卷积神经网络(cnn:convolutional neural network)与现有的用于提取相邻亮度与色度样本之间的交叉分量相关性的基于全连接的架构相结合。使用这样的架构,可以推导出复杂的非线性映射,以用于对cb和cr信道进行端到端预测。然而,这样的架构通常会在对预测块中的相应位置进行预测时忽略边界样本的空间相关性。
20.本文所公开的实施例提供了一种包含注意力模块的神经网络架构,该注意力模块用于控制每个参考相邻样本对计算针对每个样本位置的预测值的贡献,从而确保在计算预测值时考虑到空间信息。与前述的混合神经网络类似,根据本文所公开的实施例的方法采取了基于三个网络分支的方案,该三个网络分支被组合以产生预测样本。前两个分支同时工作,用以从可用的已重构样本中提取特征,该已重构样本包括已经重构的亮度块以及已经重构的相邻的亮度和色度参考样本。第一个分支(被称为交叉分量边界分支)旨在使用当前块的左侧和上方的扩展参考阵列来从相邻的已重构样本中提取交叉分量信息。第二个分支(被称为亮度卷积分支)应用卷积操作来遍及并置的已重构亮度块而提取空间图案。本文所描述的实施例呈现了使用注意力模块来融合由第一个分支和第二个分支输出的特征的过程。下面将描述注意力模块的示例。注意力模块的输出最终被馈送到第三个网络分支,用以产生作为结果的cb和cr色度输出预测值。
21.这种使用神经网络来实现色度预测的方法可以被看作是对vvc中定义的现有色度预测模式的扩充。因此,在实施例中,可以实现基于神经网络的架构,用以与针对所支持的4
×
4、8
×
8、16
×
16设置的已建立模式进行竞争。然后,针对每个预测单元,编码器将通过使率失真成本标准最小化来在传统的角度模式、lm模型或所公开的神经网络模式之间进行选择。
22.上述布置可以在视频通信网络中实现,被设计为通过编码技术来对视频呈现进行
处理,使其能够被传输(或存储)以供回放设备解码。
23.一般而言,本公开的方面能够基于亮度样本和注意力掩蔽(attention mask)来对色度样本进行帧内预测,该注意力掩蔽通过卷积神经网络来配置。
24.如图1中所示,其示出了包括示意性视频通信网络10的布置,其中发送器20和接收器30经由通信信道40进行通信。在实践中,通信信道40可以包括卫星通信信道、有线网络、基于地面的无线电广播网络、pots实现的通信信道(例如,用于向家庭和小型商业场所提供互联网服务)、光纤通信系统或者上述中的任何组合以及任何其它可以想到的通信介质。
25.此外,本公开还扩展到通过物理传输与存储介质进行通信,在该存储介质上存储有已编码比特流的机器可读记录,用于传送到能够读取介质并从中获得比特流的适当地配置后的接收器。这方面的示例是提供数字多功能盘(dvd:digital versatile disk)或者同等产品。以下描述集中于例如通过电子或电磁信号载波的信号传输,但不应被理解为排除涉及存储介质的上述方法。
26.如图2中所示,发送器20在结构及功能上是计算机装置。其可以与通用计算机装置一起共享特定特征,但是考虑到发送器20的专用功能,一些特征可能是特定于实施方式的。读者将了解到哪些特征可能是通用类型,并且哪些特征可能需要专门配置以用于视频发送器。
27.因此,发送器20包括图形处理单元(gpu)202,该图形处理单元202被配置以便在处理图形和类似操作中特定使用。发送器20还包括一个或多个其它处理器204,其通常被提供或者被配置以用于诸如数学运算、音频处理、管理通信信道等其它目的。
28.输入接口206提供用于接收用户输入动作的设施。例如,这样的用户输入动作可以由用户与特定输入单元(包括一个或多个控制按钮和/或开关、键盘、鼠标或其它指向设备)、能够接收语音并将语音处理为控制命令的语音识别单元、被配置为接收并控制来自其它设备(诸如平板电脑或智能手机)的处理的信号处理器或者远程控制接收器的交互引起。以上的列举将被理解为是非穷尽的,并且读者可以设想其它形式的输入,无论是用户发起的还是自动的都可以。
29.同样,输出接口214能够操作以提供用于向用户或其它设备输出信号的设施。这样的输出可以包括用于对本地视频显示单元(vdu:video display unit)或任何其它设备进行驱动的显示信号。
30.通信接口208实现与一个或多个信号接收者的通信信道,无论是广播信道还是端到端信道。在当前实施例的上下文中,通信接口被配置为发射承载由发送器20编码的用于限定视频信号的比特流的信号。
31.处理器204,并且特别是为了本公开的利益,gpu 202能够操作以在编码器的操作中执行计算机程序。在这样做时,诉诸于由大容量存储设备208提供的数据存储设施,该大容量存储设备208被实现为提供大规模数据存储(尽管是在相对缓慢的访问基础上),并且在实践中将存储计算机程序且在当前背景下将存储视频呈现数据用以准备执行编码处理。
32.只读存储器(rom)210被预配置有被设计为提供发送器20的核心功能的可执行程序,并且随机存取存储器(ram)212被提供以用于在寻求执行计算机程序的过程中快速访问并存储数据及程序指令。
33.现在将参考图3描述发送器20的功能。图3示出了在发送器20上实现的编码器借助
于可执行指令对数据文件执行的处理管道,该数据文件用于表示包括用于顺序显示为图片序列的多个帧。
34.数据文件还可以包括伴随视频呈现的音频回放信息以及用以实现呈现的编目的其它补充信息(例如,电子节目指南信息、字幕或元数据等)。数据文件的这些方面的处理与本公开无关。
35.参考图3,图片序列中的当前图片或帧被传递到分割模块230,其中,当前图片或帧被分割成给定大小的矩形块以供编码器进行处理。处理可以是顺序的或并行的。该方法可以取决于特定实施方式的处理能力。
36.然后将每个块输入到预测模块232,该预测模块232寻求丢弃在该序列中存在的时间和空间冗余,并且使用先前已编码的内容来获得预测信号。能够计算这样的预测的信息被编码在比特流中。该信息应包含足够的信息以能够进行计算,包括在接收器处推断出完成该预测所需其它信息的可能性。下面将提供对当前所公开的实施例的预测模块的更多细节。
37.从原始信号中减去预测信号以获得残差信号。然后将残差信号输入到变换模块234,该变换模块234尝试通过使用更适当的数据表示来进一步减少块内的空间冗余。如上所述,在该实施例中,预期可以不对每组残差实施域变换,并且相反,根据这样做的预期效率,可以改为实施变换跳过。可以在比特流中用信号通知采用变换跳过。
38.然后,通常由量化模块236对所得信号进行量化,并且最后将由计算当前块的预测所需的系数和信息形成的所得数据输入到熵编码模块238,该熵编码模块238利用统计冗余借助于短二进制码来以紧凑形式表示信号。读者将注意到,如果已采用了变换跳过,则采用变换跳过残差编码(tsrc:transform skip residual coding)。
39.通过发送器20的编码设施的重复动作,可以构建块信息元素的比特流,用以传输到一个或多个接收器(视情况而定)。比特流还可以承载跨多个块信息元素而应用的信息元素,并因此以独立于块信息元素的比特流语法来保持比特流。这样的信息元素的示例包括配置选项、适用于帧序列的参数以及与整个视频呈现相关的参数。
40.现在将参考图4来更详细地描述预测模块232。如将理解,这仅是示例,并且可以预期本公开及所附权利要求范围内的其它方法。
41.对帧中的每个块执行下面的处理。
42.预测模块232被配置为对所输入的亮度样本和色度样本进行处理,以产生预测数据,该预测数据可随后被用于生成用于如上所述的进一步处理的残差。
43.现在将参考图4来描述预测模块232的结构和功能。
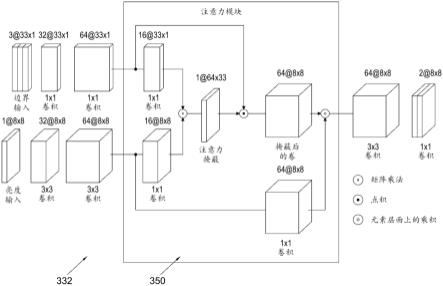
44.一般而言,预测模块232包括神经网络架构,该神经网络架构包含注意力模块250,该注意力模块250用于控制每个参考相邻样本对计算针对每个样本位置的预测值的贡献,从而确保在计算预测值时考虑到空间信息。预测模块232具有三个网络分支,该三个网络分支被组合以产生预测样本。如所示,第一个分支和第二个分支被并行地实现,用以从可用的样本(包括亮度块以及相邻的亮度和色度参考样本)中提取特征。第一个分支(被称为交叉分量边界分支)旨在使用当前块的左侧和上方的扩展参考阵列来从相邻的已重构样本中提取交叉分量信息。第二个分支(被称为亮度卷积分支)应用卷积操作来遍及并置的亮度块而提取空间图案。注意力模块融合由第一个分支和第二个分支输出的特征。
45.注意力模块250的输出最终被馈送到第三个网络分支,用以产生作为结果的cb和cr色度输出预测值。
46.采用如在深度学习框架中使用的“基于注意力”的学习来提高经训练的网络在复杂的预测任务中的性能。注意力模型可以通过预测顺序地处理的较小的“注意力区域”来减少复杂任务,用以促进更有效的学习。特别地,自我注意力(或帧内注意力)被用于评估特定输入变量对输出的影响,从而专注于同一序列中的最为相关的元素来计算预测。所述实施例的注意力模块250寻求组合来自第一个网络分支和第二个网络分支的特征,以便评估每个输入变量相对于它们的空间位置的影响。
47.这种方法可以解决用以计算基于ml的帧内预测后的样本的类似技术(通常完全丢弃输入和输出样本的空间位置中所包含的信息)的重要制约。
48.在实施例的使用示例中,假设已经对亮度分量执行了帧内预测并且最终重构的亮度样本是可用的。根据所使用的色度子采样,随后使用vvc中可用的常规滤波器来对该块进行下采样,用以获得与相应的色度分量相同的n
×
n空间维度的并置亮度样本块。为简单起见,在该版本的算法中仅考虑了方形块。在不损失通用性的情况下,可以使用更多的块大小以及更高级的下采样滤波器。
49.并置的亮度块被表示为当前块左上方的参考样本阵列被表示为b=2n+1,其中分别针对三个分量,c=y,cb,cr,其中b被如下构建。
50.首先,左边界中的样本被认为是从最底部的样本开始;然后考虑拐角;然后,顶部的样本被认为是从最左边的样本开始。在一些参考样本不可用的情况下,使用预定义的值来填充这些样本。
51.最后,通过拼接三个参考阵列by,b
cb
,b
cr
而获得的交叉分量卷被表示为在遍及s应用交叉分量边界分支并且遍及x应用亮度卷积分支之后,分别获得变换后的特征卷和
52.图4示出了针对两个分支(针对8
×
8块的特定情况)的子网络架构。表1提供了针对其它的块大小而选择的网络超参数的公开信息。由于使用了与上述最先进的基于混合神经网络的方法相类似的结构,因此未提供有关两个分支的构建和实施方式的扩展细节。
53.表1表示每个块大小的网络超参数,特别地,应用于所提议架构的不同分支的卷积核的深度。
54.分支4
×
48
×
816
×
16交叉分量边界分支16,3232,6464,96亮度卷积分支32,3264,6496,96注意力模块16,16,3216,16,6416,16,96输出分支32,264,296,2
55.在所提议的基于注意力的融合模块中,这两个特征图中的每一个使用1
×
1核来进行卷积,用以将它们投影到两个相应的缩减特征空间中。具体地,将与滤波器进行卷积以获得h维的特征矩阵f。类似地,将与滤波器进行卷积以获得h维的特征矩阵g。将两个矩阵相乘以获得预注意力图m=gtf。最后,对m的每个元素应用softmax
操作以获得注意力矩阵用以生成在能够预测块中的每个样本位置时每个边界位置的概率。正式地,对于a中的每个元素α
i,j
,其中,j=0...n
2-1表示预测块中的样本位置,并且,j=0...b-1表示参考样本位置,下面的公式被应用:
[0056][0057]
其中,t是用于控制所生成的概率的平滑度的softmax温度参数,其中0≤t≤1。注意,t值越小,所获得的注意力区域就越局部化,从而导致对给定预测位置作出贡献的边界样本也就相应地越少。
[0058]
通过计算交叉分量边界特征和注意力矩阵a之间的点积或者正式地可以获得每个参考样本对预测给定输出位置的贡献的加权和,其中,《
·
》是点积。为了进一步地细化该加权和可以乘以亮度分支的输出。为此,必须借助于使用矩阵的1
×
1卷积来变换亮度分支的输出以改变其维度,用以获得变换后的表示应用该操作以确保亮度卷积分支的输出尺寸与兼容。最后,获得注意力模型的输出如下:其中
°
是元素层面上的乘积。
[0059]
作为示例,对于所有经训练的模型,注意力模块内的维度参数h被设定为16,这是性能和复杂度之间的最佳权衡。t=0.5的值被交叉验证,从而确保信息样本与来自其余边界位置的噪声样本之间的最佳平衡。
[0060]
此外,应注意,预测模块232可以被配置为采用多个预定的帧间预测模式中的一个,但帧间预测与本公开的范围无关。此外,上述公开内容不排除实现如在vvc下指定的现有帧内预测模式的可能性。
[0061]
接收器的结构架构在图5中示出。它具有作为计算机实施的装置的元件。因此,接收器30包括图形处理单元302,该图形处理单元302被配置以便在处理图形和类似操作中特定使用。发送器30还包括一个或多个其它处理器304,其通常被提供或者被配置以用于诸如数学运算、音频处理、管理通信信道等其它目的。
[0062]
如读者将认识到的,接收器30可以以机顶盒、手持个人电子设备、个人计算机、或适合回放视频呈现的任何其它设备的形式来实现。
[0063]
输入接口306提供用于接收用户输入动作的设施。例如,这样的用户输入动作可以由用户与特定输入单元(包括一个或多个控制按钮和/或开关、键盘、鼠标或其它指向设备)、能够接收语音并将语音处理为控制命令的语音识别单元、被配置为接收并控制来自其它设备(诸如平板电脑或智能手机)的处理的信号处理器或者远程控制接收器的交互引起。以上的列举将被理解为是非穷尽的,并且读者可以设想其它形式的输入,无论是用户发起的还是自动的都可以。
[0064]
同样,输出接口314能够操作以提供用于向用户或其它设备输出信号的设施。这样的输出可以包括用于对本地电视设备进行驱动的适当格式的电视信号。
[0065]
通信接口308实现与一个或多个信号接收者的通信信道,无论是广播信道还是端到端信道。在当前实施例的上下文中,通信接口被配置为发射承载由接收器30编码的用于
限定视频信号的比特流的信号。
[0066]
处理器304,并且特别是为了本公开的利益,gpu 302能够操作以在接收器的操作中执行计算机程序。在这样做时,诉诸于由大容量存储设备308提供的数据存储设施,该大容量存储设备308被实现为提供大规模数据存储(尽管是在相对缓慢的访问基础上),并且在实践中将存储计算机程序且在当前背景下将存储视频呈现数据用以准备执行接收处理。
[0067]
只读存储器(rom)310被预配置有被设计为提供接收器30的核心功能的可执行程序,并且随机存取存储器312被提供以用于在寻求执行计算机程序的过程中快速访问并存储数据及程序指令。
[0068]
现在将参考图6来描述接收器30的功能。图6示出了由在接收器20上实现的解码器借助于可执行指令对比特流(其是是在接收器30处接收的并且包括可以从中导出视频呈现的结构化信息)执行的处理管道,包括通过发送器20的编码器功能编码出的帧的重构。
[0069]
图6中所示的解码处理旨在使在编码器处执行的处理逆转。读者将会明白,这并不意味着解码处理与编码处理完全相反。
[0070]
接收到的比特流包括一系列已编码的信息元素,每个元素与块相关。在熵解码模块330中对块信息元素进行解码,以获得计算当前块的预测所需的系数和信息的块。系数块通常在去量化模块332中被去量化,并且通常通过变换模块334被逆变换到空间域,除非用信号向解码器通知变换跳过。
[0071]
如上所述,读者将认识到,只有在发送器处分别采用了熵编码、量化和变换时,才需要在接收器处采用熵解码、去量化和逆变换。
[0072]
预测模块336如前所述地根据来自当前帧或先前帧的先前已解码的样本并使用从比特流中解码出的信息来生成预测信号。然后,在块重构模块338中,根据已解码的残差信号和计算出的预测块来导出原始图片块的重构。在实施例中,预测模块336将被配置为响应于比特流上的信息,用信号通知使用帧内预测,并且如果存在这样的信息,则从比特流中读取使解码器能够确定已采用了哪种帧内预测模式的这种信息以及在重构块信息样本时因此而应该采用哪种预测技术。
[0073]
通过解码功能对连续接收到的块信息元素的重复操作,可以将图片块重构为帧,然后可以将这些帧组装起来以产生用于回放的视频呈现。
[0074]
图7示出了示例性的解码器算法,它是对前面描述的编码器算法的补充。该算法涉及使用神经网络实现的色度预测模式——如果该实施方式也允许实现其它的色度预测模式(例如当前在vvc中定义的模式),那么其也可以用信号通知给解码器。
[0075]
如前所述,接收器30的解码器功能从比特流中提取由发送器20的编码器设施编码出的用于定义块信息和伴随的配置信息的一系列块信息元素。
[0076]
对要被解码的帧中的每个已编码的块执行下面的处理。
[0077]
预测模块332被配置为对所输入的已编码的亮度数据和已编码的色度数据进行处理,以产生随后可以用于如上所述的进一步处理的重构的亮度和色度样本数据。
[0078]
现在将参考图7来描述预测模块332的结构和功能。
[0079]
一般而言,预测模块332包括神经网络架构,该神经网络架构包含注意力模块350,该注意力模块350用于控制每个参考相邻样本对计算针对每个样本位置的预测值的贡献,从而确保在计算预测值时考虑到空间信息。预测模块332具有三个网络分支,该三个网络分
支被组合以产生预测样本。如所示,第一个分支和第二个分支被并行地实现,用以从可用的已重构样本(包括已经重构的亮度块以及已经重构的相邻的亮度和色度参考样本)中提取特征。第一个分支(被称为交叉分量边界分支)旨在使用当前块的左侧和上方的扩展参考阵列来从相邻的已重构样本中提取交叉分量信息。第二个分支(被称为亮度卷积分支)应用卷积操作来遍及并置的亮度块而提取空间图案。注意力模块融合由第一个分支和第二个分支输出的特征。
[0080]
注意力模块350的输出最终被馈送到第三个网络分支,用以产生作为结果的cb和cr色度输出预测值。
[0081]
在解码器处使用与编码器处的注意力模块性能方法相同的注意力模块性能方法。将预期,解码器处的注意力模块已按照与编码器处的方式相同的方式进行训练,用以复制在编码器处作出的帧内预测决策。这确保了解码器处色度数据的重构。
[0082]
应当理解,本发明不限于上述实施例,并且可以在不脱离本文所描述的构思的情况下进行各种修改和改进。除非在相互排斥的情况下,否则任何特征可单独使用或者与任何其它特征组合使用,并且本公开扩展并包括本文所描述的一个或多个特征的所有组合和子组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1