一种半监督时间序列异常检测方法及系统
本发明涉及异常检测技术领域,特别是涉及一种半监督时间序列异常检测方法及系统。
背景技术:
随着科技时代的发展,数据量呈爆炸式增长,在这些数据中,时间序列类型的数据的占比非常大。其中,时间序列类型的数据最常见的就是网络流量,它是指访问在线网站的人进行发送和接收的数据量,网络流量异常表示时间序列流量的异常变化,其中存在的异常数据可能会造成严重后果,快速准确地进行检测对于复杂计算机网络系统的高效运行至关重要。
目前,传统的方法存在着一定的缺陷,例如基于规则处理的方法,这种方法第一步是要获取规则,第二步是判断行为是否和异常规则相似,但是它受限于专家知识,规则库可能不完善,并且规则库需要经常更新,否则无法发现新的异常种类;基于统计学的方法是需要假设数据服从某种分布,然后利用数据去进行参数估计,但是它对假设依赖比较严重;近些年,机器学习相关算法表现出强大的表示能力,但由于数据缺标签,同时异常数据缺少的原因,大多数无监督和有监督的传统算法进行异常检测产生效果不佳的问题。
近些年,自编码器在时间序列的研究领域有广泛的应用,它是一种利用反向传播算法使得输出值等于输入值的神经网络,先将输入压缩成潜在空间表征,然后通过这种表征来解压重构输出,其中数据的压缩和解压缩函数是数据相关的、有损的、从样本中自动学习的。一般可以通过将重构的样本与原始样本做运算得到重构误差,再将重构误差与预先定义的阈值进行比较,从而判断该样本是否为异常样本,但最佳阈值很难选定。
技术实现要素:
本发明的目的是提供一种半监督时间序列异常检测方法及系统,以在不需要选定最佳阈值的同时提高异常检测的准确性。
为实现上述目的,本发明提供了如下方案:
一种半监督时间序列异常检测方法,所述方法包括:
获取网站服务器监测的流量的时间序列数据集;所述流量的时间序列数据集包括标记的正常流量数据、标记的异常流量数据、未标记的正常流量数据和未标记的异常流量数据;
在所述流量的时间序列数据集中选取正常标记流量数据集和未标记流量数据集;所述正常标记流量数据集由标记的正常流量数据组成;所述未标记流量数据集包括未标记的正常流量数据和未标记的异常流量数据;
构建基于长短期记忆网络的自编码器模型;所述自编码器模型包括一个编码器、一个正常流量数据解码器和一个异常流量数据解码器;
利用所述正常标记流量数据集和所述未标记流量数据集对所述自编码器模型进行训练,获得训练好的自编码器模型;
从网站服务器获取待检测的流量数据;
将待检测的流量数据输入所述训练好的自编码器模型,若所述待检测的流量数据经过正常流量数据解码器的重构误差小于经过异常流量数据解码器的重构误差,则将所述待检测的流量数据标记为正常流量数据;若所述待检测的流量数据经过正常流量数据解码器的重构误差大于经过异常流量数据解码器的重构误差,则将所述待检测的流量数据标记为异常流量数据。
进一步地,所述正常标记流量数据集和所述未标记流量数据集包含的数据的数量相同。
进一步地,在所述流量的时间序列数据集中选取正常标记流量数据集和未标记流量数据集,之后还包括:
采用min-max标准化方法分别对正常标记流量数据集和未标记流量数据集进行归一化处理,获得归一化后的正常标记流量数据集和归一化后的未标记流量数据集;
利用滑动窗口对所述归一化后的未标记流量数据集进行异常流量数据的富集化处理,获得富集化后的未标记流量数据集。
进一步地,利用所述正常标记流量数据集和所述未标记流量数据集对所述自编码器模型进行训练,获得训练好的自编码器模型,具体包括:
利用所述正常标记流量数据集对所述自编码器模型的编码器和正常流量数据解码器进行训练,获得一次训练好的自编码器模型;
利用所述未标记流量数据集对所述一次训练好的自编码器模型的编码器、正常流量数据解码器和异常流量数据解码器进行训练,获得二次训练好的自编码器模型。
进一步地,利用所述未标记流量数据集对所述一次训练好的自编码器模型的编码器、正常流量数据解码器和异常流量数据解码器进行训练,具体包括:
将所述未标记流量数据集的每个未标记流量数据分别输入所述一次训练好的自编码器模型的正常流量数据解码器和异常流量数据解码器,获得每个未标记流量数据经过正常流量数据解码器的第一重构误差和经过异常流量数据解码器的第二重构误差;
比较第一重构误差和第二重构误差的大小,获得比较结果;
若所述比较结果表示第一重构误差小于第二重构误差,则将未标记流量数据识别为正常流量数据,并利用识别的正常流量数据对所述一次训练好的自编码器模型的编码器和正常流量数据解码器进行训练;
若所述比较结果表示第一重构误差大于第二重构误差,则将未标记流量数据识别为异常流量数据,并利用识别的异常流量数据对所述一次训练好的自编码器模型的编码器和异常流量数据解码器进行训练。
理论上不存在第一重构误差等于第二重构误差的情况。
进一步地,对所述自编码器模型进行训练时,选择relu函数作为激活函数,选择loss=loss0+(1-yj)loss1+yjloss2作为目标函数;
其中,loss表示目标函数,loss0表示正常标记流量数据集的数据经过正常流量数据解码器的重构误差,loss1表示未标记流量数据集经过正常流量数据解码器的重构误差,loss2表示未标记流量数据集经过异常流量数据解码器的重构误差,yj表示分配给未标记流量数据集中第j个未标记流量数据的标签,
进一步地,利用所述正常标记流量数据集和所述未标记流量数据集对所述自编码器模型进行训练,获得训练好的自编码器模型,之后还包括:
利用adam优化器对所述训练好的自编码器模型进行优化,获得优化后的自编码器模型;
在所述流量的时间序列数据集中选取测试流量数据集;
利用所述测试流量数据集对所述优化后的自编码器模型进行测试。
一种半监督时间序列异常检测系统,所述系统包括:
时间序列数据集获取模块,用于获取网站服务器监测的流量的时间序列数据集;所述流量的时间序列数据集包括标记的正常流量数据、标记的异常流量数据、未标记的正常流量数据和未标记的异常流量数据;
正常标记流量数据集和未标记流量数据集选取模块,用于在所述流量的时间序列数据集中选取正常标记流量数据集和未标记流量数据集;所述正常标记流量数据集由标记的正常流量数据组成;所述未标记流量数据集包括未标记的正常流量数据和未标记的异常流量数据;
自编码器模型构建模块,用于构建基于长短期记忆网络的自编码器模型;所述自编码器模型包括一个编码器、一个正常流量数据解码器和一个异常流量数据解码器;
训练好的自编码器模型获得模块,用于利用所述正常标记流量数据集和所述未标记流量数据集对所述自编码器模型进行训练,获得训练好的自编码器模型;
待检测的流量数据获取模块,用于从网站服务器获取待检测的流量数据;
标记模块,用于将待检测的流量数据输入所述训练好的自编码器模型,若所述待检测的流量数据经过正常流量数据解码器的重构误差小于经过异常流量数据解码器的重构误差,则将所述待检测的流量数据标记为正常流量数据;若所述待检测的流量数据经过正常流量数据解码器的重构误差大于经过异常流量数据解码器的重构误差,则将所述待检测的流量数据标记为异常流量数据。
进一步地,所述训练好的自编码器模型获得模块,具体包括:
一次训练好的自编码器模型获得子模块,用于利用所述正常标记流量数据集对所述自编码器模型的编码器和正常流量数据解码器进行训练,获得一次训练好的自编码器模型;
二次训练好的自编码器模型获得子模块,用于利用所述未标记流量数据集对所述一次训练好的自编码器模型的编码器、正常流量数据解码器和异常流量数据解码器进行训练,获得二次训练好的自编码器模型。
进一步地,所述二次训练好的自编码器模型获得子模块,具体包括:
第一重构误差和第二重构误差获得单元,用于将所述未标记流量数据集的每个未标记流量数据分别输入所述一次训练好的自编码器模型的正常流量数据解码器和异常流量数据解码器,获得每个未标记流量数据经过正常流量数据解码器的第一重构误差和经过异常流量数据解码器的第二重构误差;
比较结果获得单元,用于比较第一重构误差和第二重构误差的大小,获得比较结果;
正常流量数据解码器训练单元,用于若所述比较结果表示第一重构误差小于第二重构误差,则将未标记流量数据识别为正常流量数据,并利用识别的正常流量数据对所述一次训练好的自编码器模型的编码器和正常流量数据解码器进行训练;
异常流量数据解码器训练单元,用于若所述比较结果表示第一重构误差大于第二重构误差,则将未标记流量数据识别为异常流量数据,并利用识别的异常流量数据对所述一次训练好的自编码器模型的编码器和异常流量数据解码器进行训练。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明提供了一种半监督时间序列异常检测方法,构建基于长短期记忆网络的自编码器模型,自编码器模型包括一个编码器、一个正常流量数据解码器和一个异常流量数据解码器,在流量的时间序列数据集中选取正常标记流量数据集和未标记流量数据集,利用两个训练集对自编码器模型进行训练,不需要提前预定义一个阈值,对于未标记数据,通过比较经过两个解码器的重构误差的大小即可判断是否异常。若所述待检测的流量数据经过正常流量数据解码器的重构误差小于经过异常流量数据解码器的重构误差,则将所述待检测的流量数据标记为正常流量数据;若所述待检测的流量数据经过正常流量数据解码器的重构误差大于经过异常流量数据解码器的重构误差,则将所述待检测的流量数据标记为异常流量数据。本发明避免了最佳阈值选择的困难,并能准确进行异常检测。
本发明还采用滑动窗口对未标记流量数据集进行异常流量数据的富集化处理,解决了异常点稀少的问题,丰富了异常数据,进一步提高了异常检测率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明提供的一种半监督时间序列异常检测方法的流程图;
图2为本发明提供的一种半监督时间序列异常检测方法的原理图;
图3为本发明提供的a1benchmark数据集的训练次数的度量结果图;
图4为本发明提供的kpi数据集的训练次数的度量结果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种半监督时间序列异常检测方法及系统,以在不需要选定最佳阈值的同时提高异常检测的准确性。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
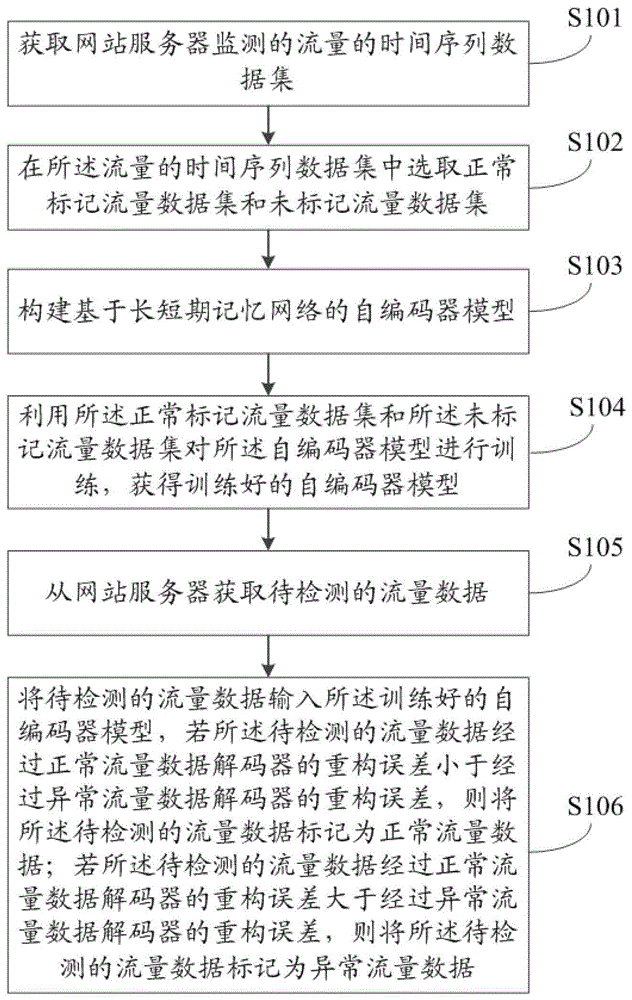
本发明提供了一种半监督时间序列异常检测方法,如图1所示,方法包括:
s101,获取网站服务器监测的流量的时间序列数据集;流量的时间序列数据集包括标记的正常流量数据、标记的异常流量数据、未标记的正常流量数据和未标记的异常流量数据;
s102,在流量的时间序列数据集中选取正常标记流量数据集和未标记流量数据集;正常标记流量数据集由标记的正常流量数据组成;未标记流量数据集包括未标记的正常流量数据和未标记的异常流量数据;
s103,构建基于长短期记忆网络的自编码器模型;自编码器模型包括一个编码器、一个正常流量数据解码器和一个异常流量数据解码器;
s104,利用正常标记流量数据集和未标记流量数据集对自编码器模型进行训练,获得训练好的自编码器模型;
s105,从网站服务器获取待检测的流量数据;
s106,将待检测的流量数据输入训练好的自编码器模型,若待检测的流量数据经过正常流量数据解码器的重构误差小于经过异常流量数据解码器的重构误差,则将待检测的流量数据标记为正常流量数据;若待检测的流量数据经过正常流量数据解码器的重构误差大于经过异常流量数据解码器的重构误差,则将待检测的流量数据标记为异常流量数据。
步骤s102中正常标记流量数据集和未标记流量数据集包含的数据的数量相同。
步骤s102之后还包括:
采用min-max标准化方法分别对正常标记流量数据集和未标记流量数据集进行归一化处理,获得归一化后的正常标记流量数据集和归一化后的未标记流量数据集;
利用滑动窗口对归一化后的未标记流量数据集进行异常流量数据的富集化处理,获得富集化后的未标记流量数据集。
步骤s104,利用正常标记流量数据集和未标记流量数据集对自编码器模型进行训练,获得训练好的自编码器模型,具体包括:
利用正常标记流量数据集对自编码器模型的编码器和正常流量数据解码器进行训练,获得一次训练好的自编码器模型;
利用未标记流量数据集对一次训练好的自编码器模型的编码器、正常流量数据解码器和异常流量数据解码器进行训练,获得二次训练好的自编码器模型。
其中,利用未标记流量数据集对一次训练好的自编码器模型的编码器、正常流量数据解码器和异常流量数据解码器进行训练,具体包括:
将未标记流量数据集的每个未标记流量数据分别输入一次训练好的自编码器模型的正常流量数据解码器和异常流量数据解码器,获得每个未标记流量数据经过正常流量数据解码器的第一重构误差和经过异常流量数据解码器的第二重构误差;
比较第一重构误差和第二重构误差的大小,获得比较结果;
若比较结果表示第一重构误差小于第二重构误差,则将未标记流量数据识别为正常流量数据,并利用识别的正常流量数据对一次训练好的自编码器模型的编码器和正常流量数据解码器进行训练;
若比较结果表示第一重构误差大于第二重构误差,则将未标记流量数据识别为异常流量数据,并利用识别的异常流量数据对一次训练好的自编码器模型的编码器和异常流量数据解码器进行训练。
对自编码器模型进行训练时,选择relu函数作为激活函数,选择loss=loss0+(1-yj)loss1+yjloss2作为目标函数;
其中,loss表示目标函数,loss0表示正常标记流量数据集的数据经过正常流量数据解码器的重构误差,loss1表示未标记流量数据集经过正常流量数据解码器的重构误差,loss2表示未标记流量数据集经过异常流量数据解码器的重构误差,yj表示分配给未标记流量数据集中第j个未标记流量数据的标签,
步骤s104,之后还包括:
利用adam优化器对训练好的自编码器模型进行优化,获得优化后的自编码器模型;
在流量的时间序列数据集中选取测试流量数据集;
利用测试流量数据集对优化后的自编码器模型进行测试。
本发明公开的一种基于新型自编码器的半监督时间序列异常检测方法。目前,时间序列的异常检测在深度学习领域开展了广泛的工作,大多传统的方法需要预先定义阈值,但很难找到最佳阈值,同时有监督算法需要大量带标记数据,而在实际应用中,标记数据稀缺。所以对于只有部分标记的时间序列数据常见场景,我们使用具有拉拢机制的半监督方法来实现异常检测,本发明是一种新颖的自编码器框架,不同于传统自编码器,它是由一个编码器,两个解码器(d1和d2,d1被称为正常数据解码器,d2被称为异常数据解码器)组成,并且检测判定的过程不需要定义阈值。
本发明的自编码器由一个编码器两个解码器(正常数据解码器d1和异常解码器d2)组成,同时使用长短时记忆网络(longshorttermmemorynetwork,lstm)作为构造该新颖自编码器的基础神经网络结构,因为lstm能够捕捉时间序列的连续性。在训练过程中,输入的是正常数据和未标记的数据。训练过程中,主要是为得到一个编码器两个解码器的相关参数,当标签为0表示正常数据的时候,将其丢给解码器1进行解码,当标签为空,即未标记的时候,将其丢给解码器1和解码器2这两个解码器进行解码,对于未标记数据,通过比较经过两个解码器的损失值的大小即可判断是否异常。多个轮回的训练以后,该模型有了稳定的参数,再进行数据集的测试,查看效果。在这个过程中,我们充分利用了标记数据和未标记数据,同时,避免阈值判定异常的方法而采用拉拢机制进行异常检测。
首先划分数据集为三个子数据集,用于训练的正常数据集dn1、未标记数据集du1及用于测试用的dt1,然后对所有数据进行归一化及滑窗富集化处理,最后使用dn1、du1对构造的模型进行训练,d1用正常数据dn1进行训练,未标记数据du1输送给d1和d2,通过比较经过两个解码器的重构误差大小进行选择解码器,从而判定是否异常。本发明中的方法设计了一种新的判定方法,称其为“拉拢机制”,对于未标记数据,两个解码器都希望得到与未标记数据有更小的误差,从而将其“拉拢”成“自己人”,所以两个解码器通过竞争的方式去拉拢该未标记数据,未标记数据的解码结果与哪个解码器的距离越近,说明与哪个解码器有更小的误差,就更能被该解码器拉拢成功,从而根据解码器的功能来判定未标记数据是正常还是异常,避免最佳阈值选择的难点,经验证,该模型具有良好的检测判别性能。
本发明的具体实现过程如下:
由于互联网技术的发展和计算机的普及,计算机网络的重要性日益增加。基于复杂网络和物联网技术的大众基础设施对社会和经济产生了重大影响,通过网络服务器交换大量信息,并提供各种服务。然而,随着互联网服务的增加,通过网络的恶意攻击逐渐变得更加先进和多样化,各种网络攻击会对web服务运行造成严重破坏,导致社会和经济损失。主动管理和预防威胁网络基础设施的各种攻击至关重要,web服务器中流量异常的检测是时间序列异常检测中的研究重点。
本发明就着web服务器中流量异常的检测展开具体研究,使用yahoowebscopes5数据集作为本发明的数据集,同时,为了验证本发明具有一定的普适性,紧接着使用由aiops数据竞赛发布的kpi(keyperformanceindicators,主要性能指标)数据集进行进一步证明,它指的是对服务、系统等运维对象的监控指标(如延迟、吞吐量等)。其存储的形式是按其发生的时间先后顺序排列而成的数列,也就是我们通常所说的时间序列,其为时间序列数据集。
步骤1将用于实验的yahoowebscopes5数据集划分为三个子数据集,获取待训练的正常数据集dn1、未标记的数据集du1,使得这两个训练子数据集的大小相等,满足|dn1|=|du1|的关系,以及用来测试的数据集dt1。同样的,与kpi(keyperformanceindicators)数据集也做相同的处理,从而来作为进一步验证该模型具有一定的普适性。
对于本发明设计方法的新颖性,不同于其他算法只有一个训练集,这里的两个训练集用于后期训练模型中的两个解码器,并且根据模型的特点,两个训练数据集要相等才能获得更好的判定结果。
步骤2对步骤1中的三个数据集进行数据归一化处理,时间序列的数据集是一段一段被收集,在数据集中通常由多条数据表示,由于每条数据值的分布范围有较大区别,正常点和异常点的分布差别大,不能公平精确地去比较分析异常数据的特点,而归一化处理能够解决该问题,使得每个数据点的取值在[0,1]范围之间。
在这里,使用min-max标准化对每条数据所有点的取值范围进行归一化处理,转换函数如下所示:
其中,x是某条时间序列中某个点的原始值,xmax、xmin分别是该条时间序列中最大值和最小值,x'是原始值被归一化后的值。由步骤1的数据集经步骤2处理后,将其更新为数据集dn2、du2、dt2。
步骤3经步骤2就将所有的数据值转换成符合训练要求的值,由于异常数据的稀缺,训练过程需要一定数量的异常点来对解码器进行训练,而稀少的异常点不足以支撑运转训练所设计的模型,为了解决这一问题,使用滑动窗口来进行富集化,同时滑窗的使用能够提高模型对时序特征的学习率。
在这里,使用步长为ts、滑窗大小为tw的窗口大小对数据进行处理,将较长的时间序列x划分成多个子序列,丰富了异常点的个数:
x={xi,i=1,2,3,...,m},
其中,
在实验过程中,根据经验tw={50×i,i=1,2,3,......,10},ts={j,j=1,2,3,......,10},使用不同的tw和ts来捕获学习时间序列的不同状态,最终选择最佳tw、ts。
经步骤3对步骤2的数据集进行处理后,再次更新数据集,获得最终用于训练的训练集dn、du和测试集dt。
步骤4构建本发明设计的模型。该模型有三个模块,分别是编码器网络enc,正常数据解码器网络d1,异常数据解码器网络d2。编码器和解码器均使用lstm网络作为基本网络,lstm可捕获数据的时序性,从而更高效提取时间序列样本的特征,并且选择relu函数作为激活函数来优化中间层输出的分布,进而提高网络的训练速度,两个解码器网络结构相同且与编码器结构绝对对称,但是各个模块的参数是独立训练得到的。
步骤5对模型进行训练,传入模型的数据只能被一个解码器解码。将正常数据集dn经过编码器传到解码器d1中,将未标记数据集du经过编码器传到两个解码器d1和d2中,但由于数据不是正常就是异常,只能被一个解码器解码,传入的数据通过比较经过两个解码器后的重构误差的大小进行判定,经过反复的迭代训练,若经过d1重构误差小于d2的重构误差,则可判断该数据和正常数据有较为相似的特征分布,该数据为正常数据,否则可将该未标记数据分类至异常数据,将其传送至d2用于d2的训练,在轮回的训练中,未标记的数据通过一种拉拢的机制来训练网络各个模块的参数。
步骤6为了给步骤5中的未标记数据分配正确的标签,在训练的过程中需要选择或定义一个最佳的损失函数作为目标函数,从而来最小化重构样本和原始样本的误差,用于更新网络的参数。在经过反复尝试以后,选择如下函数作为目标函数:
其中
其中,1代表数据标签为异常,0代表数据标签为正常,loss0是标记为正常的数据
其中,enc()表示编码结果,dec1()表示输入进d1后的解码结果,dec2()表示输入进d2后的解码结果。当loss1>loss2,表示未标记数据在经过异常解码器d2的损失值更小,重构后的样本与异常样本的分布更为相似,所以有更大概率为异常的可能,故标记为异常,值为1,整个模型的总的损失函数为loss=loss0+loss2;当loss1<loss2,表示未标记数据经过正常解码器d1的损失值更小,重构后的样本与正常样本的分布更接近,所以很可能为正常数据,故标记为正常,整个模型总的损失函数为loss=loss0+loss1。
在这个过程中,为了更大程度区分开正常样本和异常样本,这几个损失值均采用均方值作为重建误差,因为它对异常更加敏感,具体表示如下:
步骤7模型的优化,选择adam优化器进行优化。
步骤8测试时,如图2所示,将测试集dt的数据传入网络,所有数据均经过两个解码器,并根据经过两个解码器后重构误差的大小来判定是否异常。在异常检测过程中,将召回率(recall,r)、综合评价指标f1分数(f1-score)作为主要评测指标,同时为了更全面的评价模型的性能,将准确率(accuracy,acc)和精确度(precision,pre)作为辅助评判指标。
其中,召回率、f1-score、准确率、精确度分别表示如下:
召回率(recall):成功检测出的异常数据占实际异常数据总数的比例;
精确度(precision):成功检测出的异常数据占检测为异常数据的比例;
f1_score:精确度和召回率两个指标之间的平衡。f1_score越高,模型就越好;
准确率(accuracy):在检测的所有数据样本中,所有判定结果与真实结果相匹配的占比。
在本发明中,我们基于lstm网络的新颖自编码器的方法在异常检测上获得较大的提升,且判定过程无需阈值。
首先使用时序数据集中的正常数据和未标记的数据来训练构造的模型,由于数据分布区间差异大及异常点稀少的特点,要对数据进行归一化和滑动窗口富集化的处理,通过归一化的数据更能够体现出异常点的分布特征,为模型的训练及模型检测性能的提高提供了帮助。
在检测阶段,不同于传统方法将误差与预定义的阈值进行比较判断,本发明采用的是一种无阈值的方法,避免了最佳阈值选择的困难。同时,滑动窗口的富集化也提高了异常检测率。经实验证明,同传统的异常检测判定方法相比,本发明的方法在召回率、精确率、f1_score和准确率等评价指标上有一定的性能提升。
以下详细地描述本发明在真实数据集上的测试效果,我们使用的yahoowebscopes5数据集、kpi数据集是用于时序异常检测的公开数据集。对于yahoowebscopes5数据集,我们选取其中的a1benchmark类对该方法进行验证,针对这两个数据集,将该方法与其他的故障检测方法进行比较。
表1选择的时间序列数据集
我们依次用实验找到迭代的最佳次数,在此基础上,证明本发明中使用滑动窗口进行富集化是有利于提高异常检测效率的,同时验证了本发明提出的新颖自编码器模型在时间序列的异常检测上是有效的。
训练次数对模型的性能起着关键性作用,训练次数大可能造成模型的过拟合,训练次数小使得模型不能充分学习数据的特征分布,为找到最佳训练次数,做了一组比对实验。图3和图4结果表明,对于a1benchmark数据集的最佳epoch=150,kpi数据集的最佳epoch=100。图3和图4的横坐标epoch表示训练次数,纵坐标mecrics表示度量。
在找到最佳训练次数后,在本发明中,滑动窗口是一大亮点,我们设计实验继续评估滑窗的富集化对模型的异常检测效果,实验结果如下:
表2有无滑动窗口的对比实验
表2的结果表明,当使用滑动窗口时,主要评价指标召回率(recall)、f1分数均得到较大幅度提升,其中召回率均超过94%,f1分数也接近90%,这是因为滑动窗口的使用在丰富数据集的同时能够帮助lstm捕获时间依赖性。
最后,本发明最大的创新点在于,其不同于只有一个解码器的传统自编码器,我们的模型使用了两个解码器,同时使用具有拉拢机制来进行训练和检测,异常检测的过程无需阈值,为验证创新的有效性,将我们的方法与传统自编码器比较,为了保证比较的公平公正,基础网络均采用lstm网络。我们将使用标记的正常数据训练的自编码器模型称之为normal_ae,使用未标记数据训练的自编码器称之为unlabel_ae,将其与新型自编码器进行实验比对。
表3基于lstm不同自编码器对比实验
从表3的结果中可以看出,我们的方法相对于传统自编码器有更强大的异常检测性能。特别地,对于a1benchmark数据集我们的召回率(recall)和f1分数较传统自编码器的检测率提高了50%。
综合以上,通过多个实验循序渐进、一步步地去充分验证模型的检测性能,由以上实验结果可见,本发明所提出的解决方法是新颖、可靠、有效的。
本发明还提供了一种半监督时间序列异常检测系统,系统包括:
时间序列数据集获取模块,用于获取网站服务器监测的流量的时间序列数据集;流量的时间序列数据集包括标记的正常流量数据、标记的异常流量数据、未标记的正常流量数据和未标记的异常流量数据;
正常标记流量数据集和未标记流量数据集选取模块,用于在流量的时间序列数据集中选取正常标记流量数据集和未标记流量数据集;正常标记流量数据集由标记的正常流量数据组成;未标记流量数据集包括未标记的正常流量数据和未标记的异常流量数据;
自编码器模型构建模块,用于构建基于长短期记忆网络的自编码器模型;自编码器模型包括一个编码器、一个正常流量数据解码器和一个异常流量数据解码器;
训练好的自编码器模型获得模块,用于利用正常标记流量数据集和未标记流量数据集对自编码器模型进行训练,获得训练好的自编码器模型;
待检测的流量数据获取模块,用于从网站服务器获取待检测的流量数据;
标记模块,用于将待检测的流量数据输入训练好的自编码器模型,若待检测的流量数据经过正常流量数据解码器的重构误差小于经过异常流量数据解码器的重构误差,则将待检测的流量数据标记为正常流量数据;若待检测的流量数据经过正常流量数据解码器的重构误差大于经过异常流量数据解码器的重构误差,则将待检测的流量数据标记为异常流量数据。
训练好的自编码器模型获得模块,具体包括:
一次训练好的自编码器模型获得子模块,用于利用正常标记流量数据集对自编码器模型的编码器和正常流量数据解码器进行训练,获得一次训练好的自编码器模型;
二次训练好的自编码器模型获得子模块,用于利用未标记流量数据集对一次训练好的自编码器模型的编码器、正常流量数据解码器和异常流量数据解码器进行训练,获得二次训练好的自编码器模型。
二次训练好的自编码器模型获得子模块,具体包括:
第一重构误差和第二重构误差获得单元,用于将未标记流量数据集的每个未标记流量数据分别输入一次训练好的自编码器模型的正常流量数据解码器和异常流量数据解码器,获得每个未标记流量数据经过正常流量数据解码器的第一重构误差和经过异常流量数据解码器的第二重构误差;
比较结果获得单元,用于比较第一重构误差和第二重构误差的大小,获得比较结果;
正常流量数据解码器训练单元,用于若比较结果表示第一重构误差小于第二重构误差,则将未标记流量数据识别为正常流量数据,并利用识别的正常流量数据对一次训练好的自编码器模型的编码器和正常流量数据解码器进行训练;
异常流量数据解码器训练单元,用于若比较结果表示第一重构误差大于第二重构误差,则将未标记流量数据识别为异常流量数据,并利用识别的异常流量数据对一次训练好的自编码器模型的编码器和异常流量数据解码器进行训练。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!