一种非公开工业通信协议的字段语义分析方法
本发明涉及工业控制系统非公开协议逆向分析技术,特别涉及一种非公开工业通信协议的字段语义分析方法。
背景技术:
伴随工业系统的网络化和智能化进程,工业控制系统近年来得到快速发展,原本各自独立的工业控制模块通过网络进行互联互通,设备间产生了网络通信协议的需求。相比于互联网常用的文本协议,工业控制系统的网络通信协议具有非公开的特性,协议具体字段语义不明。而工业控制系统的通信协议解析是许多应用的基础所在,高准确率的协议语义解析能为工业控制系统提供更可靠的深度包解析、入侵检测、二次协议开发等应用。
现阶段对于工业控制系统非公开协议的解析手段仍然无法满足应用需求,即使通过静态分析或者动态分析的方法知晓了协议的字段分割,在缺乏语义信息的情况下也难以设计针对性的应用,因此针对非公开工业通信协议的字段语义分析方法是目前工业控制系统所迫切需要的。
技术实现要素:
本发明的目的在于针对现有的非公开工业通信协议语义解析能力不足的问题,提出一种在已知工业通信协议字段分割的前提下,利用网络流分析和动态污点分析的工业通信协议的字段语义分析方法。
本发明的目的通过以下技术方案实现:一种非公开工业通信协议的字段语义分析方法,该方法包括以下步骤:
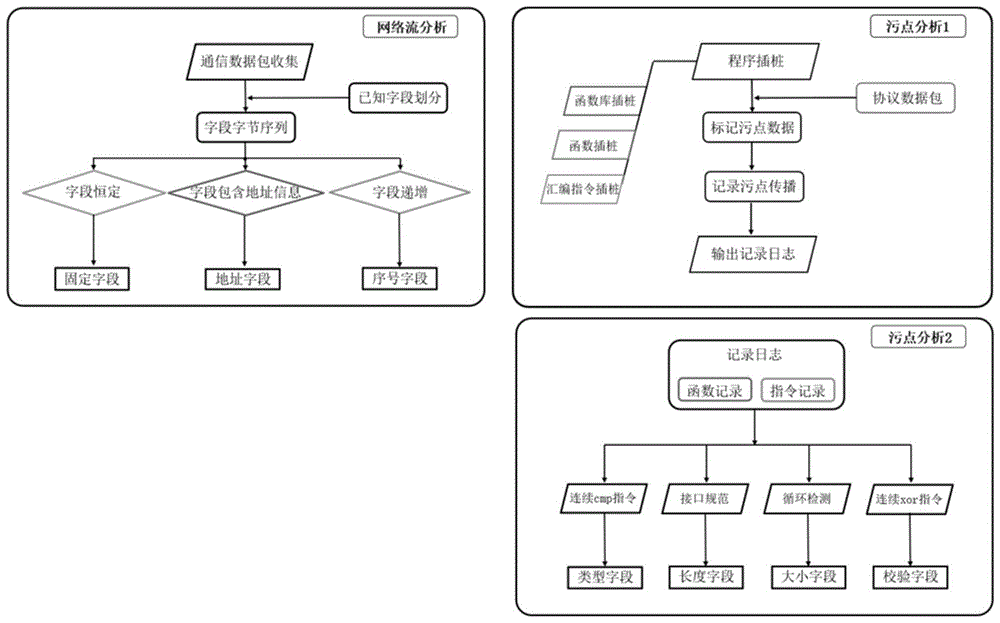
步骤1:对于已获得字段边界的工业通信协议进行网络流分析。收集网络拓扑中数据包,对于网络流数据中不变字段识别为固定字段;对网络流数据统计与网络地址/端口字节数值相同字节数,超过预设值即识别为地址字段;对于在报文序列中按序递增的字段识别为序号字段。
步骤2:对于工业通信协议的可执行程序进行污点分析。在汇编指令和/或函数处进行插桩,将网络接收数据标记为污点数据,监控污点数据在可执行程序运行过程中的传播过程,将所有涉及污点数据传播的汇编指令和/或函数上下文信息记录至日志文件中。
步骤3:根据生成的日志文件判别各字段含义。统计日志中比较指令分布,对于多次出现的比较指令对应的函数所对应字段判定为类型字段;对于网络流接收函数中长度参量的字段判定为长度字段;对于可执行程序中循环处理的计数变量对应字段判定为大小字段;根据日志中算术指令分布,识别函数中被算术指令处理的报文字节,将所有识别出的报文字节判定为校验字段。
进一步地,所述步骤1中,对收集的网络拓扑中数据包依次进行以下预处理:去除延时、重复数据包;去除网络协议层中非应用层协议数据;对于剩余数据,通过needlemanwunsch算法将可变长字段进行自动对齐。
进一步地,根据协议功能的相似性和对于常用非公开工业通信协议字段的分析,协议中典型的字段类型可以总结如下7类:固定字段,表示协议特征信息且其值在数据流传输过程中恒定,包括标识符、前导码、版本号等;地址字段,表示协议中通信双方的网络地址和/或网络端口号;序号字段,表示协议会话中报文的序号,用于标志协议报文的前后顺序关系;类型字段,表示协议报文的类型,标志协议的具体功能;长度字段,表示协议报文的总长度或者后续字段长度;大小字段,表示发送或者接收报文中数据量;校验字段,常用crc校验码,用于验证协议报文的完整性。
进一步地,所述步骤2中,利用pin工具对于工业通信协议二进制程序进行汇编指令和/或函数粒度的插桩,在函数粒度上将内存拷贝函数利用pin接口rtn_insertcall在函数进入和退出处进行插桩,在指令粒度上将具备数据读写能力的汇编指令利用ins_insertcall在指令运行时进行插桩。
进一步地,所述步骤2中,所述函数上下文信息包括函数对应内存起止位置、线程号、可能的函数名、对应传入参数等。
进一步地,所述步骤2中,所述指令上下文信息仅考虑污点数据传播相关指令,由污点传播的数据结构表示;
所述污点传播的数据结构设计为存储具体数据与协议信息的哈希表,以污点数据的内存地址或寄存器名称为键,以记录污点数据与协议对应字段具体信息的元组为值;元组具体记录对应数据是否被标记为污点、对应协议包字段、污点数据长度、标记时指令对应内存位置和具体指令等信息;污点初始化时对应数据结构也进行初始化,并根据污点数据传播规则在程序执行过程中记录传播路径上下文信息。
所述污点数据传播规则设计为:将二进制程序中有关通信协议数据传递的所有函数与汇编指令视作可能的污点传播手段,其中函数部分包括网络数据包接收函数、内存拷贝函数、字符串拷贝函数,对应污点数据拷贝;指令部分包括数据传送指令、算术指令等,不同汇编指令对应相应污点数据处理,数据传送类指令对应污点数据拷贝,部分算术指令对应污点清除与部分内容保留。
进一步地,所述步骤3中,实际的协议处理程序通常采用switch语句结构来判断类型字段的值,经过编译之后呈现为汇编代码中聚集的cmp指令;统计分析日志中cmp指令的分布,若单个函数中多次出现连续的cmp指令,并且这些指令的操作对象为同一字段,则将该字段判定为协议的类型字段。
进一步地,所述步骤3中,依据函数接口规范和指令架构的abi规范,判定长度参数位置和相应寄存器,对应污点数据传输相关的字段即为长度字段。
进一步地,所述步骤3中,协议处理程序中,大小字段通常在循环语句中进行处理和使用,依据日志中cmp指令的记录进行循环检测,记录每个基本块的起始地址和终止地址,若函数运行过程中基本块的地址重复出现,则认为基本块属于循环体的一部分,基本块所在函数对应的协议字段识别为大小字段。
进一步地,所述步骤3中,根据日志中xor指令的分布,将函数中连续被xor指令处理的报文字段判定为校验字段。
与现有技术相比,本发明具有以下优势:
1.本发明综合使用了网络流分析和程序的动态污点分析,兼顾了分析效率和分析准确性;
2.本发明在使用过程中不需要程序源码,仅需通信双方通信程序可执行,对于程序的正常功能没有影响,仅被动地记录其运行过程,没有侵入性;
3.本发明在设计语义分析时考虑了常见的七种协议语义,为后续的功能开发提供了大量可用信息,具有良好的可用性;
4.本发明针对工业控制系统的非公开协议具有广泛适用性。
附图说明
图1是本发明方法的整体架构图;
图2是以modbus/tcp协议为例的协议语义分析结果图;
图3是以modbus/tcp协议为例的函数日志示意图;
图4是以modbus/tcp协议为例的指令日志示意图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步详细说明。
本发明实施例提供一种非公开工业通信协议的字段语义分析方法,整体架构如图1所示,该方法具体包括以下步骤:
步骤1:对于已获得字段边界的工业通信协议进行网络流分析。收集网络拓扑中数据包,对于网络流数据中不变字段识别为固定字段;对网络流数据统计与网络地址/端口字节数值相同字节数,超过预设值即识别为地址字段;对于在报文序列中按序递增的字段识别为序号字段。
步骤2:对于工业通信协议的可执行程序进行污点分析。在汇编指令和/或函数处进行插桩,将网络接收数据标记为污点数据,监控污点数据在可执行程序运行过程中的传播过程,将所有涉及污点数据传播的汇编指令和/或函数上下文信息记录至日志文件中。
步骤3:根据生成的日志文件判别各字段含义。统计日志中比较指令分布,对于多次出现的比较指令对应的函数所对应字段判定为类型字段;对于网络流接收函数中长度参量的字段判定为长度字段;对于可执行程序中循环处理的计数变量对应字段判定为大小字段;根据日志中算术指令分布,识别函数中被算术指令处理的报文字节,将所有识别出的报文字节判定为校验字段。
在modbus/tcp协议解析上对本发明实施做详细解释。modbus协议目前已成为工业通信协议中的业界标准,诸多工业通信协议在modbus协议的基础上进行实现,主要字段有事务标识符、协议标识符、长度、单元标识符、功能码和变长数据区域等。在本发明实施例中,所选modbus/tcp协议为某厂商在自身业务特点上进行的改造实现。
所述步骤1中,在通信协议所部署的网络拓扑中收集网络数据包,并进行预处理。具体预处理步骤包括:通过wireshark识别网络中延时、重复数据包,去除此部分数据包;通过发送接收方网络地址对于数据包进行分类,在每一类中将除应用层外数据全部清除;将应用层数据(具体表示为字节流)与网络地址、数据长度等元信息存储至元组中;利用needlemanwunsch算法将可变长字段进行自动对齐。
所述步骤1中,在每个根据发送接收方网络地址进行分类的子类中,对所有字节流逐字节位置统计整个子类中在该位置的独特字节数,为每个位置维持一个集合,最终仅含有一个元素的集合所对应位置即识别为固定字段。将发送接收方网络地址对应的点分十进制ascii码表示和端口对应十六进制表示作为查询子串,在字节流中查询其位置(所对应字节相同数超过预设值即认为查询成功),其结果识别为地址字段。在除固定字段的其他位置,逐字节根据数据包收集顺序相邻向前求差,若特定字节位置结果始终为正且结果基本恒定(考虑网络丢包,认为求差结果种类少于总子类数据包数目的1%为结果基本恒定),即识别为序号字段。
所述步骤2中,使用pin接口rtn_insertcall对于工业通信协议二进制程序在函数的进入和退出处进行插桩,由于大量函数并非为通信协议实现程序的主体,而是实现程序的库函数调用,因此使用img_insertcall对于函数库进行插桩,保证后续日志记录仅记录通信协议实现程序主体内函数,提高后续分析效率。由于部分函数为库函数调用函数,且库函数本身在编译时进行了优化,pin可能无法准确判断其函数的进入和退出点,将库函数中与内存拷贝和网络接收相关的函数进行钩子函数包装,为钩子函数利用rtn_insertcall进行插桩。使用pin接口对于工业通信协议二进制程序进行指令粒度插桩,同样依据img_insertcall过滤掉通信协议实现程序主体外的所有汇编指令。
所述步骤2中,污点分析标记污点源为网络接收函数接收到的字节流数据,通过函数和指令中插桩记录污点是否流经相应程序位置,并记录其上下文信息。其中,函数上下文信息包括函数对应内存起止位置、线程号、可能的函数名、对应传入参数等,指令上下文信息存储至特定污点传播数据结构中,且仅筛选具有污点数据传播能力的汇编指令。
具体的,指令对应的污点传播的数据结构设计为存储具体数据与协议信息的哈希表,以污点数据的位置信息为键,以记录污点数据和协议对应字段的具体信息元组为值。对于操作数为直接内存位置或间接内存访问寄存器的汇编指令,位置信息为对应的具体内存位置,对于操作数为寄存器的汇编指令,位置信息为寄存器的名称。具体信息元组包括当前指令位置与污点数据相关的元信息,如数据是否被标记为污点、对应协议包字段、污点数据长度、标记时指令对应内存位置和具体指令。在进行污点传播的初始化时,将其对应数据结构也进行初始化,并根据污点数据传播的执行在数据结构中记录上下文信息。
所述步骤2中,污点分析时设计的具体污点数据传播规则为:将接收modbus/tcp协议数据包的网络接收函数记为污点传播初始点,对应字节流数据为污点源,将所有有关通信协议数据传递的函数/指令视为可能的污点传播手段,在具有污点传播能力的函数/指令上依据函数/指令功能记录其对于污点数据的具体处理。其中函数部分包括网络数据包接收函数(如recv/recvfrom/read等)、内存拷贝函数(如memcpy等)、字符串拷贝函数(如strcpy等);指令部分包括数据传送类指令和算术指令。具体处理根据具体函数/指令的功能包括对于污点数据的复制、清除和部分内容保留。污点传播指令过程中,将污点传播的数据结构内容记录至日志中以供后续分析,图3是以modbus/tcp协议为例的函数日志示意图,图4是以modbus/tcp协议为例的指令日志示意图。
所述步骤3中,在获得的modbus/tcp协议的分析日志基础上进行协议字段语义的识别。由于实际的工业通信协议使用类型字段标志该数据包的具体的功能类型,在源程序中对应的类型字段判定通常使用分支语句结构,经过编译之后呈现为函数中聚集的cmp指令。对于日志中所有函数中的cmp指令进行统计,如果单一函数中连续出现了3次以上cmp指令,且cmp指令操作对象为协议的相同字段,即将该字段判定为协议的类型字段。
所述步骤3中,对于常用的网络接收函数,根据函数接口规范和指令架构的abi规范,判定该函数中长度参数位置和相应寄存器,由于网络数据由这些函数存储至用户的缓存区中,与该缓存区污点数据传输相关的指令所对应的网络字段识别为长度字段。
所述步骤3中,在工业通信协议的处理程序中,大小字段通常在循环语句中作为循环语句的判断条件,因此依据日志中cmp指令的记录进行循环检测,检查每个cmp指令对应的基本块的地址是否在日志中重复出现以检查cmp指令是否属于循环体的一部分,若cmp指令属于某个循环体,则对应函数的协议字段识别为大小字段。
所述步骤3中,工业通信协议中校验字段常用crc校验作为校验手段,由于其编译后对应的算术指令被优化为xor指令,因此在日志中统计xor指令的分布,如果单一函数中连续出现了5次以上xor指令,则这些汇编指令的污点数据结构中记录的协议包字段识别为校验字段。
在modbus/tcp协议上分析的最终结果如图2所示,modbus/tcp中共有三类语义,分别为长度字段、大小字段和类型字段,本发明方法对于该协议中所有字段的语义均正确识别。
上述实施例用于解释说明本发明的具体效用,并非对本发明进行的限制,熟悉本领域的技术人员可以容易地对上述内容进行修改,并把在此说明的一般原理应用到其他方面而不必经过创造性的劳动。因此,在不脱离本发明的技术原理下,所有对本发明的改进和变型也应视作本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!