一种基于深度确定性策略梯度的虚拟网络映射方法
本发明涉及通信领域与强化学习技术领域,具体而言,尤其涉及一种基于深度确定性策略梯度的虚拟网络映射方法。
背景技术:
随着5g新型的ar/vr、在线游戏、视频渲染等高带宽低时延等业务的产生,云计算和移动互联网的高速发展,未来移动数据流量将出现爆炸式增长,联网设备越来越多且越来越智能,数据量和数据节点不断增加,不仅会占用大量网络带宽,而且会增加核心光网络的负担,现有的网络规模及技术不足以支撑流量的爆炸式增长及用户的要求。网络虚拟化是一种有效解决网络僵化的问题的方法,是未来互联网的关键特性之一。网络虚拟化可以将服务运营商与基础设施提供商解耦,可以实现多租户,多服务的资源共享,为用户提供差异化服务。
虚拟网络映射是实现网络虚拟化资源分配的一个重要挑战,能够实现将底层网络资源分配给虚拟网络请求。对于光数据中心网络的虚拟网络映射,即在数据中心节点分配计算资源,在光纤链路上分配带宽资源,同时要满足用户对于节点位置、链路时延等约束。现有的基于深度强化学习的方法(如深度q学习)无法解决高维度的状态空间或大规模的动作空间的动态虚拟网络映射决策问题。深度q学习算法在选择节点映射策略的过程,可能会导致过优估计,从而映射到整体的虚拟网络映射方案,导致整体的网络性能变差。
技术实现要素:
为了解决在大规模网络上进行虚拟资源分配时资源利用率有限、不够智能的问题,而提供一种基于深度确定性策略梯度的虚拟网络映射方法,采用深度确定性策略梯度强化学习框架,通过智能体与物理网络和请求环境中交互学习,获得每次映射的奖励值,从而优化下一次动作的算法,使整体的大规模虚拟网络请求达到最优映射,最大化基础设施服务提供商的长期收益。
本发明采用的技术手段如下:
一种基于深度确定性策略梯度的虚拟网络映射方法,包括以下步骤:
s1:将虚拟网络映射问题建模为马尔科夫过程;
s2:对当前网络状态,使用深度确定性策略梯度算法进行物理节点的选择,进行虚拟节点映射;
s3:对步骤s2中映射的虚拟节点相邻的虚拟链路使用最短路径算法进行链路映射,并在进行链路映射时满足虚拟链路的时延要求;
s4:返回当前网络状态对应的奖励值及下一个网络状态,将经验存储到经验库中,经验包括当前网络状态、当前网络状态对应的奖励值和下一个网络状态;深度确定性策略梯度算法智能体从经验库中抽取一批经验进行训练,对深度确定性策略梯度算法中目标网络的参数进行更新,直到对所有虚拟网络请求映射到达设定的最大学习回合,得到最优的映射分配方案。
进一步地,步骤s1具体包括以下步骤:
s1-1:将虚拟网络映射问题建模成马尔科夫过程
s1-2:定义状态空间
在虚拟网络映射问题中,在构建状态空间时,从虚拟网络中提取的特征如下:
物理节点k包括的特征:1)剩余的cpu资源ck;2)节点度dk;3)当前物理节点相邻的物理链路剩余带宽之和:
其中lk表示物理节点k相邻的物理链路集合,b(ls)表示物理节点k的相邻链路ls的剩余带宽;
虚拟请求r中虚拟节点u包括的特征:1)请求的cpu资源
其中,
在特征提取之后,状态空间
其中,n表示物理节点集合;
s1-3:定义动作空间
一个动作是指一个映射过程将虚拟节点映射到物理节点,动作空间
s1-4:定义奖励函数
其中rr表示第r个虚拟网络请求的收益。
进一步地,步骤s2具体包括以下步骤:
s2-1:对当前网络状态,使用深度确定性策略梯度算法进行物理节点的选择at;
s2-2:环境执行动作at选择物理节点,在选择的物理节点满足虚拟节点的计算资源请求及位置约束时即进行虚拟节点映射。
进一步地,步骤s3具体包括以下步骤:
s3-1:对于步骤s2中映射的虚拟节点所有的相邻虚拟链路进行检查,若虚拟链路的两端的虚拟节点都成功映射,则执行链路映射,若虚拟节点映射失败,则进入步骤s4;
s3-2:对于成功映射的虚拟链路,进行链路资源分配;若虚拟链路映射失败,则进入步骤s4。
进一步地,步骤s4具体包括以下步骤:
s4-1:返回当前网络状态对应的奖励值及下一个网络状态;
s4-2:将经验存储到经验库中;
s4-3:深度确定性策略梯度算法智能体从经验库中抽取一批经验,计算估计的q目标值yi=ri+γq′(si+1,μ′(si+1|θμ′)|θq′),其中,ri是经验中保存的值,经验保存的是当前网络状态si、执行选择的动作ai之后得到的奖励值ri以及下一个网络状态si+1;μ′(si+1|θμ′)表示参数为θμ′目标动作网络在预测输入为si+1时选择的动作,参数为θq的评价网络根据下个状态si+1及预测的动作对动作计算评价值q′,通过最小化均方差损失函数l更新深度确定性策略梯度算法中评价网络的参数θq:
l=e[(yi-q(si,ai|θq))2]
其中,e表示的是求平均;q表示评价网络在参数为θq时,在网络状态si时,对选择的动作ai进行评价;
s4-4:通过策略梯度更新深度确定性策略梯度算法中动作网络的参数θμ:
其中,j是基于θμ与动作网络相关函数,
s4-5:根据更新后的评价网络的参数θq和动作网络的参数θμ,更新深度确定性策略梯度算法中目标评价网络的参数θq′和目标动作网络的参数θμ′:
θq′←τθq+(1-τc)θq′
θμ′←τθμ+(1-τa)θμ′
其中,θq为评价网络的参数,τc为更新系数,θq′为目标评价网络的参数;θμ为动作网络的参数,τa为更新系数,θμ′为目标动作网络的参数;
s4-6:重复步骤s2-s4,直到对所有虚拟网络请求映射到达设定的最大学习回合,得到最优的映射分配方案。
较现有技术相比,本发明具有以下优点:
本发明提供的基于深度确定性策略梯度的虚拟网络映射方法,通过将虚拟网络映射问题建模为马尔科夫决策过程,通过深度确定性策略梯度算法对当前虚拟节点状态获取进行节点映射的物理节点;通过对该虚拟节点相邻的虚拟链路进行链路映射;将得到的奖励值和下一个状态存储到经验存储库中。深度确定性策略梯度算法的智能体从经验库中抽取一些样本进行训练,更新网络参数,直到所有的回合结束,对于大规模的虚拟网络请求得到最优的资源分配方案;相比于现有的启发式算法和基于深度q学习等算法,这种深度确定性策略梯度算法的虚拟网络映射方法,可以进一步提高虚拟网络请求的接收率,提高基础设施提供商的收益,比传统方法更灵活更智能。
基于上述理由本发明可在通信领域与强化学习领域广泛推广。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做以简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
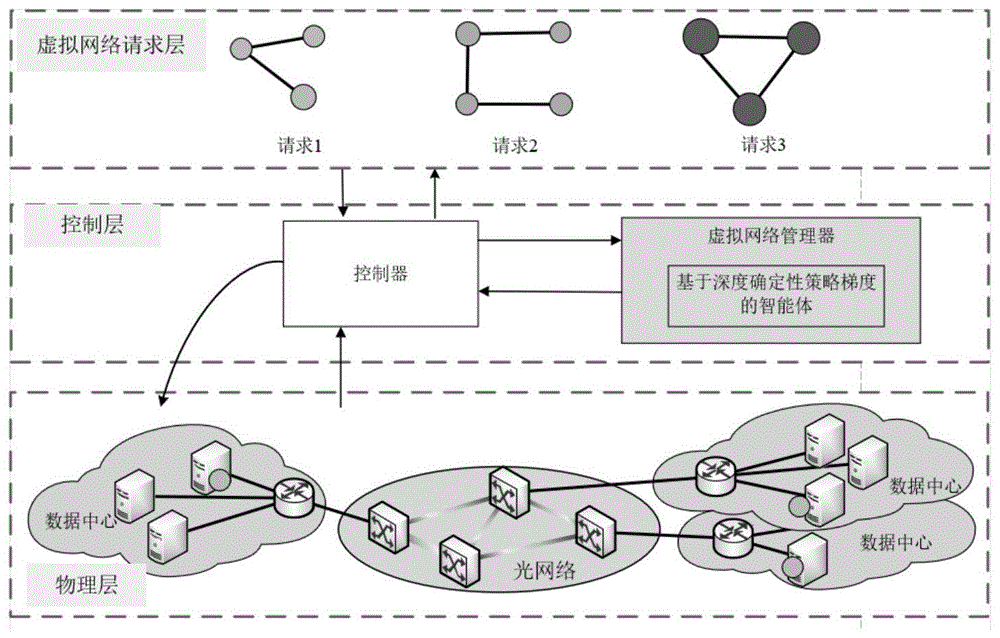
图1为本发明所述基于深度确定性策略梯度的虚拟网络映射方法的网络架构图。
图2为本发明所述深度确定性策略梯度算法的原理图。
图3为本发明所述基于深度确定性策略梯度的虚拟网络映射方法流程图。
图4为本发明所述基于深度确定性策略梯度的虚拟网络映射方法奖励值随训练回合增加的收敛结果图。
图5为本发明所述基于深度确定性策略梯度的虚拟网络映射方法网络请求接收率随训练回合增加的仿真图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
实施例1
如图3所示,本发明提供了一种基于深度确定性策略梯度的虚拟网络映射方法,包括以下步骤:
s1:将虚拟网络映射问题建模为马尔科夫过程;
s2:对当前网络状态,使用深度确定性策略梯度算法进行物理节点的选择,进行虚拟节点映射;
s3:对步骤s2中映射的虚拟节点相邻的虚拟链路使用最短路径算法进行链路映射,并在进行链路映射时满足虚拟链路的时延要求;
s4:返回当前网络状态对应的奖励值及下一个网络状态,将经验存储到经验库中,经验包括当前网络状态、当前网络状态对应的奖励值和下一个网络状态;深度确定性策略梯度算法智能体从经验库中抽取一批经验进行训练,对深度确定性策略梯度算法中目标网络的参数进行更新,直到对所有虚拟网络请求映射到达设定的最大学习回合,得到最优的映射分配方案。
进一步地,步骤s1具体包括以下步骤:
s1-1:将虚拟网络映射问题建模成马尔科夫过程
s1-2:定义状态空间
在虚拟网络映射问题中,在构建状态空间时,从虚拟网络中提取的特征如下:
物理节点k包括的特征:1)剩余的cpu资源ck;2)节点度dk;3)当前物理节点相邻的物理链路剩余带宽之和:
其中lk表示物理节点k相邻的物理链路集合,b(ls)表示物理节点k的相邻链路ls的剩余带宽;
虚拟请求r中虚拟节点u包括的特征:1)请求的cpu资源
其中,
在特征提取之后,状态空间
其中,n表示物理节点集合;
s1-3:定义动作空间
一个动作是指一个映射过程将虚拟节点映射到物理节点,动作空间
s1-4:定义奖励函数
其中rr表示第r个虚拟网络请求的收益。
进一步地,步骤s2具体包括以下步骤:
s2-1:对当前网络状态,使用深度确定性策略梯度算法进行物理节点的选择at;
s2-2:环境执行动作at选择物理节点,在选择的物理节点满足虚拟节点的计算资源请求及位置约束时即进行虚拟节点映射。
进一步地,步骤s3具体包括以下步骤:
s3-1:对于步骤s2中映射的虚拟节点所有的相邻虚拟链路进行检查,若虚拟链路的两端的虚拟节点都成功映射,则执行链路映射,若虚拟节点映射失败,则进入步骤s4;
s3-2:对于成功映射的虚拟链路,进行链路资源分配;若虚拟链路映射失败,则进入步骤s4。
进一步地,步骤s4具体包括以下步骤:
s4-1:返回当前网络状态对应的奖励值及下一个网络状态;
s4-2:将经验存储到经验库中;
s4-3:深度确定性策略梯度算法智能体从经验库中抽取一批经验,计算估计的q目标值yi=ri+γq′(si+1,μ′(si+1|θμ′)|θq′),其中,ri是经验中保存的值,经验保存的是当前网络状态si、执行选择的动作ai之后得到的奖励值ri以及下一个网络状态si+1;μ′(si+1|θμ′)表示参数为θμ′目标动作网络在预测输入为si+1时选择的动作,参数为θq的评价网络根据下个状态si+1及预测的动作对动作计算评价值q′,通过最小化均方差损失函数l更新深度确定性策略梯度算法中评价网络的参数θq:评价网络用于评价选择的动作at是否是最优的或者长期最优的;通过最小化l的值,来更新参数θq
l=e[(yi-q(si,ai|θq))2]
其中,e表示的是求平均;q表示评价网络在参数为θq时,在网络状态si时,对选择的动作ai进行评价;
s4-4:通过策略梯度更新深度确定性策略梯度算法中动作网络的参数θμ:动作网络用于根据输入的状态选择要执行的动作at;
其中,j是基于θμ与动作网络相关函数,
s4-5:根据更新后的评价网络的参数θq和动作网络的参数θμ,更新深度确定性策略梯度算法中目标评价网络的参数θq′和目标动作网络的参数θμ′:
θq′←τθq+(1-τc)θq′
θμ′←τθμ+(1-τa)θμ′
其中,θq为评价网络的参数,τc为更新系数,θq′为目标评价网络的参数;θμ为动作网络的参数,τa为更新系数,θμ′为目标动作网络的参数;
s4-6:重复步骤s2-s4,直到对所有虚拟网络请求映射到达设定的最大学习回合,得到最优的映射分配方案。
图2为深度确定性策略梯度算法的原理图,动作网络参数通过策略梯度方法来更新,评价网络参数通过损失函数来更新,目标动作网络和目标评价网络的参数通过系数τ对网络参数进行软更新,利于训练网络的稳定性。
如图1所示为基于深度确定性策略梯度的虚拟网络映射方法对应的网络架构图,如图1所示,主要包括物理层、控制层和虚拟网络请求层。本实施例中在线虚拟网络请求,将网络相关请求发送到控制层,控制层从物理层获取当前的物理网络状态,控制器将物理和虚拟网络的相关信息发送给虚拟网络管理器,基于深度确定性策略梯度的智能体将计算出的映射方案反馈给控制器,再进行虚拟网络映射及资源分配。
如图4-5所示,对发明提供的方法进行性能分析,图4为100个训练回合的奖励值的收敛趋势图,可以看出,随着训练回合数量的增加,环境反馈给智能体的奖励值趋于稳定,基于深度确定性策略梯度的智能体得到较稳定的网络参数,智能体学习到当前的一组虚拟网络请求的映射的最优策略。图5为100个训练回合虚拟网络请求接收率的仿真图,在回合80-100,虚拟网络请求的接收率保持在95%以上,可以看出,采用本发明提供的方法可以训练出较好的网络参数使得虚拟网络映射策略最优,提供更加智能的映射策略进一步满足用户的需求。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!