一种基于加权式强化学习的分段式退避算法
1.本发明属于无线传感器网络媒体访问控制层技术领域,具体涉及一种基于加权式强化学习的分段式退避算法。
背景技术:
2.在无线传感器网络中,各个传感器节点通过竞争接入共享信道来传输自身的数据,随着网络的规模扩大、数据流量增加,节点对于信道的竞争次数增加,由于冲突导致信道接入失败的情况增加;此外,在大多采用二进制指数退避算法的框架下,随着数据流量增加,网络中节点由于竞争接入信道产生的碰撞次数增加,而在每次碰撞之后,碰撞的节点就会在[0,2^(minbe+x)
‑
1](minbe为最小的退避指数大小,x为碰撞次数)内随机产生一个退避时间,但退避时间过小,会导致碰撞的概率增加、增加了节点接入信道时发生冲突导致数据发送失败的可能性,从而影响信道的有效利用率。
[0003]
并且现有的ieee 802.15.4中的退避算法在节点竞争接入信道时对于刚传输完数据的节点往往具备了更小的退避窗口,从而有更大的概率继续抢占信道,对于其余节点而言竞争进入信道会存在不公平的现象。而以往的强化学习算法在解决该问题的方面并没有对算法提供收敛和动作的偏向性。
[0004]
因此,针对上述问题,予以进一步的改进。
技术实现要素:
[0005]
本发明的主要目的在于提供一种基于加权式强化学习的分段式退避算法,其通过加权式强化学习模型对于网络访问控制控制层的信道接入方式进行调整,从而在保证节点竞争接入信道的公平性的同时提升无线传感器网络的信道有效利用率并降低丢包率,能够以“自学习”的方式动态选择效果最佳的退避窗口段来减少节点竞争接入信道发送的冲突概率,其中“自学习”通过加权的方式对于动作进行侧重式的选择并能够随着环境的变化动态的降低或者提高对于环境状态的探索概率。
[0006]
为达到以上目的,本发明提供一种基于加权式强化学习的分段式退避算法,用于在保证节点竞争接入信道的公平性的同时提升无线传感器网络的信道有效利用率并降低丢包率,包括以下步骤:
[0007]
步骤s1:建立二进制指数退避算法模型(beb),分析无线传感器网络的信道有效利用率和数据丢包率随网络中数据流量的增加而变化的情况,并且(依据ieee 802.15.4中csma/ca协议的原理)建立分段式的退避窗口,设置不同的节点数量以改变网络中的数据流量情况,以得到不同节点数量情况下的各段退避窗口的信道有效利用率;
[0008]
步骤s2:建立加权式强化学习算法,并且使得加权式强化学习算法在网络环境稳定的情况下自动减少多余的探索动作来减少资源的浪费,在网络环境波动的情况下自动增大进行探索动作的概率,并在探索动作的过程中根据原来最优动作的距离按照权重比由大到小分配,使加权式强化学习算法优先探索就近的探索动作;
[0009]
步骤s3:建立强化学习模型,将不同段的退避窗口与信道有效利用率(pb)作为强化学习模型的探索动作和奖励值,并且带入加权式强化学习算法,通过加权的方式影响探索动作的选择,使网络模型在保证节点竞争接入信道的公平性的同时的基础上选择信道有效利用率最高的退避窗口段。
[0010]
作为上述技术方案的进一步优选的技术方案,步骤s1具体实施为以下步骤:
[0011]
步骤s1.1:建立根据ieee 802.15.4csma/ca协议的二进制指数退避算法模型,并且输入网络模型(二进制指数退避算法模型的应用环境)的不同节点数量na(a=1~64)作为数据流量大小,以得到各节点数量下的信道有效利用率pa,统计获得到的各节点的信道有效利用率数据,以得到节点与信道有效利用率的关系r1;
[0012]
步骤s1.2:根据ieee 802.15.4中csma/ca协议的原理,(分析beb原理存在的问题)以建立分段式的退避窗口,输入网络模型的不同节点数量nb(b=1~64)作为数据流量大小,以得到各节点数量下的各段退避窗口的信道有效利用率pb,统计获得到的各节点的信道有效利用数据,以得到不同数据流量下不同段的退避窗口与信道有效利用率pb的关系r2;
[0013]
步骤s1.3:将r1和r2进行比对,从而获得第一比对数据(本发明的信道有效利用率明显高于传统的信道有效利用率)。
[0014]
作为上述技术方案的进一步优选的技术方案,步骤s2具体实施为以下步骤:
[0015]
步骤s2.1:建立加权式强化学习算法,制定加权函数使探索动作被选择的概率以最优动作向两侧递减,加权函数如下:
[0016][0017]
其中,m为拥有最大奖励值的探索动作,i为已知的其余探索动作,ε为探索动作执行的概率,m
‑
i表为执行其余探索动作距离最大奖励值探索动作的距离;
[0018]
步骤s2.2:建立自适应探索函数,使探索动作随着网络环境的稳定减小变化而增大,自适应探索函数如下:
[0019][0020]
其中,ε为探索动作执行的概率,v为保存初始的ε概率。
[0021]
作为上述技术方案的进一步优选的技术方案,步骤s3具体实施为以下步骤:
[0022]
步骤s3.1:建立强化学习模型,不同段的退避窗口与信道有效利用率(pb)作为强化学习模型的探索动作和奖励值;
[0023]
步骤s3.2:在强化学习模型中输入当前网络模型的不同的节点数量(nb,b=1~64),分别带入第一算法(传统的ε
‑
greedy算法,传统的强化学习算法)和加权式强化学习算法得到探索动作的执行过程c1和c2,并且将c1和c2进行比对比获得第二比对数据。
[0024]
为达到以上目的,本发明提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现所述一种基于加权
式强化学习的分段式退避算法的步骤。
[0025]
为达到以上目的,本发明提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现所述一种基于加权式强化学习的分段式退避算法的步骤。
附图说明
[0026]
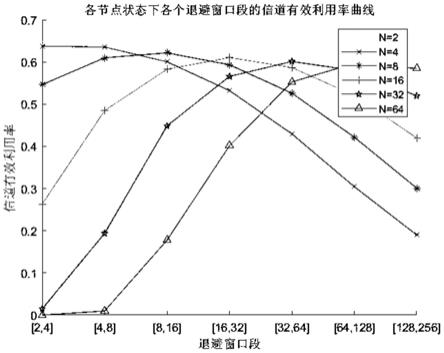
图1是本发明的一种基于加权式强化学习的分段式退避算法的各个退避窗口端的信号有效利用率曲线图。
[0027]
图2是本发明的一种基于加权式强化学习的分段式退避算法的基于强化学习模型的探索动作分布图。
[0028]
图3是传统的信号有效利用率曲线图。
[0029]
图4是传统的基于第一算法的探索动作分布图。
具体实施方式
[0030]
以下描述用于揭露本发明以使本领域技术人员能够实现本发明。以下描述中的优选实施例只作为举例,本领域技术人员可以想到其他显而易见的变型。在以下描述中界定的本发明的基本原理可以应用于其他实施方案、变形方案、改进方案、等同方案以及没有背离本发明的精神和范围的其他技术方案。
[0031]
在本发明的优选实施例中,本领域技术人员应注意,本发明所涉及的第一算法、ieee 802.15.4csma/ca协议等可被视为现有技术。
[0032]
优选实施例。
[0033]
本发明公开了一种基于加权式强化学习的分段式退避算法,用于在保证节点竞争接入信道的公平性的同时提升无线传感器网络的信道有效利用率并降低丢包率,包括以下步骤:
[0034]
步骤s1:建立二进制指数退避算法模型(beb),分析无线传感器网络的信道有效利用率和数据丢包率随网络中数据流量的增加而变化的情况,并且(依据ieee 802.15.4中csma/ca协议的原理)建立分段式的退避窗口,设置不同的节点数量以改变网络中的数据流量情况,以得到不同节点数量情况下的各段退避窗口的信道有效利用率;
[0035]
步骤s2:建立加权式强化学习算法,并且使得加权式强化学习算法在网络环境稳定的情况下自动减少多余的探索动作来减少资源的浪费,在网络环境波动的情况下自动增大进行探索动作的概率,并在探索动作的过程中根据原来最优动作的距离按照权重比由大到小分配,使加权式强化学习算法优先探索就近的探索动作;
[0036]
步骤s3:建立强化学习模型,将不同段的退避窗口与信道有效利用率(pb)作为强化学习模型的探索动作和奖励值,并且带入加权式强化学习算法,通过加权的方式影响探索动作的选择,使网络模型在保证节点竞争接入信道的公平性的同时的基础上选择信道有效利用率最高的退避窗口段。
[0037]
具体的是,步骤s1具体实施为以下步骤:
[0038]
步骤s1.1:建立根据ieee 802.15.4csma/ca(载波监听多点接入碰撞避免)协议的二进制指数退避算法模型,并且输入网络模型(二进制指数退避算法模型的应用环境)的不
同节点数量na(a=1~64)作为数据流量大小,以得到各节点数量下的信道有效利用率pa,统计获得到的各节点的信道有效利用率数据,以得到节点与信道有效利用率的关系r1;
[0039]
步骤s1.2:根据ieee 802.15.4中csma/ca协议的原理,(分析beb原理存在的问题)以建立分段式的退避窗口([2^(x
‑
1),2^x
‑
1](x为beb中的退避指数)),输入网络模型的不同节点数量nb(b=1~64)作为数据流量大小,以得到各节点数量下的各段退避窗口的信道有效利用率pb,统计获得到的各节点的信道有效利用数据,以得到不同数据流量下不同段的退避窗口与信道有效利用率pb的关系r2;
[0040]
步骤s1.3:将r1和r2进行比对,从而获得第一比对数据(本发明的信道有效利用率明显高于传统的信道有效利用率)。
[0041]
优选地,从图1和图3对比可知,本发明的各个退避窗口端的信号有效利用率曲线图在不同的节点状态下,呈现不同的曲线,可以根据不同的节点数量找到相应的退避窗口段,使得信道的有效利用率最优化;而传统的是随着节点数量的增加信道有效利用率降低,无法进行找到得信道的有效利用率最优化。
[0042]
更具体的是,步骤s2具体实施为以下步骤:
[0043]
步骤s2.1:建立加权式强化学习算法,制定加权函数使探索动作被选择的概率以最优动作向两侧递减,加权函数如下:
[0044][0045]
其中,m为拥有最大奖励值的探索动作,i为已知的其余探索动作,ε为探索动作执行的概率,m
‑
i表为执行其余探索动作距离最大奖励值探索动作的距离;
[0046]
步骤s2.2:建立自适应探索函数,使探索动作随着网络环境的稳定减小变化而增大,自适应探索函数如下:
[0047][0048]
其中,ε为探索动作执行的概率,v为保存初始的ε概率。
[0049]
进一步的是,步骤s3具体实施为以下步骤:
[0050]
步骤s3.1:建立强化学习模型,不同段的退避窗口与信道有效利用率(pb)作为强化学习模型的探索动作和奖励值;
[0051]
步骤s3.2:在强化学习模型中输入当前网络模型的不同的节点数量(nb,b=1~64),分别带入第一算法(传统的ε
‑
greedy算法,传统的强化学习算法)和加权式强化学习算法得到探索动作的执行过程c1和c2,并且将c1和c2进行比对比获得第二比对数据。
[0052]
优选地,可以选择不同的节点数量进行比对,从而获得本发明的强化学习算法的收敛性更强,并且能更好的保证信道有效利用率和公平性。
[0053]
优选地,由图2和图4可知,图2的其余探索动作(图中的竖线)明显小于传统的第一算法下的其余探索动作。
[0054]
优选地,本发明还公开一种电子设备,包括存储器、处理器及存储在存储器上并可
在处理器上运行的计算机程序,所述处理器执行所述程序时实现所述一种基于加权式强化学习的分段式退避算法的步骤。
[0055]
优选地,本发明还公开了一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现所述一种基于加权式强化学习的分段式退避算法的步骤。
[0056]
值得一提的是,本发明专利申请涉及的第一算法、ieee 802.15.4csma/ca协议等技术特征应被视为现有技术,这些技术特征的具体结构、工作原理以及可能涉及到的控制方式、空间布置方式采用本领域的常规选择即可,不应被视为本发明专利的发明点所在,本发明专利不做进一步具体展开详述。
[0057]
对于本领域的技术人员而言,依然可以对前述各实施例所记载的技术方案进行修改,或对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1