显著性图和变换系数块的编码的制作方法
显著性图和变换系数块的编码
1.本技术是申请日为2011年4月11日、国际申请号为pct/ep2011/055644、发明名称为“显著性图和变换系数块的编码”的pct申请的中国国家阶段申请的申请号为201810801490.3、发明名称为“解码显著性图的装置和方法、编码装置和方法及存储介质”的分案申请的分案申请,该中国国家阶段申请进入中国国家阶段的进入日为2012年12月13日、申请号为201180029192.3,其全部内容结合于此作为参考。
技术领域
2.本技术是针对指示在变换系数块内的显著变换系数位置的显著性图的编码以及这种变换系数块的编码。例如,此编码可,例如,被用于例如图像和视频编码中。
背景技术:
3.在传统视频编码中,视频序列的图像通常被分解成为块。块或块的色彩分量通过移动补偿预测或图像内部预测预测。块可具有不同的尺寸并且可以是正方形或矩形。块或块的色彩分量的所有取样使用同一组预测参数被预测,例如,参考索引(识别已被编码的图像组中的参考图像)、移动参数(指明供用于参考图像以及当前图像之间块的移动的测量)、用于指明插值过滤、图像内部预测模型等等的参数。移动参数可通过水平和垂直分量的位移向量或通过例如,由6个分量组成的仿射移动参数的较高阶移动参数被表示。也可能一组以上的预测参数(例如,参考索引以及移动参数)与单独的块相关联。该情况下,对于每组预测参数,产生用于块或块的色彩分量的单一中间预测信号,并且最后的预测信号利用这些中间预测信号的加权和建立。加权参数以及可能有一固定偏移量(其被加至该加权和),可以对于图像、或参考图像、或一组参考图像为固定的,或它们可被包含在对应的块的预测参组中。同样地,静止影像也经常被分解成为块,并且块利用图像内部预测方法(其可以是空间图像内部预测方法或预测块的dc分量的简易图像内部预测方法)被预测。在角落的情况中,该预测信号也可以是零。
4.在原始块或原始块的色彩分量与对应的预测信号之间的差,也被称为残差信号,其通常被变换和量化。一个二维变换被应用于残差信号并且所产生的变换系数被量化。对于该变换编码,对于一组特定预测参数被使用于其中的块或块的色彩分量,可在应用变换之前进一步被分割。变换块可以是等于或小于被用于预测的块。也有可能变换块包含多于一个被用于预测的块。在静止影像或视频序列的图像中不同变换块可具有不同的尺寸,并且变换块可被表示为正方形或矩形块。
5.产生的量化变换系数,同时也被称为变换系数水平,接着使用熵编码技术被传送。因此,变换系数水平的块通常使用扫描而被映射至变换系数值的向量(即,有序组)上,其中不同的扫描可被用于不同的块。通常,使用曲折扫描。对于仅含有交错帧的像场取样的块(这些块可以是在编码像场中的块或编码帧中的像场块),其通常也使用特别地设计用于像场块的不同扫描。通常被使用编码所产生的变换系数有序序列的熵编码算法是游程水平编码。通常,大量的变换系数水平是零,并且等于零的一组连续的变换系数水平可通过编码等
于零(游程)的连续变换系数水平的数目而有效地被表示。对于剩余(非零)的变换系数,对实际的水平编码。有各种不同的游程水平码。在非零系数之前的游程以及该非零变换系数的水平可使用单一符号或代码字一起被编码。通常,包含在最后非零值变换系数之后被传送之块末端之特殊符号。或可能先编码非零值变换系数水平数目,并且根据这数目,水平以及游程被编码。
6.稍不同的方法被使用于h.264中的高效率的cabac熵编码中。在此,变换系数水平的编码被分为三个步骤。在第一步骤中,用于各变换块的一个二进制语法元素coded_block_flag被发送,其以信号告知变换块是否包含显著变换系数水平(即,为非零值的变换系数)。如果该语法元素指示,显著变换系数水平呈现,则一个二进制评估显著性图被编码,其指明哪个变换系数水平具有非零数值。并且接着,以逆向扫描次序,非零变换系数水平的值被编码。如下所述对显著性图编码。对于扫描次序中的各系数,一个二进制语法元素significant_coeff_flag被编码,其指明对应的变换系数水平是否等于零值。如果significant_coeff_flag二进制值等于一,即,如果非零值变换系数水平存在于这扫描位置,则进一步的二进制语法元素last_significant_coeff_flag被编码。该二进制值指示目前显著变换系数水平是否为块内部的最后显著变换系数水平或在扫描次序中是否紧随着进一步的显著变换系数水平。如果last_significant_coeff_flag指示无进一步的显著变换系数紧随着,则无进一步语法元素被编码用于指明块的显著性图。在接着的步骤中,显著变换系数水平的值被编码,其在块内部的位置已利用显著性图决定。显著变换系数水平的数值通过使用下面的三个语法元素以反向扫描次序被编码。二进制语法元素coeff_abs_greater_one指示,显著变换系数水平绝对值是否大于一。如果二进制语法元素coeff_abs_greater_one指示绝对值大于一,则进一步的语法元素coeff_abs_level_minus_one被传送,其指明变换系数水平减一的绝对值。最后,二进制语法元素coeff_sign_flag,其指明变换系数数值的符号,对于各显著变换系数水平被编码。此外应注意到,有关于显著性图的语法元素以扫描次序被编码,而有关于变换系数水平的实际数值的语法元素以反向扫描次序被编码而允许更合适的上下文模型的使用。
7.在h.264中的cabac熵编码中,所有用于变换系数水平的语法元素使用一个二进制概率模型被编码。非二进制语法元素coeff_abs_level_minus_one首先被二进制化,即,其被映射至序列的二进制决定(二进制值)上,并且这些二进制值被顺序地编码。二进制语法元素significant_coeff_flag、last_significant_coeff_flag、coeff_abs_greater_one、以及coeff_sign_flag直接地被编码。各被编码的二进制值(包含二进制语法元素)被关联到上下文。上下文表示对于一类编码二进制值的概率模型。有关对于两个可能的二进制数值之一的概率的测量根据先前地通过对应的上下文被编码的二进制数值对于各上下文被估计。对于有关变换编码的数个二进制值,被使用于编码的上下文根据已被发送的语法元素或根据一块内部的位置被选择。
8.显著性图指示有关对于扫描位置的显著性(变换系数水平不是零值)的信息。在h.264的cabac熵编码中,对于一个4x4的块尺寸,分别的上下文被用于各扫描位置以供编码二进制语法元素significant_coeff_flag以及last_significant_coeff_flag,其中不同的上下文被用于扫描位置的significant_coeff_flag以及last_significant_coeff_flag。对于8x8块,相同的上下文模型被使用于四个连续的扫描位置,导致对于
significant_coeff_flag的16个上下文模型以及对于last_significant_coeff_flag的另外的16个上下文模型。用于significant_coeff_flag及last_significant_coeff_flag的这上下文模型方法,对于大的块尺寸具有一些缺点。另一方面,如果各扫描位置被关联于分别的上下文模型,当大于8x8的块被编码时,则上下文模型数目显著地增加。此增大的上下文模型数目导致慢的概率估计自适应和通常有不精确的概率估计,这两方面在编码效率上都具有负面影响。另一方面,由于非零变换系数通常被集中在变换块的特定区域中(区域是取决于残差信号对应的块内部的主要结构),对于一些连续扫描位置的上下文模型的指定(如h.264中对于8x8块的指定),对于较大的块尺寸,同时也不是最理想的。
9.在编码显著性图之后,块以逆向扫描次序被处理。如果扫描位置是显著的,即,系数不同于零,则二进制语法元素coeff_abs_greater_one被发送。起初,对于coeff_abs_greater_one语法元素,对应的上下文模型组的第二上下文模型被选择。如果在块内部的任何coeff_abs_greater_one语法元素被编码的数值等于一(即,绝对系数大于2),则上下文模型切换回至该组的第一上下文模型并且使用这上下文模型高至块末端。否则(在块内部的coeff_abs_greater_one的所有被编码值是零并且对应的绝对系数水平等于一),上下文模型根据在所考虑块的反向扫描次序先前被编码/被解码的等于零的coeff_abs_greater_one语法元素数目被选择。对于语法元素coeff_abs_greater_one的上下文模型选择可藉由下列的方程式被概述,其中目前之上下文模型索引c
t+1
根据先前的上下文模型索引c
t
以及先前被编码的语法元素coeff_abs_greater_one之数值(在方程式中利用bin
t
被表示)被挑选。对于在块内部的第一语法元素coeff_abs_greater_one,上下文模型索引被设定等于c
t
=1。
[0010][0011]
用于编码绝对变换系数水平的第二语法元素,当对于相同扫描位置的coeff_abs_greater_one语法元素是等于一时,则仅coeff_abs_level_minus_one被编码。非二进制语法元素coeff_abs_level_minus_one被二进制化成为序列的二进制值并且用于二进制化的第一二进制值;上下文模型索引如后所述地被选择。二进制化的其余二进制值利用固定的上下文被编码。用于二进制化的第一二进制值的上下文如下文所述地被选择。对于第一coeff_abs_level_minus_one语法元素,用于coeff_abs_level_minus_one语法元素的第一二进制值的上下文模型组的第一上下文模型被挑选,对应的上下文模型索引被设定为c
t
=0。对于coeff_abs_level_minus_one语法元素的各进一步的第一二进制值,上下文模型切换至该组集中的下一个上下文模型,其中组中的上下文模型数目被限定为5。上下文模型挑选可利用下面的公式被表示,其中当前的上下文模型索引c
t+1
根据先前的上下文模型索引c
t
被选择。如在上面所提到的,对于在块内部的第一语法元素coeff_abs_level_minus_one可利用上下文模型索引被设定为c
t
=0。应注意,不同的上下文模型组被使用于语法元素coeff_abs_greater_one以及coeff_abs_level_minus_one。
[0012]ct+1
(c
t
)=min(c
t
+1,4)
[0013]
对于大块,这方法具有一些缺点。对于coeff_abs_greater_one的第一上下文模型的选择(如果等于1的coeff_abs_greater_one的值已对于块被编码,则其被使用)通常过早
地被完成并且对于coeff_abs_level_minus_one的最后的上下文模型却又因为显著系数的数目大于小块中的数目而过快地被完成。因此,coeff_abs_greater_one以及coeff_abs_level_minus_one的大多数二进制值利用单一上下文模型编码。但这些二进制值通常具有不同的可能性,并且因此对于大量的二进制值的单一上下文模型的使用在编码效率上具有负面影响。
[0014]
虽然,一般而言,大块增加用以进行频谱分解变换的计算性经常消耗,有效编码小块和大块的能力将可实现较高的编码效率,例如,在编码如图像的取样阵列或表示其它空间取样信息信号,例如,深度图的取样阵列等。其理由是,当变换块内的取样阵列时,对于在空间以及频谱分辨率之间的依赖度,块愈大则变换的频谱分辨率愈高。大体上,最好可能局域性地应用对应的变换于取样阵列上,因而在此一各别的变换区域内,取样阵列的频谱构成并不大范围地变化。小的块保证在块内的内容是相对一致的。另一方面,如果块太小,则频谱分辨率低,且在非显著以及显著变换系数之间的比率将降低。
[0015]
因此,最好具有一编码结构,即使当块大时,该结构也能使得变换系数块并且它们的显著性图可高效地编码。
技术实现要素:
[0016]
因而,本发明的目标是提供一种编码结构以用于分别地编码变换系数块以及指示在变换系数块内的显著变换系数位置的显著性图,以便提高编码效率。
[0017]
该目标将通过独立的权利要求书内容实现。
[0018]
根据本技术的第一方面,本技术的基本思路是,如果扫描次序(通过该扫描次序被顺序抽取的语法元素指示,对于在变换系数块内的关联位置,关于是显著变换系数还是非显著的变换系数位于相应的位置)根据通过先前关联的语法元素被指示的显著变换系数位置,被顺序地关联至在变换系数块位置中的变换系数块位置,可实现用于编码指示在变换系数块内的显著变换系数的位置的显著性图的较高编码效率。尤其,本发明人发现,在典型的取样阵列内容,例如,图像、视频或深度图内容中,显著变换系数主要在对应于垂直方向的非零的频率和在水平方向的低频率的变换系数块的某一侧形成群组,或反之亦然,以至于考虑通过先前关联的语法元素被指示的显著变换系数位置可控制扫描的进一步起因,因而较早达到在变换系数块内的最后显著变换系数的概率,相对于根据扫描次序无关于目前为止通过先前关联的语法元素被指示的显著变换系数位置的预定程序被增大。这对于较大的块尤其是真实的,虽然上面所述对于小块其同时也是真实的。
[0019]
根据本技术的实施方式,熵解码器被配置为从数据流抽取信息,该信息能够识别关于目前通过当前关联的语法元素被指示的显著变换系数是否为最后的显著变换系数,而无关于其在变换系数块内的确切的位置,其中该熵解码器被配置为使得如果关于此最后的显著变换系数的当前语法元素发生,则将预期无进一步的语法元素。该信息可包括块内的显著变换系数的数目。可选择地,第二语法元素被插入第一语法元素中,第二语法元素指示,对于显著变换系数被置放的关联位置,关于该变换系数是否是变换系数块中的最后变换系数。
[0020]
根据本技术的实施方式,关联器根据到目前为止仅在变换系数块内的预定位置被指示的显著变换系数位置,而调整扫描次序。例如,数个子路线,其通过在变换系数块内的
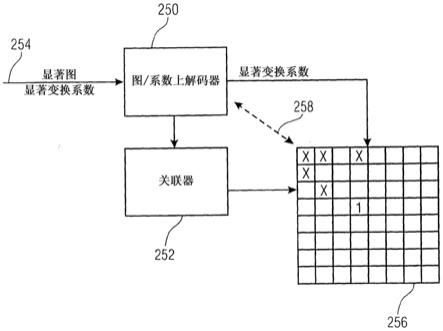
位置互相脱连的子集合,大体上对角地分别地自对应至沿着第一方向的最小频率以及沿着另一方向的最高频率的变换系数块的一对侧边,而分别地延伸至对应至沿着第二方向的零频率以及沿着第一方向的最大频率的变换系数块的一对侧边。在该情况下,关联器被配置为选择扫描次序,因而该等子路线以在该等子路线中,以子路线至变换系数块内的dc位置的距离单调性增加的顺序被遍历,各子路线被遍历而无需沿着行进方向中断,并且对于各子路线的该子路线沿其通过的方向根据在先前子路线的期间被遍历的显著变换系数位置,利用关联器被选择。通过该措施,最后的显著变换系数被位于最后子路线在一个方向被遍历的概率被增加,因而,相比于位于最后子路线的第二半内,最后的显著变换系数更有可能位于最后的子路线的第一半内,因而可能减少指示关于显著变换系数还是非显著变换系数位于相应位置的语法元素的数目。在大变换系数块的情况下,其效果特别显著。
[0021]
根据本技术的另一方面,本技术基于以下发现:如果之前提及的语法元素(其指示,对于在变换系数块内的关联位置,关于是显著变换系数还是非显著变换系数位于相应的位置)使用上下文被上下文自适应熵解码,则在变换系数块内指示显著变换系数的位置的显著性图可更有效地被编码,其中上下文依据在利用任何先前的语法元素被指示为显著的各别的语法元素的邻近区域中的一些显著变换系数,而对于各语法元素分别地被选择。尤其,本发明者发现,由于变换系数块的增大尺寸,显著变换系数在变换系数块内的某些区域以某种方式被聚集,因此上下文自适应,其不仅仅是对于以当前预定的扫描次序被遍历的显著变换系数数目敏感同时也考虑显著变换系数的邻近区域,使得上下文的较佳自适应并且因此增大熵编码的编码效率。
[0022]
当然,上面概述的两个方面可以有利的方式被结合。
[0023]
进一步地,根据本技术的又一方面,本技术基于以下发现:其中在下列情况时用以编码变换系数块的编码效率可被提高,例如:当指示在变换系数块内的显著变换系数的位置的显著性图优于在变换系数块内的显著变换系数的实际数值的编码时,并且如果遵循在变换系数块位置中的预定扫描次序(其被使用以顺序地关联显著变换系数的值序列与显著变换系数的位置)使用在子块中的子块扫描次序而扫描子块中的变换系数块,且辅助地以系数扫描次序扫描在子块内的变换系数位置时,并且如果自一些上下文的多个组中所选择的一些上下文的组被使用以用于顺序地上下文调适熵解码显著变换系数数值的值时,选择组的选择是基于在以子块扫描次序已被遍历的变换系数块子块内的变换系数的数值或已被解码的变换系数块中在同一地点的子块的变换系数的数值时。以这方式,上下文自适应是非常适合于上面概述的被聚集在变换系数块内的某些区域的显著变换系数性质,尤其是,当考虑大变换系数块时。另一方面,子块中的数值可被扫描,并且上下文可基于子块统计数据选择。
[0024]
再者,甚至后面的方面可与本技术的先前确认的任何一个或两方面相结合。
附图说明
[0025]
本技术的优选实施方式将参照下面相关图说明,其中:
[0026]
图1示出根据实施方式的编码器的块图;
[0027]
图2a至图2c示意性地示出将取样阵列(例如,图像)以不同的次分割成为块的图示;
[0028]
图3示出根据实施方式的解码器的块图;
[0029]
图4更详细地示出根据本技术实施方式的编码器的块图;
[0030]
图5更详细地示出根据本技术实施方式的解码器的块图;
[0031]
图6是示意性地示出自空间域变换成为频谱域的块变换图形;
[0032]
图7示出依照实施例的用以解码显著性图以及变换系数块的显著变换系数的装置的块图;
[0033]
图8示意性地示出将扫描次序次分割成为子路线的扫描次序的次分割以及它们不同的遍历方向;
[0034]
图9示意性地示出依照实施方式的对于变换块内某些扫描位置的邻近区域限定;
[0035]
图10示意性地示出对于变换块边界的变换块内的一些扫描位置的可能的邻近区域限定;
[0036]
图11示出依照本技术的进一步实施例的可能的变换块扫描。
具体实施方式
[0037]
值得注意的是,在图的说明中,出现在几个这些图中的组件在这些图的每个钟利用同样的参考符号指示,并且就功能性而言,避免对这些组件的重复说明,以便避免不必要的重复。然而,对于图所提供的功能以及说明,除非其对立者明确地被指示,否则同时也可适用用于其它图。
[0038]
图1示出编码器10的实例,在该编码器中,对于本技术的方面可实施。编码器将信息取样阵列20编码为数据流。信息取样阵列可表示任何类型的空间取样信息信号。例如,取样阵列20可以是静态图像或视频图像。因此,信息取样可对应于亮度值、色值、明度值、色度值等。然而,例如,在取样阵列20是由例如光时间感应器等所产生的深度图的情况下,信息取样也可以是深度值。
[0039]
编码器10是基于块的编码器。即,编码器10以块40为单位将取样阵列20编码为数据流30。以块40为单位的编码不是必须地意味着编码器10完全彼此无关地编码这些块40。反之,编码器10可使用先前编码块的重建以外插或内测其余的块,并且可使用块间隔尺寸(granularity)设定编码参数,即,用以设定对对应于各个块的各取样阵列区域编码的方式。
[0040]
进一步地,编码器10是变换编码器。即,编码器10通过使用变换编码块40,以便将各块40内的信息取样从空间域变换到频谱域。可以使用二维变换,例如,fft的dct等。优选地,块40是正方形或矩形。
[0041]
在图1中示出的被次分割成为块40的取样阵列20的次分割仅用于说明的目的。图1示出取样阵列20被次分割为以非重迭方式彼此紧邻的正方形或矩形块40的规则性二维排列。块40尺寸可预定。即,编码器10可不需在数据流30内传送块40的块尺寸信息至解码侧。例如,解码器可预期预定的块尺寸。
[0042]
然而,数个选择是可能的。例如,块可彼此重迭。然而,重迭可被限定为各块具有不与任何邻近的块重迭的部分的程度,或使各块取样,以最大方式,与沿着预定方向并列于目前块的邻近块中的块重迭。后者可表示,左方的与右方的邻近块可与当前的块重迭以便完全地覆盖当前的块,但是它们可不彼此覆盖,并且同样情况适用于垂直以及对角线方向邻
近者。
[0043]
如进一步的选择,被次分割为块40的取样阵列20的次分割通过编码器10利用经由比特流30被传至解码器侧的次分割上的次分割信息而被调适于取样阵列20的内容。
[0044]
图2a至图2c示出被次分割成为块40的取样阵列20的次分割的不同实例。图2a示出被次分割为不同尺寸的块40的取样阵列20的基于四叉树的次分割,其具有增大尺寸的40a、40b、40c以及40d指示的表示块。依照图2a的次分割,取样阵列20首先被分割为树形块40d的规则性二维排列,依次地,具有与之关联的各次分割信息,根据该信息,某树形块40d可根据四叉树结构进一步被次分割或没有。块40d的左方的树形块示例性地依照四叉树结构被次分割成为较小的块。编码器10可对于在图2a中以实线以及虚线示出的各块进行一个二维变换。换句话说,编码器10可依块次分割单位来变换阵列20。
[0045]
替代基于四叉树的次分割,更通用的基于多个树的次分割可被使用并且在不同层级之间,每个层级的子节点数目可不同。
[0046]
图2b示出用于次分割的另一实例。依照图2b,取样阵列20首先被分割成为以非重迭互相紧邻方式的规则性二维排列排列的宏块40b,在其中各宏块40b具有与其相关联的次分割信息(根据该次分割信息,宏块不被次分割,或者,如果被次分割,以规则性二维方式被次分割成为相等尺寸的子块),以便对于不同宏块得到不同的次分割间隔尺寸。其结果是在不同尺寸块40中的取样阵列20的次分割具有以40a、40b以及40a’指示的不同尺寸表示。如在图2a中,编码器10对在图2b中以实线与虚线示出的各块进行二维变换。图2c稍后将被详述。
[0047]
图3示出解码器50,其可解码通过编码器10产生的数据流30,以重建取样阵列20的重建版本60。解码器50自数据流30抽取每个块40的变换系数块,并且通过对各变换系数块进行逆变换而重建该重建版本60。
[0048]
编码器10和解码器50可被配置为进行熵编码/解码,以便分别将关于变换系数块的信息插入数据流,以及从数据流分提取该信息。这方面的细节稍后将说明。应注意到,数据流30不必定得包含取样阵列20的所有块40的关于变换系数块的信息。反之,块40的子集可以另外的方式被编码为比特流30。例如,编码器10可决定,将不同编码参数插入比特流30中以避免插入对于块40的某块的变换系数块,因而使解码器50可预测或以别的方法将各个块填入重建版本60中。例如,编码器10可进行纹理分析,以便将块置放在取样阵列20内,取样阵列可经由纹理合成利用解码器在解码器侧中被填充并且因此在比特流内指示这结果。
[0049]
如在下图的讨论中,变换系数块不必定得是表示取样阵列20的各个块40的原始信息取样的频谱域表示。反之,此变换系数块可表示各个块40的预测残差的频谱域表示。图4示出这样的编码器的实施方式。图4的编码器包括变换级100、熵编码器102、逆变换级104、预测器106以及减法器108和加法器110。减法器108、变换级100以及熵编码器102在图4编码器的输入112和输出114之间以所提到的顺序被串联连接。逆变换级104、加法器110以及预测器106以在变换级100的输出和减法器108逆向输入之间以所提到的顺序被连接,预测器106的输出同时也被连接至加法器110的进一步输入。
[0050]
图4的编码器是基于预测性变换的块编码器。即,进入输入112的取样阵列20的块由相同取样阵列20的先前编码以及重建部分或先前编码以及重建的其它取样阵列,其可在当前的取样阵列20之前或及时地接续于当前取样阵列20之后,被预测。预测通过预测器106
执行。减法器108从原块减去预测值并且变换级100对预测残差进行二维变换。二维变换本身或变换级100内部的后续措施可导致在变换系数块内的变换系数的量化。量化的变换系数块通过例如在熵编码器102内的熵编码被无损地编码,而在输出114输出所产生的数据流。逆变换级104重建量化的残差,加法器110,依次地,结合重建的残差与对应的预测,以便取得重建信息取样,使预测器106可基于重建信息取样预测在之前提到的当前编码预测块。预测器106可使用不同的预测模型,例如,图像内部预测模型以及图像间预测模型以便预测块,并且预测参数被转发至熵编码器102以供插入到数据流。
[0051]
即,依照图4的实施方式,变换系数块表示取样阵列残差的频谱表示而不是其实际的信息取样。
[0052]
应注意到,对于图4实施方式有数个选择存在,它们中的一些已在说明书的前面部分描述,该描述被结合到图4的描述。例如,由预测器106产生的预测值可以不被熵编码。反之,侧部信息可通过另外的编码方案被传至解码侧。
[0053]
图5示出能够对由图4的编码器所产生的数据流进行解码的解码器。图5的解码器包括熵解码器150、逆变换级152、加法器154以及预测器156。熵解码器150、逆变换级152以及加法器154以所提到的顺序串联连接在图5的解码器的输入158以及输出160之间。熵解码器150的进一步的输出被连接至预测器156,预测器156又被连接在加法器154的输出以及其进一步的输入之间。熵解码器150,从在输入158进入图5的解码器的数据流中抽取变换系数块,在其中逆变换在级152被应用于变换系数块,以便获得残差信号。残差信号在加法器154与来自预测器156的预测值结合,以便在输出160得到取样阵列的重建版本的重建块。根据该等重建版本,预测器156产生预测值,从而重建在编码器侧通过预测器106执行的预测。为了获得如那些被使用在编码器侧的相同预测值,预测器156使用熵解码器150也在输入158从数据流获得的预测参数。
[0054]
应注意到,在上面说明的实施方式中,进行残差预测以及变换的空间间隔尺寸不需要彼此相等。这被示出在图2c中。该图示出具有实线的预测间隔尺寸以及具有虚线的残差间隔尺寸的预测块的次分割。如所见地,次分割可彼此无关地由编码器选择。更准确地,数据流语法可允许无关于预测次分割而对残差次分割的限定。可选地,残差次分割可以是预测次分割的延伸,以至于各残差块等于预测块或是预测块的适当子集。这被示出在图2a以及图2b上,例如,再次地,预测间隔尺寸以实线被示出并且残差间隔尺寸以虚线被示出。在此,在图2a至图2c中,具有与参考符号相关联的所有块是将被进行一个二维变换的残差块,而围绕虚线块40a的较大的实线块,例如,将是预测参数设定可分别地被进行的预测块。
[0055]
上面的实施方式共同点为(残差或原始)取样的块将在编码器侧被变换成为变换系数块,依次地,其将在解码器侧被逆变换为取样的重建块。这将在图6中说明。图6示出取样块200。在图6情况下,该块200是示例性正方形以及具有4x4取样202的尺寸。取样202沿着水平方向x以及垂直方向y被规则排列。通过上面提到的二维变换t,块200被变换到频谱域,即成为变换系数206的块204,变换块204具有相同于块200的尺寸。即,变换块204在水平方向以及垂直方向,具有如同块200的取样一般多的变换系数206。然而,由于变换t是频谱变换,在变换块204内的变换系数206的位置并不对应于空间位置,而是对应于块200内容的频谱分量。具体地,变换块204的水平轴对应于一个轴,沿着该轴水平方向的频谱频率单调增大,垂直轴对应于一个轴,沿着该轴垂直方向的空间频率单调增大,在其中dc分量变换系数
被置于角落中,在这里,示例性地置于块204的左上角,使得在右下角,放置对应于水平以及垂直方向的最高频率的变换系数206。忽略空间方向,某变换系数206所属的空间频率,大体上自左上角增加至右下角。通过逆变换t-1
,变换块204自频谱域再被变换至空间域,以便再获得块200的复制块208。在变换期间无量化/损失介入的情况下,重建将是完美的。
[0056]
已如在上面所提到的,从图6可看到,块200的较大的块尺寸增加产生的频谱表示204的频谱分辨率。另一方面,量化噪声趋于在整个块208延伸,因此,在块200内的突发的以及非常小范围的事物,由于量化噪声,则趋于导致再变换块的相对于原块200的误差。然而,使用较大的块的主要优点是,一方面的显著,即,非零(量化)变换系数的数目与另一方面的非显著的变换系数的数目之间的比率,相较于较小的块,在较大的块之内可能被减少,从而能够获得较好的编码效率。换句话说,通常地,显著变换系数,即,不被量化为零值之变换系数,稀疏地被分配在变换块204上。由于这点,依照将在下面更详细被说明之实施例,显著变换系数的位置经由显著性图被以信号告知在数据流内。此外,显著变换系数的数值,即,变换系数被量化的情况下的变换系数水平,在数据流内传送。
[0057]
因此,根据本技术的实施方式,用于解码数据流的显著性图或用于解码数据流的显著性图和对应的显著变换系数值的装置可如图7中所示出地被实施,并且在上面所提到的各熵解码器,即,解码器50以及熵解码器150,可包括图7中所示出的装置。
[0058]
图7的装置包括图/系数熵解码器250以及关联器252。图/系数熵解码器250被连接至输入254,表示显著性图的语法元素和显著变换系数值在输入254进入。如下面更详细地描述的,有关于其中描述一方面的显著性图的语法元素以及另一方面的显著变换系数值进入图/系数熵解码器250的顺序存在着不同的可能性。显著性图语法元素可置于对应的水平之前,或两者可交叉。然而,初步地,假设表示显著性图的语法元素在显著变换系数值(水平)之前,以至于映射图/系数熵解码器250首先解码显著性图,接着解码显著变换系数的变换系数水平。
[0059]
由于图/系数熵解码器250顺序解码表示显著性图的语法元素和显著变换系数值,所以关联器(associator)252被配置为将这些顺序解码的语法元素/数值关联至变换块256内的位置。其中,关联器252将依次解码的表示显著性图的语法元素和显著变换系数水平关联至变换块256的位置的扫描次序,遵循在变换块256位置中的一维扫描次序,其是相同于在编码侧使用以引导这些元素进入数据流的顺序。下面将更详细地叙述,对于显著性图语法元素的扫描次序也可以等于用于显著系数值的顺序,或不等于。
[0060]
图/系数熵解码器250可访问变换块256上到目前为止可供使用的信息(如由关联器252产生的达到目前将被解码的语法元素/水平),以便设定对如由虚线258指示的目前将被解码的语法元素/水平进行熵解码的概率估计上下文(context)。例如,关联器252可登录到目前为止从顺序关联的语法元素收集的信息,例如,水平本身或关于下列的信息,如关于是否显著变换系数位于相应位置,或关于是否并不知道其中图/系数熵解码器250访问该内存的变换块256的相应位置。刚提及的内存没有示出于图7中,但是参考符号256也可以指示该内存,只要内存或登录缓冲器将用于存储到目前为止利用关联器252以及熵解码器250所获得的初步信息。因此,图7通过叉号示出由先前解码的表示显著性图的语法元素获得的显著变换系数的位置,“1”将指示在相应位置的显著变换系数的显著变换系数水平已被解码,并且是1。在显著性图语法元素在数据流中在显著值之前的情况下,在解码相应值时,在输
入“1”之前,叉号应当已经被记录在内存256内“1”的位置(这情况将表示整个显著性图)。
[0061]
下面的描述集中在编码变换系数块或显著性图的特定实施方式,这些实施方式是可容易地变换至上面说明的实施方式。在这些实施方式中,可以针对每个变换块发送二进制语法元素coded_block_flag,其以信号告知该变换块是否包含任何显著变换系数水平(即,为非零的变换系数)。如果该语法元素指示这些显著变换系数水平存在,则这些显著性图被编码,即,接着进行。显著性图指明,如在上面所指示的,哪个变换系数水平具有非零值。显著性图编码涉及二进制语法元素significant_coeff_flag的编码,其中各二进制语法元素significant_coeff_flag指明对于各个关联系数位置对应的变换系数水平是否不等于零值。以某扫描次序进行编码,其可根据到目前为止被确认为显著的显著系数位置而在显著性图编码期间改变,如在下面更详细的描述的。进一步地,显著性图编码涉及二进制语法元素last_significant_coeff_flag的编码,其中,二进制语法元素last_significant_coeff_flag将significant_coeff_flag序列散布在其位置上,其中significant_coeff_flag以信号告知显著系数。如果significant_coeff_flag二进制值等于1,即,如果非零值变换系数水平存在于该扫描位置中,则编码进一步的二进制语法元素last_significant_coeff_flag。该二进制值指示目前的显著变换系数水平是否为在块内部的最后的显著变换系数水平或进一步的显著变换系数水平是否依扫描次序跟随在其后。如果last_significant_coeff_flag指示出无进一步的显著变换系数跟随,则对于指定用于块的显著性图,无进一步的语法元素被编码。可选地,显著系数位置的数目可在序列significant_coeff_flag编码之前在数据流内用信号表明。在下一个步骤中,编码显著变换系数水平值。如上面所描述的,可选地,水平的传送可与显著性图的传送交错进行。显著变换系数水平值以进一步的扫描次序被编码,其实例在下面描述。使用下面的三个语法元素。二进制语法元素coeff_abs_greater_one指示显著变换系数水平的绝对值是否大于1。如果二进制语法元素coeff_abs_greater_one指示绝对值大于1,则发送进一步的语法元素coeff_abs_level_minus_one,语法元素coeff_abs_level_minus_one指明变换系数水平减1的绝对值。最后,对于各显著变换系数水平,编码指明变换系数数值的符号的二进制语法元素coeff_sign_flag。
[0062]
下面描述的实施方式可进一步降低位率并且因此增大编码效率。为了达成这点,这些实施方式对于有关变换系数的语法元素的上下文模型使用特定方法。具体地,对于语法元素significant_coeff_flag、last_significant_coeff_flag、coeff_abs_greater_one以及coeff_abs_level_minus_one,可以使用新的上下文模型选择。更进一步地,描述在显著性图(指定非零变换系数水平的位置)的编码/解码期间的扫描的自适应切换。关于必须提到的语法元素的含义,可参考本技术的上述部分。
[0063]
说明显著性图的significant_coeff_flag以及last_significant_coeff_flag语法元素的编码,基于已经编码的扫描位置的限定的邻近区域的新的上下文模型以及自适应扫描而被改进。这些新的概念使得显著性图的编码更高效(即,对应的位率降低),尤其对于大的块尺寸而言。
[0064]
下面概述的实施方式的一个方面是,在显著性图编码/解码期间,扫描次序(即,变换系数值的块到变换系数水平的有序集合(向量)上的映射)基于显著性图的已经被编码/被解码的语法元素的值而被调整。
[0065]
在优选实施方式中,扫描次序在二个或更多个预定扫描模式之间被自适应地切换。在优选实施方式中,切换可仅仅在某些预定扫描位置发生。在本发明的进一步的优选实施方式中,扫描次序在二个预定扫描模式之间自适应地被切换。在优选实施方式中,在二个预定扫描模式之间的切换可仅仅发生在某些预定扫描位置。
[0066]
在扫描模式之间切换的优点是降低位率,降低位率是由于有较少的编码语法元素数目的结果。作为直观实例并参照图6,因为残差块主要包含水平或垂直结构,通常的情况是显著变换系数的值——特别是对于大的变换块——被集中在块边沿270、272之一。利用最常用的曲折扫描274,其存在大约为0.5的概率,其中最后显著系数被遇到的曲折扫描的最后对角线次扫描从显著系数不被集中侧开始。该情况下,对于等于零的变换系数水平的大量语法元素必须在到达最后非零变换系数值之前被编码。如果对角线次扫描经常在显著变换系数水平被集中的侧开始,则这可被避免。
[0067]
下面更详细说明本发明优选实施方式。
[0068]
如在上面所提及的,也是对于大的块尺寸,优选其保有适度小的上下文模型数目,以便使上下文模型能够快速自适应并且能够提供高的编码效率。因此,特定上下文应被使用于一个以上的扫描位置。但是由于显著变换系数水平通常被集中在变换块的某些区域中(这集中情况可能是因通常出现在,例如,残差块中的某些主要结构的结果),分配相同上下文至一些连续的扫描位置的设想,如对于h.264中的8x8块的处理,通常是不适合的。对于设计上下文的选择,可使用上面提到的显著变换系数水平往往被集中在变换块某些区域中的观察结果。在下面,将说明这观察结果可被利用的设想。
[0069]
在一个优选实施方式中,大的变换块(例如,大于8x8)被分割成为一些矩形子块(例如,分成16个子块)并且这些子块的每个被关联至用以编码significant_coeff_flag以及last_significant_coeff_flag的分别的上下文模型(其中不同的上下文模型被用于significant_coeff_flag以及last_significant_coeff_flag)。对于significant_coeff_flag以及last_significant_coeff_flag,分割成为子块可以不同。相同的上下文模型可被用于位于特定子块中的所有扫描位置。
[0070]
在进一步的优选实施方式中,大的变换块(例如,大于8x8)可被分割成为一些矩形及/或非矩形子区域并且这些子区域中的每个被关联至用以编码significant_coeff_flag和/或last_significant_coeff_flag的分别的上下文模型。对于significant_coeff_flag和last_significant_coeff_flag,分割成为子区域可以不同。相同的上下文模型可被用于位于特定子区域中的所有扫描位置。
[0071]
在进一步的优选实施方式中,用以编码significant_coeff_flag和/或last_significant_coeff_flag的上下文模型,基于在目前扫描位置的预定空间邻近区域中已被编码的符号而被选择。对于不同的扫描位置,预定邻近区域可以是不同的。在优选实施方式中,基于仅计算已被编码的显著性指示的目前扫描位置的预定空间邻近区域中的显著变换系数水平的数目,上下文模型被选择。
[0072]
下面将更详细地说明本发明的优选实施方式。
[0073]
如上面所提及的,对于大的块尺寸,常见的上下文模型,通过对于coeff_abs_greater_one和coeff_abs_level_minus_one语法元素的单一上下文模型而编码大量的二进制值(其通常具有不同的概率)。为了避免大块尺寸的缺点,依照一实施方式,大块可被分
割为特定尺寸的小正方形或矩形子块,并且分别的上下文模型被应用于各个子块。此外,可使用多组上下文模型,其中对于各个子块,这些上下文模型中的一个基于先前被编码的子块的统计数据的分析被选择。在本发明优选实施方式中,使用在先前被编码的相同块的子块中大于2的变换系数的数(即,coeff_abs_level_minus_1》1),以得到当前子块的上下文模型组。对于coeff_abs_greater_one以及coeff_abs_level_minus_one语法元素的上下文模型的这些增强,特别对于大的块尺寸而言,使得对两语法元素的编码更高效。在优选实施方式中,子块的块尺寸是2x2。在另外的优选实施方式中,子块的块尺寸是4x4。
[0074]
在第一步骤中,大于预定尺寸的块可被分割为特定尺寸的较小的子块。绝对变换系数水平的编码处理程序,使用扫描(其中不同的扫描可被用于不同的块)以将正方形或矩形块的子块映射至有序子块组(向量)上。在优选实施方式中,子块使用曲折扫描处理;子块内部的变换系数水平以逆向曲折扫描处理,即,自属于垂直以及水平方向的最高频率的变换系数装载至有关两方向的最低频率系数的扫描。在本发明另外的优选实施方式中,逆向曲折扫描被用于编码子块并且被用于编码子块内部的变换系数水平。在本发明另外的优选实施方式中,使用被用于编码显著性图(参看上述)的相同的自适应扫描处理变换系数水平的整个块。
[0075]
大的变换块到子块的分割避免对于大的变换块的多数二进制值只使用一个上下文模型的问题。子块的内部,目前技术的上下文模型(如于h.264中所指明)或固定的上下文可根据子块实际尺寸来使用。此外,对于这些子块的统计数据(根据概率模型)是不同于具有相同尺寸的变换块的统计数据。通过扩展coeff_abs_greater_one以及coeff_abs_level_minus_one语法元素的上下文模型组可揭示这些性质。可提供多组上下文模型,并且对于各个子块,可基于目前变换块的先前被编码的子块或在先前被编码的变换块中的统计数据而选择这些上下文模型组中的一个。在本发明的优选实施方式中,基于相同块的先前被编码的子块统计数据得到所选择的上下文模型组。在本发明另外的优选实施方式中,基于先前被编码的块的相同子块统计数据得到所选择的上下文模型组。在优选实施方式中,上下文模型组数目被设定为等于4,而在另外的优选实施方式中,上下文模型组数目被设定为等于16。在优选实施方式中,被用于得到上下文模型组的统计数据是在先前被编码的子块中大于2的绝对变换系数水平的数目。在另一优选实施方式中,在显著系数的数目以及具有绝对值大于2的变换系数水平的数目之间,被用于得到上下文模型组的统计数据是不同。
[0076]
显著性图的编码可如下面所述地进行,即,通过扫描次序的自适应切换。
[0077]
在优选实施方式中,用以编码显著性图的扫描次序通过二个预定扫描模式之间的切换被调适。扫描模式之间的切换可仅仅在某些预定扫描位置被完成。扫描模式是否被切换的决定取决于已被编码/被解码的显著性图语法元素值。在优选实施方式中,两预定扫描模式指定具有对角线次扫描的扫描模式,相似于曲折扫描的扫描模式。这些扫描模式被示出在图8中。两扫描模式300和302由对于从左下方到右上方的对角线或反之亦然的一些对角线次扫描所组成。对于两预定扫描模式的从左上方到右下方的对角线次扫描的扫描(未在图形中被示出)被完成。但是对角线次扫描内部的扫描不同(如图中所示)。对于第一扫描模式300,对角线次扫描被从左下方到右上方扫描(图8的左方图示),并且对于第二扫描模式302,对角线次扫描被从右上方到左下方扫描(图8的右方图示)。在实施方式中,显著性图的编码以第二扫描模式开始。在编码/解码语法元素的同时,显著变换系数值的数目利用两
个计数器c1和c2计算。第一计数器c1对位于变换块左下部分的显著变换系数的数目计数;即,当对于变换块内部的水平坐标x小于垂直坐标y显著变换系数水平被编码/解码时,计数器增加1。第二计数器c2对位于变换块右上部分的显著变换系数计数;即,当对于变换块内的水平坐标x大于垂直坐标y显著变换系数水平被编码/解码时,计数器增加1。计数器的自适应可利用图7的关联器252执行并且可利用下列公式描述,其中t表示扫描位置索引并且两计数器以零初始化:
[0078][0079][0080]
在各个对角线次扫描的末端,利用关联器252决定第一预定扫描模式300还是第二预定扫描模式302被用于下一个对角线次扫描。该决定取决于计数器c1和c2的值。当对于变换块的左下部分的计数器值大于对于左下部分的计数器值时,使用扫描从左下方到顶右上方的对角线次扫描的扫描模式;否则(对于变换块的左下部分的计数器值小于或等于对于左下部分的计数器值),使用扫描从右上方到左上方扫描的对角线次扫描的扫描模式。该决定可利用下列公式表示:
[0081][0082]
应注意到,上面描述的本发明实施方式可容易地被应用至其它扫描模式。作为一实例,被使用于h.264中的像场宏块的扫描模式也可被分解成为次扫描。在进一步的优选实施方式中,所给定但却是任意的扫描模式被分解成为次扫描。对于各个次扫描,定义两个扫描模式:一个是从左下方到右上方,一个是从右上到到左下方(基本扫描方向)。此外,两个计数器被引入,其对次扫描内部的第一部分(接近于变换块的左下方边界)以及第二部分(接近于变换块的右上方边界)的显著系数的数目计数。最后,在各个次扫描的结束,决定(根据计数器数值)下一个次扫描是从左下方到右上方还是从右上方到做下方地扫描。
[0083]
在下面,将描述关于熵解码器250如何建立上下文模型的实施例。
[0084]
在优选实施方式中,对于significant_coeff_flag的上下文模型将如下所述地被处理。对于4x4块,上下文模型如在h.264中所说明地被处理。对于8x8块,变换块被分解成为16个2x2取样的子块,并且这些子块中的每个被关联至分别的上下文。注意到,这思路同时也可被扩展到较大的块尺寸、不同的子块数目、以及如上面所描述的非矩形子区域。
[0085]
在进一步的优选实施方式中,对于较大的变换块(例如,对于大于8x8之块)的上下文模型选择基于预定邻近区域(变换块内部)中已被编码的显著变换系数的数目。对应于本发明优选实方式的邻近区域的限定的实例将在图9中描述。有圆圈围绕的叉号是可供使用的邻近区,其通常被考虑用于评估,有三角形围绕的十字形记号是邻近区,其可基于当前扫描位置和当前扫描方向被评估:
[0086]
·
如果当前扫描位置位于2x2的左方角落304的内部,则分别的上下文模型被用于各个扫描位置(图9,左方图示)。
[0087]
·
如果当前扫描位置不是位于2x2的左方角落内部并且不在变换块第一列或第一
行上,则在图9右方所示出的邻近区被用于评估无任何东西围绕着它的当前扫描位置“x”的邻近区域中的显著变换系数的数目。
[0088]
·
如果无任何东西围绕着它的当前扫描位置“x”落在变换块第一列内,则使用图10右方图示中所指明的邻近区。
[0089]
·
如果当前扫描位置“x”落在块的第一行中,则使用图10左方图示中所指明的邻近区。
[0090]
换句话说,解码器250可被配置为通过利用上下文通过上下文自适应熵解码顺序地抽取显著性图语法元素,其中这些上下文依据显著变换系数根据先前被抽取的且别关联的显著性图语法元素所在的若干位置而各自被选择,这些位置被限定为位于相应的当前显著性图语法元素被关联的位置(图9右手侧与图10两侧中的“x”、以及图9左手侧的任何记号位置)的邻近区域中的位置。如所示出,与相应的当前语法元素关联的位置的邻近区域,可仅包含下列的位置:与相应的显著性图语法元素关联的位置以最大在垂直方向上的一个位置和/或在水平方向上的一个位置分开的或直接邻接的位置。可选地,仅与相应的当前语法元素直接邻接的位置可被考虑。同时地,变换系数块尺寸可等于或大于8x8位置。
[0091]
在优选实施方式中,用于编码的特定significant_coeff_flag的上下文模型基于限定的邻近区域中已被编码的显著变换系数水平数目而选择。在此,可供使用上下文模型的数目可以小于在限定的邻近区域中的显著变换系数水平数目的可能值。编码器和解码器可包含用以将限定的邻近区域中的显著变换系数水平数目映射至上下文模型索引上的列表(或不同的映射图机制)。
[0092]
在进一步的优选实施方式中,所选择的上下文模型索引取决于限定的邻近区域中的显著变换系数水平数目,并且取决于作为被使用的邻近区域类型或扫描位置或对于扫描位置的量化值的一个或多个附加参数。
[0093]
对于last_significant_coeff_flag的编码,可以使用如对于significant_coeff_flag的相似的上下文模型。然而,对于last_significant_coeff_flag的概率测量主要取决于变换块的当前扫描位置至左上方角落的距离。在优选实施方式中,用于编码last_significant_coeff_flag的上下文模型基于当前扫描位置所在的扫描对角线而选择(即,在上面图8的实施方式的情况下,其基于x+y选择,其中x以及y各别表示变换块内部的扫描位置的水平和垂直位置,或基于在当前的次扫描和左上方dc位置之间有多少的次扫描(例如,次扫描索引(index)减去1))。在本发明的优选实施方式中,相同的上下文被用于不同的x+y值。距离量测,即,x+y或次扫描索引以某一方式(例如,通过量化x+y或次扫描索引)被映射到上下文模型组上,其中对于距离量测的可能值之数目大于用于编码last_significant_coeff_flag的可用上下文模型的数目。
[0094]
在优选实施方式中,不同的上下文模型结构被用于不同尺寸的变换块。
[0095]
下面将说明绝对变换系数水平的编码。
[0096]
在优选实施方式中,子块尺寸是2x2并且子块内部的上下文模型不可用,即,单一上下文模型被用于2x2子块内部的所有变换系数。仅大于2x2的块可通过次分割处理发生作用。在本发明进一步的优选实施方式中,子块尺寸是4x4并且子块内部的上下文模型如在h.264中地被完成;仅大于4x4的块通过次分割处理发生作用。
[0097]
关于扫描次序,在优选实施方式中,曲折扫描320被用于扫描变换块256的子块
322,即,沿着大体上增大频率的方向,而子块内部的变换系数则以逆向曲折扫描324被扫描(图11)。在本发明进一步的优选实施方式中,子块322以及子块322内部的变换系数水平都使用逆向曲折扫描方式被扫描(如图11中的图示,其中箭头320是反向的)。在另外的优选实施方式中,与用于编码显著性图相同的自适应扫描被用于处理变换系数水平,其中自适应决定是同样的,以至于完全地相同的扫描被使用于显著性图的编码以及变换系数水平数值的编码。应注意到,扫描其本身通常不取决于所选择的统计数据或上下文模型组数目,也不取决于使子块内部的上下文模型成为动作或成为不动作的决定。
[0098]
接着将说明对于用于系数水平的上下文模型的实施方式。
[0099]
在优选实施方式中,子块的上下文模型相似于已在上面描述的对于h.264中的4x4块的上下文模型。被用于编码coeff_abs_greater_one语法元素和coeff_abs_level_minus_one语法元素的第一二进制值的上下文模型数目等于五,例如,对于二个语法元素使用不同的上下文模型组。在进一步的优选实施方式中,子块内部的上下文模型不动作并且在各个子块的内部仅一个预定上下文模型被使用。对于这两实施方式,用于子块322的上下文模型组在预定数目的上下文模型组中选择。对于子块322的上下文模型组的选择基于一个或多个已被编码的子块的某些统计数据。在优选实施方式中,用于选择对于子块的上下文模型组的统计数据是从相同块256中一个或多个已被编码的子块获得的。下面将说明统计数据如何被用于得到所选择的上下文模型组。在进一步的优选实施方式中,统计数据从具有相同块尺寸的先前被编码的块中的相同子块(例如,图2b中块40a和40a’)获得。在本发明另外的优选实施方式中,统计数据从相同块中限定的邻近子块获得,其取决于对于子块选择的扫描。同时,重要地应注意到,统计数据来源应无关于扫描次序,以及如何产生统计数据以得到上下文模型组。
[0100]
在优选实施方式中,上下文模型组数目等于四,在另外的优选实施方式中,上下文模型组数目等于16。通常,上下文模型组数目不是固定的并且将依照所选择的统计数据调整。在优选实施方式中,用于子块322的上下文模型组基于一个或多个已被编码的子块中大于2的绝对变换系数水平数目得到。对于上下文模型组的索引(index)通过将参考子块中大于2的绝对变换系数水平数目映射至一组预定上下文模型索引上来决定。该映射可通过量化大于2的绝对变换系数水平数目或通过预定列表实施。在进一步的优选实施方式中,对于子块的上下文模型组基于在一个或多个已被编码的子块中的显著变换系数水平数目与大于2的绝对变换系数水平数目之间的差得到。对于上下文模型组的索引通过将该差值映射到一组预定上下文模型索引上而被决定。该映射可通过量化在显著变换系数水平数目与大于2的绝对变换系数水平数目之间的差或通过预定列表而被实施。
[0101]
在另外的优选实施方式中,当相同的自适应扫描被用于处理绝对变换系数水平和显著性图时,相同块中的子块的部分统计数据可被使用以得到对于当前子块的上下文模型组。或者,如果可能的话,在先前被编码的变换块中的先前被编码的子块的统计数据可被使用。其表示,例如,替代使用用于得到上下文模型的子块中大于2的绝对变换系数水平的绝对数目,使用已被编码的大于2的绝对变换系数水平数目乘以子块中的变换系数数目与子块中已被编码的变换系数数目比的数值;或替代使用在子块中显著变换系数水平数目与大于2的绝对变换系数水平数目之间的差,使用在子块中已被编码的显著变换系数水平数目与大于2的已被编码的绝对变换系数水平数目乘以子块中变换系数数目与已被编码的变换
系数数目的比之间的差。
[0102]
对于子块内部的上下文模型,基本上,可以采用用于h.264的现有技术的上下文模型的反向(inverse)。这表示,当相同的自适应扫描被用于处理绝对变换系数水平以及显著性图时,变换系数水平基本上以正向扫描次序被编码,以替代如h.264中的反向的扫描次序。因此,上下文模型切换因而必须被调整。根据实施方式,变换系数水平的编码以用于coeff_abs_greater_one和coeff_abs_level_minus_one语法元素的第一上下文模型开始,并且当由于最后的上下文模型切换两个等于零的coeff_abs_greater_one语法元素已被编码时,则其被切换至组中的下一个上下文模型。换句话说,上下文选择取决于扫描次序中大于零的已被编码的coeff_abs_greater_one语法元素数目。对于coeff_abs_greater_one以及对于coeff_abs_level_minus_one的上下文模型的数目可以与h.264中相同。
[0103]
因此,上面实施方式可被应用于数字信号处理的领域,具体地,应用于图像和视频解码器和编码器。具体地,上面的实施方式用对于有关采用概率模型的熵编码器被编码的变换系数的语法元素的改进的上下文模型,使能有关于基于块的图像和视频编解码器中的变换系数的语法元素的编码。与现有技术相比,尤其对于大的变换块,可以实现编码效率提高。
[0104]
虽然一些方面已在装置的上下文中描述,应明白,这些方面同时也表示对应方法的描述,其中块或组件对应于方法步骤或方法步骤的特征。相似地,在方法步骤的上下文中描述的方面也表示对应的装置的对应块或项或特征的描述。
[0105]
用以分别表示变换块或显著性图的创造性编码信号,可被储存在数字储存介质上或可在传输介质(例如,无线发送介质或有线的发送介质(例如,因特网))上传输。
[0106]
根据某些实施需求,本发明的实施方式可以以硬件或软件实施。实施可使用数字储存介质进行,例如,软磁盘、dvd、蓝光盘、cd、rom、prom、eprom、eeprom或flash内存,使电子可读取控制信号储存在其上,其与可编程计算机系统合作(或能够合作)使得相应的方法被执行。因此,数字储存介质可以是计算机可读取的。
[0107]
根据本发明一些实施方式包括具有电子可读取控制信号的数据载体,其能够与可编程计算机系统合作,从而执行在此处描述的方法。
[0108]
大体上,本发明实施方式可被实施为具有程序代码的计算机程序产品,当该计算机程序产品在计算机上执行时,程序代码可操作以执行各方法中的一个。该程序代码,例如,可被存储在机器可读载体上。
[0109]
其它实施方式包括用以执行在此描述的各种方法之一的计算机程序,其被存储在机器可读取载体上。
[0110]
换句话说,本发明方法的实施方式,因此,是具有程序代码的计算机程序,当该计算机程序在计算机上执行时,用以执行本文描述的各种方法之一。
[0111]
本发明方法进一步的实施方式,因此是数据载体(或数字存储介质、或计算机可读取介质),该数据载体包括被记录在其上而用以执行本文描述的各种方法之一的计算机程序。
[0112]
本发明方法进一步的实施方式,因此,是表示用以执行本文描述的各种方法之一的计算机程序的数据流或信号序列。该数据流或信号序列,例如,可被配置为经由数据通信连接,例如,经由因特网,而被传送。
[0113]
进一步的实施方式包括处理构件,例如,计算机,或可编程逻辑装置,其被配置为或适于进行本文中描述的各种方法之一。
[0114]
进一步的实施方式包括计算机,其具有被安装在其上而用以执行在本文中说明的各种方法之一的计算机程序。
[0115]
在一些实施方式中,可编程逻辑装置(例如,场可程序门阵列),可用以执行本文描述的各种方法的一些或所有的功能。在一些实施方式中,场可程序门阵列可与微处理器配合,以便执行于本文描述的各种方法之一。大体上,这些方法优选地可通过任何硬件装置执行。
[0116]
上面所描述的实施方式仅作为本发明原理示出。本领域技术人员应了解,本文所描述的本发明的布置以及细节可具有不同的修改和变化。因此,本发明将仅通过待决的申请权利要求的范围限定,而不由本文经由实施方式的描述以及说明所呈现的特定细节限定。
[0117]
本发明还可以如下方式配置。
[0118]
1.一种用于解码来自数据流的指示变换系数块内的显著变换系数的位置的显著性图的装置,所述装置包括:
[0119]
解码器(250),被配置为从所述数据流顺序抽取第一类型语法元素,所述第一类型语法元素指示,对于所述变换系数块(256)内的关联位置,至少关于显著变换系数还是非显著变换系数位于相应的位置;以及
[0120]
关联器(252),被配置为在所述变换系数块的位置中以扫描次序将顺序提取的所述第一类型语法元素顺序地关联至所述变换系数块的位置,其取决于先前被抽取的并且被关联的第一类型语法元素所指示的所述显著变换系数的位置。
[0121]
2.根据项1所述的装置,其中,所述解码器(250)进一步被配置为,基于所述数据流中的信息且无关于该先前被抽取的并且被关联的第一类型语法元素所指示的所述非显著变换系数的若干位置,识别关于所述变换系数块中的最后显著变换系数是否位于与当前抽取的第一类型语法元素相关联的位置,其中,所述当前抽取的第一类型语法元素指示显著变换系数位于该位置。
[0122]
3.根据项1或2所述的装置,其中,所述解码器(250)进一步被配置为,在指示显著变换系数位于相应的关联位置的第一类型语法元素和紧接于其后的第一类型语法元素之间,从比特流中抽取第二类型语法元素,其中,所述第二类型语法元素指示,对于显著变换系数所在的所述关联位置,在所述相应的关联位置是否有所述变换系数块中的最后显著变换系数。
[0123]
4.根据项1至3中任一项所述的装置,其中,所述解码器(250)进一步被配置为,在所述变换系数块的所有第一类型语法元素的抽取之后,通过上下文自适应熵解码,从所述数据流连续地抽取所述变换系数块内的所述显著变换系数的值,其中,所述关联器(250)被配置为,在所述变换系数块的位置中以预定的系数扫描次序将所述顺序抽取的值与所述显著变换系数的位置顺序地关联,根据该结果,所述变换系数块使用子块扫描次序(320)以变换系数块(256)的子块(322)的方式被扫描,辅助地,以位置子扫描次序(324)扫描所述子块(322)内的变换系数的位置,其中,所述解码器被配置为,在对所述显著变换系数值的值顺序地进行上下文自适应熵解码时,使用从若干上下文的多个组中选择的若干上下文的选择
组,所述选择组的选择基于已经以子块扫描次序(320)被遍历的变换系数块的子块内的变换系数的值,或基于在相等尺寸的先前被解码的变换系数块内共同地点子块的变换系数的值而对每个子块进行。
[0124]
5.根据项1至4中任一项所述的装置,其中,所述解码器(250)被配置为通过使用上下文通过上下文自适应熵解码顺序抽取所述第一类型语法元素,所述上下文依据,显著变换系数根据先前被抽取的并被关联的第一类型语法元素而位于的若干位置,而对于每个所述第一类型语法元素被各自地选择,所述若干位置在与相应的第一类型语法元素关联的位置的邻近区域内。
[0125]
6.根据项5所述的装置,其中,所述解码器进一步地被配置为使得与相应的第一类型语法元素相关联的位置的邻近区域仅包括:与相应的第一类型语法元素关联的位置直接邻接的位置,或与相应的第一类型语法元素关联的位置以最大在垂直方向的一个位置和/或在水平方向上的一个位置分开的或直接邻接的位置,其中,所述变换系数块的尺寸等于或大于8x8位置。
[0126]
7.根据项5或6所述的装置,其中,所述解码器进一步被配置为,在以与相应的第一类型语法元素关联的位置的邻近区域中的若干可用位置加权的情况下,将在与相应的第一类型语法元素关联的位置的邻近区域内显著变换系数根据先前被抽取的且被关联的第一类型语法元素而位于的位置的数目,映射至预定的一组可能上下文索引中的上下文索引。
[0127]
8.根据项1至7中任一项所述的装置,其中,所述关联器(252)进一步地被配置为,将被顺序抽取的第一类型语法元素顺序地关联至所述变换系数块的位置,其沿着在所述变换系数块的第一对邻接侧和所述变换系数块的第二对邻接侧之间延伸的子路序列进行,其中,水平方向上最低频率的位置和垂直方向上最高频率的位置分别沿所述变换系数块的第一对邻接侧放置,所述垂直方向上最低频率的位置和水平方向上最高频率的位置分别沿所述变换系数块的第二对邻接侧放置,所述子路线与垂直和水平两方向上的最低频率的位置具有增加的距离,其中,所述关联器(252)被配置为决定方向(300,302),沿着该方向所述被顺序抽取的第一类型语法元素基于先前次扫描内的显著变换系数的位置被关联至所述变换系数块的位置。
[0128]
9.一种用于解码来自数据流的指示变换系数块内的显著变换系数的位置的显著性图的装置,所述装置包括:
[0129]
解码器(250),被配置为从所述数据流抽取指示所述变换系数块内的显著变换系数的位置的显著性图,然后抽取所述变换系数块内的所述显著变换系数的值,在抽取所述显著性图时,通过上下文自适应熵解码从所述数据流顺序地抽取第一类型语法元素,所述第一类型语法元素指示,对于与变换系数块内的关联位置,关于显著变换系数还是非显著变换系数位于相应的位置;以及
[0130]
关联器(250),被配置为在所述变换系数块的位置中以预定扫描次序,将顺序抽取的第一类型语法元素顺序地关联至所述变换系数块的位置,
[0131]
其中,所述解码器被配置为,在对所述第一类型语法元素进行上下文自适应熵解码时,使用上下文,所述上下文依据显著变换系数根据先前被抽取并被关联的第一类型语法元素而位于的若干位置,而对于每个所述第一类型语法元素被各自地选择,所述若干位置在与当前第一类型语法元素关联的位置的邻近区域内。
[0132]
10.根据项9所述的装置,其中,所述解码器(250)进一步被配置为使得与相应的第一类型语法元素相关联的位置的邻近区域仅包括:与相应的第一类型语法元素关联的位置直接邻接的位置,或与相应的第一类型语法元素关联的位置以最大在垂直方向的一个位置和/或在水平方向上的一个位置分开的或直接邻接的位置,其中,所述变换系数块的尺寸等于或大于8x8位置。
[0133]
11.根据项9或10所述的装置,其中,所述解码器(250)进一步被配置为,在以与相应的第一类型语法元素关联的位置的邻近区域中的若干可用位置加权的情况下,将在与相应的第一类型语法元素关联的位置的邻近区域内显著变换系数根据先前被抽取的且被关联的第一类型语法元素而位于的位置的数目,映射至预定的一组可能上下文索引中的上下文索引。
[0134]
12.一种用于解码变换系数块的装置,所述装置包括:
[0135]
解码器(250),被配置为从所述数据流抽取指示所述变换系数块内的显著变换系数的位置的显著性图,然后抽取所述变换系数块内的所述显著变换系数的值,在抽取所述显著变换系数的值时,通过上下文自适应熵解码顺序地抽取所述值;以及
[0136]
关联器(252),被配置为在所述变换系数块的位置中以预定的系数扫描次序将所述顺序抽取的值与所述显著变换系数的位置顺序地关联,根据该结果,所述变换系数块使用子块扫描次序(320)以变换系数块(256)的子块(322)的方式被扫描,辅助地,以位置子扫描次序(324)扫描所述子块内的变换系数的位置,
[0137]
其中,所述解码器(250)被配置为,在对所述显著变换系数值的值顺序地进行上下文自适应熵解码时,使用从若干上下文的多个组中选择的若干上下文的一选择组,所述选择组的选择基于已经以子块扫描次序被遍历的变换系数块的子块内的变换系数的值,或基于在相等尺寸的先前被解码的变换系数块内共同地点子块的变换系数的值而对每个子块进行。
[0138]
13.根据项12所述的装置,其中,所述解码器被配置为使得多个上下文组的上下文的数目大于一,并且被配置为,在对于相应的子块使用所述数目的上下文的选择组对子块内的所述显著变换系数值的值顺序地进行上下文自适应解码时,将所述数目的上下文的所述选择组的上下文唯一地指定到相应的子块内的位置。
[0139]
14.根据项12或13所述的装置,其中,所述关联器(252)被配置为使得所述子块扫描次序以曲折方式从包括在垂直方向上和水平方向上最低频率的位置的子块进行到包括在垂直和水平两个方向上最高频率的位置的子块,同时所述位置次扫描次序在各子块中以曲折方式从相应子块内有关在垂直方向上和水平方向上的最高频率的位置进行到所述相应子块内有关在垂直和水平两个方向上最低频率的位置。
[0140]
15.一种基于变换的解码器,所述解码器被配置为使用根据项1至11中任一项所述的对来自数据流的指示变换系数块内的显著变换系数的位置的显著性图进行解码的装置(150)对所述变换系数块解码,并对所述变换系数块执行(152)从频谱域到空间域的变换。
[0141]
16.一种预测性解码器,包括:
[0142]
基于变换的解码器(150,152),被配置为使用根据项1至11中任一项所述的对来自数据流的指示变换系数块内的显著变换系数的位置的显著性图进行解码的装置(150)对所述变换系数块解码,并对所述变换系数块执行(152)从频谱域到空间域的变换以获得残差
块;
[0143]
预测器(156),被配置为为表示空间取样信息信号的信息取样阵列的块提供预测;以及
[0144]
组合器(154),被配置为组合所述块的所述预测和所述残差块以重建信息取样阵列。
[0145]
17.一种用以将指示变换系数块内的显著变换系数的位置的显著性图编码为数据流的装置,所述装置被配置为通过熵编码将第一类型语法元素顺序地编码为数据流,所述第一类型语法元素指示,对于所述变换系数块内的关联位置,至少关于显著变化系数还是非显著变换系数位于相应的位置,其中,所述装置进一步被配置为,在所述变换系数块的位置中以扫描次序将所述第一类型语法元素编码为所述数据流,其取决于通过先前编码的第一类型语法元素所指示的所述显著变换系数的位置。
[0146]
18.一种用以将指示变换系数块内的显著变换系数的位置的显著性图编码为数据流的装置,所述装置被配置为编码指示所述变换系数块内的显著变换系数的位置的显著性图,然后编码所述变换系数块内的所述显著变换系数的值成为数据流,在编码所述显著性图时,通过上下文自适应熵编码将第一类型语法元素顺序编码为所述数据流,所述第一类型语法元素指示,对于所述变换系数块内的关联位置,关于是显著变化系数还是非显著变换系数位于相应的位置,其中,所述装置进一步被配置为在所述变换系数块的位置中以预定的扫描次序将所述第一类型语法元素顺序地编码为所述数据流,其中所述装置被配置为,在对每个所述第一类型语法元素进行上下文自适应熵编码时使用上下文,所述上下文依据显著变换系数位于的并且与先前被编码为数据流的第一类型语法元素关联的若干位置,而对于所述第一类型语法元素被各自地选择,所述若干位置在与当前第一类型语法元素关联的位置的邻近区域内。
[0147]
19.一种用于编码变换系数块的装置,所述装置被配置为编码指示所述变换系数块内的显著变换系数的位置的显著性图,然后编码在所述变换系数块内的所述显著变换系数的值成为数据流,在抽取所述显著变换系数的值时,通过上下文自适应熵编码顺序地编码所述值,其中,所述装置被配置为在所述变换系数块的位置中以预定的系数扫描次序编码所述值成为数据流,根据该结果,所述变换系数块使用子块扫描次序以变换系数块的子块的方式被扫描,辅助地,以位置子扫描次序扫描所述子块内的变换系数的位置,其中,所述装置进一步地被配置为,在对所述显著变换系数值的值顺序地进行上下文自适应熵编码时,使用从若干上下文的多个组中选择的若干上下文的一选择组,所述选择组的选择基于已经以子块扫描次序被遍历的变换系数块的子块内的变换系数的值,或基于在相等尺寸的先前被编码的变换系数块内共同地点子块的变换系数的值而对每个子块进行。
[0148]
20.一种用于解码来自数据流的指示变换系数块内的显著变换系数的位置的显著性图的方法,所述方法包括以下步骤:
[0149]
从所述数据流顺序地抽取第一类型语法元素,所述第一类型语法元素指示,对于所述变换系数块内的关联位置,至少关于显著变换系数还是非显著变换系数位于相应的位置;以及
[0150]
在所述变换系数块的位置中以扫描次序将顺序抽取的第一类型语法元素顺序地关联至所述变换系数块的位置,其取决于先前被抽取的并且被关联的第一类型语法元素所
指示的所述显著变换系数的位置。
[0151]
21.一种用于解码来自数据流的指示变换系数块内的显著变换系数的位置的显著性图的方法,所述方法包括以下步骤:
[0152]
从所述数据流抽取指示所述变换系数块内的显著变换系数的位置的显著性图,然后抽取所述变换系数块内的所述显著变换系数的值,在抽取所述显著性图时,通过上下文自适应熵解码从所述数据流顺序地抽取第一类型语法元素,所述第一类型语法元素指示,对于所述变换系数块内的关联位置,关于显著变换系数还是非显著变换系数位于相应的位置;以及
[0153]
在所述变换系数块的位置中以预定扫描次序将顺序抽取的第一类型语法元素顺序地关联至所述变换系数块的位置,
[0154]
其中,在对所述第一类型语法元素进行上下文自适应熵解码时,使用上下文,所述上下文依据显著变换系数根据先前被抽取并被关联的第一类型语法元素而位于的若干位置,而对于每个所述第一类型语法元素被各自地选择,所述若干位置在与相应的第一类型语法元素关联的位置的邻近区域内。
[0155]
22.一种用于解码变换系数块的方法,所述方法包括以下步骤:
[0156]
从数据流中抽取指示所述变换系数块内的显著变换系数的位置的显著图,然后抽取所述变换系数块内的所述显著变换系数的值,在抽取所述显著变换系数的值时,通过上下文自适应熵解码顺序地抽取所述值;以及
[0157]
在所述变换系数块的位置中以预定的系数扫描次序,将顺序被抽取的值与所述显著变换系数的位置顺序地关联,根据该结果,所述变换系数块使用子块扫描次序以变换系数块的子块的方式被扫描,辅助地,以位置子扫描次序扫描所述子块内的变换系数的位置,
[0158]
其中,在对所述显著变换系数值的值顺序地进行上下文自适应熵解码时,使用从若干上下文的多个组中选择的若干上下文的一选择组,所述选择组的选择基于已经以子块扫描次序被遍历的变换系数块的子块内的变换系数的值,或基于在相等尺寸的先前被解码的变换系数块内共同地点子块的变换系数的值而对每个子块进行。
[0159]
23.一种用于将指示变换系数块内的显著变换系数的位置的显著性图编码为数据流的方法,所述方法包括以下步骤:
[0160]
通过熵编码将第一类型语法元素编码顺序地编码为数据流,所述第一类型语法元素指示,对于所述变换系数块内的关联位置,至少关于显著变化系数还是非显著变换系数位于相应的位置,在所述变换系数块的位置中以扫描次序使将述第一类型语法元素编码为所述数据流,其取决于通过先前编码的第一类型语法元素所指示的所述显著变换系数的位置。
[0161]
24.一种用于将指示变换系数块内的显著变换系数的位置的显著性图编码为数据流的方法,所述方法包括以下步骤:
[0162]
编码指示所述变换系数块内的显著变换系数的位置的显著性图,然后编码所述变换系数块内的所述显著变换系数的值成为数据流,在编码所述显著性图时,通过上下文自适应熵编码将所述第一类型语法元素顺序编码为所述数据流,所述第一类型语法元素指示,对于所述变换系数块内的关联位置,关于显著变化系数还是非显著变换系数位于相应的位置,其中,将所述第一类型语法元素顺序地编码为所述数据流在所述变换系数块的位
置中以预定的扫描次序执行,在每个所述第一类型语法元素进行所述上下文自适应熵编码时使用上下文,所述上下文依据显著变换系数位于的并且与先前被编码为数据流的第一类型语法元素关联的若干位置,而对于所述第一类型语法元素被各自地选择,所述若干位置在与当前第一类型语法元素关联的位置的邻近区域内。
[0163]
25.一种用于编码变换系数块方法,所述方法包括以下步骤:
[0164]
编码指示所述变换系数块内的显著变换系数的位置的显著性图,然后编码所述变换系数块内的所述显著变换系数的值成为数据流,在编码所述显著变换系数的值时,通过上下文自适应熵编码顺序地编码所述值,其中,编码所述值为数据流的步骤在所述变换系数块的位置以预定系数扫描次序被执行,根据该结果,所述变换系数块使用子块扫描次序以变换系数块的子块的方式被扫描,辅助地,以位置子扫描次序扫描所述子块内的变换系数的位置,其中,在对所述显著变换系数值的值顺序地进行上下文自适应熵编码时,使用从若干上下文的多个组中选择的若干上下文的一选择组,所述选择组的选择基于已经以子块扫描次序被遍历的变换系数块的子块内的变换系数的值,或基于在相等尺寸的先前被编码的变换系数块内共同地点子块的变换系数的值而对每个子块进行。
[0165]
26.一种在其中被编码指示在变换系数块内的显著变换系数的位置的显著性图的数据流,其中,第一类型语法元素通过熵编码被顺序地编码为数据流,所述第一类型语法元素指示,对于所述变换系数块内的关联位置,至少关于显著变换系数还是非显著变换系数位于相应的位置,其中所述第一类型语法元素在所述变换系数块的位置中以扫描次序被编码成为数据流,其取决于通过先前被编码的第一类型语法元素所指示的所述显著变换系数的位置。
[0166]
27.一种在其中被编码指示在变换系数块内的显著变换系数的位置的显著性图的数据流,其中,指示该变换系数块内的显著变换系数的位置的显著性图,及其后紧接着的所述变换系数块内的所述显著变换系数的值被编码为数据流,其中,在该显著性图内,所述第一类型语法元素通过上下文自适应熵编码被顺序地编码为数据流,所述第一类型语法元素指示,对于所述变换系数块内的关联位置,至少关于显著变换系数还是非显著变换系数位于相应的位置,其中,所述第一类型语法元素在所述变换系数块的位置中以预定的扫描次序被顺序地编码为数据流,并且所述第一类型语法元素使用上下文被上下文自适应熵编码为数据流,其中,所述上下文依据显著变换系数位于的并且与先前被编码为数据流的第一类型语法元素关联的若干位置对于所述第一类型语法元素各自地被选择,所述若干位置在与当前第一类型语法元素关联的位置的邻近区域内。
[0167]
28.一种数据流,包括指示在变换系数块内的显著变换系数的位置的显著性图,其后紧接着的所述变换系数块内的显著变换系数的值的编码,其中,所述显著变换系数的值在所述变换系数块位置中以预定系数扫描次序通过上下文自适应熵编码被顺序地编码为数据流,根据该结果,所述变换系数块使用子块扫描次序以变换系数块的子块的方式被扫描,辅助地,以位置子扫描次序扫描所述子块内的变换系数的位置,其中,使用从若干上下文的多个组中选择的若干上下文的一选择组,所述显著变换系数值的值被顺序地上下文自适应熵编码为数据流,所述选择组的选择基于所述变换系数块的子块内的所述变化系数的值、已经以子块扫描次序被遍历的变换系数块的子块内的变换系数的值,或在相等尺寸的先前被编码的变换系数块内共同地点子块的变换系数的值而对每个子块进行。
[0168]
29.计算机可读数字存储介质,具有含程序代码的计算机程序存储在其上,当在计算机运行时,所述程序代码执行根据项23至25中任一项所述的方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1