时延敏感流转发的方法及装置与流程
1.本发明涉及网络通信技术领域,具体涉及一种时延敏感流转发的方法及装置。
背景技术:
2.工业物联网(iiot,industrial internet of things)促进了智能制造的发展,需要各种现场设备之间频繁的信息交互。与其他传统应用程序不同,许多工业系统对端到端时延非常敏感。而基于尽力而为传输方式的传统以太网并不能保证时延的确定性,这些对实时性和确定性要求较高的特定流量远远超出了传统以太网的可控范围。
3.此外,各类时延敏感业务对端到端时延有着不同级别的需求。例如在异常监测场景下,故障信息需要在极短时间内被上传以实现及时响应,该过程对时延高度敏感。而在周期性的状态信息监控场景下,数据的传输过程虽然对时延敏感,但是程度要低于前者。而对于一些非关键性业务而言,其传输过程对时延没有特定的要求,即数据按照尽力而为的方式进行交付即可。
4.在不同时延敏感级别的传输业务混合的场景下,业务之间时延敏感性差别很大,即传输的迫切程度相差较大。对于高度时延敏感的业务,必须满足其延迟和抖动要求才能保证业务的正常进行。而对于传输迫切程度较低的业务,也应该在满足高度时延敏感业务及时传输的同时,在其时延需求范围完成数据的交付。因此,具有不同级别时延敏感性业务流量的调度,是值得考虑的问题。
5.面向时延敏感业务的路由优化技术引起了大量的研究。当前针对时延敏感业务的流量传输问题提出了许多可行的办法,但是这些方案大多是针对整体的平均时延进行优化。在业务间时延敏感性差别较大的场景下,需要设计一种合适的路由方案,使得各个业务都能在各自的时延要求范围内完成交付,即满足业务间差异化的时延需求。此外,由于各类传输业务在网络中传输流量消耗了网络资源从而为网络运营商带来了收入,因此提高网络运营商收入的问题也是值得被考虑的问题。
6.于是,如何在满足流量传输约束、网络资源约束的条件下,尽可能地满足各类业务差异化的端到端时延需求并提高网络运营商的收入这一问题具有较高的研究价值。
技术实现要素:
7.针对现有技术存在的问题,本发明提供一种时延敏感流转发的方法及装置。
8.第一方面,本发明提供一种时延敏感流转发的方法,包括:
9.基于每个目标流的交付时延上限,确定每个所述目标流的优先级;
10.以满足交付时延上限的所述目标流个数,以及所述目标流的网络资源使用量最大化为目标,在满足传输约束,资源约束和预设的转发配置的条件下,基于drl模型,确定每个所述目标流的转发路径;
11.其中所述预设的转发配置包括:将属于同一个优先级的目标流的数据包放入同一条队列,同一条队列的数据包遵循先进先出的规则,优先级高的目标流的数据包转发完毕
再转发优先级低的目标流的数据包。
12.根据本发明提供的一种时延敏感流转发的方法,所述传输约束包括:
13.属于同一目标流的每个数据包的实际交付时延小于等于所述目标流的交付时延上限;
14.属于同一目标流的每个数据包的传输路径的最大跳数小于等于预设的最大跳数mh;
15.其中,每个数据包的实际交付时延由初始转发时刻和传输到目的节点的时刻确定。
16.根据本发明提供的一种时延敏感流转发的方法,所述属于同一目标流的每个数据包的传输路径的确定方法包括:
17.所述同一目标流的传输路径的长度与目标流的最短路径的长度的差值不超过el参数;
18.所述同一目标流的跳数不超过预设的最大跳数mh;
19.所述同一目标流的优先级属于同一个优先级;
20.其中,所述每个目标流的el参数是根据所述每个目标流的优先级确定的,所述el参数用于表征每个流的优先级g
m
的量化表示。
21.根据本发明提供的一种时延敏感流转发的方法,所述资源约束包括:
22.在任意时刻,每个节点缓存的所有流的数据包个数之和小于等于所述节点的承载能力;
23.当前节点和下一跳节点之间的链路的负载小于等于所述链路的承载能力。
24.根据本发明提供的一种时延敏感流转发的方法,所述以满足交付时延上限的目标流个数,以及目标流的网络资源使用量最大化为目标,在满足传输约束,资源约束和预设的转发配置条件下,基于drl模型,确定每个目标流的转发路径,包括:
25.获取优先级最高的流的待转发数据包所在的当前节点,确定所述当前节点的状态,所述当前节点的状态包括本地节点状态,邻居节点状态;
26.将所述当前节点的状态输入所述drl模型,输出待转发数据包的对应的动作以及所述动作对应的q值,所述动作表征所述待转发数据包的下一跳节点;
27.其中,本地节点状态包括:待转发数据包;邻居节点状态包括:邻居节点的拥塞程度,邻居节点缓存占用情况以及当前节点与所述邻居节点间的链路的带宽占用情况;
28.所述drl模型是基于每个目标流的数据包所属当前节点的状态训练得到的。
29.根据本发明提供的一种时延敏感流转发的方法,所述drl模型是基于每个目标流的数据包所属当前节点的状态训练得到的,包括:
30.根据特定的参数θ
i
初始化drl模型的神经网络参数;
31.获取所述目标流的待转发数据包所属本地节点的状态,以及所述本地节点的邻居节点的状态;
32.根据所述本地节点状态以及邻居节点状态,确定当前节点的状态;
33.根据∈
‑
greedy策略为所述待转发数据包选择动作,确定当前节点下一时刻的奖励值以及状态,并判断下一跳节点是否为目的节点;
34.基于当前节点当前时刻的状态,待转发数据包的动作,当前节点下一时刻奖励值
以及状态,和下一跳节点是否为目的节点的标识,确定当前节点的元组,并将其记录到经验池d
i
中;
35.从所述经验池di中抽样多个元组,并确定当前目标q值以及对应的损失函数;
36.根据损失函数的更新梯度以及学习率,更新神经网络的参数,直到所述神经网络参数收敛。
37.根据本发明提供的一种时延敏感流转发的方法,还包括:
38.基于神经网络构建drl模型,所述神经网络由一个输入层、三个全连接层、一个输出层构成;
39.根据待转发数据包所属流和所属节点,获取所述待转发数据包的优先级,可达节点集合以及下一跳邻居节点集合;
40.输入层的维数由待转发数据包所属的当前节点的邻居节点集合,以及待转发数据包可达节点集合两者取并集的大小加一确定;
41.输出层的维数由待转发数据包所属的当前节点的邻居节点个数确定。
42.第二方面,本发明提供一种时延敏感流转发的装置,包括:
43.优先级模块,用于基于每个目标流的交付时延上限,确定每个目标流的优先级;
44.确定模块,用于以满足交付时延上限的所述目标流个数,以及所述目标流的网络资源使用量最大化为目标,在满足传输约束,资源约束和预设的转发配置的条件下,基于drl模型,确定每个所述目标流的转发路径;
45.其中所述预设的转发配置包括:将属于同一个优先级的目标流的数据包放入同一条队列,同一条队列的数据包遵循先进先出的规则,优先级高的目标流的数据包转发完毕再转发优先级低的目标流的数据包。
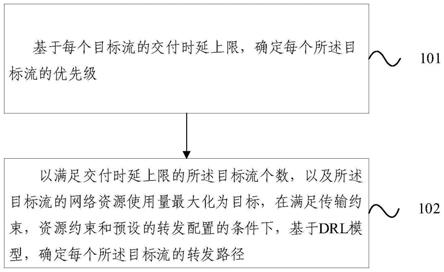
46.第三方面,本发明提供一种电子设备,包括处理器和存储有计算机程序的存储器,所述处理器执行所述程序时实现第一方面所述时延敏感流转发的方法的步骤。
47.第四方面,本发明提供一种处理器可读存储介质,所述处理器可读存储介质存储有计算机程序,所述计算机程序用于使所述处理器执行第一方面所述时延敏感流转发的方法的步骤。
48.本发明提供的时延敏感流转发的方法及装置,考虑到各类业务对时延的敏感程度相差较大,对业务流进行了优先级划分和传输路径限制。使得较高优先级的业务流量数据优先被转发以及沿着更短的路径进行传输,从而保障其在时延需求范围内完成端到端的交付。并且在满足各类业务实现时延要求范围内的可靠传输前提下,还考虑了提高网络运营商收入的优化目标。通过在模型中引入链路带宽、节点缓存在内的资源模型,从而在满足时延保障的同时实现网络运营商收入的提高。
附图说明
49.为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
50.图1是本发明提供的时延敏感流转发的方法的流程示意图;
51.图2是网络拓扑结构的示意图;
52.图3是本发明提供的交换机内部的队列模型示意图;
53.图4是本发明提供的神经网络结构示意图;
54.图5是本发明提供的时延敏感流转发的装置的结构示意图;
55.图6是本发明提供的电子设备的结构示意图。
具体实施方式
56.为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
57.下面结合图1
‑
图6描述本发明的时延敏感流转发的方法及装置。
58.图1是本发明提供的时延敏感流转发的方法的流程示意图,如图1所示,该时延敏感流转发的方法,包括:
59.步骤101、基于每个目标流的交付时延上限,确定每个所述目标流的优先级;
60.步骤102、以满足交付时延上限的所述目标流个数,以及所述目标流的网络资源使用量最大化为目标,在满足传输约束,资源约束和预设的转发配置的条件下,基于drl模型,确定每个所述目标流的转发路径;
61.其中所述预设的转发配置包括:将属于同一个优先级的目标流的数据包放入同一条队列,同一条队列的数据包遵循先进先出的规则,优先级高的目标流的数据包转发完毕再转发优先级低的目标流的数据包。
62.具体的,每个目标流flow都具有严格得交付时延上限值,该上限值体现了该flow的时延敏感特性,也代表各类时延敏感类业务对端到端时延有着不同级别的需求。
63.由于各类业务的传输紧迫程度是不同的,因此需要按照该紧迫程度对各类业务流量进行优先级划分以实现较高优先级流量的优先转发。此外,为了使时延敏感数据包尽可能的在较短时间内到达目的地,本发明还对这些数据包进行了传输路径的限制。通过以上两点思路,就可以满足各类时延敏感业务对端到端时延的差异化需求。
64.在本发明中,每个流的交付时延上限值,体现了其传输的紧迫程度,按照传输的紧迫程度,各类时延敏感流量可分为以下几类:
65.a.超时延敏感(ultra delay
‑
sensitive,uds)流:该类流量具有非常低的端到端时延需求,也被称为时间关键型流量。由于该类流量需要尽可能在最短时间内完成传输,因此被赋予网络中最高的转发优先级。其数据包在交换队列被优先转发至下一节点。此外,为了使其尽快到达目的地,该类流量的传输路径集被设定为最短路径集(即沿着源节点和目的节点之间的某一条最短路径进行传输)。
66.b.一般时延敏感(ordinary delay
‑
sensitive,ods)流:该类流量具有一定程度的端到端时延需求,但其传输紧迫程度要低于uds流。因此其传输优先级仅次于uds流,即该类流量的数据包在uds数据包之后开始转发。为了使其尽快到达目的地,该类流量的传输路径长度应尽可能接近其最短路径长度(其在网络中转发的跳数相对于其最短路径的跳数可能稍有增加,但在预设定的范围内)。
delay),该上限值体现了该flow的时延敏感特性。数据包的交付时延如果超过了该上限值,则认为该数据包的时延敏感特性没有得到保证。
83.根据不同流对应的不同的优先级,相同优先级的流放入相同的队列,得到交换机内部的队列模型如图3所示。交换机内部为每个优先级都分配了一条传输队列。图中所示的交换机维护五条传输队列,queue0和queue1供uds数据包进行传输、queue2和queue3供ods数据包进行传输、queue4供be数据包进行传输。当高优先级队列存在数据包排队时,则这些数据包优先被转发。即ods队列的数据包必须等uds队列为空时(即uds数据包转发完毕)才可以转发,同理,be队列需要等uds队列和ods队列为空时才可以开始转发数据包。此外,同一条队列的数据包遵循先进先出(fifo)的规则。门控制列表(gate control list,gcl)的参数gcl控制着交换机的输出端口具体选择哪条队列进行转发,初始时刻t0的gcl参数为“00000”,表示当前交换机中由于没有数据包待转发,因此所有队列处于关闭状态。在时刻t
i
时参数“gcl=01000”表示此时第2个优先级队列的数据包允许被转发。以上规则即构成了每个流的转发配置。
84.在满足传输约束和资源约束的条件下,最大化的满足各类业务差异化的端到端时延需求并提高网络运营商的收入,前者表现为在交付时延上限uld
flow
内被成功交付的业务流量(用集合f*表示)占总流量集合f的比重,后者表现为网络中的资源使用量。于是,本发明每个目标流的转发路径问题可以形式化描述为式(14),其中w1、w2表示权重系数:
[0085][0086]
基于drl(deep reinforcement learning,深度强化学习)的时延敏感流量数据转发机制如算法1所示,每个独立节点的初始化是相同的,而学习过程是完全独立的,每个节点node被视为一个独立的代理并具有各自独立的神经网络,同时采用了经验回放(experience replay)和目标网络(target network)技术,以减少数据的相关性和非静态性以及模型不收敛问题。
[0087]
本发明提供的时延敏感流转发的方法,考虑到各类业务对时延的敏感程度相差较大,对业务流进行了优先级划分和传输路径限制。使得较高优先级的业务流量数据优先被转发以及沿着更短的路径进行传输,从而保障其在时延需求范围内完成端到端的交付。并且在满足各类业务实现时延要求范围内的可靠传输前提下,还考虑了提高网络运营商收入的优化目标。通过在模型中引入链路带宽、节点缓存在内的资源模型,从而在满足时延保障的同时实现网络运营商收入的提高。
[0088]
可选的,所述传输约束包括:
[0089]
属于同一目标流的每个数据包的实际交付时延小于等于所述目标流的交付时延上限;
[0090]
属于同一目标流的每个数据包的传输路径的最大跳数小于等于预设的最大跳数
mh;
[0091]
其中,每个数据包的实际交付时延由初始转发时刻和传输到目的节点的时刻确定。
[0092]
具体的,各类流量分配了优先级并规划了允许传输路径集,但是由于每个流都各自具有严格的交付时延上限uld
flow
,并且网络中所有流的最大转发跳数收受到限制,因此流量的传输需要满足这些固定的传输约束。
[0093]
传输约束:对于流flow的每个数据包packet而言,其交付时延有严格的上限uld
flow
、其经过的路径跳数不能超过预设的最大跳数mh。于是,网络中流量的传输约束如式(10)和式(11)所示:
[0094][0095][0096]
其中,最大跳数mh可以根据网络的实际情况预先设定。
[0097]
本发明提供的时延敏感流转发的方法,考虑到各类业务对时延的敏感程度相差较大,对业务流进行了优先级划分和传输路径限制。使得较高优先级的业务流量数据优先被转发以及沿着更短的路径进行传输,从而保障其在时延需求范围内完成端到端的交付。并且在满足各类业务实现时延要求范围内的可靠传输前提下,还考虑了提高网络运营商收入的优化目标。通过在模型中引入链路带宽、节点缓存在内的资源模型,从而在满足时延保障的同时实现网络运营商收入的提高。
[0098]
可选的,所述属于同一目标流的每个数据包的传输路径的确定方法包括:
[0099]
所述同一目标流的传输路径的长度与目标流的最短路径的长度的差值不超过el参数;
[0100]
所述同一目标流的跳数不超过预设的最大跳数mh;
[0101]
所述同一目标流的优先级属于同一个优先级;
[0102]
其中,所述每个目标流的el参数是根据所述每个目标流的优先级确定的,所述el参数用于表征每个流的优先级g
m
的量化表示。
[0103]
具体的,同一个目标流可能存在多条传输路径,el参数是对优先级g
m
的量化表示,即每个传输路径的跳数与最短路径跳数的偏差值,该参数是一个正整数,用式(7)表示。比如:有三个优先级,分别用符号g1、g2、g3表示,每个优先级有各自对应的el参数。优先级越高,el参数的值越小。比如,优先级g1的el参数设为0,g2的el参数设为1,g3的el参数设为2。
[0104]
对于uds流而言,该el参数被设定为0,即uds流沿着最短路径传输。对于ods流而言,该el参数被设定一个较小的正整数,即ods流的传输路径与最短路径的长度相差不超过该正整数。对于be流而言,该el参数没有特定的要求。
[0105]
el={el
gm
}
ꢀꢀꢀ
(7)
[0106][0107]
[0108]
p
flow
表示流flow的传输路径集,该集合由其所有允许传输的路径组成,用式(8)表示。设|sp
flow
|表示流flow最短路径(sp)的长度,拓扑给定的情况下,通过dijkstra算法得出最短路径。流flow的所有允许传输路径具有这样的特点:路径的长度与最短路径的长度|sp
flow
|的差值不超过允许的上限值,该上限值由式(7)中的el参数指定。此外,网络中所有流的跳数均不超过预设最大跳数mh,即每个流对应的数据包在网络中传输的累计跳数如果达到了最大跳数mh,且还未到达目的节点,就会被中间交换机丢弃,造成丢包的情况。比如可以设置最大跳数mh为8,代表流对应的数据包转发8次后还未到达目标节点,则会被丢弃。
[0109]
式(9)中的集合rn
packet
由数据包packet可到达的节点组成。由于流flow的传输路径被限定至其允许传输路径集p
flow
,因此流flow的数据包packet可到达的节点是有限制的,这些节点由flow的传输路径集包含的节点组成。于是当该数据包packet由交换机转发时,交换机需要在其邻居节点中选择一个合适节点node完成转发(node属于集合rn
packet
)。此外,为了避免出现环状的传输路径,每个可到达节点只允许被该数据包packet访问一次。比如el参数为2,根据公式(7),该参数表示“传输路径的跳数与最短路径跳数的偏差值,该参数是一个正整数”。假设最短路径的长度为m,那么其路径长度的范围为m~m+2,于是从发送方到接收方之间所有长度在这个范围内的路径组成的集合,称为允许传输路径集。
[0110]
本发明提供的时延敏感流转发的方法,考虑到各类业务对时延的敏感程度相差较大,对业务流进行了优先级划分和传输路径限制。使得较高优先级的业务流量数据优先被转发以及沿着更短的路径进行传输,从而保障其在时延需求范围内完成端到端的交付。并且在满足各类业务实现时延要求范围内的可靠传输前提下,还考虑了提高网络运营商收入的优化目标。通过在模型中引入链路带宽、节点缓存在内的资源模型,从而在满足时延保障的同时实现网络运营商收入的提高。
[0111]
可选的,所述资源约束包括:
[0112]
在任意时刻,每个节点缓存的所有流的数据包个数之和小于等于所述节点的承载能力;
[0113]
当前节点和下一跳节点之间的链路的负载小于等于所述链路的承载能力。
[0114]
具体的,由于网络中节点的缓存容量(cache capacity,cc)以及链路的带宽容量(bandwidth capacity,bc)是有限的,因此流量的传输还需要满足相应的资源约束。
[0115]
任意一个节点node
i
在任意时刻t时,节点的当前缓存queue不能超过该节点的承载能力cc
nodei
。即在当前时刻任意一个节点中所有队列的uds,ods,be流的数据包个数的总和小于等于该节点的承载能力。节点承载能力cc
nodei
是空间上的概念,即某一时刻节点上能够容纳数据包的数量。类似的,任意一条链路(node
i
,node
j
)在任意时刻t时,链路当前的负载bandwidth
(nodei,nodej)
不能超过该链路的承载能力bc
(nodei,nodej)
。链路的承载能力bc
(nodei,nodej))
是指任意两个节点node
i
和node
j
之间的链路的承载能力,是一个速度上的概念。于是,网络中的资源约束如式(12)和式(13)所示:
[0116][0117][0118]
其中,f表示网络中的所有流构成的集合。
[0119]
本发明提供的时延敏感流转发的方法,考虑到各类业务对时延的敏感程度相差较大,对业务流进行了优先级划分和传输路径限制。使得较高优先级的业务流量数据优先被转发以及沿着更短的路径进行传输,从而保障其在时延需求范围内完成端到端的交付。并且在满足各类业务实现时延要求范围内的可靠传输前提下,还考虑了提高网络运营商收入的优化目标。通过在模型中引入链路带宽、节点缓存在内的资源模型,从而在满足时延保障的同时实现网络运营商收入的提高。
[0120]
可选的,所述以满足交付时延上限的所述目标流个数,以及所述目标流的网络资源使用量最大化为目标,在满足传输约束,资源约束和预设的转发配置条件下,基于drl模型,确定每个所述目标流的转发路径,包括:
[0121]
获取优先级最高的流的待转发数据包所在的当前节点,确定所述当前节点的状态,所述当前节点的状态包括本地节点状态,邻居节点状态;
[0122]
将所述当前节点的状态输入所述drl模型,输出待转发数据包的对应的动作以及所述动作对应的q值,所述动作表征所述待转发数据包的下一跳节点;
[0123]
其中,本地节点状态包括:待转发数据包;邻居节点状态包括:邻居节点的拥塞程度,邻居节点缓存占用情况以及当前节点与所述邻居节点间的链路的带宽占用情况;
[0124]
所述drl模型是基于每个目标流的数据包所属当前节点的状态训练得到的。
[0125]
具体的,数据包的路由可以看作是一个马尔可夫决策过程。每个节点都是独立的,通过观察本地节点状态以及邻居节点状态来完成策略的制定。本地节点状态指的是当前待转发的数据包packet,由于packet的可到达的节点受到集合rn
packet
限制,即交换机在选择下一节点时从集合rn
packet
中选择。而邻居节点状态包括当前待转发数据包所属节点的邻居节点node
i
的拥塞情况和资源使用情况,其中拥塞情况用length
nodei
表示任意邻居节点node
i
中优先级大于等于当前待转发数据包packet优先级的所有队列当前积压的数据包总个数,该数值用于表征节点node
i
的拥塞程度。资源使用情况用source
nodei
表示邻居节点node
i
的缓存占用情况以及当前节点与该邻居节点间的链路(node,node
i
)的带宽占用情况。
[0126]
将待转发数据包所属的当前节点对应的本地节点状态和邻居节点状态,输入drl模型,输出待转发数据包的动作,即为待转发数据包packet选择合适的下一跳节点。
[0127]
同时,待转发数据包所属节点会获得其对应的奖励值以及q值。待转发数据包在状态s时,采取行动a后的价值(value),可以用q(s,a)表示。
[0128]
接下来为每个独立节点的学习过程进行建模,并定义状态(state)、行为(action)、奖励(reward)。
[0129]
state:对于交换机节点node而言,将其最高优先级队列中的第一个数据包记作packet(该数据包即将被转发至下一节点)。节点node的邻居节点集合记为c
node
,用length
nodei
表示某邻居节点node
i
中优先级大于等于数据包packet优先级的传输队列当前积压的待转发数据包总个数,该数值用于表征节点node
i
的拥塞程度。用source
nodei
表示邻居节点node
i
的缓存占用情况以及当前节点与该邻居节点间的链路(node,node
i
)的带宽占用情况。于是当前节点node的状态可定义为:
[0130][0131]
action:对于当前节点node而言,其行为定义为:为当前待转发数据包packet选择
合适的下一跳节点。由于数据包packet的可到达节点是有限制的(数据包packet只能访问rn
packet
中的节点),因此当前节点node的action输出空间为其邻居节点c
node
与数据包packet的可到达节点rn
packet
的交集。
[0132]
a
t
={a
t
=node
k
},where:node
k
∈c
node
∩rn
packet
ꢀꢀꢀ
(16)
[0133]
reward:当前节点node为待转发packet选择了合适的下一跳node
i
并完成了转发,其奖励定义为:
[0134]
r
t
(s
t
,a
t
)=a1*r1+a2*r2ꢀꢀꢀ
(17)
[0135]
以上的a1、a2表示权重系数,是根据实验收敛难易情况以及收敛后的实验效果来设定的。r1和r2分别定义为:
[0136]
r1=d
queue
+d
prop
ꢀꢀꢀ
(18)
[0137][0138]
以上的a3、a4表示权重系数。r
t
主要分为两个部分:一部分来自于单跳时延,这包括在node的排队时延d
queue
以及至下一节点的传播时延d
prop
。在确定了下一跳节点的情况下,d
prop
传播时延是定值,因为两节点之间距离一定,传播速度一定,该时延是确定的。排队时延d
queue
表示待转发数据包在一个队列中等待的时间。另一部分来自于网络运营商通过提供网络资源供业务流量传输消耗而获得的收益,其中queue
t
表示数据包packet被转发后当前节点node的剩余缓存资源,bandwidth
t,i
表示链路(node,node
i
)的剩余带宽资源。cc
nodei
,bc
nodei
分别表示节点node
i
的缓存容量和链路(node,node
i
)的带宽容量。
[0139]
在时刻t时,当前节点node为待转发数据包packet选择合适的下一跳。具体而言,当前节点node首先观测node所有邻居节点c
node
的拥塞情况length
nodei
和资源利用情况source
nodei
从而集成当前状态s
t
,然后根据∈
‑
greedy策略选择动作,即当前节点node将以∈的概率从其动作空间中选择一个随机动作进行执行,或者以1
‑
∈的概率选择q值较高的action。即为待转发数据包packet选择合适的下一跳节点。
[0140]
本发明提供的时延敏感流转发的方法,考虑到各类业务对时延的敏感程度相差较大,对业务流进行了优先级划分和传输路径限制。使得较高优先级的业务流量数据优先被转发以及沿着更短的路径进行传输,从而保障其在时延需求范围内完成端到端的交付。并且在满足各类业务实现时延要求范围内的可靠传输前提下,还考虑了提高网络运营商收入的优化目标。通过在模型中引入链路带宽、节点缓存在内的资源模型,从而在满足时延保障的同时实现网络运营商收入的提高。
[0141]
可选的,所述drl模型是基于每个目标流的数据包所属当前节点的状态训练得到的,包括:
[0142]
根据特定的参数θ
i
初始化drl模型的神经网络参数;
[0143]
获取所述目标流的待转发数据包所属本地节点的状态,以及所述本地节点的邻居节点的状态;
[0144]
根据所述本地节点状态以及邻居节点状态,确定当前节点的状态;
[0145]
根据∈
‑
greedy策略为所述待转发数据包选择动作,确定当前节点下一时刻的奖励值以及状态,并判断下一跳节点是否为目的节点;
[0146]
基于当前节点当前时刻的状态,待转发数据包的动作,当前节点下一时刻奖励值
以及状态,和下一跳节点是否为目的节点的标识,确定当前节点的元组,并将其记录到经验池d
i
中;
[0147]
从所述经验池di中抽样多个元组,并确定当前目标q值以及对应的损失函数;
[0148]
根据损失函数的更新梯度以及学习率,更新神经网络的参数,直到所述神经网络参数收敛。
[0149]
具体的,基于drl的时延敏感流量数据转发机制如算法1所示,每个独立节点的初始化是相同的,而学习过程是完全独立的,采用同样的方法(算法1)对网络中每个单独的节点完成训练过程。在开始训练前,需要对网络中的各类时延敏感业务流量集合f按照各自的时延需求完成优先级的划分:g1,g2,
…
,g
max
‑1,g
max
。然后需要预定义好每个优先级g
m
的量化表示,即el
gm
参数,从而确定每个flow的可到达节点集rn
packet
。以上是在训练开始前的准备工作。
[0150]
每个节点node被视为一个独立的代理并具有各自独立的神经网络,同时采用了经验回放(experience replay)和目标网络(target network)技术,以减少数据的相关性和非静态性以及模型不收敛问题。完成对每个节点的经验池和神经网络的初始化操作,即将经验池设定为空,并用特定的参数θ
i
初始化各自的神经网络,特定的参数θ
i
可随机指定,且该参数在训练过程中不断修正,最终会收敛得到正确的值。
[0151]
根据待转发数据包,确定该数据包所属节点,进而确定本地节点状态,本地节点状态(即待转发数据包packet)决定了下一节点不仅要属于集合c
node
、还必须属于待转发数据包packet的可达节点集合rn
packet
。再根据本地节点状态确定邻居节点状态,包括:邻居节点的拥塞程度,邻居节点缓存占用情况以及当前节点与所述邻居节点间的链路的带宽占用情况;
[0152]
在时刻t时,当前节点node为待转发数据包packet选择合适的下一跳。具体而言,当前节点node首先观测节点node所有属于c
node
的邻居节点的拥塞情况length
nodei
和资源利用情况source
nodei
,从而集成当前节点状态然后根据∈
‑
greedy策略选择动作,即当前节点node将以∈的概率从其动作空间中选择一个随机动作进行执行,或者以1
‑
∈的概率选择q值较高的action,即:
[0153][0154]
其中,∈取值可根据经验设定,并动态调整。
[0155]
然后将待转发数据包packet转发给相应的邻居节点a
t
,计算出奖励r
t
并回传至当前节点node,得到当前节点在下一时刻t+1的状态s
t+1
。此外,如果下一个节点a
t
为传输的目的节点,则传输标志is_end
t
将设置为1,否则设置为0,即:
[0156][0157]
随后,当前节点node将元组(s
t
、a
t
、r
t
、s
t+1
、is_end
t
)记录到其经验池d
i
中,并从经验池d
i
中抽样若干元组:(s
j
、a
j
、r
j
、s
j+1
、is_end
j
)并计算当前目标q值y
j
:
[0158]
[0159]
其中γ表示衰减因子。
[0160]
定义损失函数l(θ
i
)为:
[0161]
l(θ
i
)=e[(y
j
‑
q(s
j
,a
j
;θ
i
))2]
ꢀꢀꢀ
(23)
[0162]
然后利用损失函数l(θi)的偏导数计算参数θi的更新梯度:
[0163][0164]
最后更新神经网络的参数θ
i
,即:
[0165][0166]
其中α是学习率。上述过程虽然为单个节点的训练过程,但是网络中所有节点的训练是同步进行的。于是每个节点的神经网络参数θ
i
都会随着训练的进行而不断更新,直至收敛。
[0167]
本发明提供的时延敏感流转发的方法,考虑到各类业务对时延的敏感程度相差较大,对业务流进行了优先级划分和传输路径限制。使得较高优先级的业务流量数据优先被转发以及沿着更短的路径进行传输,从而保障其在时延需求范围内完成端到端的交付。并且在满足各类业务实现时延要求范围内的可靠传输前提下,还考虑了提高网络运营商收入的优化目标。通过在模型中引入链路带宽、节点缓存在内的资源模型,从而在满足时延保障的同时实现网络运营商收入的提高。
[0168]
可选的,所述方法还包括:
[0169]
基于神经网络构建drl模型,所述神经网络由一个输入层、三个全连接层、一个输出层构成;
[0170]
根据待转发数据包所属流和所属节点,获取所述待转发数据包的优先级,可达节点集合以及下一跳邻居节点集合;
[0171]
输入层的维数由待转发数据包所属的当前节点的邻居节点集合,以及待转发数据包可达节点集合两者取并集的大小加一确定;
[0172]
输出层的维数由待转发数据包所属的当前节点的邻居节点个数确定。
[0173]
具体的,深度强化学习drl是深度学习和强化学习的结合。这两种学习方式在很大程度上是正交问题,二者结合得很好。强化学习定义了优化的目标,深度学习给出了运行机制——表征问题的方式以及解决问题的方式。将强化学习和深度学习结合在一起,寻求一个能够解决任何人类级别任务的代理,得到了能够解决很多复杂问题的一种能力——通用智能。深度强化学习中的每个节点都是一个独立的智能体,并拥有自己独立的神经网络用于决策。网络中的一个智能体的神经网络结构如图4所示,该神经网络由三个神经元数为128的完全连接层组成。输入层输入的是一个多维向量,其维数与当前节点node的邻居节点c
node
和当前待转发数据包packet密切相关。具体而言,该输入包括:
[0174]
1)本地节点状态:即当前待转发数据包packet。
[0175]
2)邻居节点状态:包括邻居节点node
i
的缓存占用情况、当前节点与该邻居节点间的链路(node,node
i
)的带宽占用情况。
[0176]
本地节点状态(即待转发数据包packet)决定了下一节点不仅要属于集合c
node
、还
必须属于待转发数据包packet的可达节点集合rn
packet
。于是在收集邻居节点状态时,只需要收集c
node
与rn
packet
两个集合的公共节点的状态即可。从而,输入层的维数等于集合c
node
∩rn
packet
的大小再加1。此外,输出层的维数等于邻居节点的个数(即|c
node
|),但是由于邻居节点中存在着数据包packet的不可达节点,因此这些不可达节点的输出q值始终为0。
[0177]
本发明提供的时延敏感流转发的方法,考虑到各类业务对时延的敏感程度相差较大,对业务流进行了优先级划分和传输路径限制。使得较高优先级的业务流量数据优先被转发以及沿着更短的路径进行传输,从而保障其在时延需求范围内完成端到端的交付。并且在满足各类业务实现时延要求范围内的可靠传输前提下,还考虑了提高网络运营商收入的优化目标。通过在模型中引入链路带宽、节点缓存在内的资源模型,从而在满足时延保障的同时实现网络运营商收入的提高。
[0178]
算法1的具体实现如下:
[0179][0180]
[0181]
图5是本发明提供的时延敏感流转发的装置的结构示意图,如图5所示,该时延敏感流转发的装置,包括:
[0182]
优先级模块501,用于基于每个目标流的交付时延上限,确定每个所述目标流的优先级;
[0183]
确定模块502,用于以满足交付时延上限的所述目标流个数,以及所述目标流的网络资源使用量最大化为目标,在满足传输约束,资源约束和预设的转发配置的条件下,基于drl模型,确定每个所述目标流的转发路径;
[0184]
其中所述预设的转发配置包括:将属于同一个优先级的目标流的数据包放入同一条队列,同一条队列的数据包遵循先进先出的规则,优先级高的目标流的数据包转发完毕再转发优先级低的目标流的数据包。
[0185]
可选的,所述传输约束包括:
[0186]
属于同一目标流的每个数据包的实际交付时延小于等于所述目标流的交付时延上限;
[0187]
属于同一目标流的每个数据包的传输路径的最大跳数小于等于预设的最大跳数mh;
[0188]
其中,每个数据包的实际交付时延由初始转发时刻和传输到目的节点的时刻确定。
[0189]
可选的,确定模块502还用于确定所述属于同一目标流的每个数据包的传输路径,包括:
[0190]
所述同一目标流的传输路径的长度与目标流的最短路径的长度的差值不超过el参数;
[0191]
所述同一目标流的跳数不超过预设的最大跳数mh;
[0192]
所述同一目标流的优先级属于同一个优先级;
[0193]
其中,所述每个目标流的el参数是根据所述每个目标流的优先级确定的,所述el参数用于表征每个流的优先级g
m
的量化表示。
[0194]
可选的,所述资源约束包括:
[0195]
在任意时刻,每个节点缓存的所有流的数据包个数之和小于等于所述节点的承载能力;
[0196]
当前节点和下一跳节点之间的链路的负载小于等于所述链路的承载能力。
[0197]
可选的,确定模块502还用于获取优先级最高的流的待转发数据包所在的当前节点,确定所述当前节点的状态,所述当前节点的状态包括本地节点状态,邻居节点状态;
[0198]
将所述当前节点的状态输入所述drl模型,输出待转发数据包的对应的动作以及所述动作对应的q值,所述动作表征所述待转发数据包的下一跳节点;
[0199]
其中,本地节点状态包括:待转发数据包;邻居节点状态包括:邻居节点的拥塞程度,邻居节点缓存占用情况以及当前节点与所述邻居节点间的链路的带宽占用情况;
[0200]
所述drl模型是基于每个目标流的数据包所属当前节点的状态训练得到的。
[0201]
可选的,所述确定模块502还用于根据特定的参数θ
i
初始化drl模型的神经网络参数;
[0202]
获取所述目标流的待转发数据包所属本地节点的状态,以及所述本地节点的邻居
节点的状态;
[0203]
根据所述本地节点状态以及邻居节点状态,确定当前节点的状态;
[0204]
根据∈
‑
greedy策略为所述待转发数据包选择动作,确定当前节点下一时刻的奖励值以及状态,并判断下一跳节点是否为目的节点;
[0205]
基于当前节点当前时刻的状态,待转发数据包的动作,当前节点下一时刻奖励值以及状态,和下一跳节点是否为目的节点的标识,确定当前节点的元组,并将其记录到经验池d
i
中;
[0206]
从所述经验池di中抽样多个元组,并确定当前目标q值以及对应的损失函数;
[0207]
根据损失函数的更新梯度以及学习率,更新神经网络的参数,直到所述神经网络参数收敛。
[0208]
可选的,所述装置还包括构建模块503用于基于神经网络构建drl模型,所述神经网络由一个输入层、三个全连接层、一个输出层构成;
[0209]
根据待转发数据包所属流和所属节点,获取所述待转发数据包的优先级,可达节点集合以及下一跳邻居节点集合;
[0210]
输入层的维数由待转发数据包所属的当前节点的邻居节点集合,以及待转发数据包可达节点集合两者取并集的大小加一确定;
[0211]
输出层的维数由待转发数据包所属的当前节点的邻居节点个数确定。
[0212]
需要说明的是,本发明中对单元的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0213]
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个处理器可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read
‑
only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0214]
在此需要说明的是,本发明提供的上述装置,能够实现上述方法实施例所实现的所有方法步骤,且能够达到相同的技术效果,在此不再对本实施例中与方法实施例相同的部分及有益效果进行具体赘述。
[0215]
图6示例了一种电子设备的实体结构示意图,如图6所示,该电子设备可以包括:处理器(processor)610、通信接口(communication interface)620、存储器(memory)630和通信总线640,其中,处理器610,通信接口620,存储器630通过通信总线640完成相互间的通信。
[0216]
可选的,处理器610可以是中央处理器(central processing unit,cpu)、专用集成电路(application specific integrated circuit,asic)、现场可编程门阵列(field-
programmable gate array,fpga)或复杂可编程逻辑器件(complex programmable logic device,cpld),处理器也可以采用多核架构。
[0217]
处理器610可以调用存储器630中的计算机程序,以执行时延敏感流转发的方法的步骤,例如包括:
[0218]
基于每个目标流的交付时延上限,确定每个目标流的优先级;
[0219]
以满足交付时延上限的所述目标流个数,以及所述目标流的网络资源使用量最大化为目标,在满足传输约束,资源约束和预设的转发配置的条件下,基于drl模型,确定每个所述目标流的转发路径;
[0220]
其中所述预设的转发配置包括:将属于同一个优先级的目标流的数据包放入同一条队列,同一条队列的数据包遵循先进先出的规则,优先级高的目标流的数据包转发完毕再转发优先级低的目标流的数据包。
[0221]
此外,上述的存储器630中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read
‑
only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
[0222]
在此需要说明的是,本发明实施例提供的电子设备,能够实现上述方法实施例所实现的所有方法步骤,且能够达到相同的技术效果,在此不再对本实施例中与方法实施例相同的部分及有益效果进行具体赘述。
[0223]
另一方面,本发明还提供一种计算机程序产品,所述计算机程序产品包括存储在非暂态计算机可读存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,计算机能够执行上述各方法所提供的时延敏感流转发的方法的步骤,例如包括:
[0224]
基于每个目标流的交付时延上限,确定每个所述目标流的优先级;
[0225]
以满足交付时延上限的所述目标流个数,以及所述目标流的网络资源使用量最大化为目标,在满足传输约束,资源约束和预设的转发配置的条件下,基于drl模型,确定每个所述目标流的转发路径;
[0226]
其中所述预设的转发配置包括:将属于同一个优先级的目标流的数据包放入同一条队列,同一条队列的数据包遵循先进先出的规则,优先级高的目标流的数据包转发完毕再转发优先级低的目标流的数据包。
[0227]
另一方面,本技术实施例还提供一种处理器可读存储介质,所述处理器可读存储介质存储有计算机程序,所述计算机程序用于使所述处理器执行上述各实施例提供的时延敏感流转发的方法的步骤,例如包括:
[0228]
基于每个目标流的交付时延上限,确定每个所述目标流的优先级;
[0229]
以满足交付时延上限的所述目标流个数,以及所述目标流的网络资源使用量最大化为目标,在满足传输约束,资源约束和预设的转发配置的条件下,基于drl模型,确定每个
所述目标流的转发路径;
[0230]
其中所述预设的转发配置包括:将属于同一个优先级的目标流的数据包放入同一条队列,同一条队列的数据包遵循先进先出的规则,优先级高的目标流的数据包转发完毕再转发优先级低的目标流的数据包。
[0231]
所述处理器可读存储介质可以是处理器能够存取的任何可用介质或数据存储设备,包括但不限于磁性存储器(例如软盘、硬盘、磁带、磁光盘(mo)等)、光学存储器(例如cd、dvd、bd、hvd等)、以及半导体存储器(例如rom、eprom、eeprom、非易失性存储器(nand flash)、固态硬盘(ssd))等。
[0232]
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
[0233]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
[0234]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1