一种强化学习与BBR算法结合的自适应拥塞控制方法及系统
一种强化学习与bbr算法结合的自适应拥塞控制方法及系统
技术领域
1.本发明涉及拥塞控制技术领域,具体来说,涉及一种强化学习与bbr算法结合的的自适应拥塞控制方法及系统。
背景技术:
2.随着互联网的普及,越来越多的网络流量堆积在瓶颈链路上。拥有一个合理的拥塞控制算法来保护互联网不受持续过载的影响显得十分重要。
3.传统的拥塞控制算法大致分为三类:基于丢失的拥塞控制算法,基于时延的拥塞控制算法,以及基于拥塞的拥塞控制算法。然而传统的拥塞控制算法只能在特定网络中工作良好。它的设计通常基于对网络的特定假设,并将预定义的事件硬连接到预定义的动作。
4.深度强化学习的设计有很大的潜力使自己适应各种条件,而无需对每一种条件进行调整或手动设计;单纯的强化学习进行拥塞控制会导致收敛性差,因此我们将强化学习与bbr算法框架相结合;其中,bbr是谷歌2016提出的基于拥塞的拥塞控制算法,很多研究表明,它具有高吞吐和低时延的特性。
5.针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
6.针对相关技术中的问题,本发明提出一种强化学习与bbr算法结合的的自适应拥塞控制方法及系统,克服传统拥塞控制算法只针对一种特定场景,而在其他场景性能下降的缺陷的技术问题。
7.本发明的技术方案是这样实现的:
8.一种强化学习与bbr算法结合的的自适应拥塞控制方法,包括以下步骤:
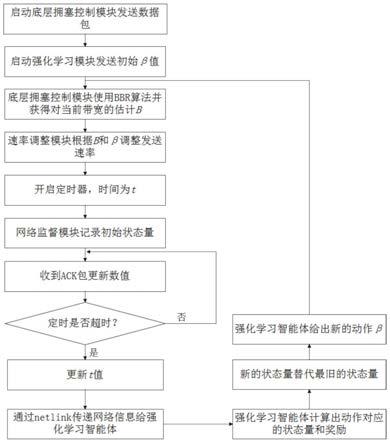
9.s1、融合深度强化学习和bbr协议的自适应拥塞控制方法,包括netlink模块、强化学习智能体、底层拥塞控制模块、网络状态监测模块和速率调整模块组成的系统,下面以真实的网络下数据传输为例子来说明;
10.s2、首先在内核态开启底层拥塞控制模块进行数据传输,再在用户态开启强化学习智能体;
11.s3、拥塞窗口计算模块根据传过来的β值和b来更新发送速率;
12.s4、强化学习智能体先开启一个初始阶段,向底层拥塞控制模块用netlink套接字发送初始的β值;
13.s5、底层拥塞控制模块收到β值后,根据公式计算出带宽值b,并将b值发送给速率调整模块;
14.s6、与此同时,网络状态监控模块在底层拥塞控制模块收到β值时开启一个时间为t的定时器,定时器开始时利用收到的ack包开始记录网络初始值,定时器结束后,网络状态监控模块利用收到的ack包记录的网络结束值,与网络初始值的差异来更新网络状态。并将t值更新为数据包往返时延的平均值;
15.s7、速率调整模块根据传过来的b值来更新发送速率;
16.s8、当强化学习智能体收到网络状态值时,从中提取出改变对应动作的状态和奖励。当定时器超时后,强化学习智能体收集到了第一个历史网络状态,并填进数组,并根据这个状态数组和训练过的模型,挑选出适应网络状态的β值给底层拥塞控制模块;
17.s9、重复步骤4
‑
8。
18.其中,还包括以下步骤:
19.步骤s101,在内核态开启bbr逻辑模块,在用户态开启强化学习智能体;
20.步骤s102,强化学习智能体先开启一个初始阶段,向bbr逻辑模块用netlink套接字发送初始的时延敏感值β=50。
21.另一方面,所述bbr逻辑模块,用于ack包计算出新的带宽和发包速度;所述拥塞窗口计算模块,用于接收带宽值b和β值,并根据返回来的ack包来获知链路往返时延rtt和获得在链路中的排队时延qrtt来更新发送速度;
22.所述netlink通信机制,用于内核和用户层通信机制;
23.所述强化学习智能体,用于将收到数值作为状态量,其他变量用于计算奖励;
24.所述网络状态监测模块,用于在所述bbr逻辑模块收到一个新的β后就记录网络初始状态。
25.进一步的,所述bbr逻辑模块,还包括:将发包后记录一段时间间隔内收到ack包的数量,再用这个数量除以时间间隔,作为测量的带宽值b。
26.进一步的,所述s8中数组长度为10。
27.进一步的,所述s4中初始的β值大小为1。
28.本发明的有益效果:
29.本发明将强化学习与拥塞控制算法bbr相结合的算法能充分利用bbr算法探测带宽的特性和强化学习自适应的特性,实现自适应网络状态,保持高吞吐和低时延;解决了传统的拥塞控制算法只针对特定场景有效的问题,借助强化学习自学习的功能,自动地能够训练出适应各种网络场景的模型,而不需要进行人工手动地调整。
附图说明
30.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
31.图1是根据本发明实施例的一种强化学习与bbr算法结合的的自适应拥塞控制方法流程示意图;
32.图2是根据本发明实施例的一种强化学习与bbr算法结合的的自适应拥塞控制系统的原理框图。
具体实施方式
33.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于
本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
34.根据本发明的实施例,提供了一种强化学习与bbr算法结合的的自适应拥塞控制方法及系统。
35.如图1
‑
2所示,根据本发明实施例的基于强化学习的自适应拥塞控制方法,以lte系统中下行链路作为场景,包括以下步骤:
36.步骤s1、融合深度强化学习和bbr协议的自适应拥塞控制方法,包括netlink模块、强化学习智能体、底层拥塞控制模块、网络状态监测模块和速率调整模块组成的系统,下面以真实的网络下数据传输为例子来说明;
37.步骤s2、首先在内核态开启底层拥塞控制模块进行数据传输,再在用户态开启强化学习智能体;
38.步骤s3、拥塞窗口计算模块根据传过来的β值和b来更新发送速率;
39.步骤s4、强化学习智能体先开启一个初始阶段,向底层拥塞控制模块用netlink套接字发送初始的β值;
40.步骤s5、底层拥塞控制模块收到β值后,根据公式计算出带宽值b,并将b值发送给速率调整模块;
41.步骤s6、与此同时,网络状态监控模块在底层拥塞控制模块收到β值时开启一个时间为t的定时器,定时器开始时利用收到的ack包开始记录网络初始值,定时器结束后,网络状态监控模块利用收到的ack包记录的网络结束值,与网络初始值的差异来更新网络状态。并将t值更新为数据包往返时延的平均值;
42.步骤s7、速率调整模块根据传过来的b值来更新发送速率;
43.步骤s8、当强化学习智能体收到网络状态值时,从中提取出改变对应动作的状态和奖励。当定时器超时后,强化学习智能体收集到了第一个历史网络状态,并填进数组,并根据这个状态数组和训练过的模型,挑选出适应网络状态的β值给底层拥塞控制模块;
44.步骤s9、重复步骤4
‑
8。
45.此外,所述bbr逻辑模块,用于ack包计算出新的带宽和发包速度;所述拥塞窗口计算模块,用于接收带宽值b和β值,并根据返回来的ack包来获知链路往返时延rtt和获得在链路中的排队时延q_r来更新发送速度;
46.netlink通信机制,用于内核和用户层通信机制;
47.强化学习智能体,用于将收到数值作为状态量,其他变量用于计算奖励;
48.网络状态监测模块,用于在所述bbr逻辑模块收到一个新的β后就记录网络初始状态。
49.bbr逻辑模块,还包括:将发包后记录一段时间间隔内收到ack包的数量,再用这个数量除以时间间隔,作为测量的带宽值b。
50.s8中数组长度为10。
51.s4中初始的β值大小为1。
52.具体的,首先要介绍的是整体的框架结构,最底层的是拥塞控制模块,它采用的是bbr算法。它保持bbr的功能不变。在上层中,网络监督模块在底层拥塞控制模块收到β值后,就开启一个定时器,并通过ack包里包含的信息来手机网络信息,在定时器超时时通过
netlink模块将这些网络信息发送给强化学习智能体,强化学习智能体根据这些网络信息获得动作β对应的状态和奖励,并根据训练的网络模型得到一个合适的β值给底层拥塞控制模块。底层拥塞控制模块根据β值计算出新的带宽b并发送给速率调整模块调节发送速率。
53.另外,底层拥塞控制模块采用的是bbr算法。bbr不断地基于当前带宽b以及当前的增益系数计算拥塞窗口c,以此结果作为拥塞控制算法的输出,在tcp连接的持续过程中,每收到一个ack,都会计算即时的带宽b。那么bbr是如何探测带宽的呢,bbr逻辑模块发包后记录一段时间间隔内收到ack包的数量,再用这个数量除以时间间隔,作为测量的带宽值b。
54.另外,速率调整计算模块收到带宽值b和β值,并根据链路往返时延r减去链路最小往返时延m_r相减来获得在链路中的排队时延q_r。之后利用公式b=b
‑
β*q_r/m_r来更新发送速度。
55.另外,网络状态监控模块,在bbr逻辑模块收到一个新的β后就记录网络初始状态:开始时已投递包的数量、开始时已丢失包的数量、开始时间。随后开启一个时长为t的定时器,定时器结束后,再重新记录状态:结束时已投递包的数量、结束时已丢失包的数量、结束时间;并将状态值:吞吐量=(结束时已投递包的数量
‑
开始时已投递包的数量)/(结束时间
‑
开始时间)、丢包率=(结束时已丢失包的数量
‑
开始时已丢失包的数量)/(结束时间
‑
开始时间)、时延和链路时延的比值、时延的变化程度、发送速率和接收速率的比值、时延测量值。
56.另外,netlink通信机制用于内核和用户层通信机制,相当于一种系统调用。
57.另外,强化学习智能体收到数值时将{时延和链路时延的比值、时延的变化程度、发送速率和接收速率的比值}作为状态量,其他变量用于计算奖励=10*吞吐量
‑
1000*时延
‑
2000*丢包率。
58.综上所述,借助于本发明的上述技术方案,通过将强化学习与拥塞控制算法bbr相结合的算法能充分利用bbr算法探测带宽的特性和强化学习自适应的特性,实现自适应网络状态,保持高吞吐和低时延;解决了传统的拥塞控制算法只针对特定场景有效的问题,借助强化学习自学习的功能,自动地能够训练出适应各种网络场景的模型,而不需要进行人工手动地调整。
59.以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1