一种基于本地化差分隐私的移动端位置隐私保护方法
1.本发明涉及位置隐私保护技术领域,更具体的说是涉及一种基于本地化差分隐私的移动端位置隐私保护方法。
背景技术:
2.持续发布位置统计信息会导致潜在的隐私泄露风险,例如,在实时流量统计中,攻击者可以根据发布的数据(包括每个位置的访问次数或实时流量密度图)来重建移动端的轨迹。即使没有公开用户的身份,攻击者也可以通过统计信息得知用户的住所和工作地点,从而可以识别出同一用户的其他位置轨迹。可见,对于移动端持续上传自身位置的情况下,仍很难有效保护用户的位置隐私不被泄露。
3.目前,已经有众多研究者对位置隐私保护进行了深入研究,提出了各种方式来保护用户的位置隐私。在传统位置隐私保护方法中,第三方服务器承担着不可或缺的作用,用户对自身位置的保护往往依赖于服务器,然而由于服务器因素导致隐私泄露的问题层出不穷,在本地完成对自身位置的保护已经是大势所趋。在众包环境下,用户需要服务器提供信息,同时还要将众包数据提交给服务器,但是将自身的隐私信息交由服务器来进行保护本身就是不可靠的。
4.并且,在大数据时代,运营商以及各种互联网企业拥有着巨量的用户数据,而这些数据并不是全部都不可见的,互联网本身的特性使得攻击者很容易就能收集到用户的相关背景知识,而用户在网络中的痕迹难免互相关联,从而可以从中推断出相应的隐私信息。例如,某个用户在网络上发布了一张自拍照,则攻击者可以根据照片中的标志性建筑物、照片的拍摄角度、光线等信息推断出用户当前所处的位置,而根据其位置特性,可以猜测出该位置为用户的住所或者公司等敏感位置。可见,空间众包的位置隐私保护需要一种能够考虑攻击者拥有背景知识的隐私保护技术。
5.因此,为了移动端在持续向服务器上传自身位置情况下的位置隐私能够被有效保护,如何提供一种基于本地化差分隐私的移动端位置隐私保护方法是本领域技术人员亟需解决的问题。
技术实现要素:
6.有鉴于此,本发明提供了一种基于本地化差分隐私的移动端位置隐私保护方法,有效保护了移动端在持续向服务器上传自身位置的情况下的位置隐私。
7.为了实现上述目的,本发明提供如下技术方案:
8.一种基于本地化差分隐私的移动端位置隐私保护方法,应用于服务器端及移动端,包括:
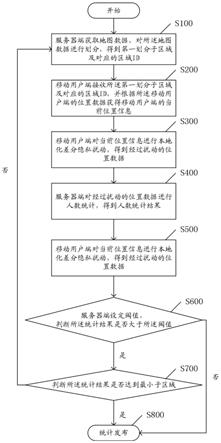
9.s100:服务器端获取地图数据,对所述地图数据进行划分,得到第一划分子区域及对应的区域id;
10.s200:移动端接收所述第一划分子区域及对应的区域id,并根据所述移动端的当
前位置数据获得移动端的当前所在区域id;
11.s300:移动端通过当前所在区域id对当前位置信息进行本地化差分隐私扰动,得到经过扰动的位置数据。
12.优选的,还包括:
13.s400:服务器端对经过扰动的位置数据进行人数统计,得到人数统计结果;
14.s500:服务器端设定阈值,判断所述统计结果是否大于所述阈值,若是,则进行步骤s600;
15.s600:判断所述统计结果是否达到最小子区域,若是,则进行步骤s700;
16.s700:发布所述统计结果。
17.优选的,所述s200,包括:当服务器端接收到移动端查询当前区域编号请求时,将得到的第一划分子区域及对应的区域id发送至所述移动端,所述移动端根据第一划分子区域及对应的区域id查询以及当前所在位置,查询当前所在区域id。
18.优选的,所述s300进行本地化差分隐私扰动的具体过程包括:
19.设a={a1,a2,...,a
n
}为地图经过服务器划分后的区域id,其中n表示地图经过划分之后的区域总数据;
20.根据所述s200中移动端得的当前所在区域id的结果,设a
i
(1≤i≤n)为当前位置的id,n维向量l表示任意用户的当前位置,l为位置向量,即:
[0021][0022]
其中,l
j
表示位置向量l中的第j位的值;
[0023]
对位置向量l进行扰动,在位置向量l中任意用户都使用随机相应的机制进行扰动,即:
[0024][0025]
其中,f是用来控制隐私保护程度的参数,向量u为永久性随机响应;
[0026]
通过扰动永久性随机相应u中任意用户来增加另一个随机性:
[0027][0028]
其中,s为瞬时性随机响应,q、p表示将s中的第k位设置为1的概率。
[0029]
优选的,所述s300还包括:所述移动端周期性判断区域id是否更新,若已更新,则对更新之后的区域id再次进行扰动。
[0030]
优选的,所述s400还包括:
[0031]
用控制隐私保护程度的参数f、概率q以及概率p表示瞬时性随机响应中的值是1的概率,即:
[0032]
[0033][0034]
根据公式计算差分隐私ε;
[0035]
根据差分隐私ε得到每个区域最后的人数统计结果。
[0036]
优选的,所述s500还包括:判断所述统计结果是否大于所述阈值,若否,则直接执行步骤s700发布所述统计结果。
[0037]
优选的,所述s600还包括:所述统计结果没有达到最小子区域,则返回步骤s100将当前区域进行重新子区域划分。
[0038]
优选的,所述最小子区域指的是服务器预定义的地图划分之后的最小值,防止区域无限划分,造成不必要的计算资源浪费。
[0039]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于本地化差分隐私的移动端位置隐私保护方法,采用本地化差分隐私来对移动端的位置进行扰动,在本地完成对用户位置数据的干扰,使单个用户的位置数据没有可用性,攻击者或者恶意服务器无法从单个用户单次上传的数据中分析出有效信息,隐私保护效果显著,并对地图进行划分,同时考虑到不同时刻不同区域的用户数量有所变化,将根据区域内用户数量对地图进行动态划分,在保留本地化差分隐私原有优势的基础上,使得服务器端获得的用户位置分布更为细致。此外,本发明可以及时响应位置分布的变化,从而大大提高了数据的可用性。
附图说明
[0040]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0041]
图1为本发明提供的移动端位置隐私保护方法流程示意图;
[0042]
图2为本实施例2提供的地图分割示意图;
[0043]
图3为本实施例2提供的本发明方法与现有技术在不同数据量下的错误率示意图;
[0044]
图4为本实施例2提供的本发明方法与现有技术之间的错误率差异示意图;
[0045]
图5为本实施例2提供的本发明方法与现有技术之间的错误率差异运行时间的对比图。
具体实施方式
[0046]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0047]
实施例1
[0048]
参见附图1所示,为本发明实施例公开的一种基于本地化差分隐私的移动端位置
隐私保护方法,应用于服务器端及移动端,包括:
[0049]
s100:服务器端获取地图数据,对地图数据进行划分,得到第一划分子区域及对应的区域id;
[0050]
s200:移动端接收第一划分子区域及对应的区域id,并根据移动端的当前位置数据获得移动端的当前所在区域id;
[0051]
s300:移动端通过当前所在区域id对当前位置信息进行本地化差分隐私扰动,得到经过扰动的位置数据。
[0052]
s400:服务器端对经过扰动的位置数据进行人数统计,得到人数统计结果;
[0053]
s500:服务器端设定阈值,判断统计结果是否大于阈值,若是,则进行步骤s600;
[0054]
s600:判断统计结果是否达到最小子区域,若是,则进行步骤s700;
[0055]
s700:发布统计结果。
[0056]
在一个具体实施例中,s100包括:获取地图数据,该地图数据为地图空间,用hilbert曲线对地图空间进行划分,并应用动态希尔伯特曲线(dhc
‑
dynamic hilbert curve)将地图从二维空间映射到一维空间,从而确保空间相关性,同时可以根据用户位置密度动态划分地图,以响应移动端的位置变化。
[0057]
在一个具体实施例中,s200包括:服务器端首先将地图递归地分为相等大小的4个子区域,直到满足服务器预定义的最低位置精度要求为止。
[0058]
移动端发送查询请求到服务器段,服务器端把当前的地图分区情况和区域id发送给用户。
[0059]
在一个具体实施例中,s300包括:移动端将根据当前所在的位置,查询所在的区域id,再通过本地化差分隐私扰动后发送给服务器端。
[0060]
具体的,位置数据扰动过程为:
[0061]
采用rappor算法来对移动端的位置数据进行扰动,令a={a1,a2,...,a
n
}为地图经过服务器划分后的区域id,其中n表示地图经过分割之后的区域总数。用户从服务器获取区域id后,找到当前位置所属的id。令a
i
(1≤i≤n)为当前位置的id。然后,n维向量l(表示某个用户的当前位置)可被定义为
[0062][0063]
其中,l
j
表示向量l中第j位的值。
[0064]
之后需要对移动端的位置向量l进行扰动,在位置向量l中的每一位都使用如下随机响应的机制来进行扰动
[0065][0066]
其中,f是用来控制隐私保护程度的参数,其取值范围为(0,1),其值越大,隐私保护程度越高。在rappor算法中,向量u称为永久性随机响应。
[0067]
然后,为了增强隐私保护效果,rappor算法通过扰动永久性随机响应u中的每一位来增加另一个随机性,如下所示:
[0068][0069]
也就是说,系统参数q(或p)的值表示将s(在rappor算法中称为瞬时性随机响应)中的第k位设置为1的概率。
[0070]
最后,瞬时性随机响应s将会发送到数据收集服务器。
[0071]
在一个具体实施例中,s300还包括:移动端周期性判断区域id是否更新,若已更新,则对更新之后的区域id再次进行扰动。
[0072]
具体的,如果当前区域中的用户数量大于预定义的阈值,并且区域划分未达到服务器定义的最小范围,则将该区域划分为4个相等大小的子区域,然后对地图划分状态和区域id进行更新。
[0073]
更具体的,如附图2所示,为本实施例提供的阈值σ=1的地图分割示意图,根据给定阈值进行递归划分,直到分割后区域中的用户数量不超过给定阈值,如果达到了服务器定义的最高位置精度,将不会继续对地图进行分割;
[0074]
在位置数据连续上传的情况下,移动端将会周期性地查询地图分区是否已更新,如果区域id已更新,则用户将会对更新之后的区域id进行扰动;
[0075]
如果用户离开当前区域,并且包含当前区域和相邻区域的区域中的用户数量小于σ,则当前区域和相邻区域将合并为划分之前的区域,区域id将同时更新。
[0076]
这样,可以根据区域内用户数量的变化实时更新地图分区,使得移动端所在的区域划分更为细致,移动端的位置分布更为精确,提高数据可用性的同时保证了每个用户的位置隐私不受损失。
[0077]
在一个具体实施例中,s400包括:服务器端接收到经过扰动的位置数据之后,服务器可以计算出每个区域的用户数量的的统计信息。
[0078]
具体的,服务器收到用户发送的数据之后,可以根据预定义的值f,q,p以及用户本地计算得到的瞬时性随机响应s来计算得到每个区域最后的统计结果。在用户只发送一次数据的情况下,攻击者要想得知用户的具体位置,只能通过用户上传的扰动之后的瞬时性随机响应,而瞬时性随机响应经过了两次随机化,对于攻击者来说,完全无法从中分辨出用户的真实位置。
[0079]
根据rappor的实现过程,我们可以用f,p,q来表示在用户上传的瞬时性随机响应中的值是1的概率,如下所示:
[0080][0081][0082]
根据本地化差分隐私的定义,我们可以知道上述随机编码方法满足ε
‑
差分隐私,其中q
*
和p
*
可以由公式上述计算得出,证明过程如下。
[0083]
令rr1为两个条件概率之比,即为了满足本地化差分隐私条件,该比值必须小于或等于e
ε
,则
[0084][0085]
即此时
[0086]
根据差分隐私ε得到每个区域最后的人数统计结果。
[0087]
上述证明方式自然会扩展到移动端所上传的所有数据,因为每个移动端上传的瞬时性随机响应是一组向量,而向量中每一位的计算都是独立的,对于服务器端收到的移动端统计数据来说,每位移动端的位置数据随机化的概率是不变的,因而不会影响最终结果。
[0088]
具体的,位置数据统计过程为:
[0089]
使用em算法来对各区域移动端密度进行计算。
[0090]
具体为:
[0091]
地图区域编码表示为一组向量a={a1,a2,...,a
n
},其中a
i
可以用来表示用户当前所处的位置,令x
i
为相应位置区域的n维向量l的对应表示(即x
i
的第i位设置为1,其他为设置为0)。假设表r存有服务器端收集到用户上传的n条记录,pos={pos1,pos2,
…
,pos
n
}是表r中记录的pos的值的集合,在给定第r个观测值pos
r
的情况下,按照前文扰动方式通过l=x
i
生成pos
r
的概率可以通过贝叶斯公式计算得出,如下所示:
[0092][0093]
其中n表示前文中使用dhc方式划分的区域数量。似然度p(pos
r
|l=x
i
)的计算方式如下:根据上述第二步的扰动方式,给定位置向量l,分别计算出相应的永久随机响应u的第k位为1和0的概率如下:
[0094][0095][0096]
此外,根据上一小节中关于瞬时性随机响应的计算方式,在给定k=1的情况下,瞬时随机响应s的第k位为1和0的概率分别为:
[0097][0098][0099]
同理可得,给定l
k
=0,瞬时随机响应s的第k位为1和0的概率分别为:
[0100][0101][0102]
给定第r个观测值pos
r
,假设pos
r,u
表示pos
r
的第u位的值(pos
r,u
的值为0或1且1≤r≤n)。则似然度p(pos
r
|l=x
i
)的计算方式如下:
[0103][0104]
例如,当pos
r
=0101且l=x2=0100时,似然度p(pos
r
|l=x2)的计算方式如下:
[0105][0106]
其中,pos
r,1
=0,pos
r,2
=1,pos
r,3
=0,pos
r,4
=1,则似然度p(pos
r
|l=x2)可以根据如下公式计算:
[0107]
p(pos
r
|l=x2)=p(s1=1|l1=0)
×
p(s2=1|l2=1)
×
p(s3=0|l2=0)
×
p(s4=1|l4=0)
[0108]
假设我们前文设置的rappor参数为f=0,q=0.75,p=0.25,则此时的似然度p(pos
r
|l=x2)为:
[0109]
p(pos
t
|l=x2)=(1
‑
p)
×
q
×
(1
‑
p)
×
p=(1
‑
0.25)
×
0.75
×
(1
‑
0.25)
×
0.25=
0.105
[0110]
使用em算法计算p(l=x
i
)的过程如下:
[0111]
(1)初始化:指定初始参数其中,x
i
为相应位置区域的n维向量l的对应表示,1≤i≤n,n为当前划分的区域数量;
[0112]
(2)e
‑
step:使用当前参数计算后验概率p(l=x
i
|pos
r
),计算过程如公式:
[0113][0114]
(3)m
‑
step:更新参数如公式:
[0115][0116]
(4)迭代:重复步骤2和步骤3,直到参数的更改在预定义的阈值γ内,如公式所示:
[0117][0118]
其中,γ是服务器预定义的数值,用来判断计算收敛;
[0119]
(5)最后,通过用户扰动之后的位置数据就可以得出区域a
i
的密度估算值,即:
[0120][0121]
在一个具体实施例中,s500还包括:判断所述统计结果是否大于阈值,若否,则直接执行步骤s700发布所述统计结果。
[0122]
在一个具体实施例中,s600还包括:统计结果没有达到最小子区域,则返回步骤s100将当前区域进行重新子区域划分。
[0123]
具体的,最小子区域指的是服务器预定义的地图划分之后的最小值,防止区域无限划分,造成不必要的计算资源浪费。
[0124]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于本地化差分隐私的移动端位置隐私保护方法,采用本地化差分隐私来对移动端的位置进行扰动,在本地完成对用户位置数据的干扰,使单个用户的位置数据没有可用性,攻击者或者恶意服务器无法从单个用户单次上传的数据中分析出有效信息,隐私保护效果显著,并对地图进行划分,同时考虑到不同时刻不同区域的用户数量有所变化,将根据区域内用户数量对地图进行动态划分,在保留本地化差分隐私原有优势的基础上,使得服务器端获得的用户位置分布更为细致。此外,本发明可以及时响应位置分布的变化,从而大大提高了数据的可用性。
[0125]
实施例2
[0126]
实验分析
[0127]
实验分两个部分,分别是使用仿真的数据集和真实的数据集来进行实验。首先模拟了大量具有不同移动参数的模拟数据集,并将这些数据用于初步实验评估。其次,使用真
实数据集gowalla来验证该方法的可用性。在实验中,使用错误率er来量化方法中的误差,具体公式为:
[0128][0129]
其中n表示服务器接收移动端位置数据之前的区域划分的初始值(服务器预定义的最低位置精度要求),d
i
和d'
i
对应于第i个区域内实际用户的数量和扰动后的用户的数量。
[0130]
为了与本发明提出的方法做出对比,不再进行动态划分,根据服务器定义的最高位置精度要求将地图分为大小相等的区域,然后同样使用rappor来扰动移动端的位置。使用现有技术中的静态方法以最高的精度来进行地图分割,可以使移动端在地图上的位置变化更加敏感,为了以示区分,本发明所提的一种基于本地化差分隐私的移动端位置隐私保护方法以dr
‑
ldp表示。
[0131]
(1)仿真实验
[0132]
首先,使用matlab来模拟具有不同移动行为的用户。在20
×
20单位方格的区域上随机生成模拟用户,使他们在整个区域内以不同的速度自由移动(前进,转向,暂停),并周期性的记录他们当前的位置。最低位置精度范围设置为4
×
4个单位的方格,最高位置精度范围设置为1
×
1个单位的方格。dr
‑
ldp中的阈值σ设置为10,即,当某个区域中的人数大于σ时,当前区域将被分为4个大小相等的区域。对于这两种方法,分别生成了1k,5k和10k的用户,以观察这两种方法在用户数量不同时的性能。
[0133]
如附图3所示,显示了本发明方法与现有技术在不同数据量下的错误率。因为实验是在移动端连续的位置数据生成下进行的,所以选取同样长度时间内的平均错误率作为比较。图中,x轴和y轴分别表示数据量的大小和在不同数据量下的错误率。在该实验中,f,q,p分别设置为0、0.75和0.25,对应于ε=ln(9)。从图中可以看出,对于这两种方法,错误率都会随着数据量的增加而减小,并且在数据量的增加的过程中,错误率逐渐接近于0,这表明ldp适合用于移动端的位置隐私保护。可以看到,使用dr
‑
ldp的错误率在不同的数据量之下均低于静态方法的错误率,这是因为dp
‑
ldp方法会动态划分地图空间,从而使得区域划分会更加合理,而静态方法的区域中用户数量分布不均匀,在用户数量较少的区域,其相对误差就会较大,而在用户密集的区域,两种方法的错误率相差不大,因此,在整体空间内使得了dr
‑
ldp方法的错误率相对较小。
[0134]
(2)用真实数据集实验
[0135]
用真实数据集实验主要是为了评估两种方法在实际环境中的有效性。为了验证dr
‑
ldp方法的实用性,我们从gowalla数据集中选择了1326个真实用户的签到数据,并进行了初步处理。在此实验中,将f分别设置为0.2、0.75和0.25,这提供了差分隐私。
[0136]
如附图4所示,在一段时间内真实数据集上本发明方法与现有技术之间的错误率差异(计算间隔20h),其中,x轴和y轴分别表示时间周期和错误率。可以看出,在真实位置数据集中,dr
‑
ldp的错误率始终低于静态方法,与仿真实验相比,差异更加明显,同时,在真实数据集上进行实验的时候静态方法的错误率均要高于其在仿真实验时的错误率。这是因为在真实位置数据集中,移动端的位置分布非常不均匀,这导致静态方法会计算大量不存在
用户的区域,这大大增加了位置扰动的误差,从而影响了位置精度。由于dr
‑
ldp方法的特性,会将人数较少的区域合并,减少了区域的分割数量,降低了位置分布的偏差。这说明了在真实环境中,dr
‑
ldp方法在数据统计发布时的数据可用性是较为良好的。
[0137]
如附图5所示,为本发明方法与现有技术之间的错误率差异运行时间的对比图,我们可以观察到dr
‑
ldp的性能明显优于静态方法,其中dr
‑
ldp的运行时间一般在5s
‑
7s之间,而静态方法的运行时间普遍在8s以上。主要原因是静态方法需要计算所有基本单元,dr
‑
ldp不会分割用户数量小于σ的区域,从而降低了计算复杂度。随着时间的持续,静态方法的运行时间基本维持不变,而dr
‑
ldp方法的运行时间在逐步下降,随后维持稳定。这是因为静态方法的算法复杂度不随时间的变化而改变,而dr
‑
ldp方法在用户进入地图空间之后会动态划分区域,随着用户数量的改变,地图划分情况也随之稳定,用户的进入离开不会影响大范围的区域,因而其算法复杂度在刚开始会逐渐下降,在区域划分大致完成之后其算法复杂度会维持在一定水平,其运行时间也随之改变。
[0138]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0139]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1