一种基于参数化动作空间的网络能耗两级控制方法
1.本发明涉及数据中心网络技术领域,尤其是一种基于深度强化学习的参数化动作空间的网络能耗两级控制方法。
背景技术:
2.随着大数据时代的到来,作为支撑云计算技术的基础设施,拥有丰富计算能力和显著存储能力的数据中心网络(data center network,dcn),成为学术界和工业界的研究热点。为了支撑日益增长的云计算服务,全球范围内数据中心迅猛发展。据synergyresearch的最新统计报告,到2020年底,超大规模数据中心在全球范围内已建成超过597座。2020年全球数据中心增长率为18.3%,云计算相关业务增长率为40%。另一方面,单个数据中心的网络设备规模也呈指数级增长。如此庞大规模和数量众多的数据中心,在提供大量数据存储和计算服务的同时,也给能耗的管理带来了巨大挑战。根据研究报告,2017年数据中心消耗的电能占全美所有能耗的比重为2%,且该消耗仍然以每年12%的速度增长。数据中心是由it系统和相关支撑系统(如冷却系统、电力传输系统、照明系统等)组成,其中数据中心it系统包括计算设备、存储设备、网络设备等。在数据中心能耗方面,根据文献的调研结果,全球范围内路由器、交换机、服务器等数据中心设备总共消耗的电能占全球总耗电量的比重超过了5%。此外,为了满足高性能和高可靠性的要求,数据中心网络架构通常按照1:1的收敛比进行设计以满足高峰流量负荷。然而在实际网络中网络流量一般很少达到峰值,过度预留的链路带宽大部分时间都处于低利用率或者空闲状态,造成巨大的能源浪费。相关研究资料显示,云数据中心的平均资源利用率只维持在10%左右,而且云服务器按需服务形式使其在大部分时间都处于空闲状态,即便如此,空闲服务器和链路也会消耗满负荷状态下60%的能耗。此外,在真实的数据中心网络中,链路的平均利用率在5%到25%之间,而且白天和晚上差异巨大,所以在数据中心网络级能耗方面(包括交换机/路由器/链路等)还有非常大的优化空间。显然,解决数据中心网络层面的能耗问题已迫在眉睫,高效节能的数据中心对环境保护和产业发展都有很大的价值和好处。
3.学术界和工业界都为实现绿色数据中心进行了大量的研究,如基于贪心策略的方法对数据中心网络级能耗进行优化。该方法无法应对网络流量突发带来的能耗影响,对于流完成时间以及链路冗余率等因素缺乏全面的考虑。并且随着网络规模的提升,计算复杂度呈指数级增加,不适合基于实时流量快速反应部署的数据中心网络。如基于网络拓扑的启发式算法能够获得近似最优解,并大幅度降低计算时间。但是,启发式算法其本身需要根据不同的实际应用场景,设置不同的启发机制,故需要大量经验的积累和尝试,而且启发式算法理论上缺乏准确有效的迭代停止条件。
4.近年来,深度学习以及强化学习技术的发展,为数据中心网络能耗节约问题提供了新的思路。所提出的模型基本上是在链路带宽分配,流完成时间等约束条件限制下,通过流量聚合实现网络流整合,进行任务调度。在这之后,将空闲链路和网络设备关闭或休眠,以达到节能的目的。但这些工作一味追求最大化节能,往往忽略了网络的可靠性和可用性
等关键因素,容易出现单点故障(single
‑
point
‑
of
‑
failure)问题。一旦某个结点或者链路出现故障,就会影响业务连续性,造成丢包、断链等问题,严重影响用户体验。另一方面,单纯地运用强化学习对时刻变化的数据中心网络流进行优化,会面临一系列新的问题,比如需要大量训练数据,强化学习难以收敛,在尝试学习的过程中犯错成本高,难以应用于真实环境等。虽然上述研究取得了良好的结果,但是仍有巨大的改进和提升空间,其缺乏对于链路故障的有效容错机制,无法有效利用网络流量的波动特性。并且,对于网络策略执行的定性判断不够细化,例如将离散动作(开启、关闭路由等)和连续动作(调整发送方数据发送速率)都视为同一种类型。
技术实现要素:
5.本发明的目的是针对现有技术的不足而提供的一种基于参数化动作空间的网络能耗两级控制方法,采用划分动作空间以及深度强化学习的方法,对数据中心网络级能耗进行优化,提高数据中心网络整体链路利用率,降低网络资源和能源开销,在应对网络流量突发带来的能耗影响,不仅节约了大量的网络能耗,而且大大改善了在应对流传输时间限制、可靠性要求、链路应对突发和智能网络带宽分配等方面的性能,较好的解决了数据中心网络低利用率、高能耗的问题。
6.本发明的目的是这样实现的:一种基于参数化动作空间的网络能耗两级控制方法,其特点是该方法包括以下具体步骤:
7.s1:将网络能耗问题抽象为多商品流(multi
‑
commodity flow)问题,即mcf问题。
8.s2:基于所抽象的mcf问题,建立基于深度学习的网络流量预测模型和基于深度强化学习的网络能耗优化模型。
9.s3:将由网络流量预测模型所预测的未来网络流作为能耗优化模型的输入,输出新的最优化网络路由集合,并依据此做出网络动作。
10.所述步骤s1具体包括:
11.s11:抽象网络关系和实体集合。
12.s12:基于抽象出的集合,将数据中心网络级能耗优化问题构建了一个混合整数线性规划数学模型,该模型由下述1~9式表述为:
13.minimize:
14.θ
v
×
∑
x∈v sx+2
×
θ
p
×
∑
k∈e l
k
ꢀꢀ
(1);
15.subject to:
[0016][0017][0018][0019][0020][0021]
[0022][0023][0024]
其中:公式(2)和公式(4)规定了流传输带宽要求和时间限制;公式(3)规定了流的可靠性要求,每一条流都应分配ft数量的备用路径;公式(5)规定了链路容量和流突发要求,对于每条链路k∈e,都具有最大带宽容量c
k
,并且该条链路上总流量所占用的带宽不能超过链路容量的α(α∈(0,1)),α的默认值为0.9;公式(6)规定了网络流量守恒的要求,即交换机和链路的总流入流量等于总流出流量。
[0025]
s13:假定所优化的路由路径是链路不相关的,则将公式(2)简化为下述10~11式:
[0026][0027][0028]
所述步骤s2具体包括:
[0029]
s21:考虑到数据中心网络的流量具有时间波动性,流量预测需要迅速、准确,在能耗优化系统中运用只保留忘记门的lstm单元实现多层动态rnn模型,该模型可以使神经网络在记忆最近的信息和很久以前的信息之间进行切换,让数据自己决定哪些信息要保留,哪些要忘记。
[0030]
s22:建立adam优化器,运用反向传播技术,对流量预测模型进行优化。
[0031]
s23:采用注意力机制来优化流量预测模型,为输出结果中的每个序列分配不同的权重,来实现更精准的预测结果。
[0032]
s24:结果未来数据中心网络流量变化趋势——流量预测模型所预测的网络流量,根据当前数据中心网络流量分布情况和网络结构,对当前网络链路带宽分配进行优化,以适应数据中心未来网络流量变化,提供满足流量需求的最小能耗路由策略。
[0033]
所述步骤s3具体包括:
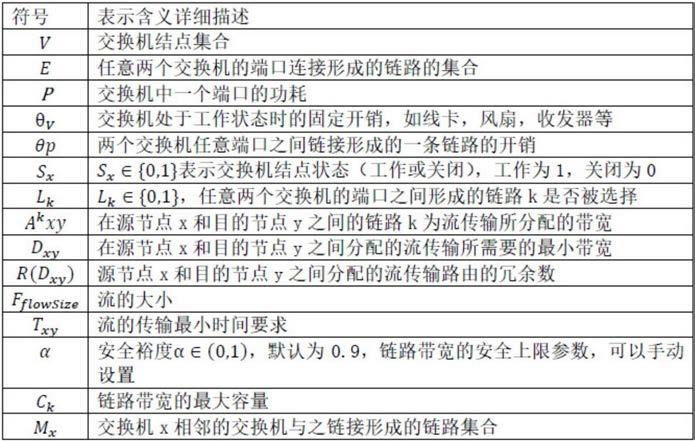
[0034]
s31:定义参数化动作空间,将数据中心网络中的交换机和链路抽象为序列[v1,v2,...,v
i
,...,v
n
]和[l1,l2,...l
i
,...l
n
],其中vi为二进制变量(1代表交换机开启,0代表关闭),调整v
i
值时的动作为离散动作;l
i
为未分配带宽占链路最大容量百分比,l
i
∈[0,1],调整l
i
值时的动作为连续动作。
[0035]
s32:对整个数据中心网络中正在运行的网络流建立一个流表f,其中包含每条流的运行情况,流被定义为一个序列组,包括流发送点和目的点,中间经过的链路集和占比,流的大小,以及该流传输时间限制,即由下述14式表示为:
[0036]
s={v,e,f|v
i
∈{0,1},.l
i
∈[0,1],p
linkset
{l1,l2,
…
l
t
},l
i
∈{0,1}}
ꢀꢀ
(14)。
[0037]
s33:将参数化动作空间应用到动作空间的划分当中。动作空间被划分为两层,即离散和连续两层动作空间。离散动作空间为改变交换机状态序列,而连续动作空间则是每个离散动作空间(交换机)其下的端口带宽占据比,强化学习的输出动作由下述15式对流表的途径路径进行更改:
[0038]
γ={v,e,f|vi∈{0,1},occ
i
∈[0,1],p
linkset
{l1,l2,
…
,l
t
},l
i
∈{0,1}}
ꢀꢀ
(15);
[0039]
对于这个参数化的动作空间γ下,动作值函数被表示为q(s,a)=q(s,v,occ_{v},
f)。所以当智能体处于s
t
状态下时,在每一个episode
t
下,
[0040]
s34,据此,贝尔曼方程式可以写为下述17式:
[0041][0042]
s35:将公式(17)求导,得对于每一个v
i
∈v,选择最大的q(s
t+1
,v,occ
*
,f),但是要计算连续空间的最大上界是非常困难的,所以针对每一个给定v
i
和maxq,可以找到下述18式:
[0043][0044]
s36:对于occv,使用一个确定性策略网络occ
v
(s,ω)来近似求得上述公式(18),其中,ω是神经网络权重参数。这个策略输出的将是一组连续变量。所有的输出结果的范围相同,因为剩余带宽的流量分配有限,相互影响,所以只用一个神经网络occ
v
(s,ω)去近似所有的即可。
[0045]
s37:采用下述19~22的梯度下降策略来更新神经网络参数:
[0046][0047][0048][0049][0050]
其中,确定性策略网络occ
v
(s,ω)的参数更新方法为公式(22)。
[0051]
s38:由于mcf问题存在多个约束限制,所以将奖励函数划分为3个部分,针对不同的情况对智能体进行不同奖励,总奖励为不同奖励之和相加。在定义奖励函数之前,需要明确路径容量的概念:一条路径path的最大容量取決于这条路上链路的最小容量:确路径容量的概念:一条路径path的最大容量取決于这条路上链路的最小容量:总奖励函数为r
tot
(s
t
,a
t
)=r1(s
t
,a
t
)+r2(s
t
,a
t
)+r3(s
t
,a
t
)。当前网络路由和链路带宽分配能使第i条流需求被满足时,获得的奖励为reward(s
t
,a
t
)=size
i
。当存在两个流集合seta和setb,seta需求能被满足,但setb当中的所有流需求均不能被满足,且seta和setb均可以为空,在满足流带宽分配的seta集合中,存在一个集合seta1,包含所有既满足链路带宽分配,又满足流在网络中的传输时间限制,由下述23式定义奖励函数:
[0052][0053]
其中:λ1,λ2,...λ
n
均为可调惩罚权重参数。当数据中心网络中的交换机和链路被关闭,相关的奖励函数被定义为:s
i
=1,l
k
=1。当数据中心网络链路备用路由数大于等于ft时,相关的奖励函数被定义为:r3(s
t
,a
t
)=r3(s
t
,a
t
)+λ5×
n,其中n为备用链路的数量。在r3(s
t
,a
t
)中,需要对网络中的每条流的备用
路由进行检查,然后反馈备用链路的数量n给智能体进行奖惩。当每条流所在路由中的每一条链路都存在备用链路时,整条路由存在冗余。备用路由冗余数ft可以被设置,默认为1,当对每条链路上的每个流进行冗余检查时,使用智能路由冗余检查算法,该算法的复杂度为o(l2),l为网络中的链路数量。
[0054]
本发明与现有技术相比具有从离散动作空间的视角来使用深度强化学习技术优化数据中心网络能耗,不仅在能耗节约方面效果显著,在应对流传输时间限制,可靠性要求,链路应对突发,智能网络带宽分配方面也有较好表现。仿真实验表明,随着网络规模的扩大,本发明在大型数据中心网络的节能效果均优于现有传统的和基于人工智能的方案。
[0055]
附图及附图说明
[0056]
图1为本发明流程图。
具体实施方式
[0057]
参阅图1,本发明按下述步骤进行网络能耗的两级控制:
[0058]
s1,将网络能耗问题抽象为多商品流(multi
‑
commodity flow)问题,即mcf问题,具体包括:
[0059]
s11,抽象网络关系和实体集合,详见下表1所示:
[0060]
表1抽象网络关系和实体集合
[0061][0062]
s12,基于抽象出的集合,将数据中心网络级能耗优化问题构建由下述1~9式表述的混合整数线性规划数学模型:
[0063]
minimize:
[0064]
θ
v
×
∑
x∈v sx+2
×
θ
p
×
∑
k∈e l
k
ꢀꢀ
(1);
[0065]
subject to:
[0066][0067][0068]
[0069][0070][0071][0072][0073][0074]
所述公式(2)和公式(4)规定了流传输带宽要求和时间限制;所述公式(3)规定了流的可靠性要求,每一条流都应分配ft数量的备用路径;所述公式(5)规定了链路容量和流突发要求,对于每条链路k∈e,都具有最大带宽容量c
k
,并且该条链路上总流量所占用的带宽不能超过链路容量的α(α∈(0,1)),α的默认值为0.9;所述公式(6)规定了网络流量守恒的要求,即交换机和链路的总流入流量等于总流出流量。
[0075]
s13:假定优化的路由路径是链路不相关的,则将2式简化为下述10~11式:
[0076][0077][0078]
s2,基于所抽象的mcf问题,建立基于深度学习的网络流量预测模型和基于深度强化学习的网络能耗优化模型,具体包括:
[0079]
s21,考虑到数据中心网络的流量具有时间波动性,流量预测需要迅速、准确,所以我们在能耗优化系统中运用只保留忘记门的lstm单元实现多层动态rnn模型,该模型可以使神经网络在记忆最近的信息和很久以前的信息之间进行切换,让数据自己决定哪些信息要保留,哪些要忘记。
[0080]
s22,建立adam优化器,运用反向传播技术,对流量预测模型进行优化。
[0081]
s23,采用注意力机制来优化流量预测模型,为输出结果中的每个序列分配不同的权重,来实现更精准的预测结果。
[0082]
s24,结果未来数据中心网络流量变化趋势——流量预测模型所预测的网络流量,根据当前数据中心网络流量分布情况和网络结构,对当前网络链路带宽分配进行优化,以适应数据中心未来网络流量变化,提供满足流量需求的最小能耗路由策略。
[0083]
s3,将由网络流量预测模型所预测的未来网络流作为能耗优化模型的输入,输出新的最优化网络路由集合,并依据此做出网络动作,具体包括:
[0084]
s31:定义参数化动作空间,将数据中心网络中的交换机和链路抽象为下述12~13式表示的序列:
[0085]
[v1,v2,...,v
i
,...,v
n
]
ꢀꢀꢀꢀꢀ
(12);
[0086]
[l1,l2,...l
i
,...l
n
]
ꢀꢀꢀꢀꢀꢀꢀ
(13);
[0087]
其中:vi为二进制变量,即1代表交换机开启,0代表关闭,调整vi值时的动作为离散动作;l
i
为未分配带宽占链路最大容量百分比,l
i
∈[0,1],调整l
i
值时的动作为连续动作。
[0088]
s32:对整个数据中心网络中正在运行的网络流建立一个流表f,所述流表f包含每
条流的运行情况;所述流为包括流发送点和目的点一个序列组、中间经过的链路集和占比、流的大小,以及该流传输时间限制的序列组s,且由下述14式定义为:
[0089]
s={v,e,f|v
i
∈{0,1},.l
i
∈[0,1],p
linkset
{l1,l2,...l
t
},l
i
∈{0,1}}
ꢀꢀ
(14)。
[0090]
s33:将动作空间划分为离散和连续两层动作空间,所述离散动作空间为改变交换机状态序列;所述连续动作空间为每个离散动作空间(交换机)其下的端口带宽占据比,强化学习的输出动作由下述15式对流表的途径路径进行更改:
[0091]
γ={v,e,f|v
i
∈{0,1},occ
i
∈[0,1],p
linkset
{l1,l2,...,l
t
},l
i
∈{0,1}}
ꢀꢀ
(15);
[0092]
对于这个参数化的动作空间γ下,动作值函数q(s,a)由下述16式定义为:
[0093]
q(s,a)=q(s,v,occ
_
{v},f)
ꢀꢀ
(16);
[0094]
当智能体处于st状态下时,在每一个episode
t
下,
[0095]
s34:据此,贝尔曼方程式可以由下述17式定义为:
[0096][0097]
s35:对上述公式(17)求导,得对于每一个v
i
∈v,选择最大的q(s
t+1
,v,occ
*
,f),对每一个给定v
i
和maxq找到由下述18式定义的
[0098][0099]
s36:对于occv,使用一个确定性策略神经网络occ
v
(s,ω),近似所有的即近似求得上述公式(18),其中:ω是神经网络权重参数。
[0100]
s37:采用下述19~22的梯度下降策略来更新神经网络参数:
[0101][0102][0103][0104][0105]
所述22式为确定性策略神经网络occv(s,ω)的参数更新。
[0106]
s38:由于所解决的mcf问题存在多个约束限制,所以将奖励函数划分为3个部分,针对不同的情况对智能体进行不同奖励,总奖励为不同奖励之和相加。在定义奖励函数之前,需要明确路径容量的概念:一条路径path的最大容量取決于这条路上链路的最小容量:总奖励函数为r
tot
(s
t
,a
t
)=r1(s
t
,a
t
)+r2(s
t
,a
t
)+r3(s
t
,a
t
)。当前网络路由和链路带宽分配能使第i条流需求被满足时,获得的奖励为reward(s
t
,a
t
)=size
i
。当存在两个流集合seta和setb,seta需求能被满足,但setb当中的所有流需求均不能被满足,且seta和setb均可以为空,在满足流带宽分配的seta集合中,存在一个集合seta1,包含所有既满足链路带宽分配,又满足流在网络中的传输时间限制,由此由下
述23式定义奖励函数r1(s
t
,a
t
):
[0107][0108]
其中:λ1,λ2,...λ
n
均为可调惩罚权重参数。
[0109]
当数据中心网络中的交换机和链路被关闭,相关的奖励函数r2(s
t
,a
t
)则由下述24式定义为:
[0110][0111]
其中:s
i
=1,l
k
=1。
[0112]
当数据中心网络链路备用路由数大于等于ft时,相关的奖励函数r3(s
t
,a
t
)由下述25式定义为:
[0113]
r3(s
t
,a
t
)=r3(s
t
,a
t
)+λ5×
n
ꢀꢀ
(25);
[0114]
其中:n为备用链路的数量。在r3(s
t
,a
t
)中,需要对网络中的每条流的备用路由进行检查,然后反馈备用链路的数量n给智能体进行奖惩。当每条流所在路由中的每一条链路都存在备用链路时,整条路由存在冗余。备用路由冗余数ft可以被设置,默认为1,当对每条链路上的每个流进行冗余检查时,使用智能路由冗余检查算法,其伪代码详见下述表2所示:
[0115]
表2智能路由冗余检查算法伪代码
[0116][0117]
该算法的复杂度为o(l2),l为网络中的链路数量。
[0118]
本发明提高数据中心网络整体链路利用率,并降低网络资源和能源开销,有效解决了现有数据中心网络低利用率、高能耗的问题。以上所述仅为本发明作进一步详细描述和说明,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1