一种实时检测失陷主机并回溯的方法与流程
1.本发明属于大数据网络安全技术领域,具体涉及一种实时检测失陷主机并回溯的方法。
背景技术:
2.随着信息技术的迅猛发展,企业内部网络威胁形式呈现了多样化、复杂化的特点,也面临着如apt攻击等新一代威胁的挑战,这一类威胁不仅传播速度更快,其利用的攻击面也越来越宽广,在这种威胁的常态下仅仅依靠传统的防火墙、入侵检测等安全防护设备已经不能完全满足企业用户的网络安全防护需要。以网络安全pdr模型来看,传统网络安全还是以“防护(p)”为主,但是随着攻击技术的发展,原有的防御手段不能满足需求时,攻防的平衡被打破,整个安全体系出现了缺失,因此,为了满足企业应对新形势威胁的安全防护需求,需要加强pdr模型中“检测(d)”和“响应(r)的安全防御能力,以使得整个安全体系重新恢复平衡,这其中在现阶段又以检测能力最为关键。
3.失陷主机通常是指网络入侵攻击者以某种方式获得控制权的主机,在获得控制权后,攻击者可能以该主机为跳板继续攻击企业内网的其他主机;另外,失陷主机往往具有无规律性、高隐蔽性的特点,很多入侵动作本身难以识别或无法确认攻击是否成功,但通过攻陷后的各种动作可以判断该主机已经被攻陷。政府、机关、企业的网络都会进行网络划分,比如说办公网络区、dmz(外网服务器区域),以此来保证网络的安全,所有和互联网通信的设备都会通过路由器设备,在路由器设备处采集流量将还原网络日志,通过网络日志分析,是否存在和恶意ip通信行为;办公设备或者服务器受攻击后被非法组织控制,此设备就会主动向非法组织服务器指定ip或者域名进行通信,并传输数据,针对这种向恶意ip或域名进行通信的设备我们就叫做失陷主机。
4.因此,传统网络安全以“防范”为中心,始终遵循p2dr策略,建立防护
‑
检测
‑
响应的模型,即首先对信息系统的风险进行全面评估,然后制定相应的防护策略,包括:在关键风险点部署访问控制设备,如防火墙,ips,认证授权等,修复系统漏洞,正确配置系统,定期升级维护,教育用户正确使用系统等。检测是响应和加强防护的依据,通过检测网络流量和行为,与预设策略进行匹配,如果触发防护策略,则认为发生了网络攻击,响应系统就执行预设动作阻止攻击,并进行报警和恢复处理。
5.与之对应的,传统安全产品,如终端杀毒、防火墙、ips、web应用防火墙等,均是基于已知特征和预设规则展开工作,其理论依据同样是p2dr防护模型,这是一种静态的、被动的、防御思维的安全模型。
6.失陷主机检测是企业应对新形势威胁的有效检测手段之一,其通过检测分析手段,快速定位攻击行为,并对攻击行为进行溯源,做到在攻击行为产生恶劣影响之前及时感知已失陷的主机,从而做到提前预警及快速响应,以降低恶意攻击行为对企业内网造成的影响和损失。
7.对于失陷主机的检测,通常需要通过传统的部署在企业内部网络边界的入侵检
测/防护系统、web应用防火墙等安全设备来捕获外部对企业内网各种入侵攻击事件的原始数据,然后对这些数据进行深度加工,关联分析处理后才能得到主机失陷的准确信息。但是往往由于传统安全设备上每日都会产生大量的安全事件和运行日志等安全数据,其数据量可能非常巨大,而且各设备之间以及同一设备各个数据之间缺乏有效关联,会形成信息孤岛,无法对大量数据进行整体性的关联分析,因此通过传统安全检测手段很难做到对新型攻击形势下主机失陷信息的准确分析和识别。
技术实现要素:
8.为了克服上述现有技术中存在的问题和不足,本发明旨在于提出一种能解决海量网络日志实时检测性能及失陷主机回溯分析的失陷主机检测、回溯的方法。
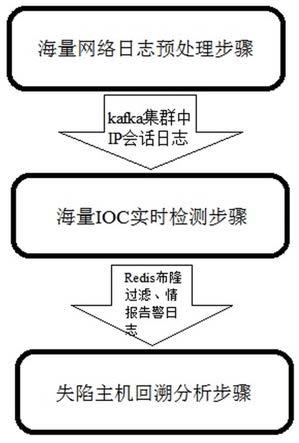
9.本发明的目的是通过以下技术方案实现的:一种实时检测失陷主机并回溯的方法,包括海量网络日志预处理步骤、海量ioc实时检测步骤及失陷主机回溯分析步骤;所述海量网络日志预处理步骤,通过安全探针设备将各安全域间的流量所产生的日志数据上传到智能分析检测平台,所述智能分析检测平台是一套部署在客户网络环境中的、基于大数据的应用系统,包括大数据处理引擎、ioc实时检测引擎以及部署在客户网络中的kafka集群,大数据处理引擎是数据处理的工具,kafka集群是一个消息中间件,相当于一个仓库,是智能分析平台的一部分,主要用于缓存数据,探针采集日志后会存储到仓库,然后大数据引擎就从仓库里面去取用对应的日志。智能分析检测平台将日志数据范式化后统一存储到kafka集群,然后通过智能分析检测平台的大数据处理引擎将kafka集群中的日志数据按照数据来源、源ip、目的ip的标签进行聚合形成ip会话日志,并将ip会话日志重新写入kafka集群供后续使用,kafka是一个消息中间件,搭建智能分析检测平台的时候就会搭建kafka集群,部署在客户网络中,是智能分析平台的一部分,主要用于缓存数据,kafka相当于一个仓库,探针采集日志后会存储到仓库,然后大数据引擎就从仓库里面去取日志;然后将ip会话日志按天进行存储,存储的同时提取需要检测的ip会话日志并发送到kafka集群中作为待检测ip会话日志供威胁情报检测用;接着,所述大数据处理引擎根据kafka集群中ip会话日志的源ip和目的ip与作为标准的ip总表进行比对,如果ip总表中不存在对应的源ip和目的ip,则ip总表将对应的ip会话日志入库,并存在ip总表相应的关联信息处;如果ip总表中已经存在对应的源ip和目的ip,则在ip总表中更新对应ip会话日志的最近出现时间、ip访问情况,ip总表是整个检测流程中的一个中间表,用于对失陷主机进行回溯用的,因此,这里更新ip总表的目的是为了保留该ip对应的关联信息,方便后续通过ip反查对应的关联信息,以提升查询效率。检测到失陷主机后,通过ip总表就可以查到,该失陷主机在哪些单位出现过,进而做下一步的追踪溯源。
10.即,海量网络日志预处理步骤主要是为了降低数据量并根据后续业务产生ip总表、ip会话日志等中间表信息,为后续回溯提供数据支持。
11.优选地,所述日志数据包括tcp会话、udp会话、icmp会话、应用访问日志和文件传输日志。
12.进一步的,所述海量网络日志预处理步骤中,所述安全探针通常指全流量探针,用于旁路采集网络流量,并把流量数据转换成各种网络的日志数据,主要包括全流量探针、
ids探针、netflow流量采集探针等,此类探针一般会部署到企业网络路由器出口、运营商流量出口等。
13.优选地,所述安全域是指被实时检测的办公网络区和dmz区,安全域间的流量是指办公网络区和/或dmz区访问互联网时的通信流量,比如张三访问了百度就会产生和百度服务器的通信流量,部署在路由器出口的安全探针就会捕获流量并将流量还原生一条一条的日志。
14.更进一步的,所述海量网络日志预处理步骤中,聚合形成ip会话日志,具体的,是为kafka集群中的所有日志数据设置日志id,日志id=数据来源+源ip+目的ip,并在日志数据中添加用于存储不同的网络日志类型的协议字段;将日志id相同的日志数据进行合并,将日志数据的接收流量、发送流量进行累加;合并时记录每个要合并的日志数据的开始时间和结束时间并进行排序,将最早的开始时间和最末的结束时间作为日志id的的开始时间和结束时间。
15.优选地,所述海量网络日志预处理步骤中,需要检测的ip会话日志,具体的,所述大数据处理引擎在对ip会话日志按天进行存储过程中,发现新的ip会话日志和/或在新的协议中出现的ip会话日志,则将其作为需要检测的ip会话日志,其中,新的协议是指,在聚合形成ip会话日志过程中,为存储不同的网络日志类型需要在聚合形成的ip会话日志中加入协议字段,即,内容相同的ip会话日志可能是属于不同类型的网络日志中的,为区分与已经判定正常的网络日志类型中的相同ip会话日志,这里需要将出现在新类型网络日志中的、与之前已经判定过或存储过的内容相同的ip会话日志进行区别对待,也需要进行检查。
16.具体的,所述ip总表中原始数据包括ip会话日志的来源、源ip、目的ip、接收流量、发送流量、会话开始时间、会话结束时间,存储的字段包括ip、所属国家、地区、首次发现时间、最近出现时间、ip访问情况,所述ip访问情况包括访问协议、访问单位、接收流量、发送流量、访问时间。
17.所述海量ioc实时检测步骤,用于进行实时检测,通过智能分析检测平台的ioc实时检测引擎从所述海量网络日志预处理步骤处理得到的kafka集群中读取ip会话日志,提取ip会话日志中的源ip和目的ip并通过redis布隆过滤器进行过滤,对redis布隆过滤器过滤出的已检测过的ip会话日志、直接从redis缓存中获取检测标签信息并生成情报告警日志,获取检测标签失败则丢弃该ip会话日志信息;对redis布隆过滤器过滤出的未检测过的ip会话日志、调用威胁情报中心的api进行检测,并对检测命中的ip会话日志生成情报告警日志;这里的主要需求是:海量ioc实时检测步骤中实时检测引擎读取的ip会话日志时会做策略,只有新出现的ip会话或者已经存在的ip会话、但是在新的协议出现的情况才会被检测,以减少检测日志数量。
18.优选地,所述海量ioc实时检测步骤中,情报告警日志中存储有攻击者ip、失陷主机、失陷主机单位、协议等信息。
19.进一步的,所述海量ioc实时检测步骤中,redis布隆过滤器在将检测过的ip会话中的源ip和目的ip存储到redis布隆过滤器中,检测的时候通过布隆过滤器过滤,布隆过滤器能够判定当前检测的ip会话是否检测过,检测过的ip会话日志直接从redis中获取对应的检测结果,没有检测过的ip会话日志则进入检测流程;对ip会话进行检测的时候如果命中情报,则会返回该ip对的威胁标签(如:c2、木马等)、设置标签,并将标签信息存储到
redis缓存(以ip为key),然后检测程序会生成一条告警日志,日志字段为源ip、目的ip、协议、单位信息、威胁标签、命中时间、命中情报等,其中源ip、目的ip、协议、单位信息来源于ip会话日志,威胁标签来源于命中结果,命中时间即检测时间,命中情报即检测的ip。
20.所述失陷主机回溯分析步骤,通过智能分析检测平台对所述海量ioc实时检测步骤得到的情报告警日志进行实时告警分析,定位失陷主机及所在单位,并钻取到ip会话日志的数据做进一步分析研判,同时,通过命中ip会话日志可以快速定位全网受影响的主机、流量传输情况以及会话建立的时间。即,在这一步中,失陷主机根据预处理中间表回溯到和当前失陷主机通信的ip及流量等信息。
21.更为优选地,所述智能分析检测平台还包括数据采集引擎、事件聚合引擎、威胁情报中心、取证系统等,本方案中对失陷主机的检测只是智能分析检测平台的一项检测能力,所述数据采集引擎包括安全探针设备,用于采集各安全域间的流量所产生的日志数据并上传到智能分析检测平台中,所述事件聚合引擎、威胁情报中心和取证系统则用于根据所述海量ioc实时检测步骤得到的情报告警日志进行实时告警分析,定位失陷主机及所在单位,并钻取到ip会话日志的数据做进一步分析研判,同时,通过命中ip会话日志可以快速定位全网受影响的主机、流量传输情况以及会话建立的时间。
22.有益效果:与现有技术方案相比,本发明所提供的这种技术方案的有益效果如下:1、基于目标检测+分割+分类的方式,本发明能够应对各种不同道路情况下的各种不同的道路病害情况,大大覆盖了病害会出现的各种场景,并且分割的方式能够比较好的刻画病害形态,而分类的方式则能对不同的病害进行详细的类别分类;2、该发明基于深度学习能够有较高的精度,并且模型训练完毕之后不需要再进行训练,可直接进行预测使用,保证了在使用阶段的计算量很小,预测精度和效率更高;3、该发明基于深度学习,该发明在处理病害问题上有较好的泛化能力,针对各种不同的路面场景都能够很好的进行结果预测,相比传统方法,受到拍摄的路面图片的影响更小。
附图说明
23.本发明的前述和下文具体描述在结合以下附图阅读时变得更清楚,附图中:图1为本发明回溯方法的逻辑示意图。
具体实施方式
24.下面通过几个具体的实施例来进一步说明实现本发明目的技术方案,需要说明的是,本发明要求保护的技术方案包括但不限于以下实施例。
25.实施例1作为本发明一种具体的实施方案,本实施例提供的这种实时检测失陷主机并回溯的方法,如图1所示,包括海量网络日志预处理步骤、海量ioc实时检测步骤及失陷主机回溯分析步骤。
26.具体的,所述海量网络日志预处理步骤,通过安全探针设备将各安全域间的流量所产生的日志数据上传到智能分析检测平台,所述智能分析检测平台包括大数据处理引
擎、ioc实时检测引擎以及部署在客户网络中的kafka集群,大数据处理引擎是数据处理的工具,kafka集群是一个消息中间件,相当于一个仓库,是智能分析平台的一部分,主要用于缓存数据,探针采集日志后会存储到仓库,然后大数据引擎就从仓库里面去取用对应的日志,智能分析检测平台将日志数据范式化后统一存储到kafka集群,然后通过智能分析检测平台的大数据处理引擎将kafka集群中的日志数据按照数据来源、源ip、目的ip的标签进行聚合形成ip会话日志,并将ip会话日志重新写入kafka集群供后续使用,kafka是一个消息中间件,搭建智能分析检测平台的时候就会搭建kafka集群,部署在客户网络中,是智能分析平台的一部分,主要用于缓存数据,kafka相当于一个仓库,探针采集日志后会存储到仓库,然后大数据引擎就从仓库里面去取日志;然后将ip会话日志按天进行存储,存储的同时提取需要检测的ip会话日志并发送到kafka集群中作为待检测ip会话日志供威胁情报检测用;接着,所述大数据处理引擎根据kafka集群中ip会话日志的源ip和目的ip与作为标准的ip总表进行比对,如果ip总表中不存在对应的源ip和目的ip,则ip总表将对应的ip会话日志入库,并存在ip总表相应的关联信息处;如果ip总表中已经存在对应的源ip和目的ip,则在ip总表中更新对应ip会话日志的最近出现时间、ip访问情况,ip总表是整个检测流程中的一个中间表,用于对失陷主机进行回溯用的,因此,这里更新ip总表的目的是为了保留该ip对应的关联信息,方便后续通过ip反查对应的关联信息,以提升查询效率。检测到失陷主机后,通过ip总表就可以查到,该失陷主机在哪些单位出现过,进而做下一步的追踪溯源。
27.海量网络日志预处理步骤主要是为了降低数据量并根据后续业务产生ip总表、ip会话日志等中间表信息,为后续回溯提供数据支持。
28.所述海量ioc实时检测步骤,海量ioc检测用于实时检测,通过智能分析检测平台的实时检测引擎从所述海量网络日志预处理步骤处理得到的kafka集群中读取ip会话日志,提取ip会话日志中的源ip和目的ip并通过redis布隆过滤器进行过滤,对redis布隆过滤器过滤出的已检测过的ip会话日志、直接从redis缓存中获取检测标签信息并生成情报告警日志,获取检测标签失败则丢弃该ip会话日志信息;对redis布隆过滤器过滤出的未检测过的ip会话日志、调用威胁情报中心的api进行检测,并对检测命中的ip会话日志生成情报告警日志;这里的主要需求是:海量ioc实时检测步骤中实时检测引擎读取的ip会话日志时会做策略,只有新出现的ip会话或者已经存在的ip会话、但是在新的协议出现的情况才会被检测,以减少检测日志数量。
29.所述失陷主机回溯分析步骤,通过智能分析检测平台对所述海量ioc实时检测步骤得到的情报告警日志进行实时告警分析,定位失陷主机及所在单位,并钻取到ip会话日志的数据做进一步分析研判,同时,通过命中ip会话日志可以快速定位全网受影响的主机、流量传输情况以及会话建立的时间。即,在这一步中,失陷主机根据预处理中间表回溯到和当前失陷主机通信的ip及流量等信息。
30.实施例2作为本发明一种更为详细的实施方案,本实施例提供的这种实时检测失陷主机并回溯的方法,包括海量网络日志预处理步骤、海量ioc实时检测步骤及失陷主机回溯分析步骤。
31.具体的,所述海量网络日志预处理步骤:首先,通过安全探针设备将各安全域间的流量所产生的日志数据上传到智能分析
检测平台,所述智能分析检测平台包括数据采集引擎、大数据处理引擎、ioc实时检测引擎、事件聚合引擎、威胁情报中心、取证系统以及部署在客户网络中的kafka集群,所述数据采集引擎包括安全探针设备,用于实现上述采集各安全域间的流量所产生的日志数据并上传到智能分析检测平台中的功能,大数据处理引擎是数据处理的工具,kafka集群是一个消息中间件,相当于一个仓库,是智能分析平台的一部分,主要用于缓存数据,探针采集日志后会存储到仓库,然后大数据引擎就从仓库里面去取用对应的日志,智能分析检测平台将日志数据范式化后统一存储到kafka集群所述日志数据包括tcp会话、udp会话、icmp会话、应用访问日志和文件传输日志;所述安全探针通常指全流量探针,用于旁路采集网络流量,并把流量数据转换成各种网络的日志数据,主要包括全流量探针、ids探针、netflow流量采集探针等,此类探针一般会部署到企业网络路由器出口、运营商流量出口等;所述安全域是指被实时检测的办公网络区和dmz区,安全域间的流量是指办公网络区和/或dmz区访问互联网时的通信流量,比如张三访问了百度就会产生和百度服务器的通信流量,部署在路由器出口的安全探针就会捕获流量并将流量还原生一条一条的日志。
32.然后,通过智能分析检测平台的大数据处理引擎将kafka集群中的日志数据按照数据来源、源ip、目的ip的标签进行聚合形成ip会话日志,并将ip会话日志重新写入kafka集群供后续使用。所述智能分析检测平台是一套部署在客户网络环境中的、基于大数据的应用系统,用于为客户网络起到安全防护作用,主要包括数据采集引擎、大数据处理引擎、ioc实时检测引擎、事件聚合引擎、威胁情报中心、取证系统等,本方案中对失陷主机的检测只是智能分析检测平台的一项检测能力,kafka是一个消息中间件,搭建智能分析检测平台的时候就会搭建kafka集群,部署在客户网络中,是智能分析平台的一部分,主要用于缓存数据,kafka相当于一个仓库,探针采集日志后会存储到仓库,然后大数据引擎就从仓库里面去取日志。ip会话日志重新写入kafka集群后,将ip会话日志按天进行存储,存储的同时提取需要检测的ip会话日志并发送到kafka集群中作为待检测ip会话日志供威胁情报检测用;接着,所述大数据处理引擎根据kafka集群中ip会话日志的源ip和目的ip与作为标准的ip总表进行比对,如果ip总表中不存在对应的源ip和目的ip,则ip总表将对应的ip会话日志入库,并存在ip总表相应的关联信息处;如果ip总表中已经存在对应的源ip和目的ip,则在ip总表中更新对应ip会话日志的最近出现时间、ip访问情况,ip总表是整个检测流程中的一个中间表,用于对失陷主机进行回溯用的,因此,这里更新ip总表的目的是为了保留该ip对应的关联信息,方便后续通过ip反查对应的关联信息,以提升查询效率。检测到失陷主机后,通过ip总表就可以查到,该失陷主机在哪些单位出现过,进而做下一步的追踪溯源。
33.进一步的,聚合形成ip会话日志,是为kafka集群中的所有日志数据设置日志id,日志id=数据来源+源ip+目的ip,并在日志数据中添加用于存储不同的网络日志类型的协议字段;将日志id相同的日志数据进行合并,将日志数据的接收流量、发送流量进行累加;合并时记录每个要合并的日志数据的开始时间和结束时间并进行排序,将最早的开始时间和最末的结束时间作为日志id的的开始时间和结束时间。
34.更进一步的,所述需要检测的ip会话日志,具体的,所述大数据处理引擎在对ip会话日志按天进行存储过程中,发现新的ip会话日志和/或在新的协议中出现的ip会话日志,则将其作为需要检测的ip会话日志,其中,新的协议是指,在聚合形成ip会话日志过程中,为存储不同的网络日志类型需要在聚合形成的ip会话日志中加入协议字段,即,内容相同
的ip会话日志可能是属于不同类型的网络日志中的,为区分与已经判定正常的网络日志类型中的相同ip会话日志,这里需要将出现在新类型网络日志中的、与之前已经判定过或存储过的内容相同的ip会话日志进行区别对待,也需要进行检查。
35.优选地,所述ip总表中原始数据包括ip会话日志的来源、源ip、目的ip、接收流量、发送流量、会话开始时间、会话结束时间,存储的字段包括ip、所属国家、地区、首次发现时间、最近出现时间、ip访问情况,所述ip访问情况包括访问协议、访问单位、接收流量、发送流量、访问时间。
36.综上,所述海量网络日志预处理步骤,主要是为了降低数据量并根据后续业务产生ip总表、ip会话日志等中间表信息,为后续回溯提供数据支持。
37.而所述海量ioc实时检测步骤,海量ioc检测用于实时检测,通过智能分析检测平台的ioc实时检测引擎从所述海量网络日志预处理步骤处理得到的kafka集群中读取ip会话日志,提取ip会话日志中的源ip和目的ip并通过redis布隆过滤器进行过滤:对redis布隆过滤器过滤出的已检测过的ip会话日志、直接从redis缓存中获取检测标签信息并生成情报告警日志,获取检测标签失败则丢弃该ip会话日志信息,其中,情报告警日志中存储有攻击者ip、失陷主机、失陷主机单位、协议等信息。
38.对redis布隆过滤器过滤出的未检测过的ip会话日志、调用威胁情报中心的api进行检测,并对检测命中的ip会话日志生成情报告警日志;这里的主要需求是:海量ioc实时检测步骤中实时检测引擎读取的ip会话日志时会做策略,只有新出现的ip会话或者已经存在的ip会话、但是在新的协议出现的情况才会被检测,以减少检测日志数量。
39.所述失陷主机回溯分析步骤,通过智能分析检测平台的事件聚合引擎、威胁情报中心和取证系统对所述海量ioc实时检测步骤得到的情报告警日志进行实时告警分析,定位失陷主机及所在单位,并钻取到ip会话日志的数据做进一步分析研判,同时,通过命中ip会话日志可以快速定位全网受影响的主机、流量传输情况以及会话建立的时间。即,在这一步中,失陷主机根据预处理中间表回溯到和当前失陷主机通信的ip及流量等信息。
40.优选地,所述海量ioc实时检测步骤中,redis布隆过滤器在将检测过的ip会话中的源ip和目的ip存储到redis布隆过滤器中,检测的时候通过布隆过滤器过滤,布隆过滤器能够判定当前检测的ip会话是否检测过,检测过的ip会话日志直接从redis中获取对应的检测结果,没有检测过的ip会话日志则进入检测流程;对ip会话进行检测的时候如果命中情报,则会返回该ip对的威胁标签(如c2、木马等)、设置标签,并将标签信息存储到redis缓存(以ip为key),然后检测程序会生成一条告警日志,日志字段为源ip、目的ip、协议、单位信息、威胁标签、命中时间、命中情报等,其中源ip、目的ip、协议、单位信息来源于ip会话日志,威胁标签来源于命中结果,命中时间即检测时间,命中情报即检测的ip。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1