基于区块链预言机的高价值数据上链系统及方法与流程
1.本发明涉及区块链技术领域,具体涉及基于区块链预言机的高价值数据上链系统及方法。
背景技术:
2.预言机就好比区块链世界中的一个第三方数据代理商,当区块链上的某个智能合约有数据交互需求时,预言机主要做的事情就是处理区块链里智能合约提供的请求,把一些链外的信息和数据传递到链内。
3.现有的区块链数据在上链时,没有根据区块链上若干个子节点的内存使用情况进行合理的筛选和分类,使得不同占存的高价值数据不能合理的上链存储,导致高价值数据上链的效果不佳。
技术实现要素:
4.本发明的目的在于提供基于区块链预言机的高价值数据上链系统及方法,解决以下技术问题:如何解决现有方案中不能根据若干个子节点的内存使用情况对高价值数据进行合理上链的技术问题。
5.本发明的目的可以通过以下技术方案实现:基于区块链预言机的高价值数据上链系统,包括节点统计模块、筛选排序模块、内存分配模块、上链分析模块和上链更新模块;节点统计模块用于获取区块链上的存储信息,该存储信息包含第一存储数据和第二存储数据,第一存储数据包含若干个子节点的未存储内存;第二存储数据包含若干个子节点的已存储内存,将存储信息发送至中心节点;筛选排序模块用于根据未存储内存和已存储内存,获取若干个子节点的内存可用率,将不小于预设的标准可用率的内存可用率对应的子节点标记为待上链节点;将若干个待上链节点根据内存可用率进行降序排列,得到第一节点排序集;内存分配模块用于根据存储信息中的第一存储数据获取未存储内存的存储均值,根据若干个待上链节点的未存储内存,计算未存储内存与存储均值之间的差值,得到内存调配值,对内存调配值进行分析,得到第二节点排序集,对第二节点排序集进行上链内存划分,得到划分排序集;上链分析模块用于获取待上链的信息,获取信息中不同数据的价值系数,将价值系数与预设的价值范围进行匹配,得到选中数据和备选数据,获取选中数据的占存并标记为第一占存,获取备选数据的占存并标记为第二占存;将若干个选中数据根据第一占存进行降序排列,得到选中排序集;将若干个备选数据根据第二占存进行降序排列,得到备选排序集;上链更新模块用于根据划分排序集将选中排序集中的若干个选中数据进行上链,根据备选排序集对上链的数据进行更新。
6.进一步地,分别对若干个子节点中的未存储内存和已存储内存进行取值和标记,将未存储内存标记为wcni,i=1,2,3...n;将已存储内存标记为ycni,通过公式计算获取若干个子节点的内存可用率。
7.进一步地,对内存调配值进行分析的具体步骤包括:将大于k的内存调配值对应的待上链节点设定为第一上链节点,将若干个第一上链节点降序排列,得到第一上链集;将不大于k的内存调配值对应的待上链节点设定为第二上链节点,将若干个第二上链节点降序排列,得到第二上链集;第一上链集和第二上链集构成第二节点排序集;k为正整数。
8.进一步地,对第二节点排序集进行上链内存划分的具体步骤包括:获取第二节点排序集中的第一上链集和第二上链集;根据预设的内存划分比例分别对第一上链集和第二上链集中的未存储内存进行划分,得到第一划分内存和第二划分内存,将第一划分内存设定为上链内存,将第二划分内存设定为动态内存;其中,上链内存用于存储高价值数据;动态内存用于存储其它数据;对第一上链集中的若干个上链内存和动态内存分类组合,得到第一上链划分集;对第二上链集中的若干个上链内存和动态内存分类组合,得到第二上链划分集;第一上链划分集和第二上链划分集构成划分排序集。
9.进一步地,获取信息中不同数据的价值系数的具体步骤包括:获取信息中不同的数据,在单位时间内获取数据的请求次数和请求频率,将请求次数标记qqci;将请求频率标记为qqpi;通过公式计算获取数据的价值系数;其中,a1和a2表示为不同的比例系数且均大于零。
10.进一步地,将价值系数与预设的价值范围进行匹配的具体步骤包括:将价值范围的最大值标记为j1;将价值范围的最小值标记为j2;将价值系数sjx
i
与价值范围进行对比:若sjx
i
>j2,则判定该价值系数对应的数据价值高,并将其设定为选中数据;若j2≥sjx
i
>j1,则判定该价值系数对应的数据价值中等,并将其设定为备选数据;若j1≥sjx
i
,则判定该价值系数对应的数据价值低。
11.进一步地,根据划分排序集将选中排序集中的若干个选中数据进行上链的具体步骤包括:获取选中排序集中若干个选中数据的第一占存,将第一占存分别与第一上链划分集和第二上链划分集中的若干个上链内存进行匹配;将排首位的选中数据分配至第一上链划分集中排首位的上链内存进行存储;将排第二位的选中数据分配至第二上链划分集中排首位的上链内存进行匹配,若该选中数据的第一内存不大于该上链内存,则上链成功;若该选中数据的第一内存大于该上链内存,则上链失败,并将该选中数据分配至第一上链划分集中排第二位的上链内存进行存储;依次类推,直至排序集中的选中数据分配至第二上链划分集中的上链内存进行存储,实现对选中排序集中若干个选中数据的动态上链。
12.进一步地,根据备选排序集对上链的数据进行更新的具体步骤包括:
将选中排序集中排末尾的选中数据设定为第一更新数据,将备选排序集中排首尾的备选数据设定为第二更新数据;当第一更新数据对应的价值系数小于第二更新数据对应的价值系数时,将第一更新数据下链,并将第二更新数据根据对应的第二占存进行上链,实现高价值数据的上链更新。
13.基于区块链预言机的高价值数据上链方法,包括:获取区块链上的存储信息,该存储信息包含第一存储数据和第二存储数据,第一存储数据包含若干个子节点的未存储内存;第二存储数据包含若干个子节点的已存储内存,将存储信息发送至中心节点;根据未存储内存和已存储内存,获取若干个子节点的内存可用率,将不小于预设的标准可用率的内存可用率对应的子节点标记为待上链节点;将若干个待上链节点根据内存可用率进行降序排列,得到第一节点排序集;根据存储信息中的第一存储数据获取未存储内存的存储均值,根据若干个待上链节点的未存储内存,计算未存储内存与存储均值之间的差值,得到内存调配值,对内存调配值进行分析,得到第二节点排序集,对第二节点排序集进行上链内存划分,得到划分排序集;获取待上链的信息,获取信息中不同数据的价值系数,将价值系数与预设的价值范围进行匹配,得到选中数据和备选数据,获取选中数据的占存并标记为第一占存,获取备选数据的占存并标记为第二占存;将若干个选中数据根据第一占存进行降序排列,得到选中排序集;将若干个备选数据根据第二占存进行降序排列,得到备选排序集;根据划分排序集将选中排序集中的若干个选中数据进行上链,根据备选排序集对上链的数据进行更新。
14.本发明的有益效果:1、根据区块链上若干个子节点的内存可用率并对若干个子节点进行筛分,得到待上链节点,使得已存储内存使用较多的子节点不进行高价值数据的上链,避免已存储内存使用较多的子节点影响高价值数据上链的运行;根据未存储内存的存储均值来对若干个待上链节点进行分类,使得不同大小的未存储内存来存储不同占存的高价值数据,使得高价值数据上链的存储更加合理高效;根据内存划分比例对未存储内存进行划分,使得未存储内存内可以实现对高价值数据以及其它数据分别进行存储,并且互不影响,可以有效提高高价值数据上链的整体效果,避免高价值数据分配不合理进而影响整个子节点的运行效果;2、通过将待上链的信息中不同数据根据价值系数分成选中数据和备选数据,根据选中数据的第一占存以及第一上链划分集和第二上链划分集中的若干个上链内存进行动态分配,使得第一上链划分集和第二上链划分集中的若干个上链内存均可以进行高价值数据的上链,使得高价值数据的上链分配的更均匀,避免某一子节点出现问题时影响高价值数据的使用,备选数据根据价值系数的变化可以变成选中数据并上链,便于后续高价值数据上链的更新,提高了高价值数据上链的效果。
附图说明
15.下面结合附图对本发明作进一步的说明。
16.图1为本发明基于区块链预言机的高价值数据上链系统的模块框图。
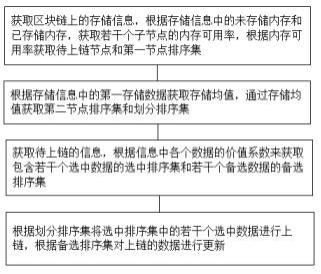
17.图2为本发明基于区块链预言机的高价值数据上链方法的流程框图。
具体实施方式
18.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
19.实施例一请参阅图1,本发明为基于区块链预言机的高价值数据上链系统,包括节点统计模块、筛选排序模块、内存分配模块、上链分析模块和上链更新模块;本实施例中,根据区块链上若干个子节点的未存储内存和已存储内存,获取若干个子节点的内存可用率并对若干个子节点进行筛分,得到待上链节点,使得已存储内存使用较多的子节点不进行高价值数据的上链;根据未存储内存的存储均值来对若干个待上链节点进行分类,使得不同大小的未存储内存来存储不同占存的高价值数据;根据内存划分比例对未存储内存进行划分,使得未存储内存内可以实现对高价值数据以及其它数据分别进行存储,并且互不影响;将待上链的信息中不同数据根据价值系数分成选中数据和备选数据,对若干个选中数据进行动态上链,根据备选数据对上链的数据进行更新,提高了高价值数据上链的效果。
20.节点统计模块用于获取区块链上的存储信息,该存储信息包含第一存储数据和第二存储数据,第一存储数据包含若干个子节点的未存储内存;第二存储数据包含若干个子节点的已存储内存,将存储信息发送至中心节点;筛选排序模块用于根据未存储内存和已存储内存,获取若干个子节点的内存可用率,分别对若干个子节点中的未存储内存和已存储内存进行取值和标记,将未存储内存标记为wcni,i=1,2,3...n;将已存储内存标记为ycni,通过公式计算获取若干个子节点的内存可用率;将内存可用率与预设的标准可用率进行对比匹配,用于对各个子节点进行筛选,将不小于预设的标准可用率的内存可用率对应的子节点标记为待上链节点;将若干个待上链节点根据内存可用率进行降序排列,得到第一节点排序集;例如,有子节点a、b、c、d,a的存储总内存为1000g,未使用内存为400g,已使用内存为600g;b的存储总内存为2000g,未使用内存为1300g,已使用内存为700g;c的存储总内存为3000g,未使用内存为2000g,已使用内存为1000g;d的存储总内存为4000g,未使用内存为3300g,已使用内存为700g;则a、b、c、d对应的内存可用率分别为2/3、13/7、2、33/7,当预设的标准可用率为1时,则大于等于1的内存可用率对应的子节点b、c、d为待上链节点,将子节点a不进行高价值数据的上链操作,因为子节点a的已使用内存使用较多,影响数据的处理速度,通过对各个子节点进行筛选,可以有效提高高价值数据上链的整体效果。
21.内存分配模块用于根据存储信息中的第一存储数据获取未存储内存的存储均值,这里指的是待上链节点的未存储内存的存储均值,根据若干个待上链节点的未存储内存,
计算未存储内存与存储均值之间的差值,得到内存调配值,对内存调配值进行分析,得到第二节点排序集,具体的步骤包括:将大于k的内存调配值对应的待上链节点设定为第一上链节点,将若干个第一上链节点降序排列,得到第一上链集;将不大于k的内存调配值对应的待上链节点设定为第二上链节点,将若干个第二上链节点降序排列,得到第二上链集;第一上链集和第二上链集构成第二节点排序集;k为正整数;例如,待上链节点b、c、d对应的存储均值为2200g,待上链节点b的内存调配值为
‑
900g;待上链节点c的内存调配值为
‑
200g;待上链节点d的内存调配值为900g;k可以根据待上链节点的存储均值进行取值,k可以取值为100,则待上链节点d为第一上链节点,待上链节点b和c为第二上链节点;通过对筛分后的待上链节点根据未存储内存与存储均值进行分组排列,便于后续对不同占存的高价值数据进行更合理的动态分配,未存储内存较多的待上链节点来上链存储占存大的高价值数据,未存储内存较少的待上链节点来上链存储占存小的高价值数据,对未存储内存中等的待上链节点,后续进一步来动态分配,提高了高价值数据分配的效果,避免高价值数据分配不合理进而影响整个子节点的运行效果。
22.对第二节点排序集进行上链内存划分,得到划分排序集;具体的步骤包括:获取第二节点排序集中的第一上链集和第二上链集;根据预设的内存划分比例分别对第一上链集和第二上链集中的未存储内存进行划分,得到第一划分内存和第二划分内存,将第一划分内存设定为上链内存,将第二划分内存设定为动态内存;其中,上链内存用于存储高价值数据;动态内存用于存储其它数据;对第一上链集中的若干个上链内存和动态内存分类组合,得到第一上链划分集;对第二上链集中的若干个上链内存和动态内存分类组合,得到第二上链划分集;第一上链划分集和第二上链划分集构成划分排序集。
23.例如,第一上链集中待上链节点d的未使用内存为3300g,第二上链集中待上链节点b和c的未使用内存为1300g和2000g,预设的内存划分比例可以为0.2,则上链节点d的未使用内存被划分为660g和2640g,660g为第一划分内存用于存储高价值数据,2640g为第二划分内存用于存储其它数据;同理,上链节点b的未使用内存被划分为260g和1040g,260g为上链节点b的第一划分内存,1040g为上链节点b的第二划分内存;上链节点c的未使用内存被划分为400g和1600g,40g为上链节点c的第一划分内存,1600g为上链节点c的第二划分内存;通过对筛分后的待上链节点中的未使用内存进行一步筛分,可以使得高价值数据获取专属的存储空间,不会使得高价值数据的上链影响待上链节点的运行,比如,高价值数据上链时占存大于上链节点的可分配内存,既影响高价值数据的上链,又会影响到待上链节点的正常运行,本实施例中预先划分出单独的内存供高价值数据上链用,可以提高高价值数据上链的效率。
24.上链分析模块用于获取待上链的信息,获取信息中不同数据的价值系数,获取信息中不同的数据,在单位时间内获取数据的请求次数和请求频率,单位时间可以为10min,将请求次数标记qqci;将请求频率标记为qqpi;通过公式计算获取数据的价值系数;其中,a1和a2表示为不同的比例系数且均大于零;请求频率为该数据的请求次数与所有数据请求的总次数的比值;将价值系数与预设的价值范围进行匹配,将预设的价值范围的最大值标记为j1;
将价值范围的最小值标记为j2;将价值系数sjx
i
与价值范围进行对比:若sjx
i
>j2,则判定该价值系数对应的数据价值高,并将其设定为选中数据;若j2≥sjx
i
>j1,则判定该价值系数对应的数据价值中等,并将其设定为备选数据;若j1≥sjx
i
,则判定该价值系数对应的数据价值低,可以将其设定为基础数据;其中,基础数据根据价值系数的变化可以变成备选数据;备选数据根据价值系数的变化可以变成选中数据并上链,便于后续高价值数据上链的更新。
25.获取选中数据的占存并标记为第一占存,获取备选数据的占存并标记为第二占存;将若干个选中数据根据第一占存进行降序排列,得到选中排序集;将若干个备选数据根据第二占存进行降序排列,得到备选排序集。
26.本实施例中,根据价值系数对待上链的数据进行分析归类,使得待上链的数据归类成可立即上链的高价值数据和待上链的中价值数据,其中,待上链的中价值数据可根据价值系数及时进行上链,提高了高价值数据上链的效率。
27.上链更新模块用于根据划分排序集将选中排序集中的若干个选中数据进行上链,具体的步骤包括:获取选中排序集中若干个选中数据的第一占存,将第一占存分别与第一上链划分集和第二上链划分集中的若干个上链内存进行匹配。
28.将排首位的选中数据分配至第一上链划分集中排首位的上链内存进行存储。
29.将排第二位的选中数据分配至第二上链划分集中排首位的上链内存进行匹配,若该选中数据的第一内存不大于该上链内存,则上链成功;若该选中数据的第一内存大于该上链内存,则上链失败,并将该选中数据分配至第一上链划分集中排第二位的上链内存进行存储。
30.依次类推,直至排序集中的选中数据分配至第二上链划分集中的上链内存进行存储,实现对选中排序集中若干个选中数据的动态上链。
31.其中,当选中数据分配至第二上链划分集中上链成功后,下一个选中数据分配至第二上链划分集中进行上链,下下一个选中数据再分配至第一上链划分集中进行上链,实现高价值数据在第二上链划分集和第一上链划分集上进行交叉上链。
32.本实施例中,根据选中数据的占存以及第一上链划分集和第二上链划分集中的若干个上链内存进行动态分配,使得第一上链划分集和第二上链划分集中的若干个上链内存均可以进行高价值数据的上链,使得高价值数据的上链分配的更均匀,避免某一子节点出现问题时影响高价值数据的使用,提高了高价值数据的安全性。
33.根据备选排序集对上链的数据进行更新,具体的步骤包括:将选中排序集中排末尾的选中数据设定为第一更新数据,将备选排序集中排首尾的备选数据设定为第二更新数据;当第一更新数据对应的价值系数小于第二更新数据对应的价值系数时,将第一更新数据下链,并将第二更新数据根据对应的第二占存进行上链,实现高价值数据的上链更新。
34.实施例二请参阅图2,基于区块链预言机的高价值数据上链方法,包括:获取区块链上的存储信息,该存储信息包含第一存储数据和第二存储数据,第一
存储数据包含若干个子节点的未存储内存;第二存储数据包含若干个子节点的已存储内存,将存储信息发送至中心节点。
35.根据未存储内存和已存储内存,获取若干个子节点的内存可用率,将不小于预设的标准可用率的内存可用率对应的子节点标记为待上链节点;将若干个待上链节点根据内存可用率进行降序排列,得到第一节点排序集。
36.根据存储信息中的第一存储数据获取未存储内存的存储均值,根据若干个待上链节点的未存储内存,计算未存储内存与存储均值之间的差值,得到内存调配值,对内存调配值进行分析,得到第二节点排序集,对第二节点排序集进行上链内存划分,得到划分排序集。
37.获取待上链的信息,获取信息中不同数据的价值系数,将价值系数与预设的价值范围进行匹配,得到选中数据和备选数据,获取选中数据的占存并标记为第一占存,获取备选数据的占存并标记为第二占存;将若干个选中数据根据第一占存进行降序排列,得到选中排序集;将若干个备选数据根据第二占存进行降序排列,得到备选排序集。
38.根据划分排序集将选中排序集中的若干个选中数据进行上链,根据备选排序集对上链的数据进行更新。
39.以上对本发明的一个实施例进行了详细说明,但所述内容仅为本发明的较佳实施例,不能被认为用于限定本发明的实施范围。凡依本发明申请范围所作的均等变化与改进等,均应仍归属于本发明的专利涵盖范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1