一种基于片上网络的多核系统和处理方法与流程
1.本技术涉及半导体技术领域,尤其涉及一种基于片上网络的多核系统和处理方法。
背景技术:
2.随着半导体工艺的快速发展,多核芯片以其超强运算能力逐渐走向主流。尤其是在并行计算方面,包含多个运算核心的异构多核芯片已经广泛应用于高性能计算领域。
3.然而,随着核的数量增长,芯片上集成的noc(network on chip,片上网络)总线的位宽以及路由器的规模呈现非线性上升,从而提高了noc总线工作时的功耗,导致多核芯片的功耗过高。功耗问题逐渐成为了影响多核芯片发展的问题。
技术实现要素:
4.本技术实施例期望提供一种基于片上网络的多核系统和处理方法。
5.本技术的技术方案是这样实现的:
6.本技术实施例第一方面提供一种基于片上网络的多核系统,所述多核系统包括:路由单元和多个运算单元;其中,
7.所述路由单元包括第一路由器和第二路由器;所述第一路由器和所述第二路由器的接口数量不同;
8.每个所述运算单元包括至少两个相邻设置的处理子单元,每个处理子单元包括堆叠设置的处理器和存储器;
9.针对每个所述运算单元,所述处理子单元之间通过所述路由单元连接。
10.可选地,所述运算单元包括第一运算单元和第二运算单元,所述第一运算单元和所述第二运算单元的处理子单元数量不同。
11.可选地,所述第一路由器的接口数量大于所述第二路由器的接口数量,所述第一路由器位于第一区域,所述第二路由器位于第二区域;其中,所述第二区域为所述第一区域的外围区域。
12.可选地,所述路由单元还包括第三路由器,所述第三路由器与所述第一路由器、所述第二路由器的接口数量不同。
13.可选地,所述存储器配置为存储运算数据;
14.所述处理器配置为从同一所述处理子单元的所述存储器中获取运算数据,并基于运算数据,与所述运算单元内的其他处理器执行预设运算操作。
15.可选地,所述处理器还配置为从所属的处理子单元之外的目标处理子单元的所述存储器中获取运算数据;所述目标处理子单元与所述处理器之间的路由单元的数量不超过其他处理子单元与所述处理器之间的路由单元的数量。
16.可选地,所述处理器还配置为从所属的运算单元的其他处理子单元的所述存储器中获取运算数据。
17.可选地,所述存储器包括dram存储器或mram存储器。
18.本技术实施例第二方面提供一种处理方法,应用于第一方面所述的一种基于片上网络的多核系统,包括:
19.所述处理器从同一所述处理子单元的所述存储器中获取运算数据;
20.基于所述运算数据,与所述运算单元内的其他处理器共同执行预设运算操作。
21.可选地,当所述处理器从同一所述处理子单元的所述存储器中获取运算数据失败时,所述处理器从所属的处理子单元之外的目标处理子单元的所述存储器中获取运算数据;所述目标处理子单元与所述处理器之间的路由单元的数量不超过其他处理子单元与所述处理器之间的路由单元的数量。
22.本技术公开了一种基于片上网络的多核系统和处理方法,其中,所述基于片上网络的多核系统包括:路由单元和多个运算单元;其中,所述路由单元包括第一路由器和第二路由器;所述第一路由器和所述第二路由器的接口数量不同;每个所述运算单元包括至少两个相邻设置的处理子单元,每个处理子单元包括堆叠设置的处理器和存储器;针对每个所述运算单元,所述处理子单元之间通过所述路由单元连接。本技术通过划分出多个运算单元,每个所述运算单元包括堆叠设置的处理器和存储器,从而处理器无需从片外存储器获取运算数据,使得运算单元能够独立完成运算操作,减少了距离较远的处理器之间的数据交互,从而缩小了路由器的位宽,降低了对路由器的接口数量需求,如此,在极大程度上减小了路由器的功耗,降低了系统的整体功耗。
附图说明
23.图1为本技术实施例提供的一种多核系统的结构示意图;
24.图2为本技术实施例提供的另一种多核系统的结构示意图;
25.图3为本技术实施例提供的基于片上网络的多核系统的结构示意图;
26.图4为本技术实施例提供的一种处理子单元的结构示意图;
27.图5为本技术实施例提供的一种处理子单元的具体结构示意图;
28.图6为本技术实施例提供的一种处理方法的流程示意图。
具体实施方式
29.下面将参照附图更详细地描述本技术公开的示例性实施方式。虽然附图中显示了本技术的示例性实施方式,然而应当理解,可以以各种形式实现本技术,而不应被这里阐述的具体实施方式所限制。相反,提供这些实施方式是为了能够更透彻地理解本技术,并且能够将本技术公开的范围完整的传达给本领域的技术人员。
30.在下文的描述中,给出了大量具体的细节以便提供对本技术更为彻底的理解。然而,对于本领域技术人员而言显而易见的是,本技术可以无需一个或多个这些细节而得以实施。在其他的例子中,为了避免与本技术发生混淆,对于本领域公知的一些技术特征未进行描述;即,这里不描述实际实施例的全部特征,不详细描述公知的功能和结构。
31.附图中所示的流程图仅是示例性说明,不是必须包括所有的步骤。例如,有的步骤还可以分解,而有的步骤可以合并或部分合并,因此实际执行的顺序有可能根据实际情况改变。
32.应当明白,空间关系术语例如“在......下”、“在......下面”、“下面的”、“在......之下”、“在......之上”、“上面的”等,在这里可为了方便描述而被使用从而描述图中所示的一个元件或特征与其它元件或特征的关系。应当明白,除了图中所示的取向以外,空间关系术语意图还包括使用和操作中的器件的不同取向。例如,如果附图中的器件翻转,然后,描述为“在其它元件下面”或“在其之下”或“在其下”元件或特征将取向为在其它元件或特征“上”。因此,示例性术语“在......下面”和“在......下”可包括上和下两个取向。器件可以另外地取向(旋转90度或其它取向)并且在此使用的空间描述语相应地被解释。
33.在此使用的术语的目的仅在于描述具体实施例并且不作为本技术的限制。在此使用时,单数形式的“一”、“一个”和“所述/该”也意图包括复数形式,除非上下文清楚指出另外的方式。还应明白术语“组成”和/或“包括”,当在该说明书中使用时,确定所述特征、整数、步骤、操作、元件和/或部件的存在,但不排除一个或更多其它的特征、整数、步骤、操作、元件、部件和/或组的存在或添加。在此使用时,术语“和/或”包括相关所列项目的任何及所有组合。
34.在多核芯片中,noc总线主要用于核,如ai(artificial intelligence,人工智能)核,gpu(graphics processing unit,图形处理器)核,cpu(central processing unit,中央处理器)核之间的数据交互,随着核的数量增长,noc总线的位宽以及路由器的规模都会随之增大,并由此造成数据传输过程中的总功耗的上升。这里,noc总线为包括路由器在内的数据传输路线。
35.对于一条数据传输路线,其功耗p的计算公式如下:
36.p=hops
·
pr+d
2d
·
ph37.其中,pr为路由器功耗,hops为数据传输经过的路由器数量,ph为noc总线间的链路功耗,d
2d
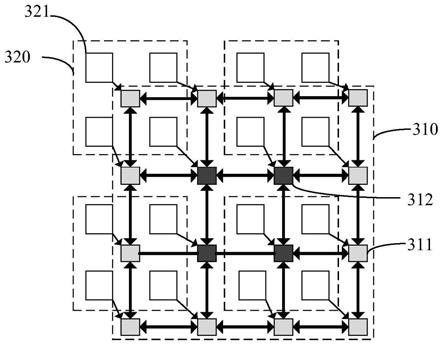
为数据传输的平均曼哈顿距离。路由器功耗pr与n
port
log2n
port
成正比,其中n
port
为路由器接口数。
38.基于上述计算公式可知,一条数据传输路线上的总功耗,不仅与路由器的接口数量有关,还与数据传输路线的长度,以及在数据传输过程中经过的路由器的数量有关。数据传输路线上的路由器的数量和路由器的接口数量越多,数据传输路线的功耗就越大。
39.在一个实施例中,如图1所示,图1为本技术实施例提供的一种多核系统的结构示意图。该多核架构包括多个处理器110,每个处理器110与对应的路由器120连接,相邻的路由器120互相连接。这里,处理器可以是嵌入式神经网络处理器(npu,network process units),npu是一种专门应用于网络应用数据包的处理器,采用“数据驱动并行计算”的架构,擅长处理视频、图像类的海量多媒体数据。当然,这里的处理器还可以是cpu处理器、gpu处理器等。
40.在该多核系统下,处理器具有两种数据传输路线,分别为第一数据传输路线和第二数据传输路线。在第一数据传输路线中,处理器110通过路由器120从片内的静态随机存取存储器(sram,static random-access memory)130中获取运算数据,执行预设运算操作。在第二数据传输路线中,处理器110通过路由器120、总线140、双倍速率物理层(ddr phy,double data rate physical layer)150从片外的动态随机存取存储器(dram,dynamic random access memory)160中获取运算数据,执行预设运算操作。相较于基于第一数据传
输路线从片内获取运算数据,第二数据传输路线需要经过更多的路由器120以及其他的器件,才能从片外获取到运算数据,因此,第二数据传输路线的功耗远大于第一数据传输路线的功耗。
41.在本实施例中,处理器110优先从片内的静态随机存取存储器130中获取运算数据,只有当获取运算数据失败时,处理器110才会从片外的动态随机存取存储器160中获取运算数据。换言之,该多核系统中优先采取第一数据传输路线,在第一数据传输路线执行失败时,才会采取第二数据传输路线。
42.对于本实施例中的多核系统的路线总功耗,一方面,由于单个的处理器110难以完成预设运算操作,往往需要多个处理器110配合才能完成预设运算操作,而处理器110之间通过一个或多个路由器120连接,路线上的路由器120数量越多,功耗也就越大,因此会增加额外的路由器120功耗,另一方面,处理器110要从静态随机存取存储器130获取运算数据,需要增加额外的路由器120接口用于与片内的静态随机存取存储器130建立连接,由此带来额外的功耗,甚至,当处理器110无法从片内的静态随机存取存储器130中获取运算数据时,需要从片外的动态随机存取存储器160中获取运算数据,而处理器110从片外的动态随机存取存储器160获取运算数据需要经过更多的路由器120,由此,造成了更大的功耗。
43.在另一个实施例中,如图2所示,图2为本技术实施例提供的另一种多核系统的结构示意图。该多核系统包括多个处理器210,每个处理器210中设有对应的静态随机存取存储器220,相邻的处理器210之间通过路由器230进行连接,相邻的路由器230互相连接。这里,处理器210可以是嵌入式神经网络处理器(npu),npu是一种专门应用于网络应用数据包的处理器,采用“数据驱动并行计算”的架构,擅长处理视频、图像类的海量多媒体数据。当然,这里的处理器还可以是cpu处理、gpu处理器等。图2提供的多核系统中将图1提供的多核系统中的静态随机存取存储器分布到各个处理器中,然而由于静态随机存取存储器的内存有限,大多情况下处理器仍需从片外的动态随机存取存储器中获取运算数据。
44.在该多核系统下,处理器210具有三种数据传输路线,分别为第一数据传输路线、第二数据传输路线和第三数据传输路线。在第一数据传输路线中,处理器210可以直接从对应的静态随机存取存储器220中获取运算数据,执行预设运算操作。在第二数据传输路线中,处理器210通过路由器230从临近的处理器210对应的静态随机存取存储器220中获取运算数据,执行预设运算操作。在第三数据传输路线中,处理器210通过路由器230、总线240、双倍速率物理层250从片外的动态随机存取存储器260中获取运算数据,执行预设运算操作。相较于基于第一数据传输路线和第二数据传输路线从片内获取运算数据,第三数据传输路线需要经过更多的路由器120以及其他的器件,才能从片外获取到运算数据,因此,第三数据传输路线的功耗远大于第一数据传输路线和第二数据传输路线的功耗。
45.需要说明的是,在本实施例中,处理器210同样是优先从对应的静态随机存取存储器220中获取运算数据,当获取运算数据失败时,处理器210开始从片内的其他处理器对应的静态随机存取存储器220中获取运算数据,而这需要通过复杂的判断机制才能实现,只有当再次获取运算数据失败时,处理器210才会从片外的动态随机存取存储器260中获取运算数据。换言之,该多核系统中优先采取第一数据传输路线,在第一数据传输路线执行失败时,才会采取第二数据传输路线,进一步,在第二数据传输路线执行失败时,才会采取第三数据传输路线。
46.在本实施例中,通常情况下,单个的处理器210难以完成预设运算操作,需要多个处理器210配合才能完成预设运算操作,而处理器210之间通过一个或多个路由器230连接,路线上的路由器230数量越多,功耗也就越大,因此会增加额外的路由器230功耗以及路由器230之间的链路功耗,甚至,当处理器210无法从对应的静态随机存取存储器220中获取运算数据时,需要通过复杂的判断机制从片内的其他处理器对应的静态随机存取存储器220中获取运算数据,甚至需要从片外的动态随机存取存储器260中获取运算数据,而处理器210从片外的动态随机存取存储器260获取运算数据需要经过更多的路由器230,并且对路由器的接口数量要求更多,由此,造成了更大的功耗。
47.在一个实施例中,图3为本技术实施例提供的基于片上网络的多核系统的结构示意图,图4为本技术实施例提供的处理子单元的结构示意图。结合图3和图4所示,所述基于片上网络多核架构的系统包括:路由单元310和多个运算单元320;其中,
48.所述路由单元310包括第一路由器311和第二路由器312;所述第一路由器311和所述第二路由器312的接口数量不同;
49.每个所述运算单元320包括至少两个处理子单元321,每个处理子单元321包括堆叠设置的处理器3211和存储器3212;
50.针对每个所述运算单元320,所述处理子单元321之间通过所述路由单元310连接。
51.需要说明的是,图3以每个所述运算单元320包括4个处理子单元321为例进行说明。
52.在本实施例中,存储器3212配置为存储运算数据。存储器3212可以是动态随机存取存储器,还可以是闪存(flash),相变存储器(phase change memory,pcm),或者磁性随机存储器(magnetic random access memory,mram)。以存储器3212为动态随机存取存储器为例,相较于静态随机存取存储器,同尺寸的动态随机存取存储器的内存更大,可以存储更多的运算数据。存储器3212用于存储处理器3211执行预设运算操作所需的运算数据。预设运算操作可以是多个基于预先设置的算法程序进行的运算操作。不同的存储器3212中存储的数据可以部分相同,也可以完全相同,这里不作限制。相较于图1和图2提供的多核系统,本实施例中将片外的动态随机存取存储器设置到各个处理器3211中,与处理器3211键合形成处理子单元321,由此,本实施例中的处理器无需从片外获取运算数据,在极大程度上减少了功耗。
53.处理器3211配置为从同一处理子单元321的存储器3212中获取运算数据,并基于运算数据,与运算单元320内的其他处理器3211一起执行预设运算操作。这里,处理器3211可以是嵌入式神经网络处理器(npu),npu是一种专门应用于网络应用数据包的处理器,采用“数据驱动并行计算”的架构,擅长处理视频、图像类的海量多媒体数据。当然,这里的处理器3211还可以是cpu处理、gpu处理器等。
54.在本实施例中,处理子单元321由处理器3211和存储器3212堆叠设置而成,这里,可以通过wafer on wafer或者die on wafer的技术将存储器3212与处理器3211进行键合。其中,在die on wafer的技术中,存储器3212的形成方式可以是将初始的存储晶圆切割成多个存储裸片,再将多个存储裸片与处理器3211对应的逻辑晶圆完成键合,然后进行晶圆切割以形成存储器。通过将处理器3211和存储器3212堆叠设置,避免了处理器在横向上的的横向扩张,有利于实现处理器的小型化。应理解,堆叠的处理器3211和存储器3212的相对
位置不受限制。
55.在一个示例中,请参阅图5,图5为本技术实施例提供的一种处理子单元的具体结构示意图,其中,最上层为存储裸片400(memory die),中间层为逻辑裸片401(logic die),虚线表征存储裸片400与逻辑裸片401的键合面,最下层为基板和处理器。存储裸片例如可以是dram存储裸片,或者mram存储裸片。具体地,从上至下依次为芯片基板410(chip substrate)、存储器件层420(memory device layer)、金属层430(metal layer)、混合键合层440(hybrid bonding layer)、金属层(图中未标记)、逻辑器件层450(logic device layer)、芯片基板(图中未标记)、倒装焊微凸点460(fipchip bumps)、基板470(substrate)、键合凸点480(bonding bumps)、处理器490,其中,在逻辑器件层和其芯片基板中还存在硅通孔(through silicon via,tsv),用以完成层间互连。通过键合和封装等工艺,可以实现存储器3212和处理器3211的键合封装,由此得到处理子单元321。
56.在本实施例中,每个处理器都具有键合设置的存储器。相邻的运算单元之间通过路由器进行连接,运算单元内部的各处理子单元也通过路由器进行连接。这里,处理器具有两种数据传输路线,分别为第一数据传输路线和第二数据传输路线。在第一数据传输路线中,处理器可以直接从键合的存储器中获取运算数据,执行预设运算操作。在第二数据传输路线中,处理器通过路由器从同一运算单元中距离较近的另一处理器对应的存储器中获取运算数据,执行预设运算操作,由此,避免了处理器从远距离的其他运算单元的处理子单元中的存储器中获取数据,减少了传输链路上的路由器的功耗。这里,处理器与存储器之间的距离与二者之间的路由器的数量相关,路由器的数量越多,表征二者之间的距离越大。由于不需要从远距离获取运算数据,也不需要从片外的存储器获取运算数据,因此极大地降低了对路由器的接口数量需求以及对路由器的数量要求,从而降低了路由器的功耗。
57.在本实施例中,所述第二路由器的接口数量为第一路由器的接口数量两倍。
58.在一个示例中,第一路由器311的接口数量可以为256个,第二路由器312的接口数量可以为128个。这里,第一路由器311位于第一区域,第二路由器312位于第二区域,第一区域可以是系统的中心区域,第二区域为第一区域的外围区域。本技术实施例中在中心区域设置接口数量较多的路由器,使其能够满足传输链路的需求,而在外围区域设置接口数量较少的路由器,是由于其所需的接口数量较少。相较之下,在前述的多核架构中,由于其需要从片外获取运算数据,其所需的接口数量往往要更多,通常为512个。本实施例通过减少路由器的接口数量,从而降低了数据传输过程中路由器的功耗。
59.本技术通过划分出多个运算单元,每个所述运算单元包括堆叠设置的处理器和存储器,从而使得运算单元能够独立完成运算操作,减少了距离较远的处理器之间的数据交互,从而缩小了路由器的位宽,降低了对路由器的接口数量需求,如此,在极大程度上减小了路由器的功耗,降低了系统的整体功耗。
60.在一个实施例中,运算单元包括第一运算单元和第二运算单元,第一运算单元和第二运算单元的处理子单元数量不同。
61.请在此参阅图3,在图3中,每个运算单元包括四个处理子单元,四个处理子单元相互协同可以执行至少一项预设运算操作。当然,每个运算单元包括的处理子单元的数量不局限四个,还可以是五个,六个等等,具体数量不作限制,另外,在同一个基于片上网络多核架构的系统中,不同的运算单元可以包括不同数量的处理子单元,如由四个处理子单元组
成的第一运算单元,由六个处理子单元组成的第二运算单元,还可以有第三运算单元、第四运算单元,各个运算单元均包括不同数量的处理子单元,由此,可以执行多项预设运算操作。
62.在一个示例中,根据预设运算操作对应的算法复杂程度,确定运算单元的组成。当预设运算操作对应的算法复杂程度较高时,可以将更多数量的处理子单元划归为一个运算单元;反之,当预设运算操作对应的算法复杂程度较低时,将数量较少的处理子单元划归为一个运算单元。一个运算单元包括的处理子单元的具体数量根据算法复杂程度决定,这里不做限定。
63.在本实施例中,路由单元还包括第三路由器(图中未示出),第三路由器与第一路由器、第二路由器的接口数量不同。
64.在本实施例中,所述第二路由器的接口数量为第三路由器的接口数量两倍。
65.在一个示例中,第一路由器311的接口数量可以为256个,第二路由器312的接口数量可以为128个,第三路由器的接口数量可以为64个。这里,第一路由器311位于第一区域,第二路由器312和第三路由器位于第二区域,第一区域可以是系统的中心区域,第二区域为第一区域的外围区域。
66.在本实施例中,路由单元可以包括多种不同接口数量的路由器,示例性地,位于系统中心区域的路由器的接口数量多于位于系统边缘区域的路由器的接口数量,位于同一个运算单元中心的路由器的接口数量多于位于运算单元边缘的路由器的接口数量。通过设置包括不同接口数量的的路由器,避免了统一采用多接口造成路由器接口的浪费,从而减小了路由器的功耗。
67.在一个实施例中,处理器还配置为从所属的处理子单元之外的目标处理子单元的存储器中获取运算数据;目标处理子单元与处理器之间的路由单元的数量不超过其他处理子单元与处理器之间的路由单元的数量。
68.在本实施例中,还包括有与每个处理器对应的数据寄存器。数据寄存器中存储有各处理器到各处理子单元的距离参数,这里,距离参数与传输链路上的路由器的数量相关,传输链路上的路由器的数量越多,距离参数越大。当处理器从自身所属的处理子单元中的存储器获取运算数据失败时,可以基于距离参数,从最近的其他处理子单元,即目标处理子单元中获取运算参数,由此,可以减少数据传输路线上的路由器的功耗。
69.在一个实施例中,处理器还配置为从所属的运算单元的其他处理子单元的存储器中获取运算数据。
70.相较于从运算单元外的其他处理子单元获取运算数据,直接从运算单元内的其他处理子单元的存储器中获取运算数据的数据传输路线更短。这里,可以通过算法设置数据传输路线的优先级进行操作,优先级与数据传输路线上的路由器数量相关,数据传输路线上的路由器数量越少,优先级越高,即处理器优先从所属的处理子单元的存储器中获取运算数据,当获取运算数据失败时,从处理器所属的运算单元中的距离参数最小的其他处理子单元的存储器中获取运算数据,通过缩短处理器从存储器获取数据的数据传输路线,从而减小了路由器的功耗。
71.本技术实施例还提供一种处理方法,应用于上述的一种基于片上网络多核架构的系统,如图6所示,包括:
72.s501,处理器从同一处理子单元的存储器中获取运算数据;
73.s502,基于运算数据,与运算单元内的其他处理器共同执行预设运算操作。
74.在本实施例中,处理器可以直接从同一处理子单元的存储器中获取运算数据,执行预设运算操作,由于处理器和存储器是堆叠设置的,传输路径短,因此可以极大地较小数据传输的功耗。
75.在一个实施例中,当处理器从同一处理子单元的存储器中获取运算数据失败时,处理器从所属的处理子单元之外的目标处理子单元的存储器中获取运算数据;目标处理子单元与处理器之间的路由单元的数量不超过其他处理子单元与处理器之间的路由单元的数量。
76.在本实施例中,处理器优先同一处理子单元的存储器中获取运算数据,当获取运算数据失败时,则从同一运算单元内的其他处理子单元中的存储器中获取运算数据,由此,避免了处理器从运算单元以外的远距离处理子单元中的存储器中获取数据,减少了传输链路上的路由器的功耗。这里,处理器与存储器之间的距离与二者之间的路由器的数量相关,路由器的数量越多,表征二者之间的距离越大。
77.本技术实施例通过划分出多个运算单元,每个所述运算单元包括堆叠设置的处理器和存储器,从而处理器无需从片外存储器获取运算数据,使得运算单元能够独立完成运算操作,减少了距离较远的处理器之间的数据交互,从而缩小了路由器的位宽,降低了对路由器的接口数量需求,如此,在极大程度上减小了路由器的功耗,降低了系统的整体功耗。
78.本技术所提供的几个方法实施例中所揭露的方法,在不冲突的情况下可以任意组合,得到新的方法实施例。
79.本技术所提供的几个产品实施例中所揭露的特征,在不冲突的情况下可以任意组合,得到新的产品实施例。
80.本技术所提供的几个方法或设备实施例中所揭露的特征,在不冲突的情况下可以任意组合,得到新的方法实施例或设备实施例。
81.在本技术所提供的几个实施例中,应该理解到,所揭露的方法和装置,可以通过其它的方式实现。以上所描述的装置实施例仅仅是示意性的,例如,所述模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,如:多个模块或组件可以结合,或可以集成到另一个系统,或一些特征可以忽略,或不执行。另外,所显示或讨论的各组成部分相互之间的耦合、或直接耦合、或通信连接可以是通过一些接口,装置或模块的间接耦合或通信连接,可以是电性的、机械的或其它形式的。
82.上述作为分离部件说明的模块可以是、或也可以不是物理上分开的,作为模块显示的部件可以是、或也可以不是物理单元,即可以位于一个地方,也可以分布到多个网络模块上;可以根据实际的需要选择其中的部分或全部模块来实现本实施例方案的目的。
83.另外,在本技术各实施例中的各功能模块可以全部集成在一个处理模块中,也可以是各模块分别单独作为一个模块,也可以两个或两个以上模块集成在一个模块中;上述集成的模块既可以采用硬件的形式实现,也可以采用硬件加软件功能模块的形式实现。
84.以上所述,仅为本技术的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应以所述权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1