一种SRv6网络下基于强化学习的流量调度方法
一种srv6网络下基于强化学习的流量调度方法
技术领域
1.本发明属于计算机技术领域,更具体地,涉及一种srv6网络下基于强化学习的流量调度方法。
背景技术:
2.流量工程旨在解决流量爆炸式增长问题,是一种通过调整流量路由链路,对网络资源进行优化调度,从而实现全局或局部网络链路上的负载均衡,以避免网络拥塞,提高网络利用率的技术,其核心是网络流量的调度方法。
3.在传统的流量调度方案中,常采用ecmp(equal cost multi-path,等价多路径路由)算法进行负载均衡,该类算法仅通过简单的数学模型将流量按比例分配到多条链路中,缺乏对网络状况的感知机制。进一步而言,通过sdn(software defined network,软件定义网络)等技术刻画网络拓扑,将流量调度映射为线性规划问题,能够在多项式时间内求出实际网络下的最优解。但受限于ip(internet protocol,网际互连协议)网络路由逐跳查表的转发机制,流量调度的重路由具有过大的网络开销同时有导致环路的风险。
4.srv6网络是一种新兴的网络技术,仅通过部署部分srv6节点,在源端加入转发标签,就能够做到端到端的显式路径转发,流的状态仅存储在sr(segment routing,分段路由)域的入口,从而避免过大的重路由开销以及环路风险。但由于网络升级的困难,导致目前srv6网络大都是部分部署在ipv6网络域中,这导致了显示路径转发的不完全,从而增加了流量调度的复杂性。
技术实现要素:
5.针对现有技术的局限性,本发明主要针对srv6网络环境下的流量调度,利用强化学习的强大表达能力构造了一套基于强化学习的流量调度方法,主要实现了在具体网络情况下,针对不同业务的链路自适应计算优先级以及权重,其目的在于提升网络的利用率以及用户的满意度。
6.本发明提供一种srv6网络下基于强化学习的流量调度方法,包括如下步骤:
7.(1)通过sdn控制器获取链路状态信息、网络拓扑以及流量特征:所述sdn控制器所收集链路状态信息包括转发链路带宽以及时延,所述流量特征包括端到端的业务流量类型以及业务流量矩阵;
8.(2)预训练算路组件以进行流量调度:所述算路组件包含网络特征计算模块、强化学习网络模块以及真实环境仿真模块,网络特征计算模块通过历史业务流量矩阵计算端到端的特征业务流量矩阵;强化学习网络模块基于actor-critic结构在连续动作空间内进行训练;真实环境仿真模块通过所收集网络拓扑信息以及链路状态信息构建真实网络仿真环境,模拟在特征业务流量矩阵下的srv6报文转发过程,为强化学习网络提供反馈;
9.(3)通过算路组件调节链路权重参数以及优先级,并通过srv6网络转发数据包:所述算路组件输出动作构成链路权重集合以及链路优先级集合,所述权重集合通过聚合相同
头结点以及目的节点链路构成多个链路聚合组,在组内相似优先级链路构成等价路径ecmp,在ecmp组内进行链路权重归一化;所述srv6网络对业务流量通过优先级参数选择优先级最高的有效ecmp组,并通过链路权重参数分割流量,以实现非平衡链路负载均衡;
10.(4)通过实时数据进一步迭代强化学习网络:所述强化学习网路在真实环境中通过真实网络信息进一步进行训练迭代。
11.总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有如下有益的效果:无需获得完整网络拓扑,能够在部分部署的srv6网路下实现链路的负载均衡,增大网络链路的利用率。
附图说明
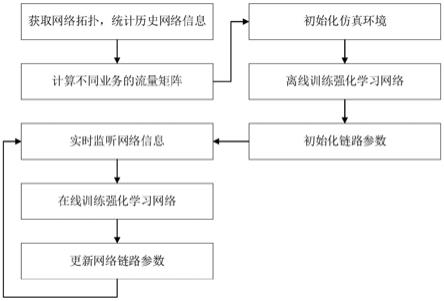
12.图1是本发明实施例中一种srv6网络下基于强化学习的流量调度方法的主要流程图;
13.图2是本发明实施例中一种srv6网络下基于强化学习的流量调度方法的sdn控制器的结构图;
14.图3是本发明实施例中一种srv6网络下基于强化学习的流量调度方法用于算路组件训练的强化学习网络图;
15.图4是本发明实施例中一种srv6网络下基于强化学习的流量调度方法的链路优先级聚类算法示意图。
具体实施方式
16.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
17.由于ipv6庞大地址域的支持,使得端到端的直接连接成为可能,这使得端到端的流量行为带有极为强烈的用户行为特征,通过学习该特征能够更好地进行流量负载调度。为提高srv6网络下的链路利用率,如图1所示,本发明提供了一种srv6(segment routing ipv6)网络下基于强化学习的流量调度方法,基于srv6 policy模型实现了结合强化学习基于业务分类进行链路负载均衡的流量调度方法,包括:
18.(1)通过sdn控制器获取链路状态信息、网络拓扑以及流量特征。所述sdn控制器所收集链路状态信息包括转发链路带宽以及时延,所收集流量特征包括端到端的业务流量类型以及业务流量矩阵;
19.如图2所示,sdn控制器包括信息采集模块、链路状态数据库、网络信息数据库以及算路组件。信息采集模块通过bgp(border gateway protocol,边界网关协议)协议采集网络信息,包括网络拓扑信息以及流量矩阵;链路状态数据库存储网络拓扑信息,用于在强化学习网络训练中模拟真实网络环境反馈;网络信息数据库统计时延优先业务以及带宽优先业务的网络流量矩阵,作为强化学习状态输入。
20.业务流量类型为时延优先或带宽优先,业务流量矩阵包括时延优先业务流量矩阵以及带宽优先业务流量矩阵,业务流量矩阵中行数和列数代表头结点和目的节点,其数值
代表一定时间内端到端的业务流量;算路组件通过强化学习网络调度网络流量。
21.(2)预训练算路组件以进行流量调度。
22.所述算路组件包含网络特征计算模块、强化学习网络模块以及真实环境仿真模块,网络特征计算模块通过历史业务流量矩阵计算端到端的特征业务流量矩阵;强化学习网络包括两个同构网络,即带宽优先业务强化学习网络以及时延优先业务强化学习网络,强化学习网络基于actor-critic结构在连续动作空间内进行训练;真实环境仿真模块通过所收集网络拓扑信息以及链路状态信息构建真实网络仿真环境,模拟在特征业务流量矩阵下的srv6报文转发过程,为强化学习网络提供反馈;
23.具体地,网络特征计算模块通过对两种业务流量矩阵(时延优先业务流量矩阵以及带宽优先业务流量矩阵)求数学期望获得两种业务的特征流量矩阵,由于ipv6端到端的特性,特征流量矩阵能够代表端到端的历史行为特征。基于td3(twin delayed deep deterministic policy gradient algorithm)模型构造两个强化学习网络分别用于对时延优先业务和带宽优先业务进行流量调度,对两种特征流量矩阵分别进行强化学习训练。sdn控制器通过链路状态数据库构建虚拟仿真网络,每次迭代通过仿真环境计算奖励函数反馈,参与强化学习网络训练;
24.算路组件强化学习网络模块针对于两种不同业务,构建两个同构网络,即带宽优先业务强化学习网络以及时延优先业务强化学习网络,强化学习网络结构如图3所示,由一个表演者(actor)模块和两个评价者(critic)模块构成,三个模块具有相同的dnn(deep neural networks)。其强化学习网络结构中输入状态空间为s
t
={u1,u2,...,ue},其中e为链路数,ui为链路i的使用率,输出行为空间为a
t
={p1,p2,...,pe,w1,w2,...,we},其中pi为链路i的优先级,wi为链路i的权重,e为链路数。
25.在状态空间s={u1,u2,...,ue}(其中e为链路数,ui为链路i的使用率)下,actor模块输出具体行为μ(s;θ
μ
)={p1,p2,...,pe,w1,w2,...,we}(其中pi为链路i的优先级,wi为链路i的权重,e为链路数),critic模块输出在当前状态下进行行为μ(s;θ
μ
)的预期收益q(s,a;θq),具体而言,actor模块具有损失函数:
[0026][0027]
critic模块具有损失函数:
[0028][0029][0030]
其中d为回放经验库,ε为随机噪声,为状态下的奖励回馈。
[0031]
强化学习网络训练为保证样本独立同分布采用经验回放机制,同时为保证行为的探索能力,在表演者训练迭代以及行为输出时加入噪声,同时表演者网络更新频率慢于评价者网络更新速率,其中表演者网络采用确定性策略梯度下降进行参数更新;
[0032]
进一步地,所述带宽优先强化学习网络训练目标为最大链路利用率的最小化,其奖励函数为:
[0033][0034][0035]
时延优先业务强化学习网络训练目标为平均延迟和最大链路利用率的最小化,其奖励函数为:
[0036][0037][0038]
其中t为迭代总轮数,e为链路数,ui(k)为第k轮迭代中链路i的链路利用率,tk为第k轮迭代中网络环境仿真所得到的端到端最长时延,t
t
为第t轮迭代中网络环境仿真所得到的端到端最长时延,其中β为相对重要程度,其值取决于先验知识。
[0039]
(3)通过算路组件调节链路权重参数以及优先级,并通过srv6网络转发数据包。
[0040]
所述算路组件输出动作构成链路权重集合以及链路优先级集合,所述权重集合通过聚合相同头结点以及目的节点链路构成多个链路聚合组,在组内相似优先级链路构成等价路径ecmp,在ecmp组内进行链路权重归一化;所述srv6网络对业务流量通过优先级参数选择优先级最高的有效ecmp组,并通过链路权重参数分割流量,以实现非平衡链路负载均衡;
[0041]
在相同头结点以及目的节点的链路聚合组中依据链路优先级采用dbscan(density-based spatial clustering ofapplications with noise)算法基于密度进行聚类,最终形成k条等价路径,其中最小包含点数以及扫描半径基于先验知识。
[0042]
具体地,通过上述sdn算路组件求解出最优化的链路集合,依据srv6policy模型,将链路按照(headend,color,endpoint)-preference-weight的三层模型划分为多个链路组,其中由于sdn算路组件优先级输出为连续值,采用dbscan算法进行密度聚类,将相似优先级的链路组划分为等价链路,最终生成链路信息数据库。通过bgp或pcep等协议将srv6 policy下发到头结点,实现控制器全局调优。srv6网络转发数据通过srv6 policy引流,最终实现链路负载均衡;
[0043]
其中dbscan算法是一种针对密度的聚类算法,具体而言,如图4所示,通过对选中点周围ε范围内进行扫描,将范围内不少于n个点聚集为一类,并对新加入的所有点继续迭代运行扫描算法,若范围内点的个数不足n,则重新选择样本点。最终形成的链路数据结构满足srv6 policy模型要求,数据流首先通过头尾节点以及业务类型命中一条policy,然后选择优先级最高的可用链路组作为转发链路组,最终流量依据转发链路组中参数见负载均衡转发;
[0044]
(4)通过实时数据进一步迭代强化学习网络。
[0045]
所述强化学习网路在真实环境中通过真实网络信息进一步进行训练迭代;
[0046]
具体地,依据真实网络反馈,微调算路组件中的强化学习网络,按照一定次数迭代后,更新srv6 policy,并通过控制器下发至srv6转发节点。
[0047]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以
限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1