一种高容量通用图像信息隐藏方法
1.本发明涉及信息安全技术领域,特别是高容量通用图像信息隐藏方法。
背景技术:
2.图像信息隐一种将秘密信息隐藏在载体图像中从而获得含密图像,然后通过含密图像恢复秘密信息的技术,常用于隐蔽通信等用途。评价图像信息隐藏算法的基本标准是隐蔽性和嵌入容量,隐蔽性要求含密图像的失真尽可能小,且难以被隐写分析检测到,嵌入容量则代表了载体图像中可以隐藏的秘密信息量。因此,如何在保证隐蔽性的前提下进一步提高信息隐藏算法的嵌入容量是图像信息隐藏发展的一个重要方向。从最低有效位信息隐藏算法,发展到基于最小失真和综合网格编码框架的自适应信息隐藏算法,图像信息隐藏算法的隐蔽性不断提高,但嵌入容量往往都在0.5bpp(bits per pixel)以下,并无明显改变。直到基于深度学习的图像信息隐藏算法的出现,大大提高了嵌入容量,一张rgb三通道的彩色图像作为秘密信息嵌入载体图像时的嵌入容量可达24bpp[zhang c,benz p,karjauv a,sun g.udh:universal deep hiding for steganography,watermarking,and light field messaging.in advances in neural information processing systems(vol.33).2020.]。主流的基于深度学习的图像信息隐藏模型往往包含一对编码器和解码器用来嵌入和恢复秘密信息,嵌入时需要将载体图像和秘密信息一起输入编码器来生成含密图像,因此在嵌入过程中载体图像和秘密信息是耦合的,一次嵌入过程只能将秘密信息隐藏到一张载体图像中,每生成一张新的含密图像都需要重新进行一次嵌入过程,效率较低。此外,一张载体图像能隐藏的信息量也是根据训练过程中的设置决定的,训练完成后便无法更改,如训练时设置一张灰度图像作为秘密信息,则测试时也只能将一张灰度图像隐藏进载体图像。此外,由于基于深度学习的图像信息隐藏模型具有较高的嵌入容量,因此会不可避免地使含密图像的视觉效果有所下降,且基本不具备抵抗隐写分析检测的能力。
技术实现要素:
[0003]
本发明提供了一种高容量通用图像信息隐藏方法,用以解决现有技术中图像信息隐藏方案嵌入效率低,隐蔽性低的问题。
[0004]
为解决上述问题,本发明的技术方案如下:
[0005]
一种高容量通用图像信息隐藏方法,采用包含编码器,完成信息隐藏模型训练的判别器、和解码器组成的信息隐藏模型;在编码端,秘密信息输入所述编码器生成含密扰动,然后将含密扰动与载体图像相加得到含密图像;在解码端将含密图像解码提取秘密信息,其中:
[0006]
1)编码器中包含一个注意力模块和一个简化的u-net网络,注意力模块使用两个卷积块创建一个注意力概率图,并鼓励编码器根据图像的内容关注像素的不同通道维度,注意力模块输出注意力概率图pm后与秘密信息m相乘,得到注意力特征图ma,然后送进编码器剩下的网络结构中生成含密扰动,然后添加到载体图像上生成含密图像;所述注意力模
块可表示为:
[0007][0008]
其中,conv表示卷积层,a和b表示卷积层输出的特征图,d是秘密信息m的通道数,l代表b中元素位置,j和k表示b的通道维度;
[0009]
秘密信息的嵌入方法为:将秘密信息输入编码器,生成含密扰动me,然后与载体图像相加:
[0010]
si=ci+me,i≥1
[0011]
其中,ci表示第i张需嵌入秘密信息的载体图像,si表示第i张含密图像;
[0012]
2)所述判别器为一隐写分析模型,通过对抗学习,使得编码器学会根据秘密信息生成含密对抗扰动,并添加到载体图像上,使生成的含密图像同时成为攻击判别器的对抗样本,从而提高含密图像抵抗隐写分析检测的能力。
[0013]
进一步地,所述训练信息隐藏模型的具体方法为:将隐写分析模型设置为判别器,编码器努力生成能够欺骗判别器的含密对抗扰动,而判别器则努力去识别载体图像和含密图像的差异,通过对抗训练使编码器生成的含密图像具有更强的抵抗隐写分析的能力,从而使判别器的识别准确率接近0.5,即相当于随机猜测;经过迭代训练,并通过判别器的反馈更新编码器的参数,使编码器最终可以学会生成含密对抗扰动,所述对抗训练表示为:
[0014][0015]
其中,g表示编码器,d表示判别器,判别器的目标是区分对抗样本x+g(z)和原始样本x,原始样本x代表载体图像,z代表秘密信息,对抗样本x+g(z)代表含密图像,x是从载体图像的类别中进行采样的,此判别器在对抗训练中促使生成的含密图像更接近载体图像的类别;
[0016]
针对判别器的攻击过程可表示为:
[0017][0018]
其中,表示判别器的输出结果与目标之间的距离,t表示目标类别;采用目标攻击的方式,将载体图像类别标签设为0,含密图像的类别标签设为1,目标类别标签t=0。
[0019]
训练图像信息隐藏模型,采用的损失函数为:
[0020][0021]
该损失函数包括三部分,分别是编码器的损失判别器的损失以及解码器的损失其中,β用于控制不同损失的相对比例;表示载体图像和含密图像之间的均方误差损失,用来衡量含密图像的失真程度;表示针对判别器的目标攻击损失,用来促使编码器学习生成含密对抗扰动;表示提取的秘密信息与原始秘密信息之间的信息损失;三者的定义如下:
[0022][0023]
其中,n代表训练样本数量,c和s分别代表载体和含密图像,y和分别代表判别器的目标和预测标签,m和m'分别代表原始秘密信息和提取的秘密信息。
[0024]
本发明的有益效果为:本发明所构建的高容量通用图像信息隐藏模型,该模型利用注意力模块和对抗学习促使编码器生成一个通用的含密对抗扰动,可以同时对多张不同的载体图像实现嵌入并生成对应的含密图像,无需重新运行模型,嵌入效率得到较大提升。本发明在不同的信息隐藏场景下均可实现秘密信息的嵌入和恢复,且生成的含密图像有着较高的视觉质量,同时在恢复秘密信息和抵抗隐写分析上取得了较好的性能。
附图说明
[0025]
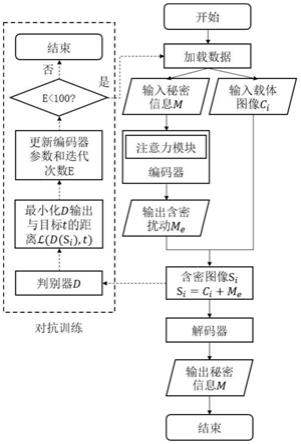
图1为本发明实施例中usgan的训练流程图。
[0026]
图2为本发明实施例中usgan的模型结构图。
[0027]
图3为本发明实施例中usgan编码器中的注意力机制示意图。
[0028]
图4为本发明实施例中不同嵌入模式下usgan秘密信息嵌入效果图。
[0029]
图5为本发明实施例中利用usgan进行三张灰度图嵌入单张彩色图时的示意图。
[0030]
图6(a)为本发明实施例中usgan生成的含密图像在xunet下的roc曲线。
[0031]
图6(b)为本发明实施例中usgan生成的含密图像在srnet下的roc曲线。
[0032]
图7为不同嵌入模式下载体图像和秘密信息的数据集。
具体实施方式
[0033]
本发明实施例将本发明的一种高容量通用图像信息隐藏方法应用在图像嵌入图像的信息隐藏场景。下面将结合本发明附图对本发明方法进一步的详述。
[0034]
结合图1和图2可看到,本发明一种高容量通用图像信息隐藏方法的主要内容和步骤,图1中虚线框为利用判别器实现信息隐藏模型训练的处理步骤。
[0035]
步骤1:构建包括编码器、解码器和判别器的信息隐藏模型。所述编码器包括一个注意力模块,以及一个简化的u-net网络。所述注意力模块使用两个卷积块创建一个注意力概率图,并鼓励编码器根据图像的内容关注像素的不同通道维度。所述注意力模块以秘密信息作为输入,输出注意力概率图pm并与秘密信息m相乘,得到注意力特征图ma,然后送进编码器剩下的网络结构中生成含密扰动。所述注意力模块可表示为:
[0036][0037]
其中,conv表示卷积层,a和b表示卷积层输出的特征图,d是秘密信息m的通道数,l代表b中元素位置,j和k表示b的通道维度。
[0038]
所述解码器包括六个卷积块的堆叠;每个卷积块包括一个卷积层,一个批归一化层和一个relu激活层;第一个卷积块的输入为含密图像,其它卷积块的输入为上一个卷积块的输出,最后一个卷积块的输出为提取的秘密信息;秘密信息的提取方法为:将含密图像输入解码器,解码器的输出为提取的秘密信息。
[0039]
所述判别器为基于卷积神经网络(cnn)的隐写分析模型。
[0040]
步骤2:训练所述信息隐藏模型。将隐写分析模型设置为判别器,与所述编码器进行对抗训练,通过对抗学习,使得编码器学会根据秘密信息生成含密对抗扰动,并添加到载体图像上,使生成的含密图像同时成为攻击判别器的对抗样本,从而提高含密图像抵抗隐写分析检测的能力。
[0041]
所述对抗训练的具体方法为:编码器努力生成能够欺骗判别器的含密对抗扰动,而判别器则努力去识别载体图像和含密图像的差异,通过对抗训练使编码器生成的含密图像具有更强的抵抗隐写分析的能力,从而使判别器的识别准确率接近0.5,即相当于随机猜测。经过迭代训练,并通过判别器的反馈更新编码器的参数,使编码器最终可以学会生成含密对抗扰动。所述对抗训练可表示为:
[0042][0043]
其中,g表示编码器,d表示判别器,判别器的目标是区分对抗样本x+g(z)和原始样本x。原始样本x代表载体图像,z代表秘密信息,对抗样本x+g(z)代表含密图像,x是从载体图像的类别中进行采样的,因此判别器在对抗训练中会促使生成的含密图像更接近载体图像的类别。
[0044]
对抗训练的目的是使编码器生成的含密扰动具有对抗扰动的特性,因此需要给编码器设置一个目标,使编码器向着目标进行参数的更新。具体来说,就是要编码器生成含密对抗扰动并添加到载体图像上得到含密图像,使得判别器将含密图像识别为载体图像。整个过程可表示为:
[0045][0046]
其中,表示判别器的输出结果与目标之间的距离,t表示目标类别。若要欺骗判别器,则判别器需要将含密图像的分类结果判定为错误的类别(无目标攻击),或者判定为非原始类别的目标类别(目标攻击),从而误导判别器的分类结果。本发明中,因为只有载体图像和含密图像两个类别,所以无目标攻击和目标攻击的含义是等价的。本发明采用目标攻击的方式,将载体图像类别标签设为0,含密图像的类别标签设为1,因此目标类别标签t=0。
[0047]
步骤3:基于训练后的信息隐藏模型,进行秘密信息的嵌入和提取。
[0048]
秘密信息的嵌入:将秘密信息输入编码器,生成含密扰动me,然后将含密扰动与载体图像相加得到含密图像:
[0049]
si=ci+me,i≥1
[0050]
其中,ci表示第i张需嵌入秘密信息的载体图像,si表示第i张含密图像。含密图像和载体图像的视觉效果保持一致。该模型通过生成一个通用的含密扰动添加到不同载体图像上,便可同时生成多张含密图像,无需重新运行模型。
[0051]
为了训练图像信息隐藏模型,采用的损失函数为:
[0052][0053]
该损失函数包括三部分,分别是编码器的损失判别器的损失以及解码器的损失其中,β用于控制不同损失的相对比例。表示载体图像和含密图像之间的均方误差损失,用来衡量含密图像的失真程度。表示针对判别器的目标攻击损失,用来促使编码器学习生成含密对抗扰动。表示提取的秘密信息与原始秘密信息之间的信息损失。三者的定义如下:
[0054][0055]
其中,n代表训练样本数量,c和s分别代表载体和含密图像,y和分别代表判别器的目标和预测标签,m和m'分别代表原始秘密信息和提取的秘密信息。
[0056]
下面,结合实施例,对本发明实施例中的技术方案进行清楚、完整地描述。
[0057]
首先,构建图像信息隐藏模型usgan。本实施例中,秘密信息嵌入和提取的流程图如图1所示,秘密信息可以通过usgan隐藏到载体图像中并从含密图像中恢复。如图2所示,usgan由编码器、判别器和解码器三部分组成,编码器以秘密信息m为输入生成含密对抗扰动me,然后与载体图像ci(i=1,2,
…
,n)相加生成含密图像si,含密图像同时也是攻击判别器的对抗样本。解码器以含密图像si为输入并恢复出秘密信息m'i。判别器以载体图像ci与对应的含密图像si为输入并输出分类概率,用来判断输入的图像是载体还是含密图像,并与编码器进行对抗训练,提高usgan隐藏秘密信息的隐蔽性。
[0058]
usgan的编码器采用的是改进后的u-net网络,解码器采用的是一系列卷积层的堆叠,判别器则是被攻击的隐写分析模型。编码器中的注意力模块使用两个卷积块创建一个注意力概率图,并鼓励编码器根据图像的内容关注像素的不同通道维度,提高含密图像的质量。具体来说,注意力模块以秘密信息作为输入,输出注意力概率图pm并与秘密信息相乘,得到注意力特征图ma,然后送进编码器剩下的网络结构中生成含密扰动me,过程如图3所示。
[0059]
如图3所示,注意力模块的输出是一个注意力概率图,其中每个像素上的概率向量可以解释为最终生成的含密对抗扰动在通道维度上的强度分布,用来控制秘密信息中不同注意力的像素位置生成的扰动变化。所述注意力模块可表示为:
[0060][0061]
其中,conv表示卷积层,a和b表示卷积层输出的特征图,d是秘密信息m的通道数,l代表b中元素位置,j和k表示b的通道维度。
[0062]
能否抵抗隐写分析的检测是图像信息隐藏隐蔽性的一个重要的评价标准。本发明实施例通过对抗学习,使得usgan的编码器学会根据秘密信息生成含密对抗扰动,并添加到载体图像上,使生成的含密图像同时成为攻击判别器的对抗样本,从而提高usgan抵抗隐写分析检测的能力。对抗攻击的判别器是判别器,因此可以通过和判别器进行对抗训练的方式使得编码器学习如何将含密扰动转换成对抗扰动,同时又不破坏扰动中隐藏的秘密信息。具体来说,本发明实施例将目标判别器设置为判别器,编码器努力生成能够欺骗判别器的含密对抗扰动,而判别器则努力去识别载体图像和含密图像的差异,通过对抗训练使usgan生成的含密图像具有更强的抵抗隐写分析的能力,从而使判别器的识别准确率接近0.5,即相当于随机猜测。经过迭代训练,并通过判别器的反馈更新编码器的参数,使编码器最终可以学会生成含密对抗扰动。所述对抗训练可表示为:
[0063][0064]
其中,g表示编码器,d表示判别器,判别器的目标是区分对抗样本x+g(z)和原始样本x。原始样本x代表载体图像,z代表秘密信息,对抗样本x+g(z)代表含密图像,x是从载体图像的类别中进行采样的,因此判别器在对抗训练中会促使生成的含密图像更接近载体图像的类别。
[0065]
对抗训练的目的是使编码器生成的含密扰动具有对抗扰动的特性,因此需要给编码器设置一个目标,使编码器向着目标进行参数的更新。具体来说,就是要编码器生成含密对抗扰动并添加到载体图像上得到含密图像,使得判别器将含密图像识别为载体图像。整个过程可表示为:
[0066][0067]
其中,表示判别器的输出结果与目标之间的距离,t表示目标类别。若要欺骗判别器,则判别器需要将含密图像的分类结果判定为错误的类别(无目标攻击),或者判定为非原始类别的目标类别(目标攻击),从而误导判别器的分类结果。本发明实施例中,因为只有载体图像和含密图像两个类别,所以无目标攻击和目标攻击的含义是等价的。本发明实施例采用目标攻击的方式,将载体图像类别标签设为0,含密图像的类别标签设为1,因此目标标签t=0。
[0068]
在构建好图像信息隐藏模型后,需要对模型进行训练,以得到训练好的信息隐藏
模型usgan。具体过程如下:
[0069]
本发明实施例使用bossbase和mscoco作为实验的数据集。bossbase包含10000张单通道的灰度图像,将其按8:2划分为训练集和测试集,训练集和测试集中又分别按1:1划分为载体图像和秘密信息,为了提高训练效率,所有的图像均归一化到128
×
128的尺寸。从mscoco中取出10000张三通道的rgb彩色图像,并进行与bossbase相同的数据集划分和图像预处理。
[0070]
本发明实施例使用adam(adaptivemomentestimation)优化器训练usgan模型,初始学习率为0.001,并随着训练轮次的增加逐渐衰减。
[0071]
进一步的,训练usgan的损失函数包括三部分,分别是编码器的损失判别器的损失以及解码器的损失表示载体图像和含密图像之间的均方误差损失,用来衡量含密图像的失真程度。表示针对判别器的目标攻击损失,用来促使编码器学习生成含密对抗扰动。表示提取的秘密信息与原始秘密信息之间的信息损失。三者的定义如下:
[0072][0073]
其中,n代表训练样本数量,c和s分别代表载体图像和含密图像,y和分别代表判别器的目标标签和预测标签,m和m'分别代表原始秘密信息和提取的秘密信息。总的损失函数定义如下:
[0074][0075]
其中,β用于控制编码器损失和解码器损失的相对比例。
[0076]
在模型训练完成后,便可进行秘密信息的嵌入和提取。
[0077]
为了验证本发明实施例模型在不同场景下的通用性,根据载体和秘密信息来源的不同,本发明实施例在四种嵌入模式下进行了实验,具体设置如图7所示。例如seta表示在训练和测试时载体图像为mscoco中的三通道彩色图像,秘密信息为bossbase中的单通道灰度图像。
[0078]
本发明实施例在四种嵌入模式下的信息隐藏效果如图4所示。
[0079]
本发明实施例测试了usgan将多张秘密信息嵌入到单张载体图像中时的信息隐藏效果,结果如图5所示。
[0080]
为了进一步评估隐写分析模型在检测usgan生成的含密图像上的性能,本发明实施例利用隐写分析的实验结果绘出四种嵌入模式下xunet和srnet检测usgan生成的含密图像时的受试者工作特征(receiver operating characteristic,简称roc)曲线并计算roc曲线下的面积(area under curve,简称auc),结果如图6所示。
[0081]
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术
人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1