一种基于深度学习和脏纸编码的MISO系统波束形成设计方法
一种基于深度学习和脏纸编码的miso系统波束形成设计方法
技术领域
1.本发明涉及多输入单输出(miso)下行传输优化领域,具体地说,涉及一种基于深度学习和脏纸编码的miso系统波束形成设计方法。
背景技术:
2.下行波束形成是多用户多输入多输出系统中有效提高频谱利用率的主要技术,可以实现多天线的性能增益。波束形成技术有多种形式,在给定的功率约束下,最大限度地提高下行总传输速率是该领域的一个重要研究方向。然而,直接优化下行总传输速率是一个复杂的非凸问题。采用加权最小均方误差(wmmse)迭代算法可以得到局部最优解,但是迭代过程引入的延迟也会使波束形成方案无法适应5g中高可靠性、低时延的场景。一些文章引入了基于信道状态信息直接计算波束形成向量的启发式波束形成算法,但这些技术性能不高,精度不高。延迟和性能之间的权衡似乎限制了波束形成技术及其实际应用的潜力。
技术实现要素:
3.本发明所要解决的技术问题是提供一种基于深度学习的在脏纸编码条件下实现miso下行总和速率最大化的波束形成设计方法,该方法采用脏纸编码和上下行链路对偶知识,有效降低了复杂度,在性能和复杂度上取得了良好的平衡。
4.本发明为解决上述技术问题采用以下技术方案:
5.一种基于深度学习的在脏纸编码条件下实现miso下行总和速率最大化的波束形成设计方法,其特征在于,所述多输入单输出(miso)下行传输场景中有一个配备m个天线的基站(bs)和k个单天线用户。假定信道状态信息是已知的,在使用脏纸编码时,假设预编码顺序为1...k。由于用户i对用户k(k>i)的干扰是已知的,用户k的干扰对用户i的下行解调信干噪比(sinr)没有影响,所以用户i的sinr为:
[0006][0007]
其中hi∈cm×1为用户i与基站之间的信道,ui表示用户i的波束形成向量,σ2为加性高斯白噪声的方差。
[0008]
具体的,该方法设计步骤如下:
[0009]
步骤一、利用上行功率分配注水迭代算法,获得深度神经网络模型所需要的训练样本集,对深度神经网络模型进行优化训练;
[0010]
步骤二、设计波束形成网络bfnet,bfnet包括两部分:深度神经网络模型和波束形成恢复模型;深度神经网络模型是一种全连接网络,用于预测关键特征向量;波束形成恢复模型利用专家知识进行波束成形向量的恢复;
[0011]
步骤三、将信道状态信息送入训练完成后的深度神经网络模型,预测关键向量(即上行功率分配q=[q1,...,qk]
t
);
[0012]
步骤四、将关键向量送入波束形成恢复模型中,利用上下行链路对偶知识计算下行功率分配,利用信道状态信息、关键向量与下行功率构造波束成形矩阵。
[0013]
本发明采用以上技术方案与现有技术相比,利用在脏纸编码条件下上下行链路对偶的独特性,将下行链路问题转化为上行链路问题,并且利用深度深度神经网络,将计算复杂度从在线优化转移到离线训练,利用训练好的深度神经网络寻找波束形成的最优解,大大降低了计算复杂度和时延。
附图说明
[0014]
图1为本发明的miso系统模型图。;
[0015]
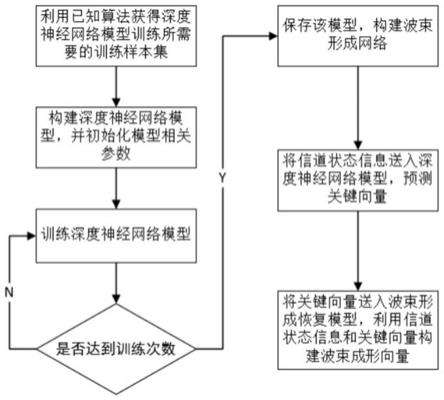
图2为本发明的方法流程示意图;
[0016]
图3为本发明的波束形成网络图;
[0017]
图4为本发明实施例提供的系统总和速率与总功率约束关系图。
具体实施方式
[0018]
为进一步了解本发明的内容,结合附图和具体实施例对本发明作详细描述。应当理解的是,实施例仅仅是对本发明进行解释而并非限定。
[0019]
本发明提供一种基于深度学习的在脏纸编码条件下实现miso下行总和速率最大化的波束形成设计方法,该方法采用脏纸编码和上下行链路对偶知识,有效降低了复杂度,在性能和复杂度上取得了良好的平衡。
[0020]
在一个实施例中,如图1所示,多输入单输出(miso)下行传输场景中有一个配备m个天线的基站(bs)和k个单天线用户。假定信道状态信息是已知的,在使用脏纸编码时,假设预编码顺序为1...k。由于用户i对用户k(k>i)的干扰是已知的,用户k的干扰对用户i的下行解调信干噪比(sinr)没有影响,所以用户i的sinr为:
[0021][0022]
其中hi∈cm×1为用户i与基站之间的信道,ui表示用户i的波束形成向量,σ2为加性高斯白噪声的方差。
[0023]
在一个实施例中,如图2所示,提供的一种基于深度学习的在脏纸编码条件下实现miso下行总和速率最大化的波束形成设计方法,该方法包括以下步骤:
[0024]
步骤一、利用上行功率分配注水迭代算法,获得深度神经网络模型所需要的训练样本集,对深度神经网络模型进行优化训练;
[0025]
步骤二、设计波束形成网络bfnet,bfnet包括两部分:深度神经网络模型和波束形成恢复模型;深度神经网络模型是一种全连接网络,用于预测关键特征向量;波束形成恢复模型利用专家知识进行波束成形向量的恢复;
[0026]
步骤三、将信道状态信息送入训练完成后的深度神经网络模型,预测关键向量;
[0027]
步骤四、将关键向量送入波束形成恢复模型中,利用上下行链路对偶知识计算下行功率分配,利用信道状态信息、关键向量与下行功率构造波束成形矩阵。
[0028]
在一个实施例中,如图3所示,bfnet包括两部分:深度神经网络模型和波束形成恢
复模型。其中深度神经网络模型利用信道状态信息生成关键向量,而波束形成恢复模型利用上下行链路对偶知识将关键向量转化成下行功率分配,然后利用信道状态信息、关键向量与下行功率分配构造波束成形矩阵。
[0029]
在一个实施例中,步骤二中采用上行功率分配注水迭代算法,该算法可以利用信道状态信息计算使上行总和速率最大的上行功率分配。
[0030]
在一个实施例中,步骤三中的关键向量为上行功率分配q=[q1,...,qk]
t
,qi为用户i的上行功率分配。
[0031]
在一个实施例中,步骤四中,根据上下行对偶知识,用户j在上行链路中达到的速率为:
[0032][0033]
其中用户j的上行解调信干噪比hj为用户j与基站之间的信道,uj表示用户j的波束形成向量,qj为用户j的上行功率分配,
[0034]
利用矩阵知识,得到简化公式为:
[0035][0036]
其中将作为上行链路的有效信道,翻转该信道得到:
[0037][0038]
现在考虑用户j在下行链路中的速率,使用相反的编码顺序,得到:
[0039][0040]
当选择时,其中u=[u1,u2,...,uk]为波束形成矩阵,pm为功率约束,为功率约束,分别是总功率约束下的下行总和速率和总功率约束下的上行总和速率。
[0041]
其中下行功率分配也可以按照该方法计算:其中为的svd分解。利用步骤三中获取的上行功率分配以及上述知识,计算下行功率分配。
[0042]
在一个实施例中,步骤四中构建的波束成形矩阵u=[u1,u2,...,uk],具体为
[0043][0044]
其中i为单位矩阵,qk为用户k的上行功率分配,hk为用户k与基站之间的信道,运算符||||2代表2范数运算。
[0045]
本实施例中利用上行功率分配注水迭代算法生成训练样本集。我们分别准备了20000个训练样本和5000个测试样本,每次训练读取100样本,共训练200次。深度神经网络模型包括三层全连接层,各层权重初始化为标准正太分布,偏置因子初始化为0,学习率大小为0.001。下行传输场景参数配置如表1所示:
[0046]
表1下行传输场景参数配置
[0047][0048]
图4中展示了bfnet、加权最小均方误差算法(wmmse)、迫零(zf)以及正则迫零(rzf)四种方案下的下行总和速率。由此可见,当功率小于25dbm时,所提出的深度学习的性能总是接近于wmmse算法,但在25dbm之后,所提出的深度学习的性能要优于wmmse算法。由图4可以发现,本发明提出的一种基于深度学习的在脏纸编码条件下实现miso下行总和速率最大化的波束形成设计方法可以同时兼顾性能与算法复杂度。
[0049]
以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1