基于视频的网格压缩的制作方法
基于视频的网格压缩
1.(一个或多个)相关申请的交叉引用
2.本技术援引35 u.s.c.
§
119(e)要求于2020年10月7日提交的标题为“video based mesh compression”的美国临时专利申请序列no.63/088,705和于2020年10月6日提交的标题为“video based mesh compression”的美国临时专利申请序列no.63/087,958的优先权,其通过引用整体并入本文以用于所有目的。
技术领域
3.本发明涉及三维图形。更具体而言,本发明涉及三维图形的编解码(coding)。
背景技术:
4.最近,一种基于从3d到2d的投影来压缩体积内容(诸如点云)的新颖方法正在被标准化。也称为v3c(基于可视体积视频的压缩)的该方法将3d体积数据映射到若干2d面片中,然后将这些面片进一步布置到图集(atlas)图像中,随后用视频编码器对图集图像进行编码。图集图像与点的几何结构、相应的纹理和指示要考虑哪些位置用于点云重构的占用图对应。
5.在2017年,mpeg已经发布了关于点云压缩的提案征集(cfp)。在评估了若干提案之后,目前mpeg正在考虑两种不同的点云压缩技术:3d原生编解码技术(基于八叉树和相似的编解码方法),或3d到2d投影,然后是传统的视频编解码。在动态3d场景的情况下,mpeg使用基于面片表面建模的测试模型软件(tmc2)、将面片从3d投影到2d图像,并用诸如hevc之类的视频编码器对2d图像进行编解码。事实证明,这种方法比原生3d编解码更高效,并且能够以可接受的质量实现具有竞争力的位速率。
6.由于基于投影的方法(也称为基于视频的方法或v-pcc)编解码3d点云的成功,该标准有望在未来的版本中包括更多的3d数据,诸如3d网格。但是,当前版本的标准只适合传输点的不连通集合,因此没有发送点的连通性的机构,因为它是3d网格压缩所要求的。
7.已经提出了将v-pcc的功能性扩展到网格的方法。一种可能的方式是使用v-pcc对顶点进行编码,然后使用网格压缩方法(如tfan或edgebreaker)对连通性进行编码。这种方法的局限性在于原始网格必须是密集的,因此从顶点生成的点云不是稀疏的,并且可以在投影之后被高效编码。而且,顶点的次序影响连通性的编解码,并且已经提出了不同的方法来重组网格连通性。对稀疏网格进行编码的另一种方式是使用raw面片数据对3d中的顶点位置进行编码。由于raw面片直接对(x,y,z)进行编码,因此在这种方法中,所有顶点都被编码为raw数据,而连通性则通过类似的网格压缩方法被编码,如前面所提到的。注意的是,在raw面片中,顶点可以按任何优选次序发送,因此可以使用从连通性编码生成的次序。该方法可以对稀疏点云进行编码,但是,raw面片对于对3d数据进行编码效率不高,并且这种方法会丢失更多数据,诸如三角形面的属性。
技术实现要素:
8.本文描述了一种使用网格表面数据的投影和连通性数据的视频表示来压缩3d网格数据的方法。该方法利用3d表面面片来表示网格表面上连接的三角形的集合。投影表面数据存储在图集数据中编码的面片(网格面片)中。网格的连通性(即,表面面片的顶点和三角形)使用基于视频的压缩技术进行编码。数据被封装在名为顶点视频数据的新视频组件中,并且所公开的结构允许通过在层中分离顶点的集合并为网格连通性创建细节级别来进行渐进式网格编码。这种方法扩展了目前用于点云和多视图以及深度内容的编码的v3c(基于体积视频)标准的功能性。
9.在一个方面,一种方法包括对输入网格执行网格体素化,实现将网格分割成包括光栅化的网格表面和顶点位置和连通性信息的面片的面片生成,从光栅化的网格表面生成基于可视体积视频的压缩(v3c)图像,用顶点位置和连通性信息实现基于视频的网格压缩,并基于v3c图像和基于视频的网格压缩生成v3c位流。顶点位置和连通性信息包括表面面片的三角形信息。来自用顶点位置和连通性信息实现基于视频的网格压缩的数据被封装在顶点视频组件结构中。顶点视频组件结构通过分离层中的顶点的集合并生成用于网格连通性的细节级别来实现渐进式网格编码。当仅实现一层时,视频数据被嵌入在占用图中。连通性信息是使用包括泊松表面重构或球枢转的表面重构算法生成的。从光栅化的网格表面生成v3c图像包括组合未跟踪的和跟踪的网格信息。该方法还包括在二维投影的面片域中实现边折叠过滤器。该方法还包括实现连通性信息的基于面片的表面细分。
10.在另一方面,一种装置包括用于存储应用的非暂态存储器和耦合到存储器的处理器,该应用用于:对输入网格执行网格体素化,实现将网格分割成包括光栅化的网格表面和顶点位置和连通性信息的面片的面片生成,从光栅化的网格表面生成基于可视体积视频的压缩(v3c)图像,用顶点位置和连通性信息实现基于视频的网格压缩,并基于v3c图像和基于视频的网格压缩生成v3c位流;该处理器被配置用于处理应用。顶点位置和连通性信息包括表面面片的三角形信息。来自用顶点位置和连通性信息实现基于视频的网格压缩的数据被封装在顶点视频组件结构中。顶点视频组件结构通过分离层中的顶点的集合并生成用于网格连通性的细节级别来实现渐进式网格编码。当仅实现一层时,视频数据被嵌入在占用图中。连通性信息是使用包括泊松表面重构或球枢转的表面重构算法生成的。从光栅化的网格表面生成v3c图像包括组合未跟踪的和跟踪的网格信息。该应用还被配置用于在二维投影的面片域中实现边折叠过滤器。该应用还被配置用于实现连通性信息的基于面片的表面细分。
11.在另一方面,一种系统包括用于获取三维内容的一个或多个相机、用于对三维内容进行编码的编码器:对输入网格执行网格体素化,实现将网格分割成包括光栅化的网格表面和顶点位置和连通性信息的面片的面片生成,从光栅化的网格表面生成基于可视体积视频的压缩(v3c)图像,用顶点位置和连通性信息实现基于视频的网格压缩,并基于v3c图像和基于视频的网格压缩生成v3c位流。顶点位置和连通性信息包括表面面片的三角形信息。来自用顶点位置和连通性信息实现基于视频的网格压缩的数据被封装在顶点视频组件结构中。顶点视频组件结构通过分离层中的顶点的集合并生成用于网格连通性的细节级别来实现渐进式网格编解码。当仅实现一层时,视频数据被嵌入在占用图中。连通性信息是使用包括泊松表面重构或球枢转的表面重构算法生成的。从光栅化的网格表面生成v3c图像
包括组合未跟踪的和跟踪的网格信息。编码器被配置用于在二维投影的面片域中实现边折叠过滤器。编码器被配置用于实现连通性信息的基于面片的表面细分。
附图说明
12.图1图示了根据一些实施例的实现v3c网格编解码的方法的流程图。
13.图2图示了根据一些实施例的网格体素化的图。
14.图3图示了根据一些实施例的面片生成的图。
15.图4图示了根据一些实施例的面片光栅化的图。
16.图5图示了根据一些实施例的v3c图像生成的图。
17.图6图示了根据一些实施例的顶点视频数据的图像。
18.图7图示了根据一些实施例的示例性细节级别生成的图像。
19.图8图示了根据一些实施例的网格的图。
20.图9图示了根据一些实施例的网格重构的图。
21.图10图示了根据一些实施例的允许发送点云和网格面片的混合的高级语法和图像的图。
22.图11a-b图示了根据一些实施例的组合的未跟踪的和跟踪的网格信息的图。
23.图12图示了根据一些实施例的基于面片的边折叠的示例性图像。
24.图13图示了根据一些实施例的基于面片的聚类抽取的示例性图像。
25.图14图示了根据一些实施例的基于面片的表面细分的示例性图像。
26.图15图示了根据一些实施例的基于面片的表面重构的示例性图像。
27.图16图示了根据一些实施例的三角形边检测的图。
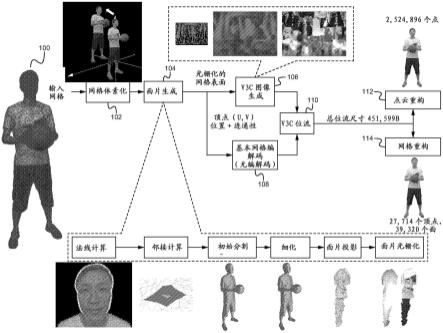
28.图17图示了根据一些实施例的基于颜色分离的三角形的分割的边的图。
29.图18图示了根据一些实施例的组合的三角形的分割的边的图。
30.图19-23图示了根据一些实施例的重新调整尺寸和重新缩放的边的图。
31.图24图示了根据一些实施例的被配置为实现基于视频的网格压缩方法的示例性计算设备的框图。
32.图25图示了根据一些实施例的被配置为实现基于视频的网格压缩的系统的图。
具体实施方式
33.本文描述了一种使用网格表面数据的投影和连通性数据的视频表示来压缩3d网格数据的方法。该方法利用3d表面面片来表示网格表面上的连接的三角形的集合。投影的表面数据存储在图集数据中编码的面片(网格面片)中。网格的连通性(即,表面面片的顶点和三角形)使用基于视频的压缩技术进行编码。数据被封装在名为顶点视频数据的新视频组件中,并且所公开的结构允许通过在层中分离顶点的集合并为网格连通性创建细节级别来进行渐进式网格编码。这种方法扩展了目前用于点云和多视图以及深度内容的编解码的v3c(基于体积视频)标准的功能性。
34.在使用视频编码器的3d点云编解码中,从3d到2d的投影对于生成将表示点云的视频是重要的。生成视频的最高效方法是使用3d面片,它分割物体的表面并使用正交投影生成分割的深度图像,这些图像被捆绑在一起并用作视频编码器的输入。此外,投影步骤未捕
获的点也可以直接编码在视频信号中。在当前的点云标准中,无法对3d网格进行编码,因为没有定义的方法对网格的连通性进行编码。此外,如果顶点数据稀疏,那么该标准的性能差,因为它不能利用顶点之间的相关性。
35.本文描述了一种使用v3c标准对体积数据进行编解码来执行网格的编解码的方法。描述了一种分割网格表面并提出联合表面采样和2d面片生成的方法。对于每个面片,本地连通性和投影到2d面片的顶点的位置被编码。描述了用信号发送连通性和顶点位置的方法,使得能够重构原始输入网格。此外,描述了一种将顶点和连通性映射到视频帧中并使用视频编解码工具将网格连通性数据编码到称为顶点视频数据的视频序列中的方法。
36.图1图示了根据一些实施例的实现v3c网格编解码的方法的流程图。在步骤100中,接收或获取输入网格。例如,输入网格被下载(例如,从网络设备)或由设备(例如,相机或自主车辆)获取/捕获。
37.在步骤102中,执行网格体素化。网格能够具有浮点的顶点位置,因此这些位置被转换到整数空间。v-pcc和v3c假设体素化的点云。
38.在步骤104中,实现面片生成(或创建)。面片生成包括:法线计算、邻接计算、初始分割;细化、面片投影和面片光栅化。法线计算是计算每个三角形的法线(例如,三角形的边的叉积)。邻接计算涉及计算每个三角形的邻接关系(例如,网格中的哪些三角形邻接或接触当前三角形或其它三角形)。初始分割包括根据朝向对法线进行分类。例如,三角形的法线能够指向上、下、左、右、前或后,并且能够基于方向/朝向进行分类。在一些实施例中,三角形基于它们的法线的朝向进行颜色编解码(例如,法线指向上的所有三角形都被涂成绿色)。细化涉及定位离群值(例如,被蓝色三角形包围的单个红色三角形)和平滑离群值(例如,改变单个红色三角形以匹配其蓝色的邻居)。通过分析邻居和平滑朝向(例如,调整法线的朝向)来执行细化。一旦存在光滑的表面,就执行面片投影,这涉及为特定的三角形分类(例如,基于朝向)投影面片。通过投影,顶点和连通性在面片上示出。例如,这个示例中的身体和面部是分离的投影,因为存在将两者分开的具有不同分类的三角形。v3c和v-pcc不理解该方面;更确切地说,v3c和v-pcc理解点,因此投影被光栅化(例如,表面上的采样点包括点的距离以生成几何图像和表面的属性)。光栅化的网格表面与v3c图像非常相似。
39.面片生成导致光栅化的网格表面和顶点位置和连通性。在步骤106中,光栅化的网格表面被用于v3c图像生成/创建。在步骤108中,顶点位置和连接性被用于网格编解码(例如,基于视频的网格压缩)。在步骤110中,v3c位流是从生成的v3c图像和基本网格编解码生成的。在一些实施例中,网格编解码不涉及任何附加编解码,并且顶点位置和连通性直接进入v3c位流。
40.v3c位流使得能够在步骤112中进行点云重构,和/或在步骤114中进行网格构造。能够从v3c位流中提取点云和/或网格,这提供了显著的灵活性。在一些实施例中,实现更少或附加的步骤。在一些实施例中,修改步骤的次序。
41.本文描述的方法与2021年1月28日提交的标题为“projection-based mesh compression”的美国专利申请序列no.17/161,300相关,该专利申请通过引用整体并入本文以用于所有目的。
42.为了解决体素化,网格缩放和偏移量信息在图集适配参数集(atlas adaptation parameter set,aaps)中被发送。能够使用可用的相机参数。可替代地,为体素化引入新的
语法元素(在仅使用缩放和偏移量的情况下)。以下是示例性语法:
[0043][0044]
aaps_voxelization_parameters_present_flag等于1指定体素化参数应存在于当前图集适配参数集中。
[0045]
aaps_voxelization_parameters_present_flag等于0指定用于当前适配参数集的体素化参数将不存在。
[0046]
vp_scale_enabled_flag等于1指示用于当前体素化的缩放参数存在。
[0047]
vp_scale_enabled_flag等于0指示用于当前体素化的缩放参数不存在。
[0048]
当vp_scale_enabled_flag不存在时,应推断为等于0。
[0049]
vp_offset_enabled_flag等于1指示用于当前体素化的偏移量参数存在。
[0050]
vp_offset_enabled_flag等于0指示用于当前体素化的偏移量参数不存在。当vp_offset_enabled_flag不存在时,应推断为等于0。
[0051]
vp_scale指定用于当前体素化的缩放的值scale为2-16
的增量。
[0052]
vp_scale的值应在1到2
32-1的范围内,包括端点。当vp_scale不存在时,应推断为等于2
16
。scale的值计算如下:
[0053]
scale=vp_scale
÷216
[0054]
vp_offset_on_axis[d]以2-16
的增量指示用于当前体素化的沿着d轴的偏移量的值offset[d]。vp_offset_on_axis[d]的值应在-2
31
到2
31-1的范围内,包括端点,其中d在0到2的范围内,包括端点。d的值等于0、1和2,分别与x、y和z轴对应。当vp_offset_on_axis[d]不存在时,应推断为等于0。
[0055]
offset[d]=vp_offset_on_axis[d]
÷216
[0056]
这个过程指定了反向体素化过程,以从体素化的解码的顶点值到浮点重构值。以下适用:
[0057]
for(n=0;n《vertexcnt;n++)
[0058]
for(k=0;k《3;k++)
[0059]
vertexreconstructed[n][k]=scale*(decodedvertex[n][k])+offset[k]
[0060]
图2图示了根据一些实施例的网格体素化的图。每个帧具有不同的界定框。获得每帧的界定框(例如,t=1、t=16和t=32时的帧200)。然后,从许多界定框计算序列界定框202,sequencebb=(minpoint,maxpoint)。序列界定框202包含所有顶点,与帧无关。计算适合由bitdepth定义的范围内的最大范围的缩放,maxrange=max(maxpoint16[0..2]-minpoint16[0..2]),scale=(2
bitdepth-1)/maxrange-》scale16。结果按最小值缩放和移位,voxelizedpoint=floor((originalpoint-minpoint16)/scale16)。缩放和移位量能够是用户定义的或基于学习算法由计算机生成的(例如,通过分析界定框并自动计算缩放和移位量)。这些值存储在aaps中,移位量=minpoint16并且缩放=scale16。
[0061]
输入参数(modelscale):
[0062]
(-1):自动计算每帧缩放
[0063]
(0):自动计算序列缩放
[0064]
(》1):用户定义的缩放。
[0065]
在一些实施例中,网格体素化涉及将输入网格的点的位置的浮点值转换成整数。整数的精度能够由用户设置或自动设置。在一些实施例中,网格体素化包括移位值,使得没有负数。
[0066]
例如,原始网格位于轴线下方,从而产生负数。经由网格体素化,网格被移位和/或缩放以避免负值和非整数值。在一种实施方式中,找到低于零的最低顶点值,然后能够移位这些值以使得最低顶点值高于零。在一些实施例中,值的范围适合指定的位范围(例如,通过缩放),诸如11位。
[0067]
体素化的网格210是缩放和移位之后的原始网格。例如,体素化的网格210是在它已经生长并且已经被移位以使得它只是正值(这在一些情况下对于编码来说是更好的)之后的原始网格。
[0068]
体素化会使三角形退化(占据相同位置的顶点),但编解码过程移除退化的顶点并由于网格分割而增加顶点的数量(例如,移除重复顶点过滤器能够被用于减少顶点的数量)。在示例中,原始网格有20,692个顶点;39,455个面;和体素化的顶点中的20,692个点,而重构的网格有27,942个顶点;39,240个面并且重构的点云有1,938,384个点。
[0069]
图3图示了根据一些实施例的面片生成的图。如上所述,面片生成涉及法线计算、邻接计算、初始分割(或法线分类)和分割细化(或类别细化)。计算每个三角形的法线涉及三角形边之间的叉积。邻接计算确定三角形是否共享顶点,如果是,那么三角形是邻居。通过分析法线的朝向、对法线的朝向(例如,上、下、左、右、向前、向后)进行分类,并确定法线的朝向是否与全都被分类为相同的邻近法线不同地分类(例如,第一面片被分类为向上,而大多数或所有邻近面片被分类为向前),然后改变面片的法线的分类以匹配邻居的朝向(例如,将第一面片分类改变为向前),初始分割和分割细化与v-pcc相同地执行。
[0070]
如上所述,实现了将网格分割成面片的面片生成。面片生成还生成1)光栅化的网格表面和2)顶点位置和连通性信息。光栅化的网格表面是经过v3c图像或v-pcc图像生成的点的集合并被编码为v3c图像或v-pcc图像。接收顶点位置和连通性信息以用于基本网格编
解码。
[0071]
本文描述的面片生成与v-pcc中的面片生成相似。但是,不是计算每个点的法线,而是计算每个三角形的法线。每个三角形的法线是使用边之间的叉积来计算的,以确定法线向量。然后,根据法线对三角形进行分类。例如,将法线划分为n个(例如,6个)类别,诸如前、后、上、下、左和右。法线以不同的颜色指示,以示出初始分割。图3示出了灰度中的不同颜色,诸如黑色和浅灰色,不同的颜色指示不同的法线。虽然可能难以看到,但顶表面(例如,人的头顶、球的顶部和运动鞋的顶部)是一种颜色(例如,绿色),人/球的第一侧很暗,表示另一种颜色(例如,红色),球的底部是另一种颜色(例如,紫色),而主要是浅灰色的人和球的正面表示另一种颜色(例如,青色)。
[0072]
通过将法线的乘积乘以方向,能够找到主方向。通过查看邻近的三角形,能够实现平滑/细化过程。例如,如果高于阈值的数量的邻近三角形都是蓝色的,那么这个三角形也被归类为蓝色,即使存在最初指示三角形是红色的异常。
[0073]
生成三角形的连接的分量以识别哪些三角形具有相同的颜色(例如,具有相同类别的三角形共享至少一个顶点)。
[0074]
连通性信息描述点如何在3d中连接。这些连接一起生成三角形(更具体而言,共享3个点的3个不同的连接),从而生成表面(由三角形的集合描述)。虽然本文描述了三角形,但也允许其它几何形状(例如,矩形)。
[0075]
通过识别具有不同颜色的三角形,能够使用颜色来对连通性进行编码。由三个连接识别的每个三角形都用唯一的颜色编解码。
[0076]
图4图示了根据一些实施例的面片光栅化的图,面片生成过程的组成部分之一。面片生成还包括生成三角形的连接的分量(具有相同类别的三角形共享至少一个顶点)。如果连接的分量的界定框小于预定义的区域,那么将三角形移动到单独的列表中以进行独立的三角形编解码。这些未投影的三角形不会被光栅化,而是被编解码为具有相关联颜色顶点的顶点。否则,每个三角形被投影到面片。如果顶点的投影的位置已经被占用,那么该三角形被编解码到另一个面片中,并进入丢失的三角形列表以稍后再次处理。可替代地,图能够被用于识别重叠的顶点,并且仍然能够表示具有重叠顶点的三角形。对三角形进行光栅化以生成用于点云表示的点。
[0077]
示出了原始体素化的顶点400。光栅化的表面点402(添加到点云表示)遵循网格的结构,因此点云几何形状能够与底层网格一样粗糙。但是,能够通过为每个光栅化的像素发送附加的位置来改进几何形状。
[0078]
图5图示了根据一些实施例的v3c图像生成的图。当投影网格时,生成占用图、几何图和纹理图。对于v3c图像生成,占用图和几何图以与以前相同的方式生成。属性图(纹理)是从未压缩的几何形状生成的。
[0079]
当生成面片时,添加信息以指示面片在2d图像上的位置。还指示哪些是顶点的位置以及它们是如何连接的。以下语法执行这些任务:
[0080]
[0081]
[0082]
[0083][0084]
mpdu_binary_object_present_flag[tileid][p]等于1指定语法元素mpdu_mesh_binary_object_size_bytes[tileid][p]和mpdu_mesh_binary_object[tileid][p][i]对于当前图集图块的当前面片p存在,图块id等于tileid。如果mpdu_binary_object_present_flag[tileid][p]等于0,那么语法元素mpdu_mesh_binary_object_size_bytes[tileid][p]和mpdu_mesh_binary_object[tileid][p][i]对于当前面片不存在。如果mpdu_binary_object_present_flag[tileid][p]不存在,那么应推断其值等于0。
[0085]
mpdu_mesh_binary_object_size_bytes[tileid][p]指定用于以二进制形式表示网格信息的字节数。
[0086]
mpdu_mesh_binary_object[tileid][p][i]指定用于第p个面片的网格的二进制表示的i字节。
[0087]
mpdu_vertex_count_minus3[tileid][p]加3指定面片中存在的顶点数。
[0088]
mpdu_face_count[tileid][p]指定面片中存在的三角形的数量。当不存在时,mpdu_face_count[tileid][p]的值应为零。
[0089]
mpdu_face_vertex[tileid][p][i][k]指定用于当前图集图块的当前面片p的第i个三角形或四边形的顶点索引的第k个值,图块id等于tileid。mpdu_face_vertex[tileid][p][i][k]的值应在0到mpdu_vert_count_minus3[tileid][p]+2的范围内。
[0090]
mpdu_vertex_pos_x[tileid][p][i]指定用于当前图集图块的当前面片p的第i个顶点的x坐标值,图块id等于tileid。
[0091]
mpdu_vertex_pos_x[p][i]的值应在0到mpdu_2d_size_x_minus1[p]的范围内,包括端点。
[0092]
mpdu_vertex_pos_y[tileid][p][i]指定用于当前图集图块的当前面片p的第i个顶点的y坐标值,图块id等于tileid。
[0093]
mpdu_vertex_pos_y[tileid][p][i]的值应在0到mpdu_2d_size_y_minus1
[tileid][p]的范围内,包括端点。
[0094]
网格面片数据的一些元素由图集序列参数集(asps)中定义的参数控制。能够使用用于网格的asps的新扩展。
[0095][0096][0097]
asps_mesh_extension_present_flag等于1指定asps_mesh_extension()语法结
构存在于atlas_sequence_parameter_set_rbsp语法结构中。
[0098]
asps_mesh_extension_present_flag等于0指定这个语法结构不存在。当不存在时,asps_mesh_extension_present_flag的值被推断为等于0。
[0099]
asps_extension_6bits等于0指定没有asps_extension_data_flag语法元素存在于asps rbsp语法结构中。当存在时,asps_extension_6bits在符合本文档的这个版本的位流中应等于0。不等于0的asps_extension_6bits的值被保留供iso/iec将来使用。解码器应允许asps_extension_6bits的值不等于0并且应忽略asps nal单元中的所有asps_extension_data_flag语法元素。当不存在时,asps_extension_6bits的值被推断为等于0。
[0100][0101]
asps_mesh_binary_coding_enabled_flag等于1指示与面片相关联的顶点和连通性信息以二进制格式存在。
[0102]
asps_mesh_binary_coding_enabled_flag等于0指示网格顶点和连通性数据不以二进制格式存在。当不存在时,asps_mesh_binary_coding_enabled_flag被推断为0。
[0103]
asps_mesh_binary_codec_id指示用于压缩用于面片的顶点和连通性信息的编解码器的标识符。asps_mesh_binary_codec_id应在0到255的范围内,包括端点。这个编解码器可以通过附录a中定义的简档或通过本文档之外的方式来识别。
[0104]
asps_mesh_quad_face_flag等于1指示四边形被用于多边形表示。asps_mesh_
quad_face_flage等于0指示三角形被用于网格的多边形表示。当不存在时,asps_mesh_quad_flag的值被推断为等于0。
[0105]
asps_mesh_vertices_in_vertex_map_flag等于1指示顶点信息存在于顶点视频数据中。asps_mesh_vertices_in_vertex_flag等于0指示顶点信息存在于面片数据中。当不存在时,asps_mesh_vertices_in_vertex_map_flag的值被推断为等于0。
[0106]
该语法允许四种不同类型的顶点/连通性编解码:
[0107]
1.直接在面片中发送顶点和连通性信息。
[0108]
2.在顶点图中发送顶点信息并且在面片中发送面连通性。
[0109]
3.在顶点图中发送顶点信息并且在解码器侧推导面连通性(例如,使用球枢转或泊松重构)。
[0110]
4.使用外部网格编码器(例如,sc3dm、draco等)对顶点和连通性信息进行编解码。
[0111]
与常规3d网格不同,2d网格是经过编码的。
[0112]
新的v3c视频数据单元携带顶点的位置的信息。数据单元能够包含指示投影的顶点的位置的二进制值,或者也能够包含用于连通性重构的多级信息。数据单元允许通过对多层中的顶点进行编解码来构造细节级别。数据单元使用vps扩展来定义附加参数。
[0113]
[0114]
[0115][0116]
vuh_lod_index在存在时指示当前顶点流的lod索引。
[0117]
当不存在时,当前顶点子位流的lod索引是基于子位流的类型和子条款x.x中针对顶点视频子位流分别描述的操作导出的。
[0118]
vuh_lod_index的值在存在时应在0到vms_lod_count_minus1[vuh_atlas_id]的范围内,包括端点。
[0119]
vuh_reserved_zero_13bits当存在时在符合本文档的这个版本的位流中应等于0。用于vuh_reserved_zero_13bits的其它值被保留以供iso/iec将来使用。解码器应忽略vuh_reserved_zero_13bits的值。
[0120]
[0121][0122]
vme_lod_count_minus1[k]加1指示用于对图集id为k的图集的顶点数据进行编码的lod的数量。vme_lod_count_minus1[j]应在0到15的范围内,包括端点。
[0123]
vme_embed_vertex_in_occupancy_flag[k]等于1指定顶点信息是从条款xx中针对图集id为k的图集指定的占用图导出的。
[0124]
vme_embed_vertex_in_occupancy_flag[k]等于0指定顶点信息不是从占用视频导出的。当vme_embed_vertex_in_occupancy_flag[k]不存在时,推断为等于0。
[0125]
vme_multiple_lod_streams_present_flag[k]等于0指示用于图集id为k的图集的所有lod分别被放置在单个顶点视频流中。
[0126]
vme_multiple_lod_streams_present_flag[k]等于1指示用于图集id为k的图集的所有lod被放置在分离的视频流中。当vme_multiple_lod_streams_present_flag[k]不存在时,其值应被推断为等于0。
[0127]
vme_lod_absolute_coding_enabled_flag[j][i]等于1指示用于图集id为k的图集的索引为i的lod被编解码,没有任何形式的图预测。vme_lod_absolute_coding_enabled_flag[k][i]等于0指示用于图集id为k的图集的索引为i的lod在编解码之前首先从另一个更早被编解码的图被预测。如果vme_lod_absolute_coding_enabled_flag[j][i]不存在,其值应被推断为等于1。
[0128]
当vps_map_absolute_coding_enabled_flag[j][i]等于0时,vme_lod_predictor_index_diff[k][i]被用于计算用于图集id为k的图集的索引为i的lod的预测器。更具体而言,用于lod i的图预测器索引,lodpredictorindex[i],应计算为:
[0129]
lodpredictorindex[i]=(i
–
1)
–
vme_lod_predictor_index_diff[j][i]vme_lod_predictor_index_diff[j][i]的值应在0到i
–
1的范围内,包括端点。当vme_lod_predictor_index_diff[j][i]不存在时,其值应被推断为等于0。
[0130]
vme_vegrtex_video_present_flag[k]等于0指示id为k的图集没有顶点数据。
vms_vertex_video_present_flag[k]等于1指示id为k的图集有顶点数据。当vms_vertex_video_present_flag[j]不存在时,推断为等于0。
[0131][0132]
vi_vertex_codec_id[j]指示用于压缩用于图集id为j的图集的顶点信息的编解码器的标识符。
[0133]
vi_vertex_codec_id[j]应在0到255的范围内,包括端点。这个编解码器可以通过简档、分量编解码器映射sei消息或通过本文档之外的手段来识别。
[0134]
vi_lossy_vertex_compression_threshold[j]指示要用于从具有图集id j的图集的解码的顶点视频中导出二进制顶点的阈值。vi_lossy_vertex_compression_threshold[j]应在0到255的范围内,包括端点。
[0135]
vi_vertex_2d_bit_depth_minus1[j]加1指示用于图集id为j的图集的顶点视频应转换到的标称2d位深度。vi_vertex_2d_bit_depth_minus1[j]应在0到31的范围内,包括端点。vi_vertex_msb_align_flag[j]指示如何将与图集id为j的图集相关联的解码的顶点视频样本转换成标称顶点位深度的样本。
[0136]
图6图示了根据一些实施例的顶点视频数据的图像。顶点视频数据使用多层来指示细节级别,这对于渐进式网格编解码是有用的。如果只使用一层,那么可以将视频数据嵌入到占用图中,以避免生成若干解码实例。能够使用表面重构算法(例如,泊松表面重构和球枢转)生成连通性信息。
[0137]
顶点视频数据在图像中显示为圆点/点。这些点指示顶点在投影的图像中的位置。顶点视频数据能够在分离的视频中被直接发送,如图像600中所示,或者顶点视频数据能够嵌入在占用图像602中。图604示出了球枢转的示例。
[0138]
图7图示了根据一些实施例的示例性细节级别生成的图像。顶点能够在层中组合以生成网格的多级别表示。指定细节级别的生成。原始点云在图像700中示出,它有762个顶点和1,245个面。不是发送所有数据,而是仅发送10%的顶点/连通性,这是10%的聚类抽取,如图像702中所示,其发送58个顶点和82个面。图像704示出5%的聚类抽取,它发送213个顶点和512个面。图像706示出2.5%的聚类抽取,它发送605个顶点和978个面。通过将层分离,有可能逐步发送多个层以提高质量(例如,第一层为10%抽取,第二层为5%,并且第三层为2.5%)。这些层能够被组合以获得网格的顶点和面的原始数量(或接近其)。
[0139]
图8图示了根据一些实施例的网格的图。在一些实施例中,sc3dm(mpeg)能够被用于对每个面片的网格信息进行编码。sc3dm能够被用于对连通性和(u,v)信息进行编码。在一些实施例中,draco被用于对每个面片的网格信息进行编码。draco能够被用于对连通性和(u,v)信息进行编码。
[0140]
图9图示了根据一些实施例的网格重构的图。连通性使用新的顶点编号,但能够将面片加在一起。由于压缩,接缝处的顶点可能不匹配。网格平滑或拉链算法能够被用来解决这个问题。
[0141]
图10图示了根据一些实施例的允许发送点云和网格面片的混合的高级语法和图像的图。由于网格是在面片级别描述的,因此有可能混合和匹配用于物体的面片。例如,仅点云的面片能够被用于头部或头发,而网格面片被用于诸如身体之类的平坦区域。
[0142]
被跟踪的网格面片数据单元能够使用面片来指示连通性从一个面片到另一个面片没有改变。这对于跟踪的网格情况特别有用,因为只发送增量位置。在跟踪的网格的情况下,发生全局运动,该运动能够通过界定框位置和旋转(新引入的使用四元数的语法元素)和由顶点运动捕获的表面运动捕获。如果参考面片正在使用v3c_vvd数据,那么顶点运动能够在面片信息中显式发送,或者从视频数据中导出。发送增量顶点信息的位的数量能够在图集帧参数集(atlas frame parameter set,afps)中被发送。可替代地,运动信息也能够作为单应变换被发送。
[0143]
[0144]
[0145][0146]
tmpdu_vertices_changed_position_flag指定顶点是否改变它们的位置。tmpdu_vertex_delta_pos_x[p][i]指定面片p的第i个顶点的x坐标值与由tmpdu_ref_index[p]指示的匹配的面片的差异。tmpdu_vertex_pos_x[p][i]的值应在0到pow2(afps_num_bits_delta_x)-1的范围内,包括端点。
[0147]
tmpdu_vertex_delta_pos_y[p][i]指定面片p的第i个顶点的y坐标值与由tmpdu_ref_index[p]指示的匹配的面片的差异。tmpdu_vertex_pos_x[p][i]的值应在0到pow2(afps_num_bits_delta_y)-1的范围内,包括端点。
[0148]
tmpdu_rotation_present_flag指定旋转值是否存在。
[0149]
tmpdu_3d_rotation_qx使用四元数表示为当前面片的几何旋转指定x分量qx。tmpdu_3d_rotation_qx的值应在-2
15
到2
15-1的范围内,包括端点。当tmpdu_3d_rotation_qx不存在时,其值应被推断为等于0。qx的值计算如下:
[0150]
qx=tmpdu_3d_rotation_qx
÷215
[0151]
tmpdu_3d_rotation_qy使用四元数表示为当前面片的几何旋转指定y分量qy。tmpdu_3d_rotation_qy的值应在-2
15
到2
15-1的范围内,包括端点。当tmpdu_3d_rotation_qy不存在时,其值应被推断为等于0。qy的值被计算如下:
[0152]
qy=tmpdu_3d_rotation_qy
÷215
[0153]
tmpdu_3d_rotation_qz使用四元数表示为当前面片的几何旋转指定z分量qz。tmpdu_3d_rotation_qz的值应在在-2
15
到2
15-1的范围内,包括端点。当tmpdu_3d_rotation_qz不存在时,其值应被推断为等于0。qz的值被计算如下:
[0154]
qz=tmpdu_3d_rotation_qz
÷215
[0155]
使用四元数表示的当前点云图像的几何旋转的第四分量qw被计算如下:
[0156]
qw=sqrt(1
–
(qx2+qy2+qz2))
[0157]
单位四元数可以表示为旋转矩阵r,如下所示:
[0158]
[0159]
图11a-b图示了根据一些实施例的组合的未跟踪的和跟踪的网格信息的图。为了避免跟踪问题,一些算法将网格分割为跟踪的部分和未跟踪的部分。跟踪的部分在时间上是一致的并且能够由提出的tracked_mesh_patch_data_unit()表示,而未跟踪的部分在每一帧都是新的,并且能够由mesh_patch_data_unit()表示。由于符号允许将点云混合到几何形状中,因此也能够改进表面表示(例如,保留原始网格并在网格的顶部插入点云以隐藏缺陷)。
[0160]
图12图示了根据一些实施例的基于面片的边折叠的示例性图像。边折叠过滤器能够被应用于面片数据以减少编解码的三角形的数量。几何和纹理信息能够保持不变以改进渲染。网格简化能够通过使用精细的几何数据来逆转。meshlab可以选择应用边折叠,即使具有边界保持。但是,该算法在3d空间中工作,并且它不使用网格的投影特点。新的想法是做“2d投影的面片域中的边折叠过滤器”,即,考虑边的2d特点,对面片数据应用边折叠。
[0161]
图像1200示出了具有5,685个顶点和8,437个面的原始密集网格。图像1202示出了具有2,987个顶点和3,041个面的面片边折叠(保留边界)。图像1204示出了具有1,373个顶点和1,285个面的面片边折叠。图像1206示出了具有224个顶点和333个面的完整网格边折叠。
[0162]
图13图示了根据一些实施例的基于面片的聚类抽取的示例性图像。meshlab可以选择基于3d网格进行抽取(聚类抽取)。由于面片是2d中的投影的数据,因此能够替代地在2d空间中执行抽取。此外,保留被抽取的顶点的数量以重构回面(使用精细几何数据和表面细分)。这个信息可以在占用图中被发送。
[0163]
图像1300示出了具有5,685个顶点和8,437个面的原始密集网格。图像1302示出了具有3,321个顶点和4,538个面的聚类抽取(1%)。图像1304示出了具有730个顶点和870个面的聚类抽取(2.5%)。图像1306示出了具有216个顶点和228个面的聚类抽取(5%)。图像1308示出了具有90个顶点和104个面的聚类抽取(10%)。
[0164]
图14图示了根据一些实施例的基于面片的表面细分的示例性图像。meshlab有若干过滤器以生成更精细的网格,但它们假设一些启发法(例如,在中间点划分三角形)。如果使用几何信息来引导应当在哪里划分三角形,那么能够获得更好的结果。例如,能够从低分辨率网格生成高分辨率网格。网格信息的上采样由几何形状引导。
[0165]
图像1400示出了具有224个顶点和333个面的网格。图像1402示出了细分表面:具有784个顶点和1,332个面的中点(1次迭代)。图像1404示出了细分表面:具有2,892个顶点和5,308个面的中点(2次迭代)。图像1406示出了细分表面:具有8,564个顶点和16,300个面的中点(3次迭代)。
[0166]
图15图示了根据一些实施例的基于面片的表面重构的示例性图像。meshlab具有过滤器以从点云(屏幕泊松和球枢转)重构网格表面。算法能够被用于在面片级别重构解码器侧的网格连通性(顶点列表被发信号通知,例如经由占用图可用)。在一些实施例中,不发送连通性信息,并且能够使用泊松或球枢转来重新生成连通性信息。
[0167]
图像1500示出了具有5,685个顶点的密集顶点云。图像1502示出了具有13,104个顶点和26,033个面的泊松表面重构。图像1504示出了具有5,685个顶点和10,459个面的球枢转。
[0168]
在一些实施例中,顶点的位置是从占用图获得的。能够使用嵌入在占用图中的颜
色信息。在编码器侧,与每个三重顶点集相关联的面区域被涂上固定的颜色。每个面的颜料颜色都是不同的,并以易于颜色分割的方式选择。使用m元(m-ary)级别的占用图。在解码器侧,占用图被解码。面信息是基于分割的颜色导出的。
[0169]
在一些实施例中,顶点的位置是从占用获得的。指派新的属性来携带面信息。在编码器侧,生成尺寸(宽x高)等于面数的属性矩形。该属性具有三个维度,而每个维度都携带三重顶点之一的索引。在解码器侧,对属性视频进行解码。从解码的属性视频中导出面信息。
[0170]
在一些实施例中,顶点的位置是使用delaunay三角测量从占用图获得的。在解码器侧,占用图视频被解码。从解码的占用图获得的顶点被三角测量。三角测量的点被用于获得面信息。
[0171]
图16图示了根据一些实施例的三角形边检测的图。原始图像1600具有蓝色、红色和黄色三角形。分割的蓝色三角形图像1602示出蓝色三角形,分割的红色三角形图像1604示出红色三角形,并且分割的黄色三角形图像1606示出黄色三角形。
[0172]
三角形能够基于颜色进行分组。三角形能够基于相交的边被分割,这指示三角形在哪里,三角形的边在哪里,甚至顶点在哪里。
[0173]
图17图示了根据一些实施例的基于颜色分离的三角形的分割的边的图。原始图像1600具有蓝色、红色和黄色三角形。分割的蓝色边图像1700示出蓝色三角形边,分割的红色边图像1702示出红色三角形边,并且分割的黄色边图像1704示出黄色三角形边。
[0174]
图18图示了根据一些实施例的组合的三角形的分割的边的图。原始图像1600具有蓝色、红色和黄色三角形。组合的边在三角形边图像1800中示出。
[0175]
图19-23图示了根据一些实施例的重新调整尺寸和重新缩放边的图。图像、三角形和/或边能够被重新调整尺寸(例如,收缩),然后能够检测重新调整尺寸的三角形,能够确定重新缩放的边,并且能够确定/生成重新调整尺寸的边。
[0176]
如本文所述,通过进行分割、找到边、三角形和顶点以及确定哪些位置是连接的,颜色能够被用于对三角形位置和三角形连通性进行编码。
[0177]
图24图示了根据一些实施例的被配置为实现基于视频的网格压缩方法的示例性计算设备的框图。计算设备2400能够被用于获取、存储、计算、处理、传送和/或显示信息,诸如包括3d内容的图像和视频。计算设备2400能够实现任何编码/解码方面。一般而言,适于实现计算设备2400的硬件结构包括网络接口2402、存储器2404、处理器2406、(一个或多个)i/o设备2408、总线2410和存储设备2412。处理器的选择并不重要,只要选择具有足够速度的合适处理器即可。存储器2404能够是本领域已知的任何常规计算机存储器。存储设备2412能够包括硬盘驱动器、cdrom、cdrw、dvd、dvdrw、高清盘/驱动器、超高清驱动器、闪存卡或任何其它存储设备。计算设备2400能够包括一个或多个网络接口2402。网络接口的示例包括连接到以太网或其它类型的lan的网卡。(一个或多个)i/o设备2408能够包括以下当中的一个或多个:键盘、鼠标、监视器、屏幕、打印机、调制解调器、触摸屏、按钮接口和其它设备。用于实现基于视频的网格压缩实现的基于视频的(一个或多个)网格压缩应用2430很可能存储在存储设备2412和存储器2404中并且如应用通常被处理那样被处理。图24中所示的更多或更少组件能够被包括在计算设备2400中。在一些实施例中,包括基于视频的网格压缩硬件2420。虽然图24中的计算设备2400包括用于基于视频的网格压缩实现的应用2430和
硬件2420,但是基于视频的网格压缩方法能够以硬件、固件、软件或其任何组合在计算设备上实现。例如,在一些实施例中,基于视频的网格压缩应用2430被编程在存储器中并且使用处理器来执行。在另一个示例中,在一些实施例中,基于视频的网格压缩硬件2420是编程的硬件逻辑,包括专门被设计用于实现基于视频的网格压缩方法的门。
[0178]
在一些实施例中,(一个或多个)基于视频的网格压缩应用2430包括若干应用和/或模块。在一些实施例中,模块也包括一个或多个子模块。在一些实施例中,能够包括更少或附加的模块。
[0179]
合适的计算设备的示例包括个人计算机、膝上型计算机、计算机工作站、服务器、大型计算机、手持计算机、个人数字助理、蜂窝/移动电话、智能电器、游戏控制台、数码相机、数码摄像机、照相电话、智能电话、便携式音乐播放器、平板计算机、移动设备、视频播放器、视频盘刻录机/播放器(例如,dvd刻录机/播放器、高清盘刻录机/播放器,超高清盘刻录机/播放器)、电视机、家庭娱乐系统、增强现实设备、虚拟现实设备、智能珠宝(例如,智能手表)、车辆(例如,自动驾驶车辆)或任何其它合适的计算设备。
[0180]
图25图示了根据一些实施例的被配置为实现基于视频的网格压缩的系统的图。编码器2500被配置为实现编码过程。如本文所述,能够实现任何编码,诸如基于视频的网格压缩。网格和其它信息能够直接传送到解码器2504或通过网络2502传送。网络能够是任何类型的网络,诸如局域网(lan)、互联网、无线网络、有线网络、蜂窝网络和/或任何其它网络或网络的组合。解码器2504对编码的内容进行解码。
[0181]
为了利用基于视频的网格压缩方法,设备获取或接收3d内容(例如,点云内容)。基于视频的网格压缩方法能够在用户协助下实现或在没有用户参与的情况下自动实现。
[0182]
在操作中,与以前的实施方式相比,基于视频的网格压缩方法使得能够实现更高效和更准确的3d内容编码。
[0183]
基于视频的网格压缩的一些实施例
[0184]
1、一种方法,包括:
[0185]
对输入网格执行网格体素化;
[0186]
实现面片生成,所述面片生成将网格分割成包括光栅化的网格表面和顶点位置和连通性信息的面片;
[0187]
从光栅化的网格表面生成基于可视体积视频的压缩(v3c)图像;
[0188]
用顶点位置和连通性信息实现基于视频的网格压缩;以及
[0189]
基于v3c图像和基于视频的网格压缩生成v3c位流。
[0190]
2、如条款1所述的方法,其中顶点位置和连通性信息包括表面面片的三角形信息。
[0191]
3、如条款1所述的方法,其中来自用顶点位置和连通性信息实现基于视频的网格压缩的数据被封装在顶点视频组件结构中。
[0192]
4、如条款3所述的方法,其中顶点视频组件结构通过分离各层中的顶点的集合并生成用于网格连通性的各细节级别来实现渐进式网格编码。
[0193]
5、如条款1所述的方法,其中当仅实现一层时,视频数据被嵌入在占用图中。
[0194]
6、如条款1所述的方法,其中连通性信息是使用包括泊松表面重构或球枢转的表面重构算法生成的。
[0195]
7、如条款1所述的方法,其中从光栅化的网格表面生成v3c图像包括组合未跟踪的
和跟踪的网格信息。
[0196]
8、如条款1所述的方法,还包括在二维投影的面片域中实现边折叠过滤器。
[0197]
9、如条款1所述的方法,还包括实现连通性信息的基于面片的表面细分。
[0198]
10、一种装置,包括:
[0199]
用于存储应用的非暂态存储器,所述应用用于:
[0200]
对输入网格执行网格体素化;
[0201]
实现面片生成,所述面片生成将网格分割成包括光栅化的网格表面和顶点位置和连通性信息的面片;
[0202]
从光栅化的网格表面生成基于可视体积视频的压缩(v3c)图像;
[0203]
用顶点位置和连通性信息实现基于视频的网格压缩;以及
[0204]
基于v3c图像和基于视频的网格压缩生成v3c位流;以及耦合到存储器的处理器,所述处理器被配置用于处理所述应用。
[0205]
11、如条款10所述的装置,其中顶点位置和连通性信息包括表面面片的三角形信息。
[0206]
12、如条款10所述的装置,其中来自用顶点位置和连通性信息实现基于视频的网格压缩的数据被封装在顶点视频组件结构中。
[0207]
13、如条款12所述的装置,其中顶点视频组件结构通过分离各层中的顶点的集合并生成用于网格连通性的各细节级别来实现渐进式网格编码。
[0208]
14、如条款10所述的装置,其中当仅实现一层时,视频数据被嵌入在占用图中。
[0209]
15、如条款10所述的装置,其中连通性信息是使用包括泊松表面重构或球枢转的表面重构算法生成的。
[0210]
16、如条款10所述的装置,其中从光栅化的网格表面生成v3c图像包括组合未跟踪的和跟踪的网格信息。
[0211]
17、如条款10所述的装置,其中所述应用还被配置用于在二维投影的面片域中实现边折叠过滤器。
[0212]
18、如条款10所述的装置,其中所述应用还被配置用于实现连通性信息的基于面片的表面细分。
[0213]
19、一种系统,包括:
[0214]
一个或多个相机,用于获取三维内容;
[0215]
编码器,用于对三维内容进行编码:
[0216]
对输入网格执行网格体素化;
[0217]
实现面片生成,所述面片生成将网格分割成包括光栅化的网格表面和顶点位置和连通性信息的面片;
[0218]
从光栅化的网格表面生成基于可视体积视频的压缩(v3c)图像;
[0219]
用顶点位置和连通性信息实现基于视频的网格压缩;以及
[0220]
基于v3c图像和基于视频的网格压缩生成v3c位流。
[0221]
20、如条款19所述的系统,其中顶点位置和连通性信息包括表面面片的三角形信息。
[0222]
21、如条款19所述的系统,其中来自用顶点位置和连通性信息实现基于视频的网
格压缩的数据被封装在顶点视频组件结构中。
[0223]
22、如条款21所述的系统,其中顶点视频组件结构通过分离各层中的顶点的集合并生成用于网格连通性的各细节级别来实现渐进式网格编码。
[0224]
23、如条款19所述的系统,其中当仅实现一层时,视频数据被嵌入在占用图中。
[0225]
24、如条款19所述的系统,其中连通性信息是使用包括泊松表面重构或球枢转的表面重构算法生成的。
[0226]
25、如条款19所述的系统,其中从光栅化的网格表面生成v3c图像包括组合未跟踪的和跟踪的网格信息。
[0227]
26、如条款19所述的系统,其中编码器被配置用于在二维投影的面片域中实现边折叠过滤器。
[0228]
27、如条款19所述的系统,其中所述编码器被配置用于实现连通性信息的基于面片的表面细分。
[0229]
本发明已根据具体实施例进行了描述,具体实施例结合了促进理解本发明的构造和操作原理的细节。本文对具体实施例及其细节的这种引用并不旨在限制所附权利要求的范围。对本领域技术人员来说显而易见的是,在不脱离如权利要求限定的本发明的精神和范围的情况下,可以在选择用于说明的实施例中进行其它各种修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1