用于机器学习应用的用户装备(UE)能力报告的制作方法
用于机器学习应用的用户装备(ue)能力报告
1.相关申请的交叉引用
2.本技术要求于2021年10月7日提交的题为“user equipment(ue)capability report for machine learning applications(用于机器学习应用的用户装备(ue)能力报告)”的美国专利申请no.17/496,650的优先权,该美国专利申请要求于2020年10月9日提交的题为“user equipment(ue)capability report for machine learning applications(用于机器学习应用的用户装备(ue)能力报告)”的美国临时专利申请no.63/090,141的权益,这些申请的公开内容通过援引全部明确纳入于此。
3.公开领域
4.本公开的各方面一般涉及无线通信,尤其涉及用于机器学习应用的用户装备(ue)能力报告的技术和装置。
5.背景
6.无线通信系统被广泛部署以提供诸如电话、视频、数据、消息接发、和广播等各种电信服务。典型的无线通信系统可以采用能够通过共享可用的系统资源(例如,带宽、发射功率等)来支持与多个用户通信的多址技术。此类多址技术的示例包括码分多址(cdma)系统、时分多址(tdma)系统、频分多址(fdma)系统、正交频分多址(ofdma)系统、单载波频分多址(sc-fdma)系统、时分同步码分多址(td-scdma)系统、以及长期演进(lte)。lte/高级lte是对由第三代伙伴项目(3gpp)颁布的通用移动电信系统(umts)移动标准的增强集。
7.无线通信网络可包括能支持数个用户装备(ue)通信的数个基站(bs)。用户装备(ue)可经由下行链路和上行链路来与基站(bs)通信。下行链路(或即前向链路)是指从bs到ue的通信链路,而上行链路(或即反向链路)是指从ue到bs的通信链路。如将更详细描述的,bs可以被称为b节点、gnb、接入点(ap)、无线电头端、传送接收点(trp)、新无线电(nr)bs、5g b节点等等。
8.以上多址技术已经在各种电信标准中被采纳以提供使得不同的用户装备能够在城市、国家、地区、以及甚至全球级别上进行通信的共同协议。新无线电(nr)(其还可被称为5g)是对由第三代伙伴项目(3gpp)颁布的lte移动标准的增强集。nr被设计成通过改善频谱效率、降低成本、改善服务、利用新频谱、以及与在下行链路(dl)上使用具有循环前缀(cp)的正交频分复用(ofdm)(cp-ofdm)、在上行链路(ul)上使用cp-ofdm和/或sc-fdm(例如,还被称为离散傅里叶变换扩展ofdm(dft-s-ofdm)以及支持波束成形、多输入多输出(mimo)天线技术和载波聚集的其他开放标准更好地整合,来更好地支持移动宽带因特网接入。
9.人工神经网络可以包括诸群互连的人工神经元(例如,神经元模型)。人工神经网络可以是计算设备或表示为要由计算设备执行的方法。卷积神经网络(诸如深度卷积神经网络)是一种前馈人工神经网络。卷积神经网络可以包括可以在平铺感受野中配置的各神经元层。将神经网络处理应用于无线通信以达成更高的效率将是合乎需要的。
10.概述
11.根据本公开的各方面,一种无线通信的方法从基站接收机器学习模型。该方法向该基站报告机器学习处理能力。该方法还向该基站传送对该机器学习模型的梯度更新或权
重更新。
12.在本公开的其他方面,一种无线通信的方法向数个用户装备(ue)传送机器学习模型。该方法从每个ue接收机器学习处理能力报告。该方法还根据机器学习处理能力报告来对数个ue编群以接收对该机器学习模型的梯度更新。
13.在本公开的其他方面,一种用于在用户装备(ue)处进行无线通信的装置包括处理器以及与该处理器耦合的存储器。存储在该存储器中的指令在由该处理器执行时能操作用于使得该装置从基站接收机器学习模型。该装置可以向该基站报告机器学习处理能力。该装置还可以向该基站传送对该机器学习模型的梯度更新或权重更新。
14.在本公开的其他方面,一种用于在基站处进行无线通信的装置包括处理器以及与该处理器耦合的存储器。存储在该存储器中的指令在由该处理器执行时能操作用于使得该装置向数个用户装备(ue)传送机器学习模型。该装置可以从每个ue接收机器学习处理能力报告。该装置还可以根据机器学习处理能力报告来对数个ue编群以接收对该机器学习模型的梯度更新。
15.在本公开的其他方面,一种用于无线通信的用户装备(ue)包括用于从基站接收机器学习模型的装置。该ue包括用于向该基站报告机器学习处理能力的装置。该ue还包括用于向该基站传送对该机器学习模型的梯度更新或权重更新的装置。
16.在本公开的另外其他方面,一种用于无线通信的基站包括用于向数个用户装备(ue)传送机器学习模型的装置。该基站包括用于从该数个ue中的每个ue接收机器学习处理能力报告的装置。该基站还包括用于根据机器学习处理能力报告来对数个ue编群以接收对该机器学习模型的梯度更新的装置。
17.在本公开的另外其他方面,公开了一种其上记录有程序代码的非瞬态计算机可读介质。该程序代码由用户装备(ue)执行并包括用于从基站接收机器学习模型的程序代码。该ue包括用于向该基站报告机器学习处理能力的程序代码。该ue还包括用于向该基站传送对该机器学习模型的梯度更新或权重更新的程序代码。
18.在本公开的其他方面,公开了一种其上记录有程序代码的非瞬态计算机可读介质。该程序代码由基站执行并包括用于向数个用户装备(ue)传送机器学习模型的程序代码。该基站包括用于从该数个ue中的每个ue接收机器学习处理能力报告的程序代码。该基站还包括用于根据机器学习处理能力报告来对数个ue编群以接收对该机器学习模型的梯度更新的程序代码。
19.各方面一般包括如基本上参照附图和说明书描述并且如附图和说明书所解说的方法、装置、系统、计算机程序产品、非瞬态计算机可读介质、用户装备、基站、无线通信设备和处理系统。
20.前述内容已较宽泛地勾勒出根据本公开的示例的特征和技术优势以力图使下面的详细描述可被更好地理解。将描述附加的特征和优势。所公开的概念和具体示例可容易地被用作修改或设计用于实施与本公开相同目的的其他结构的基础。此类等效构造并不背离所附权利要求书的范围。所公开的概念的特性在其组织和操作方法两方面以及相关联的优势将因结合附图来考虑以下描述而被更好地理解。每一附图是出于解说和描述目的来提供的,而非定义对权利要求的限定。
21.附图简述
22.为了可以详细地理解本公开的特征,可以参照各方面进行更具体的描述,其中一些方面在附图中解说。然而应注意,附图仅解说了本公开的某些方面,故不应被认为限定其范围,因为本描述可允许有其他等同有效的方面。不同附图中的相同附图标记可标识相同或相似的元素。
23.图1是概念性地解说根据本公开的各个方面的无线通信网络的示例的框图。
24.图2是概念性地解说根据本公开的各个方面的无线通信网络中基站与用户装备(ue)处于通信的示例的框图。
25.图3解说了根据本公开的某些方面的使用片上系统(soc)(包括通用处理器)来设计神经网络的示例实现。
26.图4a、4b和4c是解说根据本公开的各方面的神经网络的示图。
27.图4d是解说根据本公开的各方面的示例性深度卷积网络(dcn)的示图。
28.图5是解说根据本公开的各方面的示例性深度卷积网络(dcn)的框图。
29.图6是解说根据本公开的各方面的联合学习的框图。
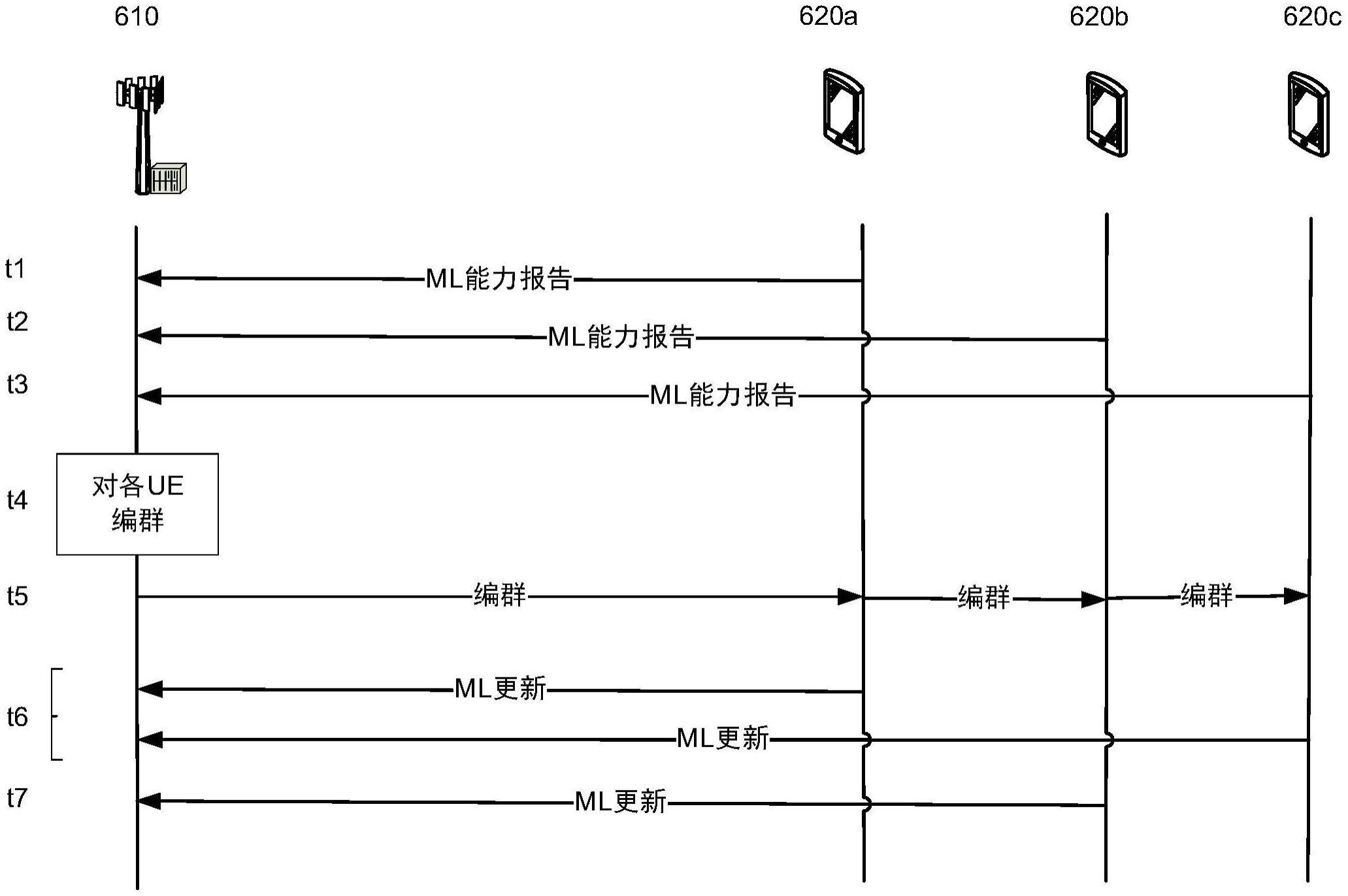
30.图7是解说根据本公开的各方面的报告机器学习能力的时序图。
31.图8是解说根据本公开的各个方面的例如由用户装备(ue)执行的示例过程的流程图。
32.图9是解说根据本公开的各个方面的例如由基站执行的示例过程的流程图。
33.详细描述
34.以下参照附图更全面地描述本公开的各个方面。然而,本公开可用许多不同形式来实施并且不应解释为被限于本公开通篇给出的任何具体结构或功能。相反,提供这些方面是为了使得本公开将是透彻和完整的,并且其将向本领域技术人员完全传达本公开的范围。基于本教导,本领域技术人员应领会,本公开的范围旨在覆盖本公开的任何方面,不论其是与本公开的任何其他方面相独立地实现还是组合地实现的。例如,可使用所阐述的任何数目的方面来实现装置或实践方法。另外,本公开的范围旨在覆盖使用作为所阐述的本公开的各个方面的补充或者另外的其他结构、功能性、或者结构及功能性来实践的此类装置或方法。应当理解,所披露的本公开的任何方面可由权利要求的一个或多个元素来实施。
35.现在将参照各种装置和技术给出电信系统的若干方面。这些装置和技术将在以下详细描述中进行描述并在附图中由各种框、模块、组件、电路、步骤、过程、算法等等(统称为“元素”)来解说。这些元素可使用硬件、软件、或其组合来实现。此类元素是实现成硬件还是软件取决于具体应用和加诸于整体系统上的设计约束。
36.应当注意到,虽然各方面可使用通常与5g和后代无线技术相关联的术语来描述,但本公开的各方面可以在基于其他代的通信系统(诸如并包括3g和/或4g技术)中应用。
37.标准机器学习办法将训练数据集中于一台机器上或数据中心中。联合学习模型支持对用户装备(ue)和基站(或集中式服务器)之中的共享预测模型的协作式学习。联合学习是其中一群ue从基站接收机器学习模型并共同工作以训练该模型的过程。更具体而言,每个ue在本地训练模型,并根据例如在本地执行的随机梯度下降过程来发送回经更新的神经网络模型权重或梯度更新。基站从该群中的所有ue接收更新,并例如通过平均化这些更新来聚集更新以获得神经网络的经更新全局权重。基站向各ue发送经更新模型,并且该过程一轮接一轮地重复,直至获得全局模型的期望性能水平。
38.在联合学习过程的每一轮中,一群ue在这些ue从基站接收模型之后的给定时间区间内发送回权重或梯度更新。如果ue错过了发送更新的最终期限,则权重或梯度将变得陈旧,并且基站针对联合学习过程的该本地训练轮次将不会将更新纳入权重或梯度聚集中。
39.根据本公开的各方面,ue向基站报告其机器学习处理能力。在一些方面,该报告可指示机器学习硬件能力。在其他方面,该报告指示用于在每一轮联合学习中计算梯度或权重更新的近似周转时间。在本公开的另外其他方面,ue报告例如因变于该ue的电池状态的、用于计算梯度或权重的近似周转时间。
40.所报告的机器学习硬件能力向基站提供了ue侧用于准备每个梯度或权重更新的近似训练时间。例如,基站可以基于所报告的机器学习能力来决定报告方ue是快速ue还是慢速ue。因此,基站可根据机器学习能力来对各ue编群以用于不同的联合学习轮次。慢速ue可以与其他更慢的ue编群,而快速ue与其他更快的ue编群,从而提高联合学习过程的效率。
41.图1是解说可以在其中实践本公开的各方面的网络100的示图。网络100可以是5g或nr网络或某一其他无线网络,诸如lte网络。无线网络100可包括数个bs 110(示为bs 110a、bs 110b、bs 110c、以及bs 110d)和其他网络实体。bs是与用户装备(ue)通信的实体并且还可被称为基站、nr bs、b节点、gnb、5g b节点(nb)、接入点、传送接收点(trp)、等等。每个bs可为特定地理区域提供通信覆盖。在3gpp中,术语“蜂窝小区”可以指bs的覆盖区域和/或服务该覆盖区域的bs子系统,这取决于使用该术语的上下文。
42.bs可以为宏蜂窝小区、微微蜂窝小区、毫微微蜂窝小区、和/或另一类型的蜂窝小区提供通信覆盖。宏蜂窝小区可覆盖相对较大的地理区域(例如,半径为数千米),并且可允许由具有服务订阅的ue无约束地接入。微微蜂窝小区可覆盖相对较小的地理区域,并且可允许由具有服务订阅的ue无约束地接入。毫微微蜂窝小区可覆盖相对较小的地理区域(例如,住宅),并且可允许由与该毫微微蜂窝小区有关联的ue(例如,封闭订户群(csg)中的ue)有约束地接入。用于宏蜂窝小区的bs可被称为宏bs。用于微微蜂窝小区的bs可被称为微微bs。用于毫微微蜂窝小区的bs可被称为毫微微bs或家用bs。在图1中示出的示例中,bs 110a可以是用于宏蜂窝小区102a的宏bs,bs 110b可以是用于微微蜂窝小区102b的微微bs,并且bs 110c可以是用于毫微微蜂窝小区102c的毫微微bs。bs可支持一个或多个(例如,三个)蜂窝小区。术语“enb”、“基站”、“nr bs”、“gnb”、“trp”、“ap”、“b节点”、“5g nb”和“蜂窝小区”可以可互换地使用。
43.在一些方面,蜂窝小区可以不必是驻定的,并且蜂窝小区的地理区域可根据移动bs的位置而移动。在一些方面,bs可通过各种类型的回程接口(诸如直接物理连接、虚拟网络等等)使用任何合适的传输网络来彼此互连和/或互连至无线网络100中的一个或多个其他bs或网络节点(未示出)。
44.无线网络100还可以包括中继站。中继站是能接收来自上游站(例如,bs或ue)的数据的传输并向下游站(例如,ue或bs)发送该数据的传输的实体。中继站也可以是能为其他ue中继传输的ue。在图1中示出的示例中,中继站110d可与宏bs 110a和ue 120d进行通信以促成bs 110a与ue 120d之间的通信。中继站还可被称为中继bs、中继基站、中继等等。
45.无线网络100可以是包括不同类型的bs(例如,宏bs、微微bs、毫微微bs、中继bs等)的异构网络。这些不同类型的bs可具有不同的发射功率电平、不同的覆盖区域、以及对无线网络100中的干扰的不同影响。例如,宏bs可具有高发射功率电平(例如,5到40瓦),而微微
bs、毫微微bs和中继bs可具有较低发射功率电平(例如,0.1到2瓦)。
46.网络控制器130可耦合到bs集,并且可提供对这些bs的协调和控制。网络控制器130可经由回程来与各bs进行通信。这些bs还可例如经由无线或有线回程直接或间接地彼此通信。
47.ue 120(例如,120a、120b、120c)可分散遍及无线网络100,并且每个ue可以是驻定的或移动的。ue还可被称为接入终端、终端、移动站、订户单元、站、等等。ue可以是蜂窝电话(例如,智能电话)、个人数字助理(pda)、无线调制解调器、无线通信设备、手持设备、膝上型计算机、无绳电话、无线本地环路(wll)站、平板、相机、游戏设备、上网本、智能本、超级本、医疗设备或装备、生物测定传感器/设备、可穿戴设备(智能手表、智能服装、智能眼镜、智能腕带、智能首饰(例如,智能戒指、智能手环))、娱乐设备(例如,音乐或视频设备、或卫星无线电)、交通工具组件或传感器、智能仪表/传感器、工业制造装备、全球定位系统设备、或者被配置成经由无线或有线介质通信的任何其他合适的设备。
48.一些ue可被认为是机器类型通信(mtc)ue、或者演进型或增强型机器类型通信(emtc)ue。mtc和emtc ue例如包括机器人、无人机、远程设备、传感器、仪表、监视器、位置标签等等,其可与基站、另一设备(例如,远程设备)或某个其他实体进行通信。无线节点可以例如经由有线或无线通信链路来为网络(例如,广域网(诸如因特网)或蜂窝网络)提供连通性或提供至该网络的连通性。一些ue可被认为是物联网(iot)设备,和/或可被实现为nb-iot(窄带物联网)设备。一些ue可被认为是客户端装备(cpe)。ue 120可被包括在外壳的内部,该外壳容纳ue 120的组件,诸如处理器组件、存储器组件、等等。
49.一般而言,在给定的地理区域中可部署任何数目的无线网络。每个无线网络可支持特定的rat,并且可在一个或多个频率上操作。rat还可被称为无线电技术、空中接口、等等。频率还可被称为载波、频率信道、等等。每个频率可在给定的地理区域中支持单个rat以避免不同rat的无线网络之间的干扰。在一些情形中,可部署nr或5g rat网络。
50.在一些方面,两个或更多个ue 120(例如,被示为ue 120a和ue 120e)可使用一个或多个侧链路信道来直接通信(例如,不使用基站110作为中介来彼此通信)。例如,ue 120可使用对等(p2p)通信、设备到设备(d2d)通信、车联网(v2x)协议(例如,其可包括交通工具到交通工具(v2v)协议、交通工具到基础设施(v2i)协议等等)、网状网络等等进行通信。在该情形中,ue 120可执行调度操作、资源选择操作、和/或在他处描述为由基站110执行的其他操作。例如,基站110可以经由下行链路控制信息(dci)、无线电资源控制(rrc)信令、媒体接入控制-控制元素(mac-ce)或经由系统信息(例如,系统信息块(sib))来配置ue 120。
51.ue 120可包括机器学习(ml)能力报告模块140。为了简洁起见,仅一个ue 120d被示出为包括ml能力报告模块140。ml能力报告模块140可从基站接收机器学习模型,并向基站报告机器学习处理能力。ml能力报告模块140还可向基站传送对机器学习模型的梯度更新或权重更新。
52.基站110可包括ml能力编群模块138。为了简洁起见,仅一个基站110a被示出为包括ml能力报告模块138。ml能力编群模块138可向多个用户装备(ue)传送机器学习模型。ml能力编群模块138还可从每个ue接收机器学习处理能力报告。ml能力编群模块138可进一步根据机器学习处理能力报告来对各ue编群以用于接收对机器学习模型的梯度更新。
53.如以上所指示的,图1仅仅是作为示例来提供的。其他示例可以不同于关于图1所
描述的示例。
54.图2示出了基站110和ue 120的设计200的框图,基站110和ue 120可以是图1中的各基站之一和各ue之一。基站110可装备有t个天线234a到234t,并且ue 120可装备有r个天线252a到252r,其中一般而言t≥1且r≥1。
55.在基站110处,发射处理器220可从数据源212接收给一个或多个ue的数据,至少部分地基于从每个ue接收到的信道质量指示符(cqi)来为该ue选择一种或多种调制和编码方案(mcs),至少部分地基于为每个ue选择的(诸)mcs来处理(例如,编码和调制)给该ue的数据,并提供针对所有ue的数据码元。减小mcs会降低吞吐量,但会提高传输的可靠性。发射处理器220还可处理系统信息(例如,针对半静态资源划分信息(srpi)等)和控制信息(例如,cqi请求、准予、上层信令等),并提供开销码元和控制码元。发射处理器220还可生成用于参考信号(例如,因蜂窝小区而异的参考信号(crs))和同步信号(例如,主同步信号(pss)和副同步信号(sss))的参考码元。发射(tx)多输入多输出(mimo)处理器230可在适用的情况下对数据码元、控制码元、开销码元、和/或参考码元执行空间处理(例如,预编码),并且可将t个输出码元流提供给t个调制器(mod)232a到232t。每个调制器232可处理各自的输出码元流(例如,针对ofdm等)以获得输出采样流。每个调制器232可进一步处理(例如,转换至模拟、放大、滤波、及上变频)输出采样流以获得下行链路信号。来自调制器232a到232t的t个下行链路信号可分别经由t个天线234a到234t被传送。根据以下更详细描述的各个方面,可以利用位置编码来生成同步信号以传达附加信息。
56.在ue 120处,天线252a到252r可接收来自基站110和/或其他基站的下行链路信号并且可分别向解调器(demod)254a到254r提供收到信号。每个解调器254可调理(例如,滤波、放大、下变频、及数字化)收到信号以获得输入采样。每个解调器254可进一步处理输入采样(例如,针对ofdm等)以获得收到码元。mimo检测器256可获得来自所有r个解调器254a到254r的收到码元,在适用的情况下对这些收到码元执行mimo检测,并且提供检出码元。接收处理器258可处理(例如,解调和解码)这些检出码元,将针对ue 120的经解码数据提供给数据阱260,并且将经解码的控制信息和系统信息提供给控制器/处理器280。信道处理器可确定参考信号收到功率(rsrp)、收到信号强度指示符(rssi)、参考信号收到质量(rsrq)、信道质量指示符(cqi)等等。在一些方面,ue 120的一个或多个组件可被包括在外壳中。
57.在上行链路上,在ue 120处,发射处理器264可接收和处理来自数据源262的数据和来自控制器/处理器280的控制信息(例如,针对包括rsrp、rssi、rsrq、cqi等的报告)。发射处理器264还可生成用于一个或多个参考信号的参考码元。来自发射处理器264的码元可在适用的情况下由tx mimo处理器266预编码,由调制器254a到254r进一步处理(例如,针对dft-s-ofdm、cp-ofdm等),并且被传送到基站110。在基站110处,来自ue 120和其他ue的上行链路信号可由天线234接收,由解调器254处理,在适用的情况下由mimo检测器236检测,并由接收处理器238进一步处理以获得经解码的由ue 120发送的数据和控制信息。接收处理器238可将经解码的数据提供给数据阱239并将经解码的控制信息提供给控制器/处理器240。基站110可包括通信单元244并且经由通信单元244与网络控制器130通信。网络控制器130可包括通信单元294、控制器/处理器290、以及存储器292。
58.基站110的控制器/处理器240、ue 120的控制器/处理器280、和/或图2的(诸)任何其他组件可执行与机器学习能力报告相关联的一种或多种技术,如在他处更详细地描述
的。例如,基站110的控制器/处理器240、ue 120的控制器/处理器280、和/或图2的(诸)任何其他组件可执行或指导例如图7-图9的过程和/或如所描述的其他过程的操作。存储器242和282可分别存储用于基站110和ue 120的数据和程序代码。调度器246可调度ue以进行下行链路和/或上行链路上的数据传输。
59.在一些方面,ue 120或基站110可包括用于接收的装置、用于报告的装置、用于传送的装置、用于编群的装置、和/或用于调度的装置。此类装置可包括结合图2所描述的ue 120或基站110的一个或多个组件。
60.如以上所指示的,图2仅仅是作为示例来提供的。其他示例可以不同于关于图2所描述的示例。
61.在一些情形中,支持不同类型的应用和/或服务的不同类型的设备可以共存于蜂窝小区中。不同类型的设备的示例包括ue手持机、客户端装备(cpe)、交通工具、物联网(iot)设备等等。不同类型的应用的示例包括超可靠低等待时间通信(urllc)应用、大规模机器类型通信(mmtc)应用、增强型移动宽带(embb)应用、车联网(v2x)应用等等。此外,在一些情形中,单个设备可同时支持不同的应用或服务。
62.图3解说了根据本公开的某些方面的片上系统(soc)300的示例实现,其可包括被配置成用于生成用于神经网络训练的梯度的中央处理单元(cpu)302或多核cpu。soc 300可被包括在基站110或ue 120中。变量(例如,神经信号和突触权重)、与计算设备(例如,带有权重的神经网络)相关联的系统参数、延迟、频率槽信息、以及任务信息可被存储在与神经处理单元(npu)308相关联的存储器块、与cpu 302相关联的存储器块、与图形处理单元(gpu)304相关联的存储器块、与数字信号处理器(dsp)306相关联的存储器块、存储器块318中,或可跨多个块分布。在cpu 302处执行的指令可从与cpu 302相关联的程序存储器加载或者可从存储器块318加载。
63.soc 300还可包括为具体功能定制的附加处理块,诸如gpu 304、dsp 306、连通性块310(其可包括第五代(5g)连通性、第四代长期演进(4g lte)连通性、wi-fi连通性、usb连通性、蓝牙连通性等)以及例如可检测和识别姿势的多媒体处理器312。在一种实现中,npu实现在cpu、dsp、和/或gpu中。soc 300还可包括传感器处理器314、图像信号处理器(isp)316、和/或导航模块320(其可包括全球定位系统)。
64.soc 300可基于arm指令集。在本公开的各方面,被加载到通用处理器302中的指令可包括用于从基站接收机器学习模型的代码。通用处理器302还可包括用于向基站报告机器学习处理能力的代码。通用处理器302可进一步包括用于向基站传送对机器学习模型的梯度更新或权重更新的代码。在本公开的其他方面,被加载到通用处理器302中的指令可包括:用于向多个用户装备(ue)传送机器学习模型的代码;以及用于从每个ue接收机器学习处理能力报告的代码。被加载到通用处理器302中的指令还可包括用于根据机器学习处理能力报告来对各ue编群以用于接收对机器学习模型的梯度更新的代码。
65.深度学习架构可通过学习在每一层中以逐次更高的抽象程度来表示输入、藉此构建输入数据的有用特征表示来执行对象识别任务。以此方式,深度学习解决了传统机器学习的主要瓶颈。在深度学习出现之前,用于对象识别问题的机器学习办法可能严重依赖人类工程设计的特征,或许与浅分类器相结合。浅分类器可以是两类线性分类器,例如,其中可将特征向量分量的加权和与阈值作比较以预测输入属于哪一类。人类工程设计的特征可
以是由拥有领域专业知识的工程师针对具体问题领域定制的模版或内核。相比之下,深度学习架构可学习以表示与人类工程师可能会设计的相似的特征,但它是通过训练来学习的。此外,深度网络可以学习以表示和识别人类可能还没有考虑过的新类型的特征。
66.深度学习架构可以学习特征阶层。例如,如果向第一层呈递视觉数据,则第一层可学习以识别输入流中的相对简单的特征(诸如边)。在另一示例中,如果向第一层呈递听觉数据,则第一层可学习以识别特定频率中的频谱功率。取第一层的输出作为输入的第二层可以学习以识别特征组合,诸如对于视觉数据识别简单形状或对于听觉数据识别声音组合。例如,更高层可学习以表示视觉数据中的复杂形状或听觉数据中的词语。再高层可学习以识别常见视觉对象或口述短语。
67.深度学习架构在被应用于具有自然阶层结构的问题时可能表现特别好。例如,机动交通工具的分类可受益于首先学习以识别轮子、挡风玻璃、以及其他特征。这些特征可在更高层以不同方式被组合以识别轿车、卡车和飞机。
68.神经网络可被设计成具有各种连通性模式。在前馈网络中,信息从较低层被传递到较高层,其中给定层中的每个神经元向更高层中的神经元进行传达。如上所述,可在前馈网络的相继层中构建阶层式表示。神经网络还可具有回流或反馈(也被称为自顶向下(top-down))连接。在回流连接中,来自给定层中的神经元的输出可被传达给相同层中的另一神经元。回流架构可有助于识别跨越不止一个按顺序递送给该神经网络的输入数据组块的模式。从给定层中的神经元到较低层中的神经元的连接被称为反馈(或自顶向下)连接。当高层级概念的识别可辅助辨别输入的特定低层级特征时,具有许多反馈连接的网络可能是有助益的。
69.神经网络的各层之间的连接可以是全连通的或局部连通的。图4a解说了全连通神经网络402的示例。在全连通神经网络402中,第一层中的神经元可将它的输出传达给第二层中的每个神经元,从而第二层中的每个神经元将从第一层中的每个神经元接收输入。图4b解说了局部连通神经网络404的示例。在局部连通神经网络404中,第一层中的神经元可连接到第二层中有限数目的神经元。更一般化地,局部连通神经网络404的局部连通层可被配置成使得一层中的每个神经元将具有相同或相似的连通性模式,但其连接强度可具有不同的值(例如,410、412、414和416)。局部连通的连通性模式可能在更高层中产生空间上相异的感受野,这是由于给定区域中的更高层神经元可接收到通过训练被调谐为到网络的总输入的受限部分的性质的输入。
70.局部连通神经网络的一个示例是卷积神经网络。图4c解说了卷积神经网络406的示例。卷积神经网络406可被配置成使得与针对第二层中每个神经元的输入相关联的连接强度被共享(例如,408)。卷积神经网络可能非常适合于其中输入的空间位置有意义的问题。
71.一种类型的卷积神经网络是深度卷积网络(dcn)。图4d解说了被设计成从自图像捕获设备430(诸如车载相机)输入的图像426识别视觉特征的dcn 400的详细示例。可对当前示例的dcn 400进行训练以标识交通标志以及在交通标志上提供的数字。当然,dcn 400可被训练用于其他任务,诸如标识车道标记或标识交通信号灯。
72.可以用受监督式学习来训练dcn 400。在训练期间,可向dcn 400呈递图像(诸如限速标志的图像426),并且随后可计算“前向传递(forward pass)”以产生输出422。dcn 400
可包括特征提取区段和分类区段。在接收到图像426之际,卷积层432可向图像426应用卷积核(未示出),以生成第一组特征图418。作为示例,卷积层432的卷积核可以是生成28x28特征图的5x5内核。在本示例中,由于在第一组特征图418中生成四个不同的特征图,因此在卷积层432处四个不同的卷积核被应用于图像426。卷积核还可被称为过滤器或卷积过滤器。
73.第一组特征图418可由最大池化层(未示出)进行子采样以生成第二组特征图420。最大池化层减小了第一组特征图418的大小。即,第二组特征图420的大小(诸如14x14)小于第一组特征图418的大小(诸如28x28)。减小的大小向后续层提供类似的信息,同时降低存储器消耗。第二组特征图420可经由一个或多个后续卷积层(未示出)被进一步卷积,以生成后续的一组或多组特征图(未示出)。
74.在图4d的示例中,第二组特征图420被卷积以生成第一特征向量424。此外,第一特征向量424被进一步卷积以生成第二特征向量428。第二特征向量428的每个特征可包括与图像426的可能特征(诸如,“标志”、“60”和“100”)相对应的数字。softmax(软最大化)函数(未示出)可将第二特征向量428中的数字转换为概率。如此,dcn 400的输出422是图像426包括一个或多个特征的概率。
75.在本示例中,输出422中关于“标志”和“60”的概率高于输出422的其他特征(诸如“30”、“40”、“50”、“70”、“80”、“90”和“100”)的概率。在训练之前,由dcn 400产生的输出422很可能是不正确的。由此,可计算输出422与目标输出之间的误差。目标输出是图像426的真值(例如,“标志”和“60”)。dcn 400的权重可随后被调整以使得dcn 400的输出422与目标输出更紧密地对齐。
76.为了调整权重,学习算法可为权重计算梯度向量。该梯度可指示在权重被调整情况下误差将增加或减少的量。在顶层,该梯度可直接对应于连接倒数第二层中的活化神经元与输出层中的神经元的权重的值。在较低层中,该梯度可取决于权重的值以及所计算出的较高层的误差梯度。权重可随后被调整以减小误差。这种调整权重的方式可被称为“反向传播”,因为其涉及在神经网络中的“反向传递(backward pass)”。
77.在实践中,权重的误差梯度可能是在少量示例上计算的,从而计算出的梯度近似于真实误差梯度。这种近似方法可被称为随机梯度下降法。随机梯度下降法可被重复,直到整个系统可达成的误差率已停止下降或直到误差率已达到目标水平。在学习之后,可向dcn呈递新图像(例如,图像426的限速标志)并且通过网络前向传递可产生输出422,其可被认为是该dcn的推断或预测。
78.深度置信网络(dbn)是包括多层隐藏节点的概率性模型。dbn可被用于提取训练数据集的阶层式表示。dbn可通过堆叠多层受限波尔兹曼机(rbm)来获得。rbm是一类可在输入集上学习概率分布的人工神经网络。由于rbm可在没有关于每个输入应该被分类到哪个类的信息的情况下学习概率分布,因此rbm经常被用在无监督式学习中。使用混合无监督式和受监督式范式,dbn的底部rbm可按无监督方式被训练并且可以用作特征提取器,而顶部rbm可按受监督方式(在来自先前层的输入和目标类的联合分布上)被训练并且可用作分类器。
79.深度卷积网络(dcn)是卷积网络的网络,其配置有附加的池化和归一化层。dcn已在许多任务上达成现有最先进的性能。dcn可以使用受监督式学习来训练,其中输入和输出目标两者对于许多典范是已知的并被用于通过使用梯度下降法来修改网络的权重。
80.dcn可以是前馈网络。另外,如上所述,从dcn的第一层中的神经元到下一更高层中
的神经元群的连接跨第一层中的各神经元被共享。dcn的前馈和共享连接可被用于进行快速处理。dcn的计算负担可比例如类似大小的包括回流或反馈连接的神经网络的计算负担小得多。
81.卷积网络的每一层的处理可被认为是空间不变模版或基础投影。如果输入首先被分解成多个通道,诸如彩色图像的红色、绿色和蓝色通道,则在该输入上训练的卷积网络可被认为是三维的,其具有沿着该图像的轴的两个空间维度以及捕获颜色信息的第三维度。卷积连接的输出可被认为在后续层中形成特征图,该特征图(例如,220)中的每个元素从先前层(例如,特征图218)中一定范围的神经元以及从该多个通道中的每个通道接收输入。特征图中的值可以用非线性(诸如矫正,max(0,x))进一步处理。来自毗邻神经元的值可被进一步池化(这对应于降采样)并可提供附加的局部不变性以及维度缩减。还可通过特征图中神经元之间的侧向抑制来应用归一化,其对应于白化。
82.深度学习架构的性能可随着有更多被标记的数据点变为可用或随着计算能力提高而提高。现代深度神经网络用比仅仅十五年前可供典型研究者使用的计算资源多数千倍的计算资源来例行地训练。新的架构和训练范式可进一步推升深度学习的性能。经矫正的线性单元可减少被称为梯度消失的训练问题。新的训练技术可减少过度拟合(over-fitting)并因此使更大的模型能够达成更好的普遍化。封装技术可抽象出给定的感受野中的数据并进一步提升总体性能。
83.图5是解说深度卷积网络550的框图。深度卷积网络550可包括多个基于连通性和权重共享的不同类型的层。如图5中所示,深度卷积网络550包括卷积块554a、554b。卷积块554a、554b中的每一者可配置有卷积层(conv)356、归一化层(lnorm)558、和最大池化层(max pool)560。
84.卷积层556可包括一个或多个卷积过滤器,其可被应用于输入数据以生成特征图。尽管仅示出了两个卷积块554a、554b,但本公开不限于此,而是代之以根据设计偏好可将任何数目的卷积块554a、554b包括在深度卷积网络550中。归一化层558可对卷积过滤器的输出进行归一化。例如,归一化层558可提供白化或侧向抑制。最大池化层560可提供在空间上的降采样聚集以实现局部不变性以及维度缩减。
85.例如,深度卷积网络的并行过滤器组可被加载到soc 300的cpu 302或gpu 304上以达成高性能和低功耗。在替换实施例中,并行过滤器组可被加载到soc 300的dsp 306或isp 316上。另外,深度卷积网络550可访问其他可存在于soc 300上的处理块,诸如分别专用于传感器和导航的传感器处理器314和导航模块320。
86.深度卷积网络550还可包括一个或多个全连通层562(fc1和fc2)。深度卷积网络550可进一步包括逻辑回归(lr)层564。深度卷积网络550的每一层556、558、560、562、564之间是要被更新的权重(未示出)。每一层(例如,556、558、560、562、564)的输出可以用作深度卷积网络550中一后续层(例如,556、558、560、562、564)的输入以从第一卷积块554a处供应的输入数据552(例如,图像、音频、视频、传感器数据和/或其他输入数据)学习阶层式特征表示。深度卷积网络550的输出是针对输入数据552的分类得分566。分类得分566可以是概率集,其中每个概率是输入数据包括来自特征集的特征的概率。
87.如以上所指示的,图3-图5是作为示例来提供的。其他示例可以不同于关于图3-图5所描述的示例。
88.如上文提及的,标准机器学习办法将训练数据集中于一台机器上或数据中心中。相比之下,联合学习是其中一群ue从基站接收机器学习模型并共同工作以训练该模型的过程。更具体而言,每个ue在本地训练模型,并根据例如在本地执行的随机梯度下降过程来发送回经更新的神经网络模型权重或梯度更新。基站从该群中的所有ue接收更新,并例如通过平均化这些更新来聚集更新以获得神经网络的经更新全局权重。基站向各ue发送经更新模型,并且该过程一轮接一轮地重复,直至获得全局模型的期望性能水平。
89.在联合学习过程的每一轮中,一群ue在这些ue从基站接收模型之后的给定时间区间内发送回权重或梯度更新。如果ue错过了发送更新的最终期限,则权重或梯度将变得陈旧,并且基站针对联合学习过程的该轮次将不会将更新纳入权重或梯度聚集中。
90.根据本公开的各方面,ue向基站报告其机器学习处理能力。在一些方面,该报告可指示机器学习硬件能力。在其他方面,该报告指示用于在每一轮联合学习中计算梯度或权重更新的近似周转时间。在本公开的另外其他方面,ue报告例如因变于该ue的电池状态的、用于计算梯度或权重的近似周转时间。
91.图6是解说根据本公开的各方面的联合学习系统600的框图。在一些配置中,基站610(例如,gnb)与参与联合学习过程的一群用户装备(ue)620(例如,620a、620b、620c)共享全局联合学习模型630。在这些配置中,模型参数由联合学习系统600优化。模型参数w
(n)
表示全局联合学习模型630的偏置和权重,g
(n)
表示梯度估计,其中n是联合学习轮次索引。初始模型参数被指定为w
(0)
。
92.在这些配置中,各ue 620均包括本地数据集640(例如,640a、640b、640c)、梯度计算块624、以及梯度压缩块622。在该示例中,第二ue 620b的梯度计算块624被配置成通过分散随机梯度下降法(sgd)来执行本地更新。每个ue 620执行某种类型的训练迭代,诸如单个随机梯度下降步骤或如式(1)中所见的多个随机梯度下降步骤:
[0093][0094]
其中fk(w
(n)
)表示用于第n轮联合学习的权重w的本地损失函数,并且g
k(n)
表示用于第n轮联合学习的本地梯度。
[0095]
在ue 620已完成本地更新之后,梯度压缩块622可如式(2)中所见地压缩经计算梯度向量以获得经压缩值(例如,632a、632b、632c),其中q()表示压缩函数:
[0096][0097]
ue 620向基站610反馈所计算的经压缩梯度向量(例如,632a、632b、632c)。该联合学习过程包括在该过程的每一轮中将所计算的经压缩梯度向量632(例如,632a、632b、632c)从所有ue 620传输至基站610。
[0098]
在这些配置中,基站610包括梯度平均化块612,其被配置成平均化所计算的经压缩梯度向量632。虽然示出了平均化,但还可构想其他类型的聚集。另外,模型更新块614被配置成更新全局联合学习模型630的参数。经更新模型随后被发送给所有ue 620。该过程重复直至满足全局联合学习准确性规范(例如,直至全局联合学习算法收敛)。准确性规范可以指本地训练的期望准确性水平。例如,准确性规范可指示联合学习过程的每次迭
代中的本地训练损失应当降至低于阈值。
[0099]
该全局联合学习算法基于如式(3)中所见的本地损失函数fk(w):
[0100][0101]
其中xj表示模型的输入向量,yj表示模型的输出标量,w是全局联合学习模型的权重向量,并且dk表示第k个ue处的数据集大小。例如,输入可以是向量化图像,并且输出可以是检测到的数字(例如,单个标量)。
[0102]
该全局联合学习算法还基于如式(4)中所见的全局损失函数f(w)(假定|dk|=d):
[0103][0104]
该联合学习过程的总体目标是要获得神经网络的使全局损失函数f(w)最小化的最优参数w*:
[0105]
w*=argmin f(w).
ꢀꢀꢀꢀ
(5)
[0106]
在该联合学习过程中,所计算的经压缩梯度向量632的本地计算(例如,用于更新全局联合学习模型630)是从各ue 620收集的,并且平均值由梯度平均化块612(或另一类型的聚集估计)计算如下:
[0107][0108]
基于该平均梯度g
)n)
,经更新的模型参数从基站610传送(例如,广播)到各ue 620。另外,基站610的模型更新块614执行如式(6)中所见的模型更新:
[0109]w(n+1)
=w
(n)-η.g
(n)
,(6)其中η表示学习率,这是全局联合学习模型630的参数。
[0110]
在联合学习过程的每一轮中,一群ue在这些ue从基站接收模型之后的给定时间区间内发送回权重或梯度更新。在一种配置中,该群大小是十到二十个ue。如果ue错过了发送更新的最终期限,则权重或梯度将变得陈旧,并且基站在联合学习过程的该轮次中将不会纳入来自该ue的梯度更新。
[0111]
如果基站知晓参与联合学习过程的ue的机器学习能力,则该信息对于基站会是有用的。例如,基站可根据机器学习能力来对各ue编群以用于不同的联合学习轮次。如果较慢ue与较快ue编群在一起,则较慢ue将是训练规程的瓶颈,从而不利地影响联合学习过程的收敛时间。由此,较慢ue可以与其他较慢ue编群在一起,而快速ue与其他快速ue编群在一起。此外,针对联合学习训练过程的不同轮次可以将不同ue配对在一起。
[0112]
根据本公开的各方面,ue向基站报告其机器学习处理能力。该机器学习处理能力报告可以具有标准化格式。例如,该报告可被添加到3gpp ts 38.306中定义的ue能力报告。该标准化格式可指示ue的机器学习硬件能力,诸如gpu、npu等的能力。
[0113]
在本公开的各方面,该报告按机器学习硬件能力的标准度量的形式来指示该机器学习硬件能力。例如,该报告可指示每秒运算次数或每秒乘累加(mac)运算次数等等。这些度量是ue的基本硬件特性并且不会随时间变化。
[0114]
硬件特性可反映最佳场景。由此,该报告可指示制造商规格,诸如每秒万亿次运算(top/s)或每秒万亿次乘累加运算(tmac/s)。制造商指定的硬件能力可能更接近真实世界性能。
[0115]
在任何情况下,所报告的机器学习硬件能力向基站提供了ue侧的近似训练时间,以便准备梯度或权重更新。例如,基站可基于所报告的机器学习硬件能力来决定报告方ue是快速ue还是慢速ue。基站可根据速度范围来调度ue。例如,具有第一处理能力范围的ue可被包括在第一群中,而具有第二处理能力范围的ue可被包括在第二群中。在一些实现中,处理能力可以是机器学习处理能力。
[0116]
在本公开的其他方面,该报告指示用于在每一轮联合学习中计算梯度或权重更新的近似或估计周转时间。该报告可指示例如经量化时间或近似时间。
[0117]
周转时间因变于ue的机器学习硬件能力。周转时间还因变于参数,诸如所采用的联合学习过程的类型或与特定联合学习过程相关联的应用。周转时间可以因变于其他参数,诸如机器学习模型的期望准确性水平和/或所训练的机器学习模型的实际类型。影响周转时间的其他参数包括本地训练的学习率、和/或在推导出并发送更新之前需要的迭代(例如,随机梯度下降迭代)的次数。
[0118]
用于ue处的本地训练的批量大小也会影响周转时间。例如,较小批量的训练数据与较大批量的训练数据相比花费较少的时间来处理。注意,较小的批量大小增加迭代次数。
[0119]
根据本公开的各方面,基站可将ue配置成具有用于特定联合学习过程的上述参数。ue随后可以使用这些参数的知识来评估用于计算权重或梯度更新的时间量,并报告(近似)周转时间。对于该选项,只要上述参数对于给定联合学习过程是固定的,ue就抑制发送经更新报告。当参数被重配置时,ue发送经更新报告。
[0120]
在本公开的其他方面,ue报告例如因变于该ue的电池状态的、用于计算梯度或权重的近似周转时间。例如,如果ue处于功率节省模式,则ue可决定不参与联合学习。缺乏参与可例如通过将周转时间设置为无穷大来实现。在其他方面,周转时间可被设置为较大值。
[0121]
注意,报告机器学习硬件能力可以不如报告周转时间那么动态。此外,报告因变于电池状态的周转时间比报告更一般的周转时间更加动态。
[0122]
图7是解说根据本公开的各方面的报告机器学习能力的时序图。在时间t1,基站610从第一ue 620a接收机器学习(ml)能力报告。在时间t2,基站610从第二ue 620b接收机器学习(ml)能力报告。在时间t3,基站610从第三ue 620c接收机器学习(ml)能力报告。机器学习能力报告可以指示机器学习硬件能力或机器学习周转时间,如先前所描述的。
[0123]
基于所接收的机器学习能力报告,基站610在时间t4对各ue 620编群并在时间t5根据编群来调度各ue 620。在该示例中,第一ue 620a和第三ue 620c作为较快ue被编群在一起。第二ue 620b在其自己的群中。相应地,在时间t6,第一ue 620a和第三ue 620c发送其对机器学习(ml)模型的更新。这些更新在传输之前在每个ue 620本地计算,并且将针对每一轮联合学习在基站610处被聚集。在时间t7,第二ue 620b向ue发送其更新以被包括在该轮联合学习中。由于对ue 620的编群,较慢ue针对其联合学习更新轮次可能不会错过最终期限。相应地,基站考虑更完整的更新集合并且可以更迅速和准确地训练模型。
[0124]
图8是解说根据本公开的各个方面的例如由ue执行的示例过程800的流程图。示例过程800是用于机器学习应用的用户装备(ue)能力报告的示例。
[0125]
如图8中所示,在一些方面,过程800可包括从基站接收机器学习模型(框802)。例如,ue(例如,使用天线252、demod/mod 254、mimo检测器256、接收处理器258、控制器/处理器280、和/或存储器282)可以接收机器学习模型。该机器学习模型可在联合学习过程中被
训练。
[0126]
过程800还可包括向该基站报告机器学习处理能力(框804)。例如,ue(例如,使用天线252、demod/mod 254、tx mimo处理器266、发射处理器264、控制器/处理器280、和/或存储器282)可以向该基站报告机器学习处理能力。在本公开的一些方面,该报告可指示机器学习硬件能力。在其他方面,该报告指示用于在每一轮联合学习中计算梯度或权重更新的近似周转时间。在另外其他方面,ue报告例如因变于该ue的电池状态的、用于计算梯度或权重的近似周转时间。该机器学习处理能力报告可以具有标准化格式。
[0127]
过程800可进一步包括向该基站传送对该机器学习模型的梯度更新或权重更新(框806)。例如,ue(例如,使用天线252、demod/mod 254、tx mimo处理器266、发射处理器264、控制器/处理器280、和/或存储器282)可以向该基站传送梯度更新或权重更新。这些更新可作为联合学习过程的一部分在本地进行计算。
[0128]
图9是解说根据本公开的各个方面的例如由基站执行的示例过程900的流程图。示例过程900是用于机器学习应用的用户装备(ue)能力报告的示例。
[0129]
如图9中所示,在一些方面,过程900可包括向数个用户装备(ue)传送机器学习模型(框902)。例如,基站(例如,使用天线234、mod/demod 232、tx mimo处理器230、发射处理器220、控制器/处理器240、和/或存储器242)可以传送机器学习模型。该机器学习模型可在联合学习过程中被训练。
[0130]
过程900可包括从该数个ue中的每个ue接收机器学习处理能力报告(框904)。例如,基站(例如,使用天线234、mod/demod 232、mimo检测器236、接收处理器238、控制器/处理器240、和/或存储器242)可以从该数个ue中的每个ue接收机器学习处理能力报告。在本公开的一些方面,该报告可指示机器学习硬件能力。在其他方面,该报告指示用于在每一轮联合学习中计算梯度或权重更新的近似周转时间。在另外其他方面,ue报告例如因变于该ue的电池状态的、用于计算梯度或权重的近似周转时间。该机器学习处理能力报告可以具有标准化格式。
[0131]
过程900可进一步包括根据机器学习处理能力报告来对各ue编群以用于接收对该机器学习模型的梯度更新(框906)。例如,基站(例如,使用天线234、mod/demod 232、mimo检测器236、tx mimo处理器230、接收处理器238、发射处理器220、控制器/处理器240、和/或存储器242)可以对该数个ue编群。例如,基站可基于所报告的机器学习硬件能力来决定报告方ue是快速ue还是慢速ue。基站可根据速度范围来调度ue。一组较高速度ue可被编群在一起,而一组较低速度ue可被编群在一起。
[0132]
示例方面
[0133]
方面1:一种由用户装备(ue)进行无线通信的方法,包括:从基站接收机器学习模型;向该基站报告机器学习处理能力;以及向该基站传送对该机器学习模型的梯度更新或权重更新。
[0134]
方面2:如方面1的方法,其中,该机器学习处理能力包括机器学习硬件能力。
[0135]
方面3:如方面1或2的方法,其中,该机器学习硬件能力包括制造商指定的硬件能力。
[0136]
方面4:如前述方面中任一者的方法,其中,该机器学习处理能力包括用于计算梯度的经估计周转时间。
[0137]
方面5:如前述方面中任一者的方法,其中,该经估计周转时间基于联合学习过程、联合学习应用、本地训练的期望准确性水平、该机器学习模型的类型、本地训练轮数、被配置用于ue训练的批量大小、和/或本地训练的学习率。
[0138]
方面6:如前述方面中任一者的方法,进一步包括:从该基站接收针对联合学习过程、联合学习应用、期望准确性水平、机器学习模型的类型、本地训练轮数、批量大小、和/或学习率的参数。
[0139]
方面7:如前述方面中任一者的方法,进一步包括:响应于至少一个参数发生变化而报告经更新的机器学习处理能力。
[0140]
方面8:如前述方面中任一者的方法,其中,该经估计周转时间基于该ue的电池状态。
[0141]
方面9:如前述方面中任一者的方法,其中,该经估计周转时间响应于该ue在功率节省模式中操作而被设置为无穷大。
[0142]
方面10:一种由基站进行无线通信的方法,包括:向多个用户装备(ue)传送机器学习模型;从该多个ue中的每个ue接收机器学习处理能力报告;以及根据来自该多个ue中的每个ue的机器学习处理能力报告来对该多个ue编群以用于接收对该机器学习模型的梯度更新。
[0143]
方面11:如方面10的方法,其中,该编群进一步包括:将具有第一处理能力的ue调度成用于在第一时间段中传送梯度更新并将具有第二处理能力的ue调度成用于在第二时间段中传送梯度更新。
[0144]
方面12:一种用于由用户装备(ue)进行无线通信的装置,包括:处理器;与该处理器耦合的存储器;以及指令,这些指令存储在该存储器中并且在由该处理器执行时能操作用于使得该装置:从基站接收机器学习模型;向该基站报告机器学习处理能力;以及向该基站传送对该机器学习模型的梯度更新或权重更新。
[0145]
方面13:如方面12的装置,其中,该机器学习处理能力包括机器学习硬件能力。
[0146]
方面14:如方面12或13的装置,其中,该机器学习硬件能力包括制造商指定的硬件能力。
[0147]
方面15:如方面12-14中任一者的装置,其中,该机器学习处理能力包括用于计算梯度的经估计周转时间。
[0148]
方面16:如方面12-15中任一者的装置,其中,该经估计周转时间基于联合学习过程、联合学习应用、本地训练的期望准确性水平、机器学习模型的类型、本地训练轮数、被配置用于ue训练的批量大小、和/或本地训练的学习率。
[0149]
方面17:如方面12-16中任一者的装置,其中,该处理器使得该装置从该基站接收针对联合学习过程、联合学习应用、期望准确性水平、机器学习模型的类型、本地训练轮数、批量大小、和/或学习率的参数。
[0150]
方面18:如方面12-17中任一者的装置,其中,该处理器使得该装置响应于至少一个参数发生变化而报告经更新的机器学习处理能力。
[0151]
方面19:如方面12-18中任一者的装置,其中,该经估计周转时间基于该ue的电池状态。
[0152]
方面20:如方面12-19中任一者的装置,其中,该经估计周转时间响应于该ue在功
c、c-c、和c-c-c,或者a、b和c的任何其他排序)。
[0167]
所使用的元素、动作或指令不应被解释为关键或必要的,除非被明确描述为这样。而且,如所使用的,冠词“一”和“某一”旨在包括一个或多个项目,并且可以与“一个或多个”互换地使用。此外,如所使用的,术语“集(集合)”和“群”旨在包括一个或多个项目(例如,相关项、非相关项、相关和非相关项的组合等),并且可以与“一个或多个”可互换地使用。在旨在仅有一个项目的场合,使用短语“仅一个”或类似语言。而且,如所使用的,术语“具有”、“含有”、“包含”等旨在是开放性术语。此外,短语“基于”旨在意指“至少部分地基于”,除非另外明确陈述。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1