分布式数据处理方法、电子设备、可读存储介质及产品与流程
本技术涉及分布式系统,更具体地,涉及一种分布式数据处理方法、一种电子设备、一种计算机可读存储介质以及一种计算机程序产品。
背景技术:
1、数据倾斜是指分布式系统在执行大数据任务过程中,某些节点(或包括多个节点的分区)处理的数据,显著高于其他节点,从而使得这些节点的处理速度低于平均的处理速度,拖慢整个任务的执行过程。进一步地,若倾斜数据超过节点本身设置的内存上限,还会使该节点宕掉,甚至出现分布式数据系统崩溃的情况。
2、此外,随着分布式系统技术的发展,日益增长的海量数据还进一步加剧了上述数据倾斜的问题。
3、常规的处理方法通常为在分布式系统发生数据倾斜后,通过例如web ui(websiteuser interface,网络产品界面设计)主动查看当前运行的阶段中各个任务分配的数据量以及确认已发生数据倾斜的节点位置。
4、因而,上述常规的处理方法无法预先判断可能发生数据倾斜的节点,并规避可能诱发数据倾斜的数据问题。
技术实现思路
1、本技术至少一个实施方式提供了一种可至少部分解决相关技术中存在的上述问题的分布式数据处理方法、电子设备、计算机可读存储介质和计算机程序产品。
2、根据本技术至少一个实施方式提供的分布式数据处理方法、电子设备、计算机可读存储介质和计算机程序产品,通过对流经待测集群中各节点的数据添加其所流经节点的标识和流经上述节点的时间,实现了通过较为便捷的方式,实时统计待测集群中各节点的工作量(可理解为节点的数据负荷情况)。
3、在本技术至少一个实施方式中,基于诸如斜率法、cox-stuart检验法等待测集群的数据分析策略以及实时统计待测集群中各节点的工作量,不仅可预先判断待测集群中可能发生数据倾斜的节点,并可根据的预测工作量分析结果规避可能诱发数据倾斜的数据问题。
4、此外,在本技术至少一个实施方式中,通过将节点所在终端的主机名作为数据的流经节点标识,可准确、便捷地确定待测集群中每个节点的工作量,极大地提高了预先判断可能发生数据倾斜的节点的效率。
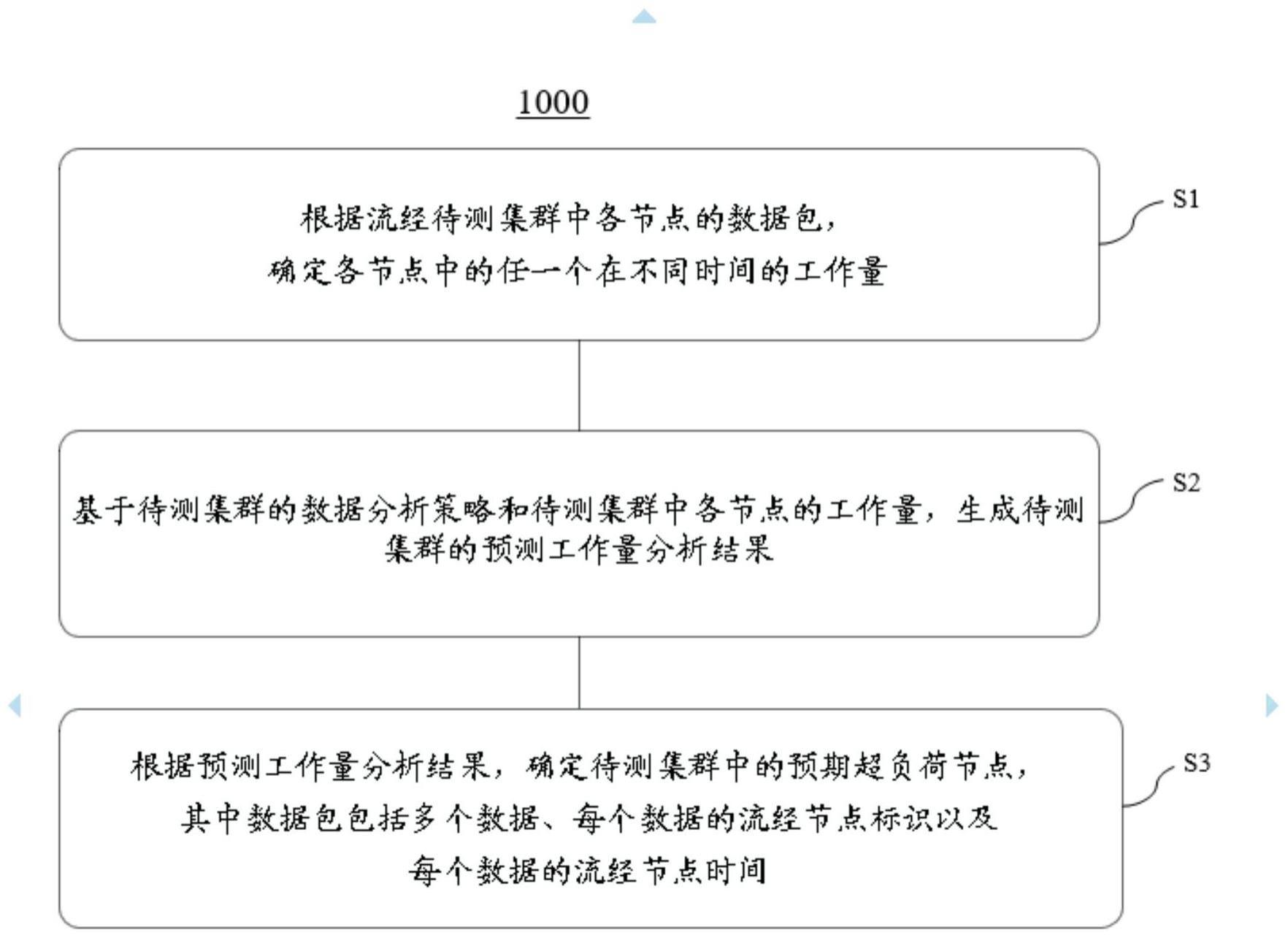
5、具体地,本技术一方面提供了一种分布式数据处理方法,所述方法包括:根据流经待测集群中各节点的数据包,确定所述各节点中的任一个在不同时间的工作量;基于所述待测集群的数据分析策略和所述待测集群中所述各节点的工作量,生成所述待测集群的预测工作量分析结果;以及根据所述预测工作量分析结果,确定所述待测集群中的预期超负荷节点,其中,所述数据包包括多个数据、每个所述数据的流经节点标识以及每个所述数据的流经节点时间。
6、在本技术一个实施方式中,基于所述待测集群的数据分析策略和所述待测集群中所述各节点的所述工作量,生成所述待测集群的预测工作量分析结果包括:将所述各节点中的任一个在不同时间的所述工作量,按照时间顺序排列,以形成所述各节点中的任一个的时序数据集;基于所述数据分析策略处理所述时序数据集,以获得所述各节点中的任一个的工作量变化趋势;以及将所述待测集群中所述各节点的工作量变化趋势汇总,以获得所述预测工作量分析结果。
7、在本技术一个实施方式中,基于所述数据分析策略处理所述时序数据集,以获得所述各节点中的任一个的工作量变化趋势包括:对所述时序数据集中各数据进行线性拟合,以获得与所述时序数据集对应的节点的工作量变化趋势,其中所述各数据为已按照时间顺序排列的、与所述时序数据集对应的节点在不同时间的所述工作量。
8、在本技术一个实施方式中,对所述时序数据集中各数据进行线性拟合,以获得与所述时序数据集对应的节点的工作量变化趋势包括:计算线性拟合曲线的斜率值;以及通过所述斜率值,确定与所述时序数据集对应的节点的工作量变化趋势,其中,如果所述斜率值大于零,则确定与所述时序数据集对应的节点的所述工作量变化趋势为上升趋势;以及如果所述斜率值小于零,则确定与所述时序数据集对应的节点的所述工作量变化趋势为下降趋势。
9、在本技术一个实施方式中,对所述时序数据集中各数值进行线性拟合包括:采用最小二乘法对所述时序数据集中各数值进行线性拟合。
10、在本技术一个实施方式中,基于所述数据分析策略处理所述时序数据集,以获得所述各节点中的任一个的工作量变化趋势包括:将所述时序数据集中具有预定间隔的两个数据设置为一个数据组,并比较所述数据组中两个数据的大小,其中所述两个数据为已按照时间顺序排列的、与所述时序数据集对应的节点在不同时间的所述工作量;以及将所述时序数据集中各数据组的比较结果汇总,以获得与所述时序数据集对应的节点的工作量变化趋势。
11、在本技术一个实施方式中,将所述时序数据集中各数据组的比较结果汇总,以获得与所述时序数据集对应的节点的工作量变化趋势包括:将排序在前的数据大于排序在后的数据的数据组的比较结果设置为负,并将排序在前的数据小于排序在后的数据的数据组的比较结果设置为正;将所述时序数据集中各数据组的比较结果汇总,并通过比较结果为正的数据组的第一数量和比较结果为负的数据组的第二数量,确定与所述时序数据集对应的节点的工作量变化趋势,其中,如果所述第一数量大于所述第二数量,则确定与所述时序数据集对应的节点的所述工作量变化趋势为上升趋势;以及如果所述第一数量小于所述第二数量,则确定与所述时序数据集对应的节点的所述工作量变化趋势为下降趋势。
12、在本技术一个实施方式中,将所述时序数据集中具有预定间隔的两个数据设置为一个数据组,并比较所述数据组中两个数据的大小包括:采用cox-stuart趋势验证法,将所述时序数据集中具有预定间隔的两个数据设置为一个数据组,并比较所述数据组中两个数据的大小。
13、在本技术一个实施方式中,根据所述预测工作量分析结果,确定所述待测集群中的预期超负荷节点包括:在所述待测集群中节点的工作量变化趋势大于预定阈值时,确定所述节点为所述预期超负荷节点。
14、根据流经待测集群中各节点的数据包,确定所述各节点中的任一个在不同时间的工作量包括:
15、在本技术一个实施方式中,根据流经待测集群中各节点的数据包,确定所述各节点中的任一个在不同时间的工作量包括:在流经第一节点的数据中添加与所述第一节点对应的流经节点标识和与所述第一节点对应的流经节点时间,其中所述第一节点为所述各节点中的任一个;以及确定在第一时间与所述第一节点对应的流经节点标识的数量,并将其作为所述第一节点在所述第一时间的工作量,其中所述第一时间为任一个与所述第一节点对应的流经节点时间。
16、在本技术一个实施方式中,所述数据的流经节点标识为所述节点所在终端的主机名。
17、在本技术一个实施方式中,所述数据的流经节点时间为设置于所述节点的实时流程序接收所述数据时对应的时间戳。
18、本技术另一方面提供了一种电子设备,其包括至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如本技术一方面提供的任一项分布式数据处理方法。
19、本技术又一方面提供了存储有计算机指令的非瞬时计算机可读存储介质,所述计算机指令用于使所述计算机执行如本技术一方面提供的任一项分布式数据处理方法。
20、本技术又一方面提供了一种计算机程序产品,包括计算机程序,所述计算机程序在被处理器执行时实现如本技术一方面提供的任一项分布式数据处理方法。
- 还没有人留言评论。精彩留言会获得点赞!