一种基于模型解释的规则式应用流量分类方法及系统与流程
1.本发明涉及使用模型解释方法生成特征匹配规则,以近似替代深度学习技术对混杂的应用流量进行自动分类,具体涉及一种基于模型解释的规则式应用流量分类方法及系统。
背景技术:
2.应用流量分类是将应用流量与其生成的具体应用协议或应用相关联的过程,其在网络安全与计算机网络等应用领域都有着重要应用,如网络服务质量(qos)提升、入侵检测和防御等。具体而言,在网络管理中,为了获得更好的网络服务质量和网络供应,网络运营商首先需要将流量分为不同的应用或者应用协议。另外,在网络安全领域中,应用流量分类是如异常检测,构建网络防火墙和过滤有害流量等活动的第一步。由于这种应用需求,该领域的研究吸引着众多学术界和工业界的研究关注。值得注意的是,大多数商业解决方案通常都依赖深度数据报文检查(dpi)进行应用流量分类,同时dpi也被认为是最准确的流量分类技术之一。在过去的十年中,研究团体探索了多种基于数据报文中有效负载的应用流量分析方法。近年来,受到深度学习技术在计算机视觉、机器翻译和语音识别等多个领域取得巨大成功的推动,一些研究人员开始考虑使用先进的深度学习技术来尝试更好地解决应用流量分类问题。但如何保证经过训练后深度学习模型所利用的特征符合应用流量先验知识、并将深度学习技术成果应用于大规模网络中进行实时应用流量分类等诸多问题,一直是深度学习技术在应用流量分类中面临的挑战。本专利将以深度学习模型与应用流量训练数据作为输入将模型转化为应用流量特征分类规则集,在尽可能保持分类准确率与原深度学习模型一致的情况下实现低计算开销、高准确率的应用流量分类。
3.在应用流量分类领域,深度学习模型的应用,有效解决了机器学习方法在特征设计阶段对专家知识的依赖,从而使应用流量中潜在的特征信息更有效地服务于应用流量分类应用。然而,现有的基于深度神经网络的应用流量分类方法与系统在实际应用过程中存在着两点局限性:
4.(1)深度学习模型计算开销高,不适用于海量应用流量实时分类的应用场景。深度学习模型需要构建起输入数据与目标结果之间的关联关系,但输入数据与目标结果之间的关联关系通常难以直接判断,因此深度学习模型往往需要使用大量的可学习参数、设计复杂的模型结构以实现高准确率的分类。然而,应用流量的实时分类场景对分类效率要求较高,部署深度学习分类方案需要新增大量计算资源,难以负担海量应用流量分类需求。
5.(2)深度学习模型进行分类的判断依据及其可信度都难以直观展现,因而难以应用于有高可靠性要求的场景。深度学习模型的分类过程封装在复杂的模型结构和大量的模型参数之中,使得直接分析深度学习模型推理过程难以实现,因此难以判断深度学习模型的推理是否基于有效的特征、结果是否可靠且具备泛用性。
6.本专利拟解决此前方法或系统存在的两点技术缺陷。
技术实现要素:
7.本发明的目的在于设计并实现一种基于模型解释的规则式应用流量分类方法及系统,使得其在应用流量分类过程中,可以在保证分类准确率与使用深度学习模型进行分类的准确率相近的同时,达到与使用规则匹配的分类方法相近的计算开销及效率,从而实现高准确率、高效率的应用流量分类。
8.为实现上述目的,本发明采用的技术方案如下:
9.所述构建阶段包括如下步骤:
10.1)以已知所属类型的应用流量为输入,将每条应用流量转换为指定格式的应用流量字节序列;
11.2)以深度学习模型与步骤1)得到的应用流量字节序列作为输入,使用应用流量字节序列作为训练数据集,采用有监督学习的方式,对深度学习模型的进行训练;
12.3)以步骤1)得到的应用流量字节序列和步骤2)得到的已训练的深度学习模型为输入,对模型进行解释,得到应用流量字节序列中各个特征对深度学习模型分类的贡献度向量;
13.4)基于3)得到的分类贡献度向量集合,进行可选的模型有效性分析,并生成分类规则集;
14.所述分类阶段包括如下步骤:
15.5)以待测应用流量为输入,将待测应用流量处理为具有与步骤1)相同格式的应用流量字节序列;
16.6)根据构建阶段中步骤4)得到的分类规则集,对待分类的应用流量进行规则匹配,并输出判别结果。
17.一种基于模型解释的规则式应用流量分类系统,包括用于构建阶段的应用流量处理模块、深度学习模型训练模块、流量特征分类贡献度分析模块、模型有效性分析模块、规则构建模块,以及用于分类阶段的应用流量接入与处理模块、规则匹配模块。其中:
18.应用流量处理模块负责将输入的应用流量以流为单位处理成字节序列,并转换为指定格式的应用流量字节序列,作为训练样本;
19.深度学习模型训练模块负责使用训练样本对给定的深度学习模型进行模型训练,直至模型分类结果满足训练终止条件;
20.流量特征分类贡献度分析模块负责使用训练样本对训练后的深度学习模型进行分析,得到流量特征的分类贡献度;
21.模型有效性分析模块为可选模块,负责基于流量特征的分类贡献度判断深度学习模型对训练样本关键特征的选择的有效性;
22.规则构建模块负责基于流量特征的分类贡献度,对特征分类贡献度向量进行筛选与处理,得到分类规则集;
23.应用流量接入与处理模块负责接入分类阶段的待分类应用流量,并将其处理为与构建阶段的应用流量处理模块相同的指定格式,得到待分类应用流量字节序列;
24.规则匹配模块基于构建阶段得到的分类规则集对待分类应用流量字节序列进行策略规则匹配,确定待分类流量所属的规则,输出判别结果,并将不属于已知类别的新类别应用流量留存,作为后续系统更新的样本使用。
25.本发明的关键技术点在于:
26.1.本发明设计了一种面向网络协议的、模型无关的深度学习模型解释方法,本方法根据应用流量的网络层和传输层首部高度格式化、而传输层载荷遵循的协议更为多样的特点,在进行基于样本的模型解释中,将格式化部分与传输层载荷分别处理,实现更适于网络协议问题的模型解释方法。同时,无需分析深度模型内部设计,即可将深度学习模型从训练样本中学习得到的分类能力,以样本中各个特征对分类结果的贡献度的方式表征,适用于所有应用应用流量分类相关的深度学习模型。
27.2.本发明基于面向网络协议的深度学习模型解释,提出了由模型解释结果生成应用流量分类规则集的方法。本方法以模型解释结果为基础,对模型解释的每条结果进行基于特征贡献度的关键特征筛选,扩大规则覆盖范围;对特征贡献度进行数值平滑,避免个别规则出现极端值,确保不同分类规则之间具有可比较性。由本方法生成的应用流量分类规则由关键特征和特征对应的贡献度组成,具有通用性高、不同类别规则彼此兼容的特点。
28.3.本发明基于应用流量分类规则集,设计了带权规则匹配的应用流量分类方法。本方法以待测应用流量样本与分类规则在规则特征上取值是否一致为依据,计算待测样本在该规则下的特征贡献度之和作为匹配权重,从而判定待测样本所属分类。应用流量分类规则集可以在无需部署深度学习模型的情况下,实现高效而精准的应用流量分类。
29.利用本专利的方法可以实现在无需部署深度学习分类模型的情况下,实现对混杂应用流量的精准分类。与已公开的相关技术相比,具有如下优点:
30.1.本专利设计了一种面向网络协议的、模型无关的模型解释方法。无需分析深度学习模型的内部结构,将深度学习模型通过模型解释、特征筛选等过程转换为由关键特征及其分类贡献度组成的应用流量分类规则集,从而将深度学习模型从训练数据中学习到的知识转换为量化的特征贡献度,以便于对模型训练结果的有效性进行分析。本专利同时设计了配套的规则匹配策略,充分利用应用流量分类规则集,在无需部署深度学习模型的情况下,达到与深度学习模型近似的分类准确率,实现高效、精准应用流量分类。
31.2.本专利在分类阶段仅依赖应用流的原始特征信息,无需其他先验知识,对于面向连接、面向无连接、明文、加密、文本、二进制等各种形式的应用协议,都可以选择具备相应处理能力的深度学习模型生成分类规则,具有较强的普适性。
附图说明
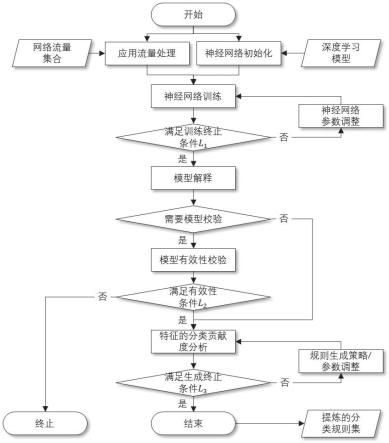
32.图1是基于模型解释的规则式应用流量分类方法的构建阶段流程图。
33.图2是基于模型解释的规则式应用流量分类方法构建阶段的特征分类贡献度生成流程图。
34.图3是基于模型解释的规则式应用流量分类方法的分类阶段流程图。
35.图4是基于模型解释的规则式应用流量分类系统架构图。
36.图5是参数n=100时,26种应用协议在验证集上的实验结果图。
37.图6是参数n=150时,26种应用协议在验证集上的实验结果图。
38.图7是参数n=200时,26种应用协议在验证集上的实验结果图。
39.图8是参数n=250时,26种应用协议在验证集上的实验结果图。
40.图9是参数n=500时,26种应用协议在验证集上的实验结果图。
41.图10是参数n=750时,26种应用协议在验证集上的实验结果图。
42.图11是参数n=1000时,26种应用协议在验证集上的实验结果图。
具体实施方式
43.本方法的工作流程,可分为构建阶段和分类阶段。在构建阶段,将根据已知类别的应用流量,训练深度学习模型,并将模型得到的有效分类知识提炼为分类规则,从而实现高准确率、高效率的分类。分类阶段,基于提炼得到的分类规则集,对网络环境中获取到的真实应用流量进行特征匹配并判断应用流量所属的应用类型。
44.构建阶段:本方法的关键技术部分在于应用流量分类规则集的构建,应用流量分类规则集的构建流程如图1所示。应用流量分类模型构建过程的输入是已知类型的应用流量的集合以及预定义的深度学习模型结构,应用流量经过预处理后成为符合深度学习模型输入要求的数据格式。应用流量分类模型构建过程的输出为由训练后的深度学习模型中提炼得到的应用流量分类规则集。
45.本方法基于预训练的深度学习模型进行特征分类贡献度生成的过程如图2所示,其具体实施步骤如下:
46.1.应用流量处理模块,给定已知应用协议类型的应用流量样本集合,将集合中每条应用流flowi预处理为满足深度学习模型输入要求的应用流量字节序列fi,得到应用流量字节序列集合f={f1,f2,
…
,fi,
…
,fm}。特别地,本方法需要定义一个特殊元素nan,以表示应用流量字节序列fi中某个位置置为空值,需要在数据处理时预留出该特殊元素的数据表征空间。具体来说,对于每条应用流flowi,其应用流量字节序列表示为fi={f
i1
,f
i2
,
…
,f
in
},任意应用流量字节序列fi的字节序列长度都统一为n,序列中字节顺序有意义,字节在序列中的次序称为位置,字节及其在序列中的位置称为特征。以应用流flowi的网络层报文为分析对象,设该报文实际的总长度为ni。若ni≥n,则取应用流flowi的前n个字节,后续字节截断丢弃,每个字节构成应用流量字节序列fi中的一个特征;若应用流flowi的网络层字节长度ni《n,则构成的应用流量字节序列fi中,第ni个特征之后的n-ni个特征置为空值,即个特征置为空值,即
47.2.模型初始化模块,本方法不关注该模型内部模型结构、不限定所使用的深度学习模型具体设计,仅需保证深度学习模型的输入数据为符合应用流量处理模块的应用流量字节序列,设置模型训练所使用的超参数,并初始化深度学习模型中的可训练参数,为神经网络构建阶段做准备。
48.3.神经网络训练模块,使用已知类型的应用流量字节序列集合,对初始化后的深度学习模型进行迭代训练,定期判断深度学习模型是否满足模型训练终止条件。如未满足终止条件要求,则对深度学习模型参数进行调整(如反向传播等),或调整深度学习模型的超参数设置,并继续进行一轮训练;重复上述过程直至模型训练效果满足终止条件要求。终止条件要求可以为达到指定的分类准确率、达到指定的分类召回率等。
49.4.模型解释模块,本方法分析深度学习模型在进行类别判断时,应用流量字节序列中各特征对深度学习模型进行类别判断的贡献度。贡献度的具体计算方法如下:
50.(1)首先,以已知类别的应用流量字节序列集合f为输入,对于f中任一序列fi=
{f
i1
,f
i2
,
…
,f
in
}(fi长度为n),生成p个伪样本fi'中任一伪样本'中任一伪样本中选取qj个特征置为空值nan,其余特征取值与fi相同,qj∈[0,n]。伪样本中置为空值的特征数量qj的确定方式,包括但不限于随机选取、基于概率分布的选取等方式;中置为空值nan的特定特征的确定方式,包括但不限于随机选取、基于概率分布生成的等方法。在伪样本中置为空值的特征,采用应用流量处理模块定义的空值元素nan表示。
[0051]
(2)其次,使用算法计算生成的伪样本与真实样本fi之间的相似性,评估真伪样本间相似性的算法包括但不限于余弦算法、欧氏距离、jaccard距离等各类距离算法。
[0052]
为清楚说明本方法所使用的距离计算方法,需要定义特征出现向量,表示伪样本与真实样本间特征的对应关系。以序列f={f1,f2,..,fn}为基准,某序列f'={f'1,f'2,
…
,fn'}中任意特征取值范围为f'i∈{nan,fi}(i∈[1,n]),即fi'的取值可能性仅有两种,要么为空值nan、要么为基准序列f中与fi'处于同一序列位置的特征值fi。则f'以序列f={f1,f2,..,fn}为基准的特征出现向量a'={a1',a2',
…
,an'}中任意元素ai'(i∈[1,n])取值范围如下:
[0053][0054]
假设以真实样本fi={f
i1
,f
i2
,
…
,f
in
}为基准,则fi自身的特征出现向量为伪样本样本的特征出现向量为样本fi中ip层首部和运输层首部对应的特征总长度为n',n'≤n。由于fi中各个特征均未置空,因此是由n个1组成的向量,任意伪样本中,存在qj个特征置为nan,因此中,存在qj个元素为0,其余n-qj个元素为1。
[0055]
以应用流量的网络层首部和传输层首部为首部区(特征总长度为n')、以传输层载荷即高层协议数据为载荷区(特征总长度为n-n'),将应用流量字节序列真实样本fi的特征出现向量划分为首部特征出现向量和载荷特征出现向量将应用流量字节序列伪样本的特征出现向量划分为首部特征出现向量和载荷特征出现向量以余弦距离函数为例,计算真实样本fi与伪样本的距离如下:
[0056][0057]
[0058][0059]
(3)同时,将应用流量字节序列fi与对应的伪样本集合输入已在神经网络训练模块完成训练、可应用模型解释方法的深度学习模型,得到伪样本分类向量集合量集合设待解释的深度学习模型可分类的应用流量类别数为k种、应用流量字节序列fi的真实类别为ki,该深度学习模型对应用流量字节序列fi进行分类得到的分类向量为ci={c1,c2,
…
,ck},fi在真实类别上取得的分类值为该深度学习模型对fi的伪样本进行分类得到的分类向量为伪样本在fi的真实类别上取得的分类值为fi的伪样本集合f'i所得的对应分类值向量为其中任意
[0060]
(4)以应用流量伪样本集合与真实应用流量字节序列fi的差异度集合伪样本集合f'i对应的特征出现向量集合为伪样本集合f'i的分类向量集合作为输入,使用拟合算法计算真实应用流量字节序列fi中各个特征对深度学习模型输出的样本分类向量的贡献程度,得到应用流量字节序列对应的特征分类贡献度向量。拟合算法的种类包括但不限于lasso回归、算法岭回归、回归树、无偏差的单层感知机等其他回归类算法或其他自定义的能解决回归类问题的算法。以lasso回归算法为例,对于应用流量字节序列fi,设回归算法的拟合参数向量为wi={w
i1
,w
i2
,
…
,w
in
},以di为参数对wi进行初始化,求解方程a'i×
wi=c'i,求解所得wi即为应用流量字节序列fi的特征贡献度向量。
[0061]
5.模型有效性校验模块,本阶段为可选流程,结合各个特征在网络协议格式中的定义,判断深度学习模型在分类时贡献度较高的应用流量字节序列特征,是否可以与已知的通用网络协议格式对应。以特征分类贡献度向量为输入,选取部分贡献度较高的特征,还原其在对应的应用流量协议格式语义。如果应用流量字节序列所生成的特征贡献度向量中,贡献度较高的特征不能与已知的通用网络协议格式对应,则认为该样本的模型解释结果无效。若神经网络模型的模型解释集合没有达到设定有效性条件,则判定该深度学习模型对该应用流量样本没有生成有效的模型解释,不予生成对应规则;若神经网络模型的模型解释满足设定的有效性条件,则判定该样本的模型解释得到的特征分类贡献度向量集合可以用于应用流量分类规则生成。最终,将所有有效的应用流量样本特征分类贡献度向量集合输入到特征分类贡献度分析模块。
[0062]
6.特征分类贡献度分析模块,对于应用流量样本fi={f
i1
,f
i2
,
…
,f
in
},以模型解释模块得到的特征分类贡献度向量wi={w
i1
,w
i2
,
…
,w
in
}为输入,根据网络协议格式定义与分类系统实际需要,对特征分类贡献度向量及向量中特征进行筛选,最后由保留的特征分类贡献度向量形成提炼的流量分类规则集。对特征分类贡献度向量筛选方法包括但不限于:(1)设定贡献度取值阈值或取值范围,仅保留贡献度满足取值范围的特征及其贡献度;
(2)设定规则特征数量上限,选取特征贡献度绝对值靠前的特征及其贡献度等。不符合保留规则的特征f
ij
取值置为nan、对应贡献度w
ij
置为0。
[0063]
对于经过筛选的特征分类贡献度向量中保留下来的特征(即所有非空值nan的特征),对其特征贡献度进行数值平滑处理,避免贡献度中的部分极端值对分类结果造成干扰。对分类贡献度进行处理的方式包括但不限于标准化、归一化及其他自定义算法。本方法采用的数值平滑处理算法如下,对于应用流量字节序列fi={f
i1
,f
i2
,
…
,f
in
}的特征贡献度向量wi={w
i1
,w
i2
,
…
,w
in
},设其平滑后的特征贡献度向量为w'i={w'
i1
,w'
i2
,
…
,w'
in
},则有:
[0064][0065]
任意应用流量字节序列fi={f
i1
,f
i2
,
…
,f
in
}及其平滑后的特征分类贡献度向量w'i={w'
i1
,w'
i2
,
…
,w'
in
}中,所有序列特征取值与其对应特征贡献度组成数值对ri={(f
i1
,w'
i1
),(f
i2
,w'
i2
),
…
,(f
in
,w'
in
)},即为提炼的应用流量分类规则,全部分类规则构成提炼的应用流量分类规则集。
[0066]
分类阶段:以构建阶段得到的提炼的应用流量分类规则集为基础,判断输入的待分类应用流量是否为分类规则集中已知类型的应用流量,并给出分类结果。分类阶段的工作流程如图3所示。
[0067]
1.应用流量处理模块,对于待分类的应用流量,将其转换为与构建阶段预设的深度学习模型要求的输入一致的序列,记为具体处理过程与构建阶段应用流量处理模块一致,不在此赘述。
[0068]
2.规则匹配模块,以构建阶段生成的应用流量分类规则集为输入,以特定的匹配策略基于规则集判定待测应用流量字节序列所属类别。具体的匹配策略可根据分类规则集表征形式、应用流量字节序列表征形式以及其他条件及需求设计。以本方法实验中采用的匹配策略为例,对匹配过程进行介绍,实际匹配策略不限于下文所述方式。
[0069]
(1)首先,将待测的应用流量字节序列与规则集r={r1,r2,
…
,r
l
}中每条规则进行比对。设应用流量字节序列与任意规则rj={(f
j1
,w'
j1
),(f
j2
,w'
j2
),
…
,(f
jn
,w'
jn
)}(j∈[1,l])的生效位权重总值为w
ij
,从序列和规则rj起始位置开始逐位比对特征取值,若应用流量字节序列中第q位特征取值与规则rj中第q位特征取值一致,则认为规则中该位为生效位。其中,应用流量字节序列和规则rj中置空为nan的特征位不关注,不计入生效位。当待测应用流量字节序列或规则rj二者任一达到序列末尾时,终止匹配。应用流量字节序列与规则集r中每条规则匹配,得到全体规则的生效位的数量ci、生效位在规则全长中所占比例si、生效位的贡献度之和ti。
[0070][0071]
(2)待测应用流量与规则集中每条规则rj均进行上述匹配,得到所有规则在待测应用流量字节序列下的生效位数量向量ci、生效位在所属规则内所占比例向量si、生效位总贡献度向量ti,基于ci、si、ti进行待测应用流量所匹配的规则的选取。选取命中规则的具体操作如算法2所示:首先,选取生效位在规则中比例最高的规则,形成第一级候选规则集i;其次,在第一级候选规则集i中,选取生效位数量最大的规则,形成第二级候选规则集i';最后,选取第二级候选规则集中生效位总贡献度最高的规则,形成命中规则集i”。命中规则集i”中,命中规则对应的应用流量类别,即为待测应用流量的分类结果;若命中规则集i”为空集,则认为待测应用流量字节序列不属于已知类别,判定为未知类型的应用流量。
[0072][0073][0074]
(3)根据上述规则匹配的结果,将待分类的应用流量所属类别提供给后续外部应用使用。对于未知类别的新应用流量、以及外部应用反馈为分类错误的应用流量,将通过人
工校验等方式,确定其所属的真实类别,并将这些应用流量留存,作为后续分类系统更新的增量样本。
[0075]
当新增未知类别的应用流量数量达到分析系统更新要求,或需要定期对系统进行整体更新时,可将增量样本按需更新进已知类型应用流量样本集合,重复离线构建阶段流程,并将新构建的规则集更新至分类阶段。系统整体更新的过程中,也可以对用于生成规则的深度学习模型进行局部调整或整体更换,以保证更新后流量分类规则集能够满足分类阶段的使用需求。
[0076]
结合上述基于规则式模型解释的应用流量分类方法,本专利同时公开了一种基于模型解释的规则式应用流量分类系统。本系统主要由构建阶段和分类阶段两个阶段构成,系统图架构如图4所示。
[0077]
1.构建阶段:首先,将已知应用流量输入(1)应用流量处理模块,将其转换为与深度学习模型要求的输入数据相匹配的数据组织形式,形成已知类别的训练样本。随后,(2)深度学习模型训练模块使用已知类别的训练样本,完成给定的深度学习模型的训练,使之达到目标分类要求。以已知类别的训练样本和完成训练的深度学习模型为输入,(3)特征分类贡献度分析模块基于各个训练样本,对深度学习模型进行分类判断时各个特征对该分类结果的贡献度加以量化,得到各个训练样本中,各位特征对应的分类贡献度。若有必要,可选择在(4)模型有效性分析模块根据训练样本中各个特征的分类贡献度,判断深度学习模型是否自动学习到了符合应用流量行为或网络协议语义的特征信息。最后,在(5)规则构建模块,根据各个训练样本中不同特征的分类贡献度,进行特征筛选,生成提炼的应用流量分类规则集,提供给后续分类阶段使用。
[0078]
2.分类阶段:首先,(6)应用流量接入与处理模块与待分类应用流量对接,将其转换为与(1)应用流量处理模块中相同的数据组织形式,形成待分类应用流量样本。随后,(7)规则匹配模块根据离线构建阶段生成的应用流量分类规则集,基于一定策略,对待分类样本进行规则匹配,判定待分类的应用流量所属的类别,并将分类结果提供给后续外部应用使用。最后,可以根据系统使用情况,对系统进行定期或不定期的更新。若出现新应用类别的应用流量,或有分类错误的应用流量,则可以将其更新到应用流量训练样本中,重新训练深度学习模型并生成应用流量分类规则集。系统更新时,也可以对采用的深度学习模型进行调整或更换,从而保证生成的应用流量分类规则集能够满足分类性能需求。
[0079]
表格1:实验验证中所使用的应用协议名称及各个类别的网络流个数,其中k代表103。
[0080]
在验证实验中,本专利对apple tv、blink camera、blink security hub、echo dot、echo plus、echo spot、fire tv、google home mini、insteon hub、osram lightify hub、migichome strip、nest thermostat、ring doorbell共计26种类型的应用流量开展实例验证。实验中所使用的具体应用流量信息如表1所示。为保证样本数量均衡,对于每个流量类别,随机地选择了3,000个样本,流个数不足3,000的应用协议类别则保留全部样本。最终得到共计40,912
[0081]
应用类型流个数应用类型流个数apple tv0.91kroku tv1.63kblink camera0.79ksamsung tv7.92k
blink security hub48sengled hub0.09kecho dot0.92ksmartthings hub6.50kecho plus2.7kanova sousvide0.09kecho spot4.6kphilips hub12.9kfire tv1.16kwemo plug8.18kgoogle home mini0.78ktp-link bulb4.46kinsteon hub0.93ktp-link plug1.90kosram lightify hub0.35kwansview camera6.47kmigichome strip0.36kxiaomi cleaner0.04knest thermostat5.35kxiaomi hub0.17kring doorbell1.06kyi camera5.26k
[0082]
个实验样本。此外,在实验数据集上开展了5折交叉验证,其中训练集,验证集和测试集的比例为3:1:1,训练集包含24,546个实验样本,验证集包含8,184个实验样本,测试集包含8,182个实验样本。
[0083]
验证实验展示了在两种超参数下深度学习模型解释所产生的规则集的分类效果,超参数包括:(1)进行模型解释时,为每条真样本生成的伪样本数量(以p表示);(2)生成规则集时,保留的特征数量(以k表示,按分类贡献度绝对值从大到小排序)。在不同超参数设置的情况下分别进行实验,本专利所解释的深度学习模型为现有工作,模型为bsnn(byte segment neural network);最终生成的规则集包含24,546条应用分类规则。
[0084]
首先,定义实验分析指标如下:
[0085]
(1)类别t的真阳值,由tp
t
表示:该值是一组样本的个数,其中每个样本由应用流量分类器报告为属于类别t,并且确实是属于相应的类别t。
[0086]
(2)类别t的真阳率,tpr
t
,其具体的定义如下:
[0087][0088]
(3)多类别分类准确性指标acc,定义如下:
[0089][0090]
其中t代表总的分类类别数。
[0091]
基于模型解释的规则式应用流量分类方法与系统在26种不同类型设备产生的数据下的实验结果如图5至图11所示。
[0092]
在验证实验的构建阶段,本发明使用验证集来定量评估不同深度学习模型的分类性能,并基于在验证集上取得最优acc的深度学习模型,使用训练集的数据生成分类规则集。实验的参数设置上,模型解释时每条真实样本生成的伪样本生成数量n取值范围为100、150、200、250、500、750、1000;生成规则集时保留的特征数量k的取值范围为8、16、20、32、48、64、96、128,即保留按特征贡献度绝对值从大到小排序的前k个特征。根据参数p和k的取值范围,共计得到56组实验结果;根据匹配到多种应用类别(含该样本真实类别t)的样本是否计入真阳值tp
t
,每组实验结果包含两类数据:(1)多匹配样本计入tp
t
的acc,(2)多匹配样
本不计入tp
t
的acc。多匹配样本计入tp
t
时,acc的取值范围为78.22%至95.56%,最高的acc值在p=500、k=48的参数设置下取得。多匹配样本不计入tp
t
时,acc的取值范围为63.42%至95.46%,最高的acc值在p=500、k=48的参数设置下取得。
[0093]
在验证实验中,基础深度学习模型bsnn经过训练后,在验证集上得到的平均acc为93.40%、在测试集上得到的平均acc为92.82%。实验结果证明,使用本方法得到的类均acc值与被解释的原始模型相近,在特定的参数设置下可以取得更高的分类准确率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1