支持多视图可适性的OLS的制作方法
支持多视图可适性的ols
1.本技术是分案申请,原申请的申请号是202080066116.9,原申请日是2020年9月18日,原申请的全部内容通过引用结合在本技术中。
2.相关申请的交叉引用
3.本专利申请要求王业奎于2019年9月24日递交、申请号为62/905,132、申请名称为“对支持多视图可适性的输出层集的指示”的美国临时专利申请的权益,其通过引用结合在本技术中。
技术领域
4.本发明通常涉及视频译码,具体地涉及在多层码流中配置输出层集(output layer set,ols),以支持多视图视频的空间可适性和信噪比(signal to noise,snr)可适性。
背景技术:
5.即使是相对较短的视频,也需要大量的视频数据来描述,这可能会导致数据在带宽容量受限的通信网络中进行流式传输或以其它方式传输时遇到困难。因此,视频数据通常需要先进行压缩,然后通过现代电信网络进行传输。由于内存资源可能有限,在存储设备中存储视频时,该视频的大小也可能是一个问题。视频压缩设备通常在源侧使用软件和/或硬件对该视频数据进行译码,然后进行传输或存储,从而减少用于表示数字视频图像所需的数据量。然后,对视频数据进行解码的视频解压缩设备在目的地侧接收压缩后的数据。在网络资源有限以及对更高视频质量的需求不断增长的情况下,需要改进压缩和解压缩技术,从而能够在几乎不影响图像质量的情况下提高压缩比。
技术实现要素:
6.在一个实施例中,本发明包括一种由解码器实现的方法。所述方法包括:所述解码器的接收器接收包括输出层集(output layer set,ols)和视频参数集(video parameter set,vps)的码流,其中,所述ols包括一层或多层编码图像,所述vps包括ols模式识别码(ols_mode_idc),表示对于每个ols,所述每个ols中的所有层均为输出层;所述解码器的处理器根据所述vps中的ols_mode_idc确定所述输出层;所述解码器的处理器对来自所述输出层的编码图像进行解码,以产生解码图像。
7.一些视频译码系统用于仅解码并输出由层id表示的最高编码层以及一个或多个被指示的较低层。由于解码器可能不希望解码最高层,因此这可能会在可适性方面带来问题。具体地,解码器通常请求解码器能够支持的最高层,但是解码器通常又无法解码高于被请求层的层。在一个特定的示例中,解码器可能希望接收和解码总编码层为15层中的第三层。该第三层可以在没有第4层到第15层的情况下被发送到解码器,因为不需要通过这些层来解码第三层。但是,解码器可能无法正确解码和显示该第三层,因为最高层(第15层)不存在,而且视频系统总是被指示要解码并显示该最高层。因此,在此类系统中尝试视频可适性
时会产生错误。因为解码器需要始终支持最高层,会导致系统无法根据不同的硬件和网络要求调整到中间层,所以这个问题很严重。使用多视图后,这个问题更加严重。在多视图中,将输出不止一层进行显示。例如,用户可以使用耳机,并且可以向每只眼睛显示不同的层,从而创建三维(three dimensional,3d)视频的印象。不支持可适性的系统也不支持多视图可适性。
8.本示例包括一种支持多视图可适性的机制。这些层包含在多个ols中。编码器可以发送包含这些层的ols,以调整到特定的特性,如大小或snr。进一步地,所述编码器可以,例如,在vps中传输ols_mode_idc语法元素。所述ols_mode_idc语法元素可以设置为1,表示支持多视图可适性。例如,所述ols_mode_idc可以表示ols的总数等于所述vps中指定的层的总数,表示第i个ols包括层0~层i(包括首尾值),并表示对于每个ols,所有层都被视为输出层。这样可以支持可适性,因为所述解码器可以接收并解码特定ols中的所有层。由于所有层均为输出层,因此所述解码器可以选择和渲染所需的输出层。这样,经编码的层的总数可能不会对解码过程产生影响,并且可以避免错误,同时仍然可以提供可适性多视图视频。因此,所公开的机制改进了编码器和/或解码器的功能。此外,所公开的机制还可以减小码流的大小,从而减少编码器侧和解码器侧对处理器、存储器和/或网络资源的使用。在一个特定实施例中,使用所述ols_mode_idc可以为包括共用很多数据的多个ols的多个编码码流节省比特,从而节省了流媒体服务器中的比特,并为传输此类码流节省带宽。例如,将所述ols_mode_idc设置为1的优点是支持多视图应用等的使用案例,其中,两个或多个视图(每个视图由一层表示)将同时输出并显示。
9.可选地,根据上述任一方面,在本方面的另一种实现方式中,所述ols_mode_idc表示所述vps指定的ols的总数等于所述vps指定的层数。
10.可选地,根据上述任一方面,在本方面的另一种实现方式中,所述ols_mode_idc表示第i个ols包括层索引为0~i(包括首尾值)的层。
11.可选地,根据上述任一方面,在本方面的另一种实现方式中,所述ols_mode_idc等于1。
12.可选地,根据上述任一方面,在本方面的另一种实现方式中,所述vps包括vps_max_layers_minus1(vps maximum layers minus one),表示所述vps指定的层数,其是参考所述vps的每个编码视频序列(coded video sequence,cvs)中允许的最大层数。
13.可选地,根据上述任一方面,在本方面的另一种实现方式中,当所述ols_mode_idc等于0时,或者当所述ols_mode_idc等于1时,所述ols的总数(totalnumolss)等于vps_max_layers_minus1+1。
14.可选地,根据上述任一方面,在本方面的另一种实现方式中,第i个ols中的层数(numlayersinols[i])和所述第i个ols中第j层的网络抽象层(network abstraction layer,nal)单元头层标识(nuh_layer_id)的值(layeridinols[i][j])推导如下:
[0015][0016][0017]
其中,vps_layer_id[i]为第i个vps层标识,totalnumolss为所述vps指定的ols的总数,each_layer_is_an_ols_flag(each layer is an ols flag)表示至少一个ols是否包括不止一层。
[0018]
在一个实施例中,本发明包括一种由编码器实现的方法。所述方法包括:编码器的处理器对包括一个或多个ols的码流进行编码,其中,所述一个或多个ols包括一层或多层编码图像;所述处理器将vps编码到所述码流中,其中,所述vps包括ols_mode_idc,表示对于每个ols,所述每个ols中的所有层均为输出层;耦合到所述处理器的存储器存储所述码流,以发送给解码器。
[0019]
一些视频译码系统用于仅解码并输出由层id表示的最高编码层以及一个或多个被指示的较低层。由于解码器可能不希望解码最高层,因此这可能会在可适性方面带来问题。具体地,解码器通常请求解码器能够支持的最高层,但是解码器通常又无法解码高于被请求层的层。在一个特定的示例中,解码器可能希望接收和解码总编码层为15层中的第三层。该第三层可以在没有第4层到第15层的情况下被发送到解码器,因为不需要通过这些层来解码第三层。但是,解码器可能无法正确解码和显示该第三层,因为最高层(第15层)不存在,而且视频系统总是被指示要解码并显示该最高层。因此,在此类系统中尝试视频可适性时会产生错误。因为解码器需要始终支持最高层,会导致系统无法根据不同的硬件和网络要求调整到中间层,所以这个问题很严重。使用多视图后,这个问题更加严重。在多视图中,将输出不止一层进行显示。例如,用户可以使用耳机,并且可以向每只眼睛显示不同的层,从而创建三维(three dimensional,3d)视频的印象。不支持可适性的系统也不支持多视图可适性。
[0020]
本示例包括一种支持多视图可适性的机制。这些层包含在多个ols中。编码器可以发送包含这些层的ols,以调整到特定的特性,如大小或snr。进一步地,所述编码器可以,例如,在vps中传输ols_mode_idc语法元素。所述ols_mode_idc语法元素可以设置为1,表示支持多视图可适性。例如,所述ols_mode_idc可以表示ols的总数等于所述vps中指定的层的总数,表示第i个ols包括层0~层i(包括首尾值),并表示对于每个ols,所有层都被视为输出层。这样可以支持可适性,因为所述解码器可以接收并解码特定ols中的所有层。由于所有层均为输出层,因此所述解码器可以选择和渲染所需的输出层。这样,经编码的层的总数可能不会对解码过程产生影响,并且可以避免错误,同时仍然可以提供可适性多视图视频。
因此,所公开的机制改进了编码器和/或解码器的功能。此外,所公开的机制还可以减小码流的大小,从而减少编码器侧和解码器侧对处理器、存储器和/或网络资源的使用。在一个特定实施例中,使用所述ols_mode_idc可以为包括共用很多数据的多个ols的多个编码码流节省比特,从而节省了流媒体服务器中的比特,并为传输此类码流节省带宽。例如,将所述ols_mode_idc设置为1的优点是支持多视图应用等的使用案例,其中,两个或多个视图(每个视图由一层表示)将同时输出并显示。
[0021]
可选地,根据上述任一方面,在本方面的另一种实现方式中,所述ols_mode_idc表示所述vps指定的ols的总数等于所述vps指定的层数。
[0022]
可选地,根据上述任一方面,在本方面的另一种实现方式中,所述ols_mode_idc表示第i个ols包括层索引为0~i(包括首尾值)的层。
[0023]
可选地,根据上述任一方面,在本方面的另一种实现方式中,所述ols_mode_idc等于1。
[0024]
可选地,根据上述任一方面,在本方面的另一种实现方式中,所述vps包括vps_max_layers_minus1,表示所述vps指定的层数,其是参考所述vps的每个cvs中允许的最大层数。
[0025]
可选地,根据上述任一方面,在本方面的另一种实现方式中,当所述ols_mode_idc等于0时,或者当所述ols_mode_idc等于1时,totalnumolss等于vps_max_layers_minus1+1。
[0026]
可选地,根据上述任一方面,在本方面的另一种实现方式中,numlayersinols[i]和layeridinols[i][j]推导如下:
[0027][0028]
其中,vps_layer_id[i]为第i个vps层标识,totalnumolss为所述vps指定的ols的总数,each_layer_is_an_ols_flag(each layer is an ols flag)表示至少一个ols是否包括不止一层。
[0029]
在一个实施例中,本发明包括一种视频译码设备。所述视频译码设备包括:处理器、耦合到所述处理器的接收器、耦合到所述处理器的存储器和耦合到所述处理器的发送器,其中,所述处理器、所述接收器、所述存储器和所述发送器用于执行上述任一方面所述的方法。
[0030]
在一个实施例中,本发明包括一种非瞬时性计算机可读介质。所述非瞬时性计算机可读介质包括供视频译码设备使用的计算机程序产品,其中,所述计算机程序产品包括
存储在所述非瞬时性计算机可读介质中的计算机可执行指令,当所述计算机可执行指令由处理器执行时,使得所述视频译码设备执行上述任一方面所述的方法。
[0031]
在一个实施例中,本发明包括一种解码器。所述解码器包括:接收模块,用于接收包括ols和vps的码流,其中,所述ols包括一层或多层编码图像,所述vps包括ols_mode_idc,表示对于每个ols,所述每个ols中的所有层均为输出层;确定模块,用于根据所述vps中的ols_mode_idc确定所述输出层;解码模块,用于对来自所述输出层的编码图像进行解码,以产生解码图像;转发模块,用于转发所述解码图像,以显示为解码视频序列的一部分。
[0032]
一些视频译码系统用于仅解码并输出由层id表示的最高编码层以及一个或多个被指示的较低层。由于解码器可能不希望解码最高层,因此这可能会在可适性方面带来问题。具体地,解码器通常请求解码器能够支持的最高层,但是解码器通常又无法解码高于被请求层的层。在一个特定的示例中,解码器可能希望接收和解码总编码层为15层中的第三层。该第三层可以在没有第4层到第15层的情况下被发送到解码器,因为不需要通过这些层来解码第三层。但是,解码器可能无法正确解码和显示该第三层,因为最高层(第15层)不存在,而且视频系统总是被指示要解码并显示该最高层。因此,在此类系统中尝试视频可适性时会产生错误。因为解码器需要始终支持最高层,会导致系统无法根据不同的硬件和网络要求调整到中间层,所以这个问题很严重。使用多视图后,这个问题更加严重。在多视图中,将输出不止一层进行显示。例如,用户可以使用耳机,并且可以向每只眼睛显示不同的层,从而创建三维(three dimensional,3d)视频的印象。不支持可适性的系统也不支持多视图可适性。
[0033]
本示例包括一种支持多视图可适性的机制。这些层包含在多个ols中。编码器可以发送包含这些层的ols,以调整到特定的特性,如大小或snr。进一步地,所述编码器可以,例如,在vps中传输ols_mode_idc语法元素。所述ols_mode_idc语法元素可以设置为1,表示支持多视图可适性。例如,所述ols_mode_idc可以表示ols的总数等于所述vps中指定的层的总数,表示第i个ols包括层0~层i(包括首尾值),并表示对于每个ols,所有层都被视为输出层。这样可以支持可适性,因为所述解码器可以接收并解码特定ols中的所有层。由于所有层均为输出层,因此所述解码器可以选择和渲染所需的输出层。这样,经编码的层的总数可能不会对解码过程产生影响,并且可以避免错误,同时仍然可以提供可适性多视图视频。因此,所公开的机制改进了编码器和/或解码器的功能。此外,所公开的机制还可以减小码流的大小,从而减少编码器侧和解码器侧对处理器、存储器和/或网络资源的使用。在一个特定实施例中,使用所述ols_mode_idc可以为包括共用很多数据的多个ols的多个编码码流节省比特,从而节省了流媒体服务器中的比特,并为传输此类码流节省带宽。例如,将所述ols_mode_idc设置为1的优点是支持多视图应用等的使用案例,其中,两个或多个视图(每个视图由一层表示)将同时输出并显示。
[0034]
可选地,根据上述任一方面,在本方面的另一种实现方式中,所述解码器还用于执行上述任一方面所述的方法。
[0035]
在一个实施例中,本发明包括一种编码器。所述编码器包括:编码模块,用于:对包括一个或多个ols的码流进行编码,其中,所述一个或多个ols包括一层或多层编码图像;将vps编码到所述码流中,其中,所述vps包括ols_mode_idc,表示对于每个ols,所述每个ols中的所有层均为输出层;存储模块,用于存储所述码流,以发送给解码器。
[0036]
一些视频译码系统用于仅解码并输出由层id表示的最高编码层以及一个或多个被指示的较低层。由于解码器可能不希望解码最高层,因此这可能会在可适性方面带来问题。具体地,解码器通常请求解码器能够支持的最高层,但是解码器通常又无法解码高于被请求层的层。在一个特定的示例中,解码器可能希望接收和解码总编码层为15层中的第三层。该第三层可以在没有第4层到第15层的情况下被发送到解码器,因为不需要通过这些层来解码第三层。但是,解码器可能无法正确解码和显示该第三层,因为最高层(第15层)不存在,而且视频系统总是被指示要解码并显示该最高层。因此,在此类系统中尝试视频可适性时会产生错误。因为解码器需要始终支持最高层,会导致系统无法根据不同的硬件和网络要求调整到中间层,所以这个问题很严重。使用多视图后,这个问题更加严重。在多视图中,将输出不止一层进行显示。例如,用户可以使用耳机,并且可以向每只眼睛显示不同的层,从而创建三维(three dimensional,3d)视频的印象。不支持可适性的系统也不支持多视图可适性。
[0037]
本示例包括一种支持多视图可适性的机制。这些层包含在多个ols中。编码器可以发送包含这些层的ols,以调整到特定的特性,如大小或snr。进一步地,所述编码器可以,例如,在vps中传输ols_mode_idc语法元素。所述ols_mode_idc语法元素可以设置为1,表示支持多视图可适性。例如,所述ols_mode_idc可以表示ols的总数等于所述vps中指定的层的总数,表示第i个ols包括层0~层i(包括首尾值),并表示对于每个ols,所有层都被视为输出层。这样可以支持可适性,因为所述解码器可以接收并解码特定ols中的所有层。由于所有层均为输出层,因此所述解码器可以选择和渲染所需的输出层。这样,经编码的层的总数可能不会对解码过程产生影响,并且可以避免错误,同时仍然可以提供可适性多视图视频。因此,所公开的机制改进了编码器和/或解码器的功能。此外,所公开的机制还可以减小码流的大小,从而减少编码器侧和解码器侧对处理器、存储器和/或网络资源的使用。在一个特定实施例中,使用ols_mode_idc可以为包括共用很多数据的多个ols的多个编码码流节省比特,从而节省了流媒体服务器中的比特,并为传输此类码流节省带宽。例如,将ols_mode_idc设置为1的优点是支持多视图应用等的使用案例,其中,两个或多个视图(每个视图由一层表示)将同时输出并显示。
[0038]
可选地,根据上述任一方面,在本方面的另一种实现方式中,所述编码器还用于执行上述任一方面所述的方法。
[0039]
为了清楚起见,任一上述实施例可以与上述其它任何一个或多个实施例组合,创建本发明范围内的新实施例。
[0040]
根据以下结合附图和权利要求书描述的具体实施方式,可以更清楚地理解这些特征及其它特征。
附图说明
[0041]
为了更全面地理解本发明,现在参考以下结合附图和具体实施方式而进行的简要描述,其中,相似的附图标记表示相同的部件。
[0042]
图1为一种对视频信号进行译码的示例性方法的流程图;
[0043]
图2为一种用于视频译码的示例性编码和解码(编解码,codec)系统的示意图;
[0044]
图3为一种示例性视频编码器的示意图;
[0045]
图4为一种示例性视频解码器的示意图;
[0046]
图5为一种用于层间预测的示例性多层视频序列的示意图;
[0047]
图6为一种包括为多视图可适性配置的ols的示例性视频序列的示意图;
[0048]
图7为一种包括为多视图可适性配置的ols的示例性码流的示意图;
[0049]
图8为一种示例性视频译码设备的示意图;
[0050]
图9为一种对包括为多视图可适性配置的ols的视频序列进行编码的示例性方法的流程图;
[0051]
图10为一种对包括为多视图可适性配置的ols的视频序列进行解码的示例性方法的流程图;
[0052]
图11为一种对包括为多视图可适性配置的ols的视频序列进行译码的示例性系统的示意图。
具体实施方式
[0053]
首先应当理解,尽管下文提供一个或多个实施例的说明性实现方式,但本发明所公开的系统和/或方法可以使用任何数量的技术来实现,无论这些技术是当前已知的技术还是现有的技术。本发明不应限于下文所说明的说明性实现方式、附图和技术,还应包括本文所说明并描述的示例性设计和实现方式,且可以在所附权利要求书的范围以及其等效部分的完整范围内进行修改。
[0054]
以下术语的定义如下所述,除非在本文相反的上下文中使用。具体地,以下定义旨在更加清晰地描述本发明。但是,术语在不同的上下文中可能会有不同的描述。因此,以下定义应当视为补充信息,而不应当视为对此处为这些术语提供的描述的任何其它定义进行限制。
[0055]
码流是包括视频数据的一系列比特,这些视频数据会进行压缩以在编码器和解码器之间传输。编码器(encoder)是一种利用编码过程将视频数据压缩到码流中的设备。解码器(decoder)是一种利用解码过程从码流中重建视频数据以进行显示的设备。图像是创建帧或其场的亮度样本和/或色度样本组成的阵列。为了论述清楚,正在编码或解码的图像可以称为当前图像。
[0056]
网络抽象层(network abstraction layer,nal)单元是一种语法结构,其包括原始字节序列载荷(raw byte sequence payload,rbsp)形式的数据和对数据的类型的指示,并根据需要穿插预防混淆字节。视频编码层(video coding layer,vcl)nal单元是经译码的nal单元,以包括视频数据,例如包括图像的译码条带(slice)。非vcl nal单元是包括非视频数据的nal单元,例如包括支持解码视频数据、一致性性能检查或其他操作的语法和/或参数。层是一组共用指定特性(例如,常用的分辨率、帧率、图像大小等)的vcl nal单元和一组关联的非vcl nal单元。某一层的vcl nal单元可以共用nal单元头层标识(nuh_layer_id)的特定值。编码图像是包括接入单元(access unit,au)内具有nal单元头层标识(nuh_layer_id)为特定值的vcl nal单元的图像的编码表示,其中,该图像还包括该图像的所有编码树单元(coding tree unit,ctu)。解码图像是通过对编码图像执行解码过程而产生的图像。编码视频序列(coded video sequence,cvs)是指一序列au,其按解码顺序包括一个或多个编码视频序列起始(coded video sequence start,cvss)au,且可选地还包括一个
不是cvss au的au。cvss au是包括视频参数集(video parameter set,vps)指定的每一层的预测单元(prediction unit,pu)的au,其中,每个pu中的编码图像是cvs/编码层视频序列(coded layer video sequence,clvs)的起始图像。
[0057]
输出层集(output layer set,ols)是一系列层,其中,该系列层中一个或多个层被指定为输出层。输出层是指定用于输出(例如,输出到显示器)的层。最高层是ols中的一层,其在该ols的所有层中具有最大的层标识(identifier,id)。在一些示例性ols模式中,最高层可以一直是输出层。在其他模式下,被指定的层和/或所有层均为输出层。视频参数集(video parameter set,vps)是一个数据单元,包括与整个视频相关的参数。层间预测是一种通过参考参考层中的参考图像对当前层中的当前图像进行编码的机制,其中,当前图像和参考图像包含在同一个au中,参考层包括的nuh_layer_id比当前层的小。
[0058]
ols模式识别码(ols_mode_idc)是一个语法元素,指示与ols的数量、所述ols中的层以及所述ols中的输出层相关的信息。vps_max_layers_minus1(vps maximum layers minus one)是一个语法元素,指示(signal)vps指定的层数,即指示对应的cvs中允许的最大层数。each_layer_is_an_ols_flag(each layer is an ols flag)是一个语法元素,指示是否码流中的每个ols都包括单个层。ols的总数(totalnumolss)是一个变量,表示所述vps指定的ols的总数。第i个ols中的层数(numlayersinols[i])是一个变量,表示由ols索引值i所表示的特定ols中的层数。ols中的层id(layeridinols[i][j])是一个变量,表示由层索引j和ols索引i所表示的第i个ols中第j层的nuh_layer_id值。vps_layer_id[i]是一个语法元素,表示第i层的层id。
[0059]
本文中使用了以下缩略语:编码树块(coding tree block,ctb)、编码树单元(coding tree unit,ctu)、编码单元(coding unit,cu)、编码视频序列(coded video sequence,cvs)、联合视频专家组(joint video experts team,jvet)、运动约束分块集(motion constrained tile set,mcts)、最大传输单元(maximum transfer unit,mtu)、网络抽象层(network abstraction layer,nal)、输出层集(output layer set,ols)、图像顺序编号(picture order count,poc)、原始字节序列载荷(raw byte sequence payload,rbsp)、序列参数集(sequence parameter set,sps)、视频参数集(video parameter set,vps)和通用视频编码(versatile video coding,vvc)。
[0060]
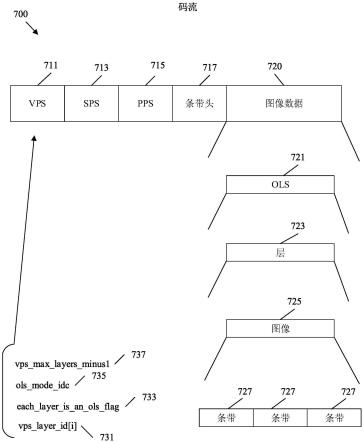
许多视频压缩技术可以用来减小视频文件的大小,同时最大限度地减少数据丢失。例如,视频压缩技术可以包括执行空间(例如,帧内)预测和/或时间(例如,帧间)预测来减少或去除视频序列中的数据冗余。对于基于块的视频译码,视频条带(例如,视频图像或视频图像的一部分)可以被分割成视频块,这些视频块还可以称为树块(treeblock)、编码树块(coding tree block,ctb)、编码树单元(coding tree unit,ctu)、编码单元(coding unit,cu)和/或译码节点(coding node)。图像中的经帧内译码(i)条带中的视频块是针对同一图像中的相邻块中的参考样本通过空间预测进行译码的,而图像中的经帧间译码的单向预测(p)或双向预测(b)条带中的视频块可以是针对同一图像中的相邻块中的参考样本通过空间预测进行译码的,也可以是针对其它参考图像中的参考样本通过时间预测进行译码的。图像(picture/image)可以称为帧(frame),参考图像(reference picture/image)可以称为参考帧。空间预测或时间预测会产生表示图像块的预测块。残差数据表示原始图像块与预测块之间的像素差。因此,经帧间译码块是根据运动矢量和残差数据进行编码的,其
中,运动矢量指向形成预测块的参考样本组成的块,残差数据表示编码块与预测块之间的差值。而经帧内译码块是根据帧内译码模式和残差数据进行编码的。为进行进一步压缩,残差数据可以从像素域变换到变换域,从而产生可以量化的残差变换系数。量化变换系数初始可以排列为二维阵列。量化变换系数可以扫描,以产生变换系数的一维矢量。熵编码可以用于实现进一步压缩。下文更详细地论述了这些视频压缩技术。
[0061]
为了确保经编码视频能够正确解码,视频根据对应的视频编码标准进行编码和解码。视频编码标准包括国际电信联盟(international telecommunication union,itu)标准化部门(itu standardization sector,itu-t)h.261、国际标准化组织/国际电工委员会(international organization for standardization/international electrotechnical commission,iso/iec)运动图像专家组(motion picture experts group,mpeg)-1第2部分、itu-t h.262或iso/iec mpeg-2第2部分、itu-t h.263、iso/iec mpeg-4第2部分、高级视频编码(advanced video coding,avc)(还称为itu-t h.264或iso/iec mpeg-4第10部分)以及高效视频编码(high efficiency video coding,hevc)(还称为itu-t h.265或mpeg-h第2部分)。avc包括可适性视频编码(scalable video coding,svc)、多视图视频编码(multiview video coding,mvc)和多视图视频编码加深度(multiview video coding plus depth,mvc+d)、三维(three dimension,3d)avc(3d-avc)等扩展版本。hevc包括可适性hevc(scalable hevc,shvc)、多视图hevc(multiview hevc,mv-hevc)、3d hevc(3d-hevc)等扩展版本。itu-t和iso/iec的联合视频专家组(joint video experts team,jvet)已经着手开发一种称为通用视频编码(versatile video coding,vvc)的视频编码标准。vvc包含在工作草案(wd)中,而工作草案包括jvet-o2001-v14。
[0062]
可以使用多层图像来支持可适性。例如,视频可以被译码成多层,某一层可以在不参考其他层的情况下进行译码。这样的层被称为联播层。相应地,某一联播层可以在不参考其他层的情况下进行解码。又如,某一层可以通过层间预测进行译码,从而允许通过仅包括当前层和参考层之间的差值来译码当前层。例如,当前层和参考层可以包括通过改变诸如信噪比(signal to noise ratio,snr)、图像大小、帧率等特性进行译码的相同视频序列。
[0063]
一些视频译码系统用于仅解码并输出由层标识(identifier,id)表示的最高编码层以及一个或多个被指示的较低层。由于解码器可能不希望解码最高层,因此这可能会在可适性方面带来问题。具体地,解码器通常请求解码器能够支持的最高层,但是解码器通常又无法解码高于被请求层的层。在一个特定的示例中,解码器可能希望接收和解码总编码层为15层中的第三层。该第三层可以在没有第4层到第15层的情况下被发送到解码器,因为不需要通过这些层来解码第三层。但是,解码器可能无法正确解码和显示该第三层,因为最高层(第15层)不存在,而且视频系统总是被指示要解码并显示该最高层。因此,在此类系统中尝试视频可适性时会产生错误。因为解码器需要始终支持最高层,会导致系统无法根据不同的硬件和网络要求调整到中间层,所以这个问题很严重。使用多视图后,这个问题更加严重。在多视图中,将输出不止一层进行显示。例如,用户可以使用耳机,并且可以向每只眼睛显示不同的层,从而创建三维(three dimensional,3d)视频的印象。不支持可适性的系统也不支持多视图可适性。
[0064]
本文公开了一种支持多视图可适性的机制。这些层包含在多个输出层集(output layer set,ols)中。编码器可以发送包含这些层的ols,以调整到特定的特性,如大小或
snr。空间可适性允许将视频序列译码成多层,以便将这些层放置到ols中,从而使得每个ols均包含足够的数据,以将该视频序列解码为适合对应输出屏幕的大小。因此,空间可适性可以包括用于解码适合智能手机屏幕的视频的一系列层、用于解码适合大电视屏幕的视频的一系列层,以及用于解码适合中间屏幕大小的视频的一系列层。snr可适性允许将视频序列译码成多层,以便将这些层放置到ols中,使得每个ols均包含足够的数据,以不同的snr解码该视频序列。因此,snr可适性可以包括根据网络条件针对低质量视频、高质量视频和各种中间质量视频可以进行解码的一系列层。此外,编码器可以,例如,在视频参数集(video parameter set,vps)中传输ols模式识别码(ols_mode_idc)语法元素。所述ols_mode_idc语法元素可以设置为1,表示支持多视图可适性。例如,所述ols_mode_idc可以表示ols的总数等于所述vps中指定的层的总数,表示第i个ols包括层0~层i(包括首尾值),并表示对于每个ols,所有层都被视为输出层。这样可以支持可适性,因为所述解码器可以接收并解码特定ols中的所有层。由于所有层均为输出层,因此所述解码器可以选择和渲染所需的输出层。这样,经编码的层的总数可能不会对解码过程产生影响,并且可以避免错误,同时仍然可以提供可适性多视图视频。因此,所公开的机制改进了编码器和/或解码器的功能。此外,所公开的机制还可以减小码流的大小,从而减少编码器侧和解码器侧对处理器、存储器和/或网络资源的使用。
[0065]
图1为一种对视频信号进行译码的示例性操作方法100的流程图。具体地,该视频信号是在编码器侧进行编码的。编码过程通过采用各种机制来压缩该视频信号,以减小视频文件的大小。较小的文件大小有助于将压缩后的视频文件传输给用户,同时降低相关的带宽开销。然后,解码器对压缩后的视频文件进行解码,以重建原始视频信号,从而向终端用户显示。解码过程通常是编码过程的逆过程,从而使得解码器重建的视频信号可以与编码器侧的视频信号保持一致。
[0066]
步骤101:将所述视频信号输入到所述编码器中。例如,所述视频信号可以是存储在存储器中的未经压缩的视频文件。又如,视频文件可以由视频摄像机等视频捕获设备捕获,并且进行编码以支持视频的直播流传输。视频文件可以同时包括音频分量和视频分量。视频分量包括一系列图像帧。这些图像帧按顺序观看时,给人以运动的视觉效果。这些帧包括以光表示的像素,在本文中称为亮度分量(或亮度样本),还包括以颜色表示的像素,称为色度分量(或颜色样本)。在一些示例中,这些帧还可以包括深度值,以支持三维观看。
[0067]
步骤103:将视频分割为块。分割包括将每帧中的像素细分成正方形块和/或矩形块进行压缩。例如,在高效视频编码(high efficiency video coding,hevc)(也称为h.265和mpeg-h第二部分)中,可以先将帧划分成编码树单元(coding tree_unit,ctu),这些ctu是预定义大小(例如,64个像素
×
64个像素)的块。这些ctu同时包括亮度样本和色度样本。编码树可以用于将ctu划分成块,然后重复细分这些块,直到获得支持进一步编码的配置。例如,帧的亮度分量可以细分,直到各个块包括相对均匀的亮度(lighting)值。此外,帧的色度分量可以细分,直到各个块包括相对均匀的色值。因此,分割机制因视频帧的内容而异。
[0068]
步骤105:使用各种压缩机制对步骤103中分割得到的图像块进行压缩。例如,可以采用帧间预测和/或帧内预测。帧间预测是为了利用普通场景中的对象往往出现在连续帧中这一事实而设计的。相应地,描述参考帧中的对象的块不需要在相邻帧中重复描述。具体
地,一个对象(例如一张桌子)可以在多个帧中保持在固定位置上。因此,该桌子被描述一次,而且相邻帧可以反过来参考该参考帧。模式匹配机制可以用于在多个帧上匹配对象。此外,由于对象移动或相机移动等原因,移动对象可以跨多个帧表示。在一个具体示例中,视频可以在多个帧中显示跨屏幕移动的汽车。运动矢量可以用来描述这种移动。运动矢量是一个二维矢量,表示对象在一个帧中的坐标到该对象在参考帧中的坐标之间的偏移。因此,帧间预测可以将当前帧中的图像块编码为一组运动矢量,表示当前帧中的图像块与参考帧中的对应块之间的偏移。
[0069]
通过帧内预测对公共帧中的块进行编码。帧内预测利用了亮度分量和色度分量往往聚集在一个帧中这一事实。例如,一棵树某个部分的一片绿色往往与类似的几片绿色相邻。帧内预测采用多种方向性预测模式(例如,hevc中有33种)、平面模式和直流(direct current,dc)模式。这些方向性模式表示当前块中的样本与对应方向上的相邻块中的样本相似/相同。平面模式表示一行/列(例如平面)中的一系列块可以根据该行的边缘上的相邻块进行插值。平面模式实际上通过采用变化值的相对恒定的斜率表示光/颜色跨行/列的平稳过渡。dc模式用于边界平滑,并表示块与所有相邻块中的样本的平均值相似/相同,这些相邻块与方向性预测模式的角度方向相关联。相应地,帧内预测块可以将图像块表示为各种关系预测模式值而不是表示为实际值。此外,帧间预测块可以将图像块表示为运动矢量值而不是表示为实际值。在任一种情况下,预测块在一些情况下可能都无法准确表示图像块。任何差值都存储在残差块中。可以对残差块进行变换以进一步压缩文件。
[0070]
步骤107:可以应用各种滤波技术。在hevc中,滤波器是根据环内滤波方案应用的。上文描述的基于块的预测可能会在解码器侧产生块状图像。此外,基于块的预测方案可以对块进行编码,然后重建经编码块,以便后续用作参考块。环内滤波方案迭代地将噪声抑制滤波器、去块效应滤波器、自适应环路滤波器和样本自适应偏移(sample adaptive offset,sao)滤波器应用于块/帧。这些滤波器减少了块伪影,使得可以准确地重建经编码文件。此外,这些滤波器减少了重建参考块中的伪影,这样,伪影不太可能在根据重建参考块编码的后续块中产生其它伪影。
[0071]
步骤109:对所述视频信号完成分割、压缩和滤波之后,将得到的数据编码到码流中。所述码流包括上文描述的数据以及支持在所述解码器侧进行适当的视频信号重建所需要的任何指示数据。例如,这些数据可以包括分割数据、预测数据、残差块和提供译码指令给所述解码器的各种标志。所述码流可以存储在存储器中,以便根据请求向所述解码器发送。所述码流还可以被广播和/或组播到多个解码器。所述码流的创建是一个迭代过程。因此,可以对多个帧和块连续和/或同时执行步骤101、步骤103、步骤105、步骤107和步骤109。图1所示的顺序是为了清楚和便于论述的目的而呈现的,并非旨在将视频译码过程限制于特定顺序。
[0072]
步骤111:所述解码器接收所述码流并开始执行解码过程。具体地,所述解码器采用熵解码方案将码流转换为对应的语法和视频数据。在步骤111中,所述解码器采用所述码流中的语法数据来确定帧的分割部分。所述分割可以与步骤103中的块分割的结果匹配。下面将描述在步骤111中采用的熵编码/解码。所述编码器在压缩过程中作出许多选择,例如,根据一个或多个输入图像中的值的空间定位从几个可能选择中选择块分割方案。指示确切的选择时可能会采用大量的位元(bin)。本文中所使用的“位元”是一个作为变量的二进制
值(例如,可以根据上下文变化而变化的比特值)。熵编码使得所述编码器丢弃任何明显不适合特定情况的选项,从而留下一组可用选项。然后,为每个可用选项分配一个码字。码字的长度取决于可用选项的数量(例如,一个位元对应两个选项,两个位元对应三到四个选项,以此类推)。然后,所述编码器对所选选项的码字进行编码。这种方案减小了码字的大小,这是因为码字与预期的一样大,从而唯一地指示从可用选项的小子集中进行选择,而不是唯一地指示从所有可能选项的可能大集合中进行选择。然后,所述解码器通过与所述编码器类似的方式确定这一组可用选项,对这一选择进行解码。通过确定这一组可用选项,所述解码器可以读取码字并确定所述编码器作出的选择。
[0073]
步骤113:所述解码器执行块解码。具体地,所述解码器采用逆变换生成残差块。然后,所述解码器采用残差块和对应的预测块,根据分割来重建图像块。预测块可以包括所述编码器在步骤105中生成的帧内预测块和帧间预测块。然后,根据在步骤111中确定的分割数据将重建图像块放置在重建视频信号的帧中。步骤113的语法还可以通过上文描述的熵编码在所述码流中进行指示。
[0074]
步骤115:通过类似于所述编码器侧的步骤107的方式对重建视频信号的帧执行滤波。例如,噪声抑制滤波器、去块效应滤波器、自适应环路滤波器和sao滤波器可以应用于帧,用于去除块伪影。对帧进行了滤波之后,在步骤117中,可以将视频信号输出到显示器,以供终端用户观看。
[0075]
图2为一种用于视频译码的示例性编码和解码(编解码,codec)系统200的示意图。具体地,编解码系统200提供功能来支持操作方法100的实现。编解码系统200广义地用于描述编码器和解码器都使用的组件。编解码系统200接收视频信号并对视频信号进行分割,如参照操作方法100中的步骤101和步骤103所述,得到分割后的视频信号201。然后,编解码系统200用作编码器,将分割后的视频信号201压缩到经编码码流中,如参照方法100中的步骤105、步骤107和步骤109所述。编解码系统200再用作解码器,从码流中生成输出视频信号,如参照操作方法100中的步骤111、步骤113、步骤115和步骤117所述。编解码系统200包括通用译码器控制组件211、变换缩放和量化组件213、帧内估计组件215、帧内预测组件217、运动补偿组件219、运动估计组件221、缩放和逆变换组件229、滤波器控制分析组件227、环内滤波器组件225、解码图像缓冲区组件223以及标头格式和上下文自适应二进制算术编码(context adaptive binary arithmetic coding,cabac)组件231。这些组件如图所示相耦合。在图2中,黑色线条表示待编码/待解码数据的运动,而虚线表示控制其它组件操作的控制数据的运动。编解码系统200中的组件都可以存在于编码器中。解码器可以包括编解码系统200中的组件的子集。例如,解码器可以包括帧内预测组件217、运动补偿组件219、缩放和逆变换组件229、环内滤波器组件225以及解码图像缓冲区组件223。下面对这些组件进行描述。
[0076]
分割后的视频信号201是捕获到的已经通过编码树分割成像素块的视频序列。编码树采用各种划分模式将像素块细分成更小的像素块。然后,这些块可以进一步细分成更小的块。这些块可以称为编码树上的节点。较大的父节点划分成较小的子节点。对节点进行细分的次数称为节点/编码树的深度。在一些情况下,划分得到的块可以包含在编码单元(coding unit,cu)中。例如,cu可以是ctu的子部分,包括亮度块、一个或多个红色差色度(cr)块和一个或多个蓝色差色度(cb)块以及cu对应的语法指令。划分模式可以包括二叉树
(binary tree,bt)、三叉树(triple tree,tt)和四叉树(quad tree,qt),用于根据所采用的划分模式将节点分别分割成不同形状的二个、三个或四个子节点。分割后的视频信号201被转发给通用译码器控制组件211、变换缩放和量化组件213、帧内估计组件215、滤波器控制分析组件227和运动估计组件221进行压缩。
[0077]
通用译码器控制组件211用于根据应用约束作出与将视频序列中的图像编码到码流中相关的决策。例如,通用译码器控制组件211管理码率/码流大小相对于重建质量的优化。这些决策可以是根据存储空间/带宽的可用性和图像分辨率请求作出的。通用译码器控制组件211还根据传输速度来管理缓冲区的利用率,以缓解缓存欠载和超载的问题。为了解决这些问题,通用译码器控制组件211管理由其它组件进行的分割、预测和滤波。例如,通用译码器控制组件211可以动态地提高压缩复杂度,以提高分辨率,并增加带宽利用率,或者动态地降低压缩复杂度,以降低分辨率和带宽利用率。因此,通用译码器控制组件211控制编解码系统200中的其它组件来平衡视频信号重建质量与码率问题。通用译码器控制组件211生成控制数据,这些控制数据用于控制其它组件的操作。该控制数据还被转发给标头格式和cabac组件231,以编码到码流中,用以指示用于在解码器侧进行解码的参数。
[0078]
分割后的视频信号201还被发送给运动估计组件221和运动补偿组件219进行帧间预测。分割后的视频信号201的帧或条带可以划分成多个视频块。运动估计组件221和运动补偿组件219根据一个或多个参考帧中的一个或多个块对所接收到的视频块执行帧间预测译码,以提供时间预测。编解码系统200可以执行多个译码过程,以便为视频数据的每个块选择合适的译码模式,等等。
[0079]
运动估计组件221和运动补偿组件219可以高度集成,但出于概念目的而在本文中分别进行描述。由运动估计组件221执行的运动估计是生成运动矢量的过程,其中,这些运动矢量用于估计视频块的运动。例如,运动矢量可以表示经译码对象相对于预测块的位移。预测块是在像素差方面发现与待编码块高度匹配的块。预测块还可以称为参考块。这种像素差可以通过绝对差异和(sum ofabsolute difference,sad)、平方差异和(sum of square difference,ssd)或其它差异度量来确定。hevc采用若干经译码对象,包括ctu、编码树块(coding tree block,ctb)和cu。例如,ctu可以被划分成ctb,ctb然后被划分成cb,cb包含在cu中。cu可以被编码为包括预测数据的预测单元(prediction unit,pu)和/或包括cu的变换残差数据的变换单元(transform unit,tu)。运动估计组件221使用率失真分析作为率失真优化过程的一部分来生成运动矢量、pu和tu。例如,运动估计组件221可以确定当前块/帧的多个参考块、多个运动矢量等,并且可以选择具有最佳率失真特性的参考块、运动矢量等。最佳率失真特性平衡了视频重建的质量(例如,压缩造成的数据丢失量)和译码效率(例如,最终编码的大小)。
[0080]
在一些示例中,编解码系统200可以计算存储在解码图像缓冲区组件223中的参考图像的子整数像素位置的值。例如,视频编解码系统200可以对参考图像的四分之一像素位置、八分之一像素位置或其它分数像素位置的值进行插值。因此,运动估计组件221可以相对于整像素位置和分数像素位置执行运动搜索,并输出具有分数像素精度的运动矢量。运动估计组件221通过将pu的位置与参考图像的预测块的位置进行比较,来计算经帧间译码条带中的视频块的pu的运动矢量。运动估计组件221将计算得到的运动矢量作为运动数据输出到标头格式和cabac组件231进行编码,并作为运动数据输出到运动补偿组件219。
[0081]
运动补偿组件219执行的运动补偿可以包括根据运动估计组件221所确定的运动矢量获取或生成预测块。同样,在一些示例中,运动估计组件221和运动补偿组件219可以在功能上集成。在接收到当前视频块的pu的运动矢量时,运动补偿组件219可以定位运动矢量所指向的预测块。然后,从正在译码的当前视频块的像素值中减去预测块的像素值,得到像素差值,从而形成残差视频块。通常,运动估计组件221相对于亮度分量执行运动估计,运动补偿组件219将根据亮度分量计算得到的运动矢量用于色度分量和亮度分量。预测块和残差块被转发给变换缩放和量化组件213。
[0082]
分割后的视频信号201还被发送给帧内估计组件215和帧内预测组件217。与运动估计组件221和运动补偿组件219一样,帧内估计组件215和帧内预测组件217可以高度集成,但出于概念目的而在本文中分别进行描述。帧内估计组件215和帧内预测组件217相对于当前帧中的各块对当前块进行帧内预测,以替代如上所述的由运动估计组件221和运动补偿组件219在各帧之间执行的帧间预测。具体地,帧内估计组件215确定帧内预测模式以对当前块进行编码。在一些示例中,帧内估计组件215从多个测试的帧内预测模式中选择合适的帧内预测模式对当前块进行编码。然后,选定的帧内预测模式被转发给标头格式和cabac组件231用于进行编码。
[0083]
例如,帧内估计组件215对各种测试的帧内预测模式进行率失真分析来计算率失真值,并在测试的模式中选择具有最佳率失真特性的帧内预测模式。率失真分析通常确定经编码块与经编码以产生该经编码块的原始未编码块之间的失真量(或误差),以及确定用于产生该经编码块的码率(例如,比特数)。帧内估计组件215根据各种经编码块的失真和速率计算比率,以确定表现出块的最佳率失真值的帧内预测模式。另外,帧内估计组件215可以用于根据率失真优化(rate-distortion optimization,rdo),使用深度建模模式(depth modeling mode,dmm)对深度图的深度块进行译码。
[0084]
帧内预测组件217在编码器上实现时可以根据由帧内估计组件215确定的所选帧内预测模式从预测块生成残差块,或者在解码器上实现时,可以从码流中读取残差块。残差块包括预测块与原始块之间的差值,表示为矩阵。然后,残差块被转发给变换缩放和量化组件213。帧内估计组件215和帧内预测组件217可以对亮度分量和色度分量都进行操作。
[0085]
变换缩放和量化组件213用于进一步压缩残差块。变换缩放和量化组件213将离散余弦变换(discrete cosine transform,dct)、离散正弦变换(discrete sine transform,dst)等变换或者概念上类似的变换应用于残差块,从而产生包括残差变换系数值的视频块;还可以应用小波变换、整数变换、子带变换或其它类型的变换。变换可以将残差信息从像素值域转换到变换域,例如频域。变换缩放和量化组件213还用于根据频率等对变换残差信息进行缩放。这种缩放包括将缩放因子应用于残差信息,使得在不同的粒度下量化不同的频率信息,这可能会影响重建视频的最终视觉质量。变换缩放和量化组件213还用于量化变换系数以进一步降低码率。量化过程可以减小与部分或全部系数相关的位深度。量化程度可以通过调整量化参数来修改。在一些示例中,变换缩放和量化组件213随后可以对包括量化变换系数的矩阵进行扫描。量化变换系数被转发给标头格式和cabac组件231,以编码到码流中。
[0086]
缩放和逆变换组件229应用与变换缩放和量化组件213相反的操作以支持运动估计。缩放和逆变换组件229应用逆缩放、逆变换和/或反量化以重建像素域中的残差块。例
如,残差块后续用作参考块,该参考块可以作为另一当前块的预测块。运动估计组件221和/或运动补偿组件219可以通过将残差块添加回对应的预测块来计算参考块,用于后续块/帧的运动估计中。将滤波器应用于重建参考块,以减少在缩放、量化和变换过程中产生的伪影。当预测后续块时,这些伪影可能会使预测不准确(并产生额外的伪影)。
[0087]
滤波器控制分析组件227和环内滤波器组件225将滤波器应用于残差块和/或重建图像块。例如,可以组合来自缩放和逆变换组件229的变换残差块与来自帧内预测组件217和/或运动补偿组件219的对应预测块,以重建原始图像块。然后,可以将滤波器应用于重建图像块。在一些示例中,滤波器还可以应用于残差块。与图2中的其它组件一样,滤波器控制分析组件227和环内滤波器组件225高度集成,且可以一起实现,但出于概念目的而在本文中分别进行描述。将应用于重建参考块的滤波器应用于特定空间区域,这些滤波器包括多个参数,以调整应用这些滤波器的方式。滤波器控制分析组件227对重建参考块进行分析,以确定可以应用此类滤波器的位置并设置对应的参数。这些数据作为滤波器控制数据被转发给标头格式和cabac组件231进行编码。环内滤波器组件225根据滤波器控制数据应用这些滤波器。这些滤波器可以包括去块效应滤波器、噪声抑制滤波器、sao滤波器和自适应环路滤波器。这些滤波器可以根据示例应用于空间域/像素域(例如,经重建的像素块)或频域中。
[0088]
当作为编码器执行操作时,解码图像缓冲区组件223中存储经过滤波的重建图像块、残差块和/或预测块,以供后续用于运动估计,如上所述。当作为解码器执行操作时,解码图像缓冲区组件223中存储经重建和经滤波的块并将其作为输出视频信号的一部分转发给显示器。解码图像缓冲区组件223可以是任何能够存储预测块、残差块和/或重建图像块的存储设备。
[0089]
标头格式和cabac组件231从编解码系统200中的各种组件接收数据,并将这些数据编码到经编码码流中,以发送给解码器。具体地,标头格式和cabac组件231生成各种标头以对控制数据(例如,通用控制数据和滤波器控制数据)进行编码。此外,将预测数据(包括帧内预测数据和运动数据)以及以量化变换系数数据形式存在的残差数据都编码到码流中。最终的码流包括由解码器重建原始分割后的视频信号201所需要的所有信息。这些信息还可以包括帧内预测模式索引表(还称为码字映射表)、各种块的编码上下文的定义、最可能的帧内预测模式的指示、分割信息的指示等。这些数据可以通过熵编码来编码。例如,这些信息可以通过上下文自适应可变长度编码(context adaptive variable length coding,cavlc)、cabac、基于语法的上下文自适应二进制算术编码(syntax-based context-adaptive binary arithmetic coding,sbac)、概率区间分割熵(probability interval partitioning entropy,pipe)编码或其它熵编码技术来编码。在熵编码之后,可以将经编码码流发送给另一设备(例如,视频解码器)或进行存档以供后续传输或检索。
[0090]
图3为一种示例性视频编码器300的框图。视频编码器300可以用于实现编解码系统200的编码功能和/或执行操作方法100中的步骤101、步骤103、步骤105、步骤107和/或步骤109。编码器300对输入视频信号进行分割,得到分割后的视频信号301,其与分割后的视频信号201基本相似。然后,通过编码器300中的组件压缩分割后的视频信号301并编码到码流中。
[0091]
具体地,分割后的视频信号301被转发给帧内预测组件317进行帧内预测。帧内预
测组件317可以与帧内估计组件215和帧内预测组件217基本相似。分割后的视频信号301还被转发给运动补偿组件321,以根据解码图像缓冲区组件323中的参考块进行帧间预测。运动补偿组件321可以与运动估计组件221和运动补偿组件219基本相似。来自帧内预测组件317和运动补偿组件321的预测块和残差块被转发给变换和量化组件313进行残差块的变换和量化。变换和量化组件313可以与变换缩放和量化组件213基本相似。经变换量化的残差块和对应的预测块(与相关的控制数据一起)被转发给熵编码组件331,以编码到码流中。熵编码组件331可以与标头格式和cabac组件231基本相似。
[0092]
经变换量化的残差块和/或对应的预测块还从变换和量化组件313转发给逆变换和反量化组件329,以重建为参考块供运动补偿组件321使用。逆变换和反量化组件329可以与缩放和逆变换组件229基本相似。根据示例,环内滤波器组件325中的环内滤波器还应用于残差块和/或经重建的参考块。环内滤波器组件325可以与滤波器控制分析组件227和环内滤波器组件225基本相似。环内滤波器组件325可以包括多个滤波器,如参照环内滤波器组件225所述。然后,经滤波的块存储在解码图像缓冲区组件323中,以作为参考块供运动补偿组件321使用。解码图像缓冲区组件323可以与解码图像缓冲区组件223基本相似。
[0093]
图4为一种示例性视频解码器400的框图。视频解码器400可以用于实现编解码系统200的解码功能和/或执行操作方法100中的步骤111、步骤113、步骤115和/或步骤117。解码器400从编码器300等接收码流,并根据码流生成经重建的输出视频信号,以向终端用户显示。
[0094]
码流由熵解码组件433接收。熵解码组件433用于执行熵解码方案,例如cavlc、cabac、sbac、pipe解码或其它熵解码技术。例如,熵解码组件433可以使用标头信息来提供上下文以解析码流中的编码为码字的附加数据。经解码信息包括对视频信号进行解码所需要的任何信息,例如,通用控制数据、滤波器控制数据、分割信息、运动数据、预测数据和残差块中的量化变换系数。经量化的变换系数被转发给逆变换和反量化组件429以重建为残差块。逆变换和反量化组件429可以与逆变换和反量化组件329基本相似。
[0095]
经重建的残差块和/或预测块被转发给帧内预测组件417以根据帧内预测操作重建为图像块。帧内预测组件417可以与帧内估计组件215和帧内预测组件217相似。具体地,帧内预测组件417使用预测模式来定位帧中的参考块,并将残差块应用于所得到的结果以重建帧内预测图像块。经重建的帧内预测图像块和/或残差块以及对应的帧间预测数据通过环内滤波器组件425被转发到解码图像缓冲区组件423。解码图像缓冲区组件423和环内滤波器组件425可以分别与解码图像缓冲区组件223和环内滤波器组件225基本相似。环内滤波组件425对重建图像块、残差块和/或预测块进行滤波。这些信息存储在解码图像缓冲区组件423中。来自解码图像缓冲区组件423的重建图像块被转发给运动补偿组件421进行帧间预测。运动补偿组件421可以与运动估计组件221和/或运动补偿组件219基本相似。具体地,运动补偿组件421使用参考块中的运动矢量生成预测块,并将残差块应用于所得到的结果以重建图像块。所得到的重建块还可以通过环内滤波器组件425转发到解码图像缓冲区组件423。解码图像缓冲区组件423继续存储其它重建图像块。这些重建图像块可以通过分割信息重建为帧。这些帧还可以放置在一个序列中。该序列作为经重建的输出视频信号输出到显示器。
[0096]
图5为一种用于层间预测521的示例性多层视频序列500的示意图。多层视频序列
500可以,例如,根据方法100由编码器(例如编解码器系统200和/或编码器300)进行编码,并由解码器(例如编解码器系统200和/或解码器400)进行解码。将多层视频序列500纳入进来,是为了描绘编码视频序列中的层的示例性应用。多层视频序列500是包括多个层例如层n 531和层n+1 532的任何视频序列。
[0097]
在一个示例中,多层视频序列500可以使用层间预测521。层间预测521应用于位于不同层的图像511、512、513和514与图像515、516、517和518之间。在所示的示例中,图像511、512、513和514是层n+1 532的一部分,而图像515、516、517和518是层n 531的一部分。层例如层n 531和/或层n+1 532是一组图像,这些图像都与某一特性的相似值相关联,例如相似的大小、质量、分辨率、信噪比、能力等。层可以正式定义为一组vcl nal单元和关联的非vcl nal单元,它们共用相同的nuh_layer_id。vcl nal单元是经译码的nal单元,以包括视频数据,例如包括图像的译码条带。非vcl nal单元是包括非视频数据的nal单元,例如包括支持解码视频数据、一致性性能检查或其他操作的语法和/或参数。
[0098]
在所示的示例中,与层n 531相比,层n+1 532关联更大的图像大小。因此,在本示例中,层n+1 532的图像511、512、513和514的大小大于层n 531的图像515、516、517和518的大小(例如,高度和宽度更大,样本更多)。但是,这些图像可以根据其它特性在层n+1 532和层n 531之间区分开。虽然只显示了两层:层n+1 532和层n 531,但是一组图像可以根据关联特性被划分为任意数量的层。层n+1 532和层n 531也可以用层id表示。层id是与图像关联的数据项,其表示该图像是所指示的层的一部分。因此,图像511至图像518中的每个图像都可以与对应的层id相关联,以指示层n+1 532或层n 531中的哪个层包括该对应的图像。例如,层id可以包括nal单元头层标识(nuh_layer_id),该nal单元头层标识是一个语法元素,指示包括nal单元的层(例如,包括层中图像的条带和/或参数)的标识。与较低质量/较小码流大小相关联的层,例如层n 531,通常被分配较小的层id,并被称为较低层。进一步地,与较高质量/较大码流大小相关联的层,例如层n+1 532,通常被分配较大的层id,并被称为较高层。
[0099]
不同的层531和层532中的图像511至图像518被配置为交替显示。在一个特定的示例中,如果需要较小的图像,则解码器可以在当前显示时间解码并显示图像515,或者,如果需要较大的图像,则解码器可以在当前显示时间解码并显示图像511。因此,较高层n+1532中的图像511至图像514与较低层n 531中的对应图像515至图像518包括基本上相同的图像数据(尽管图像大小不同)。具体地,图像511与图像515包括基本上相同的图像数据,图像512与图像516包括基本上相同的图像数据,以此类推。
[0100]
图像511至图像518可以参考同一层n 531或n+1 532中的图像511至图像518中的其它图像进行译码。参考同一层中的一个图像对另一个图像进行译码即为帧间预测523。帧间预测523由实线箭头表示。例如,图像513可以通过将层n+1 532中的图像511、512和/或514中的一个或两个图像作为参考进行帧间预测523来译码,其中,单向帧间预测中使用一个图像作为参考,和/或双向帧间预测中使用两个图像作为参考。此外,图像517可以通过将层n 531中的图像515、516和/或518中的一个或两个图像作为参考进行帧间预测523来译码,其中,单向帧间预测中使用一个图像作为参考,和/或双向帧间预测中使用两个图像作为参考。当在执行帧间预测523时,将一个图像作为同一层中另一个图像的参考时,该图像可以称为参考图像。例如,图像512可以是用于根据帧间预测523对图像513进行译码的参考
图像。帧间预测523也可以被称为多层上下文中的层内预测。因此,帧间预测523是通过参考与当前图像不同的参考图像中的指示样本对当前图像的样本进行译码的机制,其中,参考图像和当前图像位于同一层中。
[0101]
图像511至图像518也可以通过参考不同层中的图像511至图像518中的其它图像进行译码。这个过程称为层间预测521,由虚线箭头表示。层间预测521是通过参考一个参考图像中的指示样本对当前图像的样本进行译码的机制,其中,当前图像和参考图像位于不同的层中,因此具有不同的层id。例如,低层n 531中的图像可以作为参考图像对较高层n+1532中的对应图像进行译码。在一个特定的示例中,图像511可以根据层间预测521通过参考图像515进行译码。在这种情况下,图像515被用作层间参考图像。层间参考图像是用于层间预测521的参考图像。在大多数情况下,对层间预测521进行了约束,使得当前图像例如图像511只能使用同一au中包含的位于较低层的一个或多个层间参考图像,例如,图像515。au是与视频序列中的特定输出时间相关联的一组图像,因此,au可以包括和层一样多的图像,一层一个图像。当存在多层(例如,两层以上)时,层间预测521可以根据层级比当前图像低的多个层间参考图像对当前图像进行编码/解码。
[0102]
视频编码器可以使用多层视频序列500来通过帧间预测523和层间预测521的许多不同组合和/或排列对图像511至图像518进行编码。例如,图像515可以根据帧内预测进行译码。然后,将图像515作为参考图像,可以根据帧间预测523对图像516至图像518进行译码。此外,将图像515作为层间参考图像,可以根据层间预测521对图像511进行译码。然后,将图像511作为参考图像,可以根据帧间预测523对图像512至图像514进行译码。因此,参考图像可以作为用于不同译码机制中的单层参考图像和层间参考图像。通过根据较低层n531中的图像对较高层n+1 532中的图像进行译码,较高层n+1 532可以避免使用帧内预测,因为帧内预测的译码效率比帧间预测523和层间预测521的译码效率要低得多。因此,译码效率低的帧内预测可以限制用于最小/最低质量的图像,并且限于对最少量的视频数据进行译码。用作参考图像和/或层间参考图像的图像可以在参考图像列表结构中包括的一个或多个参考图像列表的条目中进行指示。
[0103]
为了执行这样的操作,诸如层n 531和层n+1 532的层可以包含在ols 525中。ols525是一系列层,其中,该系列层中的一个或多个层被指定为输出层。输出层是指定用于输出(例如,输出到显示器)的层。例如,可以包括层n 531,仅支持层间预测521,但是不可以输出层n 531。在这种情况下,层n+1 532基于层n 531进行解码并输出。在这种情况下,ols 525包括层n+1 532作为输出层。ols 525可以包括不同组合形式的许多层。例如,ols 525中的输出层可以根据层间预测521基于一个、两个或多个较低层进行译码。进一步地,ols 525可以包括不止一个输出层。因此,ols 525可以包括一个或多个输出层和重建输出层所需的任何支持层。多层视频序列500可以通过采用许多不同的ols 525进行译码,其中,每个ols 525都包括不同的层组合。
[0104]
在一个特定的示例中,可以使用层间预测521支持可适性。例如,视频可以译码成基本层如层n 531以及若干增强层如层n+1 532、层n+2、层n+3等,这些层根据层间预测521进行译码。视频序列可以针对若干可适性特性如信噪比(signal to noise ratio,snr)、帧率、图像大小等进行译码。然后,可以针对每个允许的特性创建ols 525。例如,针对第一分辨率的ols 525可以仅包括层n 531,针对第二分辨率的ols 525可以包括层n 531和层n+
1532,针对第三分辨率的ols可以包括层n 531、层n+1 532、层n+2等。这样,ols 525可以进行传输以允许解码器根据网络条件、硬件约束条件等解码所需的任何版本的多层视频序列500。
[0105]
图6为一种包括为多视图可适性配置的ols的示例性视频序列600的示意图;视频序列600是多层视频序列500的一个具体示例。因此,多层视频序列600可以,例如,根据方法100由编码器(例如编解码器系统200和/或编码器300)进行编码,并由解码器(例如编解码器系统200和/或解码器400)进行解码。视频序列600有利于可适性。
[0106]
示例性视频序列600包括ols 620、ols 621和ols 622,它们可以与ols 525基本相似。虽然只描述了三个ols,但是可以使用任何数量的ols。ols 620、ols 621和ols622分别由ols索引表示,并且分别包括一个或多个层。具体地,ols 620包括层630,ols 621包括层630和层631,ols 622包括层630、层631和层632。层630、层631和层632可以与层n 531和层n+1 532基本相似。层630、层631和层632由层索引表示。视频序列600包括与ols的数量相同的层数。具体地,ols索引最小的ols 620包括层索引最小的层630。其他每个ols包括前一个具有较小ols索引的ols的所有层加1。例如,ols 621的ols索引大于ols 620的ols索引,ols 621包括层630和层631,即包括ols 620的所有层加1。同样,ols 622的ols索引大于ols 621的ols索引,ols 622包括层630、层631和层632,即包括ols 621的所有层加1。此模式可以继续,直到到达具有最大层索引的层和具有最大ols索引的ols。
[0107]
此外,层630是基本层。所有其他层631和层632都是增强层,其基于具有较小层索引的所有层根据层间预测进行译码。具体地,层630是基本层,并且不根据层间预测进行译码。层631是增强层,其基于层630根据层间预测进行译码。进一步地,层632也是增强层,其基于层630和层631根据层间预测进行译码。结果是ols 620包括具有最低质量snr和/或最小图像大小的层630。由于ols 620不使用任何层间预测,因此ols 620可以在不参考除层630之外的任何层的情况下完全解码。ols 621包括层631,层631具有比层630更高质量snr和/或更大图像大小,并且层631可以根据层间预测完全解码,因为ols 621也包括层630。同样,ols 622包括层632,层632具有比层630和层631更高质量snr和/或更大图像大小,并且层632可以根据层间预测完全解码,因为ols 622也包括层630和层631。因此,通过向解码器发送相应的ols 622、ols 621或ols 620,对视频序列600进行译码以调整到任何预先选定的snr和/或图像大小。当使用更多ols 622、ols 621和ols 620时,视频序列600可以调整到更多的snr图像质量和/或图像大小。
[0108]
因此,视频序列600可以支持空间可适性。空间可适性允许将视频序列600译码成层630、层631和层632,以便将层630、层631和层632放置到ols 620、ols 621和ols622中,从而使得ols 620、ols 621和ols 622均包含足够的数据,以将视频序列600解码为适合对应输出屏幕的大小。因此,空间可适性可以包括用于解码适合智能手机屏幕的视频的一个或一系列层(例如,层630)、用于解码适合大电视屏幕的视频的一系列层(例如,层630、层631和层632),以及用于解码适合中间屏幕大小的视频的一系列层(例如,层630和层631)。snr可适性允许将视频序列600译码成层630、层631和层632,以便将层630、层631和层632放置到ols 620、ols 621和ols 622中,从而使得ols 620、ols621和ols 622均包含足够的数据,以不同的snr解码视频序列600。因此,snr可适性可以包括针对低质量视频、高质量视频(例如,层630、层631和层632)和各种中间质量视频(例如,层630和层631)而进行解码的一个或
一系列层(例如,层630),以支持不同的网络条件。
[0109]
本发明进行有效地指示,从而支持正确、有效地使用具有多视图层的视频序列600。例如,层630、层631和层632都可以被指定为输出层。然后,解码器可以根据需要选择和渲染层630、层631和层632以实现多视图。为了支持这种实现方式,视频序列600的译码可以根据ols_mode_idc语法元素表示。例如,ols_mode_idc语法元素可以将视频序列600标识为ols模式一。因此,ols_mode_idc语法元素可以设置为1,并在码流中进行指示,表示使用视频序列600。相应地,解码器可以接收任何ols,并且可以根据ols_mode_idc确定ols620、ols 621和ols 622的数量与层630、层631和层632的数量相同,确定当前ols的id为i表示当前ols包括id为0~i的一系列层,并确定当前ols中的所有层均为输出层。然后,解码器可以根据需要对来自ols 620、ols 621和/或ols 622的层630、层631和/或层632进行解码并显示,以实现多视图。
[0110]
图7为一种包括为多视图可适性配置的ols的示例性码流700的示意图。例如,根据方法100,码流700可以由编解码系统200和/或编码器300生成,由编解码系统200和/或解码器400进行解码。此外,码流700可以包括经译码的多层视频序列500和/或视频序列600。
[0111]
码流700包括vps 711、一个或多个序列参数集(sequence parameter set,sps)713、多个图像参数集(picture parameter set,pps)715、多个条带头717和图像数据720。vps711包括与整个码流700相关的数据。例如,vps 711可以包括在码流700中使用的数据相关的ols、层和/或子层。sps 713包括码流700包含的编码视频序列中的所有图像共有的序列数据。例如,每层可以包括一个或多个编码视频序列,每个编码视频序列可以参考sps713获取相应的参数。sps 713中的参数可以包括图像大小、位深度、译码工具参数、码率限制等。需要注意的是,虽然每个序列都参考sps 713,但是在一些示例中,单个sps 713可以包括用于多个序列的数据。pps 715包括应用于整个图像的参数。因此,视频序列中的每个图像都可以参考pps 715。需要注意的是,虽然每个图像都参考pps 715,但是在一些示例中,单个pps 715可以包括用于多个图像的数据。例如,可以根据相似参数对多个相似的图像进行译码。在这种情况下,单个pps 715可以包括用于这些相似图像的数据。pps715可以表示可用于对应图像中的条带的译码工具、量化参数、偏移等。
[0112]
条带头717包括图像725中每个条带727特有的参数。因此,视频序列中的每个条带727可以有一个条带头717。条带头717可以包括条带类型信息、poc、参考图像列表、预测权重、分块入口点、去块效应参数等。应当注意的是,在一些示例中,码流700还可以包括图像头。图像头是一种语法结构,其包括应用于单个图像中所有条带727的参数。因此,图像头和条带头717在某些上下文中可以互换使用。例如,某些参数可以在条带头717和图像头之间来回使用,这取决于这些参数对于图像725中的所有条带727是否是共有的。
[0113]
图像数据720包括根据帧间预测和/或帧内预测编码的视频数据以及对应的经变换和量化的残差数据。例如,图像数据720可以包括图像725的层723。层723可以组织成ols721。ols 721可以与ols 525、ols 620、ols 621和/或ols 622基本相似。具体地,ols721是一系列层723,其中,该系列层中的一个或多个层723被指定为一个或多个输出层。当层723支持多视图视频时,所有层723都可以被指定为输出层。例如,码流700可以被译码为包括若干ols 721,而视频按不同的分辨率、帧率、图像725的大小等进行译码。根据解码器的请求,子码流提取过程可以为从码流700中删除所请求的ols 721之外的所有ols 721。然
后,编码器可以将仅包括所请求的ols 721的码流700和仅满足所请求标准的视频传输给解码器。
[0114]
层723可以与层n 531、层n+1 532和/或层631、层632和/或层633基本相似。层723通常是一组经编码图像725。层723可以正式定义为一组vcl nal单元,当进行解码时,这些vcl nal单元共用指定的特性(例如,常用的分辨率、帧率、图像大小等)。图像725可以译码为一组vcl nal单元。层723还包括关联的非vcl nal单元,以支持对vcl nal单元进行解码。层723的vcl nal单元可以共用nuh_layer id的特定值,该值是层id的一个示例。层723可以是不根据层间预测进行译码的联播层,也可以是基于其他层根据层间预测进行译码的层723。
[0115]
图像725是创建帧或其场的亮度样本阵列和/或色度样本阵列。例如,图像725可以是编码图像,其可以输出以进行显示或用于支持对其他一个或多个图像725进行译码以便输出。图像725可以包括一组vcl nal单元。图像725包括一个或多个条带727。条带727可以被定义为图像725中的整数个完整分块或(例如分块内的)整数个连续完整编码树单元(coding tree unit,ctu)行,这些分块或ctu行只包含在单个nal单元中,特别是vcl nal单元。条带727进一步划分成ctu和/或编码树块(coding tree block,ctb)。ctu是一组预定义大小的样本,可以通过编码树进行分割。ctb是ctu的子集,包括ctu的亮度分量或色度分量。ctu/ctb根据编码树进一步划分成编码块(coding block)。然后,编码块可以根据预测机制进行编码/解码。
[0116]
本发明包括,例如,利用视频序列600支持多视图视频的空间可适性和/或snr可适性的机制。例如,vps 711可以包括ols_mode_idc 735。ols_mode_idc 735是一个语法元素,表示与ols 721的数量、ols 721中的层723和ols 721中的输出层723有关的信息。输出层723是指定用于由解码器输出的任何层,而不是仅用于基于参考的译码。ols_mode_idc 735可以设置为0或2,用于对其他类型的视频进行译码。ols_mode_idc 735可以设置为1,以支持多视图视频的空间可适性和/或snr可适性。例如,ols_mode_idc 735可以设置为1,表示视频序列中的ols 721的总数等于vps 711中指定的层723的总数,表示第i个ols 721包括层0~层i(包括首尾值),并表示对于每个ols 721,所述ols 721包含的所有层均为输出层。这一系列条件可以描述具有任何数量的ols_721的视频序列600。使用ols_mode_idc735的优点是ols_mode_idc 735可以节省比特。应用系统中的解码器通常仅接收单个ols。然而,ols_mode_idc 735还可以为包括共用很多数据的多个ols的多个编码码流节省比特,从而节省了流媒体服务器,并为传输此类码流节省带宽。具体地,将ols_mode_idc 735设置为1的优点是支持多视图应用等的使用案例,其中,两个或多个视图(每个视图由一层表示)将同时输出并显示。
[0117]
在一些示例中,vps 711还包括vps_max_layers_minus1(vps maximum layers minus one)语法元素737。vps_max_layers_minus1 737是一个语法元素,指示vps 711指定的层723的数量、以及码流700中对应编码视频序列中允许的层723的最大数量。ols_mode_idc 735可以参考vps_max_layers_minus1语法元素737。例如,ols_mode_idc 735可以表示ols 721的总数等于vps_max_layers_minus1 737指定的层723的数量。
[0118]
进一步地,vps 711可以包括each_layer_is_an_ols_flag 733。each_layer_is_an_ols_flag733是一个语法元素,指示是否码流700中的每个ols 721都包括单个层723。例
如,当不利用可适性时,每个ols 721可以包括单个联播层。相应地,each_layer_is_an_ols_flag 733可以被设置为例如0,表示一个或多个ols 721包括不止一层723,以支持可适性。因此,each_layer_is_an_ols_flag 733可以用于支持可适性。例如,解码器可以检查each_layer_is_an_ols_flag 733,以确定ols 721中的一些ols 721包括不止一层723。当each_layer_is_an_ols_flag 733设置为0并且当ols_mode_idc 735设置为1(或0,用于不同的模式)时,ols的总数(totalnumolss)可以设置为等于vps_max_layers_minus1 737。totalnumolss是一个变量,由解码器和位于编码器侧的假设参考解码器(hypothetical reference decoder,hrd)使用。totalnumolss是一个变量,用于根据码流700中的数据存储ols 721的数量。然后,totalnumolss可以用于解码器进行解码或用于位于编码器侧的hrd检查码流700的错误。
[0119]
vps 711还可以包括vps层标识(vps_layer_id[i])语法元素731。vps_layer_id[i]731是一个数组,用于存储每个层的层id(例如,nuh_layer_id)。相应地,vps_layer_id[i]731指示第i层的层id。
[0120]
解码器或hrd能够使用vps 711中的数据确定ols 721和层723的配置。在一个特定的示例中,第i个ols中的层数(numlayersinols[i])和指示所述第i个ols中第j层的nuh_layer_id值的ols中的层id(layeridinols[i][j])推导如下:
[0121][0122]
其中,vps_layer_id[i]为第i个vps层标识,totalnumolss为所述vps指定的ols的总数,each_layer_is_an_ols_flag(each layer is an ols flag)表示至少一个ols是否包括不止一层。
[0123]
可以使用vps 711中的数据来支持snr和/或空间可伸缩层723,包括支持多视图视频。层723可以被编码并包含在ols 721中。编码器可以将包括所请求的ols 721和vps 711的码流700传输到解码器。然后,解码器可以使用vps 711中的信息正确解码ols 721中的层723。这种方法支持高效译码,同时支持可适性。具体地,解码器可以快速确定ols 721中的层723的数量,确定ols 721中的所有层均为输出层,并根据层间预测解码输出层。然后,解码器可以选择应进行渲染以实现多视图的输出层。相应地,解码器可以接收为进行多视图而解码的视图所需的层723,而且解码器可以根据需要解码并显示来自层723的图像725。这样,经编码的层723的总数不会对解码过程产生影响,并且可以避免如上所述的一个或多个错误。因此,所公开的机制改进了编码器和/或解码器的功能。此外,所公开的机制还可以减小码流的大小,从而减少编码器侧和解码器侧对处理器、存储器和/或网络资源的使用。
[0124]
下文中将更加详细地描述上述信息。分层视频译码也被称为可适性视频编码或支持可适性的视频译码。视频译码中的可适性通常通过使用多层译码技术来支持。多层码流包括基本层(base layer,bl)和一个或多个增强层(enhancement layer,el)。例如,可适性包括空间可适性、质量/信噪比(signal to noise ratio,snr)可适性、多视图可适性、帧率可适性等。当使用多层译码技术时,图像或图像的一部分可以不使用参考图像(帧内预测)进行译码,可以通过参考相同层中的参考图像(帧间预测)进行译码,和/或可以通过参考其他一个或多个层中的参考图像(层间预测)进行译码。用于对当前图像进行层间预测的参考图像称为层间参考图像(inter-layer reference picture,ilrp)。图5示出了一种支持空间可适性的多层译码示例,其中,不同层的图像具有不同的分辨率。
[0125]
一些视频编码标准系列支持从一个或多个单独的配置文件实现该一个或多个配置文件的可适性,从而实现单层译码。可适性视频编码(scalable video coding,svc)是高级视频编码(advanced video coding,avc)的可扩展版,其支持空间可适性、时间可适性和质量可适性。对于svc,在el图像的每个宏块(macroblock,mb)中指示了一个标志,表示el mb是否使用较低层中的并置块进行预测。基于并置块的预测可以包括纹理、运动矢量和/或译码模式。svc中的实现方式不可以在其设计中直接重用未经修改的avc中的实现方式。el宏块在svc中的语法和解码过程与其在avc中的语法和解码过程不同。
[0126]
可适性hevc(scalable hevc,shvc)是hevc的扩展,其支持空间可适性和质量可适性。多视图hevc(multiview hevc,mv-hevc)是hevc的扩展,其支持多视图可适性。3d hevc(3d hevc,3d-hevc)是hevc的扩展,其支持比mv-hevc更高级、更高效的3d视频译码。时间可适性可以作为单层hevc编解码的组成部分而被包含进来。在hevc的多层扩展中,用于进行层间预测的解码图像仅来自同一个au,并被认为是长期参考图像(long-term reference picture,ltrp)。此类图像与当前层中其他时间参考图像一起被分配一个或多个参考图像列表中的参考索引。层间预测(inter-layer prediction,ilp)是通过将参考索引的值设置为参考一个或多个参考图像列表中的一个或多个层间参考图像在预测单元(prediction unit,pu)级实现的。当ilrp具有与正被编码或解码的当前图像不同的空间分辨率时,针对空间可适性,会重新采样参考图像或参考图像的一部分。参考图像重采样可以在图像级或编码块级实现
[0127]
vvc还可以支持分层视频译码。vvc码流可以包括多个层,这些层可以相互独立。例如,每个层都可以不使用层间预测进行译码。在这种情况下,这些层也被称为联播层。在某些情况下,这些层中的某些层使用ilp进行译码。vps中的标志可以表示这些层是否为联播层或者某些层是否使用ilp。当某些层使用ilp时,各层之间的层依赖关系也会在vps中进行指示。不同于shvc和mv-hevc,vvc可以不指定ols。一个ols包括一系列特定的层,其中,该一系列层中的一个或多个层被指定为输出层。输出层是ols中被输出的层。在vvc的一些实现方式中,当这些层是联播层时,可以仅选择一层进行解码并输出。在vvc的某些实现方式中,当任何层使用ilp时,指定对包括所有层的整个码流进行解码。进一步地,这些层中的某些层被指定为输出层。这些输出层可以被指示为仅最高层、所有层或最高层加一系列被指示的较低层。
[0128]
上述方面存在一定的问题。在一些视频译码系统中,当使用层间预测时,指定对整个码流和所有层进行解码,并且这些层中的某些层被指定为输出层。这些输出层可以被指
示为仅最高层、所有层或最高层加一系列被指示的较低层。为了简单描述所述问题,可以一起使用两层以及将较低层用作层间预测参考的上层。对于多视图可适性,系统可以指定仅使用较低层(即仅解码并输出较低层)。该系统也可以指定使用这两层(即解码并输出这两层)。然而,这在一些视频译码系统中是不可能的。
[0129]
通常,本发明描述了用于简单高效指示支持多视图可适性的输出层集(output layer set,ols)的方法。这些技术是基于itu-t和iso/iec的jvet制定的vvc描述的。但是,这些技术也适用于基于其他视频编解码规范的分层视频译码。
[0130]
上述问题中的一个或多个问题可以通过如下方式解决。具体地,本发明提供了一种简单高效指示支持空间可适性和snr可适性的ols的方法。视频译码系统可以使用vps表示某些层使用ilp,表示所述vps指定的ols的总数等于层数,表示第i个ols包括层索引为0~i(包括首尾值)的层,并表示对于每个ols仅输出该ols中的最高层。
[0131]
上述机制的一种示例性实现方式如下所述:一种示例性视频参数集语法如下所述:
[0132]
[0133][0134][0135]
一种示例性视频参数集语法如下所述。vps rbsp在被参考之前可以用于解码过程,并可以包含在temporalid等于0的至少一个接入单元中,或通过外部机制提供,而且,包
括vps rbsp的vps nal单元的nuh_layer_id可以等于vps_layer_id[0]。cvs中具有vps_video_parameter_set_id为特定值的所有vps nal单元都可以具有相同的内容。vps_video_parameter_set_id提供vps的一个标识,以供其他语法元素参考。vps_max_layers_minus1+1表示参考vps的每个cvs中允许的最大层数。vps_max_sub_layers_minus1+1表示参考vps的每个cvs中可能存在的时间子层的最大数量。vps_max_sub_layers_minus1的值可以在0~6的范围内(包括首尾值)。
[0136]
vps_all_independent_layers_flag可以设置为等于1,表示cvs中的所有层都是独立译码的,不需要使用层间预测。vps_all_independent_layers_flag可以设置为等于0,表示cvs中的一个或多个层可以使用层间预测。当不存在vps_all_independent_layers_flag的值时,则推断vps_all_independent_layers_flag的值等于1。当vps_all_independent_layers_flag等于1时,则推断vps_independent_layer_flag[i]的值等于1。当vps_all_independent_layers_flag等于0时,则推断vps_independent_layer_flag[0]的值等于1。vps_layer_id[i]表示第i层的nuh_layer_id值。对任意两个非负整数值m和n,当m小于n时,vps_layer_id[m]的值应小于vps_layer_id[n]的值。vps_independent_layer_flag[i]可以设置为等于1,表示索引为i的层不使用层间预测。vps_independent_layer_flag[i]可以设置为等于0,表示索引为i的层可以使用层间预测,并表示vps中存在vps_layer_dependency_flag[i]。当不存在vps_independent_layer_flag[i]的值时,则推断vps_independent_layer_flag[i]的值等于1。
[0137]
vps_direct_dependency_flag[i][j]可以设置为等于0,表示索引为j的层不是索引为i的层的直接参考层。vps_direct_dependency_flag[i][i]可以设置为等于1,表示索引为j的层是索引为i的层的直接参考层。对于在0~vps_max_layers_minus1的范围内(包括首尾值)的i和i,当不存在vps_direct_dependency_flag[i][j]时,则推断vps_direct_dependency_flag[i][j]等于0。表示第i层的第j直接依赖层的变量directdependentlayeridx[i][j]推导如下:
[0138][0139]
表示具有nuh_layer_id等于vps_layer_id[i]的层的层索引的变量generallayeridx[i]推导如下:
[0140]
for(i=0;i<=vps_max_layers_minus1;i++)
[0141]
generallayeridx[vps_layer_id[i]]=i
[0142]
each_layer_is_an_ols_flag可以设置为等于1,表示每个输出层集仅包括一层,并表示码流中的每个层本身即为输出层集,其中,该输出层集中包括的单个层即是唯一的输出层。each_layer_is_an_ols_flag可以设置为等于0,表示输出层集可以包括不止一层。如果vps_max_layers_minus1等于0,则推断each_layer_is_an_ols_flag的值等于1。否则,当vps_all_independent_layers_flag等于0时,则推断each_layer_is_an_ols_flag的值等于0。
[0143]
ols_mode_idc可以设置为等于0,表示vps指定的ols的总数等于vps_max_layers_minus1+1,表示第i个ols包括层索引为0~i(包括首尾值)的层,并表示对于每个ols仅输出该ols中的最高层。ols_mode_idc可以设置为等于1,表示vps指定的ols的总数等于vps_max_layers_minus1+1,表示第i个ols包括层索引为0~i(包括首尾值)的层,并表示对于每个ols输出该ols中的所有层。ols_mode_idc可以设置为等于2,表示vps指定的ols的总数是显式指示的,并表示对于每个ols输出该ols中的最高层和一系列显式指示的较低层。ols_mode_idc的值可以在0~2的范围内(包括首尾值)。ols_mode_idc的值3是预留的。当vps_all_independent_layers_flag等于1且each_layer_is_an_ols_flag等于0时,则推断ols_mode_idc的值等于2。
[0144]
num_output_layer_sets_minus1+1表示ols_mode_idc等于2时vps指定的ols的总数。表示vps指定的ols的总数的变量totalnumolss推导如下:
[0145][0146]
layer_included_flag[i][j]表示ols_mode_idc等于2时第j层(例如,具有nuh_layer_id等于vps_layer_id[j]的层)是否包含在第i个ols中。layer_included_flag[i][j]可以设置为等于1,表示第j层包含在第i个ols中。layer_included_flag[i][j]可以设置为等于0,表示第j层不包含在第i个ols中。
[0147]
表示第i个ols中的层数的变量numlayersinols[i]和指示第i个ols中第j层的nuh_layer_id值的变量layeridinols[i][j]可以推导如下:
[0148][0149]
表示具有nuh_layer_id等于layeridinols[i][j]的层的ols层索引的变量olslayeidx[i][j]可以推导如下:
[0150]
for(i=0,i<totalnumolss;i++)
[0151]
for j=0;j<numlayersinols[i];j++)
[0152]
olslayeidx[i][layeridinols[i][j]]=j
[0153]
每个ols中的最低层可以是一个独立的层。换句话说,对于0~totalnumolss-1的范围内(包括首尾值)的每个i,vps_independent_layer_flag[generallayeridx[layeridinols[i][0]]]的值可以等于1。每一层可以包含在vps指定的至少一个ols中。换句话说,对于具有nuh_layer_id为特定值的每个层(例如,nuhlayerid等于vps_layer_id[k]中的一个值,其中,k在0~vps_max_layers_minus1的范围内(包括首尾值)),可以存在至少一对i和j的值,使得layeridinols[i][j]的值等于nuhlayerid,其中,i在0~totalnumolss-1的范围内(包括首尾值),j在numlayersinols[i]-1的范围内(包括首尾值)。ols中的任何层都可以是该ols中的输出层或该ols中的输出层的(直接或间接)参考层。
[0154]
vps_output_layer_flag[i][j]表示ols_mode_idc等于2时是否输出第i个ols中的第j层。vps_output_layer_flag[i]可以设置为等于1,表示输出第i个ols中的第j层。vps_output_layer_flag[i]可以设置为等于0,表示不输出第i个ols中的第j层。当vps_all_independent_layers_flag等于1且each_layer_is_an_ols_flag等于0时,则可以推断vps_output_layer_flag[i]的值等于1。
[0155]
变量outputlayerflag[i][j]的值为1,表示输出第i个ols中的第j层,变量outputlayerflag[i][j]的值为0,表示不输出第i个ols中的第j层。该变量
to-optical,eo)组件、和/或耦合到上行端口850和/或下行端口820的无线通信组件,用于通过电、光或无线通信网络传输数据。视频译码设备800还可以包括输入和/或输出(i/o)设备860,用于与用户传输数据。i/o设备860可以包括输出设备,例如用于显示视频数据的显示器、用于输出音频数据的扬声器等。i/o设备860还可以包括输入设备,例如键盘、鼠标、轨迹球等,和/或用于与这些输出设备进行交互的对应接口。
[0161]
处理器830通过硬件和软件实现。处理器830可以实现为一个或多个cpu芯片、核(例如实现为多核处理器)、现场可编程门阵列(field-programmable gate array,fpga)、专用集成电路(application-specific integrated circuit,asic)和数字信号处理器(digital signal processor,dsp)。处理器830与下行端口820、tx/rx 810、上行端口850和存储器832通信。处理器830包括译码模块814。译码模块814实现本文描述的公开实施例,例如方法100、900和1000,其中可以采用多层视频序列500、视频序列600和/或码流700。译码模块814还可以实现本文所描述的任何其它方法/机制。此外,译码模块814可以实现编解码系统200、编码器300和/或解码器400。例如,译码模块814可以用于将视频序列译码成层和/或ols,以支持多视图可适性。例如,译码模块814可以将ols_mode_idc语法元素编码到码流的vps中和/或从码流的vps解码出ols_mode_idc语法元素,其中,ols_mode_idc语法元素可以表示视频序列中的ols的总数等于vps指定的总层数,表示第i个ols包括层0~层i(包括首尾值),并表示对于每个ols输出该ols中的所有层。译码模块814可以使用ols_mode_idc语法元素来表示/确定从可适性视频接收到的所有层均可以根据需要进行解码并显示,以实现多视图视频。因此,译码模块814使得视频译码设备800在对视频数据进行译码时提供其它功能和/或提高译码效率。所以,译码模块814改进了视频译码设备800的功能,并且解决了视频译码领域特有的问题。此外,译码模块814可以使视频译码设备800变换到不同的状态。或者,译码模块814可以实现为存储在存储器832中并由处理器830执行的指令(例如实现为存储在非瞬时性介质中的计算机程序产品)。
[0162]
存储器832包括一个或多个存储器类型,如磁盘、磁带机、固态硬盘、只读存储器(read only memory,rom)、随机存取存储器(random access memory,ram)、闪存、三态内容寻址存储器(ternary content-addressable memory,tcam)、静态随机存取存储器(static random-access memory,sram)等。存储器832可以用作溢出数据存储设备,以在选择程序用于执行时存储此类程序,并存储程序执行期间读取的指令和数据。
[0163]
图9为一种对包括为多视图可适性配置的ols的视频序列例如码流700中的多层视频序列500和/或视频序列600进行编码的示例性方法900的流程图。所述方法900可以由编码器(例如编解码系统200、编码器300和/或视频译码设备800)在执行方法100时执行。
[0164]
所述方法900可以在编码器接收视频序列并确定将所述视频序列编码为具有一系列层和ols的可适性多视图视频序列时开始,例如,根据用户的输入开始。所述频序列可以配置为支持多视图并且可以进行译码以支持snr可适性、空间可适性、本文所论述的其他特性的可适性或其组合。步骤901:所述编码器可以对包括一个或多个ols的码流进行编码,其中,所述一个或多个ols包括一层或多层编码图像。例如,这些层可以包括具有最小层id的基本层和具有递增层id的各个增强层。层id为j的每个增强层可以根据所述基本层和层id小于j的任何增强层根据层间预测进行编码。ols可以包括ols id,其中,所述ols id可以用i表示,用于区分用j表示的层id。例如,一层可能对应一个ols。因此,ols id为i的ols可以
包括层id为j的输出层,其中,i等于j;ols id为i的ols也可以包括层id为0~j-1(包括首尾值)的所有层。本示例中,可以将所有层设置为输出层。例如,ols id为5的ols可以包括层0至层5,其中,每一层均被指示为输出层。
[0165]
步骤903:所述编码器将vps编码到所述码流中。所述ols和所述层的配置可以由所述vps指示。所述vps包括ols_mode_idc语法元素。ols_mode_idc可以设置为表示所述vps指定的ols的总数等于所述vps指定的层数。此外,ols_mode_idc还可以设置为表示第i个ols包括层索引为0~i和/或i(包括首尾值)的层(例如,此时,i等于j)。ols_mode_idc还可以设置为表示对于每个ols,所述每个ols中的所有层均为输出层。例如,ols_mode_idc可以设置为若干模式中的一种模式。当ols_mode_idc设置为1时,可以对上述模式进行指示。在一些示例中,所述vps还可以包括vps_max_layers_minus1,表示所述vps指定的层数,其同时是参考所述vps的每个cvs中允许的最大层数。ols_mode_idc可以参考vps_max_layers_minus1。
[0166]
例如,所述视频序列可以由解码器和/或位于所述编码器侧的假设参考解码器(hypothetical reference decoder,hrd)进行解码,以进行标准的验证。解码所述视频序列时,当所述vps中的each_layer_is_an_ols_flag设置为0时,并且当ols_mode_idc设置为0时,或者当ols_mode_idc设置为1时,表示所述视频序列的ols的总数(totalnumolss)的变量可以设置为等于vps_max_layers_minus1+1。在一个特定的示例中,第i个ols中的层数(numlayersinols[i])和表示所述第i个ols中第j层的nuh_layer_id值的ols中的层id(layeridinols[i][j])可以推导如下:
[0167][0168][0169]
其中,vps_layer_id[i]为第i个vps层标识,totalnumolss为所述vps指定的ols的总数,each_layer_is_an_ols_flag(each layer is an ols flag)表示至少一个ols是否包括不止一层。在知道ols的id和输出层的id之后,位于所述编码器侧的hrd可以通过层间预测开始解码所述输出层中的编码图像,以执行一致性测试,从而确保视频符合标准。
[0170]
步骤905:所述编码器可以存储所述码流,以发送给解码器。例如,所述解码器可以知道可用的ols(例如,通过通信和/或其他协议如超文本传输协议动态自适应流媒体(dynamic adaptive streaming over hypertext transfer protocol,dash))。所述解码器可以选择并请求具有最大id的ols,该ols可以由所述解码器正确解码/显示。例如,在空间可适性的情况下,所述解码器可以请求ols,该ols的多视图视频和图像大小与连接到所
述解码器的屏幕相关联。在snr可适性的情况下,所述解码器可以请求具有最大id的ols,该ols的多视图视频可以根据当前网络条件(例如,根据可用的通信带宽)进行解码。然后,所述编码器和/或中间缓存或内容服务器可以将该ols和一个或多个关联层传输到解码器以进行解码。因此,所述编码器可以创建一个多视图视频序列,该多视图视频序列可以根据所述解码器的需要扩大或缩小。
[0171]
图10为一种对包括为多视图可适性配置的ols的视频序列例如码流700中的多层视频序列500和/或视频序列600进行解码的示例性方法1000的流程图所述方法1000可以由解码器(例如编解码系统200、解码器400和/或视频译码设备800)在执行方法100时执行。
[0172]
所述方法1000可以在解码器开始接收包括一个ols的码流(其中,该ols具有可适性多视图视频序列的一个或一系列层)时开始,例如,作为方法900的结果。所述视频序列可以进行译码以支持snr可适性、空间可适性、本文所论述的其他特性的可适性或其组合。步骤1001:所述解码器可以接收包括ols和vps的码流。例如,所述ols可以包括一层或多层编码图像。这些层可以包括具有最小层id的基本层和具有递增层id的各个增强层。层id为j的每个增强层可以根据所述基本层和层id小于j的任何增强层根据层间预测进行编码。所述ols可以包括ols id,其中,所述ols id可以用i表示,用于区分用j表示的层id。例如,编码码流中可以一层对应一个ols。因此,ols id为i的ols可以包括层id为j的输出层,其中,i等于j;接收到的ols id为i的ols也可以包括层id为0~j-1(包括首尾值)的所有层。本示例中,可以将所有层设置为输出层。例如,接收到的ols id为5的ols可以包括层0至层5,其中,每一层均被指示为输出层。所述ols和所述层的配置可以由所述vps指示。
[0173]
例如,所述vps包括ols_mode_idc语法元素。ols_mode_idc可以设置为表示所述vps指定的ols的总数等于所述vps指定的层数。此外,ols_mode_idc还可以设置为表示第i个ols包括层索引为0~i和/或i(包括首尾值)的层(例如,此时,i等于j)。ols_mode_idc还可以设置为表示对于每个ols,所述每个ols中的所有层均为输出层。例如,ols_mode_idc可以设置为若干模式中的一种模式。当ols_mode_idc设置为1时,可以对上述模式进行指示。在一些示例中,所述vps还可以包括vps_max_layers_minus1,表示所述vps指定的层数,其同时是参考所述vps的每个cvs中允许的最大层数。ols_mode_idc可以参考vps_max_layers_minus1。
[0174]
步骤1003:所述解码器可以根据所述vps中的ols_mode_idc确定所述输出层。例如,确定视频序列的配置时,当所述vps中的each_layer_is_an_ols_flag设置为0时,并且当ols_mode_idc设置为0时,或者当ols_mode_idc设置为1时,表示所述视频序列的ols的总数(totalnumolss)的变量可以设置为等于vps_max_layers_minus1+1。在一个特定的示例中,第i个ols中的层数(numlayersinols[i])和表示所述第i个ols中第j层的nuh_layer_id值的ols中的层id(layeridinols[i][j])可以推导如下:
[0175][0176]
其中,vps_layer_id[i]为第i个vps层标识,totalnumolss为所述vps指定的ols的总数,each_layer_is_an_ols_flag(each layer is an ols flag)表示至少一个ols是否包括不止一层。
[0177]
步骤1005:所述解码器可以根据所述输出层的id解码来自所述输出层的一个或多个编码图像,以产生一个或多个解码图像。例如,所述解码器可以通过层间预测解码所有输出层,以根据需要基于较低层解码较高层。所述解码器还可以选择多个层以实现多视图。步骤1007:所述解码器可以转发所述解码图像,以显示为解码视频序列的一部分。例如,所述解码器可以转发来自第一层的解码图像,以在第一屏幕(或第一屏幕的一部分)进行显示,并转发来自第二层集的图像,以在第二屏幕(或第二屏幕的一部分)进行显示。
[0178]
在一个特定的示例中,所述解码器可以知道可用的ols(例如,通过通信和/或其他协议如超文本传输协议动态自适应流媒体(dynamic adaptive streaming over hypertext transfer protocol,dash))。所述解码器可以选择并请求具有最大id的ols,该ols可以由所述解码器正确解码/显示。例如,在空间可适性的情况下,所述解码器可以请求ols,该ols的图像大小与连接到所述解码器的屏幕相关联。在snr可适性的情况下,所述解码器可以请求具有最大id的ols,该ols可以根据当前网络条件(例如,根据可用的通信带宽)进行解码。然后,所述编码器和/或中间缓存或内容服务器可以将该ols和一个或多个关联层传输到解码器以进行解码,从而支持多视图。因此,所述编码器可以创建一个多视图视频序列,该多视图视频序列可以根据所述解码器的需要扩大或缩小。然后,所述解码器可以使用方法1000在接收到所请求的视频序列时进行解码。
[0179]
图11为一种对包括为多视图可适性配置的ols的视频序列例如码流700中的多层视频序列500和/或视频序列600进行译码的示例性系统1100的示意图。所述系统1100可以通过编码器和解码器例如编解码系统200、编码器300、解码器400和/或视频译码设备800实现。此外,所述系统1100可以用于实现方法100、方法900和/或方法1000。
[0180]
所述系统1100包括视频编码器1102。所述视频编码器1102包括编码模块1105,用于对包括一个或多个ols的码流进行编码,其中,所述一个或多个ols包括一层或多层编码图像。所述编码模块1105还用于将vps编码到所述码流中,其中,所述vps包括ols_mode_idc,表示对于每个ols,所述每个ols中的所有层均为输出层。所述视频编码器1102还包括存储模块1106,用于存储所述码流,以发送给解码器。所述视频编码器1102还包括发送模块1107,用于将所述码流发送到视频解码器1110。所述视频编码器1102还可以用于执行方法
900中的任何步骤。
[0181]
所述系统1100还包括所述视频解码器1110。所述视频解码器1110包括:接收模块1111,用于接收包括ols和vps的码流,其中,所述ols包括一层或多层编码图像,所述vps包括ols_mode_idc,表示对于每个ols,所述每个ols中的所有层均为输出层。所述视频解码器1110还包括确定模块1113,用于根据所述vps中的ols_mode_idc确定所述输出层。所述视频解码器1110还包括解码模块1115,用于对来自所述输出层的编码图像进行解码,以产生解码图像。所述视频解码器1110还包括转发模块1117,用于转发所述解码图像,以显示为解码视频序列的一部分。所述视频解码器1110还可以用于执行方法1000中的任何步骤。
[0182]
当第一组件与第二组件之间除了线、迹线或其它介质之外,没有中间组件时,第一组件直接耦合到第二组件。当第一组件与第二组件之间除了线、迹线或其它介质之外还有中间组件时,第一组件间接耦合到第二组件。术语“耦合”及其同义词包括直接耦合和间接耦合。除非另有说明,否则术语“大约”是指包括该术语之后的数量的
±
10%的范围。
[0183]
还应当理解,本文中阐述的示例性方法的步骤不一定需要按照所描述的顺序执行,并且这些方法的步骤的顺序应当理解为仅仅是示例性的。同理,在与本发明各种实施例相一致的方法中,这些方法可以包括其它步骤,并且某些步骤可以省略或组合。
[0184]
虽然本发明提供了若干个实施例,但应当理解,在不脱离本发明的精神或范围的情况下,所公开的系统和方法可能通过其它多种具体形式体现。本发明的示例应认为是说明性的而非限制性的,且本发明并不限于本文中所描述的详细内容。例如,各种元件或组件可以组合或集成在另一系统中,或者一些特征可以省略或不实施。
[0185]
此外,在各种实施例中描述和示出为分立的或单独的技术、系统、子系统和方法,在不背离本发明的范围的情况下,可以与其它系统、组件、技术或方法组合或集成。其它变更、替换和更改的示例可以由本领域技术人员确定,并且不脱离本文公开的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1