SDN下基于深度强化学习的DDoS防御系统及方法
sdn下基于深度强化学习的ddos防御系统及方法
技术领域
1.本发明属于sdn下网络安全主动防御领域,尤其涉及一种sdn架构下基于深度强化学习的ddos攻击主动防御系统及方法。
背景技术:
2.ddos攻击事件的数量仍在逐年增加,且具有极高的攻击流量和较短的攻击持续时间,因此在此类攻击上升之前及时采取防御措施至关重要。由于软件定义网络架构在防御ddos攻击方面的优势,例如灵活的编程和控制特性,基于统计模型和机器学习模型的方法能够有效地防御软件定义网络(software-defined network,sdn)中的ddos攻击,但是这些方法的实时性较弱,当攻击特征发生变化时,这些方法需要在模型变得无效之前重新收集样本并重建模型。深度强化学习的出现为实时有效地防御ddos攻击提供了机会。与此同时,深度强化学习方法以黑盒模式运行,并依赖于不透明的数据驱动模型,所以基于深度强化学习的ddos攻击防御效果可能会出现较大差异,所以兼顾ddos攻击防御的效率、鲁棒性、实时性是至关重要的。
技术实现要素:
3.本发明的目的在于针对现有技术的不足,提供一种sdn架构下基于深度强化学习的ddos攻击主动防御系统及方法。
4.本发明的目的是通过以下技术方案来实现的:一种sdn架构下基于深度强化学习的ddos攻击主动防御系统,包括sdn控制器、边缘交换机和深度强化学习智能体处理模块;其中,sdn控制器包括网络状态收集模块、防御动作执行模块、反馈采集模块;将防御过程转换为马尔可夫决策过程,通过sdn控制器建立网络视图,实时采集边缘交换机上的网络特征信息,反映当前网络请求状态;基于深度强化学习中的近端策略优化算法,从动态环境中提取网络特征,将每条流的状态映射到防御决策,保证正常流量的通过并丢弃恶意流量,实现对ddos攻击的主动防御;并通过深度强化学习代理与网络之间的交互训练深度神经网络,利用经验优化防御策略。
5.进一步地,包括:
6.网络状态收集模块,主动请求边缘交换机的状态信息,隔δt时刻后,再获取返回的状态信息;
7.深度强化学习智能体处理模块基于近端策略优化算法实现,该模块的输入state为网络状态收集模块收集到的交换机的端口信息和通过交换机的流信息,该模块的输出为动作action,表示边缘交换机上某条流允许通过的流量比例;其中恶意流量允许通过比例趋近于0%,正常流量允许通过比例趋近于100%;
8.防御动作执行模块,利用带宽重分配的方法对深度强化学习智能体处理模块输出的动作action进行校验,并根据原始允许通过的流大小,为每条流重新分配带宽,在带宽重分配的过程中添加约束条件;所述约束条件为允许通过边缘交换机发往服务器的总流量不
超过服务器可用带宽;
9.反馈采集模块:防御动作执行模块执行后触发反馈采集模块,此时反馈采集模块调用网络状态收集模块主动请求边缘交换机和服务器的状态信息,隔δt时刻后,获取返回的下一个网络状态信息state’;再结合网络状态收集模块收集的上一网络状态信息state中通过边缘交换机的流信息和到达服务器流信息,计算出恶意流量比例pm和正常流量比例pn;基于这两个比例,计算奖励函数值reward;反馈采集模块将下一个网络状态信息state’和奖励函数值reward反馈给深度强化学习智能体处理模块。
10.进一步地,当sdn控制器未收集到某条流的状态时,对应流的状态为0,对应流允许通过的流量比例也为0。
11.进一步地,边缘交换机上某条流允许通过的流量比例的范围在[0.05,1]。
[0012]
进一步地,深度强化学习智能体处理模块包括演员神经网络a、演员神经网络b、评论家神经网络和记忆池,具体包括:
[0013]
(2.1)演员神经网络a负责与网络环境交互,其中演员神经网络a将state作为输入,输出动作的分布均值sigma和均值mu,从对应的正态分布中随机采样得到action;
[0014]
(2.2)深度强化学习智能体处理模块内神经网络的更新,依赖于记忆池中收集的样本集;在防御动作执行模块执行防御动作后,从反馈采集模块收集反馈信息,包括下一个网络状态信息state’和奖励值reward;并将(state,action,reward,state’)存入记忆池;当记忆池中储存f1组样本后,将样本实际收益与状态价值函数的作差,差值为优势函数值a,将函数值a的均方差作为损失值,反向传播,更新评论家神经网络的参数,这一更新过程训练f2次;
[0015]
(2.3)在演员神经网络a的输出的分布上采样,与演员神经网络b的输出的分布上采样得到action概率的比值,作为ratio;演员神经网络b更新的损失值为loss=min(ratio*a,clip(1-e,1+e,ratio)*a);其中,e为自定义取值,clip()函数将ratio限制在(1-e,1+e)的范围内;这一更新过程训练f3次;
[0016]
(2.4)整个近段策略优化算法每训练f1*f3步,将演员神经网络b参数值赋给演员神经网络a,完成演员神经网络a的更新。
[0017]
进一步地,防御动作执行模块,针对两种网络状况进行安全防御:
[0018]
第一种是,当允许通过边缘交换机的总流量大于服务器可用带宽时,防御动作执行模块根据约束条件,减小能够到达服务器的流量大小;
[0019]
第二种是,当允许通过边缘交换机的总流量小于服务器可用带宽时,防御动作执行模块分配剩余带宽使得正常流量比例大于恶意流量,包括如下步骤:
[0020]
根据深度强化学习智能体处理模块输出的原始允许通过流量的集合tr,在约束条件下,基于softmax函数,对每条流允许通过的带宽重新分配,将重新分配后的流允许通过流量的集合tr
′
,分别赋值给与流表绑定的meter表,超过meter表设定值的流量将被丢弃。
[0021]
进一步地,所述约束条件为将允许通过边缘交换机的总流量,限制在服务器负载us的95%内。
[0022]
进一步地,反馈采集模块计算奖励函数值reward:
[0023]
reward=0.9pn+0.1(1-pm)。
[0024]
一种sdn架构下基于深度强化学习的ddos攻击主动防御方法,包括如下步骤:
[0025]
(1)环境初始化:初始化参数总的训练轮数eposides,每轮的训练步数steps;当前训练所处轮数eposide=1,当前训练所处的步数step=1;
[0026]
(2)初始化用户发包的大小和间隔,当前训练步数设置为step=1;
[0027]
(3)sdn控制器主动下发消息请求δt内边缘交换机的状态,包括交换机的端口信息和通过交换机的流信息;
[0028]
(4)解析步骤(3)获取的状态信息;
[0029]
(5)判断是否满足step《steps;
[0030]
(6)如step不小于steps,则判断是否满足eposide《eposides:如是,eposide计数加1,回到步骤(2);如否,结束;
[0031]
(7)如step小于steps,则将步骤(4)解析的网络状态信息作为近段策略优化算法的输入,输出对应流允许通过的比例集合tr;
[0032]
(8)利用带宽重分配的方法,对近段策略优化算法输出的动作进行校验,基于softmax函数,重新分配服务器可用带宽,得到每条流可用带宽值集合tr
′
;
[0033]
(9)将tr
′
赋值给对应流的meter表限速值,超出部分的流量被丢弃;
[0034]
(10)sdn控制器主动请求δt内边缘交换机状态信息state’和服务器的状态信息,结合state中的通过边缘交换机的流信息和到达服务器流信息,计算出恶意流量比例pm和正常流量比例pn;基于这两个比例,计算奖励函数值reward;
[0035]
(11)将当前训练数据(state,action,reward,state’)存入记忆池,记忆池每收集到f1组数据,完成一次近段策略优化算法中神经网络的参数更新;
[0036]
(12)step计数加1,令state=state’,作为下一步训练中近段策略优化算法的输入,回到步骤(5)进行下一步训练,直到训练步数和训练轮数都达到最大时结束。
[0037]
本发明的有益效果是:本发明采集边缘交换机实时数据特征(流特征和端口特征)作为近端策略优化算法的输入,完成从流状态到对流允许通过比例的映射,智能地决策每条流允许通过的比例,实时主动丢弃恶意流量,同时尽可能通过正常流量,并结合到达服务器的总流量应小于服务器负载的约束条件用于决策调试,具体来说是基于softmax函数对每条流原始允许通过的大小进行带宽重分配。采用深度强化学习的近端策略优化算法,实现对ddos攻击的主动防御;决策调试过程避免了错误或冒险的决策,确保ddos攻击防御的效率和鲁棒性。本发明方法简单,实现灵活,具有较强的实用性。
附图说明
[0038]
图1是本发明ddos攻击主动防御系统的结构示意图;
[0039]
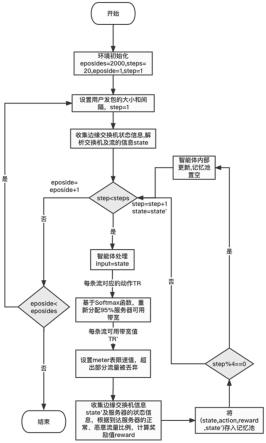
图2是本发明ddos攻击主动防御方法的流程图。
具体实施方式
[0040]
如图1所示,本发明一种sdn架构下基于深度强化学习的ddos攻击主动防御系统,包括sdn控制器、边缘交换机和深度强化学习智能体处理模块;其中,sdn控制器包括网络状态收集模块、防御动作执行模块、反馈采集模块。本发明将防御过程转换为马尔可夫决策过程,通过sdn网络控制器建立网络视图,实时采集边缘交换机上的网络特征信息(流的特征),准确反映当前网络请求状态。通过深度强化学习中的近端策略优化算法,从动态环境
中提取网络特征,将每条流的状态映射到防御决策,保证正常流量的通过并丢弃恶意流量,实现对ddos攻击的主动防御;并通过深度强化学习代理与网络之间的交互训练深度神经网络,利用经验优化缓解策略。减少在动态变化的不同网络状态下通过正常流量和丢弃恶意流量的表现差异,提高防御方法的鲁棒性。
[0041]
在本发明实施例中,sdn控制器基于opendaylight(odl)实现,边缘交换机基于open vswitch(ovs)实现。网络环境包括k个边缘交换机,且每个边缘交换机上至多有p条流。交换机的状态信息包括交换机的端口信息(每个端口的收发包大小、收发字节大小)和通过交换机的流信息(目的地址为服务器的流的包数、字节数)。服务器的状态信息包括服务器的端口信息(每个端口的收发包大小、收发字节大小)和通过服务器的流信息(目的地址为服务器的流的包数、字节数)。控制器请求状态信息到收集状态信息的时间δt选取为0.5s。本发明系统共训练2000轮(episodes),每轮训练包括200步(steps),每轮训练都重新初始化网络环境,包括用户发包的大小和间隔;每步包括完整地按顺序调用网络状态收集模块、防御动作执行模块、反馈采集模块。
[0042]
(1)网络状态收集模块,主动发送ofpt_stats_request,请求边缘交换机的状态信息,隔δt时刻后,从ofpt_stats_reply中获取返回的状态信息;控制器将状态信息以json格式发送给深度强化学习智能体处理模块。
[0043]
(2)深度强化学习智能体处理模块基于近端策略优化算法实现,该模块的输入state为网络状态收集模块收集到的交换机的端口信息e和通过交换机的流信息f,state=[(e1,f1),...,(ek,fk)],其中fk=[f
k1
,f
k2
...f
kp
],当未收集到某条流的状态时,对应流的状态f
kp
为0。该模块的输出为aciion=[(a
11
,...,a
1p
),...,(a
k1
,...,a
kp
)],a
kp
为第k个边缘交换机上第p条流允许通过的流量比例,范围在[0.05,1],k=1~k,p=1~p,当f
kp
为0时,其对应的a
kp
也为0;其中恶意流量允许通过比例趋近于0%,正常流量允许通过比例趋近于100%。例如,动作值等于0.4表示允许通过该流40%的流量。
[0044]
深度强化学习智能体处理模块包括演员(actor)神经网络a、演员(actor)神经网络b、评论家(critic)神经网络和记忆池。
[0045]
(2.1)演员(actor)神经网络a负责与网络环境交互,其中演员神经网络a将state作为输入,输出动作的分布均值sigma和均值mu,从对应的正态分布中随机采样得到action。
[0046]
(2.2)深度强化学习智能体处理模块内神经网络的更新,依赖于记忆池中收集的样本集。在防御动作执行模块执行防御动作后,从反馈采集模块收集反馈信息,包括下一个网络状态信息state’和奖励值reward;并将(state,action,reward,state’)存入记忆池。当记忆池中储存4组样本后,将样本实际收益与状态价值函数的作差,差值为优势函数值a,将函数值a的均方差作为损失值,反向传播,更新评论家神经网络的参数,这一更新过程训练4次。
[0047]
(2.3)在演员(actor)神经网络a的输出的分布上采样,与演员(actor)神经网络b的输出的分布上采样得到action概率的比值,作为ratio;演员(actor)神经网络b更新的损失值为loss=min(ratio*a,clip(1-e,1+e,ratio)*a),其中e取0.2,clip()函数将ratio限制在(0.8,1.2)的范围内。这一更新过程训练4次。
[0048]
(2.4)整个近段策略优化算法每训练16步,将演员(actor)神经网络b参数值赋给
演员(actor)神经网络a,完成演员(actor)神经网络a的更新。
[0049]
(3)防御动作执行模块,利用带宽重分配的方法对深度强化学习智能体处理模块输出的动作进行校验,并根据原始允许通过的流大小,为每条流重新分配带宽,在带宽重分配的过程中添加约束条件,即允许通过边缘交换机发往服务器的总流量不超过服务器可用带宽。
[0050]
具体地,针对两种网络状况进行安全防御:
[0051]
第一种是,当允许通过边缘交换机的总流量大于服务器可用带宽时,防御动作执行模块根据约束条件,减小了能够到达服务器的流量大小,能够保护服务器发生过载。
[0052]
第二种是,当允许通过边缘交换机的总流量小于服务器可用带宽时,由于发生ddos攻击时,攻击者为了招募更少的代理主机来使服务器过载,恶意主机倾向于在短时间内发送比正常主机更大的流量,分配剩余带宽可以使得正常流量比例大于恶意流量,能够有效提升正常流量通过率。具体步骤如下:
[0053]
深度强化学习智能体处理模块输出原始允许通过的流量大小action后,基于softmax函数,对每条流允许通过的带宽重新分配;并将允许通过边缘交换机的总流量,限制在服务器负载us的95%内。令原始γ条流允许通过流量的集合为tr=[tr1,tr2....,tr
γ
],经过重新分配后的集合tr
′
表示为:
[0054][0055][0056]
将重新分配后的tr
′
,分别赋值给与流表绑定的meter表,达到保证正常流量通过,及限制恶意流量的效果。这一过程通过openflowplugin中salflowservice和salmeterservice的api来插入、删除和更新流表来实现,超过meter表设定值的流量将被丢弃。
[0057]
(4)反馈采集模块:防御动作执行模块执行后触发反馈采集模块,此时反馈采集模块调用网络状态收集模块主动发送ofpt_stats_request,请求边缘交换机和服务器的状态信息,隔δt时刻后,从ofpt_stats_reply中获取返回的下一个网络状态信息state’;再结合网络状态收集模块收集的上一网络状态信息state中通过边缘交换机的流信息和到达服务器流信息,计算出恶意流量比例pm和正常流量比例pn。基于这两个比例,计算奖励函数值reward=0.9pn+0.1(1-pm)。反馈采集模块将下一个网络状态信息state’和奖励函数值reward反馈给深度强化学习智能体处理模块。
[0058]
如图2所示,本发明一种sdn架构下基于深度强化学习的ddos攻击主动防御方法,具体实施如下:
[0059]
(1)环境初始化。初始化参数总的训练轮数eposides=2000,每轮的训练步数steps=200,当前训练所处轮数eposide=1,当前训练所处的步数step=1。
[0060]
(2)初始化用户发包的大小和间隔,当前训练步数设置为step=1。
[0061]
(3)opendaylight控制器主动下发消息请求δt=0.5s内边缘交换机的状态,包括交换机的端口信息和通过交换机的流信息。
[0062]
(4)解析步骤(3)获取的状态信息,状态信息包括目的地址为服务器的流的包数、字节数,以及边缘交换机每个端口的收发包大小、收发字节大小。这些状态信息有效反映了当前网络的向服务器发送的请求状态,以及服务器是否发生拥塞。
[0063]
(5)判断是否满足step《steps。
[0064]
(6)如step不小于steps,则判断是否满足eposide《eposides:如是,eposide计数加1,回到步骤(2);如否,结束。
[0065]
(7)如step小于steps,则将步骤(4)解析的网络状态信息作为近段策略优化算法的输入,输出对应流允许通过的比例集合tr。
[0066]
(8)利用带宽重分配的方法,对近段策略优化算法输出的动作进行校验,基于softmax函数,重新分配95%服务器可用带宽,得到每条流可用带宽值集合tr
′
。
[0067]
(9)将tr
′
赋值给对应流的meter表限速值,超出部分的流量被丢弃。
[0068]
(10)opendaylight控制器主动请求δt内边缘交换机状态信息state’和服务器的状态信息,结合state中的通过边缘交换机的流信息和到达服务器流信息,计算出恶意流量比例pm和正常流量比例pn。基于这两个比例,计算奖励函数值reward。
[0069]
(11)将当前训练数据(state,action,reward,state’)存入记忆池,记忆池每收集到4组数据,完成一次近段策略优化算法中神经网络的参数更新。
[0070]
(12)step计数加1,令state=state’,作为下一步训练中近段策略优化算法的输入,回到步骤(5)进行下一步训练,直到训练步数和训练轮数都达到最大时结束。
[0071]
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1