离散事件无线网络仿真事件聚合方法及聚合加速性能验证方法
1.本发明涉及离散事件无线网络仿真事件聚合方法及聚合加速性能验证方法,属于无线通信和离散事件仿真领域。
背景技术:
2.离散事件仿真被广泛应用于无线网络等技术研究领域。在仿真大规模无线网络及重负载行为时,大量节点分组收发会对单个节点接收分组产生大量干扰,造成离散事件和仿真计算总时长均呈指数增长趋势,因此急需引入仿真加速手段。
3.并行与分布式技术被视作为离散事件仿真的主要加速手段,虽然并行分布式仿真可以扩大无线网络仿真的规模,处理无线仿真中产生的大量接收事件,但其性能提升是以大量计算资源和高成本并发控制为代价的。
4.时间扭变(time wrap,tw)方法被提出以解决高成本并发控制的问题,其引入摇回机制(roll-back)恢复因放松时间同步而破坏的因果关系。但当tw用于重负载无线网络,频繁的摇回处理限制了计算性能的提升期望。
5.2016年,marc leinweber等人提出一种新颖的离散事件仿真源码优化思路,主要针对目标系统状态,组合相关事件,合并源码实施运算指令优化,发挥通用编译器内在的优化能力。由于现有仿真器中大多都是面向对象结构的,无线网络的仿真涉及多个对象类以及跨对象的功能合并,代码块交织合并后,存储空间呈指数增长,所以该想法的适用范围有限。
6.综上所述,如何减少离散事件无线网络仿真中冗余的接收事件,以提高仿真速度成为了目前业内人士亟待解决的问题。
技术实现要素:
7.本发明提出一种离散事件无线网络仿真接收事件聚合方法,解决仿真大规模无线网络或重负载行为时事件数量过多和仿真总时长过长的问题。该方法通过1)当无线网络节点发送分组至节点共享无线信道时,信道存储接收分组;2)注册接收分组聚合事件或更新该事件;3)当接收分组聚合事件被调度时,网络接收节点批发处理聚合事件中的所有分组。
8.首先,本发明提出一种信道存储接收分组的方法,包括以下步骤:
9.步骤1、当无线网络节点发送分组至共享信道时,信道需遍历其连接的所有接收节点;
10.步骤2、信道根据分组中的源节点地址与接收节点地址,判断接收节点是否是源节点,若接收节点是源节点则遍历下一节点,若接收节点不是源节点则存储分组并更新分组聚合事件;
11.步骤3、存储分组时,记录分组的接收时间(p1)、持续时间(p2)、结束时间(p3)和接收节点的累计分组数量。
12.进一步地,若接收节点接收到的分组是其接收的首个分组则注册接收分组聚合事件,该事件的触发时间(e0)设为分组的接收时间(e0=p1),同时记录分组聚合结束时间(e1)并将其设为分组的结束时间(e1=p3)。
13.进一步地,若接收节点接收到的分组不是其接收的首个分组则更新接收分组聚合事件,将事件触发时间e0更新为e0=min(e0,p1),将分组聚合结束时间e1更新为e1=max(e1,p3),其中,min(a,b)表示从a和b中取出最小值,max(a,b)表示从a和b中取出最大值。
14.其次,本发明还提供一种批发处理分组方法,当聚合事件被调度时,将接收节点所记录的累计分组等效为一个接收时间为步骤4所述e0、结束时间为步骤4所述e1的分组进行处理。
15.最后,本发明提供了一种离散事件无线网络仿真事件聚合加速性能验证方法,分为以下步骤:
16.步骤1,设计无线站点分布场景并在ns-3仿真平台实现该场景。所有站点以自组织方式组网,n个源站点分布在圆周上,并周期性同时向位于圆心的0号站点发送udp分组,0号站点响应接收,为节点单播方式(ucast)。源站点使用ns-3的udpechoclient,宿站点0配置udpechoserver。为避免多跳路由对性能验证的干扰,圆半径设置为5米,信号传播损耗使用ns-3的固定接收功率模型(fixedrsslossmodel)以避免捕获效应的干扰。
17.步骤2,将仿真的业务流配置分为二个阶段:第一阶段各个源站以互不干扰方式轮流向目标站点(0号站点)发送一个udp分组,用于地址解析,第二阶段n个源站点同时发送udp分组。
18.步骤3,增加一种源站点以广播方式(bcast)发送udp分组场景,此时,mac层退避和重传被关闭。
19.步骤4,采用无线网络仿真事件聚合方式时计算总时长(tb)公式:
20.tb=t0+t1n1+∑
n≥k>1
nkt2(k)#(1)其中,t0表示地址解析时段时长,t1表示单分组事件的计算时长,t2表示组合事件的批发仿真时长,n1为单分组事件数,nk为包含k个分组的组合事件次数。
21.步骤5,采用ns-3原有处理逻辑时仿真计算总时长(ty)公式:
22.其中,符号表示同步骤4。
23.步骤6,给出站点单播方式下的加速因子计算公式:
24.其中,ty是指步骤5所述的采用ns-3原有处理逻辑时仿真计算总时长,tb是采用无线网络仿真事件聚合方式时计算总时长。
25.步骤7,给出站点广播方式下的加速因子计算公式:
26.所有源站点以ip广播方式发送udp分组时,mac层退避和重传被关闭。对应的有,nn=1,且nk=0,对所有n》k≥1。
27.步骤8,开启0号站点分组捕获跟踪记录,并使用wireshark解析分组,按照步骤6和步骤7的加速因子计算公式计算加速因子,分析事件聚合方案的加速效果。
28.目前离散事件仿真系统均采用单事件调度流程,本发明将多个事件聚合实现了仿
真计算加速。1)通过存储各个接收节点累计接收的分组,将分组接收事件进行聚合,并在聚合事件被调度时,由接收节点批发处理接收节点所记录的累计分组。2)通过事件聚合极大地减少了离散事件数量,提高仿真计算速度。本方案针对离散事件仿真的计算模型,因此具有广泛的扩展应用价值,能与并行分布式计算共同作用。
附图说明
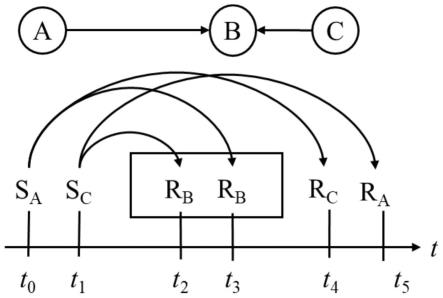
29.图1是本技术描述的事件时序示意图。
30.图2是本技术提出的事件聚合的处理流程图。
31.图3是本技术描述的用于性能验证的节点拓扑图。
32.图4是性能验证的最大并发量和并发占比的结果图。
33.图5是加速因子计算结果图(单播业务)。
34.图6是加速因子计算结果图(多播业务)。
具体实施方式
35.下面结合说明书附图对本发明的技术方案做进一步的详细说明。
36.图1用a、c节点向b节点发送分组的场景描述事件聚合方案,其中a、c节点与b之间的距离不相同。图1下部分表示事件调度和产生过程,其中s
x
表示节点x发送分组事件,r
x
表示节点x接收分组事件。
37.图1中,a、c节点分别在t0和t1时刻调用分组发送方法发送分组,信道对象模拟广播过程会将分组复制多份,通过事件注册和延后回调方式经由分组接收方法交给信道连接的接收节点。b、c节点处理a节点分组事件的时间分别为t3、t4,a、b节点处理c节点分组的时间分别为t2、t5。b距离c节点近,产生的传输时延较小,所以会出现b接收c节点分组事件的预定处理时间早于t3的情况。红色框表示可以进行聚合的事件。
38.在单线程事件驱动架构的仿真器里,事件处理过程都依次提取出图1中单个事件并处理,共处理六次。对于时域上重叠产生冲突的rb事件,b节点其实可以一同处理的,即可以将两个rb事件合并为一个事件并处理,如图1中黑框所示。
39.本技术提出一种离散事件无线网络仿真事件聚合方法,具体流程图如图2:
40.步骤1、当无线网络节点发送分组至共享信道时,信道需遍历其连接的所有接收节点;
41.步骤2、信道根据分组中的源节点地址与接收节点地址,判断接收节点是否是源节点,若接收节点是源节点则遍历下一节点,若接收节点不是源节点则存储分组并更新分组聚合事件;
42.步骤3、存储分组时,记录分组的接收时间(p1),持续时间(p2),结束时间(p3)和接收节点的累计分组数量;
43.步骤4、更新分组聚合事件时,接收节点收到首个分组则注册分组聚合事件,该事件的触发时间(e0)设为分组的接收时间(e0=p1),同时记录分组聚合结束时间(e1)并将其设为分组的结束时间(e1=p3);接收节点接收到后续分组后e0=min(e0,p1),e1=max(e1,p3),其中,min(a,b)表示从a和b中取出最小的值,max(a,b)表示从a和b中取出最大的值。
44.步骤5、当聚合事件被调度时,将接收节点所记录的累计分组等效为一个接收时间
为步骤4所述e0、结束时间为步骤4所述e1的分组再进行处理。
45.进一步地,选用ns-3仿真器中无线模块进行本技术提出的事件聚合方案加速性能验证。其步骤如下。
46.步骤一:设计站点分布场景如图3。所有站点以ad-hoc方式组网,n个源站点分布在圆周上,并周期性同时向位于圆心的0号站点发送udp分组,0号站点响应接收。源站点使用ns-3的udpechoclient,宿站点0配置udpechoserver。为避免多跳路由对性能验证的干扰,圆半径设置为5米,信号传播损耗使用固定接收功率模型(fixedrsslossmodel)以避免捕获效应的干扰。站点总数n为1-800可变,站点发送分组间隔为1秒,分组长度为64字节。
47.步骤二:进行初步实验并观察。经初步实验发现,当n较大时,并发冲突长时间持续发生。所以,将仿真的业务流配置分为二个阶段:第一阶段各个源站以互不干扰方式轮流向目标(站点0)发送一个udp分组,第二阶段n个源站点同时发送udp分组。第一阶段构成实验统计本底,通过增大第二队段的分组发送数量,可减小第一阶段对性能验证的干扰。
48.随着n增大,仿真网络的并发分组数量得到提高。但受mac层指数退避的控制,并发量又会被缩减,结果如图4。从图4可见,最大并发量(m)随站点数的变化近似为线性相关,并发占比(r)随站点数的变化则是线性负相关的。可预期的加速峰值,可能出现在n《100的仿真网络中。
49.因此为了增大并发量,设置节点为广播方式以减少mac层退避的影响。
50.步骤三:设置两种条件,一种是节点单播方式、混合了退避过程的综合仿真(ucast),一种是广播方式、关闭了指数退避的批发仿真(bcast)。
51.步骤四:加速性能测试与分析。
52.根据以上仿真场景设计,设batch仿真的计算总时长记为tb,它包括地址解析时段时长(t0)、单分组事件的计算时长(t1)和组合事件的批发仿真时长(t2)。
[0053][0054]
其中,n1为单分组事件数,nk为包含k个分组的组合事件次数。
[0055]
同等仿真条件下,相应的yans计算总时长为:
[0056][0057]
所有源站点以ip广播方式发送udp分组时,mac层退避和重传被关闭。对应的有,nn=1,且nk=0,对所有n》k≥1。参考并行与分布式计算的加速因子定义,设:
[0058][0059][0060]
其中,式(3)对应于单播方式、混合退避过程的综合仿真,式(4)对应于广播方式、剔除退避过程的批发仿真。
[0061]
图5为节点数(n)固定为80,综合仿真计算总时长的实验结果统计。图6给出了分组数(p
src
)固定为100,综合仿真和批发仿真加速因子随n的变化。
[0062]
从图5可以看出,随着源站点发送分组数(p
src
)的增加,仿真计算总时长呈线性增长。当p
src
《100时,综合仿真加速因子(f)最大约为1.3。
[0063]
从图6可见,综合仿真(ucast)最大加速性能发生在n《100的情况。而从剔除mac退避的批发仿真(bcast)可以更清楚地看到,本设计的针对并发冲突的事件组合和批发仿真方法,其计算加速因子随n增大而增大,即,网络规模越大,批发仿真的性能提升效果越好。当n=1000时,f可达7.5。
[0064]
以上所述仅为本发明的较佳实施方式,本发明的保护范围并不以上述实施方式为限,但凡本领域普通技术人员根据本发明所揭示内容所作的等效修饰或变化,皆应纳入权利要求书中记载的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1